骨架图引导的级联视网膜血管分割网络
2021-09-25姜大光李明鸣陈羽中丁文达彭晓婷李瑞瑞
姜大光,李明鸣,陈羽中,丁文达,彭晓婷,李瑞瑞
1) 北京化工大学信息科学与技术学院,北京 100029 2) 北京鹰瞳科技发展股份有限公司,北京 100089 3) 北京富通东方科技有限公司,北京 100010
视网膜血管分割是医学图像处理[1−2]的一个重要分支,是眼底图像分析的基础,在眼底疾病筛查和诊断中发挥着重要的作用. 许多类型的眼底病变都会导致视网膜血管形状、数量、结构发生改变,例如:高血压性视网膜病变会引起视网膜血管直径、曲折度和分岔角度发生变化[3];糖尿病性视网膜病变会带来视网膜静脉的扩张[4];而年龄相关的黄斑变性最终导致脉络膜毛细血管萎缩和形成大量新生血管.
视网膜血管形态结构复杂、狭长且空间跨度大,血管间常常会交错重叠. 这让视网膜血管的有效表征和特征提取任务变得富有挑战. 不仅如此,血管末端常分岔出更细微的血管,呈现出较大的尺度变化,也使得许多跟早期疾病筛查相关的不规律弯折和多角度交错等现象不易被观察到.经典机器学习方法[5−7]的分类特征需要手动设计和提取,非常依赖研究人员的领域相关知识,特征的优劣很大程度影响模型效果. 基于特定算子的目标形态检测方法[8−10]往往只针对特定的场景和条件,难以进一步提高血管分割的准确性.
近年来,得益于深度学习技术的发展,基于深度卷积神经网络的视网膜血管分割方法成为一个研究热点. 许多工作采用全卷积神经网络来完成这一任务,例如:Zhang和Chung[11]使用UNet[12]实现端到端的视网膜血管分割;Guo等[13]则采用ResNet[14]来更好地提取高维抽象特征.一些研究人员观察到血管分割任务中所存在的数据不平衡、细节特征易丢失等问题,从网络结构和训练策略等角度提出改进的方法,通过将注意力机制[15−16]、空洞卷积[17−20]、长短期记忆网络模块[21]和深监督学习[22]等技术适配到视网膜血管分割网络中,来加强网络的特征提取能力.这些研究工作有效地提升了血管分割性能,但是在医学临床应用中还有许多亟待解决的问题,特别地,细小血管的分割准确性和结构完整性是一个难点,需要进一步提升和加强. 一方面,细小血管在图像中所占的像素比例少,在训练中可能得不到有效的关注和充分的监督;另一方面,卷积神经网络本身缺乏对结构关联特征有效建模和表征的能力,不能对血管形状拓扑关系很好地表示和利用.
为了使血管脉络能够被更完整和清晰地分割出来,从而辅助医生实现微小病变发现或者准确疾病分级诊断,本文从血管形状拓扑关系的表示和利用角度出发,探索多任务卷积神经网络设计,提出骨架图引导的级联视网膜血管分割网络框架. 该框架包含两个级联的沙漏状网络模块,并采用层次化的方式传递特征. 方法引入了一个提取骨架图的辅助任务,并设计了基于图的结构平滑正则损失函数,帮助更好地刻画物体的拓扑和几何关联特性. 不仅如此,方法将骨架图和层次化特征通过融合机制传递到第二个网络模块,引导整体视网膜血管的分割.本文在DRIVE、STARE和CHASEDB1这3个著名公开的视网膜血管分割数据集上验证了提出的网络框架,与该领域近3年最新的8种方法相比,该框架得到的结果的准确性最高.同时通过消融实验,本文定量分析了提取骨架的辅助任务、基于图的结构平滑正则损失函数以及骨架提取任务和血管分割任务使用不同网络实现时对分割任务的影响. 综上所述,本文的主要创新点如下:(1)提出了一个多任务级联网络框架.能够将不同的任务级联在一起同时训练,提高模型的准确性和泛化性.该框架与选取的主干网络无关,具有灵活的适用性;(2)设计了一个骨架图提取的辅助任务,提出基于血管标注的弱监督骨架图提取方法,方法采用伪标注与基于图的结构平滑正则损失函数相结合来准确提取骨架;(3)提出骨架引导的准确血管分割的方法,通过自适应特征选择机制来有效融合的拓扑结构特征.
