基于迁移学习的离心鼓风机故障预警方法
2021-09-16李聪波蒋立君
李聪波 王 睿 张 友 蒋立君 孙 皓
1.重庆大学机械传动国家重点实验室,重庆,4000442.重庆通用工业(集团)有限责任公司,重庆,401336
0 引言
离心鼓风机作为典型的旋转流体机械,是能源、环境等领域不可或缺的关键设备[1]。离心鼓风机结构复杂、子系统繁多,加之运行在高温、高粉尘等恶劣环境下,极易出现设备劣化现象,导致设备故障停机,造成严重损失。使用多种传感器对设备运行过程进行监控,从监测数据中挖掘隐藏的设备健康信息,实现离心鼓风机故障的准确预警,从而及时安排维修以避免设备故障发生,具有重要的学术价值和现实意义。由于故障样本不够丰富、故障数据缺乏等原因,设备故障预警模型通常使用设备正常运行时的监测数据建立,使用多项式回归[2]、状态估计[3]、高斯混合模型[4]、证据K最邻近[5](evidential K-nearest neighbor,EKNN)、主成分分析[6]等方法建立正常运行状态监测数据的估计模型,然后基于模型估计值和实际观测值提出故障预警指标计算方法,最后通过数理统计方法或人工经验等为预警指标设定阈值。在实际预警中,将实时监测数据输入模型得到估计值,然后计算出预警指标并判断是否超过预警阈值,当超过时,表示设备偏离正常状态,需要及时发出预警信息。
以上预警方法难以处理海量高维数据,而自编码(autoencoder,AE)模型擅长从海量数据中挖掘有效信息,越来越多的学者将其用于故障预警中。CHEN等[7]用风力发电机正常运行数据训练多层级加噪自编码网络,将网络输入向量和输出向量之间的马氏距离作为故障预警指标并确定预警阈值,实现风力发电机故障预警。WANG等[8]使用重构的玻尔兹曼机初始化和反向传播微调完成深度自编码网络的搭建,通过数理统计方法确定重构误差的预警上下限,实现风力发电机叶片破损预警。李晓彬等[9]引入一批标准化算法优化堆叠自编码网络,提出将相似度作为预警指标,通过人工经验划定预警阈值实现磨煤机故障预警。RENSTROM等[10]使用风力发电机数据采集与监视控制(supervisory control and data acquisition,SCADA)系统的监测数据,研究自编码网络超参数对网络性能的影响,提出一种超参数选择策略建立自编码故障预警模型,实现风力发电机整机故障预警。ALFEO等[11]将自编码模型用于制造设备异常的监测,通过八个案例验证了该自编码模型在异常预警方面优于孤立森林(isolation forest,IF)模型。
自编码网络在一定程度上实现了设备故障的预警,但仍然存在以下问题:①由于数据远程传输和现场噪声影响,工厂实际运行环境下采集的离心鼓风机数据具有较高的噪声水平和较多异常值,极易导致自编码对无关信息进行学习,严重影响模型挖掘设备监测数据的相关关系和隐藏特征,极大降低模型的准确度;②现有研究通过人工经验判断数据采集时段设备是否正常运行,主观性较大,极易将故障状态数据纳入正常运行数据,而当训练样本中含有异常情况数据时,会导致异常识别的准确性和有效性下降[12]。迁移学习能将源域的数据、知识或模型,经过一系列迁移流程后应用到相关的目标领域,从而提高目标域模型性能,在变工况故障预警[13]和刀具寿命预测[14],不同种机械设备[15]、工况[16]、运行环境下[17-18]故障诊断等机械领域取得成功应用,因此,将实验室建立的高精度模型迁移后,用于工厂实际运行环境下离心鼓风机故障预警,提高预警准确度是可行的。
