基于DBSCAN和SDAE的风电机组异常工况预警研究
2021-09-24马良玉孙佳明於世磊赵尚羽
马良玉, 孙佳明, 於世磊, 赵尚羽
(华北电力大学 控制与计算机工程学院, 河北保定 071003)
风能是一种无污染、永不枯竭的清洁能源,近年来风力发电为世界各国高度重视并取得飞速发展。但是,随着风电机组服役年限增长,风电机组故障概率不断上升,给机组的安全运行带来挑战。利用风电机组监控与数据采集(SCADA)系统的大量运行数据及状态信息,开展风电机组性能评估、异常工况预警及早期故障检测,有助于降低风电机组的运维成本和提高经济效益[1-4]。
基于SCADA系统数据进行风电机组特性建模时,异常数据清洗是准确建模的前提,成为人们关注的焦点。李航涛等[5]提出一种基于概率和离散度的数据处理方法,在滤波前设置一个桨距角阈值将限功率点剔除。王一妹等[6]建立了基于密度聚类法、截断法、斜率控制法和核密度估计法相结合的异常数据识别模型,实现了风电机组运行数据的清洗。赵永宁等[7]提出一种基于四分位法和聚类分析的异常数据组合筛选模型,但是该方法利用的k-means聚类算法只能识别球形数据聚类,不适用于不规则和多密度数据集。Zheng等[8]在分析风电数据属性后,利用局部异常因子算法(LOF)检测并删除异常值,并设计了一种新型的相似度测量方法。但是该方法所用的数据量不能太小,并且在存在很多无效数据的情况下不能保证异常值检测的准确性。沈小军等[9]提出了基于变点分组法与四分位法相组合的异常数据识别清洗方法,但通过此方法清洗掉的数据较多,很多正常数据会被判断为异常数据清洗掉。
风电机组各部件之间相互关联、相互耦合,如果其中某一部件工作异常,则会在其他部件中表现出来,很难通过人工或者基于知识的方法进行故障诊断。近年来,基于机器学习和统计学习的异常状态识别及预警方法得到快速发展,已在风电机组中得到广泛应用。张帆等[10]在预处理原始SCADA数据的基础上得到数据间的相关性,构建了状态判别指标,实现了对风电机组健康状况的定量评估,但其研究仅限于低于额定风速的变工况过程。崔恺等[11]采用广义回归神经网络(GRNN)建立了风电机组的性能预测模型,进而实现风电机组异常状态的有效识别,但GRNN由于没有模型参数需要训练,要存储全部训练样本,且测试样本要与全部训练样本进行计算,计算和空间复杂度高。支持向量机(SVM)是最小化结构风险的分类器,可有效解决线性可分与线性不可分问题。睦浩淼[12]通过自组织映射与SVM回归结合实现了对风电机组异常运行状态的检测,但SVM更适合于小样本多维度数据的机器学习场合。
针对以上数据清洗和建模方法的不足,笔者以SCADA系统数据为基础,结合风电机组的工作及控制原理,根据影响主轴转速和发电功率的主要因素,确定风电机组动态特性预测模型的输入和输出参数[13]。使用具有噪声的基于密度的聚类方法(DBSCAN)对原始数据进行异常值筛选[14],并采用堆栈式降噪自编码器(SDAE)建立性能预测模型[15]。在建模过程中为提高模型收敛速度,使用Mini-batch与Adam算法相结合的方法进行梯度下降优化,并利用网格搜索算法[16]对模型内部参数进行寻优,最终得到最优的风电机组动态特性预测模型。为了降低误报警概率,构建时移动滑动窗口模型以计算风电机组转速和功率的残差评价指标,实现风电机组异常运行工况预警[10-11,17]。
1 算法原理
1.1 DBSCAN算法
DBSCAN算法是一种优秀的基于密度的聚类算法,不需要确定聚类的数量,可以发现任意形状的聚类,能有效发现噪声点和离群点[14]。DBSCAN算法需要先确定2个参数ε和minPts,ε是指在一个点周围邻近区域的半径,minPts是指邻近区域内至少包含点的个数。
DBSCAN的一些基本概念定义如下。
(1) 邻域:给定对象半径为ε内的区域称为该对象的ε邻域。
(2) 核心对象:如果给定对象ε邻域内的样本点数大于等于minPts,则称该对象为核心对象。
