基于优先经验回放的多智能体协同算法
2021-09-21黄子蓉甯彦淞
黄子蓉,甯彦淞,王 莉
(太原理工大学 大数据学院,山西 晋中 030600)
协作是多智能体系统的核心,智能体间通过协调配合可提高团队协作效率且获得更高的利益。深度强化学习结合了深度学习自学习、自适应的能力和强化学习感知试错能力,在多智能体协同中取得了阶段性成果,如星际争霸Ⅱ[1]、交通枢纽任务[2]、飞机编队[3]等。但基于深度强化学习的多智能体协同算法仍然存在经验数据回放、可扩展性和合作性能等诸多方面的挑战。
On-policy强化学习算法中,智能体与环境交互一次获得的经验元组(st,at,rt,st+1)仅利用一次便被抛弃。为了重复利用历史经验数据,DQN(Deep Q-Networks)算法中引入经验回放缓存机制[4-5],将历史数据存入经验回放缓存池中,极大地提高了经验利用率。但先前的工作采取随机采样方式回放经验或仅采样近期经验数据,忽略了经验数据的优先级,这可能造成成功经验很快被遗忘或成功经验较少的问题。SCHAUL et al[6]研究者提出的PER(prioritized experience replay)算法对经验数据进行优先级评估和排序,在采样时选取优先级较高的经验进行模型训练。该算法使重要经验被回放的概率增大,增加了模型采样效率和学习效率。但这种算法仅关注单智能体环境,随着科技的发展,人们不再仅满足于用深度强化学习算法控制单智能体,基于深度强化学习的多智能体协同研究逐步进入人们视野。如何在多智能体环境中有效利用历史经验且提高采样效率和合作性能成为关键研究挑战。
多智能体合作环境中,集中训练分散执行的框架已被证明是处理智能体间合作的有效范式。训练阶段,集中训练的框架允许每个智能体的评判网络使用其他智能体的状态和动作信息,帮助智能体更好地合作。执行阶段,分散执行的框架使智能体仅依赖它自身的观测进行决策。这一范式解决了多智能体环境非平稳问题。当面对连续型环境时,MADDPG(multi-agent deep deterministic policy gradient)算法[7]成为提升智能体间合作性能的代表性方法。MADDPG算法遵循集中训练分散执行框架, 每个智能体有自己独立的Critic网络和Actor网络,Critic网络以所有智能体的观测和动作为输入,解决了多智能体环境非平稳性问题。但当环境中智能体数量增多时,状态动作空间的大小呈指数型增长,造成可扩展性差的问题。且MADDPG算法仅选取近期经验进行回放,使之前的经验被遗忘,经验利用率低。MAAC算法[8]尝试解决上述问题。首先,MAAC算法学习带有注意力机制的Critic网络,注意力机制使智能体动态地选取周边信息,改善了智能体在复杂环境中的合作性能。同时,模型的输入维度随智能体的增长呈线性增长趋势,而非之前工作中的二次增长,一定程度上解决了可扩展性差的问题。其次,MAAC算法采用随机采样的方式进行经验回放,利用了历史经验,但该算法仍忽略了历史经验的重要程度。本文扩展了MAAC算法,提出一种基于优先经验回放的多智能体协同算法(prioritized experience replayfor multi-agent cooperation,PEMAC)。
该算法的主要贡献为:
1) 在多智能体系统中,算法基于TD误差求出每条经验数据的优先级,每次采样均采取优先级较高的经验数据更新网络。PEMAC算法提升了训练数据的质量,从而提升了模型收敛速度和智能体的合作性能。
2) PEMAC算法使用了基于注意力机制的Critic网络学习智能体间的合作,使智能体动态地选取周边信息,一定程度上实现多智能体系统的可扩展性。算法适用于合作、竞争和合作竞争混合的环境。
