基于DCS的报警优化技术研究
2021-09-28张雪王德建关国伟
张雪,王德建.2,关国伟.2
(1.中国石油集团安全环保技术研究院有限公司,北京 102206;2.中国石油渤海石油装备制造有限公司,天津 300272)
1 报警管理现状
我们对一些炼化企业的控制系统报警情况做了调研,图1是从某企业生产现场采集的渣油加氢装置“报警事件与操作事件对比图”。浅灰色代表为报警事件,深灰色代表为操作事件。可以看出,同一时间段内大量的报警事件只对应了少量的操作事件,这就说明操作人员对大部分报警并没有响应动作,因此大量报警都可能是风险等级不高的报警或无效的报警。随着过程工业自动化、智能化水平的提高,DCS、PLC、FCS等广泛应用,工艺报警的设置变得越来越容易,由于过程系统的复杂性和报警系统设计的不合理,产生了大量甚至无效的报警,这些报警信息对生产安全运行产生了重大影响。

图1 报警事件与操作事件对比图
2 信息挖掘技术研究
信息挖掘的本质是大数据的挖掘,通过训练大量数据样本,得到数据对象彼此之间的内在关联和特征,并以此为依据提取目标信息,随着计算机和人工智能的快速发展,信息挖掘与深度学习、机器学习、混合现实等多个领域的理论和技术进行了充分的融合。目前,国内外学者主要研究数据挖掘中的分类、优化、识别、预测等技术在众多领域中的应用技术。而对于石油化工行业来说,大数据时代的来临既是机遇又是挑战,生产装置规模越大数据规模就越大,对其进行挖掘分析所能得到的价值就越大。用于信息挖掘的算法主要包括关联规则法、决策树法、神经网络法和遗传算法等。
关联规则法利用交易数据、关系数据或其他信息载体,分析、挖掘和查找存在于项目集合或对象集合之间的频繁模式、关联、相关性或因果结构关系。Apriori算法是挖掘关联规则的基本算法,也是最著名的关联分析算法。但Apriori算法在较大数据集上需要花费大量的运算开销从而造成性能低下,而FP-growth却不会有这个问题,FPgrowth可以从源数据中挖掘出满足最小支持度和最小可信度的关联规则。
除了上述常见方法外,还有目前在人工智能诸多领域(如语音识别、自然语言处理、计算机视觉等)取得了突破性进展的深度学习方法。
3 报警优化设计
3.1 设计原则
本文按照独立、静态或变量值线性化设计,通过信息挖掘的关联规则法,使用FP-Growth算法对历史报警数据进行优化得到正常工作区A,如图2所示。

图2 报警工作区
确定报警数据对于异常工况的贡献度大小和各过程变量之间的相关性,通过数据预处理及FP-Growth算法将重要报警从众多关联信息中挖掘出来,使操作员不必疲于处理无效警报。报警信息优化主要流程如图3所示。

图3 报警优化流程
3.2 报警数据采集及预处理
炼化企业的报警数据一般都存储在DCS的报警日志里,炼化企业工艺过程复杂、报警数据庞大,数据更新频繁,不同厂商CS的报警数据的存储格略有不同。
本文中,基于横河DCS报警服务器,采用Mediator模式,利用OPC通信技术实时采集DCS报警数据,将报警数据预处理成具备时间戳、报警位、报警类型、报警状态和报警优先级等属性参数的数据信息。图4为中石油四川石化AAM系统报警数据采集格式。
根据FP-Growth算法频繁项集的挖掘原则,将图4报警数据预处理成报警数据事务项集数据库,见表1。

表1 报警数据事务项集数据库
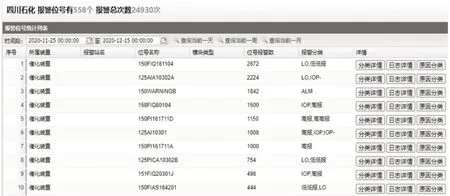
图4 报警数据
3.3 关联规则方法的FP-Growth算法
关联规则是信息挖掘理论中最活跃的研究方法之一,也是目前应用最广泛和最重要的信息挖掘方法。关联规则挖掘旨在挖掘隐藏在大型数据库中有意义的联系,所挖掘出的联系主要用频繁项集来表示,其中基于频繁项集的算法主要是Apriori算法和FP-Growth算法。
FP-Growth算法是J.Han等人针对Apriori需要频繁的便利数据库、产生大量候选项集这些缺陷提出的改进算法,FP-Growth算法对不同长度的规则具有普遍的适用性。本文选用FP-Growth算法,是为了获取较长的频繁模式,并且可生成大量的候选短频繁模式。在信息挖掘领域,FP-Growth算法的引用次数位列三甲。
3.3.1 定义
支持度S——支持度规则用来设定数据集的频繁程度统计项的出现频率,将出现次数小的项剔除掉,本文支持度S最低阈值为20%。
频繁项集——项集的支持度超过设定的阈值时,该项集即称为频繁项集。
置信度C——置信度规则用来确定项集Y在包含项集X的事务中出现的频繁程度。分子是项集XY同时出现的次数,分母是含有项集X的事务数。

