一种基于3因素概率图模型的长尾推荐方法
2021-09-13冯晨娇王智强梁吉业
冯晨娇 宋 鹏 王智强 梁吉业
1(计算智能与中文信息处理教育部重点实验室(山西大学) 太原 030006) 2(山西财经大学应用数学学院 太原 030006) 3(山西大学经济与管理学院 太原 030006)
互联网时代,伴随电子商务的迅猛发展,推荐系统日益受到广泛的关注.一方面,推荐系统能够给用户提供其可能感兴趣的商品、服务等各类信息,进而有效提升用户的信息获取效率.另一方面,推荐系统可以帮助商家有效分析用户偏好,从而增加商品销售数量和销售种类.自1992年邮件过滤系统Tapestry问世以来,推荐系统已渗透于各个领域,包括:娱乐性的电影、音乐、游戏等;内容性的个性化新闻、文档推荐、网页推荐等;电子商务性的书籍推荐、商品推荐等;服务性的旅游推荐、房屋租赁推荐等;社交性的朋友推荐等.随着这些应用系统的有效推广,推荐方法的研究受到了学术界与工业界的广泛关注.
推荐方法中,用户评分是数据建模的重要基础.然而,在现实的推荐场景中,用户给予项目的评分或者选择项目的频次是一个典型的长尾现象,符合帕累托定律.推荐系统中,所谓长尾是指长尾项,俗称冷门项目,最早由Anderson[1]提出.其区别于冷启动问题,冷启动问题是指针对新用户或新项目的推荐,而长尾项或者说冷门项目是指只有少数人给予评分的项目.
在电子商务等应用场景中,长尾项有其独特的价值,并日益受到重视.文献[2]指出对长尾项的推荐是推荐系统有效性的重要评测指标.一方面,长尾项往往是用户独有的兴趣,对长尾项的抓取是提升个性化推荐精度的关键所在;进一步地,长尾推荐可以给用户带来不同程度的惊喜度和满意度[3-4].另一方面,对于商家来说,长尾推荐是其收益提升的重要途径.文献[5]指出亚马逊网站30%~40%的图书销售业绩源自于那些难以在实体店发现的书目,在此基础上,文章进一步强调长尾商品是支撑电子商务业绩增长的重要驱动力.文献[6]以亚马逊网站200类图书为样本,开展了长尾商品的推荐效应研究,结果表明,最冷门的20%图书商品可实现50%的业绩增长.文献[7]指出推荐系统的设计不应仅仅关注热门商品,面向长尾商品的推荐系统研究可有效提高冷门产品的销售业绩,进而实现商家的利润最大化.
事实上,稀疏性是制约推荐系统性能提升的重要影响因素.特别地,对于长尾项而言,其数据稀疏程度更加凸显.因此,从现有研究进展来看,诸多成果通过增加信息源来缓解数据稀疏问题,进而开展长尾推荐研究.文献[8-12]利用用户信息(如社会网络、用户属性、用户评论和文本挖掘)或产品属性等额外的信息源来挖掘用户的个性化偏好和长尾项之间的关系.另一方面,相关研究成果通过引入多样性指标提升系统的新颖性推荐性能,进而促进长尾项的推荐效果[13-15].从推荐方法研究路径来看,现有成果已由单一追求预测精度向“准确性+新颖性”综合考量的方向发展,相应地,其在一定程度上促进了长尾项的推荐.然而,多样性指标尚缺乏统一的度量,且其和准确性、新颖性之间的内在关联也存在不同的观点[16-18],因此,多样性指标的非一致性问题也给长尾推荐建模带来了新的困惑.
与以往研究不同,本文试图在不引入额外信息源的基础上,同时回避多样性指标的非一致性问题,将影响长尾项推荐的3个因素引入概率图模型.其中,3个因素分别是用户活跃度、项目非流行度和用户-项目偏好水平.在实际的推荐场景中,从用户视角来看,与新用户或非活跃用户相比,活跃用户更倾向于选择一些冷门项目,因此,用户活跃度是长尾项推荐的重要影响因素之一;从项目视角来看,项目的非流行程度决定了其是否归属于长尾项目,相应地,项目非流行度自然是长尾推荐的重要影响因素之二;从用户对项目的评价视角来看,偏好水平越高,越可能表明用户对该项目具有个性化偏好,而长尾项目往往是用户个性化偏好的现实表现,因此,用户-项目偏好水平则是长尾推荐的重要影响因素之三.基于上述分析,本文引入前述3个因素构造二项分布随机变量,在概率图模型框架下构建了一个新的长尾推荐方法,进而实现推荐精度与新颖性的相对均衡.
1 相关研究
早期的长尾推荐多采用聚类方法开展相关研究.文献[8]通过评分数目的多少将所有的项目分为长尾项和热门项,在此基础上,基于项目属性对长尾项聚类,通过同一类中长尾项评分的共享,增加长尾推荐中可用的评分数目,进而运用已有的预测模型进行推荐.文献[9]进一步对文献[8]方法进行了改进,提出一个自适应聚类方法.其与文献[8]方法的主要区别在于不再硬性划分长尾项和热门项,而是通过评分数目的自适应聚类实现长尾推荐.然而,文献[9]方法仍然面临着聚类个数难以确定、初始类中心点选择困难等问题.
