输血辅助决策系统构建与应用效果分析*
2021-09-24杨江存
——沈 鑫 陈 航 黄 波 杨江存*
“互联网+医疗健康”战略背景下,智慧医疗迅速发展。基于人工智能将医院信息与临床实践集成,根据医学专业知识和经验推理判断,经机器深度学习分析后生成个体化评价建议的临床辅助决策系统。陕西省人民医院利用电子病历采集患者就诊信息和临床输血数据,分析影响红细胞输注的各项参数,经计算机深度学习后构建输血辅助决策系统,建立精准化用血管理决策平台,为安全、合理、高效输血提供了保障。
1 系统构建
输血辅助决策系统设计主要包括四部分,见图1。
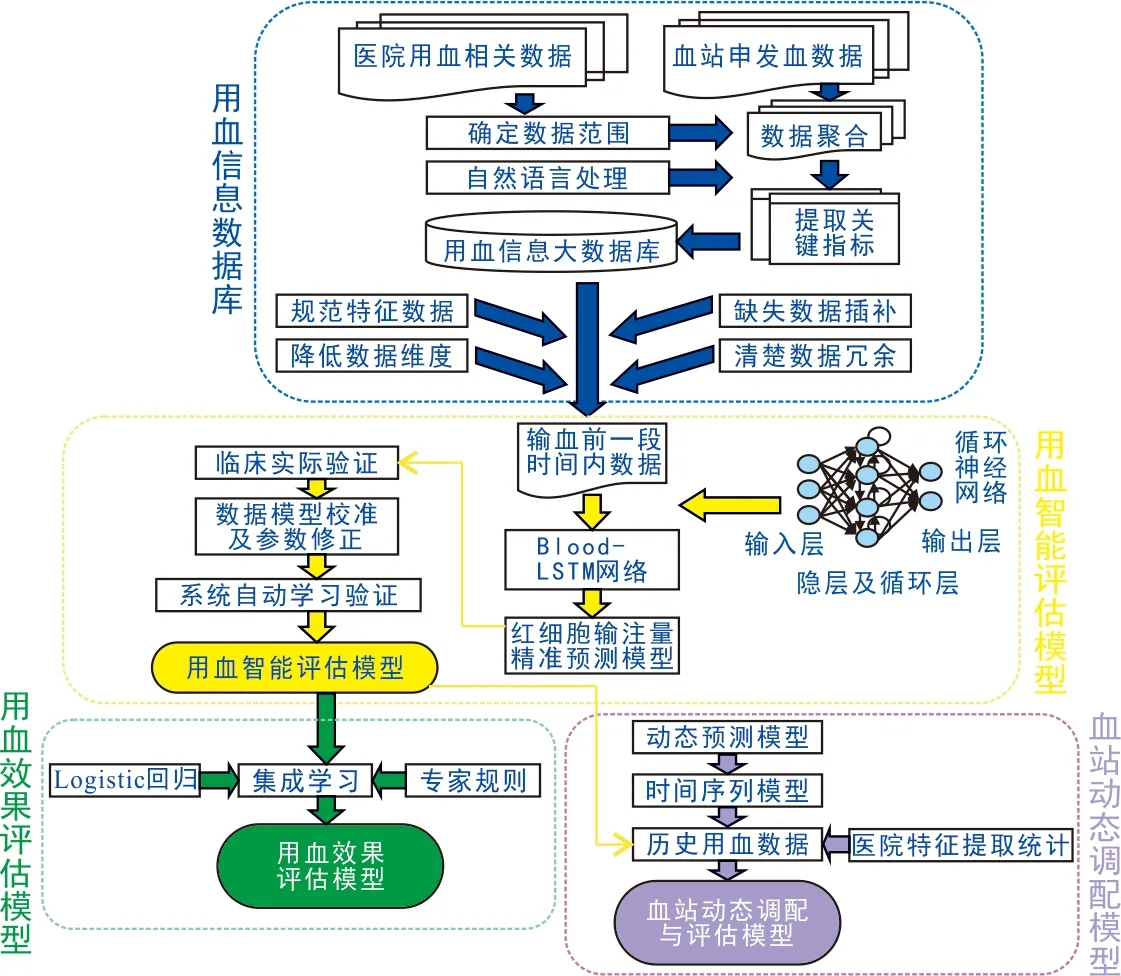
图1 输血辅助决策系统设计思路
1.1 用血信息数据库
依托HIS、LIS、输血管理平台、手术麻醉管理系统等,采集医院申请用血、发血历史数据与用血相关数据,通过自然语言处理、数据集成、数据清理、数据变换、数据归约等,生成输血信息数据库。数据库可查询数据,用于实时统计分析,实现用血预测、评估和动态决策。
1.2 用血智能评估模型
针对择期手术、内科治疗、急诊创伤等三种不同目的的用血,分别构建模型。以择期手术为例:利用数据库中患者基本情况(年龄、性别、身高、体重、疾病诊断、合并症与并发症等)、检查化验(血常规、凝血指标、生化检查、血气检查等)、生命体征检测(血压、脉搏、呼吸、心率、血氧饱和度、体温等)、手术信息(手术名称、手术级别、紧急程度、手术者、手术次数、手术开始时间、手术备血量等)、实际输注情况(有无自体输血、实际输注量、红细胞保存天数等),训练机器学习模型,对患者的失血量及合理用血量进行预测。实际应用中,更新跟踪模型,收集医生反馈信息,针对与预测不一致情况进行访谈,从中提取更多特征,结合前期预测积累数据对模型进行校准,同时生成统计数据。利用长短式记忆网络LSTM及贝叶斯算法,将用血信息数据库中的自然语言序列数据进行链式递归。通过持续使用-反馈、输入-输出对用血智能评估模型进行调整,助力精准化决策评判。
1.3 用血效果评估模型
