融合意图列表查询机制的门控槽模型
2021-09-28胡光敏
胡光敏,姜 黎
(湘潭大学物理与光电工程学院,湖南湘潭 411100)
0 引言
口语理解技术(Natural Language Understanding,NLU)是任务型对话系统的重要组件,旨在构建一个语义框架模型检测用户意图,以及对用户的输入进行语义成分分析。如表1 所示,给定一个与电影相关的话语“watch suspense movie ”作为输入,话语中的每个单词都有不同槽值,并且具有一个针对整个话语的特定意图。
槽填充通常可视为序列标注任务,输入序列为x=(x1,x2,…,xT),则输出对应槽标签序列常用的槽填充方法包括CNN[1]、LSTM[2]、attention-based CNN[3]。意图可视为一个文本分类任务,输入序列为x则输出对应的意图标签yi。常用的意图分类方法包括CNN[4]、deep LSTM[5]、encoder-labeler deep LSTM[6]。

Table 1 An example of user query and semantic framework表1 用户查询及语义框架示例
由于槽值往往与意图类别关系紧密,因此提出了槽填充与意图识别共同建模的方法[7]。Xu 等[8]采用triangular-CRF 和CNN 共同建模,将意图识别与槽填充任务进行联合训练。但在实际应用中,人们通常更关注于槽和意图联合准确率,于是Hakkani-Tur 等[9]将槽和意图联合准确率加入模型进行联合训练。与此同时,注意力机制的提出有效增强了文本上下文向量之间的关联[10]。