面向工业软件开发的半结构化知识语义检索方法
2021-09-13王春雨蒋祖华王福华吉永军
王春雨,蒋祖华+,王福华,吉永军,江 辉
(1.上海交通大学 机械与动力工程学院,上海 200240;2.上海宏路数据技术股份有限公司,上海 200080)
0 引言
工业软件开发是智力密集型的系统工程活动,企业在日常开发活动中积累了许多工程知识,如问题解决方案、版本更新说明、项目开发公告等。为解决遇到的工程问题,工程师需要花费大量时间从企业知识库中寻找和筛选工程知识来辅助解决问题[1-2],知识检索效果对开发效率有显著的影响。因此,面向工业软件开发,研究快速定位经验知识的检索工具,对提高企业知识的利用水平具有重要的意义。
知识检索采用多种相关性度量,从工程师输入的自然语言形式查询语句中挖掘描述用户需求的语义信息,将工程知识按相关性高低排序后推荐给工程师。现有的知识检索技术分为基于关键词匹配和基于深层语义匹配两大类。
(1)基于关键词匹配的知识检索技术按照用户查询和文本域的匹配关系细分为一对一的结构化检索和一对多的多文本域检索。前者要求输入与属性、特征、分类等数据域对应的结构化查询语句,系统在多个数据域上进行关键词匹配[3],这类技术依赖开发者定制的结构化查询语句,难以用于缺乏严格类型约束的知识检索;后者计算并汇总知识中多个文本域与用户查询的相关性[4-5],可用于格式灵活的知识。基于关键词匹配的检索技术只使用了浅层的字符统计学特征,忽视了实体间的深层关联,不能深入评估查询和知识的语义相关性,在语义丰富的工程知识库上的检索效果不够理想。
(2)基于深层语义匹配的检索技术多面向非结构化的文本型知识,按推理方法的不同细分为基于概念知识的检索技术和基于语言模型的检索技术。概念知识描述了实体概念间的语义关联[6],基于概念知识的语义推理即利用实体间的关联关系计算用户查询与知识间的语义相关性[7],其符合人类的推理直觉,检索结果的准确度高[8],然而通用的概念知识库普遍缺乏软件开发中的领域语义知识[9],如何利用概念知识描述知识复杂的上下文是研究的一个方向。语言模型通过捕获自然语言的表达模式计算两段文本的语义相关性[10],HUANG等[11]设计的双塔式语义搜索模型将文本分解为三联字符袋嵌入低维语义空间,用余弦值计量查询—知识间的语义相关性。基于语言模型的深层语义匹配方法通过捕获表达模式等语义信息,较好地解决了用户检索中“词不达意”和“一词多义”的问题[10,12],克服了基于关键词匹配方法忽视自然语言文本中实体间语义关联的缺点,但也存在领域概念知识获取难和语言模型计算复杂、响应速度慢等缺点。
近年来,根据应用场景的独特语义结构设计算法成为检索领域[13-15]的研究热点。已有研究从问题结构[16]、评分特征[17]等出发提出一些面向软件开发的语义检索方法。笔者在研究中发现,软件开发中会重用大量代码模块,工程知识会随代码重用影响所有导入的产品,因此产品适用的工程知识集存在重叠的现象,然而已有方法未考虑软件开发中这种结构的产品关联关系。另外,软件企业以半结构化形式记录的工程知识兼有标签和文本两类信息,标签包含稠密直观的概念语义信息,文本则隐含稀疏的自然语义信息,两类语义产生于工程知识形成的不同阶段,单类语义不能全面地解释采用工程知识解答问题的可行性和合理性[18]。针对上述工业软件开发工程知识检索存在的问题,本文提出一种基于知识超网络的语义检索方法,通过软件开发工程知识的提取、工程知识超网络的构建、复合语义相关性的推理,解决半结构化知识复合语义检索的困难,为软件工程师提供更有效的知识检索方法。
1 面向软件开发的半结构化知识语义检索方法框架
1.1 软件开发中的工程知识
半结构化数据既不同于文本流、音频流、视频流等完全非结构数据,也不同于数据库中严格规范约束的结构化元数据,是具有模式信息隐含、数据结构不规则、类型约束弱等[19]特征的数据。企业在软件开发中常以半结构化的格式记录知识,并在未来的工作中重用这些知识[20],如图1所示。文档结构的多样性不会对人类阅读造成障碍,但是不便于机器进行计算和推理。因此,需要先将软件开发工程知识规范化表征为便于计算机处理的统一形式。