1 相关工作
深度强化学习已有很长的发展历史。其中,几个关键的研究点为:智能体如何使用历史经验提高经验利用率;智能体如何提高合作性能;面对智能体数量较多的环境时模型的可扩展性等。
针对智能体经验利用率问题,MNIH et al[5]提出的DQN算法引入经验回放缓存机制,将经验元组存入经验回放缓存池中,极大地提高了经验利用率。但其对所有数据均匀采样,忽略了经验数据的重要程度。SCHAUL et al[6]提出的PER算法对经验数据进行优先级评估和排序,采样时选取优先级较高的经验进行模型训练,使高优先级的经验被回放的概率增大,增加了模型采样效率和学习效率。HOU et al[9]学者将PER算法引入DDPG(deep deterministic policy gradient)算法中,进一步提高了DDPG算法中经验回放机制的效率,从而加速训练过程。SHEN et al[10]将TD误差的分布进行分段,然后根据更新后的TD误差对经验进行分类,实现相似经验的交换机制,改变经验池中的经验的生命周期。这一算法降低了经验池大小,节约了系统内存。BU et al[11]提出DPSR算法为经验元组中的旧状态选择新动作,计算新的TD误差,将原始缓存池中TD误差值最小经验元组替换,解决了模型无法选择TD误差较小的经验元组的问题。
针对多智能体合作问题,集中训练分散执行的框架已被证明是处理智能体间合作的一个有效范式。集中训练阶段,智能体的评判网络输入所有智能体的状态和动作,分散执行阶段智能体仅依赖它自身观测和策略网络进行决策,评判网络失效。这一框架中,VDN[12]和QMIX[13]算法学习联合的动作值函数,然后将其分解为智能体自身的值函数,达成智能体间有效的合作。但这些方法仅适用于合作环境,且很难处理大的动作空间的游戏场景,尤其是具有连续动作空间的场景。COMA[14]和CoRe[15]算法使用反事实基线方法推断每个智能体对团队利益的贡献,从而达成智能体间合作。每个智能体的反事实基线是通过比较智能体的联合动作值函数和将其他智能体的动作固定后只改变当前智能体的动作获得的动作值函数得出的。然而这些方法必须为每个智能体所有给定动作都计算一条基线。当智能体数量增多或智能体的动作空间较大时,这些方法将更难训练。且上述方法仅从环境中获得联合奖励,对纯合作环境适用,但对于竞争和合作竞争共存的环境不适用。
MADDPG算法同样遵循集中训练分散执行的框架,该算法中每个智能体都有自身的Actor网络和Critic网络,所以适用于合作、竞争和合作竞争共存的环境。但MADDPG算法仅选取近期经验进行回放,使之前的经验被遗忘,经验利用率低,且模型无法通过经验学习一个智能体间的显式通信,模型的可扩展性较差。MD-MADDPG算法[16]通过引入存储设备,端到端的学习智能体间的显式通信协议,提高智能体的合作性能。SMARL算法[17]提出一种基于Seq2eq序列多智能体强化学习算法,该算法将智能体策略网络分解为动作网络和目标网络两部分,可以适应智能体规模动态变化的环境。BiC-DDPG算法[18]使用双向RNN结构实现信息通信。当智能体合作时,算法采用了一种映射方法将连续的联合动作空间输出映射到离散的联合动作空间,解决智能体在大型联合动作空间上的决策问题。但大多数环境中通信信道、通信协议是不可用的或通信带宽受限制,使智能体间可进行交流的信息变少。MAAC算法扩展了MADDPG算法,学习带有注意力机制的Critic网络,降低模型输入维度,一定程度上解决了可扩展性差的问题。且该算法采用随机采样的方式进行经验回放,利用了历史经验,但该算法仍忽略了历史经验的重要程度。本文基于MAAC算法提出一种基于优先经验回放的多智能体协同算法PEMAC.PEMAC算法为每条经验元组计算优先级,并基于这一优先级选取历史经验,训练Critic网络和Actor网络。