注意力机制是按照序列结构,利用模型提供的精确焦点,从序列中学习每一个元素的重要程度。Liu 等[11]提出基于注意力机制的RNN模型,该方法仅通过损失函数将意图与槽进行关联,但不能有效将两者信息进行融合,于是Goo 等[12]提出Slot-Gat⁃ed 模型,Slot-Gated 模型可利用上下文注意力机制显式地建模槽值与意图的关系。同时为解决数据稀疏性问题,提出采用自监督训练的通用语言表示模型,例如ELMO[13]和BERT[14]。通过预训练词嵌入模型对NLP 任务进行微调,从而达到更好的效果。Chen 等[15]将BERT 模型用于联合意图检测与槽填充任务,该方法相比针对特定任务的带注释数据训练,改进效果十分显著。
传统的Slot-Gated 模型旨在将意图特征融入槽位识别中,但未能将文本标签信息作为模型先验知识传入模型参与训练。而在模型中加入预训练词向量模型又会极大地增加模型占用内存大小,不利于在硬件中嵌入模型。通过加入先验知识,使模型获得更好的语义理解,如在语义关系抽取模型中对输入序列加入文本位置信息[16],以及在情感分析任务中融入情感符号信息[17]。本文提出一种新方法来提升意图准确率和意图与槽填充联合准确率。首先采用预训练词向量模型对标签信息进行编码,且不参与训练,其次将编码的标签信息作为先验知识,通过构建的注意力机制融入模型参与训练。
1 实验方法
