基于卷积神经网络的不同病理的鼾声分类
2021-09-23侯丽敏刘焕成张新鹏
侯丽敏,刘焕成,张新鹏
(上海大学 通信与信息工程学院,上海 200444)
睡眠呼吸暂停是一种常见的睡眠障碍疾病,国际睡眠医学会在睡眠呼吸暂停定义和相关评定规则的修订版中指出最常见的两类是阻塞性和中枢性呼吸暂停[1].阻塞性呼吸暂停(Obstructive Sleep Apnea,OSA)是睡眠期间人的上呼吸道被部分或完全阻塞,这种阻塞会导致人的胸肌更加努力地工作,以打开阻塞的气道并将空气吸入肺部.中枢性呼吸暂停(Central Sleep Apnea,CSA)是一个神经系统问题,大脑中枢暂时无法向负责控制呼吸的肌肉发出信号,从而导致呼吸运动停止[2].临床PSG(Polysomnogram)多路信号并行采集完全可以诊断出这两种不同的呼吸事件,它是以在睡眠期呼吸气流中断的同时是否存在呼吸努力来区分的.整夜的PSG监测中,如果OSA事件占多数,则诊断为阻塞性为主的患者.反过来,如果CSA事件占多数,则诊断为中枢性为主的患者.睡眠障碍疾病中阻塞性患者占绝大多数,中枢性患者的占比不到20%[3].然而,CSA呼吸事件通常与严重疾病有关,尤其是控制呼吸的下脑干有关的疾病[2-3].对于大脑发育不全的新生儿,CSA会产生长达20 s的呼吸暂停[4].研究者指出:CSA事件的发生与年龄正相关,在741名随机抽取的受试者中,老年人中的12%在监测中出现了中枢性呼吸事件,每小时至少出现2次以上;受试老年人中的5%在监测中出现了更多的中枢性呼吸事件,多达20次/h[5].因此,筛查不同病理的鼾声将有助于进行早期诊断和及时的相应治疗干预.
目前对OSA鼾声的信号处理和分类的研究较多,多涉及对鼾声信号的声学参数进行分析和分类、对上气道阻塞部位的确定[6]、对OSA患者患病严重程度的筛查等[7-8].而涉及CSA鼾声的研究相对较少.Hummel等[9]用录制的鼾声,首次提出了对睡眠呼吸暂停进行分类的方法,他们从25位患者的鼾声数据中切割只包含CSA事件的片段40个和切割只包含OSA事件的片段45个,每个片段中包含多个子鼾声、呼吸暂停和正常呼吸声,持续大约2.5~8.0 min,然后提取过零率、频谱质心、打鼾比等多个特征,用支持向量机(Support Vector Machine,SVM)分类器对85个音频片段进行分类,取得了良好的结果.Hummel等的研究初步说明了不同生理过程导致的OSA和CSA鼾声有着不同的声学性质.然而,他们的实验数据和参与的患者较少,有待更多的数据来验证此结论.
本文采集了更多患者的鼾声录音,共有90名患者.根据OSA与CSA产生机制的差异性,提出了利用同态信号处理的方法分离出鼾声的完整上气道冲激响应(Upper Airway Impulse Response,UAIR),即联合了幅度和相位频谱来得到的UAIR为完整的UAIR.两类鼾声的UAIR初步显示出不同的表现,本文据此提出了完整上气道冲激响应繁衍特征,包括UAIR的振动频数(Vibration Frequency,VF)、振动强度(Vibration Intensity,VI)、折叠因子(Folding Factor,FF)、上升速度(Rise Velocity,RV)和下降速度(Drop Velocity,DV)5个特征.对90名患者的OSA和CSA两类鼾声数据做了分析和统计,给出每个特征下的两类鼾声的盒图分布图.本文进一步设计了基于卷积神经网络(Convolutional Neural Networks,CNN)的深度特征加工和分类器1D CNN(1 Dimension CNN),以UAIR等5组声学特征分别作为系统输入的1维特征,对系统分类性能做了评估.使用UAIR特征的网络CSA鼾声正确率为72%,OSA鼾声正确率为86%的最佳分类结果,且高于其他的经典特征.实验结果表明1D CNN是一种较为有效的特征深度加工处理器.