近年来,诸多成果基于多样性、新颖性、相似性等指标的设计与改进来促进长尾项目的推荐.文献[13]基于3个目标实现推荐列表的优化,即提高准确性、提升多样性以及降低项目流行度.其中,给出的多目标优化问题通过模拟退火算法进行问题求解.文献[15]给出一种“资源”分配策略,即给予高评分项目与非流行项目相对均衡的推荐机会,进而在保持一定推荐准确性的同时,增加推荐方案的多样性,并提高长尾推荐效果.文献[19]基于推荐结果准确性与多样性的权衡,提出了一种多目标进化推荐方法,在此基础上可获得一组推荐方案的帕累托解,相应地,特定的目标用户可根据其行为偏好在若干推荐列表中进行选择.文献[20]提出了一种在保证推荐精度的同时降低推荐集中度的策略,即用评分和流行度指标的加权得到新的推荐排序指标.文献[21]提出了一个长尾推荐的多目标框架,在此框架下,设计了2个相互冲突的目标函数,分别刻画推荐方法的准确性与新颖性,进而基于相应的多目标进化算法构建推荐生成策略.可以看出,现有的推荐方法不再单纯追求准确率的提升,而是寻求准确性、多样性、新颖性等不同视角融合的折中(trade-off)推荐方案.
总体来看,诸多学者基于聚类、多目标优化等方法开展了长尾推荐方法研究,并在一定程度上提升了长尾项目推荐的效果.然而,聚类算法中,聚类个数设置、初始中心点选择等共性难题制约了其在实际中的应用.类似地,多目标优化算法中全局最优解、帕累托解的求解也仍然是其难点所在.特别是长尾推荐中存在的典型的数据稀疏问题,使得上述算法的有效求解变得更加困难.从现有研究进展来看,概率图模型因其可对真实世界中存在的依赖关系提供具有可解释性的数据建模与问题求解路径而逐渐受到重视.尤其对于推荐系统而言,“算法黑箱”是其饱受诟病的重要因素,相应地,长期以来,推荐系统的可解释性研究一直是学术界与工业界共同关注的问题.因此,基于概率图模型的推荐方法因其在可解释性方面的优势而日益受到重视[22-24].然而,从已有成果来看,鲜有研究基于概率图模型开展长尾推荐的算法设计.进一步地,本文试图以可解释性为切入,基于用户、项目及其关联关系,提出基于用户活跃度、项目非流行度和用户-项目偏好水平的3因素概率图模型,进而在准确性、新颖性之间给出相对均衡的长尾项目推荐生成策略.
2 长尾推荐方法
本文基于概率图模型开展长尾推荐研究.概率图模型(probabilistic graphical model,PGM),简称图模型,是指一种用图结构来描述多元随机变量之间条件独立关系的概率模型.图模型通过假设已知观测变量条件下隐变量的条件分布,来表达2类变量之间的关系,并对变量及其潜在结构给出一种可视化表示.该模型中的条件分布,通常被称为后验概率.然而,这个后验概率往往难以直接计算.一般地,机器学习和统计方法通常利用KL(Kullback-Leibler)散度将后验概率分布求解转换为其近似分布的求解,这里的近似分布称为变分分布,相应地,其推断方法称为变分推断[25].为了减少变分推断的计算复杂性,现有研究成果通常利用平均场理论,给出含有未知参数的隐变量的变分分布假设.这种近似推断策略将一个难以计算的后验概率问题转化为求解分布中未知参数的优化问题.
2.1 模型中变量描述
推荐系统中主要包括用户、项目及评分3部分.具体地,rij为第i个用户对第j个项目的评分.评分通常采用5分制,1分代表最弱的偏好,5分代表最强的偏好.为了方便,本文将项目集分为热门项目集和长尾项目集.事实上,用户对项目的评分数值通常由用户对项目的行为偏好所决定,因此,推荐系统的首要环节就是对用户的行为偏好进行建模.进一步地,由于不同用户的评分尺度往往不同,且不同项目其质量也不相同,因而,建模时则需考虑用户偏置与项目偏置.相应地,用户活跃度、项目非流行度等作为长尾项推荐的重要影响因素,其在建模时也需考虑活跃度偏置与流行度偏置.因此,在构建长尾推荐模型之前,本节首先给出模型中的相关变量描述.
对于第i位用户:
对于第j个项目:
对于每一个评分rij:
1)xij=1表示用户ui评价过的项目yj是长尾项目,xij~Bernoulli(σ(dicjzij)),其中σ(·)表示sigmoid函数,其中x=(xij)m×n.xij受3个因素影响:
① 第i位用户的活跃度di.用户活跃度越大,即用户越活跃,其评分项目越可能是长尾项.


