云边协同计算架构下大规模工厂接入的任务调度
2021-09-13满君丰赵龙乾李倩倩
满君丰,赵龙乾,彭 成,李倩倩
(湖南工业大学 计算机学院,湖南 株洲 412007)
0 引言
由李伯虎院士在云制造基础上提出的智慧云制造[1],基于泛在网络,以人为中心,借助信息化制造技术和智能科学技术等深度融合的数字化、网络化、智能化技术手段,使用户能够通过云制造服务平台随时随地按需获取制造资源与能力,进而智慧地完成制造全生命周期的各类活动。《中国制造2025》指出,智慧云制造的总体目标是实现制造过程的智能、高效、协同、绿色、安全[2]。
工业云与边缘计算是智慧云制造的关键技术之一,是时下热门的网络范例,涉及异构工业环境中的无缝连接,其通过将分布式工业设备聚集到一个公共资源池并调动这些工业设备来进行本地化生产制造。在工业环境下的云边协同计算中,信息流是信息动态交换的过程,其通过工业设备与网络、工业设备与基础设施、工业设备与工业设备之间信息的动态交互,实现协作数据传感和信息分析[3-4]。
传统的工业云方案缺乏高效的任务调度方法,难以适配先进工业生产过程中海量数据的实时分析和实时控制。任务调度亦是边缘计算系统中的重要问题之一,其目的是获得最佳的系统吞吐量和计算性能。传统的调度算法包括启发式调度算法、元启发式调度算法等,在启发式调度算法方面,最小完工时间调度算法虽然显著提高了总任务的完成率,但是调度器的计算资源和任务信息需要很高的维护成本;Min-min调度算法主要用于执行时间短的任务,但是容易造成资源负载不均衡。启发式调度算法没有考虑不同应用场景下的实际约束问题,其为启发算法的改进,是随机算法与局部搜索算法结合的产物,旨在发现最优或相对最优的解决方案。粒子群算法是一类典型的元启发算法,该算法在云计算任务调度领域可以获得更好的效果,主要缺点是不考虑用户预算;遗传算法根据优胜劣汰的规则,通过不断迭代产生新的最优解的近似解,但是在处理大规模组合问题时的效率较低。列表调度算法是异构系统下经典的调度算法,包括静态调度算法和动态调度算法。静态调度算法根据任务之间的优先级构造相应的调度列表,Sequential算法是典型的静态调度算法;动态调度算法根据处理器的使用情况和任务之间的依赖关系动态构造相应的调度列表,处理器关键路径(Critical Path on Processors, CPOP)算法是典型的动态调度算法。传统调度算法在高维度、高精度数据的处理和分析方面具有局限性,而云制造场景下的任务具有多种类、多模态、小批量等特征,因此传统调度算法难以解决云制造场景下的问题。以钣金行业为例,生产车间专注于钣金零件的自动化切割、冲孔、成形、剪切和嵌套过程,其生产队列中有20~200个作业可供调度,需要在工作链的上下游进行多站点协同和多任务并行,从而实现工厂车间的智能化集成应用。在未来的十年里,越来越多的制造企业将采用工业4.0模式实现全球协同化制造,而随着制造过程任务种类和任务规模的不断增加,亟需研究面向云边协同计算架构的大规模工厂接入任务调度方法,以有效提高任务执行效率,获得较好的云边协同效果[5-10]。
1 国内外研究现状及分析