1 数据和CNN结构的设计
本文采集了患者的鼾声录音,标注了OSA鼾声和CSA鼾声数据,根据它们产生的机制提取声学特征,设计了适合本文分类的1D CNN网络架构,从而实现对两类不同病理的鼾声的分类,也即识别.
1.1 实验数据
本文中的实验数据均来自上海市第六人民医院耳鼻喉科睡眠监测病房录制的患者鼾声信号.患者在其鼾声信号被录音的同时也进行PSG监测[10].本文采集了阻塞性呼吸暂停低通气综合征(Obstructive Sleep Apnea Hypopnea Syndrome,OSAHS)、中枢性呼吸暂停低通气综合征(Central Sleep Apnea Syndrome,CSAS)和混合性呼吸暂停综合征(Mixed Sleep Apnea Syndrome,MSAS)患者的整夜录音,3种类型患者共有90人.OSAHS患者是指PSG诊断为阻塞性的患者,这些患者整夜呼吸事件中OSA鼾声占多数;CSAS患者是指中枢性的患者,这些患者整夜呼吸事件中CSA鼾声占多数;MSAS患者是指混合性的患者,这些患者整夜呼吸事件中MSA鼾声占多数[1].其中混合性呼吸暂停的呼吸事件是指中枢性和阻塞性共存,在一个呼吸事件过程中先出现中枢性呼吸暂停,紧接着转换为阻塞性呼吸暂停.90人当中3名患者为轻度型,其余均为中度和重度型[10].音频录音的采样频率包含8 kHz和16 kHz两种.实验中将16 kHz的音频做了下采样处理,转换为8 kHz.
将整夜录音与PSG数据对齐,对照PSG中标记的OSA呼吸事件和CSA呼吸事件,做了人工切割并标注出OSA鼾声和CSA鼾声,得到的鼾声数据如表1所示.90人中包含1名CSAS患者,73名OSAHS患者和16名MSAS患者.表1中的信息包含了患者年龄的均值和标准差,男女人数,患者呼吸紊乱指数(Apnea Hypopnea Index,AHI)的均值和标准差,以及切割的CSA鼾声和OSA鼾声片段的数量.

表1 实验数据集Tab.1 Experiments data sets
1.2 声学特征


图1 鼾声完整上气道冲激响应计算的流程图Fig.1 Flowchart for calculating the upper airway impulse response of snore sound
对OSA鼾声和CSA鼾声按照图1进行计算得到相应的UAIR结果如图2所示.图2(a)和(d)分别是CSA鼾声和OSA鼾声的时域波形,图2(b)和(e)分别是CSA鼾声和OSA鼾声中某一帧的复倒谱,图2(c)和(f)是用复倒谱计算出的CSA和OSA的UAIR.比较图2(b)和(e),两者的复倒谱规律类似,但OSA的复倒谱幅值更大一些;比较图2(c)和(f),CSA鼾声的UAIR波形光滑一些,OSA鼾声的UAIR在上升和下降阶段毛刺较多,反映出其快速波动更多;OSA鼾声波形上升的幅度也更大,两者的差异性明显.由于复倒谱表现出良好的集中性,如图2(b)和(e)所示,大值集中在中心部位,其余的值很小,因此这里低倒频窗的宽度取9个样本.图2中t表示时间,由于录音的音频信号是归一化处理的,所以这些幅度没有单位.