1 国内外相关工作
长期以来,国内外研究者提出了大量的血管分割方法. 传统的方法包含:概率图模型[23]、线检测器[24]、Gabor小波变换[7]和手工特征结合有监督分类器[5,25−26]的方法. 2016年以后,得益于深度学习技术的快速发展,涌现出大量基于深度卷积神经网络的视网膜血管分割方法.Maninis等[27]采用VGG网络[28]提取特征,并将不同层次特征相融合作为分类特征,完成逐像素分类.Zhang等[29]、Guo等[13,30]、Mou等[31]分别在他们的工作中使用了UNet,并加入了空间和通道注意力机制,使网络能够更好地关注到有效目标区域.Jiang等[32]、Hatamizadeh等[33]、Gu等[34]在全卷积网络中使用了空洞卷积金字塔,能够提取不同尺度的目标特征,丰富了特征层的上下文信息.Zhang和Chung[11]、Mo和Zhang[35]使用了深监督的训练方式,对网络不同深度的隐层特征施加监督信号,有利于梯度在网络深层传递,使网络能够更有效地提取深层特征.
视网膜眼底图像分割比普通视觉图像分割难度更大,主要表现在:眼底照样本少、尺度变化大、内容细节丰富和结构信息敏感.一些方法采用特殊的损失函数设计来更好地提取特征.这类方法的基本思路是对占比少且难学习的像素施加更大的损失权重,例如:细血管或血管边缘像素,使网络在训练中能够更有效地挖掘这些样本的特征. Hu等[36]通过对交叉熵损失函数设置权重来平衡前景和背景、粗与细血管间的训练损失.Yan等[37]结合血管的长度和管壁直径设计损失函数,加大对细血管的训练权重.这些精心设计的损失函数能够有效提升血管分割的精度,但对于不同的数据分布,需要对此多次手工调整参数,不具备很好的适用性.
为了更好地提取细血管和结构信息,另一些方法则采用多任务网络设计,即:设置一个或者多个相关子任务来协助更好地完成血管分割. 例如:使用一个边缘分割的子任务[38]或使用一个血管连接点提取的子任务[39].也有研究人员尝试将血管分割的任务进行分解.Zhang等[40]就将血管特征提取分解为血管结构特征提取和纹理特征提取,并设置两个子任务,使用浅层网络提取低层的纹理特征,使用深层网络提取高层的结构特征.Zheng等[41]对血管进行细粒度的分类,分为细血管、血管边缘和粗血管三个部分,使用多任务网络对这些子类进行分类. Zou等[42]根据位置分布将血管分成五个部分分别进行处理,采用局部回归的技术促使在分割结果中保留更多的细血管.采用了由粗到细的串行多任务分割学习框架,粗分割网络的输出结果连接到细分割网络的输入,进行进一步优化. 遗憾的是,上述这些方法难以有效利用子任务网络之间的多层次特征的相关性,缺乏任务间的协同机制,造成的特征层信息冗余会导致整个任务性能的降低.
2 多任务级联视网膜血管分割网络
本文提出的骨架图引导的多任务级联视网膜分割框架如图1所示,该框架由骨架提取辅助任务、特征级联模块和血管分割主任务3部分组成.骨架提取辅助任务和血管分割主任务分别由两个编码-解码结构的沙漏型网络实现.骨架提取网络能够对血管的中心线逐像素标记,输出血管骨架图;血管分割网络将眼底图像划分为血管区域和非血管区域.两个网络之间采用多个自适应特征融合模块连接,模块在训练中学习到如何将骨架提取网络挖掘到的多层次结构信息和分割网络的血管特征进行融合,增强分割血管的结构完整性.