近年来,人工智能在制造、交通、金融、医药等领域得到广泛发展。然而,随着机器学习和深度学习技术在云制造、无人驾驶等关键应用领域的深度渗透,国内外学者开始探索先进的云边协同方法来保证交互的实时性、精准性和高效性。HUANG等[11]提出利用最佳剩余空间比来完成云边协同任务,利用权衡模型将调度问题简化为线性规划问题,通过线性规划松弛给出了一个基于极值点求解的调度方案;WANG等[12]提出一种基于双图模型的动态调度算法(Dynamic Tasks Scheduling algorithm based on Weighted Bi-graph model, DTSWB),将调度问题转化为最优化双图匹配问题,建立了整数规划模型,通过任务卸载、信息收集、任务分配和资源匹配4步实现了高效的任务调度。然而,上述方案往往只适用于求解整数线性规划问题,其要求所有或部分决策变量都必须假定为非负整数,但是在实际的工业领域中,该解决方案过于理想,通过四舍五入得到的整数解会产生较大误差。针对上述问题,JIAN等[13]提出一种改进的混沌蝙蝠群算法,解决了传统的云计算调度算法在任务复杂度与系统性能之间的平衡问题,通过引入混沌因子和二阶震荡机制,提高了系统中动态参数的更新速度;WANG等[14]提出一种基于蚁群优化算法的多任务协同调度算法(Cooperative Multi-tasks Scheduling based on Ant Colony Optimization algorithm, CMSACO),算法考虑了任务利润、任务期限、任务依赖性、节点异构性和负载均衡等因素,通过将调度问题转化为约束优化问题找到一个可行解。然而蚁群算法涉及的参数较多,容易使初始值选取不当,同时采用单一的蚁群算法容易陷入局部最优,在处理大规模组合问题时效率较低,不能很好地解决连续问题,而且在选取信息素等相关参数时大多凭借个人经验,缺乏充分的理论依据。由于自身的局限性,LI等[15]将数据块的最优放置和任务的最优调度相结合,通过高效存储边缘端设备中的数据减少提交任务的计算延迟和响应时间。然而,上述方案均未考虑任务分配的硬件资源对处理时间的影响,以及未来应对大规模工厂接入智能制造系统的现实需求,本文针对实际大型制造业生产车间中部署的边缘端服务器和云端服务器协同作业的场景,给出了可靠的解决方案,并提出云边协同计算架构下大规模工厂接入的任务调度方法。
2 问题描述
随着工业组网技术的迅猛发展,终端设备数量快速增加,海量数据的分析和处理增加了工业云平台的运行负担,边缘计算的出现将部分计算任务从云端迁移到边缘侧,为云制造的普及和发展提供了有力的技术支撑。
2.1 有向无环图任务描述
根据工业物联网环境的要求,云边协同架构主要由远端服务器集群组成的云端部件和边缘端服务器集群组成的边缘端部件构成[16]。图1所示为云边协同计算架构的工作过程示意图。从具体业务上看,云端部件主要负责对终端设备所采集的数据进行重量级模型训练,边缘端部件进行轻量级模型训练,以减少模型训练的时间和网络时延,缩短系统的闭环响应时间,提高工厂设备整体的生产效率。


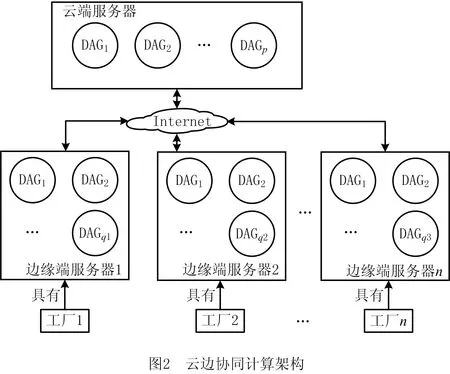
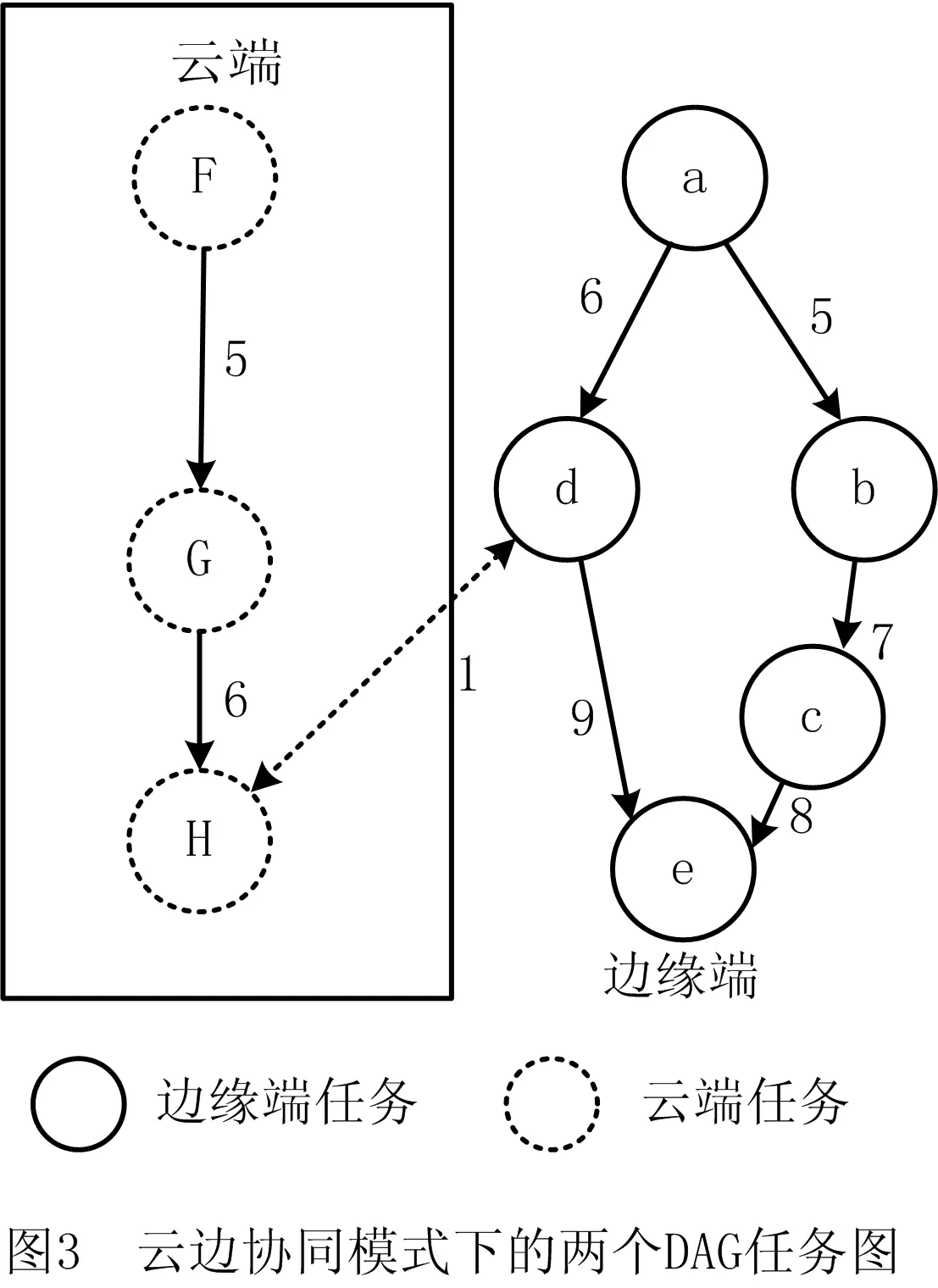
