基于灰色关联度的110千伏主网基建模型研究
2021-09-23丁萍刚杨洲王祎
丁萍刚, 杨洲, 王祎
(国网衢州供电公司,浙江 衢州 324000)
0 引 言
110 千伏主网建设能够大大提高区域供电可靠性及网架发展适应性,提供更加可靠充足的电力供应,为助力地方区域经济社会高质量发展提供有力的电力支撑[1]。因此为优化国家电力产业结构,电网企业大力投资建设110 千伏主网基建工程。但建设过程中易受自然因素、经济因素及建设项目自身等因素的影响,导致基建工程质量与工程项目风险管控不稳定[2]。在确保国家电网高效稳定的前提下,合理地管理110 千伏主网基建模型,增大国家电网建设的收益能力已经成为国家电网公司亟需解决的问题。
目前,国家电网在资金投资预算和主网基建等方面进行了探索,电力部门也对主网基建模型开始了一些新的研究。然而,由于110 千伏主网基建投资测算关系复杂、影响因素多等原因,缺乏考虑因素全面的主网基建模型。随着国家电网体制改革的逐步深化,电网的经济效益在投资决策中占据的比例越来越大,主网基建主体的多元化对110 千伏主网基建建模提出了新的挑战[3]。针对上述背景及存在问题,本文对110 千伏主网基建的相关指标进行分析,将灰色关联度应用到了主网基建模型设计中,提高主网基建模型的有效性。
1 基于灰色关联度的110 千伏主网基建模型设计
1.1 选取110 千伏主网基建特征
每一个城市的110 千伏主网基建投资额及运行变化趋势不同,导致每一个110 千伏主网基建数据指标计算出的灰色关联度数值也不同。灰色关联度分析属于灰色关联分析方法中的一种,能够根据所研究项目的发展趋势提供量化的度量,具有计算量较小的优势,适合主网基建过程的动态分析[4],可以提取出影响主网基建运行的因素,从而提高主网建设效率。若按各城市110 千伏主网基建运行影响因素的选择策略进行因素选择,则各城市主网基建运行影响因素会存在差异,在进行110 千伏主网基建运行影响因素回归树训练时,就无法选择特征相近的城市数据一起参与训练。因此需要选取统一的主网基建特征,来保证多个城市的主网基建特征与主网建设效率之间的关联性。选取5个城市的110 千伏主网基建运行影响因素与主网建设效率数据,计算两者之间的灰色关联度,计算结果如表1所示。
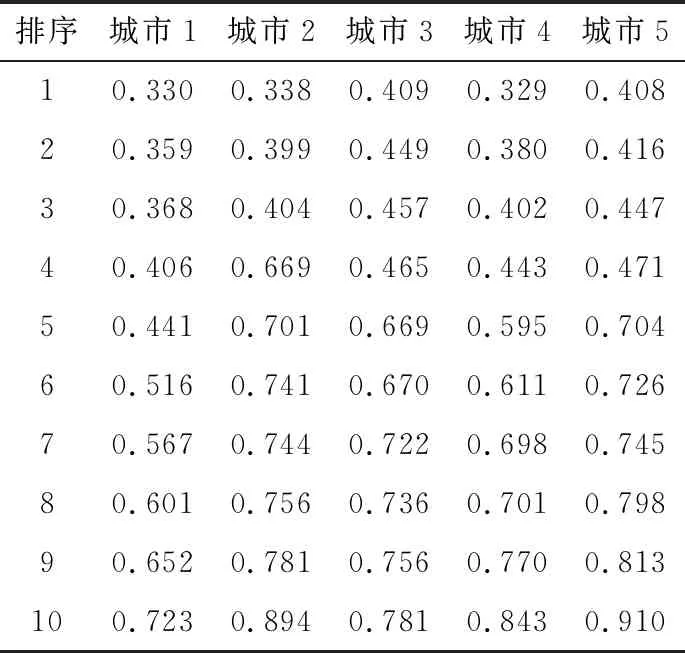
表1 主网基建运行影响因素与主网建设效率的灰色关联度数据
