基于字典学习的无监督机器异常声检测
2021-09-23李圣辰
姚 瑶,李圣辰,邵 曦
(1.南京邮电大学 通信与信息工程学院,江苏 南京 210003;2.西交利物浦大学 智能工程学院,江苏 苏州 215123)
近些年来,科学技术水平不断提高,各种高科技产品也越来越智能化,其中就包括很多监控设备.异常音频事件检测(Anomalous Sound Detection,ASD)成为了一个热点问题,尤其是在视频监控难以到达的领域,如结构复杂的机器内部或者需要监护的老人家里.这就需要一款既能实现实时监测,又能保障顾客隐私的异常事件检测系统.音频异常事件检测系统就可以代替或者结合视频监控,双管齐下,解决视觉盲区问题,缓解监控人员的压力,起到几全其美的作用.
随着工业技术的快速发展,机械化生产已经成为主流,极大地提高了产品生产的效率,保障了产品生产的质量.机器系统的稳定运行对机器生产的效率、质量,乃至安全都有重要的作用,所以在机器运行过程中做好监测和及时警报具有重大意义.在大部分时间里,机器都处于稳定运行阶段,这段时间机器发生的故障很少,但故障种类较多[1],难以收集到机器的所有故障声进行有监督地训练.无监督学习的机器异常声检测系统在异常音频样本数据集很少的情况下可以发挥巨大的作用.通过比对训练集正常样本库里的特征和新出现的异常样本特征,可以检测到异常的音频事件.
在信号处理领域,稀疏表示和字典学习被广泛应用.字典学习最初起源于压缩感知(Compressive Sensing,CS)领域,其主要思想是创建声事件表或者特征词典对场景建模,其中字典中的事件和特征不一定是先验的,因此可以从数据中以无监督的方式学习字典[2].目前构建字典有两种方法:一是解析法;二是学习法.解析法一般通过信号的某种数学变换来构造,其构造简单,计算复杂度低,但是原子形态固定,不够丰富,难以达到最优表示的目的.而通过学习法来获得过完备字典的方法被广泛应用,它的字典原子更丰富,能更好地匹配信号本身,可以获得更稀疏的表示[3],这也是本文采用的方法.在稀疏表示领域,总是希望表示系数越简单越稀疏越好.良好的稀疏度和较小的重构误差可以让特征区分得更加明显,以简化分类过程.这一方法在人脸识别领域已经取得了非常好的效果[4-5].对于无监督学习的分类,常用的方法有局部异常因子(Local Outlier Factor,LOF)检测[6]、孤立森林(Isolation Forest,iForest)[7]、自编码器(Auto-Encoder,AE)等.我们选择了单分类算法里的单类支持向量机(One-Class Support Vector Machine,OCSVM)[8],它具有计算时间短,适用于只有较少样本的训练集,对噪声的鲁棒性强等特点.它通过正常声音的数据建立异常声检测模型,该模型将训练数据样本通过核函数映射到高维特征空间,以获得更好的聚集性,并且在特征空间中求解一个最优超平面使得尽可能多的正常数据落入决策边界内.
1 特征提取
1.1 数据预处理
本次使用的音频为采样频率为16 kHz的单声道机器声,在进行特征提取之前,我们对原始音频信号进行分帧加窗,以得到更多更加准确的信息.根据音频长度,在时域上将每10 s分为311帧.将窗口的长度设置为1 024个点,单跳大小设置为512个点,然后对每一帧进行传统特征计算,并在字典学习之前进行归一化处理.
1.2 特征选择
在特征选择方面,由于本研究面对的是带有故障的机器声,信噪比很低,且具有机器特性,如振动特性、旋转特性、摩擦性等,所以我们选择了16个传统信号参数组成的特征集.传统的特征包含故障信息,更有利于学习异常音频的相关分布,从而提高分类精度.下面我们介绍一下所用的特征.