简单起见,本文假设某工厂部署的边缘端服务器中运行的一个任务与云端服务器中运行的一个任务有信息交换。图3所示为云边协同计算架构下的2个DAG任务图,云端部件下的DAG1中包含3个任务,边缘端部件下的DAG2中包含5个任务,2个DAG任务图共包含8个任务。其中:圆圈表示任务节点,云端部件和边缘端部件中的节点分别用虚点和实线表示,圆圈中的字母表示任务节点的编号,云端部件用大写字母,边缘端部件用小写字母,节点编号不区分大小写,例如圆圈中字母a表示任务节点ta,ta=tA。带箭头的实线边表示事件边,边上的数字表示两个任务之间的事件计算开销;带箭头的虚线边表示云端部件和边缘端部件的通信代价,边上的数字表示两个任务之间的通信延迟。每个DAG中包括1个入口任务节点和1个出口任务节点。考虑到不同任务的通信延迟,例如云计算的通信延迟约为100 ms,小型数据中心的通信延迟约为10 ms~40 ms,路由器的通信延迟约为5 ms,终端设备之间的通信延迟约为1 ms~2 ms[17]。这里通过time指令获得两个任务之间的事件计算开销。
2.2 资源环境
任务调度是一个在规定时间内将任务与资源进行匹配的过程。调度算法是在任务的时限要求和资源约束的条件上,找到一组能够有效提升应用程序处理速度的调度方案。云边协同计算架构下的调度资源由云端部件和边缘端部件共同组成,每个部件由多个性能异构的物理机组成,每个物理机又虚拟化出多个虚拟机。假设有m个物理机节点,每个物理机由k个性能异构的虚拟机组成,物理机之间通过网络互联。在每个物理机上,任务的执行与通信可以同时执行,分配到虚拟机上的任务之间的通信开销为0,任务的执行是非抢占式的。
2.3 任务调度目标
云边协同计算架构下DAG任务图调度是将相关任务分别调度到云端服务器和边缘端服务器中的处理器上执行。任务调度的目标包括以下方面:
(1)整个任务集在处理器上的执行时间makespan值尽可能小。
(2)针对边缘端服务器设计扁平化的调度策略,而不是通过云端服务器来统一管理。

(4)Slack表示松驰度,用于度量任务调度算法的鲁棒性,其反映一个任务调度算法所产生任务处理时间的不确定程度[18]。Slack的定义为
(1)
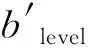
(5)不公平程度Unfairness(S)是用来衡量多DAG调度算法S不公平程度的重要指标[19],
Unfairness(S)=

∀a∈A。
(2)
式中:A为给定的多个DAG的集合;AvgSlowdown是所有Slowdown的平均值;Slowdown反映DAG的滞后程度,Slowdown(a)=Mmulti(a)/Mown(a)。
3 云边协同任务调度模型
3.1 云边协同模式下的多DAG合并
有别于传统的企业资源计划(Enterprise Resource Planning, ERP)、制造执行系统(Manufacturing Executive System, MES)等工业应用软件[20],工业大数据下的软件与产业链上下游会建立安全数据联系,以实现信息共享和知识互补。因此云边协同模式下的工业应用软件总体上可分为云边相离类任务、云边相交类任务、云边包含类任务3类。图4所示为云边协同模式下的任务调度关系图,其中图4a为云边相离类任务,即云端部件与边缘端部件中的任务互不干扰,无数据往来;图4b为云边相交类任务,即云端部件与边缘端部件中的任务互相通信,有数据交换;图4c为云边包含类任务,即云端部件中的任务是边缘端部件中任务的子任务,或者边缘端部件是云端部件中任务的子任务。
(1)云边相离类任务 该类任务的特点是云端部件和边缘端部件中的任务没有数据往来,合并的方法是增加一个虚拟的入口任务节点和出口任务节点,然后更新虚拟入口任务节点和出口任务节点与相关任务节点的通信延迟和计算开销,即