图1 骨架图引导的视网膜血管分割网络框架Fig.1 Skeleton map-guided retinal vessel segmentation framework
该框架中的两个网络的主干结构是一致的,但整个框架与主干网络的选择无关,可根据具体分割任务灵活设置.在本文中,主干网络选择使用ResNet34[14]. ResNet34具有4个编码层,深层编码特征对应着更大的感受野,具有更大范围的结构信息,浅层编码特征则蕴含着较为精细的局部结构信息,每个编码层的空间分辨率均为上层编码层的1/4.网络末端的全连接层被替换为若干个转置卷积层和上采样层,用于恢复空间分辨率,构成了解码路径.编码层的特征通过跳跃连接传递至具有相同空间分辨率的解码层,弥补在下采样中丢失的空间信息.
2.1 基于伪标注的骨架图提取
骨架,也称为“中心线”,是一种基于结构的目标描述符,能够对血管这类拓扑结构清晰和有效地表示(如图2).
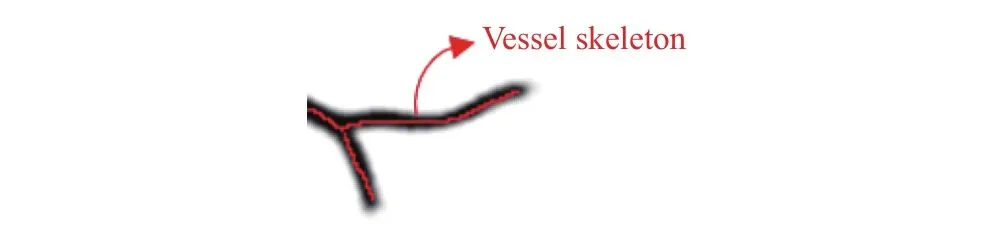
图2 血管骨架Fig.2 Vessel skeleton
观察发现,单任务血管分割模型对结构特征感知不足,提取出来血管存在部分丢失、断裂的现象. 本文提出的框架包含一个骨架提取的辅助任务,通过训练深度卷积神经网络来准确提取骨架信息.由于缺乏骨架的标注数据,因此本文采用骨架化算法[43]从血管标注中生成骨架的伪标注来作为监督信息.
2.1.1 伪标注生成方法
生成伪标注采用一种称为快速并行细化的算法[43],它通过迭代的方式,逐步将二值图像中的目标轮廓去除,仅保留目标中心线像素. 第n次迭代后每个像素点的值取决于在第n−1次迭代后其自身的值以及其8邻域内其他像素的值.每轮迭代包括两步,第一步删除像素8邻域内的东南边界点和西北角点,第二步删除西北边界点和东南角点. 整个算法的处理流程如图3所示.
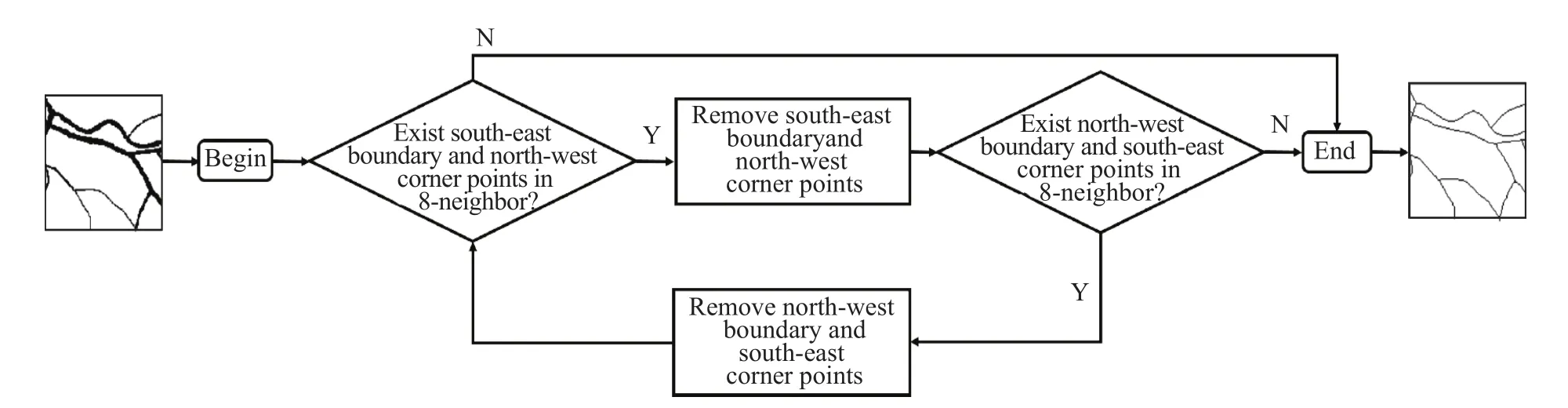
图3 快速并行细化算法流程图Fig.3 Flowchart of the fast, parallel thinning algorithm
2.1.2 基于图的结构平滑正则损失
为了使模型提取的骨架结构更加完整,在训练骨架提取网络时,引入了一个基于图的结构平滑正则项作为损失函数[44].该损失函数使模型输出的类内预测概率的分布更加均匀,在阈值二值化时有利于保留完整的血管,减少分割图中背景噪声和血管断裂的现象. 设血管为前景类,非血管为背景类,在一个局部区域中,标注中正类像素的集合为, 负类像素的集合为, 网络把像素i预测为正类的概率为. 前景和背景的损失项表示为:
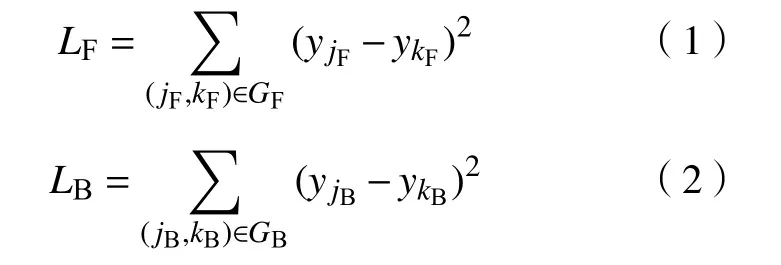


2.2 骨架图引导的视网膜血管分割
本文将来自骨架提取网络中包含结构信息多尺度特征通过本文设计的特征融合机制与视网膜血管分割网络中的特征以适当的权重进行像素级融合,加强特征层的结构信息响应. 融合后的特征作为血管分割网络中的编码特征分别以采样和跳跃连接的方式前向传播.
受注意力门控[45]的启发,本文设计了自适应特征融合模块(SAFF).注意力门控(图 4(a))的思路是利用深层特征包含的关键语义信息过滤浅层特征包含的冗余信息和噪声,输出表现为浅层特征的线性映射;自适应特征融合模块(图4(b))则是对血管特征进行结构信息补充,输出为两个特征的仿射组合.具体地,自适应特征融合模块的输入分别为骨架提取网络的解码层特征RC×H×W和血管分割网络中相同尺度的编码层特征fves∈ RC×H×W.特征融合模块会计算出值域为的融合系数矩阵 α ∈[0,1]C×H×W,其上每个单元的值表示结构特征的融合系数,融合后的新特征计算公式如下:
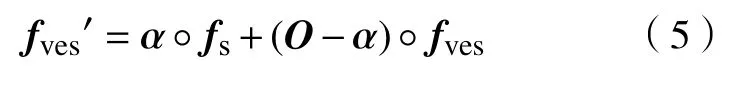
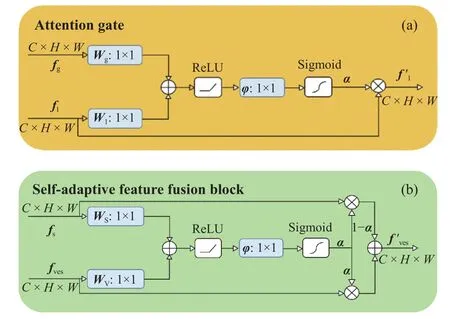
图4 自适应特征融合模块和注意力门控的对比. (a)深层特征过滤浅层特征;(b)包含结构信息的骨架特征和 血管特征融合Fig.4 Comparison of the self-adaptive feature fusion block and attention gating: (a) deeper features filter shallower features ; (b)vessel features fuse skeleton features containing structural information

3 实验与分析
3.1 实验设计
为了说明该方法的有效性,本文在3个公开的视网膜血管分割数据集进行了实验,与近3年最新的方法[11,34,37,40,46−49]进行比较.每组实验的结果为模型10次训练结果的平均值. 本文提出的方法采用Python语言编程,基于PyTorch框架实现,模型在配备16 G内存和英伟达GTX1080Ti显卡的计算机上运行.网络训练轮次总数设置为20,优化算法使用Adam,使用0.001作为学习率. 基于图的结构平滑正则损失的局部区域设置为边长为30个像素的正方形,权重系数设置为0.000001.