本节首先说明双向长短期记忆(Bidirectional Long Short-Term Memory,BLSTM)模型,然后介绍本文提出的新方法,即意图列表查询机制,最后介绍意图与槽的自注意力机制以及门控槽模型。模型架构如图1 所示,有两种不同模型,一种是基于意图列表查询机制的意图关注门控槽模型,另一种是基于意图列表查询机制的全局关注门控槽模型。
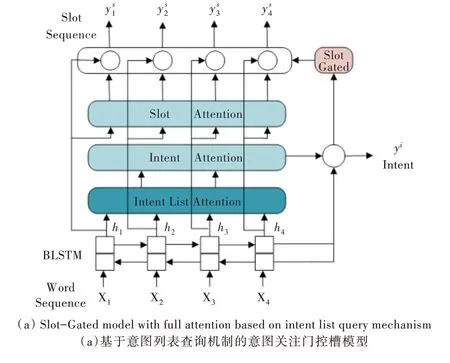
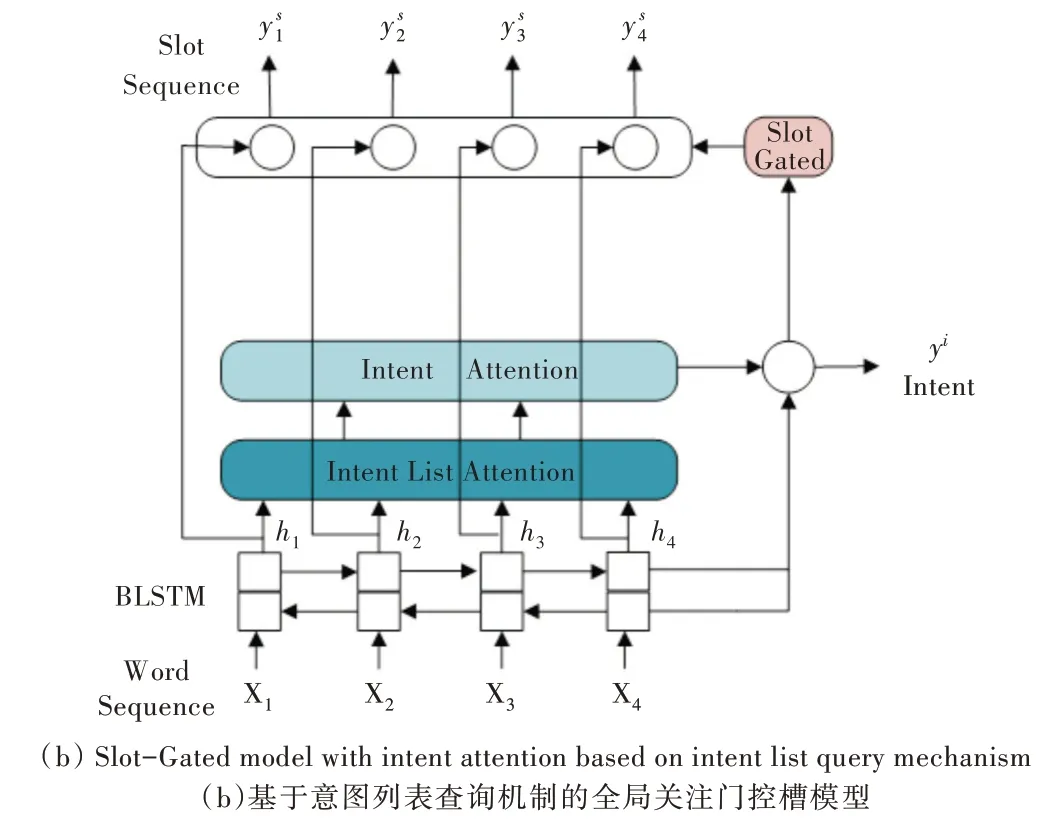
Fig.1 Architecture of the gated slot model based on the intent list query mechanism图1 基于意图列表查询机制的门控槽模型整体架构
1.1 双向RNN 模型
双向长短期记忆模型的提出是为了更好地对序列化数据进行表达。对于许多序列化数据,如声音和文本数据,其上下文之间存在密切关联。基本的LSTM 模型不能有效结合数据前后向信息,因此本文采用双向长短期记忆模型。

1.2 意图列表查询机制
本节介绍意图列表查询机制,意图列表查询机制总体架构如下:首先通过预训练词向量模型提取意图标签信息,其次通过构建的注意力机制显示建模标签与隐向量hT的关系。从训练集中提取出所有意图类别后,将BERTBase 预训练词向量导入bert-as-service 服务中,并通过bert-as-service 服务编码出各类意图的词向量表示。
传入模型的先验知识为通过bert-as-service 服务构建的意图词向量矩阵D,词向量矩阵D 参数固定且不参与训练。隐向量h 通过注意力机制从意图矩阵中学习到每一个意图的重要程度,并按照其重要程度对信息进行融合。