用血效果评估采用大数据训练模型和专家标注相结合方式进行。1.3.1 标注 开始阶段,通过查阅文献以及咨询专家意见(如不同年龄组的术后血红蛋白阈值),筛选正常数据,标注数据,提取隐性特征(如急性失血患者、输血依赖性慢性贫血患者、普通患者),保证使用合理数据,同时适应多种不同情况。
1.3.2 分类 将择期手术、内科治疗、急诊创伤分为急诊用血、非急诊用血两大类,使用无监督学习方法进行数据聚类,将用血数据进一步划分成多种不同模式,对各个模式分别处理后与专家讨论,进一步确定各个类别的评价规则。通过机器学习,进一步整合数据,提供更有效的数据,进行子类型细分,筛选典型数据,简化工作量,同时挖掘未被发现的隐性特征。
1.3.3 机器学习训练 通过以下两种训练评估模型展开。训练评估模型一:将用血智能评估模型数据与真实用血数据进行对比,对用血进行评价。训练评估模型二:择期手术者计算患者失血量(患者基本信息、手术信息、检验信息等),内科治疗者计算患者耐受程度(身高、体重、年龄、性别、血红蛋白、耐受失血量等),急诊创伤者计算患者创伤紧迫程度(TASH 评分、PWH 评分、Vandromme 评分、ABC评分等),将上述情况代入Logistic回归模型,计算权重,评价输血必要性。
1.3.4 专家与机器学习模型结合 使用模型聚合方式,将机器学习训练及专家规则相结合,进行更有效、更精准的评价。如果在某一个类别中出现大量专家规则与模型评价不一致,与专家展开讨论,不断调整,达到精准用血目的。
1.4 血站动态调配模型
根据医院历史用血数据,利用时间序列分析法,对历史数据整体均值、整体趋势、季节性及序列临近值进行分析。按指数规律递减原理,赋予离预测值较近观测值较大权数,离预测值较远观测值较小权数,根据预测值与观测值之间的时间长短确定预测值可靠性,使预测值既能反映最新数据又能呼应历史数据,从而使预测结果更符合未来时间段医院用血实际。利用智慧医疗连接医院与血站,对血站库存、医院库存、医院预测用血量、医院用血需求评分进行及时动态评估,更好地解决临床用血调配问题。
2 系统应用
系统架构分为四层,分别为数据生产层、数据接口层、数据管理层和决策应用层,见图2。系统通过Web Service方式实时获取患者输血相关数据,作为输入提交到人工智能模型进行用血量预测,然后将预测结果通过Web Service方式返回医生工作站。