3.2 数据介绍
DRIVE[50]数据集包含40张分辨率为565×584的RGB三通道彩色眼底图像;STARE[51]数据集包含20张分辨率为700×605的RGB三通道图像;CHASEDB1[52]数据集包含 28张分辨率为 999×960的RGB三通道图像,从14个孩童的左右眼拍照采集.
DRIVE数据集提供了各包含20张图片的训练集和测试集,本文选取了训练集中的第1张图片作为验证,其余19张图片用作训练. 对于STARE数据集,本文采用了Yan等[37]、Wang等[49]使用的留一法划分方式,1张图片用作测试,其余19张用于训练,20张图片轮流作为测试图片进行实验,计算20次实验中各项指标的平均值作为结果. 对于CHASEDB1数据集,实验采用了和Yan等[37]、Wang等[49]、Li等[46]、Wang 等[48]相同的划分方式,前20张用作训练,其余8张用于测试.3个数据集中的训练图片分别采用旋转和翻转的方式进行扩充,缓解由于训练数据太少导致的模型过拟合现象.由于CHASEDB1数据集的图片分辨率较高,这个数据集中的图片切片为720×720的图像块.
3.3 评价方法
本文使用了F1值、敏感性(Se)、准确率(Acc)、特征曲线ROC下的面积(AUC)这4个常用的指标对提出的方法定量评估. 从二值分割图和标注图中统计出被正确分类为正类(TP)、被正确分类为负类(TN)、被误分类为正类(FP)、被误分类为负类(FN)这四类像素的数目并进而计算出指标值,如下所示:

特征曲线从使用不同阈值得到的二值化分割图计算出的敏感性和假正率(F P/(FP+TN)×100%)做出,计算此曲线与坐标轴围成的面积得到AUC值.
3.4 实验结果
本文提出的方法在3个数据集上与其他方法的对比结果如表1所示,在所有指标上基本达到了领先.方法在3个数据集上的F1值分别为83.1%、85.8%和82.0%,在所有对比方法中达到了最高;敏感值分别为83.7%、86.4%和84.5%,同样达到了领先. 虽然方法DS[11]的敏感值在DRIVE数据集上高于本文的方法,但对于医学数据,F1值是更为重要的指标.它不仅包含着敏感性信息,还考虑了精确度,F1值越高意味着识别出的血管更为齐全,而且准确. 本文提出的方法在3个数据集上的F1值比其他方法平均高出2.6%,证明了该方法能够更加准确地识别出更多血管.同时,AUC值在3个数据集分别为98.8%、99.1%和99.1%,平均比其他方法高出0.3%;Acc值分别为97.1%、97.1%和97.7%,平均比其他方法高出0.9%.考虑到眼底图像中非血管区域和粗血管占比较大,细血管和噪声样本的占比较小,模型对这类小样本的分割性能提升反映在这两个指标上的变化不明显,因此尽管指标值只有略微提升,但同样能够说明方法对细小血管的识别准确率更高,同时减少了对噪声样本的误分类.