DAG_C=DAG_A∪DAG_B,DAG_A
≠DAG_B。
(3)
式中:集合DAG_A为DAG1;集合DAG_B为DAG2;集合DAG_C为DAG合并图。图5a所示为云边相离类任务的DAG合并图。
(2)云边相交类任务 该类任务的特点是云端部件与边缘端部件中的任务有数据交换,合并的方式是入口任务节点同时作为每个子DAG入口任务节点的父亲节点,然后通过替换实现DAG合并,
DAG_C=DAG_A⊕DAG_B,
DAG_A∩DAG_B。
(4)
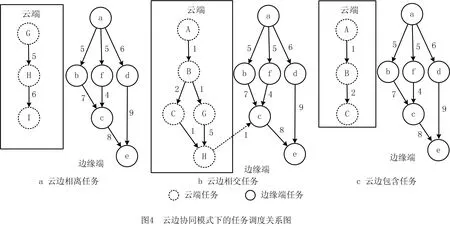
图5b所示为云边相交类任务的DAG合并图,其中虚线节点表示云端部件和边缘端部件为相同任务。
(3)云边包含类任务 该类任务的特点是云端部件中的任务为边缘端部件中任务的子任务,或者边缘端部件是云端部件中任务的子任务,因此通过式(5)实现DAG合并。图5c所示为云边包含类任务的DAG合并图。在实际云制造中,通过冗余的方式可以增强系统的健壮性[21]。
DAG_C=

(5)

3.2 云边协同模式下的多DAG分割
tES(j)为一个任务j的最早可能开始时间,任何一个任务都必须在其所有前驱任务全部完工后才能开始;tEF(j)为任务j的最早可能完成时间,即任务按最早开始时间所能达到的完成时间。计算公式为:
tES(j)=0;
tES(j)=maxk{tES(k)+t(k)};
tEF(j)=tES(j)+t(j)。
(6)
tLS(j)为一个任务j的最迟开始时间,即任务j在不影响整个任务如期完成的前提下,必须开始的最晚时间;tLF(j)为任务j的最迟完成时间,即任务按最迟时间开始所能达到的完成时间。计算公式为:
tLS(j)=maxk{tLS(k)-t(k)};
tLF(j)=tLS(j)+t(j)。
(7)
式(6)是由起始点向终点逐个递推的过程,式(7)是由终点向起始点逐个递推的过程,本文通过式(6)和式(7)找到DAG合并图的关键路径CP={cp1,cp2,…,cpm},m∈N。DAG合并图由关键任务集CTS和非关键任务集NCTS组成,其类型分为边缘端任务EST和云端任务CST,定义如下:
DAG=CTS+NCTS;
CTS=CTSEST+CTSCST;
NCTS=NCTSEST+NCTSCST;
{CTS,NCTS}=nEST+mCST,n∈N,m∈N。
(8)
DAG任务图的关键路径是进入任务到退出节点的最长路径,该路径上的每个任务为所有关键路径提供的最低成本。本文根据式(8)对合并后的DAG进行分割,图6所示为云边协同计算架构下DAG合并图的分割图,虚线箭头形成的路径为DAG合成图的关键路径,其中图6a为云边包含类任务DAG分割图,每个子图的度分别为{2,0,0,2};图6b为云边相交类任务DAG分割图,每个子图的度分别为{2,2,0};图6c为云边包含类任务DAG分割图,每个子图的度分别为{2,1,0}。

3.3 云边协同模式下的任务分配
本文提出的改进的异构最早完成时间(Improved Heterogeneous Earliest Finish Time,IHEFT)算法主要由权值分配、任务优先级分配、处理器选择3个阶段构成。假设用R表示处理器资源集合,R={CPUs,GPUs,FPGAs},GPUs是使用最广泛的加速器,FPGAs可以提供更好的性能功率比,它们在高性能计算等多个应用领域中发挥了重要的作用[22-23]。用无向图RG=(T,C)描述任务在不同处理器上的计算性能,其中T表示任务节点,C={c11,c12,…,cnm},n∈N*,m∈N*(n为任务个数,m为处理器个数)表示任务在不同处理器上的计算性能,则任务的平均计算性能