根据110 千伏主网基建运行影响因素与主网建设效率之间的关联度数值,制订主网基建特征选取步骤。
Step 1:将所有关联度数值排序,选取每个城市前t个110 千伏主网基建数据指标。
Step 2:统计5个城市的110 千伏主网基建特征数据指标i,前t个110 千伏主网基建数据指标出现的次数ni。
Step 3:删除影响最小的110 千伏主网基建数据指标。
Step 4:如果剩下的110 千伏主网基建数据量小于20,直接进入第五步;否则删除出现次数最少的c个指标,令t=t-c,重复第一步[5]。
Step 5:综合主网基建数据类别、出现次数ni,选取6个主网基建数据指标作为110 千伏主网基建特征。
110 千伏主网基建特征选取步骤的流程如图1所示。
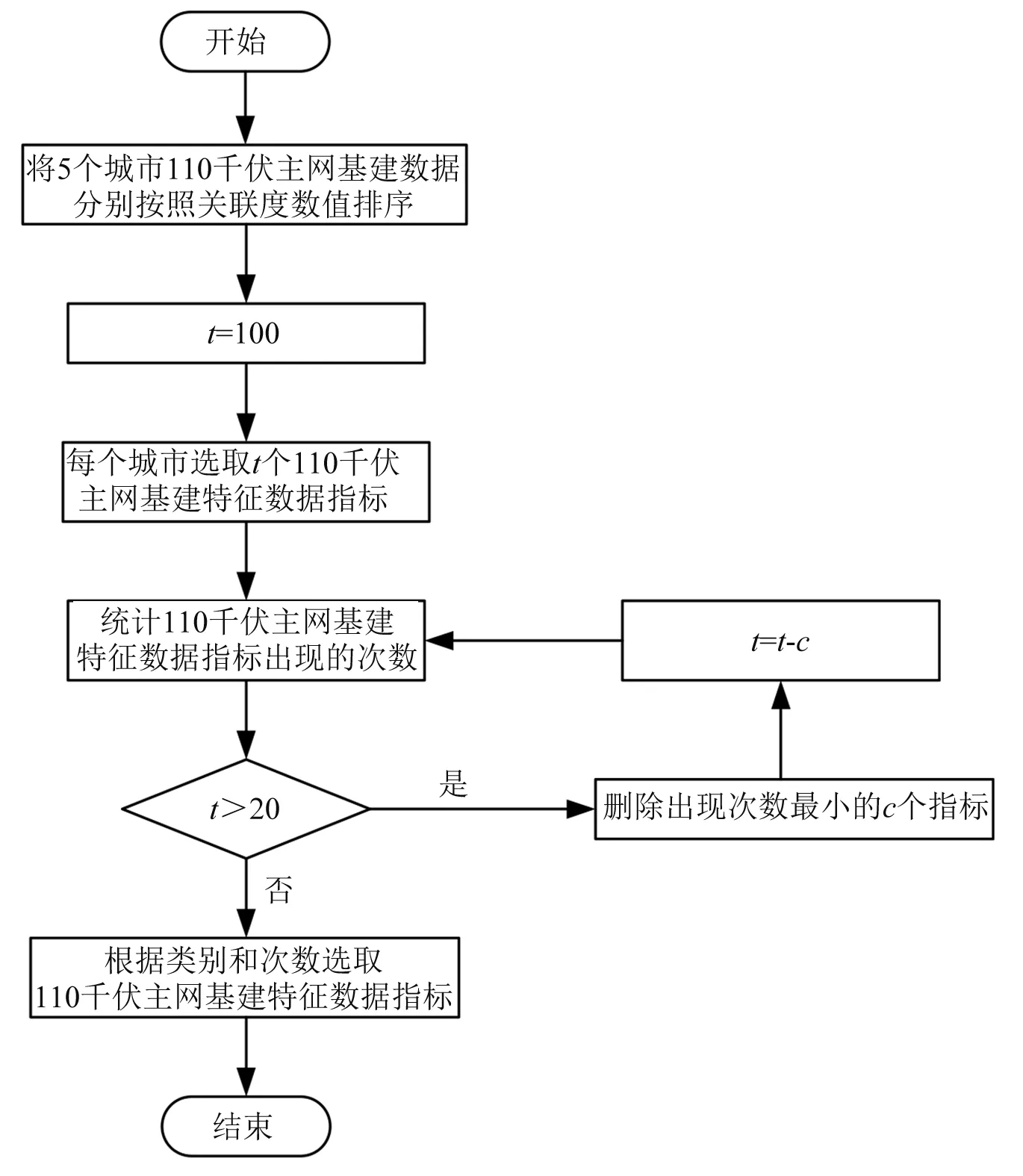
图1 110 千伏主网基建特征选取步骤流程
为了防止110 千伏主网基建特征出现差别,通过计算110 千伏主网基建运行影响因素与主网建设效率之间的灰色关联性,制订了110 千伏主网基建特征选取步骤,完成了主网基建特征的选取[6]。
1.2 聚类处理110 千伏主网基建特征数据
利用均值聚类的最优策略对110 千伏主网基建数据进行聚类处理,最优策略会将主网基建数据看作附加变量,优化操作在附加变量上进行,从而提高主网建设效率。主网基建数据聚类处理流程的具体实现步骤如下。
Step 1:整理110 千伏主网基建数据。
收集110 千伏主网基建数据样本,用x1表示。设xij为待处理数据,将其加入110 千伏主网基建数据集合[7]。
Step 2:设置待处理数据的初始值。
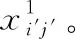
Step 3:110 千伏主网基建数据随机分类。
将110 千伏主网基建数据随机分成c类,随机得到每一类的初始聚类中心[8]。
Step 4:迭代次数初始化。
Step 5:计算灰色关联度。
对于110 千伏主网基建数据的每一个110 千伏主网基建数据元素xij,利用式(1)计算得到110 千伏主网基建数据的灰色关联度公式。
(1)

110 千伏主网基建数据的灰色关联度需满足以下条件:
uij>0
(2)
(3)
式中:uij为在第i个指标中j序列中的理想关联系数。
Step 6:更新110 千伏主网基建数据聚类中心。
根据式(4)来更新110 千伏主网基建数据聚类中心。
(4)