1.2 工程知识的规范化表征
将原始的半结构化异构文档中的工程知识表征为规范化单元以便统一检索,然后采用软件开发中工程知识通用的4个属性描述核心特征,构建规范化表征的工程知识元EKU=AP,AO,KT,CD。从原始文档中提取的工程知识元如图2所示,各属性的内涵如下:
(1)适用产品(Applicable Production,AP) 该方案/说明/公告生效的产品情境,如.Net Core。
(2)应用对象(Apply-to Object,AO) 该方案/说明/公告应用的具体模块,如身份认证程序。
(3)知识类型(Knowledge Type,KT) 工程知识的类型,用于识别内容描述的叙述模式。
(4)内容描述(Content Description,CD) 知识内容正文,包含原始文档的文本信息。

1.3 考虑复合语义信息的工程知识语义检索方法框架
本文的语义检索方法框架如图3所示,其中知识超网络包括产品树、应用对象的概念语义子网和知识内容的自然语义子网。3个语义子网对应工程知识“在某产品情境针对某应用对象,产生了某工程知识”的形成过程,构成工程知识解答用户查询的推理逻辑。通过贝叶斯方法模拟工程知识的推理过程,以评估工程知识元和用户查询的语义相关性,相关性表现为条件概率P(EKU|QAP,QAO,Q),即工程知识元EKU被推荐的概率,其中Q表示用户查询,QAP,QAO表示用户查询中的产品情境和应用对象。
(1)属性抽取和规范化表征 将原始知识文档数据转化为规范的工程知识元,解决工程知识弱类型约束问题。
(2)知识超网络的构建 基于原始知识文档规范化表征的工程知识元,将工程知识元映像为超网络中的超边,组成工业软件开发知识库的产品、对象、知识3层超网络,计算各节点间的子网内关联度和子网间节点超度等统计指标。
(3)基于超网络的深度语义推理 包括概念语义相关性计算、自然语义相关性计算和超网络的贝叶斯概率推理。概念语义相关性的计算过程如图4所示,基于超网络的统计指标用于评估用户查询和工程知识元间的语义相关性;自然语义相关性基于语言模型计算,用于评估工程知识元中文本信息和用户查询的语义相关性;最后用贝叶斯定理推理工程知识元和用户查询的匹配程度。

2 方法的具体实现
2.1 工程知识的属性抽取和规范化表征
原始文档存在的属性缺失问题,可以通过分离和抽取知识中的实体概念来补全。
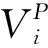
(1)

(2)

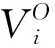
(3)
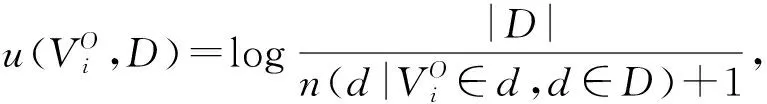
2.2 知识超网络模型的构建
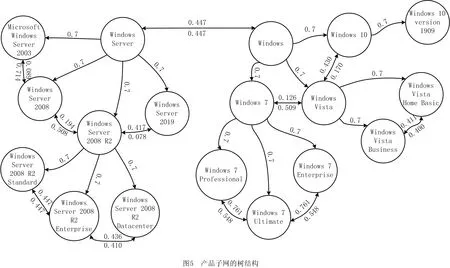
工业软件开发中,工程师对知识的需求可以分解到适用产品、应用对象、知识内容3个属性维度匹配来语义上下文,因此本文搭建产品子网、对象子网、知识子网组成的超网络模型描述工程知识元的3种语义元素。工程知识元映像到模型中的超边[22]HE表示在产品情境中针对应用对象产生的具体工程知识内容。
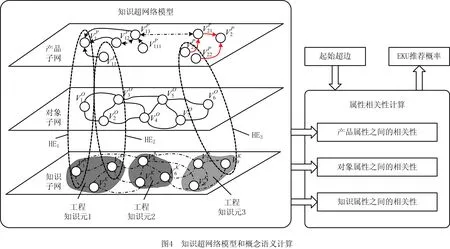
(1)产品子网NP工程知识产品情境实体VP及其之间的关联EP构成一个有向加权树。父子节点间为单向关联关系(Kind-of),参考文献[1]的领域本体构建方法,父子节点间的关联系数取0.7;同级节点间为双向关联关系(Similar-with),考虑软件开发中代码模块复用的情况,同级节点间的关联系数与产品间重叠度相关,即
(4)
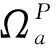
(5)
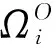
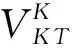
(6)
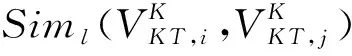
(7)
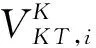
(8)
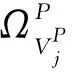
知识子网NK和对象子网NO间节点的超关联度
(9)

