基于YOLO的违禁品检测深度卷积网络
2021-09-30李柏岩刘晓强冯珍妮
朱 成, 李柏岩, 刘晓强, 冯珍妮
(东华大学 计算机科学与技术学院,上海 201620)
基于X光扫描的安检系统是目前航空和运输业违禁品检测最常用的安全保障设施。系统扫描快速通过的行李、包裹,实时生成X光图像供安检人员检查。显然,这种安检的可靠性很大程度上依赖于安检人员的经验和能力。但长时间枯燥的人工视觉检视会使安检员疲劳,容易发生误判、漏判现象,带来安全隐患。因此,高精度的自动违禁品识别技术一直受到研究者的关注,但这些技术[1-2]的识别率难以达到实际需要,一直没有被普遍使用。近年来,随着深度学习技术的出现和日趋成熟,特别是卷积神经网络(convolutional neural network,CNN)所表现出的优秀图像分类能力,为这一领域的研究带来了新助力。
基于X光图像的违禁品检测是图像分类与目标检测的一种特例,有很多特殊性。首先,X光安检机一般应用于人流密集的场所。为避免拥堵,检测工作应在较短时间(约2~3 s)内完成,有实时性要求。其次,X光扫描将行李中的物体映射到二维的图像平面,原本在空间内交错分布的物体在平面上会出现叠加的现象。但与自然光图像不同,叠加在X光图像中的物体,仍保留各自完整的轮廓,因此叠加物体的检测可以看作密集分布物体检测问题。另外,很多小尺寸的违禁品往往难以检测,这就要求违禁品检测技术应具备检测密集分布物体和小尺寸物体的能力。
近年来,基于深度学习的图像分类和目标检测技术成为研究热点[3]。目前主流的目标检测CNN网络主要分为2类:以R-CNN[4]、Fast R-CNN[5]、Faster R-CNN[6]、Mask R-CNN[7]等为代表的Two-Stage模型和以SSD[8]、YOLOv1[9]、YOLOv2[10]、YOLOv3[11]等为代表的One-Stage模型。前者使用基于候选框推荐的检测方式,具有较高的检测精度,但因为需要对每个候选区域进行卷积操作,所以花费的时间较长,检测速度慢。后者采用端到端回归的检测方式,直接预测目标物体的类别信息和位置信息,节省了生成候选框所花费的大量时间,因此在检测速度上有较大的提升,能够满足实时检测要求。经过不断地技术积累,最新版的YOLOv3无论是在检测精度或是检测速度上都优于R-CNN系列网络模型。