基于意图列表构建的注意力机制如下:式(1)表示隐向量基于查询矩阵中各项意图相乘的积,求出fd后,需将fd最后两维向量进行展平处理,从而将意图与文本向量的结合信息整合在同一维度中;式(2)表示通过softmax 求出hT与各项意图的相关度。其中,tanh 为激活函数,Wd为可学习的意图列表注意力权重,hT为隐向量,D 为意图查询矩阵。
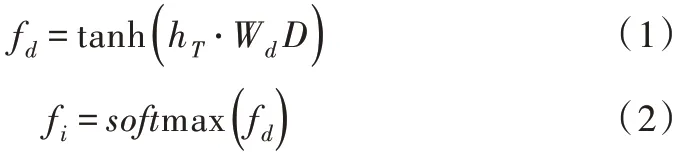
式(3)为联合各项意图向量的加权特征,具体公式如下:

1.3 意图与槽自注意力机制

1.4 Slot-Gated 机制
本节介绍Slot-Gated 机制,Slot-Gated 模型引入一个额外的门机制,利用上下文注意力机制建模槽值与意图的关系,从而提升槽填充的性能。首先组合槽上下文向量和意图上下文向量cI,Slot Gate 示意图如图2 所示。
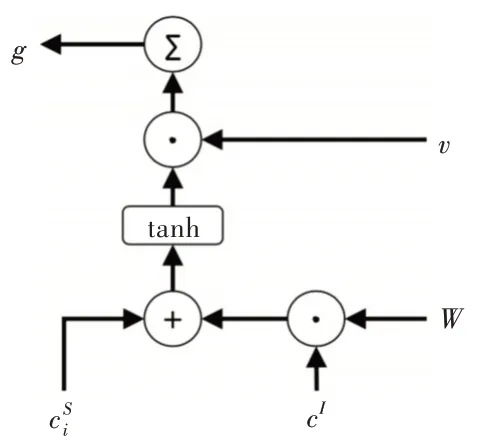
Fig.2 Illustration of the Slot Gate图2 Slot Gate 示意图
其中,v、W 分别是可训练的矩阵向量。对同一时间步中的元素进行求和,g 可看作联合上下文向量的加权特征。
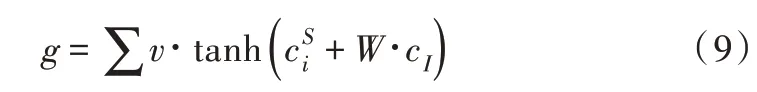
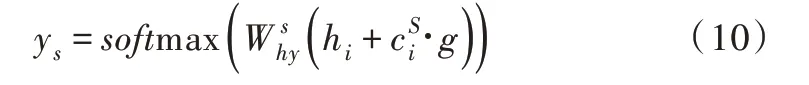
以上提出一种仅专注于意图的缝隙内控模型,组合隐向量h和意图上下文向量,通过时隙门求得g。
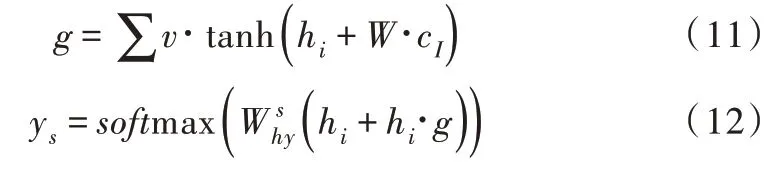