2 基于优先经验回放的多智能体协同算法
现实世界中,智能体往往通过不断试错,从错误经验中学习知识,从而实现某一目标。如人类在学会走路之前经过了无数次摔跤。受这一思想的启发,本文提出了PEMAC算法。该算法利用TD误差评估经验元组的优先级,然后选取优先级大的经验训练Actor网络和Critic网络。同时考虑到智能体和环境交互时会选择性地关注周边智能体中的一些重要信息,这样智能体能更好地做出决策。PEMAC算法在Critic网络部分引入多头自注意力机制,动态地选择其要关注智能体的哪些信息,从而提高多智能体在复杂环境中的交互性能,网络框架如图1所示。

图1 PEMAC算法框架图Fig.1 Architecture of PEMAC
具体地,在经验存储和采样阶段,先初始化所有智能体在t时刻的状态,将状态作为智能体的局部观测o,o=s=(s1,t,…,sn,t),用参数θ={θ1,…,θn}初始化策略网络,策略网络生成策略集π={π1,…,πn},然后智能体根据局部观测和策略集做出t时刻的决策a,a=(a1,t,…,an,t),智能体在状态s,执行动作a,与环境交互获得了奖励r,r=(r1,t,…,rn,t),且智能体转移到t+1时刻状态s′=(s1,t+1,…,sn,t+1).之后将每个智能体的游戏轨迹四元组(si,t,ai,t,ri,t,si,t+1)和经验优先级Pi,t存入经验回放缓存区~U(D).其中经验优先级Pi,t初始时刻均赋值为最大概率1.最后本文从U(D)中选取Pi,t值最大的一个批次的经验作为模型训练数据集。
在模型训练阶段,每个智能体将自己t时刻的状态和动作输入各自评判网络的全连接编码器中,智能体i的编码信息为ei,t,ei,t=gi(si,t,ai,t).gi为一层的MLP编码器。然后对智能体的编码信息进行多头自注意力选取,选取后的信息为(x1,t,…,xn,t).其中,
xi,t=∑j≠iαjvj=∑j≠iαjh(Vej,t).
(1)
式中:V为一个共享的线性变换矩阵,h为非线性函数(本文选取ReLU函数),注意力权重αj为智能体i的信息编码ei,t与线性变换矩阵Wq相乘后得到的键码与邻居智能体j的键码求相似度得到,即:
(2)
接着将智能体i的编码信息ei和其他智能体经过注意力选取后的信息xi,t输入到一个两层的全连接网络fi中,进而得出智能体i的动作值函数Qi,即:
(3)
(4)
(5)
其中α是在奖励值部分加入最大熵后的超参,遵循SAC算法模型。然后可通过TD误差更新智能体i在t时刻的经验元组的采样概率Pi,t,具体地:
(6)
pi=|LQi(ψ)|+ε.
(7)
其中指数σ决定使用多少优先级,当σ=0时为均匀采样。参数μ和β是结合贪婪优选算法和随机选择的优点,保证经验元组的更新概率是单调的,同时也保证了所有经验元组以较高的概率更新经验回放缓存池,而低优先级的经验元组也可以一定概率更新缓存池。ε为正数,防止TD误差逼近0时,经验元组的采样概率逼近于0.此时策略网络的更新变为:
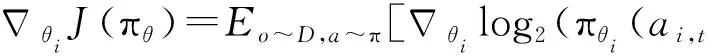
(8)
上述策略网络更新中,PEMAC算法用反事实机制方法解决信度分配问题,即排除其他智能体对当前智能体期望收益的影响。b(o,ai)是反事实基线,为:
(9)
3 实验