离心鼓风机制造完成后,需要在实验室进行试车测试后再投入工厂使用,基于实验室数据的故障预警模型难以复用于工厂实际运行环境。为此,本文提出一种基于迁移学习的离心鼓风机故障预警方法,基于源域(实验室条件)数据集建立源域模型,通过迁移学习对源域模型进行调整,快速构建目标域(工厂实际运行条件)模型,实现工厂实际运行环境下设备的准确预警。
1 基于迁移学习的自编码模型建立
迁移学习能够将源域知识或模型迁移到相关的目标域中,提高目标域模型精度[19]。实验室能够模拟设备在各种工况下的运行情况,包括各种极端工况,收集到丰富的设备正常运行数据,而工厂环境下,采集的数据噪声水平较高。将离心鼓风机实验室采集的设备运行数据Ds视为源域数据,工厂的实际运行数据Dt视为目标域数据,则它们可以分别表示为Ds={Xs,P(Xs)}、Dt={Xt,P(Xt)},其中P(·)为数据的概率分布。由于数据分布差异较大,源域数据不能直接用于建立目标域自编码模型,因此,本文提出一种迁移学习方法,实现源域模型向目标域迁移,提高目标域模型精度。
1.1 源域模型建立
源域模型建立流程如图1所示,考虑采集的时间序列具有记忆性,使用滑动时窗对实验室采集的离心鼓风机正常运行数据进行重采样,得到数量为m的源域样本S。使用源域样本数据,通过最小化重构误差,对融合稀疏正则项的自编码网络进行训练,发掘正常状态下设备运行数据的隐藏特征,完成源域自编码模型建立。
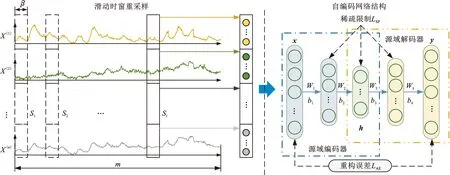
图1 源域自编码模型Fig.1 The AE model of source domain
监测的离心鼓风机运行状态数据包括温度、压力等时间序列,具有记忆性,尤其是温度等缓变量,当前温度值受到前一时刻温度值的影响较大。因此使用宽度为β的滑动时窗,一次移动一个时间点对原始数据进行重采样,使每个重采样样本包含β个时间点数据[20]。原始数据记为
(1)
式中,n为监测参数的种类;m为采集的样本个数。
重采样后数据为
(2)
k=1,2,…,m-β+1
自编码模型是一种无监督深度学习模型,由结构对称的编码器和解码器构成,分别表示为[21]
h=f(WEx+bE)
(3)
y=f(WDh+bD)
(4)
式中,WE、bE和WD、bD为编码器和解码器的权重与偏置;f(·)为sigmoid函数;x、y分别为网络输入和输出;h为编码器输出的低维特征。
自编码网络的目标是最小化输入与输出的差异,通常是输入向量x(i)与输出向量y(i)的均方误差(LAE),即
(5)
为防止网络层之间简单复制,在损失函数中引入稀疏正则项,使网络在稀疏约束下学习数据特征[22],通过迫使隐藏层神经元的平均激活度接近于0来实现各网络层稀疏化。隐藏层神经元r平均激活度为