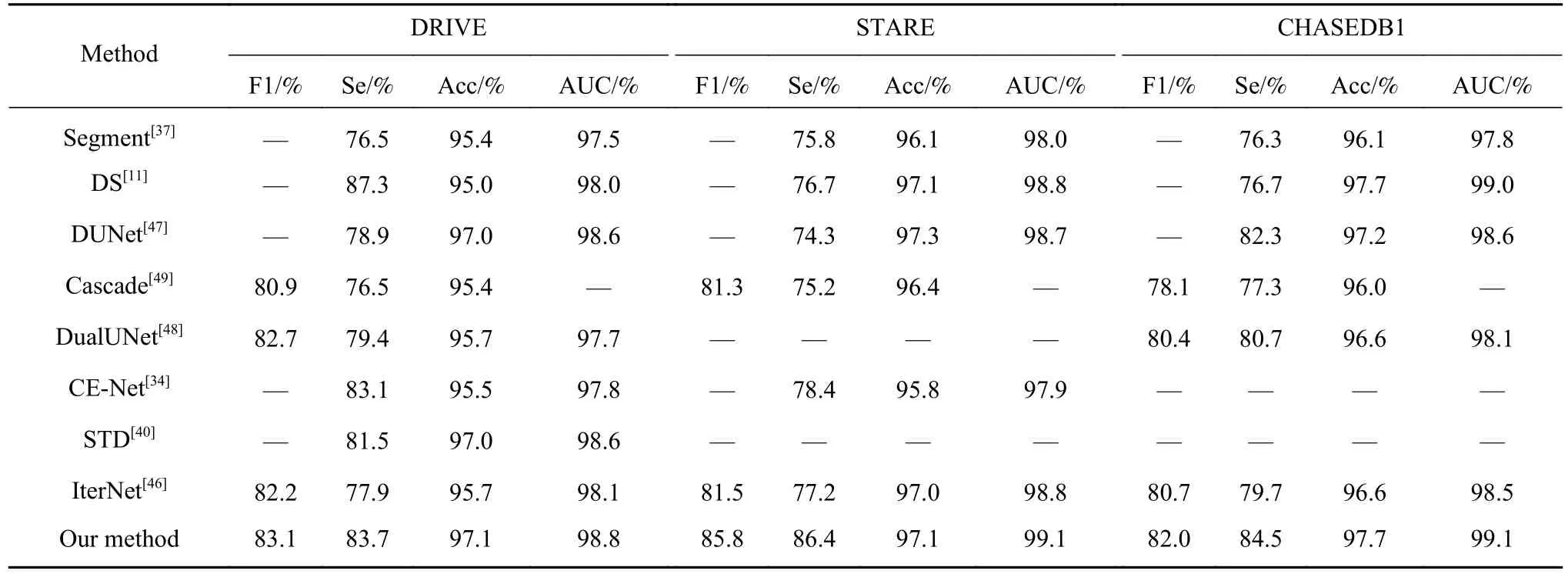
表1 本文提出的方法和近期的先进方法在F1值、敏感性Se、准确率Acc、AUC的比较结果Table 1 Comparison results between our proposed method and the recent advanced methods of the F1 score, Sensitivity, Accuracy, and AUC
3.5 消融实验
为了进一步说明框架中各个组成部分的效果,本文进行了消融实验.
第一组消融实验验证了骨架的辅助任务和基于图的结构平滑正则损失分别起到的作用. 首先,实验使用单任务分割网络ResNet34作为基准,在DRIVE和CHASEDB1训练集上训练,计算出在验证集上的指标. 然后,网络递增加入了提取骨架的辅助任务,使用二元交叉熵损失函数训练,评估该子任务对分割性能的影响. 最后,骨架提取网络的训练损失中再次递增加入了基于图的结构平滑正则项,评估该损失的效果. 在3个数据集上实验结果如表2所示,实验曲线图如图5所示. 实验结果表明:使用提取骨架的辅助任务的分割模型在两个验证集上的F1值分别达到了85.0%和81.8%,Se达到了85.5%和83.6%,相比于单任务分割网络有大幅提升,并且模型在训练中收敛速度较快,说明骨架特征能够提供给分割网络充分的拓扑和几何信息,使网络能够准确分割出更完整的血管结构,而且减小了单任务网络对特征的学习难度;使用结构平滑正则损失后,F1值和AUC值比单独使用二元交叉熵平均提高了0.1%,Se提升了0.8%,说明该损失能够促使模型准确提取出更多细小血管的骨架,同时也证明了提取出更精确的骨架能够进一步提高血管分割的效果.