(9)
在任务优先级分配阶段,需要建立多源异构场景下的任务优先级列表。因为在实际云制造环境中,无论云端任务还是边缘端任务都具有任务的多种类、大规模、强关联等特征,所以原来任务之间边的权值不能准确反映云边协同计算架构下任务的优先级,需要根据DAG合并图关键路径的边的权值之和来确定云边协同计算架构下任务的优先级。根据优先级的值将云边协同计算架构下的DAG合并图降序排列,构成任务图列表,以便后期进行任务调度。云边协同计算架构下DAG合并图Dk的优先级rank(Dk)等于该图关键路径上所有事件边的权值之和,即
(10)
后续任务调度操作将从任务图列表具有较高优先级的任务图开始优先分配处理器资源。根据任务图列表构成相应的路径列表,路径pk的优先级
(11)
在云边协同计算架构下的DAG分割图中,云端子图有ξ个,其度值为o={o1,o2,…,oξ};边缘端子图有ζ个,其度值为o={o1,o2,…,oζ}。由此得到第i个任务图在调度执行时所需要的处理器数量
(12)
式中函数wj为采用云边协同计算架构下子图度的计算策略。通过DAG分割可以确定其资源集合类型,并在处理器分配阶段根据DAG分割所得结果向任务分配资源[24-25]。DAG分割后的任务集按IHEFT算法选择和调度处理器。
4 云边协同任务调度算法
为了充分利用云端和边缘端资源实现任务的高效计算,本文提出云边协同任务调度(Cloud and Edge Collaborative Task Scheduling, CECTS)算法,算法包括DAG合并、DAG分割、处理器分配3个步骤,其中DAG合并用于减少处理冗余任务带来的时间开销。
4.1 DAG合并算法
假设云边协同计算架构下有m个工厂,其中部署的边缘端服务器和云端服务器共执行n个任务,则DAG合并算法如算法1所示。
算法1DAG合并算法。
输入:DAG。
输出:MergeDAG。
1: function Merging(DAG):
2: while DAGi∈DAG且i∈{1,2,…,m}do
3: while SubDAGj∈DAGi且j∈{1,2,…,n}do
4: MergeDAGj=SubDAGj
5: if(MergeDAGj≠SubDAGj+1)
6: MergeDAGj=MergeDAGj∪SubDAGj+1
7: if(MergeDAGj∩SubDAGj+1)
8: MergeDAGj=MergeDAGj⊕SubDAGj+1
9: if(MergeDAGj⊆SubDAGj+1)
10: MergeDAGj=SubDAGj+1
11: if(MergeDAGj⊇SubDAGj+1)
12: MergeDAGj=MergeDAGj
13: end if
14: end while
15: return MergeDAG
16: end function
算法第2~15行根据DAG任务图子图的类型对边缘任务集和云端任务集进行合并操作,包括云边相离、云边相交、边缘端任务包含云端任务、云端任务包含边缘端任务4种情况。算法的时间复杂度为O(n),空间复杂度为O(1),而且工厂数越多,其优点越明显。