(3) 直接密度可达:对于样本集合D,如果样本点q在p的ε邻域内,并且p为核心对象,那么对象q从对象p直接密度可达。
(4) 密度可达:对于样本集合D,给定一串样本点p1、p2、…、pn,p=p1,q=pn,假如对象pi从pi-1直接密度可达,那么对象q从对象p密度可达。
(5) 密度相连:存在样本集合D中的一点o,如果对象o到对象p和对象q都是密度可达的,那么p和q密度相联。
根据ε和minPts 2个参数,结合ε邻域的特征,可以把样本中的点分成3类:
(1) 核点(core point):满足NBHD(p,ε)≥minPts,则为核点。
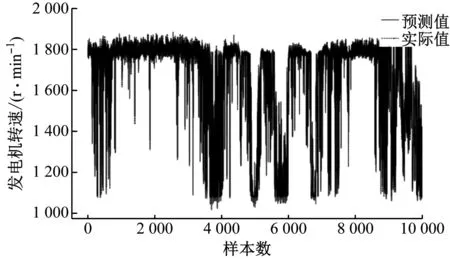
(2) 边缘点(border point):NBHD(p,ε) (3) 离群点(Outlier):既不是核点也不是边缘点,则称为离群点,又称噪声点。 有关核点、边缘点和离群点的概念如图1所示,其中minPts=4。 图1 核点、边缘点和离群点Fig.1 Core points, boundary points and outlier points 直接密度可达、密度可达和密度相连的概念如图2所示,其中各圆半径为ε,minPts取3。由于有标记的各点M、P、O和R的ε近邻均包含3个以上的点,因此它们都是核对象;M是从P直接密度可达;而Q则是从M直接密度可达;基于上述结果,Q是从P密度可达,但P从Q无法密度可达(非对称)。类似地,S和R从O是密度可达的,O、R和S均是密度相连(对称)的。 图2 直接密度可达和密度可达的概念描述Fig.2 Concepts of direct density reachable and density reachable 自编码器(Autoencoder,AE)属于神经网络的一种,其目的是对数据进行重构。AE网络可以看成是由两部分构成的:一部分是由编码器构成;另一部分是由解码器构成。降噪自编码器(Denoising AE, DAE)是由损坏的数据作为输入,通过训练来预测原始未被破坏的纯净数据的一种自编码器,增强了自编码器的鲁棒性和泛化能力。除了对输入层数据的处理不同,其余部分DAE与AE完全类似。DAE结构如图3所示。 图3 降噪自编码器结构Fig.3 The structure of DAE (1) (2) SDAE是由DAE堆叠而成的深度网络,采用无监督方式完成逐层特征提取的任务,使最终得到的特征更有代表性。SDAE将前一级DAE得到的特征作为后一级DAE的输入,完成最终建模。SDAE网络采用逐层贪婪算法先对每一层的DAE进行无监督预训练,之后再对网络进行有监督微调。 由于在风电系统建模过程中数据量较大,若直接利用SDAE模型进行训练会导致梯度下降缓慢,因此采用Mini-batch与Adam相结合的方法对SDAE进行优化,并利用网格搜索算法对模型内部参数进行寻优。Mini-batch梯度下降是指将数据集分成几个小组,不必等到算法遍历整个数据集后才更新权重和偏差,而是在每个小组结束时进行更新,极大地提高了梯度下降速度。笔者在训练模型时先将数据集分成每128组数据为一个batch,然后分别对每一个小组通过Adam算法进行梯度下降,以更新权重和偏置。Adam梯度下降算法是指在梯度下降过程中对偏差进行修正,其更新规则如式(3)和式(4)[19]所示。 (3) (4) 风电机组是由风轮、传动链、发电机、调节器和执行机构等共同构成的发电运行控制系统。其中,风轮子系统是利用风轮的转动将风能转换为机械能并带动发电机发电的重要能量转换装置,主要由叶片、叶柄和轮毂3部分组成。由于风速与风向的不确定性,在风电机组运行过程中,需要根据当前运行工况和风况对风电机组的偏航角度、桨距角和发电机转矩进行实时调节[13]。 在风电机组SCADA系统中记录了风参数、温度、桨距角、电参数、转子转速和偏航角度等近百个参数。