奖励(reward)是强化学习中一个重要的评估指标,它指导智能体优化策略且反映了强化学习中任务的完成程度。 为了验证算法的有效性,本章以奖励作为评价指标,分别基于合作寻宝[7]和漫游者-发射塔[8]两种环境进行了实验验证。合作寻宝和漫游者-发射塔环境是完全合作的环境,本文控制环境中所有的智能体。
3.1 实验环境
合作寻宝环境中,我方智能体必须在有限的步长内协调它们的行为尽可能收集到所有宝藏。如图2(a)所示,粉色的大圆代表我方智能体,其他颜色的小圆代表宝藏。我方智能体能观察到其他智能体和宝藏的相应位置。将智能体到宝藏的相对位置作为智能体的奖励。这就意味着,我方智能体必须尽可能地寻找与自己距离最近的宝藏,同时避免与其他智能体到达相同的宝藏处。另外,智能体占据一定的物理空间,当智能体间相互碰撞时会受到一定程度的惩罚。
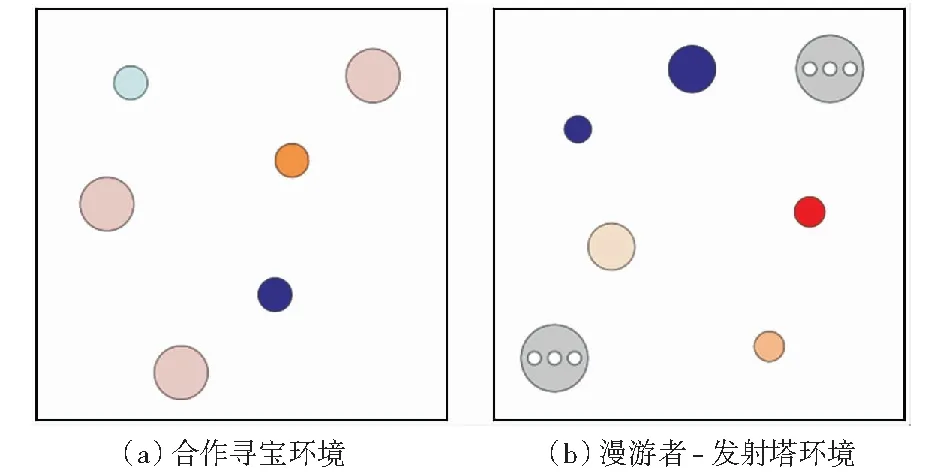
图2 实验环境Fig.2 Experimental environment
漫游者-发射塔环境中总共有2N个智能体,N个为漫游者,N个为发射塔。另外环境中设有N+1个随机地标。如图2(b)所示,灰色智能体为发射塔,大圆表示漫游者,小圆表示随机地标。每次迭代中,漫游者和塔随机配对。漫游者无法探知周边环境和目标地标位置,其必须依赖于发射塔的通信。而发射塔可以定位漫游者的位置以及它们的目标地标。
3.2 实验设置
对于合作寻宝环境来说,为验证算法在智能体数量较多的环境中模型仍适用,本文分别设置了3个合作的智能体和4个合作的智能体。环境中目标地标宝藏的数量与智能体数量一致,即分别选取了3个宝藏和4个宝藏。各个智能体计算它距离各个宝藏的相对距离,然后智能体以距离它最近的宝藏与当前智能体的相对距离的负值作为奖励。但当智能体间互相碰撞时,智能体得到-1的惩罚。
对于漫游者-发射塔环境,本文设置了2个漫游者,2个发射塔,3个目标地标。漫游者以其与目标地标距离的负值作为奖励,发射塔以与其配对的漫游者距离目标地表的距离的负值作为奖励。但当智能体间互相碰撞时,智能体得到-1的惩罚。
另外,本文选取当前运行的进程数+当前运行次数×1 000作为随机种子初始化环境。每轮游戏设置了25个步长。为证明算法有效性,本文中每种算法都在所有环境中独立运行了5次,奖励选取5次运行的平均结果。
3.3 实验结果
为验证PEMAC算法的有效性,本章选取MADDPG算法、MD-MADDPG算法和MAAC算法作为基线模型进行对比试验。表1显示了当模型收敛时,所有环境中智能体所在团队5次运行结果的平均奖励。表中所示结果为未经过平滑的平均奖励和浮动范围。图3显示了3个智能体的合作寻宝环境中,每种算法获得奖励的变化趋势,图4显示了4个智能体的合作寻宝环境中奖励的变化趋势,图5显示了漫游者-发射塔环境中奖励的变化趋势。所有图均为经过smooth函数平滑后的奖励变化趋势图。

表1 模型收敛后合作寻宝和漫游者-发射塔环境中的平均奖励Table 1 Average reward per episode after model converging in the cooperative treasure hunt and the rover-tower environments
表1和图3的结果表明,在合作寻宝环境中,当智能体数量为3时,智能体在局部观测情况下,PEMAC算法的性能优于MADDPG算法8.7%,优于MD-MADDPG算法5.2%,优于MAAC算法2.9%.表1和图4的结果表明,当智能体数量为4时,PEMAC算法的性能优于MADDPG算法8.4%,优于MD-MADDPG算法3.5%,优于MAAC算法1.6%.