(6)
式中,x(i)为输入神经元r的第i个样本。
使用KL(Kullback-Leibler)散度LSP描述平均激活度与稀疏参数的差异:
(7)
其中,R为神经网络隐藏层神经元数量;ρ为稀疏参数。因此,自编码网络的损失函数为
Lloss=LAE+λLSP
(8)
其中,λ为稀疏正则项系数。
如图1所示,源域自编码网络建立步骤如下:
(1)重采样。设置滑动时窗宽度β,对归一化后的源域数据Xs进行重采样,得到自编码网络模型的训练样本集S。
(2)初始化。设定网络层数和神经元个数,对自编码网络的权重和偏置进行随机初始化,设置稀疏参数为0.05和稀疏正则项系数λ为0.1。
(3)网络训练。从样本集S中选取小批量样本进行前向传播,得到网络的损失函数值;使用Adam算法,对自编码网络参数进行逐层更新,直到损失函数值收敛或迭代次数超过设定次数,完成源域的自编码训练。
1.2 迁移学习方法
由于离心鼓风机实验室环境和工厂实际运行环境下采集数据分布差异较大,故源域训练完成的自编码模型不能直接用于实际使用的离心鼓风机故障预警。本文通过减小源域和目标域特征的最大均值差异(maximum mean discrepancy,MMD)值来寻找源域和目标域可迁移成分,实现源域模型到目标域的领域适应,模型迁移方法见图2。
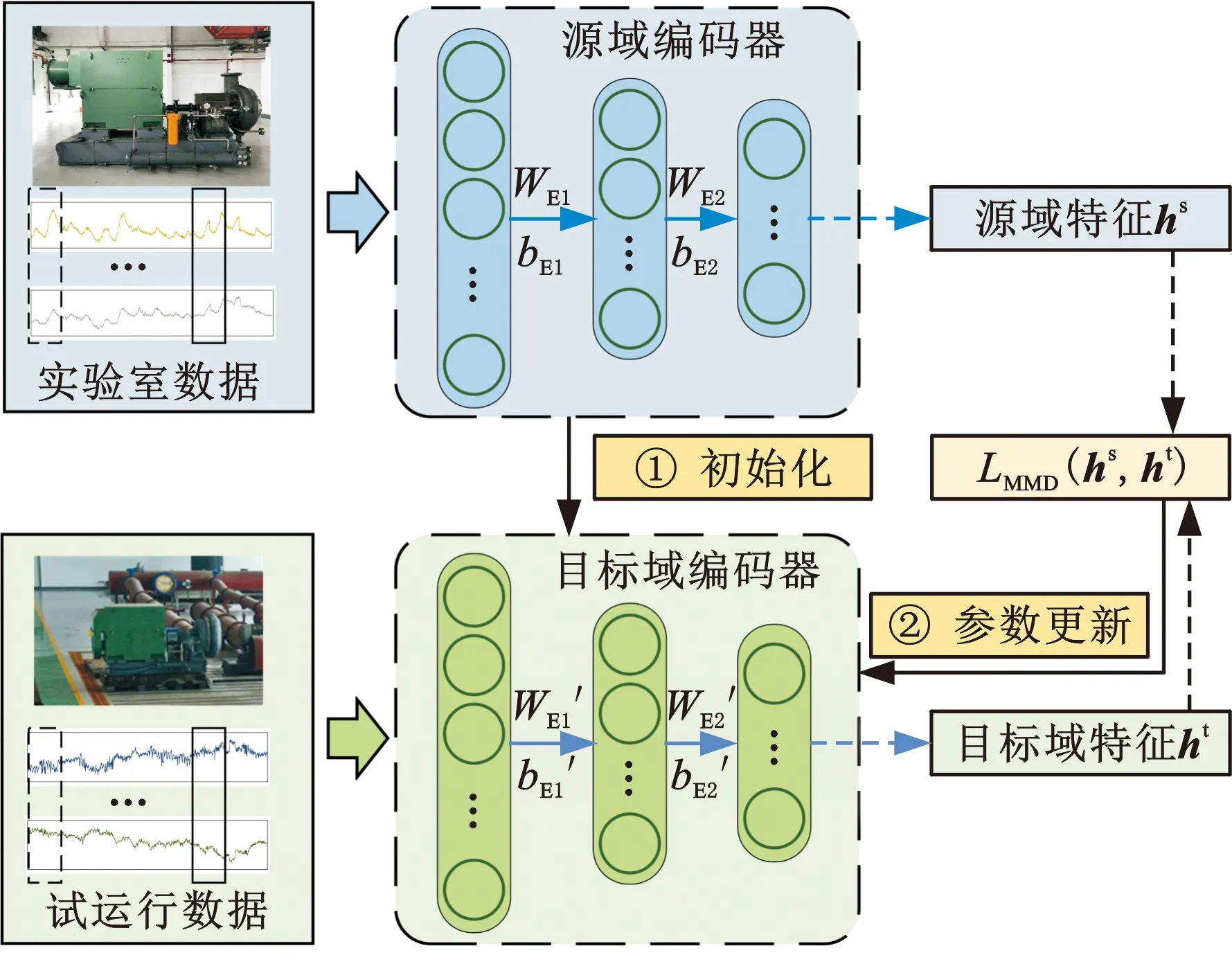
图2 模型迁移方法Fig.2 Method of proposed transfer learning
使用相同的滑动时窗对目标域数据进行重采样,得到长度为N的目标域样本数据集T。复制源域编码器的权重和偏置作为目标域编码器的初始值,固定源域编码器,将源域样本数据和目标域样本数据批量输入编码器,逐层前向传播获取源域特征hs和目标域特征ht,并计算源域特征和目标域特征的MMD值LMMD[23],其计算方法如下:
(9)
式中,k(·)为核函数运算。
不同的核函数会将数据映射到不同的空间,对MMD值起着决定性的作用。为降低核函数的影响,选用多核函数而不是单一核函数进行求解,如下式所示:
(10)
式中,kj(·)为不同的核函数,本文选择五个带宽分别为1、2、4、8、16的径向基核函数[23]。
复制源域编码器参数作为目标域编码器初始值,然后通过误差反向传播方法,以最小化源域特征和目标域低维特征的MMD值,应用梯度下降算法逐层更新目标域编码器[22]。首先将源域数据输入训练完成的源域编码器中得到低维特征hs,目标域数据输入目标域编码器获得ht,计算hs和ht的MMD值,然后根据下式更新网络参数:
(11)
其中,p、q分别代表第l层第p个节点和第l+1层第q个节点;η为学习率。此过程中保持源域自编码器参数不变,直到MMD值收敛或者迭代次数达到设定次数,从而完成目标域编码器训练。
目标域编码器训练完成后,将解码器偏置均初始化为0.1,通过权重绑定方法初始化解码器权重[24],即解码器第一层的权重为编码器最后一层权重的转置,解码器第二层权重为编码器倒数第二层权重的转置,以此类推,完成解码器参数初始化。然后固定目标域编码器,将重采样过后的目标域数据输入自编码网络进行重构,以最小化重构误差为训练目标,采用误差反向传播方式,使用较小学习率对解码网络进行微调,使之学习使用现场噪声情况,完成目标域自编码模型建立。