2 实验与分析
2.1 数据集统计
为评价所提出方法的有效性,本文采用基准数据集ATIS(航空旅行信息系统)[18]与数据集Snips[19]进行对比实验。ATIS 数据集中训练集、验证集及测试集分别包含4 478、500 和893 条话语,并具有120 个槽标签和21 个意图标签。与ATIS 相比,Snips 数据集词汇量更大,且语义环境更为复杂。Snips 数据集中训练集、验证集及测试集分别包含13 084、700 和700 条话语,并具有72 个槽标签和7 个意图标签。各数据集统计结果如表2 所示。
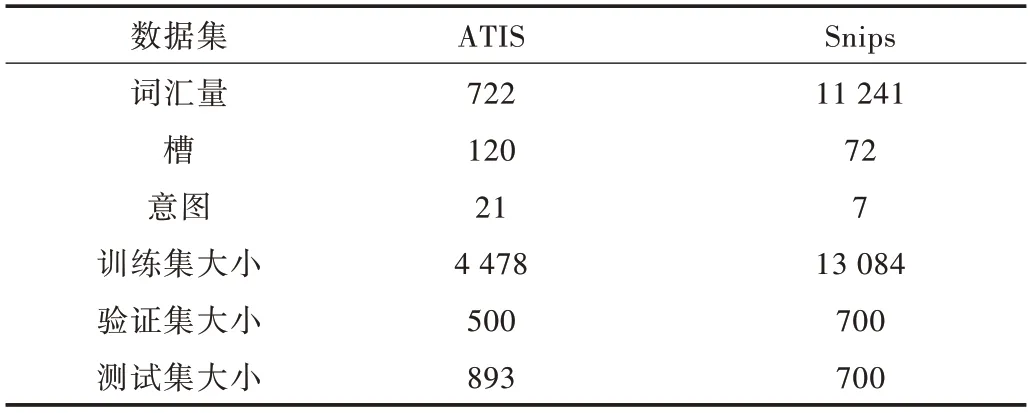
Table 2 Statistics of ATIS and Snips datasets表2 各数据集统计结果
2.2 结果分析
所有实验在Linux 系统的tensorflow1.14 环境下进行,设置批次大小为32、隐藏向量大小为64,损失函数采用交叉熵损失函数,优化器为Adam[20],损失函数采用联合优化损失函数,迭代训练100 次。
实验中除在意图识别模块中加入意图列表查询机制外,其他参数设置和模型搭建与原Slot-Gated 模型相同,该方法排除了其他因素对本实验的干扰。本文使用F1 得分评估插槽填充性能,使用准确率评估意图识别和语义框架的整体性能。在ATIS 数据集上的实验结果如图3、图4 所示(彩图扫OSID 码可见,下同)。图3 展示了全局关注和仅意图关注模型在ATIS 数据集上的损失值,图4 为全局关注和仅意图关注模型在ATIS 数据集上槽值的F1 得分,以及意图准确率和意图与槽联合准确率。
