集成学习机制下的鼻炎辅助诊断模型
2021-09-20杨晶东孟一飞荀镕基余少卿
杨晶东,孟一飞,荀镕基,余少卿
(1.上海理工大学光电信息与计算机工程学院,上海 200093;2.同济大学附属同济医院耳鼻咽喉头颈外科,上海 200065)
引 言
鼻炎(Rhinitis)是普遍存在的一种呼吸系统疾病,严重影响患者的正常工作和生活。据统计,全球有20%~30% 的普通人被过敏症状困扰,2015年全球哮喘患者已达3 亿人,变应性鼻炎(Allergic rhini‐tis,AR)患者达5 亿人。在患病初期,咽喉有明显干痒感,逐渐变为烧灼与刺痛感。若未及时干预,初期轻症急性鼻炎会转化为慢性重症鼻炎,不仅治疗周期长,治疗效果也难以保证。因此,AR 初期诊断和预防对于后期的有效治疗和控制具有重要意义。
近年来许多学者将机器学习算法应用于鼻炎诊断[1],辅助医生提高鼻炎诊断效率。Demirjian 等[2]采用改进贝叶斯理论对AR 发生概率预测,证明了免疫球蛋白(IgE)和嗜酸红细胞(Eosinophil)是一种重要影响因素。李少华等[3]采用层次聚类分析,得出5 种鼻炎常见病症与其特征相关性。黄嘉韵[4]提出了建立CART 决策树和使用关联规则算法对鼻炎5 种症型建立了辅助诊断模型,并发现了一种对症治疗规律,具有较好的准确率和可解释性。
文献[5]采用遗传编程算法(Genetic programming,GP)对多种医疗病症自主分类,通过将原始数据输送进GP 模型,并自主选择训练特征,分类准确率超越了决策树和贝叶斯方法。但GP 模型训练过程不具可解释性,不能直接应用于风险较高的诊断和临床研究。Liu 等[6]提出了采用自动超参数优化(AutoHPO)深度神经网络模型(DNN)解决医疗数据类别不平衡问题,总体精度上优于随机森林(RF)和AdaBoost 算法。机器学习算法应用于AR 诊断过程,虽然取得了较好的效果,但仍存在方法局限性,如样本数量不均衡[7]、数据属性缺失、维度过高等问题[8]。
样本不均衡问题常出现于临床样本诊断过程。模型分类更偏向多数类样本,导致多数类分类精度过高,少数类精度过低。而临床医学中往往更关注少数类的分类精度,如罕见病的漏诊率或误诊率。解决样本不均衡问题通常包括数据采样、算法适应[9]和特征选择[10]等方法。过采样方法包括随机过采样和启发式过采样[11],采用增加少数类样本,与多数类平衡,但容易增加无效样本。欠采样方法包括随机欠采样和基于最优子集搜索欠采样[12],通过减少多数类样本,与少数类样本平衡,但容易丢失样本重要特征。混合采样方法采用先合成样本、再剔除噪声,综合考虑欠采样和过采样方法特点。代价敏感学习采用向损失函数引入代价敏感学习因子,判断少数类与多数类错分代价。当多数类被错分时,损失函数增加;少数类被错分时,损失函数减少,从而提高少数类样本的分类精度。还有一些学者引入集成学习方法解决样本不均衡问题。如在过采样或者代价敏感学习方法中融入集成学习的基分类器,如代价敏感学习boosting 方法AdaCost[13],或过采样bagging 方法SMOTE[14]。此外在不均衡样本集上做特征选择也能有助于提升模型分类能力。通过选择去除掉冗余特征,保留典型的特征子集。Ksiazek 等[15]在不均衡肝细胞癌诊断中采用了遗传算法(GA)实现了特征筛选和模型参数优化,具有较好的分类精度。综上所述,本文构建一种异质集成分类模型实现AR 多输出分类。本文主要贡献如下:
(1)提出一种异质集成分类模型,实现不同证型鼻炎样本的多输出分类,提高了少数类样本的分类精度。
(2)根据鼻炎样本分布,设计一种不平衡度计算方法,增强样本均衡化,降低类别不平衡对分类的影响。
(3)提出一种自适应超参数优化方法,动态搜索集成RFs 数量和深度,提高最优超参数搜索效率。
1 分类模型框架
1.1 基于包外估计的多类别分类
Easy ensemble(EE)[16]是一种对不均衡样本实现均衡分类算法,将欠采样技术和集成学习相融合,通过多次随机采样,充分利用单次欠采样外的遗漏数据,使训练数据集均衡化。本文变应性鼻炎病症有分度、分型两类输出,属于多类别分类问题。采用基于包外估计(Out‐of‐bag,OOB)EE 集成分类算法OOBEE,将全部样本作为训练数据,采用Extra‐tree(ET)模型作为基分类器,对所有训练数据均衡化处理,实现对不平衡小样本预测。OOBEE 算法流程图如图1 所示。OOBEE 从多数类中抽取与少数类相等的样本,并组合重复使用的少数类样本构建多组基分类器,通过加权投票方法获得集成分类器,以减少样本不均衡对分类的影响。

图1 集成学习OOBEE 算法流程图Fig.1 Flow chart of integrated learning model of OOBEE
该方法数学描述为:假设训练样本集Sr={(x,y) },做T次欠采样,采用Bootstrap 随机采样法从多数类样本集中得到一个子集,并且数量和少数类样本相同,使用ET 算法对训练多组个体模型。

式中:hk,j(x) 为第j个ET 子分类器,αk,j为hk,j(x) 权重,θk为子训练集的实际类别。ET 中随机分裂特征数为m,由全体训练样本的计算得出。m依据特征重要程度(Variable importance,VI)选取

式中:oob1代表所有鼻炎测试样本,oob2代表加入噪声的测试样本。最终模型描述为
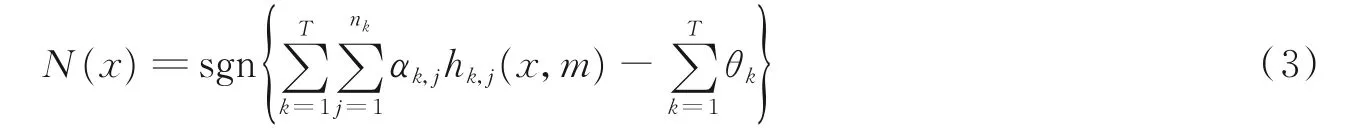
由于AdaBoost[17‐18]对小样本噪声敏感,难以获得最优解,因此不适合分析可能存在的少量错误样本。RF 算法仅采用全部样本的36.78% 作为包外估计,损失了部分训练数据,ET 算法是随机选择最佳分叉属性和特征分裂数,将全部样本作为训练或包外估计OOB。该方法采用ET 算法作为基分类器,使集成分类器方差更小,在小样本分类中具有更好的泛化能力,同时有利于提升鼻炎样本分度和分型的准确率。因此,本文采用ET 算法作为多类别分类的基分类器。
1.2 基于动态加权RF 多标签分类
常见鼻炎样本包括变应性鼻炎(AR)、鼻窦炎(RS)、上呼吸道感染(URI)和其他(OTH 含鼻息肉,鼻腔肿瘤等),鼻炎预测属于多标签分类。常采用样本拆分法,选择RF 作为基分类器[19],将多分类转化为多个单标签二分类。通过调整RF 深度、分裂特征数,减少模型过拟合和降低特征维度。但标准RF算法基分类器参数需要人为设定。本文提出了一种自适应集成森林ARF 算法,根据样本不平衡度,动态调整RF 数量和深度,提高多标签分类精度和效率。传统的不均衡度(Ib)是少数类样本数量Nl与多数类样本数量Nm的比值。