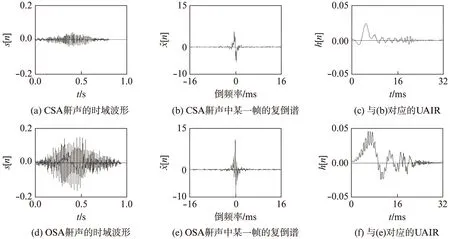
图2 鼾声上气道冲激响应的计算结果Fig.2 Results of UAIR for snore
为了进一步说明完整UAIR体现出CSA和OSA的不同,本文提出了UAIR的量化特征,包括UAIR的VF、VI、FF、RV和DV共5个特征.VF特征表示UAIR的极值点大于某个阈值的数量.VI特征表示UAIR的最大幅值与其后第1个小于零的极小值之间的距离.FF特征表示大于某阈值持续时间内的UAIR的幅值差分的绝对值之和.RV特征表示UAIR最大幅值与上升时间的比值.UAIR的最大幅值点的时刻到其后的第1个过零点时刻的持续时间的比值为DV特征.对90名患者的OSA鼾声和CSA鼾声的数据做了计算,统计每个特征下的两类鼾声的盒图分布,如图3(见 第370页)所示.OSA鼾声和CSA鼾声的分布区域有较大的差异性,说明UAIR能反映两类鼾声的不同特点.
当然图3给出的CSA鼾声和OSA鼾声定量特征的统计分布存在着一些重叠区域,单纯利用这组特征还不能准确识别鼾声.

图3 从完整上气道冲激响应提取5个量化特征的盒图分布Fig.3 Boxplot of five features from UAIR
1.3 基于CNN的鼾声识别系统
CNN在语音识别中已有广泛的使用[11-12].卷积层和池化层是交替出现的,用来对特征进行加工和处理.先前的许多研究将音频信号作傅里叶变换得到幅度谱,在幅度谱的基础上得到进一步的特征,例如对数Mel、Mel频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)等特征,使用2D CNN架构做语音识别和说话人确认[13-14].近来有研究者提出1D CNN架构,直接输入1维的原始波形来学习,从而完全避免了任何特征提取步骤.1D CNN在音频事件分类[15]和说话人识别中有良好的分类效果[16],它们均以音频的1维时序信号作为1D CNN的输入特征.
本文设计了一个基于1D CNN的网络结构对CSA鼾声和OSA鼾声进行分类,充分利用1D CNN直接从1维信号中学习和加工的特点,用完整上气道响应的1维时序波形和原始音频波形等1维特征分别作为该网络的输入.多个卷积和池化交错用于捕获信号的深度特征,与3个全连接层的分类任务结合共同实现分类的任务.这种方法也可以处理任何长度的音频信号.本文以1帧的长度作为输入向量的长度.网络结构由输入层、卷积层和全连接层组成.卷积层包括卷积、批量标准化(Batch Normalization,BN)、激活函数和池化层,激活函数使用的是修正线性单元(Rectified Linear Unit,ReLU),池化层使用的是平均池化.随后3层的全连接每层的特征数量有所下降,以较少的特征充分体现两类的差异性并防止过拟合.假设该结构1D CNN的输入是1维特征X,即X为(1×N)的数据,网络参数为Θ,M表示隐藏层的总数.则预测值
T=F(X|Θ)=fM(…f2(f1(X|Θ1)|Θ2)…|ΘM).
(1)
第m个卷积层和全连接层的计算如式(2)所示:
fm(Xm|Θm)=A(W⊗Xm+b),Θm=[W,b].fm(Xm|Θm)=A(WXm+b),Θm=[W,b].
(2)
其中:⊗表示卷积操作;W表示1维的卷积核或加权系数;Xm为输入的特征;b为偏置;A( )为激活函数.
