基于多尺度及双注意力机制的小尺寸人群计数
2021-10-05王良聪吴晓红陈洪刚何小海
王良聪,吴晓红,陈洪刚,何小海,潘 建,赵 威
(1四川大学 电子信息学院,成都610065;2中国民航局第二研究所,成都610041)
0 引 言
利用现代信息技术及创新成果,打造宜居、安全、便利、智能的生活环境,是社会良性发展的普遍追求。近年来,大量人口选择汇集在城市工作、安家,城市单位面积内的人口密度越来越大,因此带来了一系列的问题,这些问题是高效、有序的社会管理面临的巨大挑战。如2020年1月7日,伊朗高级将领苏来曼尼遭遇美方突袭不幸身亡,伊朗民众纷纷为其送葬,但送葬的过程中发生了意外,百万民众送别时发生踩踏事件,至少造成了56人死亡、213人受伤。因此,提前对人群信息进行快速统计,避免严重的公共安全责任事故发生是必要的。人群密度估计,需要重点关注人群的分布信息,然而实际场景中往往面临着相似物体(如树叶,车辆)的干扰,很难从局部小区域得出判定;在此情况下,人类的做法是观察更久,同时结合其它的周围信息进行判断。受此启发,本文设计了双注意力模块来解决这样的问题。由于摄像机拍摄视角的多样性和人群位置的复杂分布,图像中的人头尺度是变化多样的,为了应对视角剧烈变换问题,设计了一个多尺度特征融合模块,来增强网络的多尺度特征提取能力,并融合多尺度信息。本文提出的基于多尺度及双注意力机制(Multi-Scale and Dual Attention,MSDA)的小尺寸人群计数网络,实现端到端的人群计数。即输入单幅图像,就可以通过对生成的密度图进行积分,得到图像中的人群数量。本文在Shanghaitech数据集和Mall数据集上进行了实验,并取得了较好的效果。本文的贡献主要有以下3点:
(1)受KNN自适应[1]标注方法的启示,根据相机的成像原理以及画面的透视畸变,提出了基于透视关系的密度图生成方法。
(2)设计了一个多尺度特征融合模块,以达到多尺度特征融合及丰富特征信息的目的。
(3)设计了空间—通道双注意力模块,来实现对无关特征的弱化,强调重要特征。
1 相关工作
早期的研究中,采用基于检测的方法[2],即使用整体或部分身体特征的检测,训练一个分类器,利用从行人中提取到的整体或局部结构来检测行人,从而进行计数。由于基于检测的方法,在背景杂乱且密度高的图像上,表现性能会大大降低,因此有人提出了基于回归的计数方法[3],该方法是学习一种从特征到人数的映射。但此方法会忽略空间信息,还会受到尺度和视角剧烈变化的影响,导致计数能力变差。
近年来,深度卷积神经网络得到了广泛应用,在人群计数方向也取得了显著的成果。例如,使用深度卷积网络直接端对端生成密度图的方法[4]。文献[1]中提出,利用3个具有大中小的卷积核的神经网络MCNN,来分别提取人群中的特征,然后通过卷积层来生成密度图从而进行计数。文献[4]中,使用3个不同的CNN回归器和一个分类器来生成密度图。Wu等[5]使用反向卷积层,自适应的分配权重给两个分支,将计数问题看做分类,从而来进行人群计数;Chen[6]等人使用像素级的注意力机制对图像进行分级,使之生成高质量的密度图。
由此可见,近年来有许多学者针对人群计数这一课题做出了努力。但是大部分的网络[7-8],虽然性能不错,但还存在一些未能很好解决的问题。如,存在特征信息提取不充足,无法从多个感受野中提取多尺度信息,也没有融合多个尺度中的特征,达到丰富细节特征的目的;并且无法排除背景中的干扰,弱化无关特征,强调重要特征,从而来提升人群计数的准确度。基于此,本文提出了一种基于多尺度及双注意力机制的小尺寸人群计数网络来解决上述问题。
2 提出方法
由于本文的任务对象主要为小尺寸密集人群,过深的网络将存在过度的冗余,并且不利于性能特征的迁移。而VGG-16模型深度较小,能够在保证足够源域特征的同时兼顾小尺寸目标,因此本文模型将VGG-16作为主干网络。将VGG-16与提出的多尺度特征融合模块与空间-通道双注意力模块相结合,来对图像中的小尺寸目标进行检测。
2.1 密度图生成
针对人数估计,数据集[2-3]将画面中的行人标记分别以头部某点的位置坐标(头部轮廓几何中心最佳)的形式保存,即点标注形式。采用点标注的主要原因:一是大大提高效率,不用过分地去考虑每个目标精确的尺寸问题;二是因为人体头部包含的信息较多,并且在高密度人群中,仅仅头部可见。因此使用点标注来标注头部,是人群估计中较为普遍的标注方式。
假设目标的标记坐标为pi,则对图像中n个目标的总体标注函数为:

对于点标注,文献[2]中将每个目标的标注坐标都与二维高斯低通滤波函数Gσ(P)进行卷积操作后,则将形成整体的目标密度图D(p),即:

经过此操作,就可将孤立的点标注扩散至贴合目标头部轮廓的置信密度分布。若假设目标头部是圆形,通过限定二维离散高斯低通滤波函数的作用区间和标准差,就可以使得单个目标在此区间内的密度积分求和为1,从而拟合图像中的具体人数。
文献[1]中提出使用KNN算法自适应地估计图像中目标的尺寸,但场景的密集程度并不存在严格划分标准,难以形成一个统一、可移植的泛化方案。鉴于此,本文根据相机成像原理及图像的透视畸变问题,提出了基于透视关系的密度图生成方法。由于各成像设备的陈设一般都为水平放置,会导致在同一水平线上的人的尺度大致相同,符合远小近大的成像原理,据此关系可得出人群分布的位置与图像上的纵坐标呈正相关。
设目标头部的尺寸为Px,可得出整体图像的透视关系为:

其中,Py表示图像中的纵坐标;k表示透射畸变因子;b为偏移因子。k、b为待定系数,可根据图像中两个纵坐标位置不同的目标人头,确定整幅图像的透视关系,选择两个纵坐标不同的目标Px1、Px2,可得:
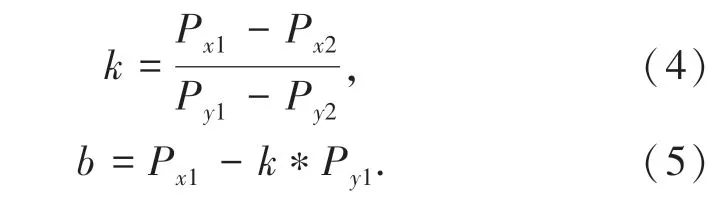
由公式(4)、式(5)可得出:
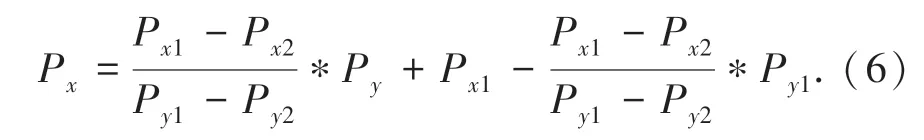
依据此方法即可对图像中的人群进行标注,从而生成密度图。如图2所示。其中图2(a)为Zhang等[3]所提出方法的示意图,图2(b)为本文方法的示意图。由图中可看见,本方法自适应的匹配了人头尺寸。

图2 不同密度图高斯核尺寸的效果对比Fig.2 Comparison of the effect of Gaussian kernel size in different density maps
2.2 MSDA模型
如图1所示,本文MSDA模型分为以下4个模块:VGG-16特征提取模块,多尺度特征融合模块(MFF),空间-通道双注意力模块(SCA)及密度图生成模块。Fi和Fd为MSDA模型的输入与输出,以VGG-16中的部分卷积层及池化层作为基础结构,

图1 MSDA模型Fig.1 Multi-scale and dual attention mechanism model
在其第4、7、10层分别提取特征进行解码设计,而后将提取的3个层的特征分别送入3个MFF模块中,1×1卷积之后将输入的特征进行转换并使得通道数统一,再对其使用膨胀卷积来扩大感受野,最后进行特征融合,并将深层融合的特征作为输入,传递给浅层,可得:

式中,H(·)表示卷积操作;⊗表示逐像素相乘操作;表示经过MFF层进行过多尺度特征融合的深层输出特征;Fin是浅层特征和深层特征融合后的多尺度特征。将低层网络的融合特征与高层网络所提取的特征Fout进行逐像素相乘操作,可以使得低高层特征进行融合,得到丰富的上下文信息。
经过SCA模块,使用平均池化、最大池化以及卷积操作达到对无关特征的弱化及重要特征的强调,最后将特征Fo输入密度图生成模块。首先经过一个3×3卷积和一个1×1卷积,再与上一层的特征结合,重新送入卷积层中;然后通过2个3×3卷积,最后使用concat操作对特征信息进行结构化的相加融合,加强特征之间的联系,相较于直接特征叠加,大幅减少了特征的通道数。由此可得:
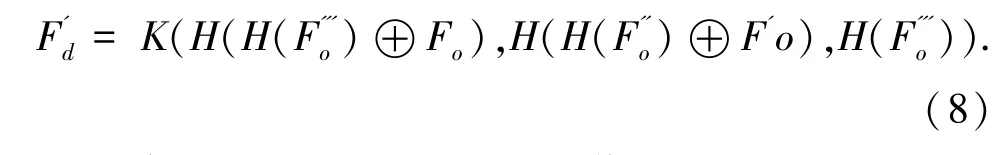
其中,H(·)表示卷积操作;K(·)表示concat操作;⊕表示逐像素相加操作;分别为第4、7、10层经过SCA模块的特征。为3层concat之后的最终特征信息层级,将送入1×1卷积层中,得到密度图Fd。
2.2.1 多尺度特征融合模块
由于摄像机拍摄的视角和人群位置的复杂性,图像中的人头尺度是复杂多样的,因此想要更准确的进行计数,就需要进行多尺度特征提取。本模块分别在3个不同层中的单层特征图中提取多尺度信息,然后融合提取后的信息。如图1所示,在MFF网络中,首先使用一个1×1的卷积层对特征映射的通道进行压缩整合。由于低层网络的感受野较小,其语义表征能力弱,因此将整合的低层特征分别送入三个膨胀率为1、2、3的膨胀卷积网络中,可得:
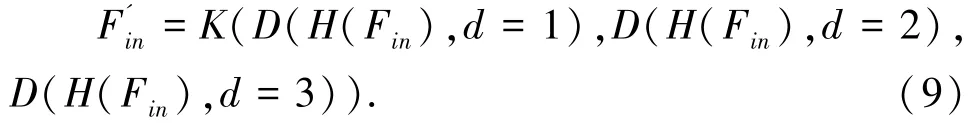
其中,H(·)表示卷积操作;K(·)表示concat操作;D(·)表示膨胀卷积操作及其中的d为膨胀率。Fin经过三列膨胀卷积操作,使用concat操作以及特征级联进行多尺度的特征融合,再经过3个3×3卷积扩大感受空间,从更广的视野非线性判断各位置的特征取舍;再经过一个1×1卷积层将特征进行转换并使得通道数统一,得到MFF模块以此来扩大低层特征中的感受野,将语义表征能力增强。
2.2.2 空间-通道双注意力模块(SCA)
一般的注意力模块只能将原始图片中的空间信息变换到另一个空间中,并保留关键信息或解决信息超载问题,而无法在空间和通道上关注特征和加强联系。鉴于此,本文设计了一个空间-通道双注意力模块,使用通道注意力网络,学习各通道的依赖程度,并根据依赖程度对不同的特征图进行调整,再结合使用空间注意力。此举不仅弥补了通道注意力的某些不足之处,还可以强调重要特征信息并忽略了无关特征信息。本模块构成如图1中SCA模块所示。首先将输入的特征Ff,分别送进2个不同的通道,然后进行1×1的卷积操作来整合特征,再分别在2个通道中使用最大池化层和平均池化层。可得:
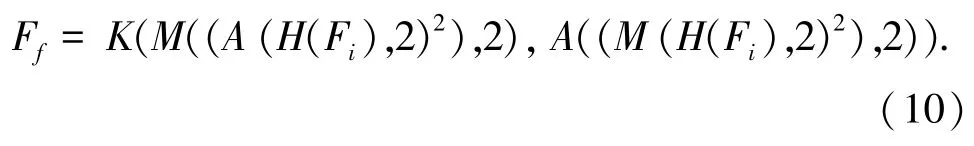
其中,H(·)表示卷积操作;K(·)表示concat操作;M(·)表示最大池化操作;A(·)表示平均池化操作;公式(10)中的2表示pool=2。 使用最大池化层M(·)可以收集目标中更细节的线索,而平均池化层A(·)可以将特征进行压缩,此时就实现了在通道上关注人群特征。将经过处理的特征快速进行不同于上一次的平均池化以及最大池化,加上空间注意力。
最后将特征Ff进行上采样,将其与原始特征Fi进行逐像素相乘操作,得到输出特征Fo。则有:

其中,Upsample(·)表示上采样操作,⊗表示逐像素相乘操作。
3 实验与分析
3.1 模型训练
在训练阶段,人群密度研究工作中一般都将欧几里得损失当做训练损失,损失函数定义如下:
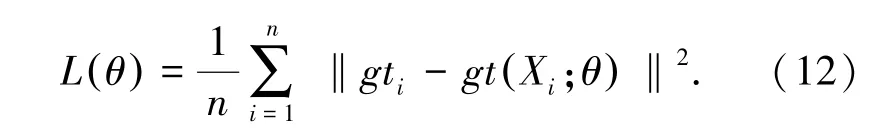
其中,g ti表示输入的第i张地面真实密度图;gt(Xi;θ)表示预测估计的密度图;Xi表示输入的第i张图像;θ是计数网络中可学习的参数。
因Adam[8]具备计算效率高、内存要求低等优点,本文将其作为优化器;设置初始学习率(Learning rate)为0.000 01;同时为了使梯度下降方向更稳定、准确、防止震荡,令每次训练输入所选取的样本数(batch size)等于4,并随机打乱每次样本的输入顺序。
3.2 评价指标
本文采用的评价指标:平均绝对误差(Mean Absolute Error,MAE)、均 方 误 差(Mean Squared Error,MSE)。其定义如下:

其中,n代表测试集的样本总数;gti表示第i张测试图的实际人数值;而eti表示对第i张测试图的估计值。MAE主要是考量真实值与估计值之间的误差平均,反映的是估计的准确性,而MSE作为方差指标,反映的是算法鲁棒性。由于这2项指标为误差度量,因此算法的MAE、MSE值越小越好。
3.3 数据集
3.3.1 Shanghaitech数据集
该数据集分为两部分:Shanghaitech Part_A(简称SHA)和Shanghaitech Part_B(简称SHB),并分别将图像中人体头部的中心区域某点的位置坐标保存在文件中。SHA源于互联网照片,由训练集中的300张图像和测试集中的182张图像构成,存在少量的灰度样本,共计241 677个标注点,照片质量不一,且绝大多数图像都拥有高密度人群;该数据集样本风格各异,且存在很多相似目标的干扰,某些极其拥挤的场景甚至人眼也难以准确计数,适合检验算法对远景高密度人群的估计能力。SHB拍摄于上海繁华的街道,由400张训练图像和316张测试图像构成,场景不固定,共计88 488个标注点;该数据集更贴近具体街道应用场景,训练集、测试集中存在很多相似场景,画面中人员特征信息较多,能够检验算法在城市监控场景中的表现能力。
3.3.2 Mall数据集
该数据集获取于国外某购物中心,由拍摄视频中抽取的2 000帧图片构成,且场景固定,并尽量以头部中心点的坐标作为标注,共计62 325个标注点。数据集的难点是远处目标模糊以及植物的干扰,其代表的是稀疏、固定场景。参照文献[2],选择前800帧图像训练,其余1 200帧图像进行测试。
3.4 实验结果
3.4.1 在Mall数据集的实验结果比较
在Mall数据集上,将本文的网络与其它网络进行了比较,比较结果见表1。结果表明,提出方法的性能有所改进;与2020年提出的CWAN[9]网络相比,MAE和MSE分别提高了0.56和0.87。在Mall数据集上的人群密度效果如图3所示。
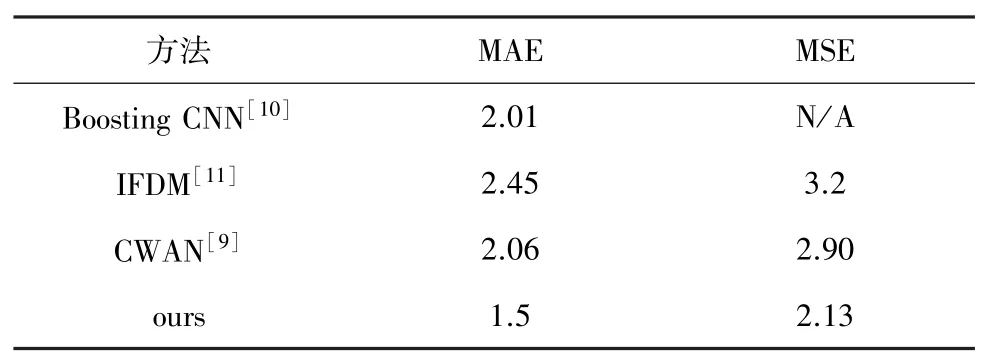
表1 Mall数据集的实验结果对比Tab.1 Comparison of experimental results in the mall dataset
3.4.2 在Shanghaitech数据集上的实验结果比较
在ShanghaiTech partA&partB两个数据集上,将本文网络和其它网络进行了比较,结果见表2。结果表明,本文提出的方法性能有显著改进。在SHA中,本 文 方 法 与 网 络CSRNet[12]相 比,MAE/MSE分别提高了4.5/12.7,与2020年所提网络HANG[13]相比也提高了1.6/4.1;在SHB部分,MAE/MSE比CSRNet提高了2.18/2.71,与HANG相比提高了1.58/4.31。其效果如图3所示。