该比值越接近0 说明样本越不均衡,越趋近于1 说明样本越均衡。但该方法无法直接应用于多类别分类,因此,本文针对鼻炎样本不均衡特性,设计不均衡度计算公式,假设全体样本个数为n,每个类标中不同种类出现频率为fj,类别个数为ci,每一类不均衡度bi计算公式为
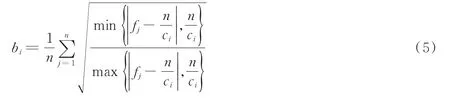
图2 描述了当样本数据为100 时,二分类时不均衡度能力曲线。可见本文方法与改进的经典方法[20]不平衡度接近,但当样本类别数量趋于平衡时,本文方法比经典方法收敛更快,说明本文的不均衡度对不均衡样本更加敏感。图3 给出了三分类时不平衡度评价能力等高线,样本总数为100,横轴和纵轴分别代表两个分类样本数量,第三分类样本数量由总数与前两类之差表示。可观察到(33,33)点不均衡度最低,而越向外围发散,不均衡度越高,等高线内部变化率也高于外围,说明本文不均衡度计算方法对于多分类的不均衡样本的敏感度较高。
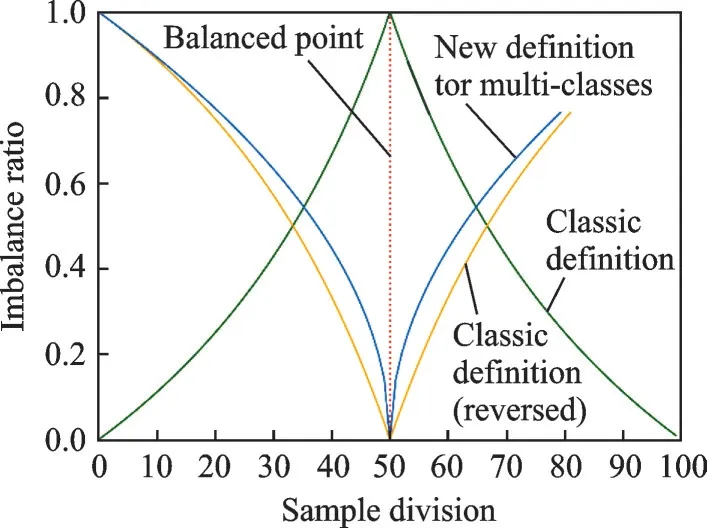
图2 不均衡度在二类别样本中的比较Fig.2 Comparison of class imbalance ratio for binary classes
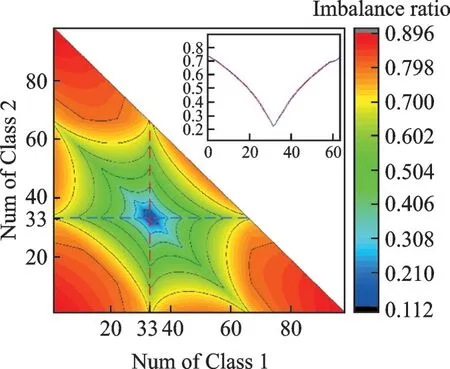
图3 不均衡度在三分类样本中分布Fig.3 Distribution of class imbalance ratio for three classes
本文采用自适应超参数优化ARF 方法,动态调整RFs 参数,其中基准参数s(e,d)为固定值,基分类器数量e和深度d均需搜索确定。本文通过动态网格搜索法获得多类别均衡化过程参数。在网格搜索过程中,RFs 算法阈值范围为e=[10,300];d=[1,15]。图4 给出了ARF 算法参数与精度动态关系图。分析可知,基分类器深度对精度影响较大,d=12 时分类精度最好,基分类器数量对分类精度影响较小,但e=[10,50]过程中分类精度出现了一个较明显提升,说明当e< 60,对分类精度影响较大。经多次测试后,参数设定为e= 70,d= 12。因此,ARF 算法可以有效调节内嵌集的基分类器数量与训练时间的均衡,动态获得集成分类器最优精度时的基分类器匹配参数。
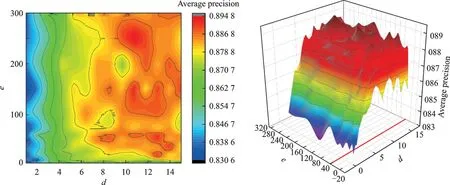
图4 ARF 模型参数与精度动态关系图Fig.4 Dynamic relationship diagram between model parameters and accuracy
ARF 模型采用RF 作为基学习器,采用等权重随机采样法生成训练集,每个基学习模型以等权重投票方式分类。假如一个模型测试集为X,类别数为c,基分类器数为m,则模型输出可表示为
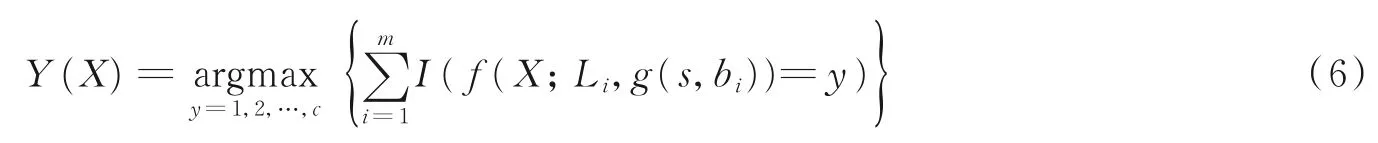
式中:f为指示函数,L为随机参数,g为基分类器RFs 动态搜索函数,函数I为真则输出1,若为假则输出0。