2.2 3因素概率图模型
面向长尾推荐的3因素概率图模型(three-factor based probabilistic graphical model,TFPGM)是生成模型.图1为该模型的板块表示.图1中节点表示随机变量,实心节点是观测变量,空心节点是隐变量;有向边表示概率依存关系;矩形表示重复,其中的数字表示重复次数.
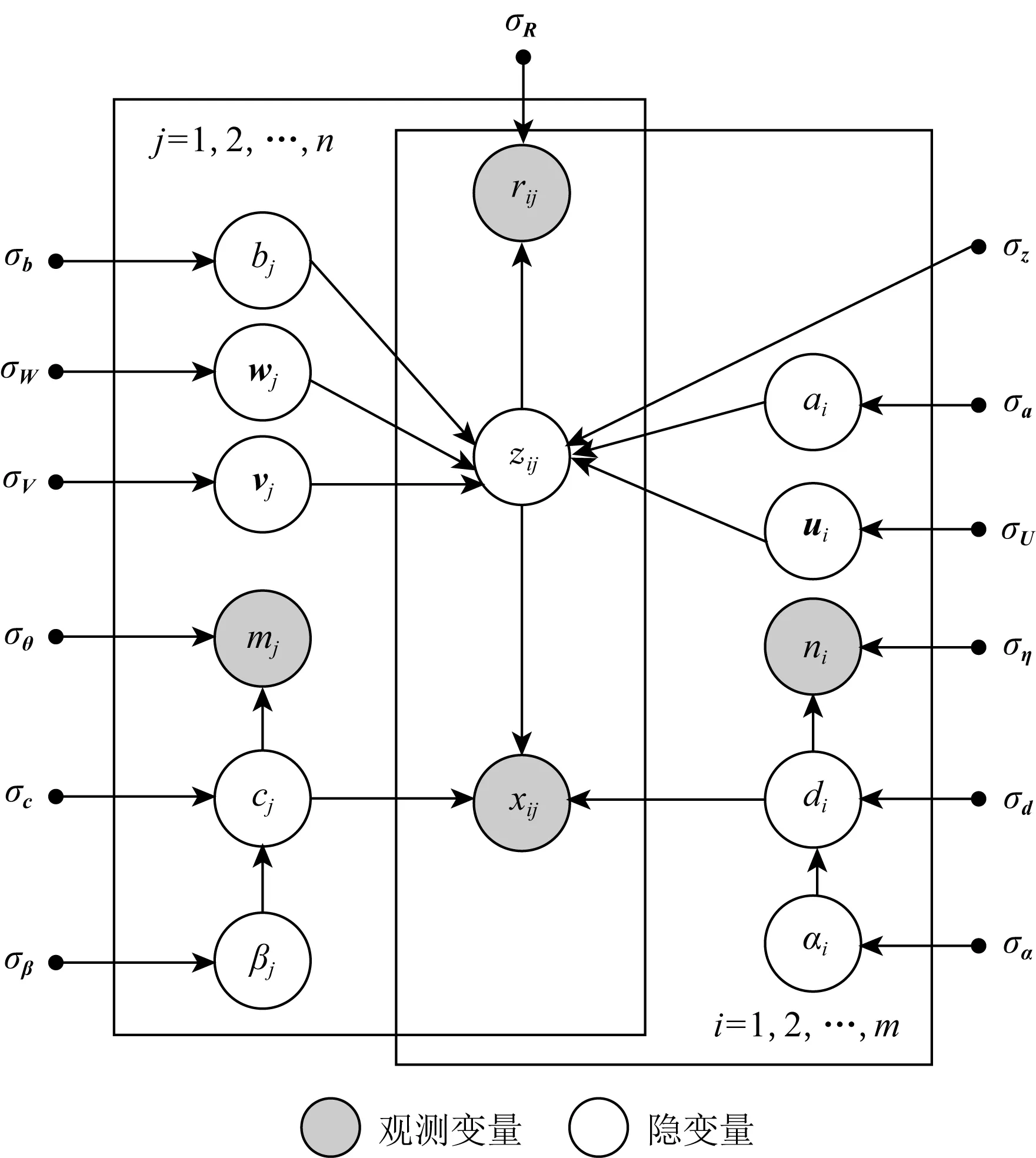
Fig.1 Three-factor based probabilistic graphical model图1 3因素概率图模型
TFPGM模型的具体生成过程为:
1)用户偏置ai、项目偏置bj、用户潜在特征向量ui、热门项目潜在特征向量vj和长尾项目潜在特征向量wj共同生成连续型隐变量zij,进一步地,zij生成可观测评分rij.
2)用户活跃度di、项目非流行度cj和用户-项目偏好水平zij这3个因素共同作用生成xij.
3)用户活跃度偏置αi生成用户活跃度di,活跃度di生成可观测比值ni.
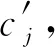
模型是以观测变量和隐变量组合的联合概率分布,设为p(R,x,η,θ,a,b,c,d,U,V,W,α,β),其中R,x,η,θ是观测变量,z,a,b,c,d,U,V,W,α,β是隐变量.为了方便起见,记为Θ,联合概率分布简记为p(R,x,η,θ,Θ).σR,σz,σa,σb,σU,σV,σW,σθ,ση,σc,σd,σα,σβ是超参数.目标是学习模型的后验概率分布p(Θ|R,x,θ,η),在此基础上进行概率推断.但是由于该模型含有多个隐变量,直接计算后验概率分布是困难的,所以采用变分推断方法用变分分布q(Θ)近似后验分布.其目标变换为寻找q*(Θ)使得KL散度D(q(Θ)‖p(Θ|R,x,θ,η))达到最小.为了降低计算复杂度,通常利用平均场理论给出q(Θ)的含有未知参数的概率分布.由变分推断理论,KL散度达到最小等价于证据下界最大[22].证据下界为
L(q)=Eq(lnp(R,x,θ,η,Θ))-Eq(lnq(Θ)),
其中,Eq表示关于q(Θ)的数学期望.故此,首先建立联合概率分布