图3 数据集中估计的密度图(左为SHA,中为SHB,右为Mall)Fig.3 The estimated density map in the dataset(SHA on the left,SHB in the middle,Mall on the right)

表2 Shanghaitech数据集实验结果对比Tab.2 Comparison of experimental results in the Shanghaitech dataset
3.5 网络结构分析
为了验证本文所提出的MFF模块及SCA模块的有效性,在ShanghaiTech数据集上进行了验证,验证结果如表3所示。SHA部分的MAE/MSE提高了7.24/10.25;SHB部 分 的MAE/MSE也 同 样 提 高 了0.55/1.74,MFF模块中使用1×1卷积核进行特征信息整合,可在不影响感受野的情况下增强决策函数的非线性,并且结合膨胀卷积之后可在不损失图像分辨率与尺寸情况下有效扩大感受野,减小参数量。MFF模块增加了多尺度特征融合,提取不同人头的细节信息并且使得高低层特征融合,联合上下文信息。

表3 网络结构分析结果Tab.3 Network structure analysis results
由表3数据可以看出,添加了SCA模型之后,在SHA和SHB两个数据集上都有明显的提高。如SHA上的MAE/MSE分别提高了6.0/3.54;在SHB上也提高了0.48/0.53,SCA模块中对输入的特征分别施加3层的平均池化、最大池化后进行特征叠加,为之后的操作提供更多的选择及降低参数量;并且SCA模块使用取舍权重因子与原输入特征相乘得到输出特征,以实现对输入特征的弱化;因此,SCA模块可以有效地弱化无关特征,强调目标信息。
4 结束语
本文提出的基于多尺度和双注意力机制的人群计数网络模型,使用膨胀卷积、最大池化和平均池化设计了MFF模块和SCA模块。MFF模块扩大了小目标的尺度空间,使浅层特征和深层特征进行了多尺度特征融合,改善了小目标中的特征信息缺乏问题和尺度剧烈变化问题。SCA模块使用池化层将注意力放在小目标上,可排除无关干扰信息,提取有效特征、减小参数量。在数据集上的测试结果表明,此方法比现有许多方法都有效,可应用于景区游客统计,反映游客的实时分布,安排相应的旅游服务;也可对拥挤的现象进行预警,实时的检测人群密度,以发现异常聚集或逃离事件的发生,从而及时协调医疗、警员力量。