鼻炎证型有4 种标签分类,分别为变应性鼻炎(AR)、鼻窦炎(RS)、上呼吸道感染(URI)和其他(OTH 含鼻息肉,鼻腔肿瘤等)。鼻炎样本的多标签分类ARF 模型如图5 所示,图中总样本集分为4 组证型子集,4 种分型鼻炎样本根据CIR(Calculation of imbalance ratio)值确定二分类的样本子集BS(Balanced sets)分布,分别输入到4 组RFs 鼻炎证型分类模型中。模型每次运行会输出预测结果与RFs包外误差,当包外误差满足优化终止条件时,可输出当前预测结果。
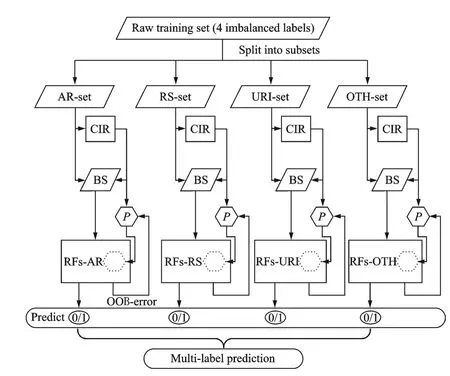
图5 ARF 算法流程图Fig.5 Flow chart of ARF model
1.3 异质集成结构的多输出分类模型
多输出分类是指从一个输入产生多个离散输出的分类模型,马忠臣等[21]总结了多输出分类类型,包括多标签分类、多输出有序分类、异质多输出分类(Heterogeneous multi‐output,HGMO)。鼻炎样本包含4 组常见的多标签鼻炎类型,每组又分度、分型。因此,鼻炎样本属于HGMO 分类,其数学描述为
假设分类问题的输出空间包含m( ≥2 )维多输出变量Y1,…,Ym,分类目标是寻求目标函数h,使其准确学习每个输入x在m维输出变量上的相应输出y=(y1,…,ym)
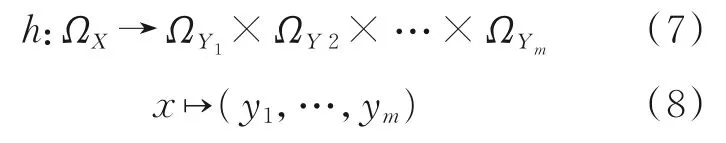
式中:输出变量Y1,…,Ym具有不同类型,yj∈ΩYj,|ΩYj|≥2;ΩX和ΩYj(j= 1,…,m)分别表示输入和输出变量所属值域。
根据HGMO 结构,本文提出了异质集成鼻炎分类器模型ARF‐OOBEE 识别多种证型鼻炎,如鼻窦炎(RS)(二元变量),变应性鼻炎(AR)严重程度或持续性(有序变量)等。图6 描述了ARF‐OOBEE 模型示意图。该模型通过将HGMO 问题转换成4 标签二分类问题(Multi‐la‐bel cassification)和2 个多类别分类问题(Multi‐class classification)。这样可有效避免多标签类型分类与多类别症状分类相互干扰,避免一个患者同时出现两组或更多的分度或分型标签。采用多种模型分别训练组件分类器,利用集成学习获得最终分类器。
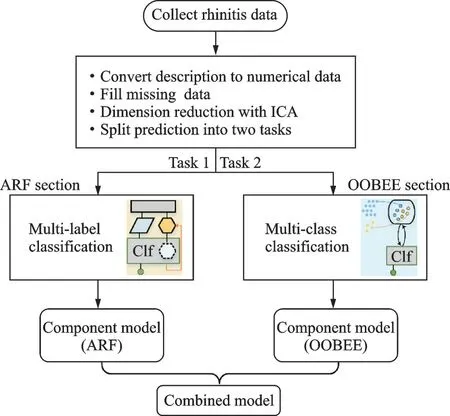
图6 ARF-OOBEE 模型结构框图Fig.6 Structure block diagram of ARF-OOBEE model
图6 左分支描述了动态随机森林方法ARF。ARF 根据子数据集中单一类标的不平衡度,自动调节集成森林的群数和森林内的基分类器数。当出现均衡子标签时,减少森林群数,计算速度最优的单森林内的基分类器数量;当出现非均衡的子标签时,增加森林群数;最终根据验证集算出集成森林权重。ARF 更有利于提高分类的准确率和均衡性,并通过动态增减训练集不均衡样本数量,实现速度与精度的动态均衡。图6 右分支描述了OOBEE 集成分类算法。该方法采用ET 算法替代Adaboost,将全部样本作为包外估计,充分利用所有训练样本,通过欠采样集成学习方式处理多分类任务中的样本不均衡问题,避免了对不均衡样本的重复判断、少数类样本特征过于稀疏等问题,提高模型的泛化能力。