2 离心鼓风机故障预警方法
2.1 基于自编码网络的预警指标
自编码是一种无监督深度学习方法,它通过最小化输出与输入误差,挖掘数据相关关系和隐藏信息。在输入新监测数据到训练完成自编码网络过程中,若设备正常运行,则自编码网络能够准确重构输入的监测数据,若设备发生故障,则监测数据的相关关系发生变化,导致输出向量和输入向量出现较大差异。基于流形学习思想,高维数据实际上是一种低维的流形结构嵌入在高维空间中,自编码网络能够将高维数据映射回低维空间,揭示数据的本质,广泛用于特征降维[25]等。采集到的离心鼓风机正常运行状态数据相关性强,冗余度高,使用自编码网络学习数据的低维流形,挖掘产生数据的内在规律是可行的。本文使用自编码网络学习数据低维流形具有以下特点:训练样本来自离心鼓风机正常运行状态下采集的数据,即自编码网络不需要重构不属于正常状态下的输入数据;设置稀疏约束项,降低网络对输入的敏感度,防止其学习过程中简单地将输入复制到输出。基于以上特征,使用自编码网络能学习到在流形上表现良好但给定不在流形上的输入会导致异常的映射函数。训练完成后的自编码网络能够很好地重构离心鼓风机正常运行数据,输入实际运行数据到自编码模型进行设备故障预警时,在设备偏离正常状态,当输入数据偏离正常流形时,自编码网络重构值将出现异常,基于此原理实现设备故障预警。
为更加直观地展示自编码网络输入值和重构值的异常,及时识别出设备早期故障现象,提出离心鼓风机故障预警指标ζ,计算公式如下:
(12)
其中,deuc、dcos分别为重构向量Y和输入向量X的欧氏距离和余弦距离,表示两向量位置和方向的差异;dot(·)表示向量的点积运算。当离心鼓风机正常运行时,输入和输出向量差异较小,ζ值较小;当设备偏离正常状态时,输出向量出现异常,ζ值变大。
2.2 故障预警策略
故障预警策略包括确定阈值和发出预警的前提条件,对正常状态下监测指标分布进行估计,再使用假设检验方法确定预警阈值。由于分布规律未知,故本文采用核密度估计方法。核密度估计法从样本出发,不需要分布的先验知识或对数据分布进行假定,其定义如下[2]:

(13)
设某一小概率值α,当设备正常运行时,指标值将落在置信度为1-α的置信区间[0,ζth]。当指标值处于置信区间外,即小概率事件发生时,可以认为出现异常,ζth可以设置为报警阈值,其关系如下:
(14)
考虑使用现场出现短时强噪声和数据采集异常值情况,导致ζ短时超过阈值,为降低此类情况导致的误报警,提出连续越限次数Q及其阈值Qth,当预警指标连续超过预警阈值的次数多于Qth时,发出故障预警信息。Qth计算方法如下:
Qth=max(Qmax,β)
(15)
其中,Qmax为正常数据重构时,预警指标ζ连续超过阈值的最大次数[20]。
本文提出的离心鼓风机故障预警流程分离线训练和在线监测两部分,流程如图3所示。
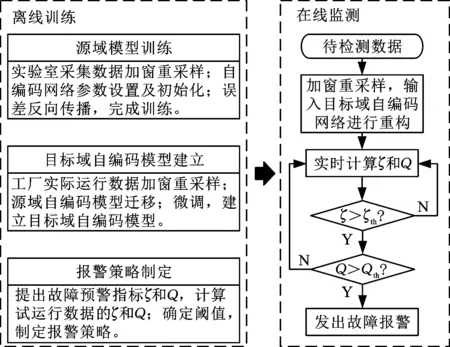