2.3 融合概念知识和自然语言信息的深度语义检索方法
2.3.1 用户查询的解析
在语义相关性计算前,基于知识超网络中的实体概念,查询解析器将自然语言形式的用户查询映射到知识超网络中,称为起始超边HEQ,
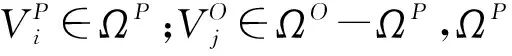
2.3.2 考虑类型特性的自然语义相关性计算
工程知识元的CD属性蕴含了自然语言的深层语义,考虑知识内容的逻辑结构差异,在语义相关性计算中需要区别处理不同类型工程知识。例如,在本文使用的原始知识库中存在“解决方案”、“软件包说明”和“开发公告”3类工程知识,“解决方案”类知识内容描述由标题(摘要)→症状(问题描述)→解决方案3段组成,其中标题(摘要)→症状(问题描述)是匹配用户查询的核心;“软件包说明”类知识内容描述由摘要→已知问题→关联信息3段信息组成,其中对软件包的核心功能描述只有摘要部分,已知问题和关联信息与用户查询不匹配;“开发公告”类知识的正文是参考信息,取公告标题与用户查询进行匹配。
基于注意力机制的语言模型具有强大的深层语义理解能力,本文采用基于Transformers的双向编码表示(Bidirectional Encoder Representations from Transformers, BERT)模型评估用户查询和工程知识元在自然语义层面的相关性。计算用户查询与工程知识元CD属性文本域的相关性分数,评估每个文本域和用户查询的相关性,而非工程知识元整体与用户查询间的相关性。因此,本文的计算模块采用孪生网络和平均池化设计,模块的架构如图6所示。
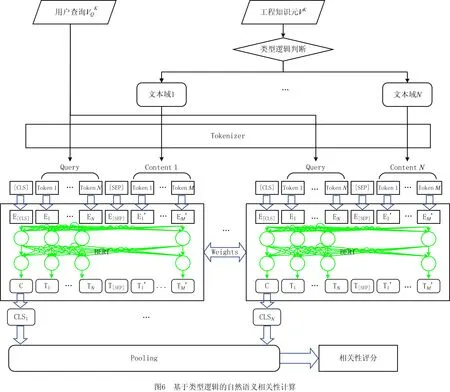
2.3.3 基于贝叶斯定理的深度语义推理
基于知识超网络的语义推理,即搜索起始超边HEQ相关性最高的工程知识元,P(EKU|QAP,QAO,Q)为在QAP产品情境中针对应用对象QAO,工程知识元EKU可以满足用户查询Q的概率:
P(EKU|QAP,QAO,Q)=
(10)
式中:
(11)
(12)
(13)
(14)
合并式(10)~式(14),最终得到知识超网络中每个工程知识元与用户查询之间的相关性评分
(15)
式中S(EKU,Q)为介于[0,1]的值。按分数倒序排列知识库中的工程知识,取得分最大的若干条输出给工程师。
3 案例实验与分析
3.1 实验设计
为了验证本文方法的有效性,在Core i7 7700HQ@2.81 GHz,16 G内存Windows 10系统下编写和运行实验用程序。
3.1.1 数据来源与采集方法
本文从微软知识库(Microsoft knowledge base)爬取实验所用原始知识文档,过滤无正文知识内容的文档,按前文所述方法规范化表征为工程知识元,存储在JSON格式的交换文件中,用于本文实验。实验前先构建原始知识库的知识超网络模型,并以节点列表+边列表的形式存储,对象子网和知识子网以邻接表的形式保存。
为降低计算耗时,工程师输入用户查询后最多召回100条候选项,然后采用本文方法进行排序,最后将返回的20条相关工程知识推荐列表给工程师。测试使用的用户查询语句是一段自然语言文本,摘取自微软Q&A和SegmentFault,共计10条用户查询。用户查询“基于.Net Framework 3.5的开发项目,多线程并行模块调用的线程池维护线程未按预期方式工作”的输入,解析得到的起始超边和评分输出如表1所示。

表1 一次检索对应的输入(用户查询)和输出(知识推荐列表)