如在表1中,可令X=F,Y=E,则

3.3.2 项头表的建立
建立FP-Tree之前首先建立项头表,项头表按降序排列,FP-Growth算法通过FP-Tree来挖掘频繁项集,若一个数据集包含K个项会产生2k-1个频繁项集,K值越大,产生的频繁项集的数目就越大。为了减少频繁项集的计算数量,坚持的原则:一个项集的支持度要小于其自己的支持度。
首先,对表1进行初次扫描,得到所有频繁1项集的计数,删除支持度低于阈值的项,在表1报警数据事务项集数据库T{AT-3201-A1,AT-3201-A6}的6条事务中扫描数据发现,C、I只出现一次,支持度低于阈值20%,因此它们不会出现在项头表中,将频繁1项集放入项头表,并按照支持度降序排列,将剩下的E、B、G、D、F、G按照支持度的大小降序排列,组成了项头表,如图5左图。
其次,剔除表1事物项中每条数据的非频繁项集,按照支持度降序排列。如AT-3201-A1中,剔除B、C、F、G、I,剩下D、E、H,按照支持度的由大到小排序成E、D、H。其他事务项以此类推,形成项集合I2,如图5右图。

图5 项头表和项集合I2
3.3.3 FP-Tree的建立
有了项头表和排序后的项集合I2,就可以开始TP-Tree的建立了。首先,插入项集合I2的第一条数据E、D、H,此时FP-Tree没有结点,因此E、D、H是一个独立的路径,所有结点的计数都为1,项头表通过结点链表链接上对应的新增结点;其次,插入G、D,如果有共用的祖先,则对应的公用祖先结点计数加1;再者,插入EBG,公用祖先节点E计数加1,此时为E2;用同样的办法可以更新最后1条数据,直到所有的数据都插入到FP-Tree中,最后形成FP-Tree构造图,如图6所示。

图6 FP-Tree构造图
3.3.4 FP-Tree的挖掘
基于图6FP-Tree构造图和图5项头表,先从最底部的H结点开始依次向上挖掘,开始寻找H结点的条件模式基,如图6所示,H有三个叶子结点,先画出H的FP子 树{E:5,B:4,G:3,D:1,F:1,H:1}、{E:5,D:1,H:1}和{E:5,B:4,F:1,H:1};接着,将所有的祖先结点计数设置为叶子结点的计数,H的FP子树即变成{E:3,B:3,G:3,D:1,D:1,F:1,F:1,H:1,H:1,H:1};其中,D结点和F 结点由于在条件模式基里面的支持度低于阈值,所以被删除;最终,去除了低支持度结点和叶子结点后的H结点的条件模式基为{E:3,B:3,G:3}。通过此条件模式基,得到H结点的 频繁2项集为{E:3,H:3}、{B:3,H:3}、{G:3,H:3}。递归合并2项集,可得到频繁3项集为{E:3,B:3,H:3}、{E:3,G:3,H:3}、{G:3,B:3,H:3}。递归合并3项集,得到频繁4项集为{E:3,B:3,G:3,H:3},则H结点对应的最大的频繁项集为频繁4项集{E:3,B:3,G:3,H:3}。
H节点挖掘完毕后,依次挖掘F、D、G、B、E节点,用以上同样的方法可以递归挖掘到每个节点的最大频繁项集,则从上面的分析可以看到,递归挖掘得到最大的频繁项集为4项集{E:3,B:3,G:3,H:3}。
4 结语
本文针对炼化企业控制系统的无效报警问题,简要概述报警管理现状和信息挖掘技术,对报警数据采集及预处理技术和关联规则方法的FP-Growth算法进行深入研究,通过支持度和置信度可根据不同工艺和工况手动配置的优势,利用最大频繁项集对报警数据节点进行信息挖掘,减少了DCS控制系统的无效报警频次,有效提高了报警准确率,使DCS控制系统报警总数约下降62%~93%。