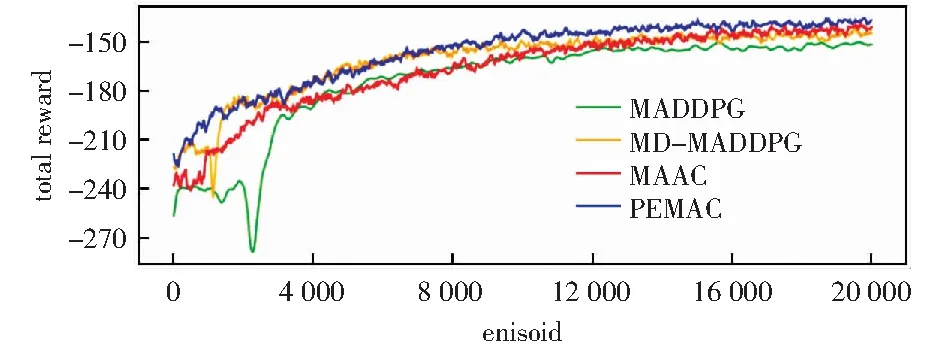
图3 合作寻宝环境中智能体数量为3时奖励的变化趋势Fig.3 Change trend of rewards when the number of agents is three in the cooperative treasure hunt environment
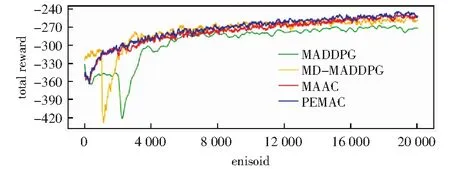
图4 合作寻宝环境中智能体数量为4时奖励的变化趋势Fig.4 Change trend of rewards when the number of agents is four in the cooperative treasure hunt environment
表1和图5的结果表明,在漫游者-发射塔环境中,智能体在局部观测情况下,PEMAC算法的性能是MADDPG算法的118.09倍,是MD-MADDPG算法的204.11倍,比MAAC算法的性能高3.7%.也证明当环境较为复杂时,注意力机制可以使智能体有选择地关注周边信息,从而提升合作性能。
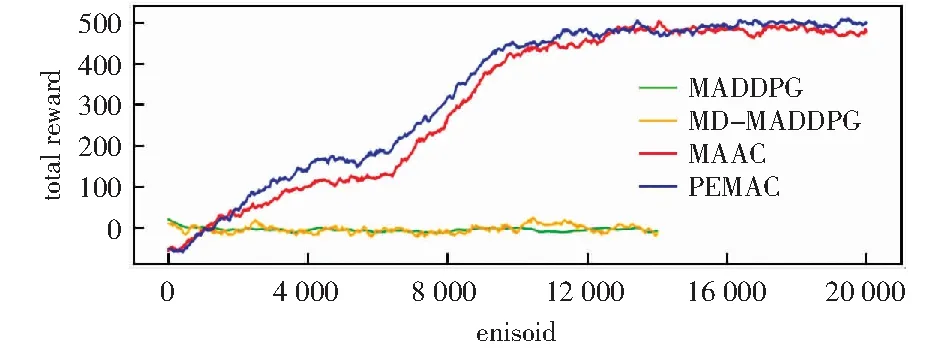
图5 漫游者-发射塔环境中的奖励变化趋势Fig.5 Change trend of rewards in the rover-tower environment