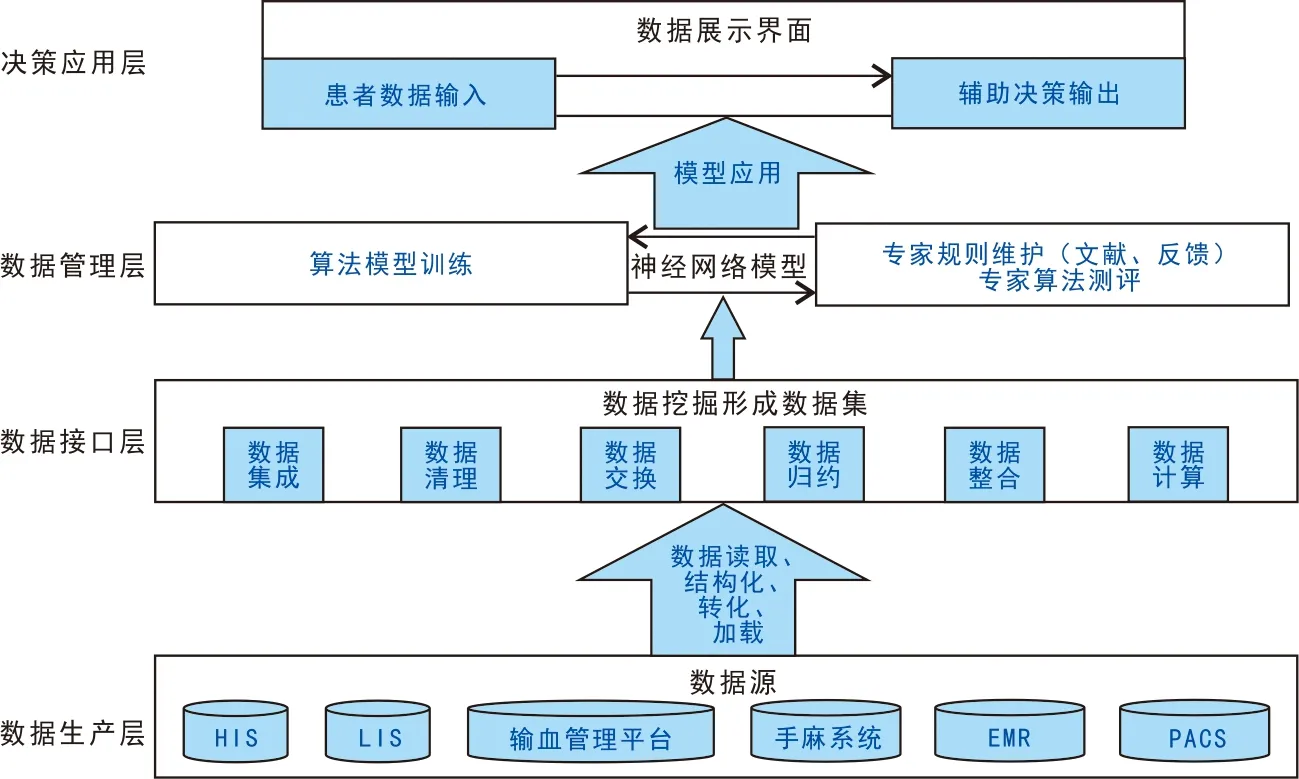
图2 系统架构
(1)用户登录。按管理者、使用者、维护者等不同类型分设权限,保障信息共享专一性,确保数据安全。
(2)选择触发。选择输血目的(术前备血、抢救用血、术中输血、纠正贫血、改善血氧状态、补充凝血因子、预防出血、纠正血小板异常等)和血液成分 “红细胞类”字样,自动触发预测模型。
(3)预测推荐。如该病例的基本信息、手术信息、检验信息满足预测模型最小集,模型会自动预测该病例本次输血推荐红细胞用量。
(4)选择调整。点击预测详情,显示经验与预测结果。经验结果分析包括经验术后血红蛋白(g/L)、经验输红细胞量(单位)、经验输红细胞量(mL)。预测结果分析包括推荐术后血红蛋白(g/L)、预测输红细胞量(单位)、预测输红细胞量(mL)。医生可综合分析,选择性调整术后血红蛋白值,给予不同红细胞用量。
(5)反馈记录。预测红细胞用量与实际值不符时,医生记录原因(如心功能不全、凝血障碍、高龄、相同部位既往再次手术等),便于模型整改。
(6)效果评估。对患者实际用血量、检查化验、症状体征、输血不良反应等进行综合评估,对输血效果进行判断。
3 运行效果
因模型评价建立在历史数据上,考虑到临床工作实际,2019年7月-8月试运行输血辅助决策系统,对是否输注红细胞、红细胞输注量预测效果展开评价,评价指标包括是否输血准确率、AI备血准确率、输血患者AI备血准确率。判定准确标准为实际输血与预测输血相差1U之内。结果显示,是否输血准确率达 88.51%,AI备血准确率达93.24%,输血患者AI备血准确率达 86.96%。
4 讨论
4.1 系统研发背景和必要性
血液是稀缺资源。世界卫生组织认为无偿献血人数占到国家总人口的1%~3%才能满足基本供血需求,我国无偿献血人数仅占总人口的0.9%,存在血液来源严重不足的问题[1]。与此同时,医疗技术水平提高及医疗保障制度完善,使临床用血量每年呈上升趋势。血液供不应求的矛盾日益严重。此外,临床工作中输血指征把握不严,现有行业规范和指南中没有血红蛋白介于60g/L~100 g/L患者的输血决策。综上,我国亟待推进精准化用血管理。国内外已有学者尝试将人工智能技术用于输血领域。