2 实验结果与分析
2.1 数据预处理
采用上海同济大学附属同济医院临床鼻炎样本461 例,其中男性261 例(占56.62%),平均年龄(30.48±19.66)岁;女性200 例(占43.38%),平均年龄(33.51±19.32)岁。样本含有多种数据类型,包括患者信息(性别,年龄等),医生问诊结果(是否流涕,何种变应原等),检测仪器信息(CT,IgE 等)。由于输入数据源种类多,数据类型不唯一,如果采用简单的剔除缺失值样本会使样本大量减少,不利于鼻炎病症预测。本文采用了混合型缺省值填充方法,对于患者个人信息采用K 近邻[22]填充相似数据均值;使用了众数插补方式填补问诊数据缺失值;对于仪器测量数据,将缺失值作为一种标签,建立RF 模型,得到预测值之后进行填充。
鼻炎诊断可设定为6 组类别,包括4 种病症标签,AR 类型2 种症状类别(分度或分型),数据呈不均匀分布。因此,本文采用独热编码。表1 和表2 分别描述了鼻炎标签分布及不平衡度数据和鼻炎类型分布,AR 标签中阳性占比较大,RS、URI、OTH 阴性占比较大,Severity 类型中轻症样本较多,中症次之,重症最少,Duration 类型中间歇性样本较多,持续性较少,可见鼻炎AR 样本最多,非AR 为30 例,仅占总病例6.5%,却包含3 种病症标签,说明鼻炎样本分布极不均衡。鼻炎样本标签数及病历分布分别如图7、8 所示,每个病例含1~5 个输出,病例分布数量总计461 例,分别为24、6、330、95、6。对于前4 组标签型预测项,每类病历表现出阳性数量有1~3 个标签,其中单证候病例354 例,占总病例76.79%;兼证病例110 例,占总病例21.91%;三证合一病例6 例,占总病例1.3%。

图7 预测输出的数量分布Fig.7 Distribution of prediction output

表1 鼻炎标签分布及不平衡度数据Table 1 Distribution of rhinitis labels and its class imbalance ratio
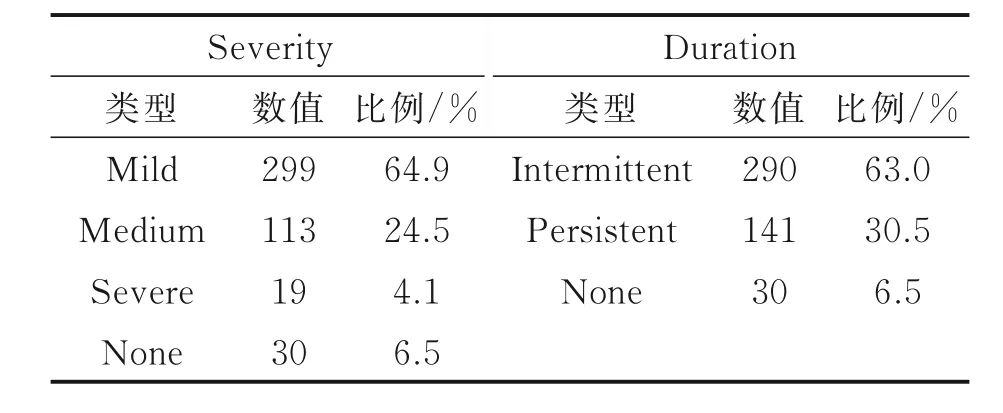
表2 鼻炎类型分布Table 2 Distribution of rhinitis types
表3 给出了针对原始鼻炎样本,采用多种不平衡度计算方法对比数据,包括过采样均衡化SMOTE 方法[23],ADASYN 方法[24],欠采样均衡化All‐KNN 方法,原始样本不平衡度(RAW)以及本文方法ARF‐OOBEE。可以看出,原始数据不平衡度最低为分度Severity,占比55.53%,最高为AR,占比为90.98%,说明所有待预测样本输出值均为不均衡。采用ADASYN 和SMOTE 方法对Types预测值做均衡化处理后,与AR、Severity 和Duration 相比,不均衡度至少降低0.403 5,但是RS、URI、OTH 不均衡度无明显变化,RS 标签上的不均衡度提高了0.085 8。同样,采用SMOTE 方法对URI 标签均衡化后,URI 不均衡度降为0,但RS、OTH 不均衡度分别增加0.043 7、0.040 1。采用All‐KNN 欠采样后具有较高不均衡度(>0.6)。由此可见,常规类别均衡化方法仅能在指定标签上具有较好的效果,无法对多输出样本做整体均衡化。而本文方法ARF‐OOBEE 将6 组不均衡多标签分类问题转化为4 组二分类和2 组多分类问题,并在组件分类模型中分别实现样本均衡化处理,较好地解决了多输出分类中样本不均衡问题。