笔者基于风电机组运行参数的内在关系对风电机组的异常运行工况进行预警,因此不考虑温度等参数。结合风电机组运行与控制原理,选取与发电机转速和有功功率密切相关的参数进行建模,最终确定的模型输入和输出参数见表1。 表1 模型的输入和输出参数 选取某风电机组SCADA系统采集的2018年4个月的历史运行数据进行建模,其采样周期为1 min,共计172 800组数据。不考虑缺失值、风电机组启动状态值(风速≤3 m/s)以及停机状态值(有功功率≤0 kW),将这些数据剔除后保留59 090组运行数据。据此绘制风速-发电机转速、风速-有功功率、发电机转速-有功功率曲线,如图4所示。 图4 输入输出主要参数统计关系Fig.4 Statistical relationship between main input and output parameters 由图4(a)和图4(b)可以看出,由于存在限负荷的情况,关系图呈“F”形,并且有较多不符合正常运行工况的离散点。若直接用这些数据进行建模,会降低模型的准确度。为此,先采用简单实用的折线法去除右下方的限负荷工况点,再采用DBSCAN聚类滤波的方法对数据进行清洗,将偏离标准值很多的离散点滤掉,最终得到正常工况数据为56 515组,如图5所示。 (a) 发电机转速 (a) 发电机转速 (a) 风速-发电机转速 (b) 风速-有功功率图5 DBSCAN清洗后的数据点Fig.5 Data points after DBSCAN cleaning 在建模过程中,由于各变量量纲不同且取值范围差异较大,为提升模型的收敛速度及模型精度,采用min-max标准化处理,将各变量归一化到[0,1],具体表达式为: x*=(x-xmin)/(xmax-xmin) (5) 式中:x为原始数据变量;x*为归一化后的变量;xmax和xmin分别为样本数据中变量的最大值和最小值。 如表1所示,记X={x1,x2,x3,x4,x5,x6,x7}为模型的输入向量,Y={y1,y2}为模型的输出向量,SDAE模型设置2个隐含层,模型的W和b等参数在训练开始前进行服从均匀分布的随机初始化。 选取正常工况的前10 000组数据,对模型进行训练,并利用网格搜索算法[16]对每个隐含层的单元个数、学习率以及噪声损坏程度进行寻优。优化后的2个隐含层单元数均为20,学习率为0.01,损坏程度为0.4,对应的模型训练结果如图6所示。 (c) 发电机转速偏差 为验证模型对不同数据的预测性能,选取随后的10 000组数据对训练好的模型进行测试,结果如图7所示。针对测试集的发电机转速和有功功率的平均绝对偏差分别为16.37 r/min和15.58 kW,精度满足工程应用要求。 在建立风电机组正常运行SDAE性能预测模型后,可利用模型输入参数的当前值对发电机转速和有功功率进行实时预测,并将预测值与实际值进行对比,得到重构误差。根据流形学习思想[20],当风电机组正常运行时,重构误差较小;若出现影响机组输出性能的设备故障、测量调控异常、保护系统动作或人为限负荷时,则重构误差会明显变大,据此可对风电机组异常工况进行早期预警,以防止事故扩大,降低运维成本。 (c) 发电机转速偏差 由于风速和风向具有很强的随机性和时变性,风电机组偏航、变桨、转矩等子系统一直处于自动调节的动态平衡过程,若直接根据单一时刻的重构误差进行异常工况预警,会导致误报警概率升高。为此,基于SDAE性能预测模型构建时移滑动窗口模型,从而实现异常状态识别,其原理如图8[10]所示。 图8 时移滑动窗口模型Fig.8 Time shift sliding window model 记Xi={x1i,x2i,x3i,x4i,x5i,x6i,x7i}为原始数据集,其中i=1,2,…,m,m为样本个数。设滑窗宽度为h,时移增量为Ω,第k时刻的窗口内输入tk-h到tk之间的数据,即Sk,其增广矩阵如式(6)所示。 (6) 在建模过程中要对h和Ω的取值进行调整,使时移滑动窗口模型能够准确预测机组的运行状态,并保证有足够的计算处理时间来确保预测的时效性。一般,若h过大会导致计算量增加以及灵敏度降低,若h过小则容易导致误报警。对于时移增量Ω来说,过大不能及时预警,过小则会增加计算频率,占用运行内存资源。 基于上述时移滑动窗口模型,在第k个窗口中将会产生h个误差,为避免正负误差相互抵消的问题并准确反映实际预测误差的大小,采用平均绝对误差C(tk)作为状态识别指标,其表达式如下: (7) 式中:Ypt和Yat分别为t时刻的模型预测值和实际值。 C(tk)值越大,则表明风电机组偏离工况越严重,为此应设定状态识别指标的预警阈值。 基于统计学中的区间估计理论,无需选取置信下限,只需选取置信上限Cth,区间[0,Cth]为状态指标C置信度为1-α的置信区间。置信上限Cth采用式(8)计算: (8) 为验证所提出预警方法的有效性,将该机组2018年历史数据导入Python,将其缺失值、风电机组启动状态值(风速≤3 m/s)以及停机状态值(有功功率≤-200 kW和主轴转速≤100 r/min)的数据筛选掉,建立异常工况预警验证数据集。根据模型训练样本集,滑窗宽度取5,即每个窗口包含5 min的数据;窗口增量为1,即每分钟向后滑动一次窗口并计算窗口内的状态指标。由式(8)确定置信度1-α中α取值为0.000 5时,发电机转速预警阈值Cth1为44.19 r/min,有功功率预警阈值Cth2为65.89 kW。 通过查询机组首发故障记录表,得知机组在2018-01-28T11:55出现“主控没有收到变桨反馈信号重复出现”故障。由于故障首次出现后控制系统的保护性调节,风电机组的转速和负荷等参数会偏离正常值,据此可实现异常状态预警。通过Pycharm软件运行本文模型程序,得到系统在2018-01-28T08:43出现转速预测与有功功率预测偏差均超限并报警,比故障记录大约早3 h。其滑窗预测报警界面如图9所示,表明此状态检测预警模型能够对上述异常工况提前给出正确预警。 图9 异常工况预警实例1Fig.9 Abnormal condition alarm case 1 对同一机组,取2018-02-11T08:26的数据为起始点,发现此模型程序在2018-02-11T08:34出现转速预测与有功功率预测偏差均超限并报警,其滑窗预测报警界面如图10所示。通过查询机组首发故障记录表,确认机组在2018-02-11T17:27出现了“振动监测器指示振动过大,继电器断开导致安全链断开”故障。预警系统对故障导致的异常工况及时正确地给出了预警,同样验证了本文模型和预警策略的正确性。 图10 异常工况预警实例2Fig.10 Abnormal condition alarm case 2 (1) 针对风电机组SCADA系统历史运行数据,采用DBSCAN聚类方法对原始数据进行清洗,剔除异常和故障数据,进而采用SDAE建立了风电机组正常工况性能预测模型,并对模型进行了验证。 (2) 基于风电机组SDAE性能预测模型,建立了基于滑动窗口的故障预警指标计算方法。以窗口的平均绝对误差作为状态识别指标,并根据统计学区间估计理论确定异常工况预警阈值。该方法可有效降低故障预警模型的误报警概率。 (3) 采用风电机组SCADA系统真实数据和故障案例对所提出的异常工况预警方法进行验证,表明该方法能够对风电机组异常工况进行提前预警,对于机组的安全运行和及时维护具有重要意义。

1.2 堆栈式降噪自编码器



2 风电机组性能预测模型的建立
2.1 模型输入输出参数的选取

2.2 SCADA数据预处理




2.3 风电机组预测模型建立与训练

3 基于时移滑动窗口的异常工况预警
3.1 时移滑动窗口模型



3.2 状态识别指标与预警阈值

4 实例分析
4.1 异常工况预警实例1

4.2 异常工况预警实例2

5 结 论