其中,Iij是示性函数,Iij=1表示有评分,Iij=0表示评分项缺失.其次,根据平均场理论及变分推断,本文建立了一个隐变量之间相互独立且分布来自于正态分布的变分分布

设Ξ={μzij,Λzij,μui,Λui,μai,Λai,μdi,Λdi,μαi,Λαi,μvj,Λvj,μwj,Λwj,μbj,Λbj,μcj,Λcj,μβj,Λβj}是q(Θ)的参数,即变分参数.
最后,定义证据下界
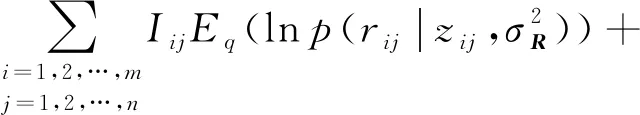
其中
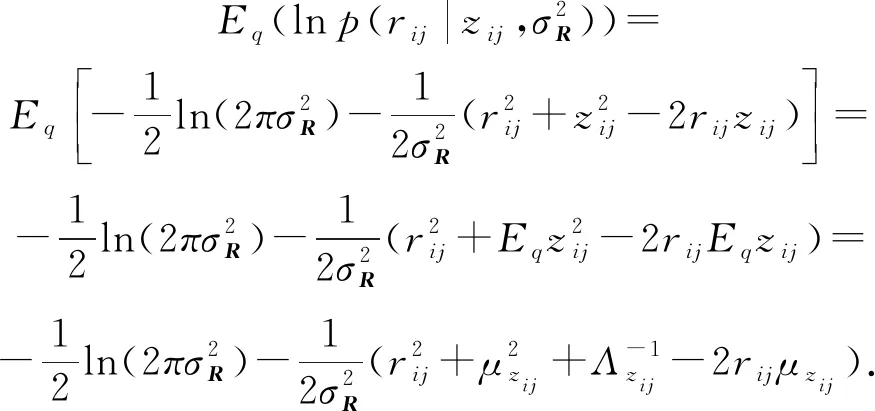
(1)
同理:
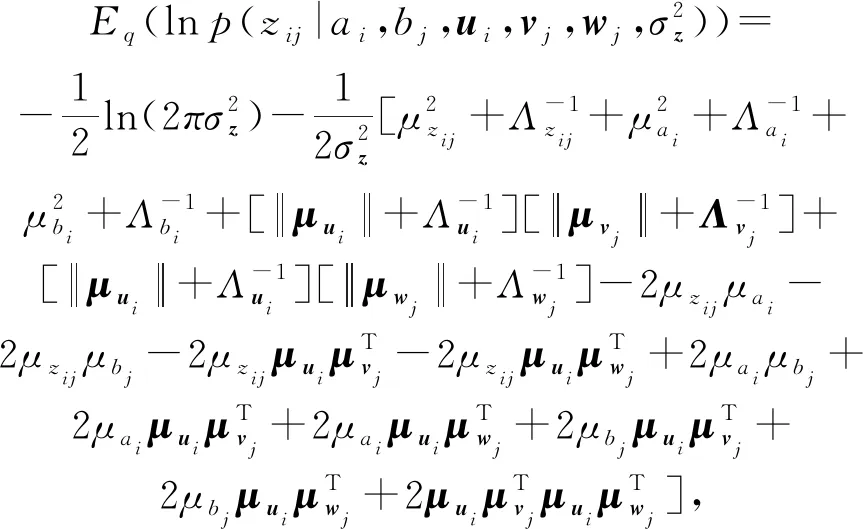
(2)