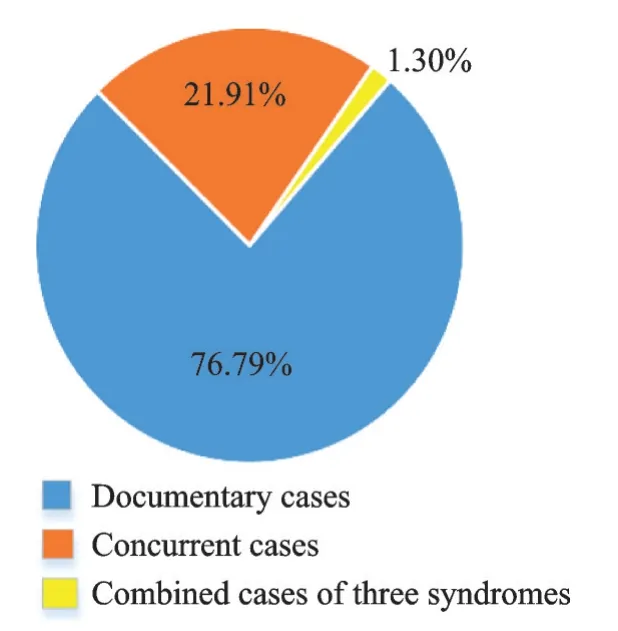
图8 鼻炎病历分布Fig.8 Types of rhinitis among patients
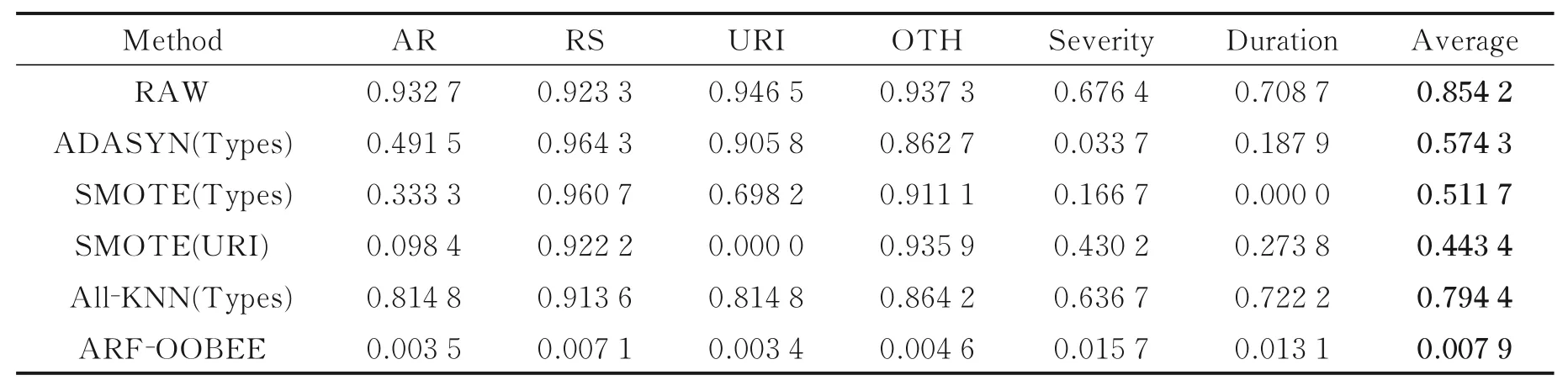
表3 各算法样本不平衡度b 对比Table 3 Comparison of class imbalance ratio b for different methods
2.2 维归约处理
鼻炎预测模型的原始输入特征数为66,具有不同来源的组成和数据类型。如果不做特征降维处理,会增加训练时间、噪音干扰和模型复杂度。常见特征降维方法有主成分分析法(PCA)[25],核主成分分析(KPCA),独立成分分析(ICA)[26],线性判别分析(LDA)[27]等。
本文采用4 种特征降维方法FastICA,PCA,KPCA,LDA 来对比分析,其中FastICA 方法将原66维特征降至25 维;PCA 将原特征数量降至33 维,LDA 方法则将原特征数量降至10 维,KPCA 方法将原特征降至54 维。本文使用RF 算法对样本分类,根据分类后ROC 曲线面积AUC 值评估各算法降维效果,表4 给出了上述4 种降维算法后AUC 值,发现FastICA 方法效果最佳,达到了0.929,相较于PCA 算法最大提升了5.6%。

表4 各种降维方法效果对比Table 4 Comparison of effects of vari⁃ous dimensional reduction methods
本文采用安德森‐达令检验方法(Anderson‐darling test)检验鼻炎样本分布,如图9 所示。假设鼻炎样本服从正态分布,当显著性水平α= 0.05 时,特征临界值Critical value = 0.746,而各特征统计量(Sta‐tistic)均大于临界值,因此拒绝原假设,即样本不服从正态分布。而经典降维方法PCA 和LDA 均符合正态分布样本。由此可见,本文采用FastICA 算法对AR 样本进行降维处理,该方法更适用于处理非高斯分布样本,计算简单、要求内存小、收敛速度快,且具有神经网络并行性、分布性等特点,能够从多变量统计数据中发现抽象的、本质的因素或成分。
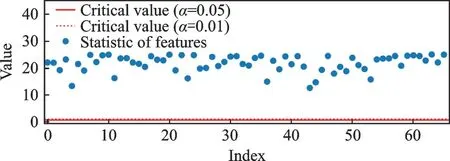
图9 原始样本的Anderson 正态分布检验Fig.9 Anderson normal distribution test of the original sample
2.3 评价指标和对比实验