4.2 DAG分割算法
本文采用关键路径算法对所得到的DAG合并图进行分割处理,并将分割后的任务分为关键任务集和非关键任务集两类,其分割规则如算法2所示。
算法2DAG分割算法。
输入:MergeDAGj。
输出:CTSj,NCTSj。
1: function Partitioning(MergeDAGj,CP(MergeDAGj)):
2: N←order tasks based on level
3: whileN is not empty do
4: while ti∈MergeDAGj且i∈{1,2,…,ξ+ζ} do
5: if(ti∈CP(MergeDAGj))
6: add task tiin CTS
7: remove task tifrom N
8: else
9: add task tiin NCTS
10: remove task tifrom N
11: end else
12: end if
13: end while
14: return CTSj,NCTSj
15: end function
算法第2行遍历每个DAG合并图获得节点个数,第3~14行对DAG合并图进行分割处理,将属于关键路径的任务置于关键任务集,不属于关键路径的任务置于非关键任务集。该算法的时间复杂度为O(n),空间复杂度为O(1),而且任务数越多,其优点越明显。
4.3 处理器分配算法
本文采用IHEFT算法对所得到的DAG分割图进行任务调度处理,并按关键路径权重之和rank(Dk)对DAG任务图进行排序,得到云边协同计算架构下不同工厂的优先级列表;将每个工厂的任务按rank(pk)排序,然后将任务分配到ϖ个处理器上。处理器分配算法如算法3所示。
算法3处理器分配算法。
输入:CTSj,NCTSj。
输出:rank(Dk)j,rank(pk)j,ϖj。
1: function IHEFT(CTSj,NCTSj):
4: if task tiis the last task then
5: rank value of ti=its average execution time
6: else:
8: end if
9: Sort the DAG in a scheduling list by descending order of rank(Dk)jvalues
10: Sort the tasks in a scheduling list by descending order of rank(pk)jvalues
11: Assign task tito the best processor base on ϖjlist
12: return set of processors with the mapping tasks, rank(Dk)j, rank(pk)j
13: end function
算法第2行遍历每个DAG分割图的任务节点,计算每个任务在处理器上的平均计算性能,第3行计算DAG合并图关键路径的边的权值之和,第4~8行计算DAG分割图路径的优先级,第9行按任务图优先级降序排序,第10行按路径优先级降序排序,第11行将任务分配到最佳的处理器上,第12行返回映射任务的处理器集等相关信息。该算法的时间复杂度为O(1),空间复杂度为O(1),而且任务数越多,其优点越明显。
5 仿真实验与结果分析
5.1 实验目的