Eq(lnp(xij|σ(dicjzij)))是Bernoulli-log似然,利用文献[26]中的不等式:
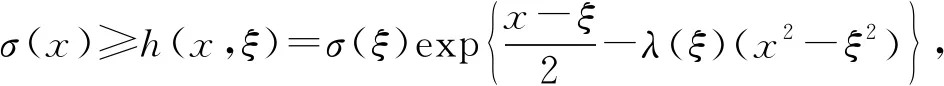
可以得到相应的下界:

(3)
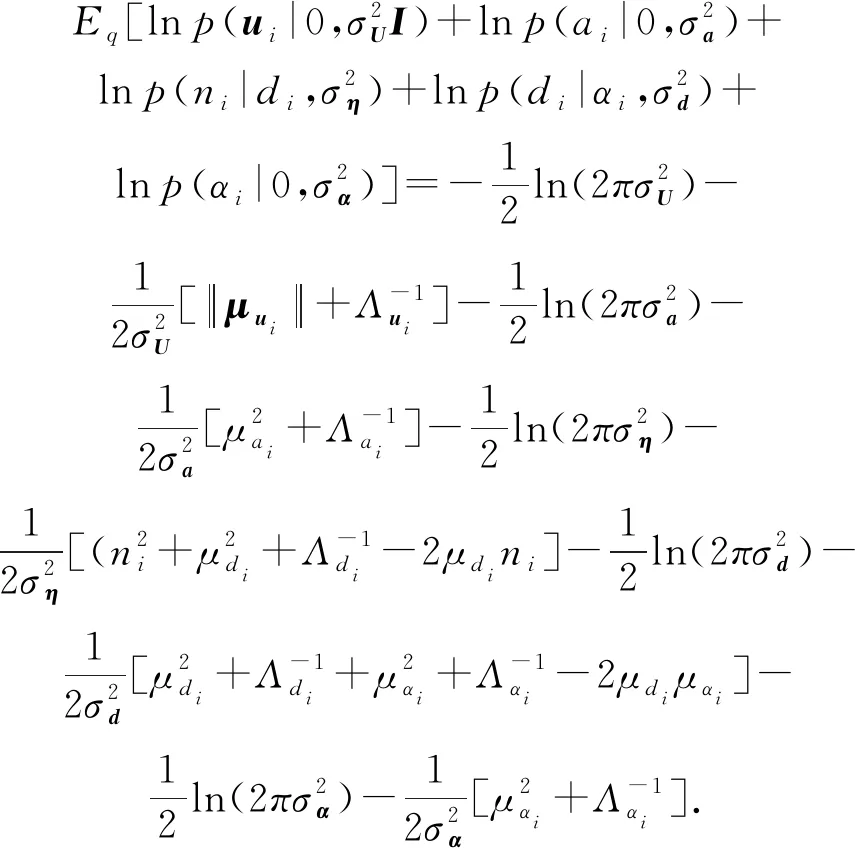
(4)
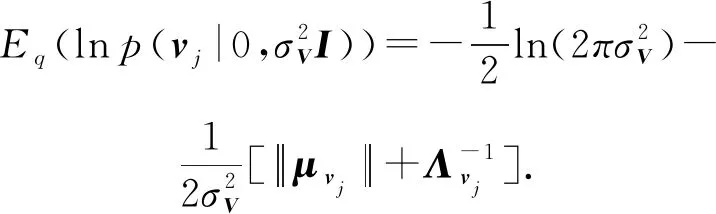
(5)

(6)

(7)

(8)

