改进贝叶斯网络的个性化隐私数据发布方法
2021-09-28陈思阳
陈思阳
(山东科技大学计算机科学与工程学院,山东青岛 266590)
0 引言
在大数据时代,数据开放与共享已成为必然趋势[1]。为了方便研究与应用,许多机构和组织会公开发布数据,然而这些数据可能包含个人敏感信息,如果直接发布会导致用户隐私泄露。例如,疾病预防控制中心需要从各种医疗机构收集病例,若未经处理便发布了原始信息,患者个人信息可能会被非法利用,对其日常生活造成严重影响[2]。为解决该问题,诸多学者对隐私保护数据发布(Privacy-Preserving Data Publishing,PPDP)方法[3]进行了研究,目的是保护原始数据的隐私信息,同时为后续数据分析保留尽可能多的数据效用。
k-匿名模型[4]是PPDP 领域提出的第一个隐私保护模型,由于其简单性和有效性而得到广泛应用[5]。k-匿名模型虽然可以防止身份泄露,但不足以防御属性泄露。因此,若干种扩展k-匿名模型被提出,如l-多样性[6]、t-紧密度[7]、(k,l)-多样性[8]、(α,ε)-匿名[9]、p-敏感度k-匿名[10],以及各种改进的匿名模型[11-13]。这些模型大多是基于k-匿名模型的传统隐私保护技术,需要特殊的背景攻击假设,不能提供严格有效的数学证明,从而降低了隐私保护的可靠性。
差分隐私保护方法由Dwork[14]提出,其克服了传统隐私保护方法的主要缺陷,无需考虑攻击者拥有的背景知识,并使用严格的数学推理证明对隐私保护模型进行量化。该方法要求在查询结果中添加噪声,因此主要应用于查询结果的发布中[15]。基于此,Hasan 等[16]提出一种非交互式保护框架,通过转换或压缩原始数据向查询结果中添加噪声以满足ε-差分隐私。非交互式隐私保护模型可以发布经过离线处理且满足差分隐私的数据集,用户可以直接在数据集上执行查询操作,解决了交互式场景下受到查询接口限制的问题[17]。Zhang 等[18]提出的PrivBayes 是隐私保护数据发布方法的典型代表,该方法通过构建贝叶斯网络保持属性间概率的一致性,同时保留了原始数据的固有特征,后续许多学者在此基础上进行了改进。例如,王良等[19]提出加权PrivBayes 方法,其考虑到字段属性值的多样性,优化选择了属性字段结点加入噪声的顺序,以构建更优的贝叶斯网络;Li 等[20]提出平滑PrivBayes 方法,引入平滑敏感度机制,可以在实现差分隐私的同时减少噪声,从而提高联合分布的精度。
然而以上算法均未对实现差分隐私时属性的敏感程度作出讨论,因此本文提出一种改进贝叶斯网络的个性化隐私数据发布算法CSAPrivBayes。该法通过关联敏感属性程度划分属性区域进而分配隐私预算,同时改进了贝叶斯网络的初始结点随机选择机制,在保护隐私的同时保证了数据可用性。