本文设计的违禁品检测网络以YOLOv3网络模型为基础,针对违禁品检测的特殊性,对其一些关键机制和结构进行了改造:① 使用新的激活函数SReLU替换此前的Sigmoid函数,缓解网络训练过程中出现的梯度下降问题,并加快网络训练的收敛速度;② 使用密集卷积块替换原模型中的部分卷积块,增加网络的特征提取能力,提高模型对小体积物体的检测能力;③ 添加一个新的损失项,提高模型对于密集分布物体的检测能力。实验表明,上述改进措施与原YOLO相比,能有效提高模型的检测效果。
1 YOLOv3网络
YOLO是最早的One-Stage系列模型之一,它构建了一个端到端回归的CNN模型。YOLO英文全称是you only look once,表示只对图像进行一次处理就能同时得到位置和分类信息。该检测方式极大地提高了模型的检测速度,使模型能够满足实时性要求。
1.1 YOLOv3网络结构
YOLOv3提出了一种新的网络结构Darknet53,该结构借鉴了ResNet[12]思想,设有5个残差结构块,防止网络随层数的加深发生退化。针对以前版本对于小尺寸物体检测能力不足的问题,YOLOv3采用了多尺度检测方式,对3个不同尺寸的特征图Scale1、Scale2和Scale3进行检测。其中:特征图Scale3尺寸最大,负责预测小尺寸物体;Scale1尺寸最小,负责预测大尺寸物体。
YOLOv3在对不同尺寸的特征图进行检测时,先对特征图Scale1进行卷积操作,输出的特征图与特征图Scale2进行叠加然后再卷积。同理,卷积操作后的输出与特征图Scale3进行叠加然后再卷积,最终得到检测结果。检测结果包含了目标中心位置、宽、高、对象置信度以及类别置信度等信息。3种特征图的大小为13×13、26×26和52×52,通道数为3。这意味着3个特征图将原图分别划分为不同数量的栅格,每个栅格负责3个边界框(bounding box)的回归计算,因此最终输出结果的尺寸是3(13×13+26×26+52×52)(5+k)=10 647(5+k),其中,k为图中要检测的对象类别数。
1.2 Bounding box中心位置回归
YOLOv3将原始图片划分为S×S个栅格,如果一个目标物体的中心点落在一个栅格中,那么这个栅格负责预测该物体。事实上,模型不是直接预测中心点坐标,而是预测一个偏移量,中心点坐标则通过计算偏移量得出。中心点坐标预测计算如图1所示,一个含有违禁品的图片被划分为5×5个栅格,手枪落在第(3,3)个栅格中,该栅格就负责手枪的预测。图1中:tx、ty为模型的输出值;cx、cy为所在栅格左上角的坐标(cx、cy分别为2和2);σ(*)为Sigmoid函数。物体的中心点坐标bx、by的计算公式为:
bx=σ(tx)+cx,by=σ(ty)+cy
(1)
通过Sigmoid函数将模型输出值映射到(0,1)之间,确保了预测的中心点位置落在该栅格中。

图1 中心点坐标预测计算示意图
模型输出值tx和ty经过Sigmoid函数激活后,采用和方差计算损失值。对于Sigmoid函数,当输入值较大时,其函数值将趋近于1,导数值将趋近于0。在此情况下使用平方误差法得到的前向传播误差将很小,会出现梯度消失的现象,导致模型难以收敛。为解决该问题,通常采用交叉熵作为损失函数,交叉熵函数适用于真实值为0或1的情况。在YOLOv3中,模型输出的tx和ty经过Sigmoid函数激活后,其真实值是在0~1之间的某个值,因此交叉熵函数并不适用于此场景。
2 模型的改进
针对基于X光图像的违禁品自动检测在实际应用场景下面临的诸多难点,如实时检测、小尺寸物体检测和密集分布物体识别等,本文对YOLOv3网络结构和机制进行有针对性地改进,消除在训练中可能会出现的梯度消失隐患,并从多方面提高对象检测和对象识别的性能。
2.1 SReLU-YOLOv3
YOLOv3在计算Bounding box中心位置误差值时,使用Sigmoid激活函数配合和方差损失函数,会导致网络在训练过程中可能出现梯度消失的情况。
本文使用SReLU[13]激活函数替代Sigmoid,其定义如下:

(2)
SReLU函数的曲线如图2所示,呈S型,与Sigmoid类似。
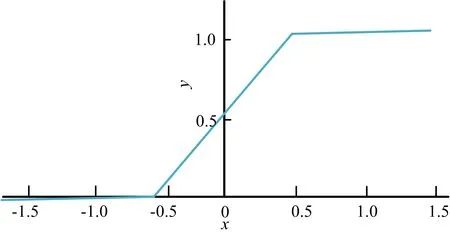
图2 SReLU函数曲线
函数分为3段,每段有固定的斜率,该做法的优点是:① 当输入值增大时,SReLU函数计算的激活值也随之增大,计算出来的损失值变化较为明显。而Sigmoid函数当输入值增加时,输出值趋近于1,变化不明显。② SReLU函数在输入值小于-0.5和大于0.5时有固定的斜率,即这2部分SReLU函数导数是一个固定值0.01。而在Sigmoid函数中,当输入值较大时,函数的导数值趋近于0。在误差的反向传播过程中,需要使用到激活函数的导数值,因而使用SReLU函数能够反向传播更大的误差值,加快模型的收敛速度。
2.2 Dense-YOLOv3