由上可知,PEMAC算法整体性能均高于MADDPG算法、MD-MADDPG算法和MAAC算法。引入优先经验回放,使重要经验被回放的概率增大,学习更有效。智能体可从大量失败经验中更有效地学习到隐藏的成功经验,从而提升算法性能。且由图3、图4和图5可知,PEMAC算法的收敛速度比其他算法的收敛速度快。算法收敛速度由智能体获得相同奖励所需要的运行次数和模型趋于稳定所运行的迭代步决定。另外,由表1和图中的浮动范围可知,当模型收敛后,智能体使用PEMAC算法获得的奖励在平均奖励附近波动范围比MAAC算法波动范围小,因而PEMAC算法可以提高MAAC算法的稳定性。
为了更细粒度地显示注意力机制如何工作,本文对漫游者-发射塔环境中漫游者对所有发射塔的注意力权重进行了可视化分析。如图6所示,流浪者1对与其匹配的发射塔1的关注度高于对发射塔2的关注度。流浪者2对发射塔2的关注度高于发射塔1。经过分析可知漫游者在无法探知周边情况时,学会了关注与其配对的塔,并与塔进行通信,从而提高智能体收益。
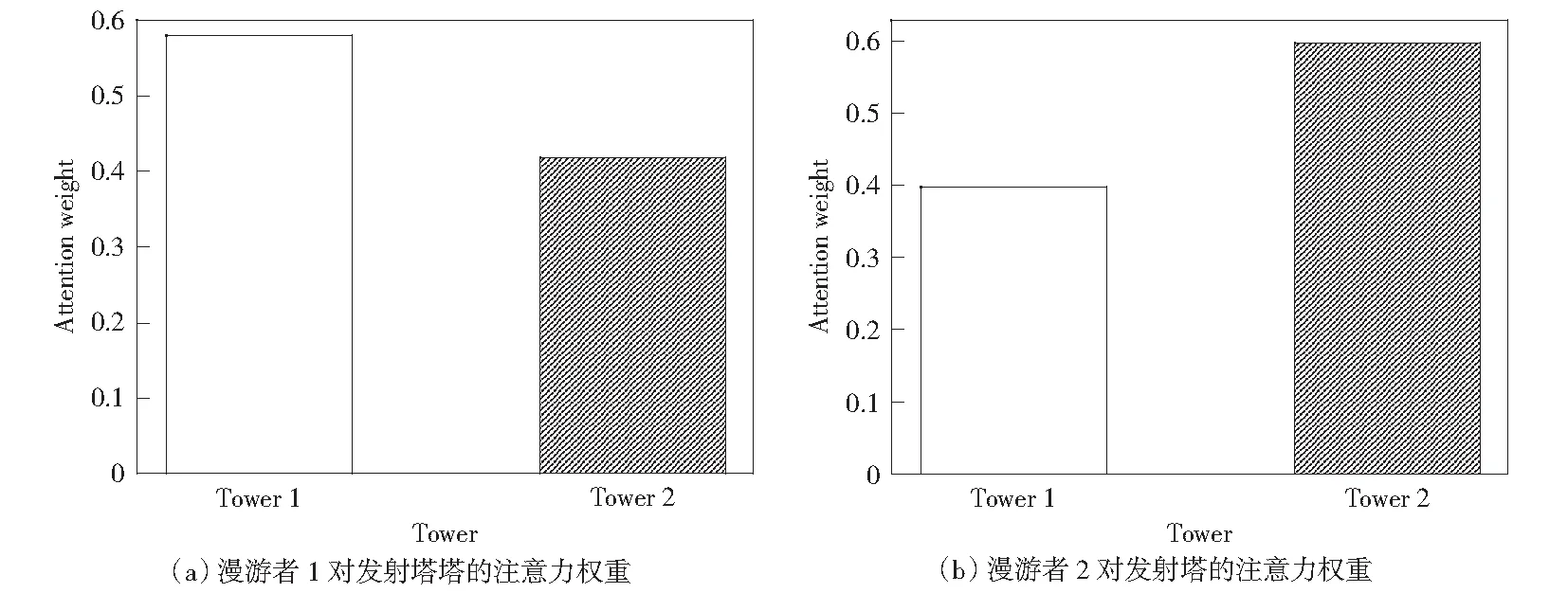
图6 漫游者对发射塔的注意力权重Fig.6 Attention weights over all tower for a rover in rover-tower environment
4 结束语
本文提出基于优先经验回放的多智能体协同算法PEMAC.该算法通过使用优先经验回放机制,从失败经验中学习隐藏成功经验,提升了模型性能,加快了收敛速度和模型稳定性。同时使用注意力机制使智能体可以选择性的关注周边信息,进一步提升了模型性能。最后本文基于合作寻宝和流浪者-发射塔环境对算法性能进行对比验证,实验结果表明PEMAC算法具有较优的合作性能。
本文虽对智能体数量增多时模型性能进行了实验验证,但环境规模仍受限。接下来计划扩展多智能体环境规模和环境复杂度,将PEMAC算法推广到更复杂的环境中。