1 差分隐私与贝叶斯网络
1.1 差分隐私
差分隐私保护模型定义了极其严格的攻击模型,成为数据发布领域最重要的隐私保护方法之一。
对于只有一个元组不同的两个数据集D1和D2,如果随机算法G满足ε-差分隐私[14],则对于随机算法G,任何可能的输出O满足:
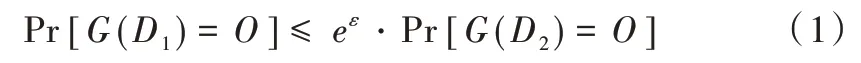
式中,Pr[⋅]为事件发生的概率,参数ε为隐私保护预算。F为将数据集映射到固定大小实数向量的函数。函数F的敏感度[21]定义为:
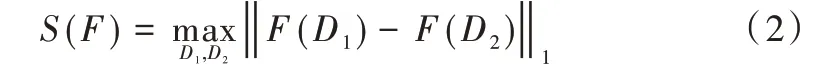
给定数据集D和查询函数f:D→Rd,f的敏感度为S(f)。算法M(D)=f(D)+η通过向f(D)输出的每个值添加随机噪声η来实现ε-差分隐私的Laplace 机制[21]。随机噪声η的概率密度函数为:
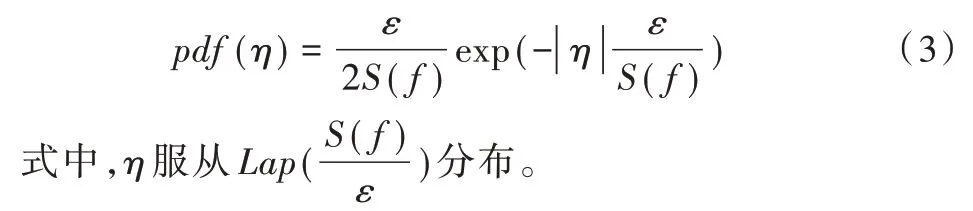
1.2 贝叶斯网络
设A为数据集D上的一组属性,Pr[A]为A上的联合概率分布,属性集A上的贝叶斯网络描述了A中某些属性之间的条件独立性。贝叶斯网络为有向无环图,其将A中的每个属性表示为一个结点,使用有向边对A中属性之间的条件独立性进行建模。图1 展示了具有5 个属性的集合A上的贝叶斯网络。
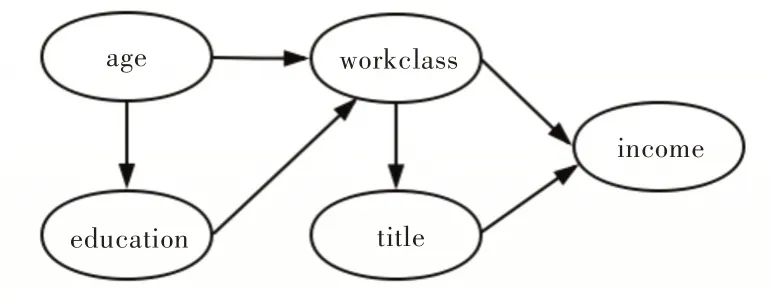
Fig.1 Bayesian network图1 贝叶斯网络
Pr[A]表示数据集D的全分布,贝叶斯网络实质上是用d 个条件分布Pr[X1|Π1],Pr[X2|Π2],…,Pr[Xd|Πd]以近似全分布Pr[A]。在给定Xi的属性父结点集Πi的情况下,任意Xi和Xj∉Πi是条件独立的,可得到:

2 基于贝叶斯网络的个性化差分隐私算法
2.1 PrivBayes 算法
PrivBayes 是一种用于发布高维数据的差分隐私方法,主要包括以下3 个步骤,分别为构建贝叶斯网络、扰动概率分布和随机取样[18]。
(1)在构建贝叶斯网络阶段,从属性集合中随机选择一个属性作为贝叶斯网络的起点,采用贪心算法从剩余属性中选择出具有最大互信息的父子结点对,并将其添加到贝叶斯网络中。当所有结点被添加到贝叶斯网络中后,输出构造完成的贝叶斯网络。
(2)在扰动概率分布阶段,首先根据构建的贝叶斯网络计算属性的联合概率分布P[Xi,Πi],然后将拉普拉斯噪声注入P[Xi,Πi] 以获得 噪声分 布P*[Xi,Πi]。添加到P[Xi,Πi]的拉普拉斯噪声比例设定为4(d-k)/nε,确保P*[Xi,Πi]的生成满足(ε/2(d-k))-差分隐私,P[Xi,Πi]具有的敏感度。