图3 故障预警流程图Fig.3 Flow chart of proposed fault warning method
3 案例分析
3.1 离心鼓风机数据集的采集和描述
为验证该方法的有效性,在重庆某离心鼓风机制造企业开展案例研究。该企业研发的远程运维平台能实时采集离心鼓风机运行数据,包括用户和实验室试车的离心鼓风机。如图4所示,离心鼓风机主要由控制系统、驱动电机、润滑系统和机体构成,传感器对设备的振动、温度和压力等重要参数进行采集,从而实现鼓风机运行状态监控。

图4 离心鼓风机和部分外接传感器Fig.4 Centrifugal blower and sensors
图5为远程运维平台界面,具体监控参数如表1所示。除振动数据外,其他数据的采样频率均为1 Hz,其中振动数据为电涡流传感器采集的位移数据,实际采样频率为512 Hz,为降低数据传输压力,平台上传的振动数据为1 s内振动的峰峰值,因此,振动数据采样频率也为1 Hz。

图5 离心鼓风机远程运维平台界面Fig.5 Interface of remote maintenance system for centrifugal blowers
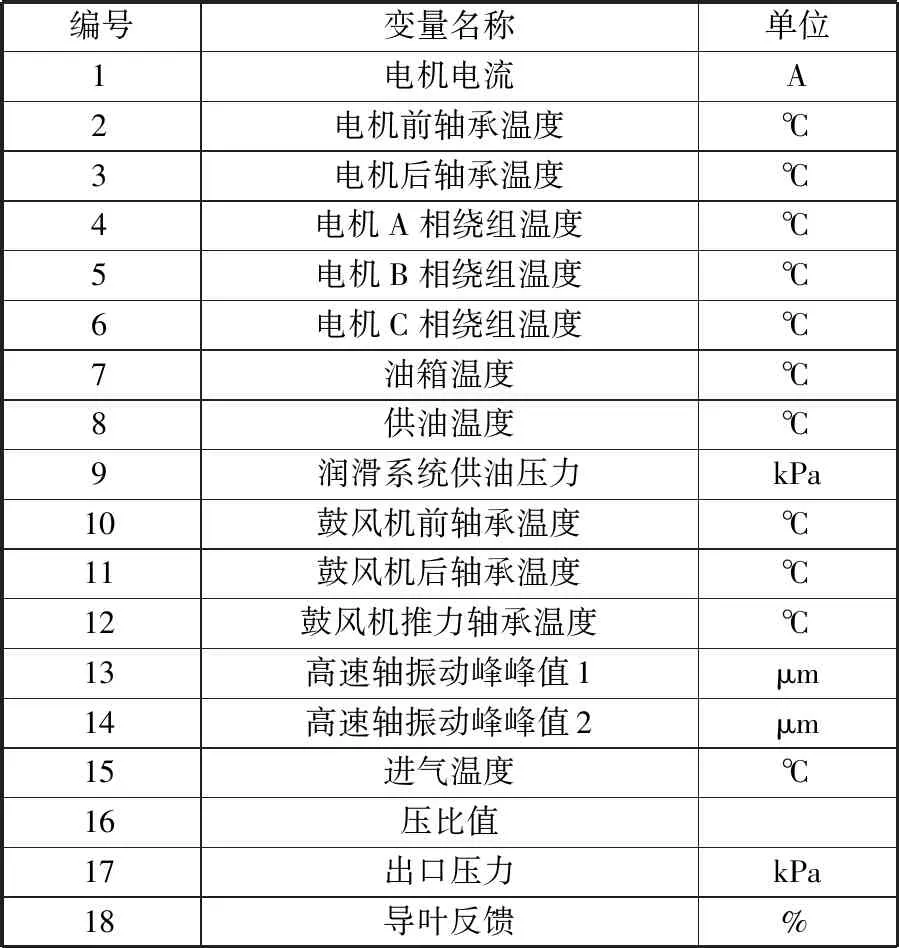
表1 离心鼓风机监测参数Tab.1 Monitoring parameters of centrifugal blowers
为验证本文方法效果,对某台离心鼓风机的一次故障进行预警分析。该台离心鼓风机在2019年6月制造完成后,一次性通过性能实验室对其进行的试车。该台鼓风机在2020年7月10日发生故障自动停机。经过现场拆机分析,查明停机是由于叶轮与壳体发生碰摩,触发了设备自动保护系统。故障转子磨损图见图6,磨损区由于碰撞摩擦,出现了明显的刮痕和高温导致的变蓝现象。

图6 转子磨损图Fig.6 Wear of the rotor
从远程运维平台导出该台离心鼓风机在2019年6月20日的11 030组实验室试车数据作为源域数据。该台鼓风机在7月20日交付给用户并进行试运行,导出当日试运行的3500组数据作为目标域数据。以上所有数据可认为均来源于鼓风机正常运行状态。该设备在2020年7月10日12时37分12秒自动停机,选取当日开机到故障停机的38 890组数据作为测试数据,进行故障预警效果分析。
3.2 目标域自编码模型建立
3.2.1源域模型建立
将源域数据加窗后作为自编码网络训练数据,编码器各层神经元个数分别为输入数据维度18β、150、35、3,解码器结构和编码器对称,学习率设为0.01,批量设为256。滑动时窗的宽度影响自编码网络重构效果,分别用1、4、7、10、13的窗口宽度对数据进行重采样,分析重构值和输入值的平均绝对误差(MAE)、最大误差(ME)和标准差(STD)来量化输入和输出的差异,评价不同窗口宽度对重构效果的影响。其中MAE用来评价自编码网络的整体重构效果,ME和STD反映模型是否能够稳定地重构输入向量,对故障预警有着重要意义。MAE、ME和STD值的计算式如下:
(16)
(17)