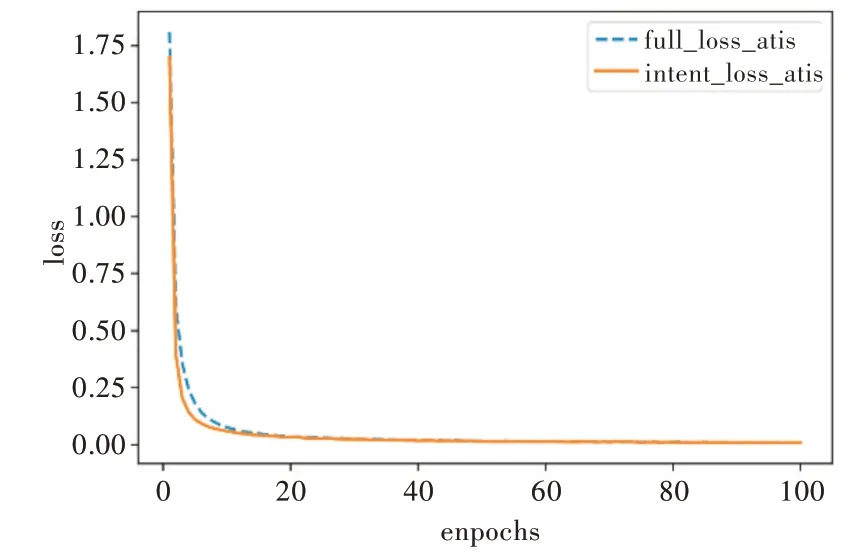
Fig.3 Loss value of the proposed model on ATIS图3 本文模型在ATIS 上的损失值
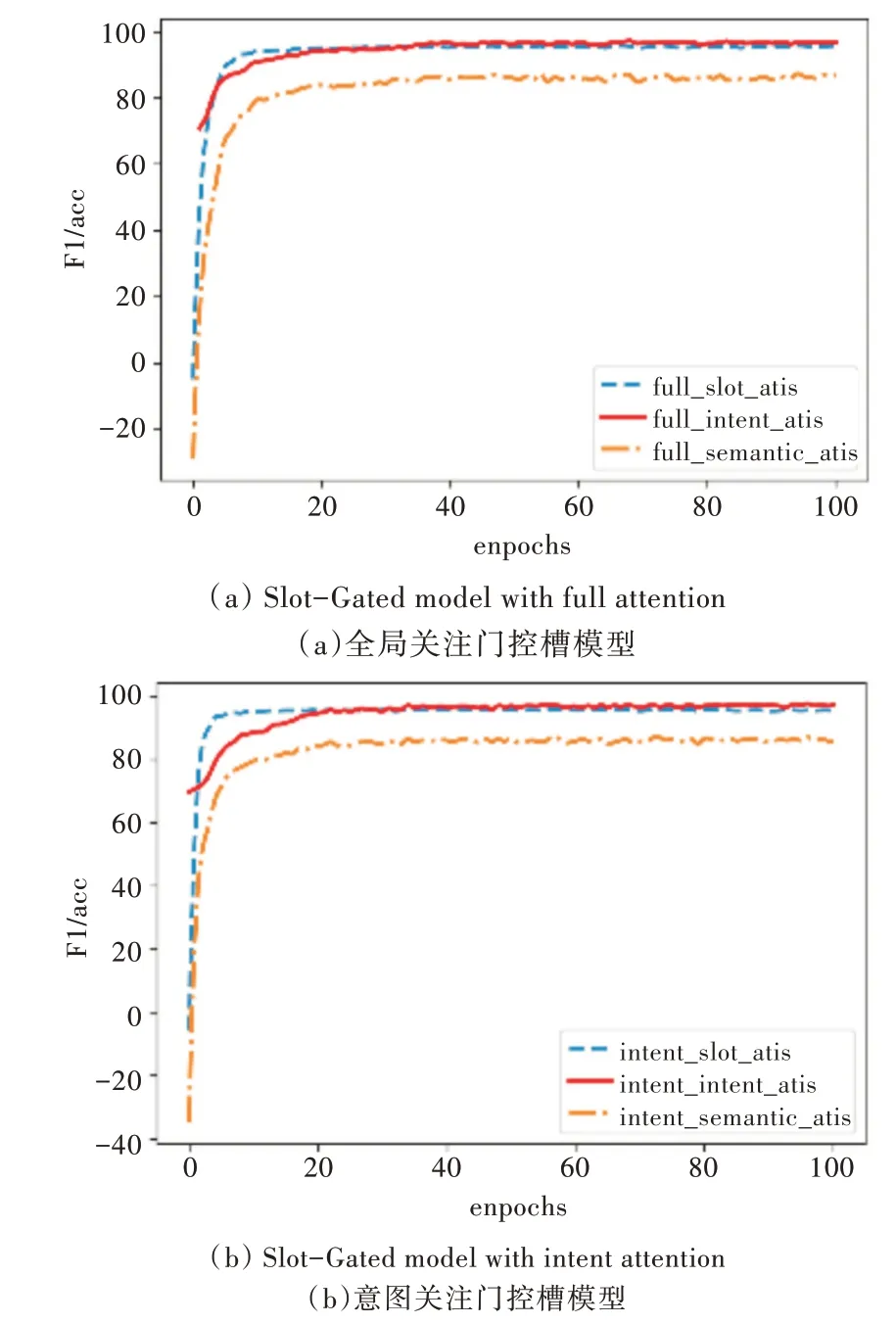
Fig.4 Performance of the proposed model on ATIS图4 本文模型在ATIS 上的性能
为了说明模型的有效性,在Snips 数据集上对模型进行测试,实验结果如图5、图6 所示。
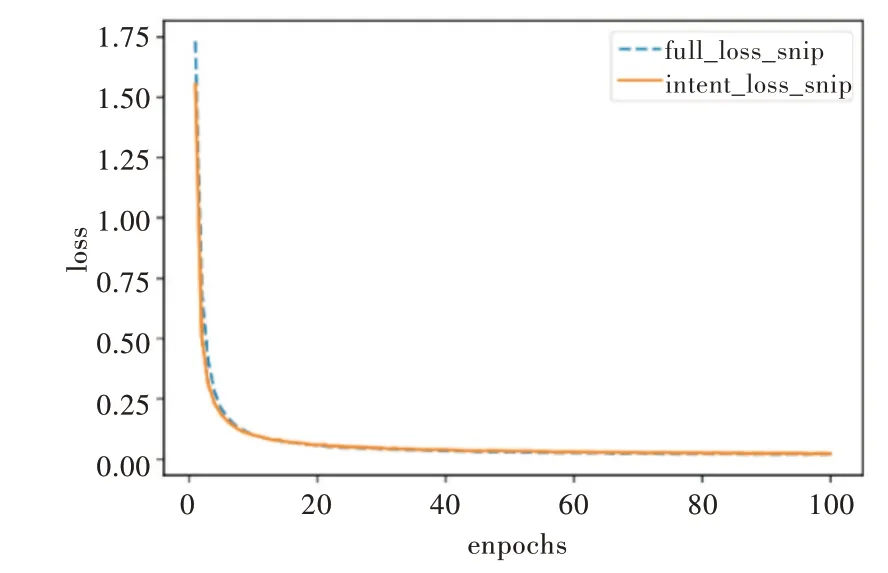
Fig.5 Loss value of the proposed model on Snip图5 本文模型在Snip 上的损失值
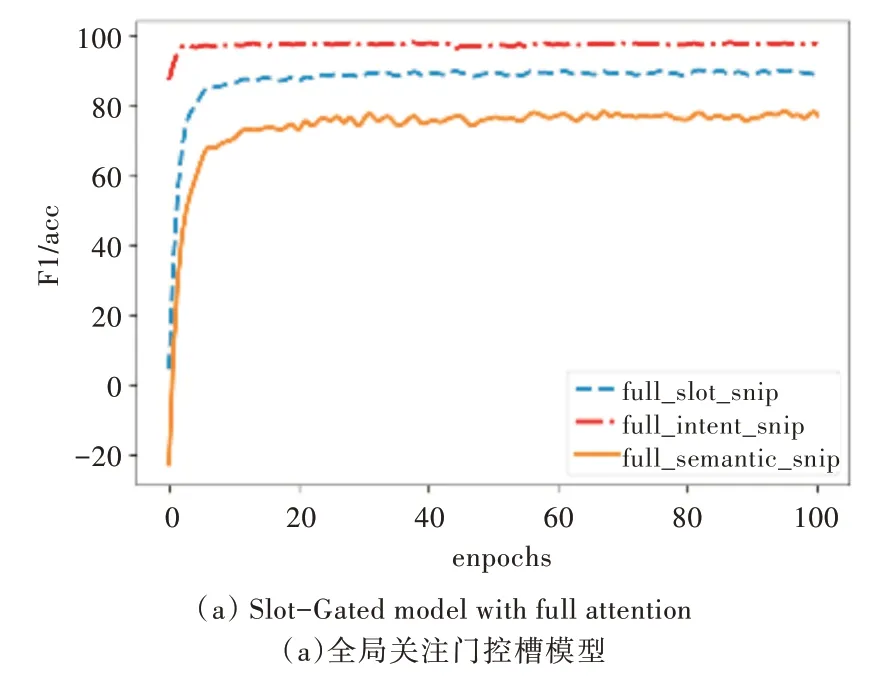
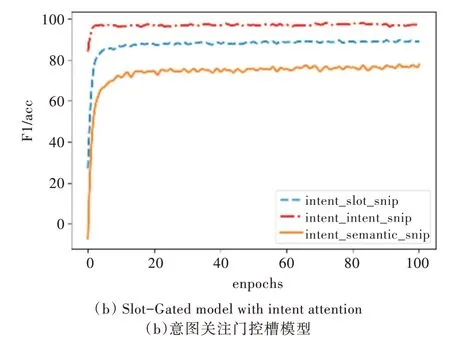
Fig.6 Performance of the proposed model on Snips图6 本文模型在Snips 上的性能
Slot-Gated 原文献中提出的各项指标为前20 轮的平均值,所展示的模型效果并未达到Slot-Gated 模型的最佳效果。本文实验进行100 轮次训练,将Slot-Gated 模型与本文方法的实验结果进行对比,如表3 所示。