式中:xj为给定聚类数;m为聚类密度。
Step 7:计算待处理110 千伏主网基建数据的关联度。
对于待处理数据集合中的每一个待处理110 千伏主网基建数据xi′j′,利用式(5)计算待处理110 千伏主网基建数据的关联度[9]。
(5)
式中:r为迭代次数;ui为在第i个指标的紧邻均值。
Step 8:判断迭代计算是否满足结束条件,如果不满足,进入Step 9,否则进入Step 10完成数据处理。
Step 9:令r=r+1,返回step 5。
Step 10:得到110 千伏主网基建数据聚类结果。
基于灰色关联度的110 千伏主网基建数据聚类处理流程如图2所示。

图2 基于灰色关联度的110 千伏主网基建数据聚类处理流程
以上根据110 千伏主网基建数据处理流程,将110 千伏主网基建数据整理并设置初始值,依据主网基建数据的随机分类结果,计算了110 千伏主网基建数据的关联度矩阵。利用110 千伏主网基建数据关联度结束条件,完成110 千伏主网基建数据的聚类处理。
1.3 构建110 千伏主网基建模型
依据基建数据聚类结果,采用数学方法构建基于灰色关联度的110 千伏主网基建模型,从已知主网基建聚类数据中获取主网负荷和线路负载信息,来提高主网建设效率。基建数据指标体系具有数据量少、变化趋势不稳定等特点[10],需要从数据中寻找历史数据的变化规律构建模型,具体步骤如下。
Step 1:预处理110 千伏主网基建数据。
设n年主网基建数据的历史序列Y0为:
Y0=[y0(1),y0(2),…,y0(n)]
(6)
对110 千伏主网基建数据的历史序列进行一次累加,得到:
(7)
式中:y1(k)为主网基建数据做一次累加处理后的指标值;y0(i)为主网基建数据历史值。
Step 2:根据灰色关联度计算110 千伏主网基建数据的灰色关联度:
(8)

通过计算110 千伏主网基建运行影响因素与主网建设效率之间的关联性,制订了主网基建特征选取步骤,完成了基建特征的选取;设置主网基建数据初始值,依据基建数据的随机分类结果,利用基建数据灰色关联度结束条件,完成主网基建数据的聚类处理;实现基于灰色关联度的110 千伏主网基建模型设计。
2 仿真试验与分析
2.1 试验环境
为检验此次构建模型的有效性,以基建工程质量控制标准(WHS)合格率及基建的建设风险值为试验指标,与基于BIM构建的模型、基于运营数据的模型作对比。以浙江省某110 千伏工程项目基建数据为试验样本。采用电力系统的分析软件ETAP进行仿真建模。