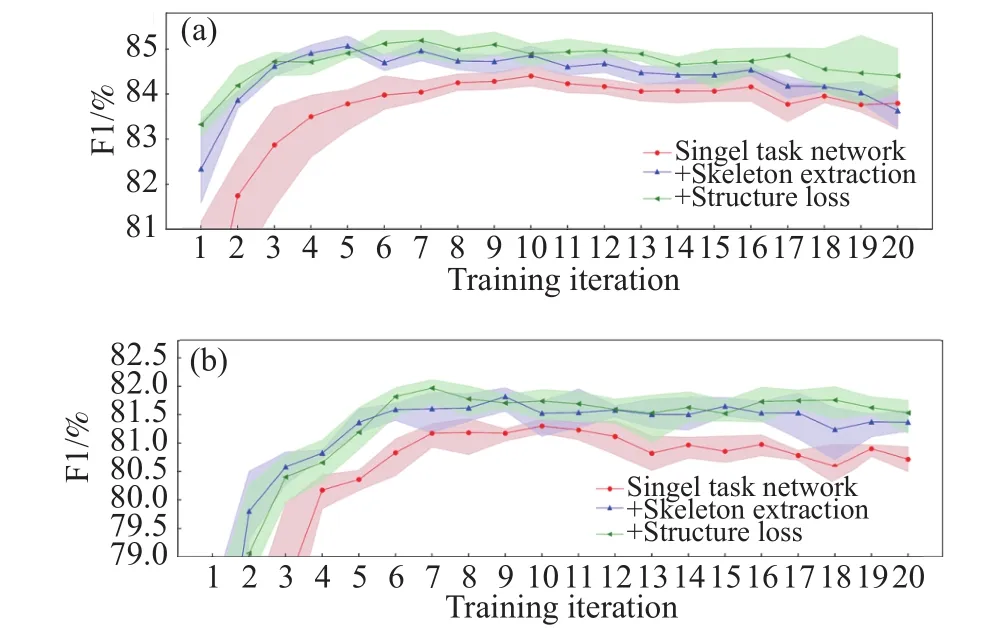
图5 消融实验中每轮训练后在不同验证集上的F1值. (a)DRIVE;(b)CHASEDB1Fig.5 F1 on the validation set after each training iteration in ablation experiments: (a) DRIVE; (b) CHASEDB1
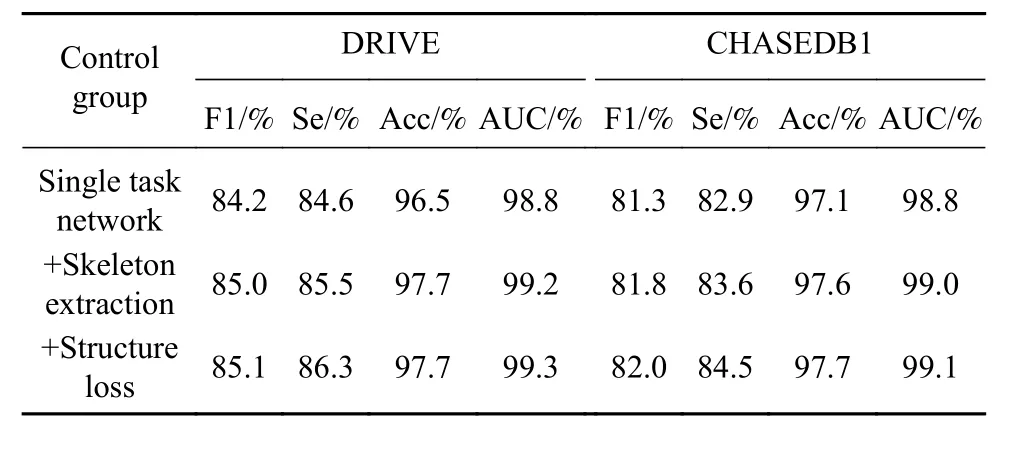
表2 第一组消融实验结果Table 2 Results of the first ablation experiments
第二组消融实验验证了框架中主干网络的普适性,实验将骨架提取网络和血管分割网络的编码路径共同替换为ResNet18和VGG16中去除全连接层的部分. 框架在两个数据集训练完成后,计算在测试集上的指标,结果如表3所示.3种主干网络在2个数据集上的指标都较高,说明该框架具有灵活的适用性.在F1指标上,ResNet34高于ResNet18和VGG16实验组,可以推断出效果越好的单任务网络应用在该框架下会取得一定程度的提升. 使用ResNet34作为主干网络的实验组在两个数据集的训练损失如图6所示.