网络越深,其抽象能力越强,因此,加深网络结构是增强模型检测效果最简单的做法。经典的CNN从7层的AlexNet[14]发展到16~19层的VGG[15],到后来22层的GoogLeNet[16]都说明了这一点。但当CNN超过一定的深度后,反而会出现梯度消失、网络退化等问题,导致网络收敛速度慢,检测精度变差。针对此问题,ResNet模型在增加深度的同时引入残差结构,该结构将浅层卷积的输出与深层卷积的输出叠加,经激活操作后作为深层的结果输出。该设计的优点是:① 将浅层卷积提取的特征信息尽可能完整地传递到深层,防止因层数过多而出现网络退化问题;② 在误差反向传播过程中,尽可能多地将误差传递到浅层,防止浅层因误差太小而出现训练停滞的现象。因此,ResNet模型能够在深度增加的情况下避免梯度消失、网络退化等问题,大幅度提高了模型的检测效果。
DenseNet[17]模型进一步提出了密集(Dense)卷积结构,该结构将当前层与前面所有层建立密集连接,使层与层之间的连接变得更加紧密。Dense卷积块结构如图3所示,每个Dense卷积结构中包含4层,每层的输入由其之前所有层的输出叠加而成。
通过这种密集连接,使得不同层的特征信息得以重用,既使最后一层也能提取到第一层的特征信息。该特点让DenseNet拥有比ResNet结构更优的特征提取能力。

图3 Dense卷积块结构示意图
本文将YOLOv3中对不同尺寸特征图做卷积操作的卷积块替换成Dense卷积块,变更前后的网络结构如图4所示。
Dense卷积块的加入强化了模型对图片特征信息的传递能力,使得用于检测物体的特征图包含了浅层的特征信息,进一步提高了模型的检测性能,尤其是对小尺度物体的检测能力。
2.3 Rep-YOLOv3
在X光安检图像中,物体相互叠加是常见的现象。可以将违禁品检测归类为密集分布物体检测问题。物体密集分布又分为同类物体密集分布和异类物体密集分布2类。对于前者,早在YOLOv1阶段,1个栅格只能预测1类物体,如果2个不同类别的物体的中心点落在同1个栅格中,模型最终只能检测出其中1个类别。该问题在YOLOv2模型中得以解决,1个栅格可以预测多类物体。然而对于同类物体密集分布的检测问题,模型虽然可以有效预测出多个bounding box,但往往在最终非极大值抑制阶段被抑制掉,导致密集分布的同类物体检测效果较差。如图5所示。
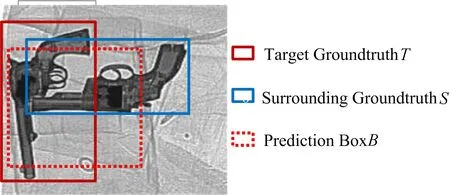
图5 密集分布物体对预测框的影响
T是目标物体的真实bounding box,S是相邻物体的bounding box,B是对目标物体的预测框。在预测过程中,B往往会受到S的干扰,偏向S而远离真实边界框T。同样,对于以S为真实bounding box预测出的边界框也会远离S而偏向T。在此情况下,负责预测2个不同物体的预测框有着极高的交并比(IoU),在非极大值抑制步骤中其中一个预测框会被抑制,最终仅产生一个预测框。