(18)
f=1,2,…,n
其中,f表示监测参数种类。图7所示为不同窗口宽度下,进行10次重构求得的MAE、ME和STD的均值和误差棒。当窗口宽度β为1和7时,ME和STD值均较小,但β=1时误差棒较长,并且窗口宽度为7时,MAE值最小,因此为充分考虑时序数据的相互影响,使自编码网络能够准确重构输入数据,窗口宽度设置为7。
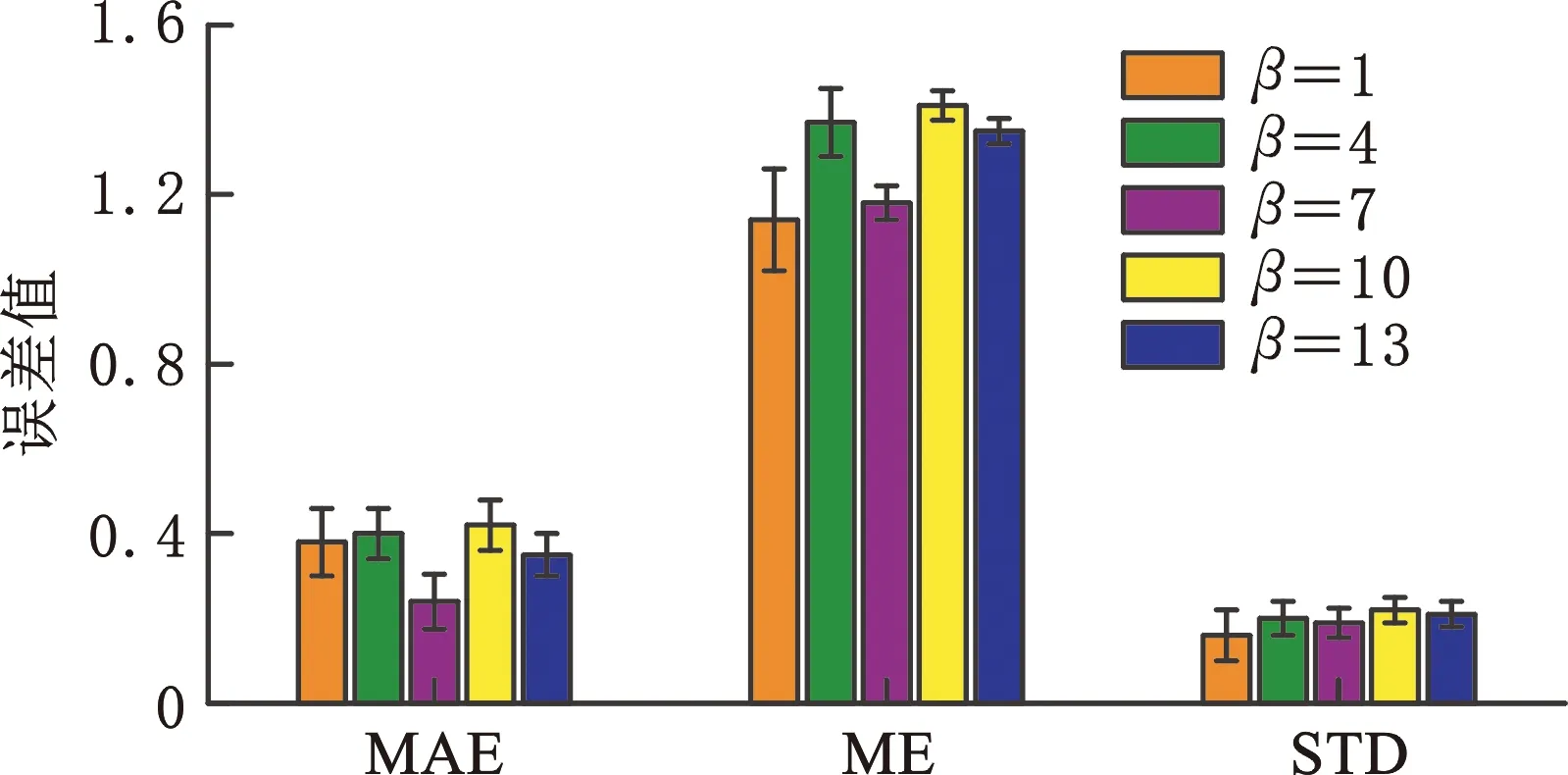
图7 不同窗口宽度的重构效果对比Fig.7 The reconstruction performance of different β
在网络参数选定后对自编码网络进行训练,训练过程中重构误差趋势如图8所示,当迭代到400代时,重构误差趋于平稳,损失值收敛到0.01,说明源域自编码模型能够很好地重构输入数据。
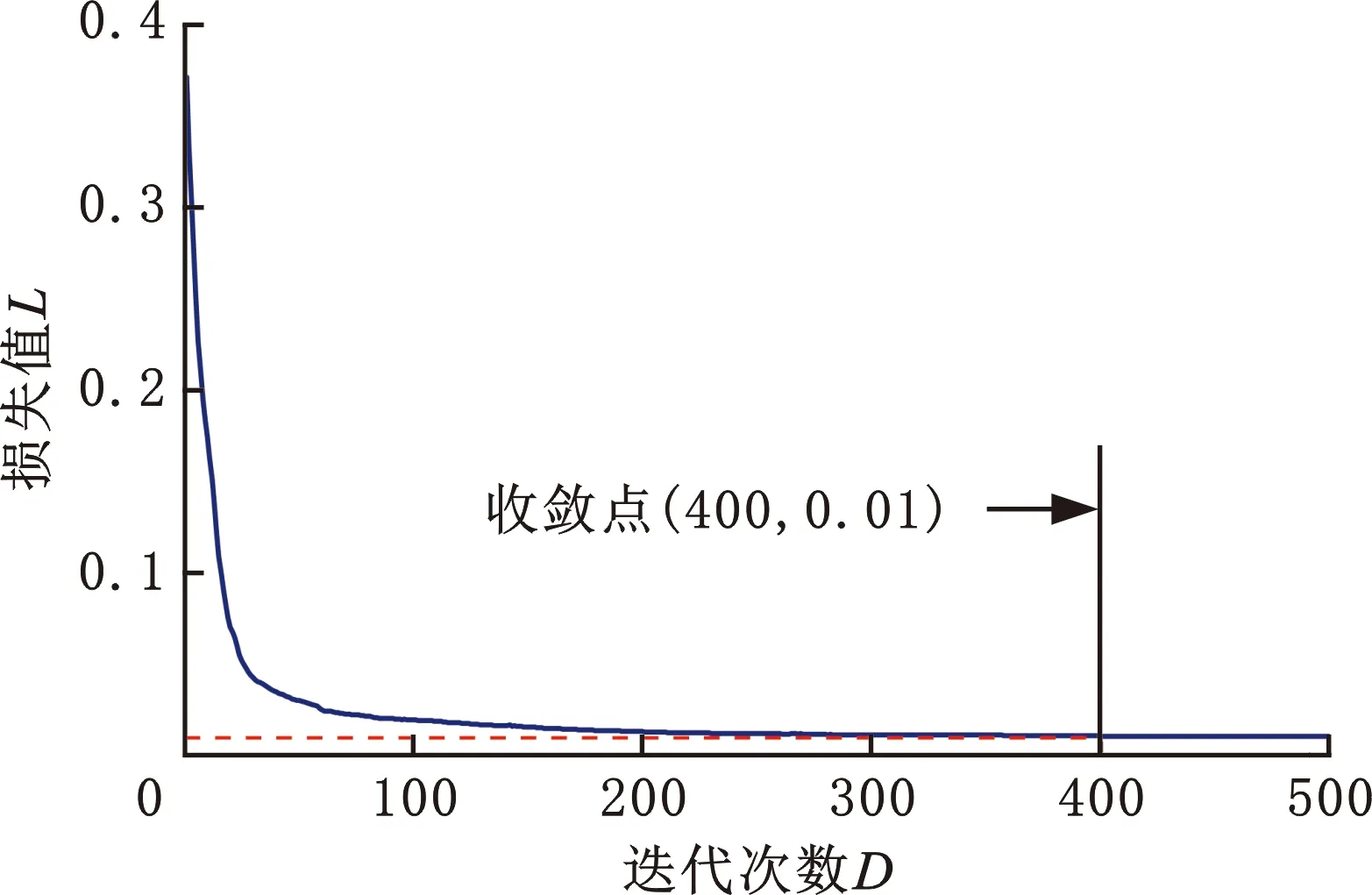
图8 源域模型训练过程损失变化Fig.8 Changing of loss during training for source AE
3.2.2模型迁移结果分析
由自编码模型结构可知,数据的低维特征维度是3,通过绘制特征分布图[13],对迁移学习效果进行分析(图9)。图9a所示为使用源域自编码器分别提取源域和目标域数据的低维特征分布,由于数据分布差异较大,因此源域特征和目标域特征分布差异也较大,源域自编码模型难以准确重构目标域数据。使用本文所提迁移学习方法完成目标域编码器训练,获得的目标域数据低维特征如图9b所示,可以看出,经过迁移后,目标域数据特征向源域低维特征靠近,且出现聚合现象,表明目标域自编码模型能够有效降低外界噪声等干扰,提取到源域和目标域数据共同特征。
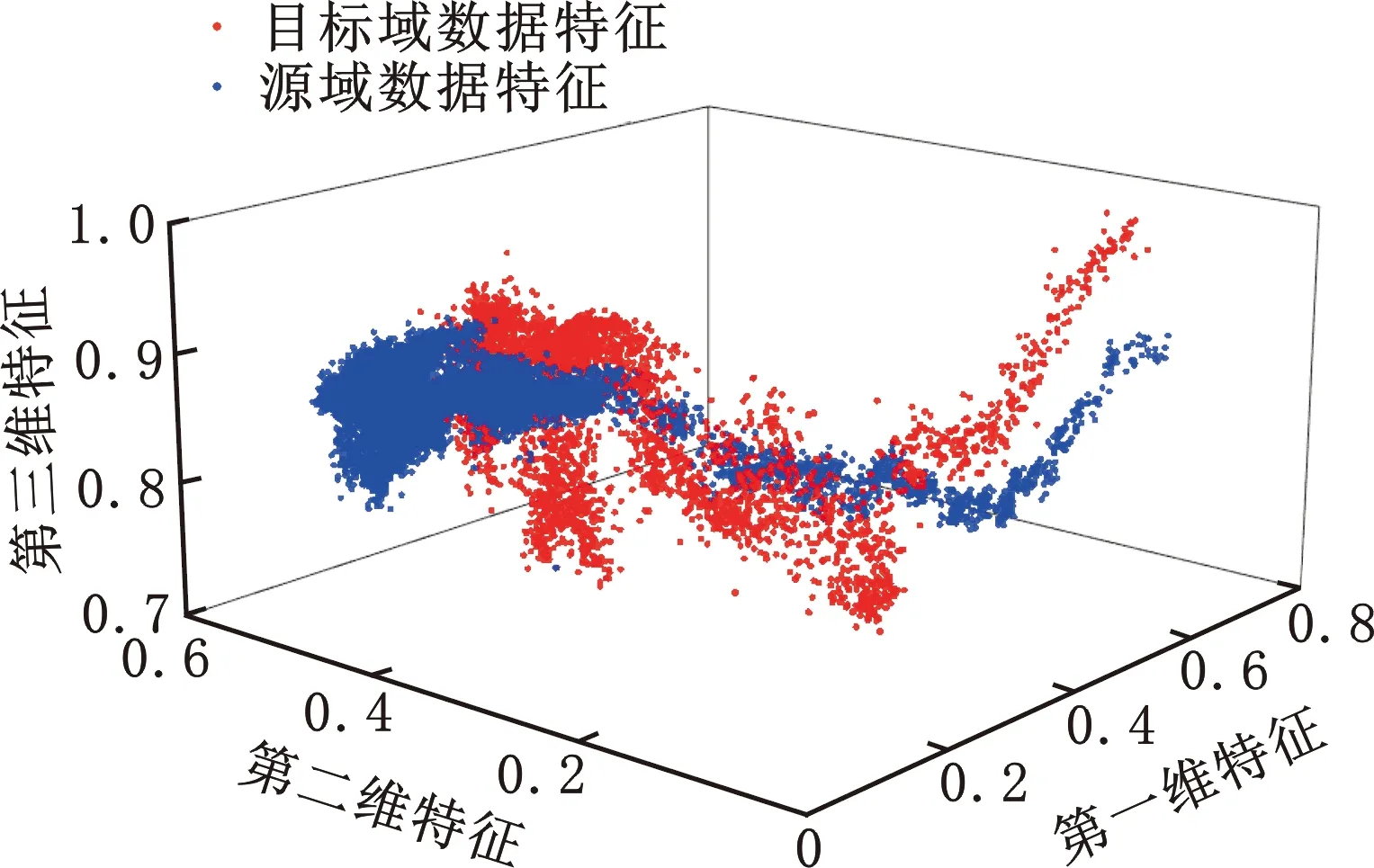
(a)迁移前低维特征分布
最后对目标域解码器进行微调,完成目标域自编码网络训练。选择电机前轴承温度分析重构效果,电机前轴承温度观测值、重构值如图10a所示,重构相对误差如图10b所示,由图10可知,重构值和观测值曲线重合度高,相对误差小于3%,表明自编码网络能够准确重构出观测值,学习到鼓风机正常运行状态的数据特征。
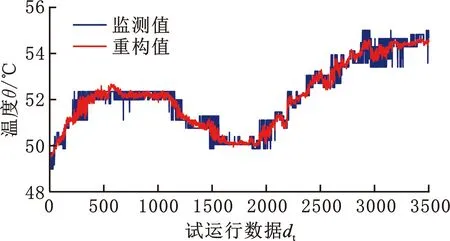
(a)电机前轴承温度重构
3.3 故障预警实现
使用目标域自编码模型对实际运行数据进行重构,计算得到预警指标ζ走势如图11和图12所示。图13是使用核密度估计法得到的密度函数曲线。选取预警指标的0.99分位数作为预警阈值,即ζth=0.3785。由图12可知,图11中a~f处连续超过预警指标的点数量分别为4、4、5、5、7、7,因此根据2.2节所述,设置连续越限阈值Qth为7,即在实际状态监测过程中,预警指标连续超过7次时才发出故障预警信号,同时,当预警指标连续小于阈值7次时取消报警。
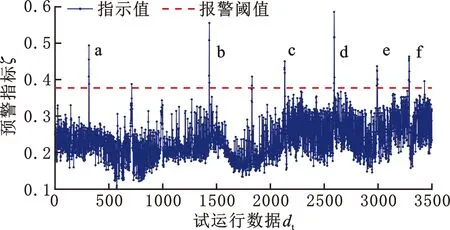
图11 实际运行数据的故障预警指标Fig.11 The indicator’s value of data collecting at test run