首先是时域特征.时域特征表征的是信号在时间和空间中的变化规律及其内在特性.通常机器信号的时域统计特征主要分为两大类型:有量纲特征参数与无量纲特征参数.其中,有量纲特征参数表征机器的运行状态,并且会随负荷、转速的变化而产生相应的变化;无量纲特征参数是相同量纲参数的比值,它能够反映机器运行过程中的故障情况.本研究用到的机器振动信号的时域特征参数分别如表1,表2所示.

表1 时域有量纲特征参数Tab.1 Dimensional characteristic parameters in time domain

表2 时域无量纲特征参数Tab.2 Dimensionless characteristic parameters in time domain
表中,Xabs代表信号绝对值,N代表采样点数.以上特征参数中,峰值指标、脉冲指标和峭度可以用来检测信号有无冲击;歪度指标可以反映数据分布情况;裕度指标、峰值和波形指标等都可以反映设备的磨损情况.我们通常用敏感性和稳定性来衡量指标的性能,并且由于稳定性和敏感性往往不会同时最优,所以这些参数常常会被组合起来运用,来兼顾这两方面的性能.例如脉冲指标、峰值指标和峭度可以很好地检测出早期故障.在冲击故障发生早期,它们的值会明显增大,敏感性好,但是上升到一定程度后反而会下降,稳定性差[9].有效值虽然对早期故障信号不敏感,但是稳定性好,所以它们经常被一起运用以获得更好的效果.
机器信号的频域特征参数可以反映出机器信号的能量随频率分布的情况.当机器出现故障时,机器设备的振动幅值会保持较高的值,这时时域特征参数仅可以表示机器设备发生了故障,而频域特征参数可以帮助分析设备发生故障的具体位置和原因.本次我们选用的频域特征如表3所示.其中:f=(1∶N/2)×fs/N;fs表示采样频率;S(f)表示信号频谱.这样,我们就获得了所需要的16维特征,包括了5个有量纲的时域特征,5个无量纲的时域特征和6个频域特征.

表3 频域特征参数Tab.3 Frequency domain characteristic parameters
2 字典学习和异常声检测
2.1 字典学习
字典学习模型在过去几十年中备受关注,并已经运用到了包括图像处理、信号还原和模式识别等领域.对于输入的音频特征,当用一组过完备基对它进行表示时,在满足一定稀疏度或者重构误差的条件下,可以得到对原始音频片段的近似表示,即Y≈DX.Y是输入的需要得到稀疏表示的原始帧特征参数,维度为特征维数×样本数,D代表稀疏矩阵,它的每一列称为一个“原子”,X是得到的Y关于D的稀疏表示系数,维度为字典原子数×样本数.其优化目标是在给定的过完备字典中用尽量少的原子来表示信号,得到稀疏的X的问题.此问题可以用以下公式来描述:
(1)
我们需要尽量减小还原后的误差,并使得X尽量稀疏以获得信号更为简洁的表示,降低模型的复杂度.稀疏字典学习包括两个阶段:一是字典构建阶段;二是利用构建好的字典表示样本阶段.字典作为信号的稀疏表示的有效工具,为提取信号隐藏的本质特征提供了更有意义的方式.因此,获得合适的字典是稀疏表示算法成功的关键.在本次实验中,我们选择学习字典法来初始化一个16×256维的离散余弦变换(Discrete Cosine Transform,DCT)过完备字典D,其中16是样本中特征的维数,256为字典原子的个数.然后对原始音频帧特征数据使用正交匹配追踪(Orthogonal Matching Pursuit,OMP)算法进行稀疏表示,得到对应字典的系数矩阵X,接着依据得到的系数矩阵X,利用K奇异值分解(K-Singular Value Decomposition,K-SVD)算法对字典D逐列快速进行更新[10],同时也对系数矩阵X进行更新,并计算重构误差;经过K次迭代或收敛到指定误差内,完成字典D和系数矩阵X的联合优化.
通常情况下,稀疏编码用于异常检测的时候,对于正常的事件样本可以以很小的代价并且以很少的原子构建,而异常事件和任何字典中的基原子都不相似,所以不能以很小的代价构建或者构建后表示系数的稀疏性很差[11].我们正是利用稀疏编码的这一特性,将稀疏系数作为中间步骤输入到OCSVM分类器中,与直接输入原始特征的方法相比,对正负样本的特征区分度更大,可以更好地实现异常事件的检测.