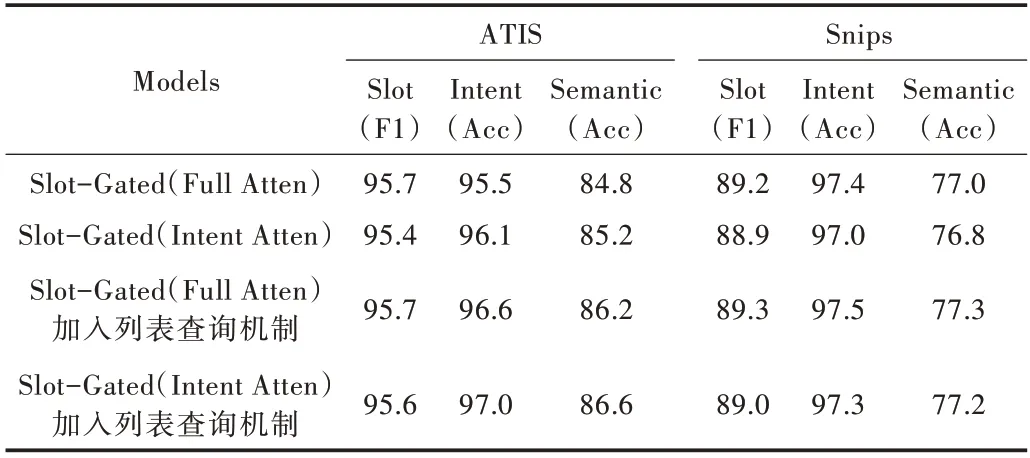
Table 3 Performance of NLU on ATIS and Snips datasets表3 NLU 在ATIS 与Snips 数据集上的性能
从表3 可以看出,针对ATIS 数据集,采用全局注意机制,意图准确率和意图与槽联合准确率分别提升了1.1%和1.5%;仅采用意图注意机制,意图准确率和意图与槽联合准确率分别提升了0.9%和1.2%。在Snips 数据集上,由于意图种类较少且训练数据充足,意图分类任务较为简单,模型能很好地拟合数据,加入列表查询机制未对模型产生明显改善效果。针对Snips 数据集,采用全局注意机制,意图准确率和意图与槽联合准确率分别提升了0.1% 和0.3%;仅采用意图注意机制,意图准确率和意图与槽联合准确率分别提升了0.3%和0.4%。实验结果表明,在Slot-Gated 模型中加入基于意图的列表查询机制对意图识别以及意图与槽联合准确率的提升具有积极意义。
3 结语
本文通过构建意图列表查询机制,给予模型在意图领域的先验知识。通过注意力机制将意图先验知识与输入句向量两者进行有效关联,并传入后续的意图识别网络进行训练,以实现更好的语义理解,从而提升模型意图识别以及意图与槽联合准确率。相比Slot-Gated 模型,本文方法在意图识别以及意图与槽联合准确率上均有所提升,并验证了将标签转换为先验知识对模型具有积极意义。当然本文方法在原模型的基础上增加了参数量,会耗费更多计算和存储成本。在今后的研究中,将致力于将先验知识与模型进行更有效融合,以提高神经网络的可解释性。