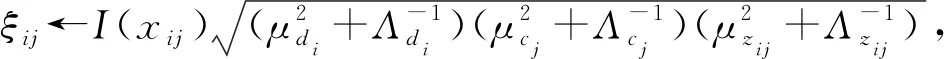
(9)

(10)

(11)
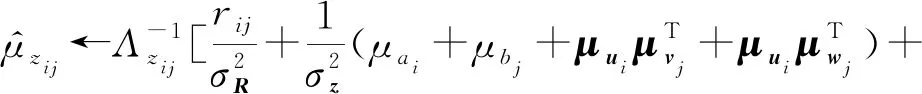
(12)
再迭代更新第i位用户的全局变分参数Λui,μui,Λai,μai,Λdi,μdi,Λαi,μαi:

(13)
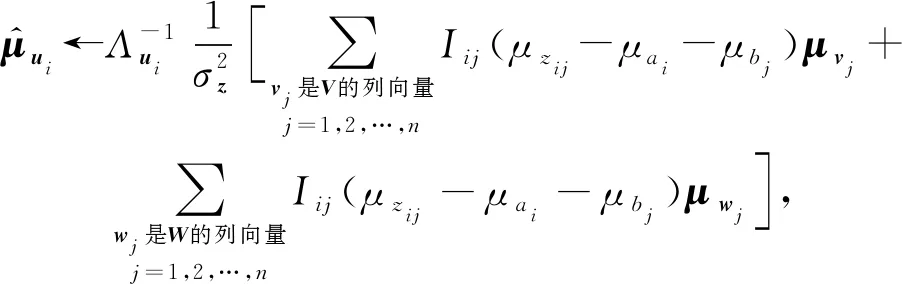
(14)

(15)

(16)

(17)
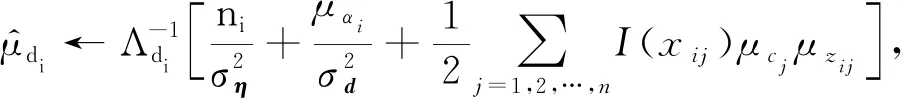
(18)

(19)

(20)
最后迭代更新第j个项目的全局变分参数Λvj,μvj,Λwj,μwj,Λbj,μbj,Λcj,μcj,Λβj,μβj:
(21)

(22)

(23)

(24)