2.2 异常事件检测
在字典学习和稀疏表示阶段结束后,我们利用训练集中正样本Y的稀疏系数矩阵X来训练一个OCSVM分类器.
OCSVM是一种用途广泛的分类器,是一种特殊的二分类器,其训练数据集只包含一种数据集[12].OCSVM分类器可以根据输入的正样本数据点的特征,建立一个正样本模型,并在测试阶段作为判别器使用.对于没有类别标签的数据集,我们可以通过支持向量数据描述(Support Vector Data Description,SVDD)来找到划分的超平面和支持向量机[14].SVDD认为所有不是正常的样本都是异常的,并且在特征空间中划分一个超球体,获得数据周围的球形边界,超球体的体积要求尽量小以最小化异常点数据的影响.OCSVM将输出划分后的标签,如果输入样本在判决边界以内,则输出标签1,否则输出标签-1.整个系统的模型如图1(见 第306页)所示.
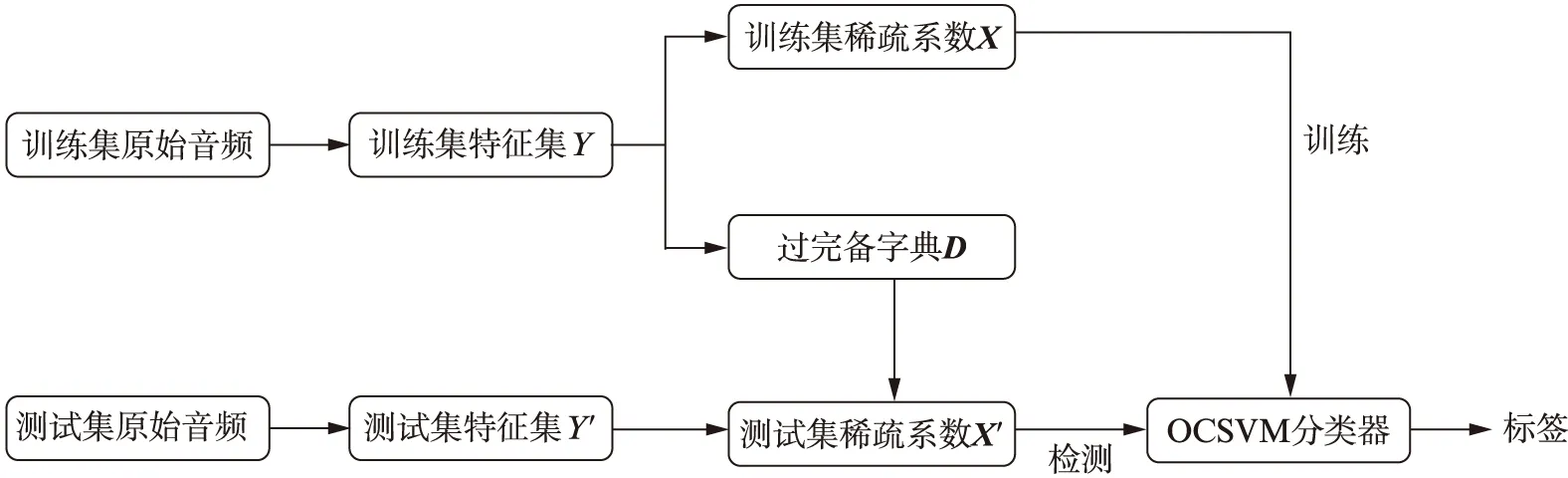
图1 系统模型的框图Fig.1 Block diagram of system model
2.3 后处理
在后处理阶段,我们建立了两种不同的评分方法来获得异常分数:一种是异常帧百分比制;另一种是异常帧连续积分制.