2.2 主网基建质量合格率对比
为验证此次构建模型的有效性,在仿真平台运用三种模型建设110 千伏主网基建工程,检验不同模型的主网基建质量。以WHS合格率作为评价标准。WHS合格率的指标考核内容为工程实体质量水平和施工、监理、建设和设计等单位的现场质量管理水平,是评价电网基建工程质量的指标之一[11]。WHS合格率以一周为报送周期,其计算公式如式(9)所示。
(9)
式中:μ为本项工程WHS质量控制点执行抽检合格点数;φ为抽检总点数。WHS合格率Q≥80%时,项目质量为合格。
基于上述试验环境,对比不同模型的基建工程合格率,具体WHS合格率试验结果如图3所示。

图3 不同模型的基建工程合格率
由图3对比结果可知,对比其他两种模型的WHS合格率,所设计模型的WHS合格率高于90%,说明基建工程质量较佳。因为该模型选取了主网基建特征,并对特征数据进行了聚类处理,提高了基建工程的WHS合格率。
2.3 基建工程项目风险对比
为验证此次设计模型的建设效率,对比三种方法的基建工程项目风险。由于工程项目风险包含的内容较多,选择与110 千伏主网基建关系较为紧密的三个方面(技术风险、运行风险和环节控制风险)作为主要考察指标[12],得到整体建设风险计算公式。
D=P+F+S
(10)
式中:P为技术风险;F为运行风险;S为环节控制风险。不同的风险通过风险可能发生的概率、频率以及严重程度的量化数值乘积计算,不同风险的量化值范围均为1~10。基于上述试验环境及建设风险计算公式,对比三种模型的基建工程项目风险,具体结果如图4所示。
从图4可以看出,对比模型的基建工程项目风险值均高于12,而所设计模型的风险值则低于5,远小于其他两种模型的建设风险。所设计的模型计算了影响主网基建运行因素与主网建设效率之间的灰色关联度,排除了关联度较低的因素,降低了建设风险。

图4 不同模型的基建工程项目风险
3 结束语
针对主网基建过程影响因素较多的问题,提出了基于灰色关联度的110 千伏主网基建模型研究。对影响主网基础设施运行的因素和主网建设效率进行灰色关联计算,剔除关联程度低的影响因素,选取主网基建特征数据并对其进行聚类处理。结合主网历史序列数据构建主网基建函数模型,通过主网基建模型的构建,实现了基于灰色关联度的110 千伏设计。仿真试验表明,此次设计模型的基建工程WHS合格率高于90%,且基建风险较低。