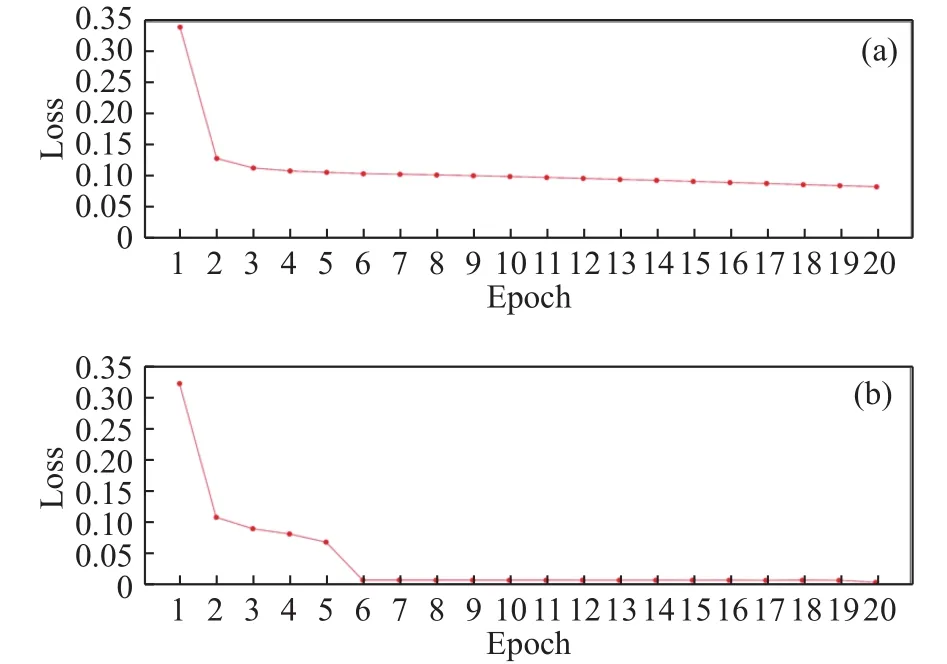
图6 框架在 DRIVE(a)和 CHASEDB1(b)数据集上的训练损失Fig.6 Training loss of the framework on the DRIVE (a) and CHASEDB1 (b) datasets
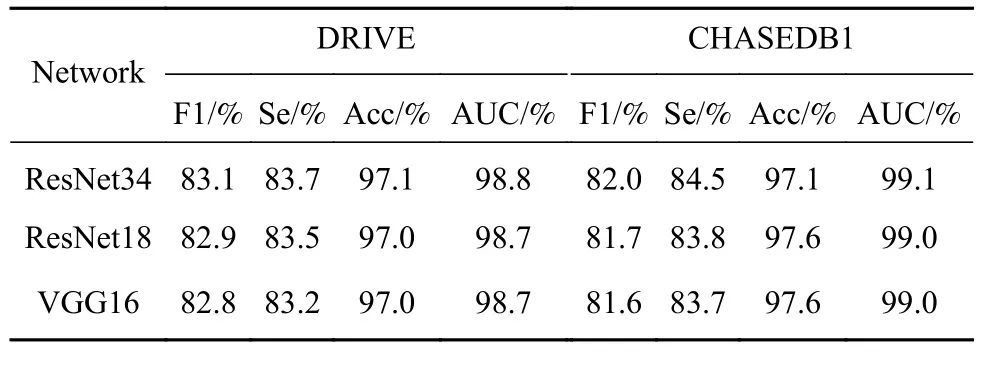
表3 第二组消融实验结果Table 3 Results of the second ablation experiments
4 结论
本文提出了一种骨架图引导的多任务级联视网膜血管分割框架,能够克服视网膜血管分割中存在的细小血管提取不完整、分割不准确的问题.从而辅助医生开展早期眼底病变筛查.提出的框架与主干网络结构无关,也可以灵活扩展到其他与拓扑结构相关的分割任务.