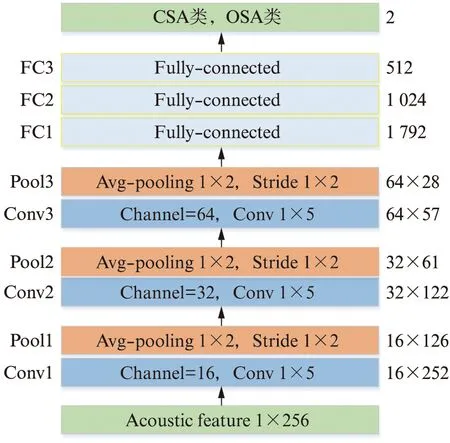
图4 对CSA鼾声和OSA鼾声分类的1D CNN结构图Fig.4 The architecture of 1D CNN for CSA snore and OSA snore classication
图4是以1维数据流作为输入特征的3层卷积加3层全连接的神经网络结构图,它由输入层、3个卷积层、3个全连接层和输出层组成.图4中的输入特征是帧特征UAIR,长度为256,卷积层滤波器的数量和尺寸等设置在图中给出,池化采用的是平均池化,步长均设为1.第1个全连接层将特征拉平为1 024个参数,最后一个全连接层参数为512个.使用softmax作为输出层的激活函数,每个输出神经元指示每个类别的输入样本的隶属度.在训练过程中,根据反向传播的分类误差调整网络的参数,并以最小化损失函数优化网络的参数.
对各个卷积层的滤波器核尺寸和池化均选用固定的尺寸,池化均采用平均池化.第1层卷积的信道数量较小,后续逐层扩大卷积处理的信道数量.由于用于训练的数据量是有限的,因此在没有明显的过度拟合的情况下网络使用更深的架构是不可行的.
2 结果和分析
为了进行4折交叉验证,根据表1将患者的数据以按大约0.75∶0.25的比例划分为训练集和测试集,共4组,同时保证训练集的患者与测试集的患者相互独立.在训练阶段,1D CNN的输入特征为每帧提取的声学特征,输出帧正确率(Frame Accuracy,FAC)λFAC作为训练的结果.统计两类鼾声各自分类正确的帧数,分别除以各自帧的总数,分别得到CSA鼾声和OSA鼾声的帧正确率(每轮的小批量数据batch取512,训练在100~200轮左右):
(3)
在测试阶段,测试集的评判准则是鼾声片段正确率(ePisode Accuracy,PAC)λPAC判别方法,该方法的判别是以每个鼾声片段中多数帧的归属结果为此片段的最终结果.这种评判符合实际情况下对鼾声的评估,单帧的归属孤立起来看没有实际意义.因此统计两类测试鼾声片段各自分类正确的数量,分别除以各自测试片段的总数,得到CSA鼾声和OSA鼾声片段的分类正确率,如式(4)所示.最后将CSA鼾声测试的正确率和OSA鼾声测试的正确率加起来平均,得到平均正确率.
(4)
对图4的结构做了不同的调整检验:当只用1层卷积和池化再做全连接时,训练的结果停留在80%左右,无法达到天花板;当用3层卷积和池化再做1层全连接时,训练的结果在85%左右,也无法达到天花板,说明网络架构太小,不能全面揭示分类任务的本质.只有采用3层卷积和3层全连接时,训练集的结果可以达到或接近天花板.当卷积层加深到5层时,结果与3层的相近.其损失函数也是一直下降最后平缓下来.对卷积核的尺寸也做了优化调整,尺寸太小或太大结果不佳,目前使用的(1×5)优于(1×3)和(1×7).池化也分别用最大池化和平均池化做了对比,平均池化时网络效果更佳.
2.1 数据扩增
切割的CSA鼾声与OSA鼾声的数据不平衡可能对分类的结果产生不良影响,因此需要对CSA鼾声数据进行扩增(Data augmentation).数据扩增常用的方法包括时间拉伸(Time stretching)、改变信噪比(Signal Noise Rate,SNR)、静音修剪(Silence trimming)、时移(Time shift)和加背景噪声(Background noise)等[17-18].
本文用时间拉伸、改变信噪比和时移的方法对训练集数据做了扩增.时间拉伸和改变信噪比的方法保证了CSA鼾声片段和OSA鼾声片段的数量接近,时移保证了CSA鼾声的帧和OSA鼾声的帧的数量接近.时间拉伸的速率分别为0.9和1.1,加白噪声的信噪比分别为10 dB和20 dB,时移对CSA鼾声片段的帧移为30样本点,OSA鼾声片段的帧移为128样本点.对UAIR特征在原始数据得到的结果与在不同数据强化下得到的结果进行对比,结果如图5所示.图中横坐标的原始表示用原始数据,组合1表示原始数据+时间拉伸,组合2表示原始数据+噪声,组合3表示原始数据+时移,组合4表示原始数据+时间拉伸+噪声+时移.用第1折的数据做实验.