为了验证本文CECTS算法,在相同实验条件下与Sequential和CPOP算法进行比较,主要比较任务跨度makespan、任务平均等待时间AWT和平均Slack值。
5.2 模拟环境
基于SimGrid提供的模拟器工具包,构建一个异构多核处理器仿真环境[26]。实验使用的计算机配置为Intel Core i5-7200U CPU @ 2.5 GHz 2.7 GHZ处理器,8 GB内存。
5.3 任务调度过程分析
采用云边协同计算架构,假设云端服务器和边缘端服务器中运行的任务如图7所示,以下详细分析CECTS算法进行多DAG任务图的合并、分割,以及在分布式异构计算环境下的处理器分配过程。

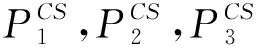
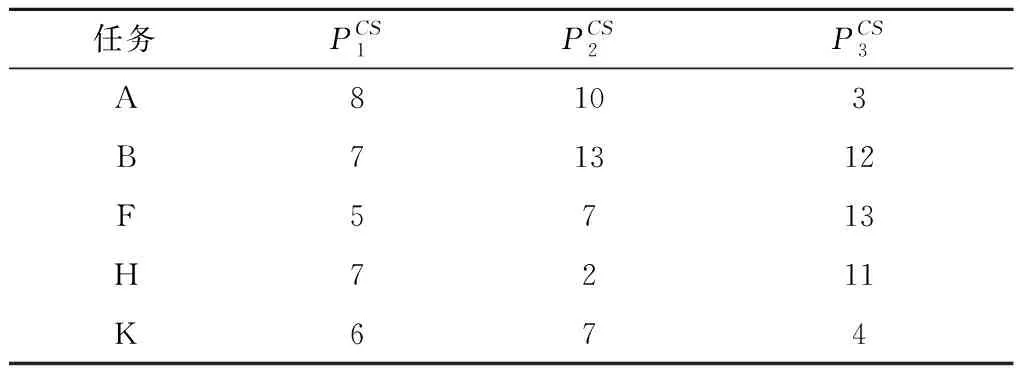
表1 DAG1任务集在处理器集上的调度时间

表2 DAG2任务集在处理器集上的调度时间
由于DAG1和DAG2为相交类任务,根据DAG合并算法可得DAG任务图合并图(如图8a),根据DAG分割算法可得DAG任务图分割图(如图8b),根据DAG处理器分配算法可得处理器资源平均利用率(如表3)。

5.4 实验结果分析
CECTS算法的时间复杂度为O(n),采用某鼓风机现场采集的实际数据进行分析,可知与传统集中式遍历方式相比,CECTS算法具有优越性。图9所示为边缘端服务器数量增加对计算时间开销的影响。
由式(11)可得DAG任务图分割图子图的度为{2,0,3},即将云边协同计算架构下的云端任务分配到2个处理器上,边缘端任务分配到3个处理器上。

任务集经过CECTS算法调度后,任务与处理器的对应关系如图10所示,图10a和10b分别表示同一任务集在不同网络环境下的调度策略。图11a和图11b所示分别为同一任务集通过Sequential和CPOP算法调度的结果。由图10和图11可知,CECTS算法的任务平均执行时间为54 s,Sequential算法的任务平均执行时间为97 s,CPOP算法的任务平均执行时间为61 s。同时可见,在减少任务执行时间的情况下,CECTS算法可以减少处理器的使用数量,图10中云端处理器的使用个数为2个,图11b中云端处理器的使用个数为3个。


系统的处理器利用率是实时系统运行性能的重要指标,其可以表征系统的时间特性和任务状态[27],表3所示为3种算法的处理器资源平均利用率。可见,采用CECTS算法的处理器资源平均利用率最高。
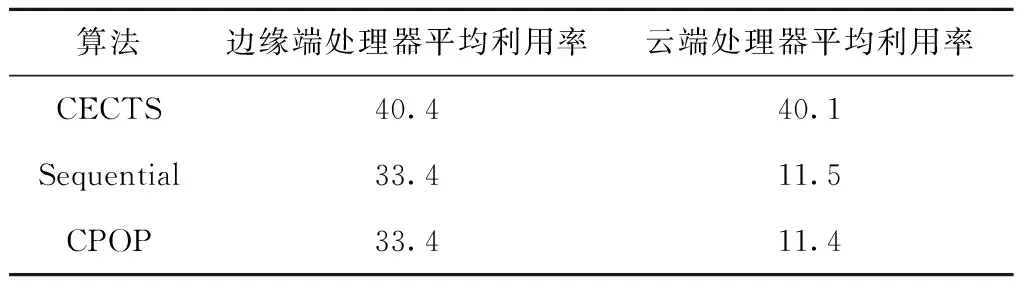
表3 3种算法的处理器资源平均利用率 %
分别采用3种算法对10个DAG任务图进行调度,表4所示为3核处理器下3种算法Slack值的对比情况。分别采用3种算法对DAG任务图模型进行调度,得到所有任务的跨度、平均等待时间和平均Slack值,如图12所示。

表4 CECTS,CPOP,Sequential算法的Slack值
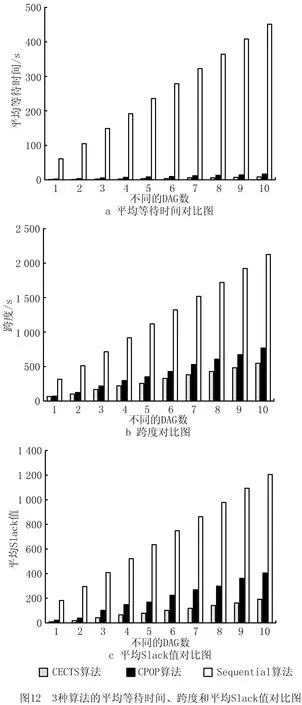