为了减少该问题带来的影响,本文参照文献[18]思想,在代价函数中添加了一个新的损失函数,该损失函数为:
Lrep=sin(IG(B,S))
(3)
其中
(4)
IG(B,S)是预测框B和相邻物体的bounding boxS的交集面积与S框面积的比例。比例越高,损失值越大。这里通过引入这样一个互斥值,尽可能拉大B与S间的距离,使B向T靠拢。这样,预测不同目标物体的预测框之间的距离就会变大,IU变小,最终在非极大值抑制操作中得以保留,进而提高模型对于密集分布物体的检测能力。
3 实验结果分析
本文在YOLOv3模型的基础上,按照上一节中描述的改进思路分别构建了SReLU-YOLOv3、Dense-YOLOv3、Rep-YOLOv3以及整合了所有改进的Contraband Detector,并逐个进行了实验。
3.1 实验数据与环境
本文的实验使用SIXray[19]数据集,该数据集中共有8 929张包含违禁品的图片。本次实验选取了其中5 276张图片,使用标注工具LabelImg进行标注。标注的违禁片包括枪、剪刀、刀、钳子、扳手、瓶装液体和金属罐等。每张图片生成1个文件,包含图片名、图片大小、含有的违禁品类别、违禁品bounding box位置等信息。
实验的网络模型运行在Ubuntu操作系统上,使用基于Keras深度学习框架实现,训练使用的GPU为11G显存的GTX1080Ti。每个模型在完整的数据集上运行100 Epoch,每批次训练16张图片,共迭代33 000次,耗时约12 h,最后选取其中训练效果最优的权重进行测试。
3.2 实验结果与分析
实验使用YOLOv3模型的检测结果作为基准,然后分别运行SReLU-YOLOv3、Dense-YOLOv3、Rep-YOLOv3和Contraband Detector模型。YOLOv3模型与Contraband Detector模型对同一张图片的检测结果如图6所示。容易看出,改进模型对于密集分布物体的检测效果有明显的改善。
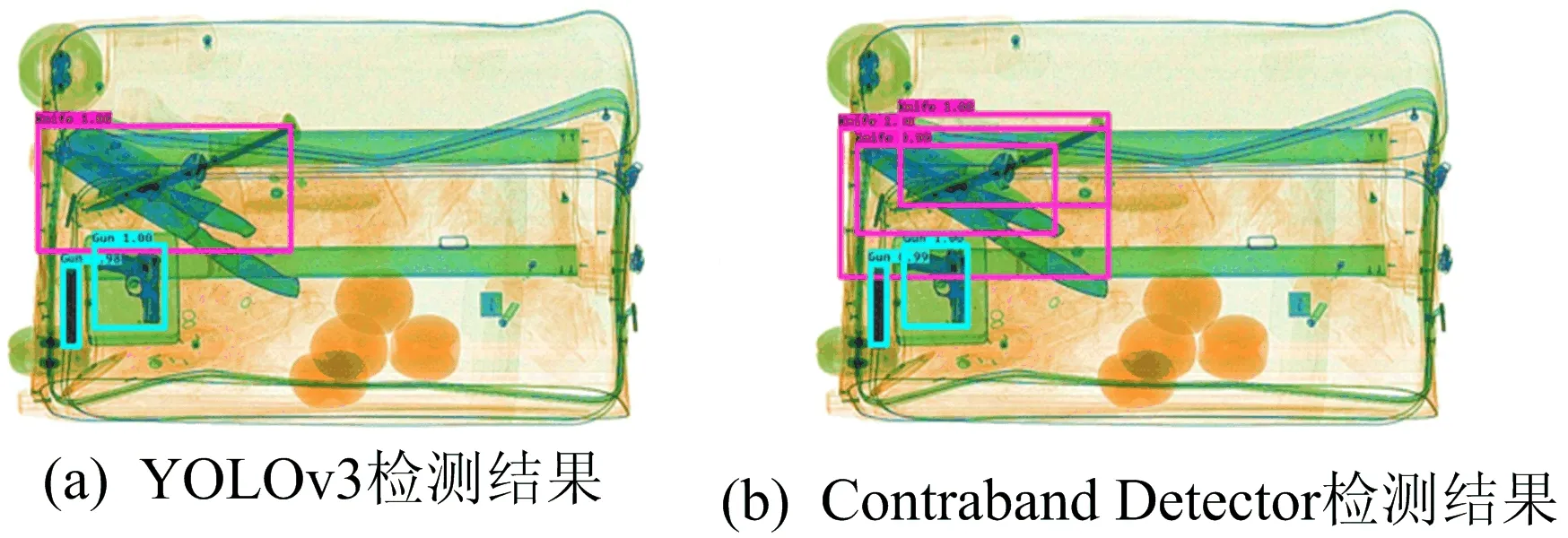
图6 不同模型的检测结果案例对比
本文挑选了200张图片用来测试模型的检测效果,如图7所示。
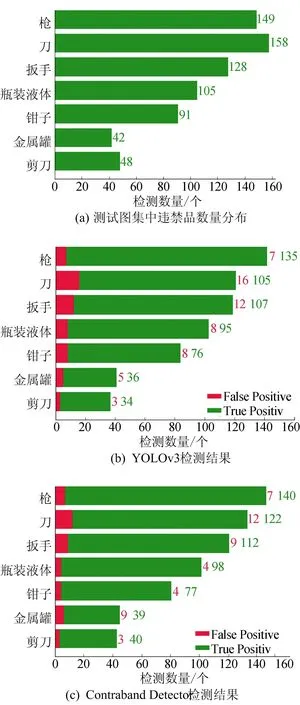
图7 检测数据中违禁品类别分布及检测效果对比