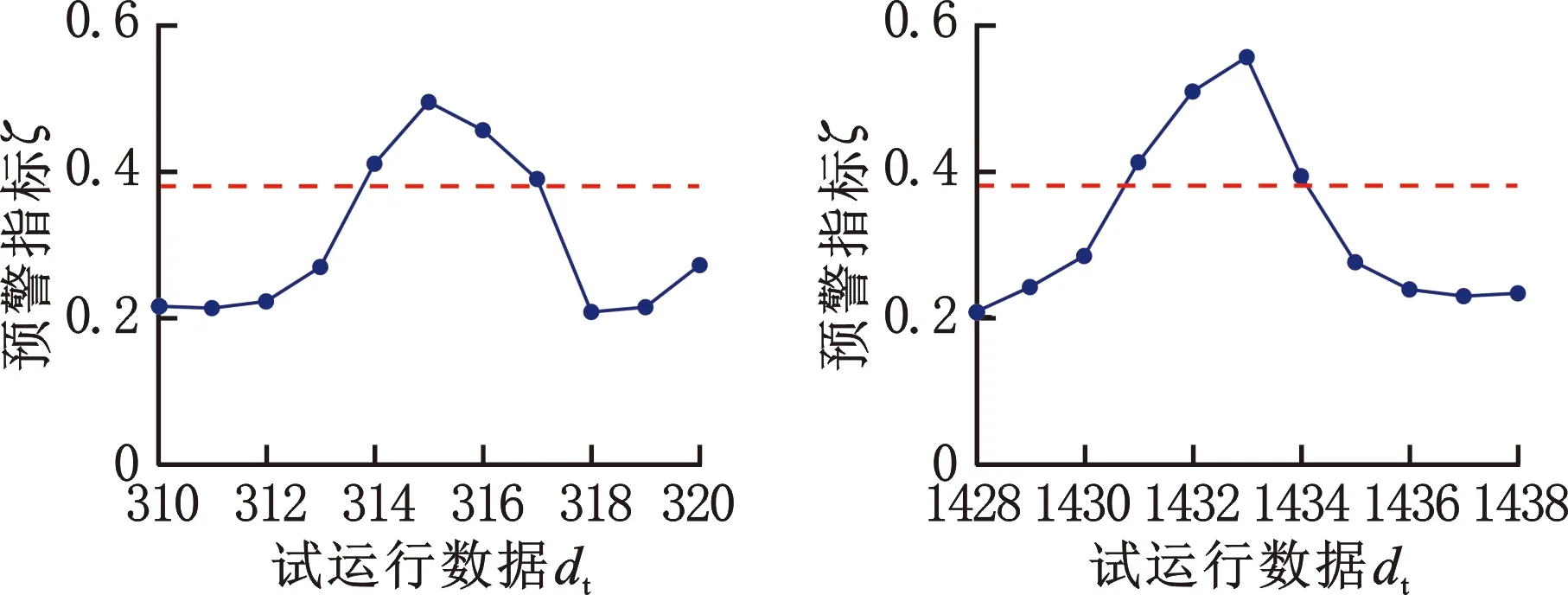
(a)a处放大图 (b)b处放大图
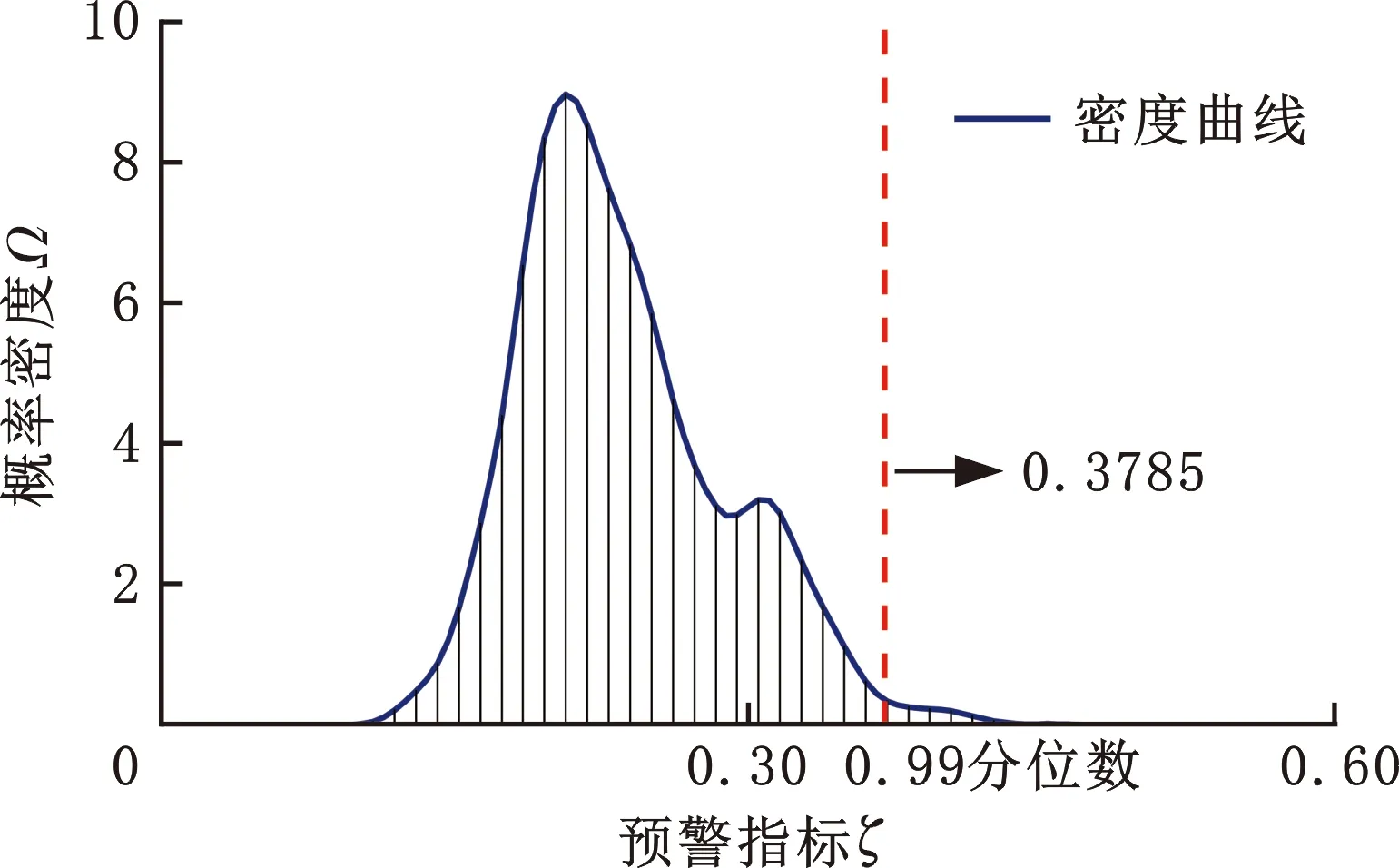
图13 指标分布Fig.13 The indicator value’s distribution
选取当日离心鼓风机开机至故障发生的38 890组数据作为测试数据进行故障预警分析,计算出预警指标ζ和报警结果如图14a、图14b所示。图14a完整地展示了设备由正常到故障状态的预警指标变化趋势,在第I阶段,设备运行良好未发生故障,模型能够准确地重构输入数据,故障预警指标ζ绝大部分处于报警阈值之下且并未触发报警。在故障发生前期,即第Ⅱ阶段,设备正在劣化,逐渐偏离正常状态,模型难以准确重构输入数据,预警指标出现变大趋势。在故障发生的阶段Ⅲ,在转子和壳体发生碰撞的一瞬间,振动值瞬间变大,对应的预警指标发生跃变,如图15所示。在第15 376点处连续7次超过报警阈值,触发报警。在第Ⅳ阶段,设备状况进一步恶化,指标值持续变大,最后发生剧烈波动,符合碰撞摩擦的故障特征。本文方法发出故障预警信息比自动停机时刻提前了23 514 s,约6 h 31 min,且故障预警指标ζ变化趋势高度符合工程实际,若在发出报警信号时及时检修设备,能有效避免故障进一步扩大。

(a)测试数据的指标走势图
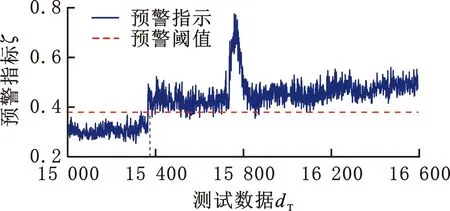
图15 阶段Ⅲ指标变化细节图Fig.15 Indicator’s value of phase Ⅲ
3.4 对比分析
为进一步验证本文方法的有效性,选择三种方法进行预警效果对比分析。前两种方法分别只使用源域数据、只使用目标域数据实现工厂实际运行环境下设备故障预警,第三种是典型的基于自编码网络进行故障预警方法。下面给出对比方法的细节和预警结果。
(1)方法1:基于源域数据的故障预警。该方法直接使用源域训练完成的自编码网络,不进行迁移和微调,对实际运行数据进行重构,求出实际运行数据指标分布,并按相同方法得出ζth、Qth,最后对测试数据进行故障预警分析,结果如图16所示。
(a)方法1测试数据的指标走势图
(2)方法2:基于目标域数据的故障预警。该方法直接使用目标域的3500组实际运行数据,经过加窗重采样后,训练与源域结构相同的自编码网络,参数设置和训练方法与源域模型建立过程保持一致。使用训练完成后的网络,输入实际运行数据得出计算指标值,按相同的方法确定报警阈值和报警策略,最后对测试数据进行故障预警效果分析。由于20 000点后走势和本文所提方法相似度高,因此,图17只展示了测试数据的前20 000个预警指标值。

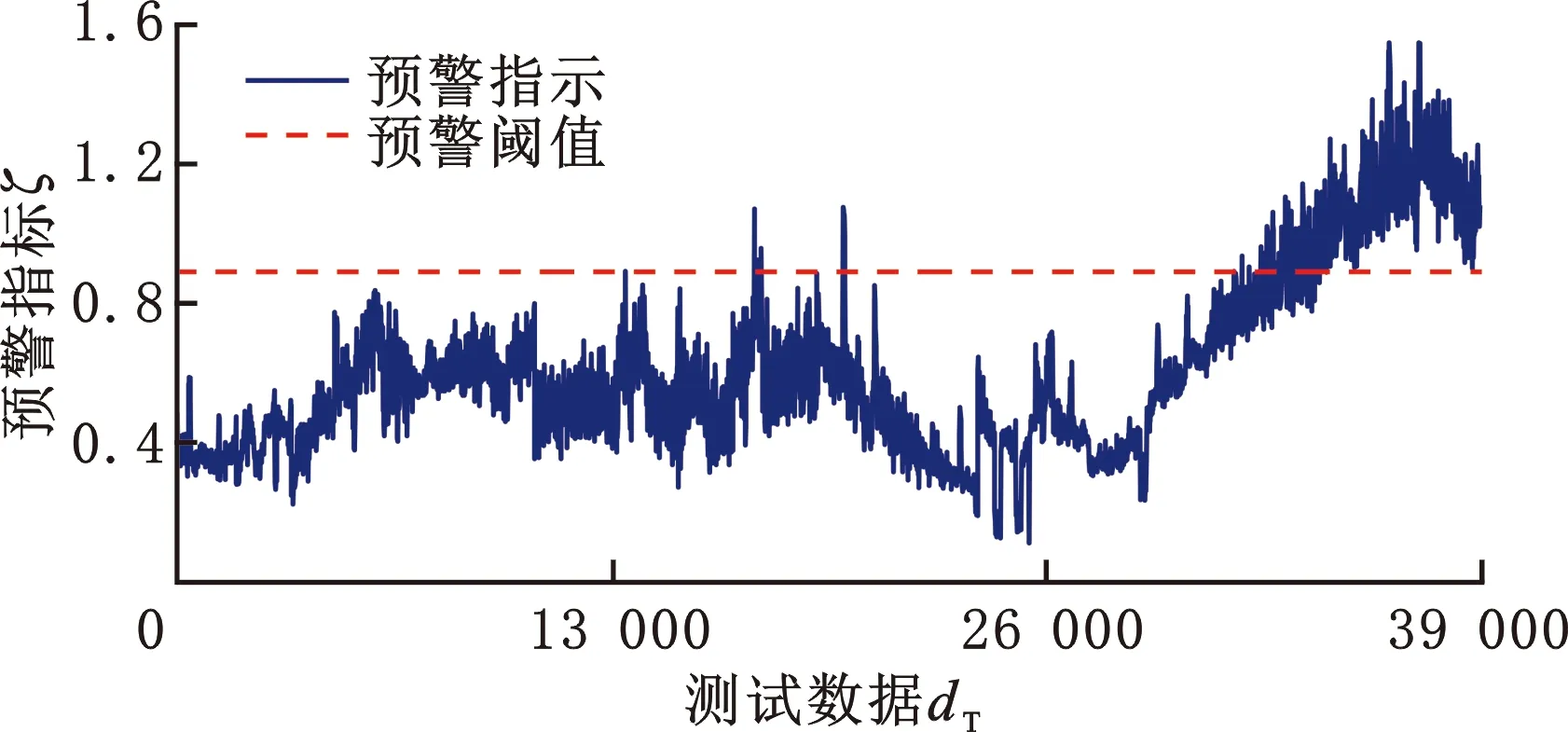
(a)方法2测试数据的指标走势图