(25)
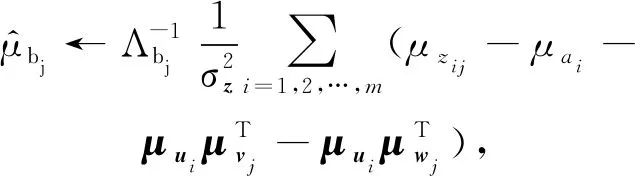
(26)
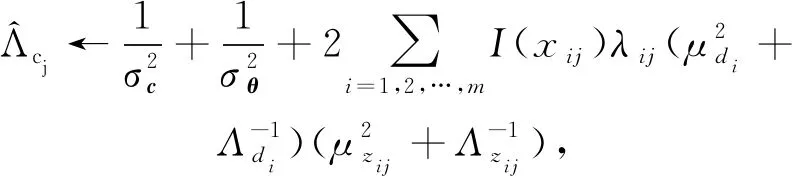
(27)
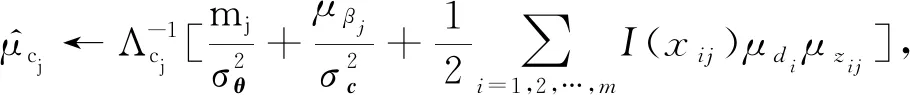
(28)
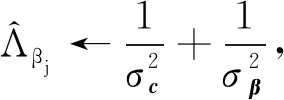
(29)
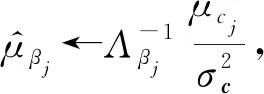
(30)
直至收敛.其中I(xij)表示示性函数,即当xij=1时取1;当xij=0时取0.
基于上述思想及相关计算,变分推断的长尾项推荐方法的步骤如算法1.
算法1.长尾项推荐变分算法.
输入:可观测评分R、长尾示性矩阵x、更新步长ρ、迭代次数iter_num;
输出:变分参数Ξ.
① 随机初始化全局变分参数
② whileiter ③iter=iter+1; ④ forrij是R的元素 ⑤ while不收敛 利用式(9)~(12)计算ξij,λij,Λzij,μzij; ⑥ end while ⑦ end for ⑧ fori=1,2,…,m ⑨ end for ⑩ forj=1,2,…,n (31) 本节引入实验需要的数据集;介绍了代表准确性、多样性和新颖性的评价指标;引入了TFPGM及其对比算法开展实验比较分析. 本文选择了3个数据集ML-100k,ML-lm(1)https://grouplens.org/datasets/movielens/,Film-Trust(2)https://www.librec.net/datasets.html.上述数据集中的评分均是以5分制给出,即最高为5分,最低为1分.数据集ML-100k中有943个用户对1 680个项目给出的100 000个评分,数据集密度为6.3%.数据集ML-lm中有6 040个用户对3 952个项目给出的1 000 209个评分,数据集密度为4.19%.FilmTrust数据集包括1 508个用户对2 071个项目给出的35 497个评分,数据集密度为1.14%. 本文利用巴莱多定律(也叫二八定律)将项目分为热门项目和长尾项目.其方法是将项目按照评分数量由高到低排列,取后20%的项目为长尾项目[27].按此方法,ML-100k,数据集中评分数量少于6个的项目是长尾项;ML-lm数据集中评分数量少于14个的项目是长尾项;FilmTrust数据集中评分数量少于2个的项目是长尾项. 本文选择了5个指标,具体包括:与准确性相关的平均绝对误差(mean absolute error,MAE)、均方根误差(root mean squared error,RMSE)、召回率(Recall)、与多样性相关的平均列表内距离(in list distance,ILD)[28]、与流行度相反的新颖性(Novelty)[21],用于刻画长尾推荐性能.具体公式为 其中,|·|表示集合中元素的个数;Rtest表示5折交叉验证法中随机选择出的1折测试集;Ii表示面向第i位用户推荐的前k个物品集合,I表示面向所有用户推荐的前k个物品集合;Ti表示测试集中面向第i位用户推荐的物品集合;d(i,j)表示第i个项目和第j个项目的距离,本文采用余弦距离;Li表示第i位用户的topN列表,Uj表示评分过项目j的用户集合.这5个指标中,MAE,RMSE表示预测评分的准确率,衡量预测评分与真实评分之间的误差,该值越小,误差越小.Recall表示topN推荐预测的召回率,该值越大,说明预测的topN和真实的topN之间越一致.上述3个准确性指标的计算均采用5折交叉验证方法.ILD表示推荐结果的多样性,该值越大,推荐的覆盖面越大.Novelty表示推荐结果的平均流行度,该值越小,推荐结果越新颖.为了降低随机初始化导致的误差,本文在计算ILD和Novelty指标时,重复10次取平均值. 为了说明本文方法的有效性,选择了其他经典方法作为对比实验,具体有: 1)概率矩阵分解(probabilistic matrix factori-zation,PMF)方法[22].PMF是已知用户评分,给出用户潜在特征和项目潜在特征的后验概率,并以对数后验概率最大化为目标函数得到用户潜在特征矩阵和项目潜在特征矩阵的估计值,最后通过两者的内积来预测未知评分.该方法的核心参数是潜在特征空间维数,本文设为30. 2)k近邻推荐(knearest neighbor recommen-dation,kNN)方法[29].kNN是利用目标用户近邻的项目评分的加权平均值作为预测评分,此方法的核心是近邻的确定和权重的设置.本文均以皮尔逊相关系数为依据给出近邻和权重,且采用基于用户的近邻推荐.该方法的核心参数是近邻数,本文设为30. 3)基于变分推断的概率图模型(probabilistic graphical model based on variation inference,PGMVI).事实上,图2所示的概率图模型在推荐系统中更多地称为矩阵分解模型.一般地,由于矩阵分解其最终目标函数是二次函数,因此,通常采用梯度下降法求解.需要说明的是,由于3因素概率图模型的复杂性(如2.2节所示),本文采用了变分推断求解参数.与此相对应,本文针对图2的矩阵分解模型引入变分推断算法,其预测公式为 (32) Fig.2 Probabilistic graphical model图2 概率图模型 该模型与TFPGM涉及到的参数在表1中列示.