(3)在随机取样阶段,首先将第一个属性结点按照属性取值划分概率区间,生成一个随机数,根据其所在的取值区间确定X1的取样值。对于剩余属性结点,在给定父结点下按照属性取值划分联合概率区间,再根据生成随机数所在概率区间确定X的取样值。
2.2 CSAPrivBayes 算法
PrivBayes 算法解决了高维数据的发布安全问题,但也存在一些不足。该算法随机选取了首个属性,通过向属性的低维联合分布概率加入拉普拉斯机制实现差分隐私保护,并没有考虑敏感属性和一般属性,可能导致敏感属性隐私泄露以及一般属性隐私保护过度。为此,本文提出CSAPrivBayes 算法,首先定义静态权重值作为选取首个网络结点的依据以提高贝叶斯网络精度,再根据准标识符属性关联敏感属性的程度进行区域划分,进而采用不同隐私预算,实现个性化差分隐私保护。算法具体步骤如下:
(1)输入:数据集D、参数k、阈值θ。
(2)输出:低维带噪数据集D'。
(3)对数据集D进行预处理,采用二分k均值算法将连续属性离散化。
(4)计算数据集D中所有属性X的静态权重值W,选取W值最大的属性作为X1,将其添加到网络N中。对于有d个属性的数据集,属性Xi的静态权重值为:
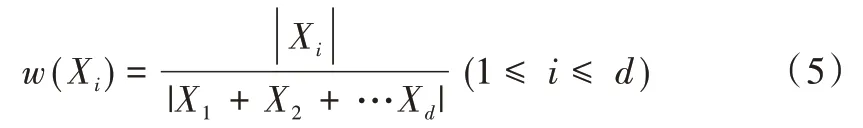
(5)使用贪婪搜索策略选择最大的互信息对(Xi,Πi),将其添加到贝叶斯网络N中。
(6)重复步骤(5)直至选择出(d-1)个AP对。
(7)计算N中属性结点Xi的联合概率分布P[Xi,Πi]。
(8)计算N中所有属性与敏感属性的互信息I(Xi,S)。数据集D中的准标识符属性Qi与敏感属性S的互信息为:

(9)如果属性Xi的I(Xi,S)≥阈值θ,则将其划分到区域A,否则划分到区域B。

(12)将加噪的联合分布P*[Xi,Πi]中的负值归零并归一化。
(13)从P*[Xi,Πi]中随机采样P*[Xi|Πi]生成低维带噪数据集D'。
(14)输出低维带噪数据集D'。
3 实验与结果分析
3.1 实验环境与数据集
硬件环境:Intel(R)Core(TM)i5-5200U CPU@ 2.20 GHz,内存8G,操作系统Win7_64 位旗舰版;软件环境:使用Python 编程语言实现,IDE 开发工具为Pycharm。使用美国人口普查数据集,随机选择24 000 条数据,其中选取6 个离散属性,4 个连续属性,具体信息如表1 所示。
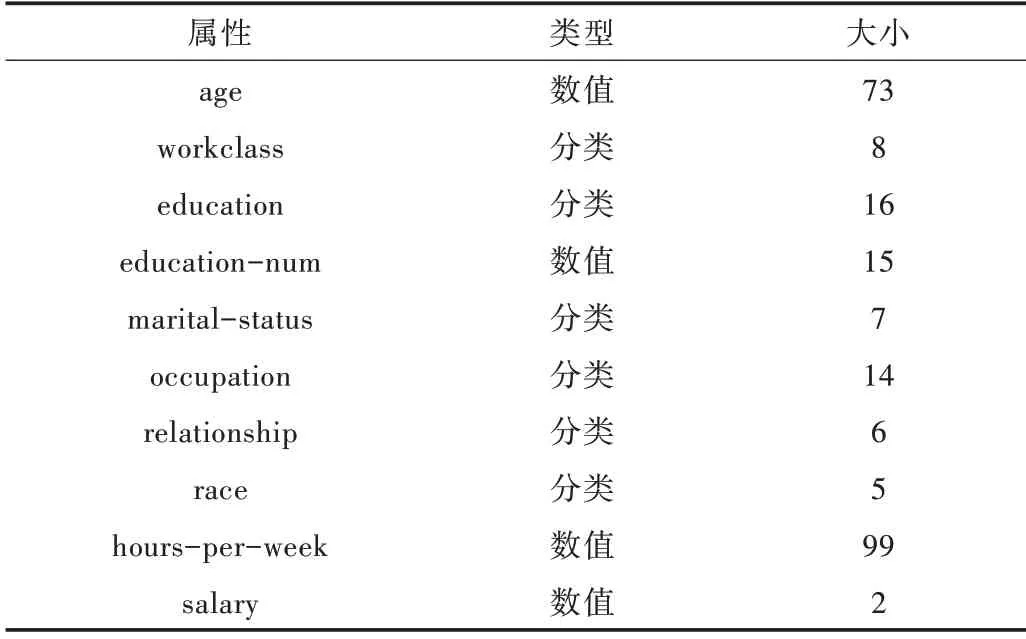
Table 1 Dataset information表1 数据集信息
3.2 评价指标
使用误分类率评估所发布合成数据集的可用性,误分类率越小,数据集的可用性越高。设FN为实际为正例且被分类器分为负例的个数,FP为实际为负例且被分类器分为正例的个数,P为实际的正例个数,N为实际的负例个数,则误分类率的计算公式为:
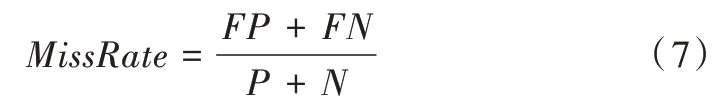
使用分类准确率评估所生成贝叶斯网络分类的精确度,分类准确率越高,贝叶斯网络的精确度越好。设TP为实际为正例且被分类器分为正例的个数,TN为实际为负例且被分类器分为负例的个数,则分类准确率的计算公式为:
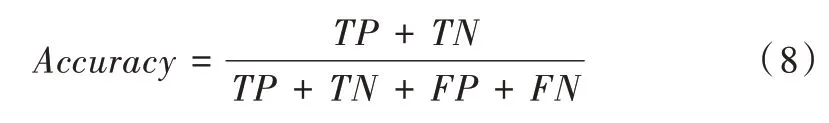
3.3 实验结果分析
使用SVM 算法评估发布数据的可用性,分类变量为salary 属性,将Adult 数据集的80%作为训练集,20%作为测试集。实验采用交叉验证比较PrivBayes 与CSAPrivBayes算法的平均误分类率,结果如图2 所示。
由图2 可以看出,随着隐私预算的增加,加入的噪声变小,数据的可用性变好,两种算法的误分类率均呈下降趋势。然而,CSAPrivBayes 算法考虑了属性敏感程度,合理分配隐私预算,误分类率降至15%,远低于PrivBayes 算法,在数据可用性方面也表现更佳。
采用分类准确率评估PrivBayes 与CSAPrivBayes 算法的贝叶斯网络质量,取k值为3,ε值为1.6,跟随数据量的变化比较两种算法的表现。如图3 所示,通过PrivBayes 和CSAPrivBayes 两种算法构建了不同的贝叶斯网络结构,随着训练数据量的增加,两种贝叶斯网络的分类准确率均逐步提高。CSAPrivBayes 算法根据属性结点的重要程度确定首选结点,分类准确率达到84%,构建的贝叶斯网络质量优于PrivBayes 算法。
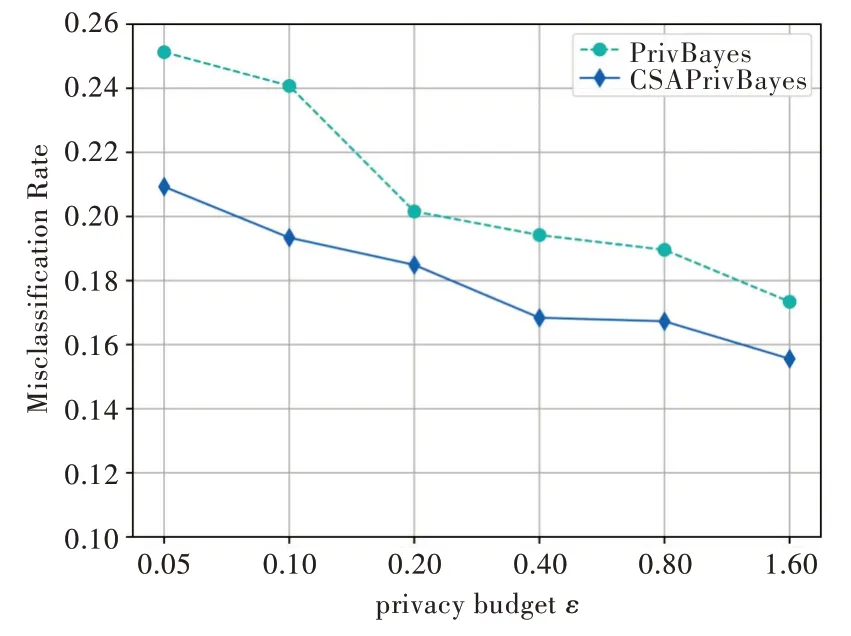
Fig.2 Comparison of attribute misclassification rate of the two algorithms on Adult dataset图2 Adult 数据集上两种算法的错误分类率比较
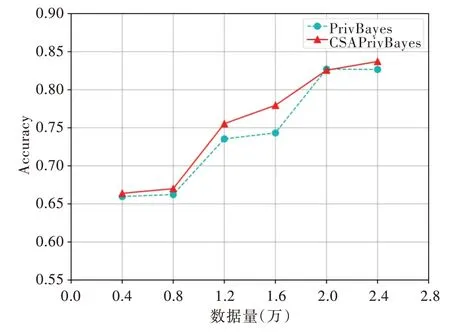
Fig.3 Accuracy comparison of the two algorithms on Adult dataset with ε=1.6图3 ε=1.6 时两种算法在Adult 数据集上的准确率比较
4 结语
为解决PrivBayes 算法随机选择首选结点与无法合理分配隐私预算的问题,本文提出一种改进的隐私数据发布方法CSAPrivBayes。其通过对属性结点添加权重值确定首选机制,根据关联敏感属性程度分配隐私预算实现个性化隐私保护。实验结果表明,CSAPrivBayes 算法可以提高所构建贝叶斯网络的精度以及合成数据的可用性。在后续研究中,可通过使用不同的启发式算法构建贝叶斯网络,进一步优化CSAPrivBayes 算法的性能。