从实验数据可见,随着DAG数量的增加,任务调度的跨度和任务平均等待时间均会相应增加。总体来说,CECTS算法的性能最佳,CPOP算法其次,Sequential算法最差。在任务调度的跨度方面,CECTS算法比CPOP算法最低降低17%,最高降低28%;CECTS算法比Sequential算法最低降低74%,最高降低80%。在平均任务等待时间方面,CECTS算法比CPOP算法最低降低47%,最高降低54%;CECTS算法比Sequential算法最低降低96%,最高降低97%。在平均Slack值方面,CECTS算法比CPOP算法最低降低52%,最高降低63%;CECTS算法比Sequential算法最低降低84%,最高降低93%。
调度算法的公平性用于表明多个DAG任务图调度算法的可靠程度,是反映该算法能否公平处理不同优先级别任务需求的重要指标。图13所示为CECTS算法和CPOP算法的公平程度,其中CPOP算法比CECTS算法最低提高了106.25%,最高提高了176.92%,CECTS算法的方差为0.001 246,CPOP算法的方差为0.006 462,而且随着任务图数量的增加,CECTS的稳定性更好。

任务完成率定义为任务完成的数量与任务总数的比值,更高的任务完成率能够带来更好的服务质量。通过比较CECTS算法与Min-min算法、DTSWB、CMSACO,得到任务完成率对比图,如图14所示。可见,当任务数在60个以内时,CECTS算法、DTSWB、CMSACO都能保持较好的任务完成率,Min-min算法因负载不均衡导致任务完成率只有80%左右;当任务数达到80个时,DTSWB和CMSACO的任务完成率均明显降低,分别为78.2%和77.4%;当任务数为100时,DTSWB的任务完成率只有53.2%,而本文CECTS算法的任务完成率为89.7%,具有较好的稳定性。

负载率表示使用处理器资源的利用率,定义为处理器使用的数量与其总数的比值。提升负载率有助于加快任务的处理速度,从而提高服务质量。图15所示为CECTS算法、DTSWB和CMSACO的负载率对比图,可见,当任务数量达到一定规模时,CECTS算法、DTSWB和CMSACO都能保持较好的负载率;当任务数量在30个以内时,DTSWB和CMSACO因负载不均衡导致负载率只有80%左右,而CECTS算法的负载率为96%左右,具有较好的稳定性。
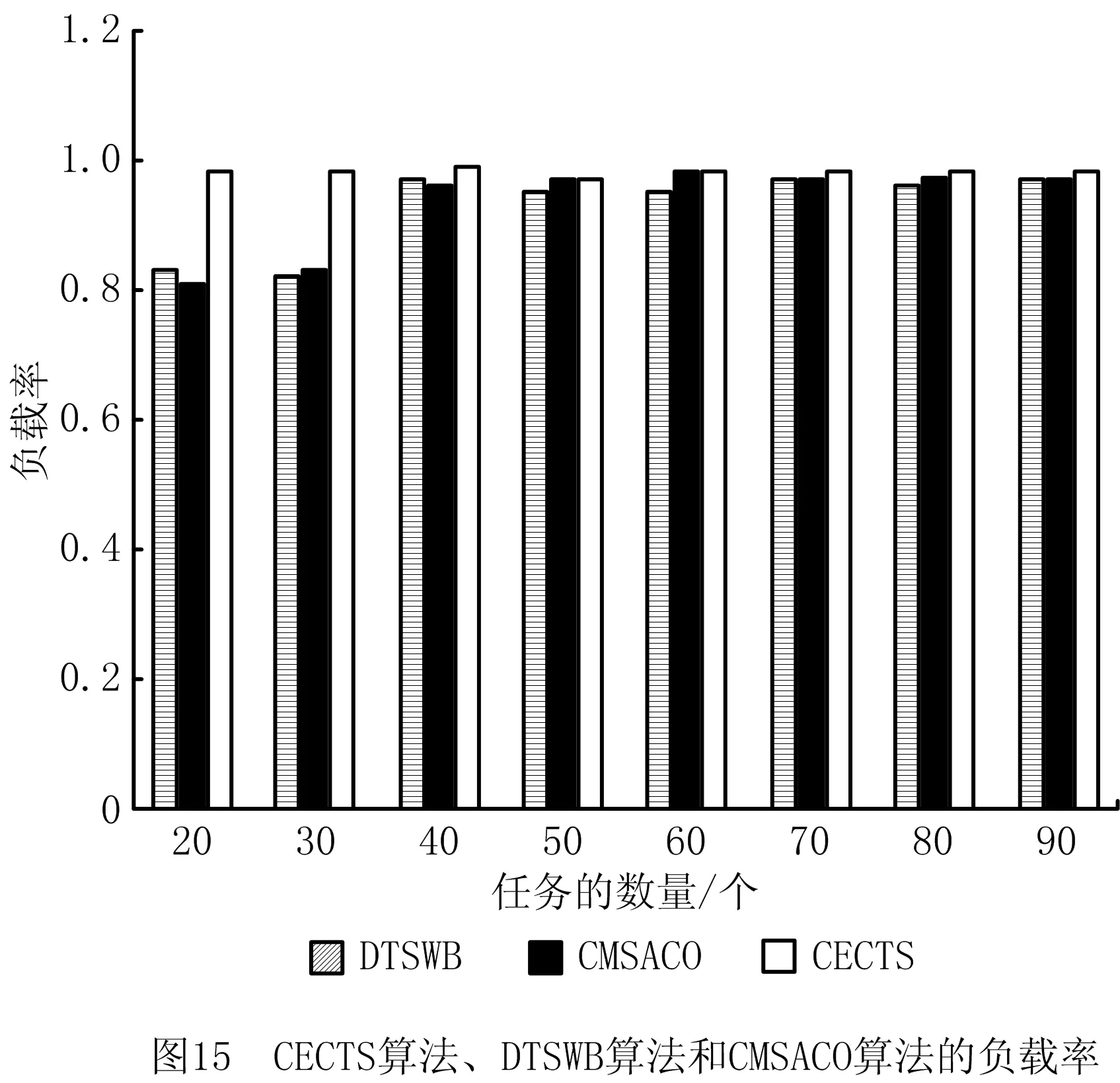
通过以上实验分析可知,CECTS算法在平均任务等待时间、平均Slack值两方面均优于CPOP算法和Sequential算法;在算法的公平程度方面,CECTS算法具有较高的公平性,且随DAG数量的增加保持了较好的稳定性。通过比较CECTS算法、DTSWB和CMSACO可知,本文CECTS算法在任务完成率和负载率方面均有比较突出的优势。
6 结束语
随着网络信息技术的不断发展,以智能制造为主导的新型工业模式得到广泛应用,本文针对云制造场景,给出云边协同计算架构下大规模工厂接入的任务调度方法,通过多任务图合并、任务图分割和处理器分配3个步骤对复杂场景下的任务调度问题进行求解。仿真结果表明,与其他调度算法相比,本文提出的CECTS算法可以减少处理冗余任务的时间开销,并按云边协同方式将任务调度到合适的处理器上,在整体上提高了任务处理的速度,从而使任务在大规模边缘端服务器资源受限的情况下得到更高效的处理。
考虑存在特定需求、设备作业期间的突发事件及未知用户对系统的影响,下一步将改进和细化需求分析模型,在获取真实数据后,对本文方案的有效性进行评估,并进一步提高算法性能。另外,还将深入研究边缘侧设备协同作业的任务调度方案,以对本文工作进行补充。