在第1种方法中,分类器对音频的每一帧进行预测,得到1或-1的标签.通过计算所有帧中-1标签的比例来确定最终得分.对于第2种方法,我们遍历这些连续-1标签的帧来计算得分.当计分器第1次遇到-1,就会积1分,如果第2个标签仍然是-1,那么它的得分是2,如果第3个标签也为-1,那么它的分数为4.
以此类推,每一个连续的第i个标签为-1的帧得分为2i-1,最后将这些连续标签为-1的帧的得分叠加求和.直到遇到标签1,前述计分器停止计分,当再次遇到标签-1时,重复前面的过程.计分器公式见式(2)~(4).由此,我们可以得到每一段音频的异常分数Sanomaly,分数越高,这段音频是异常的可能性就越大.
(2)
(3)
(4)
3 实验结果
3.1 实验数据集
本文采用DCASE2020 Challenge Task2提供的两个数据集,分别是微型机器数据集ToyADMOS[15]和工业机器声数据集MIMII Dataset[16].ToyADMOS数据集包含了toycar和toyconveyor两个微型机器的操作声,作者通过故意损坏微型机器来收集它们的异常操作的声音;MIMII Dataset包含了pump,valve,slider和fan这4个真实工业类型的机器声.在训练集中除了toyconveyor只有3个机器ID以外,其他5类机器声都有4个机器ID,每个机器ID下都有几百个音频片段,每个音频片段时长大约10 s,包含了机器声和其他环境噪声.训练集的所有音频片段都只包含正常机器声,不包含异常机器声;而在测试集中,每个机器ID的音频既包含了正常音频也包含了异常音频.
3.2 评价指标
为了评判系统的性能,我们将上述每段音频的异常得分转化为受测者工作特性曲线下面积(Area Under Curve,AUC).AUC是一种传统的异常检测性能指标,它表示随机给定一个正样本和一个负样本,模型预测正样本为正的概率预测大于负样本为正的概率的可能性,我们将它记为ηAUC.ηAUC的值越大,系统性能越好,检测异常的能力越强,其表达式如下:
(5)
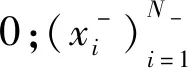
3.3 实验结果
我们通过对不同机型的百分率计分法和连续计分法的比较,选出最优方法,并且对比了本文系统和DCASE2020 Challenge Task2官方提供的使用AE的基线系统(Baseline system),结果如表4所示.

表4 本系统和Baseline系统的结果对比Tab.4 The comparison of results between the proposed system and Baseline system
实验结果表明,基于字典学习的OCSVM系统对fan,pump,valve这几个机器种类上的部分机型的识别效果是明显优于基线系统的,比如机器fan04的AUC从61.61%提升到了82.24%,性能提高了21%左右,机器pump00的AUC从67.15%提高到82.90%,性能提高了15%左右,机器valve02的AUC从68.18%提升到87.90%,性能提高了近20%;但是在两类toy机器和slider上,只有个别机器的效果优于基线系统,大部分的效果比基线系统的要差.
由此可以得出结论:该系统对fan,pump,valve这3类机器上的异常声检测效果较好,可以很好地实现机器异常声检测任务;对于toycar,toyconveyor和slider这3类机器,检测效果不理想,还需要继续改进.
4 结 语
本文针对无监督的机器异常声检测问题,提出了基于字典学习的无监督机器异常声事件检测系统.对于异常机器声数据集少,训练集只有正常样本的问题,使用了异常检测算法中的OCSVM分类器对数据进行分类,并采用字典学习和稀疏表示算法来加大特征之间的区别度,简化分类过程.同时采用更适用于机器声的传统特征参数作为特征集.实验结果表明,对于数据集的一部分机器,如fan,pump,valve这3类机器,该方法有一定的提升作用,对于另外一部分机器,如toy和slider两类机器,效果反而变差.通过观察比较,我们发现数据集中的这几类音频的异常声和正常声的特征分布差别很小,故而在字典学习后的稀疏域上区分不明显,导致OCSVM分类器不能很好地确定区分边界.后续工作将在这方面继续改进,研究可以更易区分正常声和异常声的方法.