从图7可以看出,改进后的模型在检测出更多物体的同时,假阳的数量也有所减少,初步判断模型的检测效果有所提高。
目标检测领域的常用评价标准是mAP(mean average precision)。本文根据各个模型的检测数据,计算出模型对各个类别检测结果的平均精度,然后计算模型的mAP,结果见表1所列。
表1中的Y、S、D、R、C分别代表YOLOv3、SReLU-YOLOv3、Dense-YOLOv3、Rep-YOLOv3、Contraband Detector模型。从表1数据可以看出,Contraband Detector模型在各个类别的检测效果上优于YOLOv3模型,其中剪刀和刀的提升效果显著。在所有类别中剪刀的体积最小,加入Dense卷积的模型大幅提高了对剪刀的检测能力,从69.38%提升到80.51%。另外,实验所用的数据集中,刀的相互叠加现象最多,而加入新损失函数的Rep-YOLOv3对于刀检测效果为72.62%,提升最为明显。各个模型的mAP相对于原始YOLOv3模型的mAP值80.38%均有提高,并且本文模型的mAP值为86.59%,提升效果最好。
实验记录了每张图片的检测时长,计算出各个模型的检测速度,结果如图8所示。
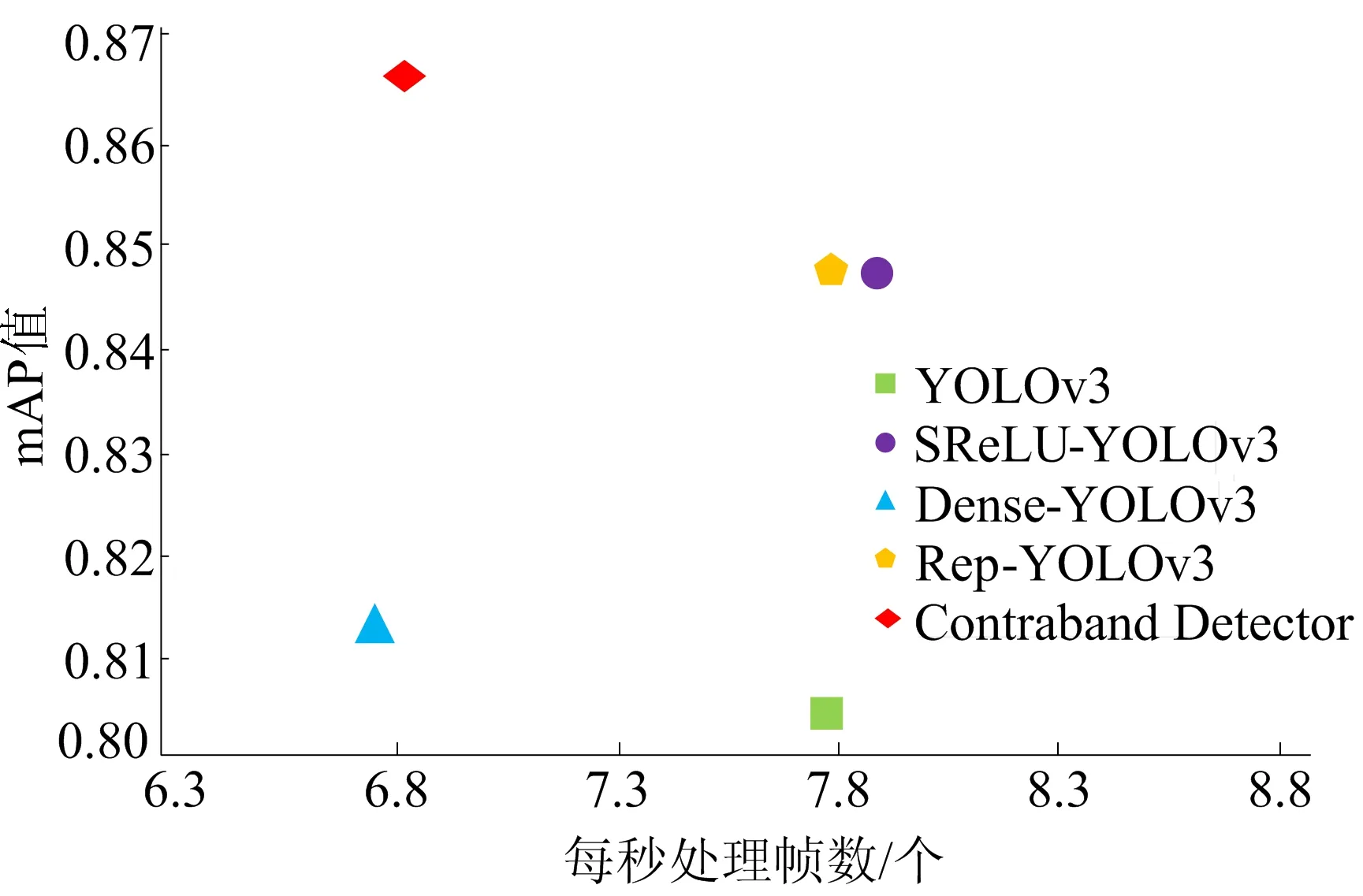
图8 模型检测速度与精度散点图
在YOLOv3的文献中,模型用C语言实现,而本实验使用Python语言,再加上硬件平台差异,本实验给出的YOLOv3模型检测速度与YOLO官方给出的数据有一定差异。SReLU-YOLOv3与Rep-YOLOv3因为未改变模型的网络结构,所以检测速度与YOLOv3相当。Dense-YOLOv3和Contraband Detector改变了网络结构,计算量增加,因此速度稍慢于YOLOv3。
4 结 论
本文研究了X光安检图像的违禁品自动检测技术,在分析了应用环境和卷积神经网络YOLOv3的一些问题后,针对性地提出了改进方案:① 使用新的激活函数SReLU代替此前的Sigmoid函数,缓解了梯度下降问题,加快了网络训练的收敛速度;② 使用Dense卷积块替换原网络模型中的卷积块,增加了网络的特征提取能力,提高了模型对小尺度物体的检测能力;③ 添加了一个新的损失项,提高了模型对于密集分布物体的检测能力。实验结果表明,改进措施能有效增强模型的检测能力,提升了mAP值,虽然在速度上略有下降,但仍然能够满足实时性要求。进一步研究工作可以改进模型的预测框选择方法,提高性能。