图5 数据不平衡与数据扩增之后的实验结果对比Fig.5 Comparison experimental results of data imbalance and after data augmentation
原始数据与不同数据扩增方法的结果对比表明数据扩增均能提高测试集CSA鼾声的片段正确率.用原始不平衡的数据,CSA鼾声的λPAC仅有43%,不同的数据扩增方法提高了CSA鼾声的片段正确率,其中原始数据+时移数据的表现更好,与原始数据相比,对CSA鼾声的λPAC提升了24.93%,其他方法次之.原因可能是时间拉伸或者添加不同的信噪比都扩增了CSA鼾声片段的数量,但是增加的数据在一定程度上造成鼾声频谱有某种变化,而时移法对原始音频数据没做任何变形处理,鼾声的频谱没有任何本质的改变.对OSA鼾声的识别几乎不受数据扩增的影响,其片段正确率都保持在90%以上.
2.2 实验结果
训练和测试的结果如表2所示.训练的帧正确率λFAC是以上升平缓阶段之后的10轮结果的均值;测试的片段正确率λPAC以训练对应的10轮结果的均值.4折交叉验证之后再做均值和方差.得到表2中的训练集λFAC和测试集λPAC.表2的最后1列是对测试集结果的平均正确率,将CSA鼾声测试的正确率和OSA鼾声测试的正确率均值加起来的平均值.
表2的结果显示训练集的结果均接近天花板,说明本文设计的1D CNN结构是合理有效的,其中3个卷积层对输入的特征深度加工,经3个全连接层的分类,能够较好地训练出CSA和OSA两类鼾声的深度参数或模型.测试集的结果表明5组特征对CSA鼾声分类的正确率在55%~72%,其中UAIR特征取得的分类正确率最高,为72.27%,而对数Mel特征取得的分类正确率最低,为55.19%.测试集的5组特征对OSA鼾声分类效果较好,正确率分布在86%~94%之间.本文提出的UAIR特征在1D CNN系统上取得了良好的效果,说明UAIR特征经过卷积神经网络的加工能够较有效地提取出CSA鼾声和OSA鼾声的区分特征.
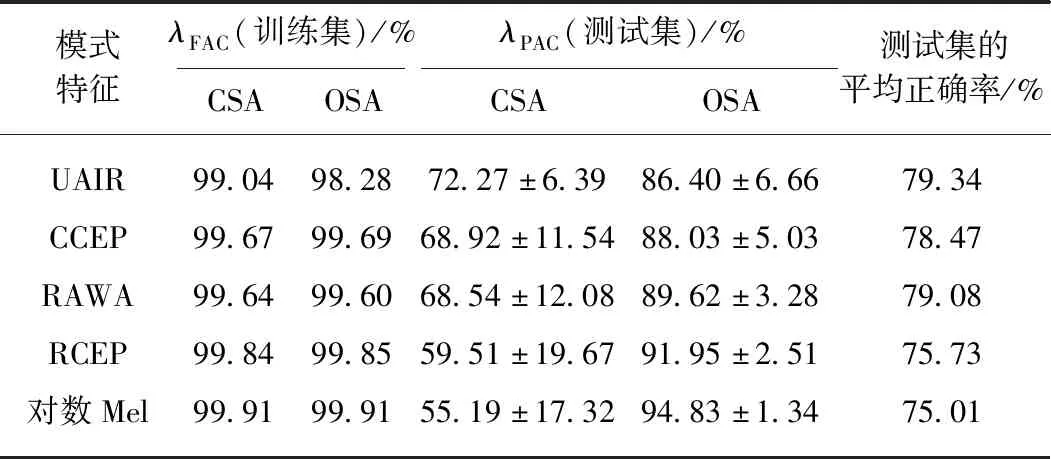
表2 实验结果Tab.2 Experiments results
2.3 分析
本文设计的1D CNN系统对CSA鼾声的识别效果仍不够理想,其中UAIR特征做出的正确率均值达到72.2%,方差6.3%,其他特征在CSA鼾声识别上,均值更低,方差更大.方差大说明了这些特征的稳定性变差,如表2所示.原因可能有以下几个方面.如表1的数据显示,CSA的鼾声片段远少于OSA鼾声的片段,尽管对数据数量的不平衡做了扩增,数据内部仍有其他方面的不平衡,本文数据集的90人仅1人是中枢性患者,89人为阻塞性和混合性患者.