续表1
表中,“起始超边”是“用户查询”经解析后得到的,对应2.3.1节;“文章ID”对应微软知识库中的KBNumber,通过该ID可以链接到富文本的知识原文;“文章标题”是知识原文的标题;“相关性评分”是式(15)的计算结果。请工程师评判检索结果,其中正确符合用户查询需求的知识用下划线加粗显示。
3.1.2 评估方法
与文献[4,10,12]中的知识检索方法对比检索结果的准确率Precision。文献[10]选择Doc2Vec作为语义分析模块,RM3作为查询扩展模块,相似度阈值设为0.6;文献[12]采用和本文方法相同的方式精调,实验时将工程知识元的CD属性合并为整段文本送入,准确率计算如下:
(16)
式中:P@N表示检索的推荐列表中前N项的准确率,P是Precision的缩写;TP为检索的推荐列表中符合用户查询需求的知识数量;FP为推荐列表中不符合用户查询需求的知识数量。
3.2 实验结果
3.2.1 自然语义相关性计算模块训练测试
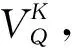

表2 不同预训练模型的检索准确率

从实验结果来看,两种mask方式的模型对整体检索性能的影响没有显着差异。这是由于字mask模型以中文字为单元,分词时会将一个完整的词切分为若干子词,全词mask模型则以完整的中文词为单元。而本文使用的软件开发领域知识库中,存在许多预训练模型未登录的专有词,全词mask模型中这些专有词会被歧义切分,降低了P@10和P@15的准确率。而P@20中全词mask的准确率略高于字mask,则是因为全词mask对通用中文词的完整切分,可以发现更多相关的长尾知识。总体来看,自然语义相关性为先验概率,修正概念语义相关性后,先验概率的决定性降低,同时受限于预训练模型对领域专有词的收录,两种mask方式的模型对本文知识检索性能的影响不显着。
3.2.2 与其他方法的对比
对比文献[4]基于关键词的方法、文献[10]基于本体概念推理的方法、文献[12]基于语言模型的方法和本文方法,记为BM25F,SELM,NDSSM,CNDSSM,实验使用10组用户查询,统计4种方法输出的P@10,P@15,P@20,结果如表3和图8所示。
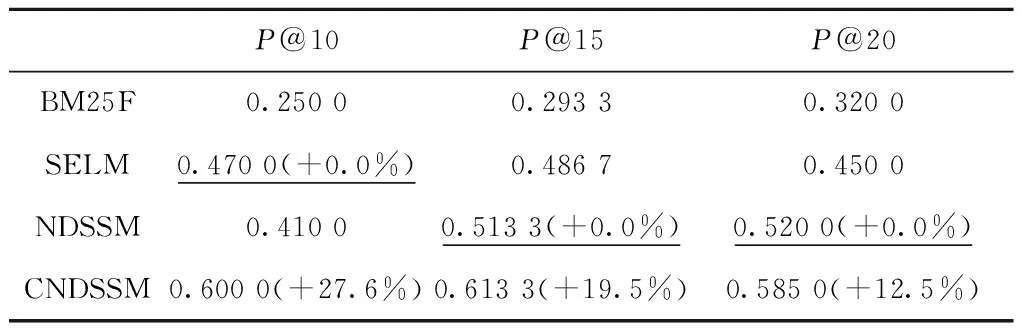
表3 4种语义检索方法检索结果的准确率