为评价AR 样本预测结果,选择混淆矩阵综合指标:真阳性(TP),假阴性(FN),假阳性(FP)和真阴性(TN)。并使用临床常用性能量测统计参数:精确度(Precision),灵敏度(Sensitivity),特异性(Spec‐ificity),G‐Mean,F1,ROC 曲线面积AUC 等作为预测评估指标[28]。

本文采用6 种典型集成学习分类算法进行对比实验,包括深度森林(GCForest)、堆叠集成(GA‐Stacking)、代价敏感提升树(AdaCost)、随机森林(RF)、极端随机树(ET)和极端梯度提升树(XG‐Boost),参数设置如下:
(1)GCForest 算法将两个随机森林(RF)和两颗极端随机树(ET)作为基分类器,添加进级联层中,其中每个基分类器的子树设定为100 棵,最大深度12。
(2)GA‐Stacking 算法由遗传算法进行特征筛选,采用两点交叉,单点变异,概率均为0.8,种群规模100,迭代200 次;堆叠第一级集成了RF、AdaBoost、梯度提升树(GBDT)、ET、支持向量机(SVM)和XGBoost 这6 种分类算法,使用10Fold 分割训练数据;堆叠第二级采用逻辑回归(LR)对第一级输出预测训练。
(3)AdaCost 算法为AdaBoost 改进算法,集成了50 个基分类器,代价参数为1.25。
(4)RF 算法内部由150 棵决策树构成,每个决策树最大限制深度为12,叶节点最小分裂数为2。
(5)ET 算法参数设置同RF。
(6)XGBoost 算法采用200 个基学习器,学习率0.01,最大限制深度12。
2.4 集成模型性能分析
本文采用ARF‐OOBEE 模型与6 种典型方法对比,分别将6 类鼻炎样本按比例、随机有回放地分层划分训练集与测试集,并进行12 次交叉验证,训练集与测试集比例为7∶3,并分析模型评估指标均值与方差。表5 给出了多种方法综合预测指标,可以发现ARF‐OOBEE 算法F1 值为78.3%,均高于其他6种算法,其中相较于集成学习GCForest 算法,F1 值提升了3.2%,ARF‐OOBEE 算法G ‐Mean 值为79.9%,高于其他6 种算法,相较于集成学习方法XGBoost 提升了1%,表明集成学习方法可以有效地提升不均衡样本分类性能。GCForest 算法具有复杂的串联结构,但对于不均衡的鼻炎样本,与RF 算法相比,GCForest 算法灵敏度提高了2.4%,G‐Mean 提高1.1%,而精确度降低了4%,这说明仅仅通过增加集成复杂度,无法提升AR 的分类精度,同时还会增加模型总体训练时耗。本文提出模型准确率、F1值、灵敏高于其他集成分类模型约2%~3%。说明ARF‐OOBEE 模型具有自适应特性,可以动态改变集成基分类器数量,对于数据不均衡样本具有较好的综合分类性能。
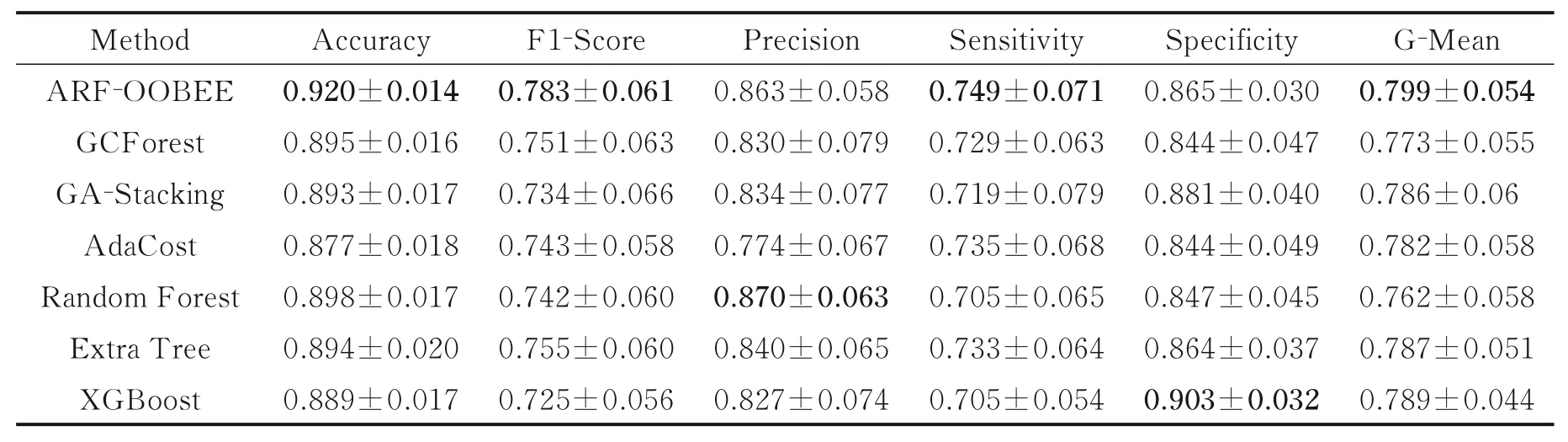
表5 多种分类方法的综合评价指标Table 5 Comprehensive evaluation indicator of different classification methods 100%