对这阻塞性和混合性的89人来看,他们的CSA呼吸事件大部分夹杂在OSA呼吸事件或MSA呼吸事件之间,患者已有过阻塞性的呼吸事件,身体器官尤其是脑部已处于缺氧状态,过量的二氧化碳导致中枢运动控制系统的间歇,这时发生了中枢性呼吸事件,但上气道的狭窄仍有可能存在,使得CSA鼾声发生时可能同时含有上气道狭窄的信息.再者,训练集与测试集的患者是独立的,训练正确率高,测试正确率偏低,反映出CSA鼾声可能与患者的个体关联性较强.本文设计的1D CNN对CSA鼾声的本质体现不够充分,有些依赖患者的数据.今后在这点上还要继续深入研究.另外,ID CNN的输入是一帧向量,对时序上的关联性体现不够密切,扩大输入的帧向量,或用2D CNN架构,进一步挖掘多方向上的特征帮助区分CSA鼾声与OSA鼾声.
从综合角度来看,测试集的5组特征的识别结果中,UAIR特征效果最佳,取得了识别出七成的CSA鼾声,识别出八成多OSA鼾声的良好结果;原始音频时域波形RAWA次之,且UAIR和RAWA的平均正确率达到了79%以上.再次证明1D CNN架构适合1维的时序数据流作为输入特征,UAIR和RAWA均为音频时序波形.本文从RAWA计算出其复倒谱,经低倒频窗只取了复倒谱集中的9个值计算出UAIR,可见UAIR更能突显出CSA鼾声与OSA鼾声产生过程的不同.复倒谱CCEP的平均正确率为78.47%.UAIR、RAWA和CCEP特征的共同特点是:CCEP和UAIR联合了频谱的幅度和相位信息,信息量更大一些,RAWA也是完整的时域波形,对识别出两类不同病理的鼾声是非常有用的.RCEP和对数Mel特征的识别效果比较差,尽管它们在OSA鼾声的识别上正确率更高一些,却牺牲了CSA鼾声的识别,只有近一半的CSA鼾声被正确识别出来.RECP和对数Mel特征只包含了频谱的幅度谱,丢弃了相位谱.因此保留信息全面的一些特征如UAIR、CCEP和RAWA,两类不同病理的鼾声中有着良好的区分性.
3 结 语
本文提出了一种用于中枢性和阻塞性鼾声分类的1D CNN网络.网络的体系结构由3个卷积层和3个全连接层组成,充分利用了1D CNN可以直接从音频波形或帧向量中学习滤波器的特性,得到对两类鼾声的区分性较强的特征加工,在7 000多个音频样本的数据集上对提出的方法进行了评估.实验结果表明,这种直接处理音频波形的神经体系结构对两种不同病理的鼾声具有良好的特征加工和分类效果.此外,网络对本文中5组特征的训练也显示出很好地普适性.本文通过对不同病理的鼾声产生机制的分析,提出了完整上气道冲激响应(UAIR)特征,1D CNN架构能较精确地提取一些重要的区分特征,取得了良好的效果.与多组特征比较,UAIR特征表现最佳.在今后的工作中,我们将会探讨其他更复杂的深度学习方法,例如残差网络、增加注意力机制等,试图捕获更多的差异特征,进一步提高CSA鼾声和OSA鼾声的区分能力.
致谢:感谢上海交通大学附属上海第六人民医院耳鼻喉科在实验数据采集中的帮助和支持.