Jo C等应用术前血红蛋白、血小板值、手术类型、年龄、体重、抗凝药使用六个术前变量,开发了基于机器学习算法的全膝关节置换术后输血预测模型,预测术后输血可能性,并为高危患者提供适当预防措施[2]。李杰等采用人工神经网络、极端梯度提升和Logistic回归预测了再次剖宫产术中输血[3]。利用智慧医疗,纳入影响精准用血因素,提供多因素关联判断,构建输血模型并不断完善,最终建立精准化用血管理决策平台,可为卫生健康行政部门及医疗机构制定政策、血液量化和调剂管理提供参考,可为医务人员提供临床辅助决策依据,更能保障患者合理、公平、高效用血。
4.2 系统应用注意事项
第一,智慧医疗平台开发设计前需综合考虑分析,确保基础环境、基础数据库群、软件基础平台及数据交换平台、综合运用及服务体系、保障体系等方面完备。如前期该院已搭建输血全过程闭环管理平台,实现了血液入库→入库复检→入库审核→交叉配血→血液发放→输血过程记录→不良反应→血袋销毁血袋闭环流转,形成了临床用血评估、标本核收、鉴定、交叉配血、发血、核对、输血过程、输血后评估、输血反应判断等信息反馈闭环,这为输血辅助决策系统构建用血效果评估模型和血站动态调配模型奠定了基础[4]。
第二,要搜集丰富的输血数据资源,引进数据挖掘清洗技术,建立用血需求评估及疗效评价数学模型。
第三,系统开发、实践、改进需管理者、临床业务专家、数据分析统计专家、信息人员等共同参与。应建立多方参与讨论的质控会,逐一查看预测不准确的病历,分析产生原因并针对性改进。
第四,应以输血数据质量为抓手,以输血模型构建为关键点,以输血预测准确为目标。输血数据来源广,数据类型差异大。针对数据格式不规范、关键指标(如手术名称、术前术后血红蛋白)缺失等问题,采用多重插值算法,利用输血数据库中无缺失数据计算统计分布多次插值填补,再从中筛选置信度最高的插补结果。针对数据偏差较大的问题,通过制定专家规则,将不符合规则样本变成无标签数据,然后利用弱监督学习,对这部分样本迭代计算生成标签,再参与到模型中变成训练样本。同时,为提高预测的准确性,在平台中添加手工录入反馈信息,医生对智能分析结果与实际结构有出入的手工录入进行原因分析并反馈,帮助集成学习模型修正,写入数据库中持久化,待积累到一定量后重新训练模型,帮助模型更新迭代。