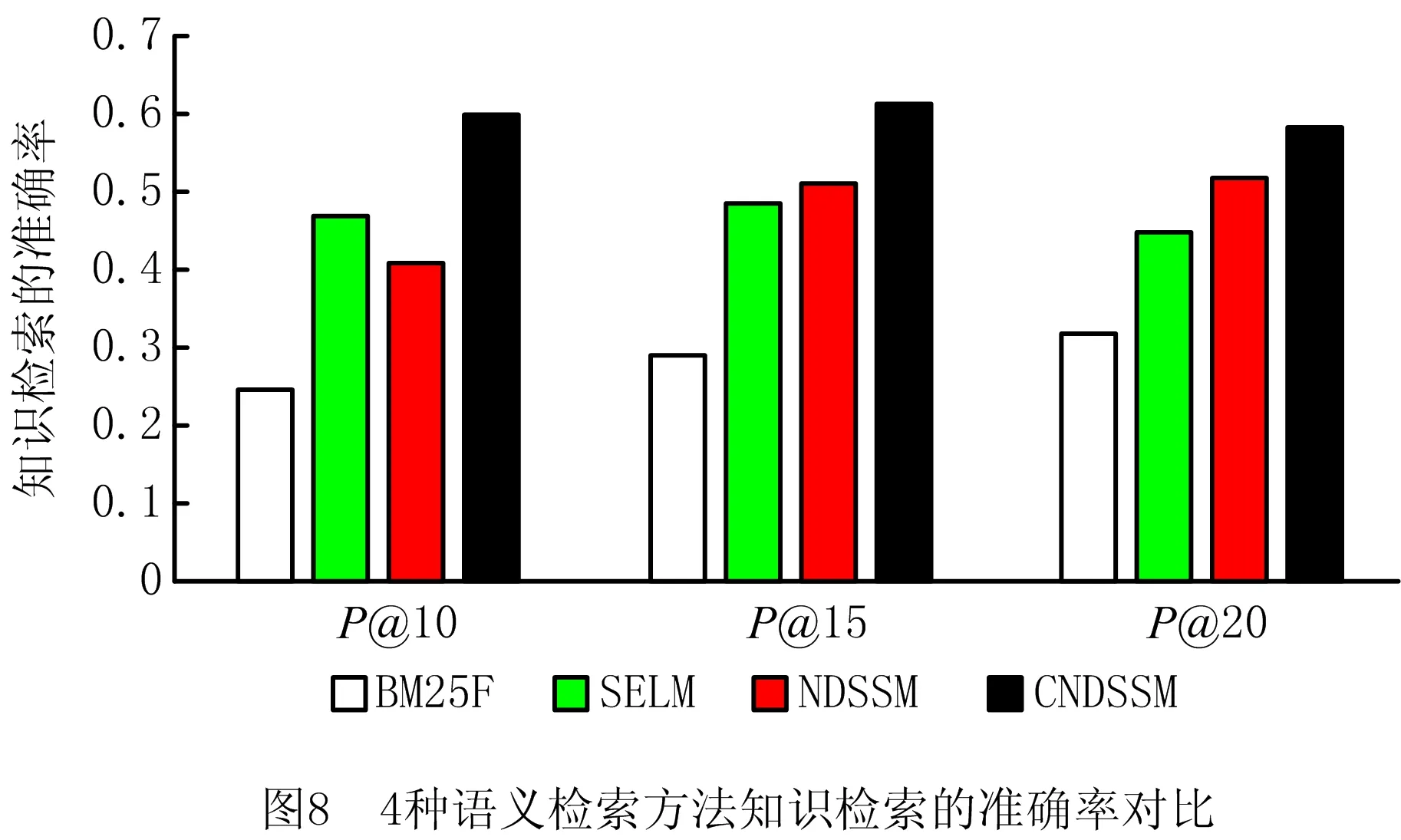
由对比试验可见,本文方法的工程知识检索准确率高于其他方法。SELM虽然同样基于概念知识进行上下文推理的语义检索,但是只使用了本体的单类概念语义,没有充分利用半结构化工程知识中复合概念语义信息和文本的自然语义信息,因此检索准确率低于CNDSSM方法。NDSSM是基于语言模型的交互式深度语义搜索方法,所用模型从自然表达的上下文判断两段文本的相关性,并未考虑工程知识产生上下文对相关性的影响,因此准确率低于CNDSSM方法。在取前10个最相关工程知识时(P@10),BM25F方法的准确率仅有0.25,CNDSSM的领先优势较P@20时更为显着,这是由于BM25F基于关键词进行匹配,受信息密度变化的影响,不能公平地计算不同类型知识与用户查询语句的相关性,在返回的推荐列表前部给出了更多长文本的工程知识。而CNDSSM在定制多文本域自然语义计算模块、解决长度问题的同时,利用工程知识元中的实体信息计算概念语义,提高了语义相关性评估的准确性。可以看出,采用本文提出的CNDSSM方法对软件开发中的工程知识进行检索时效果更好。
4 结束语
针对传统检索方法的不足,本文面向工业软件开发提出一种基于超网络模型的知识检索方法。该方法针对代码模块重用的现象,使用产品树表示语义关联;基于已知的概念知识抽取属性信息解决属性缺失的问题,并将多类型的工程知识规范化表征为适合机器处理的工程知识元;通过知识超网络表示复合的语义关联,将工程知识的产品情境、应用对象、知识内容3种信息整合到统一框架下,采用贝叶斯方法计算用户查询和工程知识的语义相关性。本文有两个特点:①针对半结构化工程知识的特点,设计了一种多信息域联合的实体识别方法,适用于工程知识的规范化表征;②基于预训练语言模型,设计了一种考虑知识类型的自然语义相关性计算模块,以在相关性推理中融合概念语义和自然语义,适用于工程知识库的检索。实验结果表明,本文方法有效利用了软件开发工程知识的深层语义,其准确率较其他语义检索方法提高了至少12.5%。
因为本文方法对不同类型知识的识别和处理还需人工干预,所以将其应用于载体类型复杂的异构知识库时难度较大。下一步研究将考虑更多的知识类型,从识别异构工程知识的通用性出发,捕获多维语义信息,扩展方法在不同工程场景下的应用。