表6 给出了针对原始样本6 类鼻炎病症数据独立分类评价指标。数据分析可知,针对多标签分类鼻炎病症AR、RS、URI、OTH 预测准确度较高(>90%),而多分类鼻炎病症Severity、Duration 分类准确度较低(<90%)。这是因为前者ARF 模型是二分类输出,后者OOBEE 模型是多类别分类。两者基分类器均为决策树,但是与多标签二分类相比,多类别分类模型中决策树分裂次数更多,分裂机制更复杂,因此,ARF 多标签二分类精度高于多类别分类。此外,AR 特异性值仅为59.3%,比其他病症类型明显偏低,这是由于AR 型样本不平衡度(93.27%)过大,而ARF‐OOBEE 算法会自适应均衡化鼻炎AR类的非均衡样本,导致一部分AR 样本没有参与样本子集训练,使AR 二分类特异性降低,模型会将较少的阴性患者诊断为阳性,导致误诊率升高,但提高了AR 多标签二分类的其他评估指标。在实际临床中,可以通过医师二次核查排除,从而提升AR 特异性,有效地降低鼻炎误诊率。
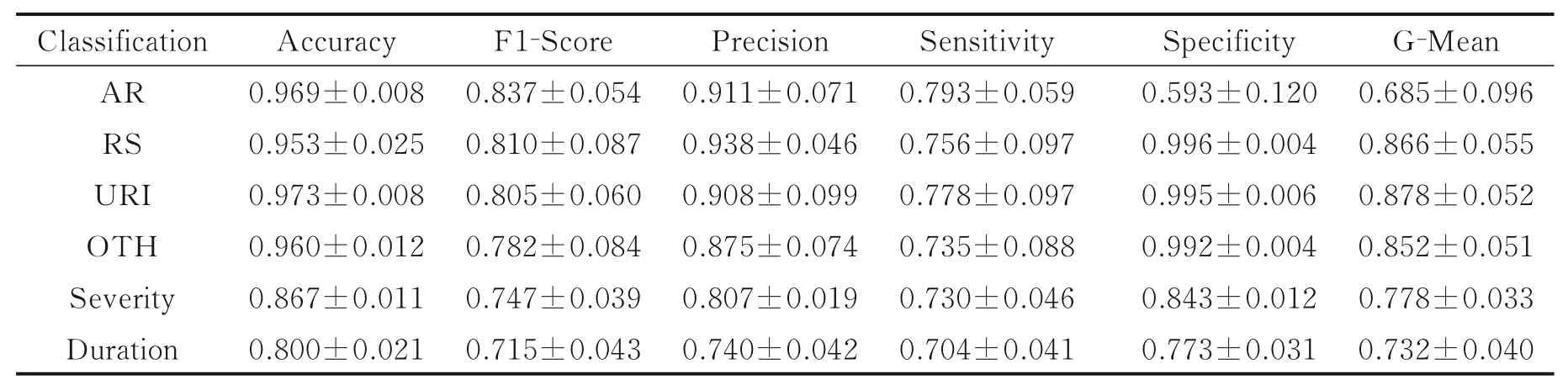
表6 ARF⁃OOBEE 算法各分类预测评价指标Table 6 Evaluation Indicator comparison of ARF⁃OOBEE for different classes 100%
图10 和图11 分别给出了本文ARF‐OOBEE 方法与6 种典型分类模型ROC 和PR 曲线数据统计。由图10 中可以看出,蓝线曲线ARF‐OOBEE 算法从(0,0)点快速上升,增幅大于其他6 种方法,说明正例样本检测精度较高。ARF‐OOBEE 算法AUC 面积为0.953,均高于其他算法,比GCForest 算法提高1.4%,比RF 提高2.4%。由于ROC 曲线对数据的不均衡分布不敏感,因此本文还采用了PR 曲线作为辅助参考。PR 曲线Precision 和Recall 值都关注正类样本检测率。如图11 所示,ARF‐OOBEE 模型PR曲线位于所有方法曲线的最外围,数据变化平缓,与横轴面积超过了其他6 种曲线,其中mAP=0.895,比典型集成GCForest 算法多0.5%,比RF 算法多2.2%,说明该模型具有较高的查准率和查全率,样本不均衡对分类影响较小,因此,本文鼻炎预测模型ARF‐OOBEE 具有较好的泛化性能。

图10 多种分类器ROC 曲线对比Fig.10 ROC curve for comparison different classifiers
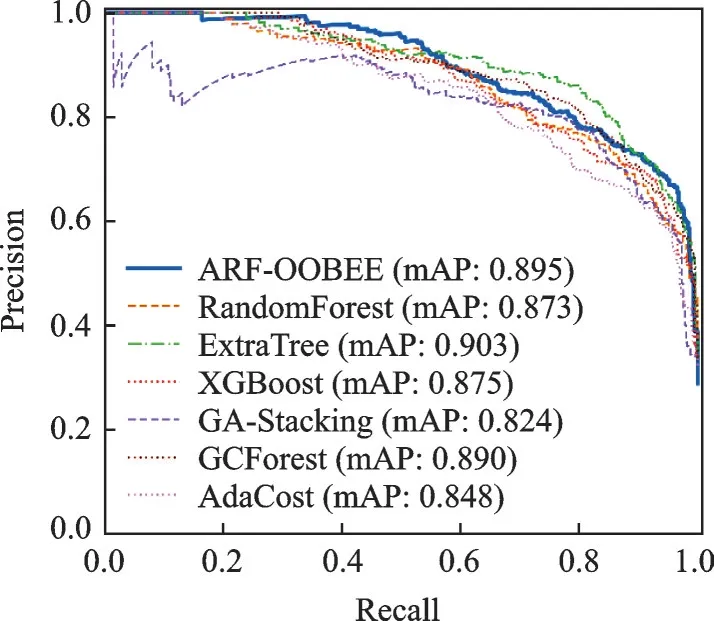
图11 多种分类器PR 曲线对比Fig.11 PR curve comparison for different classifiers
3 结束语
针对临床鼻炎样本高维度、不均衡、稀疏特征,本文构建一种异质集成分类器,采用一种有效的不平衡类分析方法,设计自适应动态子分类器,对多类型、不均衡鼻炎样本实现多输出分类。该方法可快速均衡化鼻炎样本,提高多数类和少数类分类精度。本文算法训练时耗低于GCForest 算法,但高于RF算法。LR、NB 两种算法分类精度与上述集成方法相似,但训练时耗较低。以后工作考虑对ARF‐OO‐BEE 模型自适应参数搜索算法中增加LR 基分类器,减少训练时耗。由于ARF‐OOBEE 模型中含有异质基分类器的并行计算,可以通过对多核处理器的优化来提高模型训练的运算效率和分类精度。