(3)方法3[20]:使用文献[20]所提的MW-SMDAE(moving window-stacked multilevel denoising autoencoder)方法建立自编码模型。该台离心鼓风机在制造完成后到此次故障前运行正常,未出现自动停机现象。采集故障前一天的12 123组运行数据,训练文献[20]所提出的多层级加噪的两层自编码网络。训练完毕后,计算得出训练数据的指标值,然后根据数据分布确定报警阈值ζth、连续报警阈值Qth,并对测试数据进行故障预警分析,故障预警结果如图18所示。
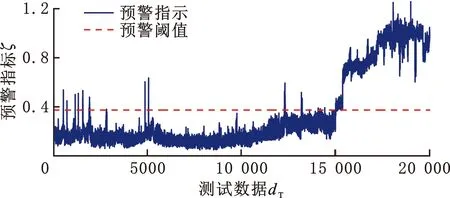
(a)方法3测试数据的指标走势图
如图16a所示,方法1所得出的预警指标走势和实际故障演化趋势一致性较差,存在故障预警不及时等问题。由图17a、图18a可知,方法2、方法3和本文方法相似,指标走势能较好地反映转子磨损故障实际,但两种方法在故障发生期间均出现较大跃变,而且方法2在故障进一步扩大期间,即18 000点后,指标值出现异常减小现象。另外,方法2和方法3在故障预警前出现较多误报警。
为进一步分析各种方法预警效果,表2给出了各方法的报警阈值、报警点和误报次数等详细预警结果。由表2可知,方法1的预警阈值最大,故障提前时间最短,但在发出故障预警前存在大量超过阈值的点。方法2和方法3虽然报警提前时间优于本文方法,但存在误报警点且多次报警前指标超过阈值,降低了故障预警精度。

表2 四种方法预警效果对比Tab.2 Comparison of four fault warning methods’performance
对四种故障预警方法进行对比分析如下:由于源域和目标域数据分布有差异,源域自编码网络不能准确地重构实际运行数据,导致预警阈值较大,且源域数据包含部分极端工况运行数据,因此方法1将一些早期故障状态误判为正常运行状态,故障报警提前时间最短;方法2仅使用实际运行数据进行故障预警,由于训练数据较少,因此自编码网络出现轻微过拟合现象,预警阈值最小,过拟合现象也导致了误报次数较多;当训练数据量增加,方法3误报次数和报警前超限的点少于方法2误报次数和报警前超限的点,但是由于采集的数据可能包含故障信息,加之现场噪声影响,从而导致模型存在偏差,不能稳定重构正常状态运行数据。本文所提方法故障预警提前时间较方法2和方法3短,但误报警和报警前指标超限次数都少于其余三种方法,指标走势高度符合故障演化趋势,最满足实际需求。可见本文方法能很好地将实验室模型数据用于设备故障预警中,有效提高故障预警效果,降低现场噪声、数据量不够丰富或设备正常状态判断失误对模型精度的影响。
4 结论
本文结合离心鼓风机使用实际,提出一种迁移学习方法,将实验室数据建立的模型用于实际使用过程中离心鼓风机的故障预警中,有效提高了预警准确度。首先对实验室采集数据进行加窗重采样,训练融入稀疏限制的源域自编码网络;然后通过最小化特征的最大均值差异值和对模型进行微调,实现模型迁移;最后根据自编码网络提出故障预警指标并制定预警策略,实现离心鼓风机故障预警。
使用实际的离心鼓风机故障案例对本文所提方法进行故障预警分析,结果表明:故障预警指标能很好地反映设备故障演化趋势,所提的迁移学习方法能有效地将实验室数据和模型用于实际使用过程中设备故障预警模型的建立,有效提高预警精度,具有工程应用价值。