由于2个模型有共同的参数,为了清晰地比较2个模型的效果,令相同参数的取值一致;考虑表1的简洁性,TFPGM方法中与PGMVI相同的参数不再重复列示.不同算法迭代步长均为0.3,迭代100次,变量初始化采用相同的策略. Tabel 1 Parameter Settings表1 参数设定 本节通过5个评价指标在3个数据集上运行4种算法来进行对比研究.本文提出的方法是在适当保持准确性前提下,提高推荐新颖性.为了便于比较,本文将实验结果如表2所示. Tabel 2 Performance Comparison of Different Recommendation Methods表2 不同推荐方法在性能上的比较 从表2可以看出,在准确性方面,kNN方法在MAE,RMSE取到最优值的情况最多,PGMVI,TFPGM的表现稍差;而召回率指标上,在3个不同的数据集,PGMVI,TFPGM,PMF分别是最优.在多样性方面,各种方法则没有表现出明显的优势.如前文所述,“多样性可优化精确性”[16]“多样性提升需以精确性为代价”[17,20]导致的非一致性问题为推荐系统建模带来了新的困惑,而本文实验结果中多样性指标表现出的不确定性也进一步印证了其存在的非一致性问题.在新颖性方面,TFPGM在所有数据集上均达到最优,其次是PGMVI,且TFPGM,PGMVI显著优于kNN和PMF.实验结果验证了变分推断方法对长尾推荐的有效性.进一步地,从新颖性指标来看,TFPGM优于PGMVI,这归功于模型中添加的3因素变量,其在推荐方法中起到了促进长尾推荐的作用. 需要着重强调的是,PMF在准确性指标MAE,RMSE上的效果稍差.其原因在于,本文在整体实验部分采用了准确性与新颖性的折中策略[18],即对新颖性的追求在一定程度上损失了精度.为了更好地说明这一问题,以PMF为例,表3列示了“精度优先”策略、“精确性与新颖性折中”策略的实验结果. 从表3可以看出,精度优先策略下,PMF在3个数据集上的MAE,RMSE指标均表现出较好的性能,但在新颖性指标上则表现较差;折中策略下,PMF在3个数据集上的新颖性指标均表现较好,而在准确性方面则表现较差.事实上,从现有研究成果来看,准确性与新颖性的均衡特性具有普遍性[18,21,30],因此,本文的实验分析均采用折中策略. Tabel 3 Performance Comparison of PMF Based on Two Strategies表3 PMF基于2种策略的性能比较 新颖性作为长尾推荐的重要评价指标,表2表明,PGMVI和TFPGM在新颖性指标上明显优于PMF和kNN.为了进一步比较PGMVI和TFPGM方法在新颖性指标上的差异,本节取top 3,top 5,top 7,top 10的不同推荐场景对上述2种方法的长尾推荐性能进行对比. 图3~5分别给出了PGMVI和TFPGM方法在3个数据集的4种推荐场景下的比较结果.可以看出,TFPGM均优于PGMVI方法.实际上,2种方法的关键区别在于3因素概率图模型从用户、项目及其关联关系3维视角引入了长尾推荐的重要影响要素.进一步比较2种方法的预测式(31)(32),相对于概率图模型而言,3因素概率图模型预测公式中包含参数μwj.由于参数μwj受到μdi,μcj,μzij的影响,这使得如果参数μdi,μcj,μzij数值较大,则μwj的值较大,相应地,在topN推荐中其对应的评分项则更容易被推荐.同时,由于上述变分参数恰好是3因素di,cj,zij的变分参数,因此,当参数μdi,μcj,μzij数值较大时,xij=1的概率也较大,即增加了长尾项目推荐的可能性. Fig.3 Comparison of Novelty on ML-100k图3 Novelty在ML-100k数据集上的比较 Fig.4 Comparison of Novelty on ML-1m图4 Novelty在ML-1m数据集上的比较 需要进一步说明的是,尽管本文方法是准确性与新颖性的均衡调节,但其在准确性上也表现出相应的优势.为了更清晰地展现不同的topN推荐场景下4种方法的推荐精度,本文以Recall指标为例,分别在top 10,top 100,top 200,top 300,top 400,top 500的不同推荐场景下进行了实验比较.图6~8表明,在3个数据集上,随着推荐项目数量的增加,所有算法的召回率持续增加;在ML-100k和Film-Trust中 PGMVI和TFPGM有明显优势,在ML-1m中4种方法差异不大.可见,本文提出的TFPGM方法,在保证一定精度的前提下提高了推荐的新颖性. Fig.6 Comparison of Recall on ML-100k图6 Recall在ML-100k数据集上的比较 Fig.7 Comparison of Recall on ML-1m图7 Recall在ML-1m数据集上的比较 Fig.8 Comparison of Recall on FilmTrust图8 Recall在FilmTrust数据集上的比较 本文面向推荐场景中的长尾现象,以提高推荐系统的可解释性为切入,着眼于用户、项目以及两者之间内在关联的统一性,基于用户活跃度、项目非流行度、用户-项目偏好水平3个长尾推荐的重要影响因素,提出了基于概率图模型的长尾推荐方法.4种方法、3组数据集、5个评价指标的比较实验,验证了本文方法在推荐准确性与新颖性之间的均衡调节作用.本文研究成果对于提升长尾推荐性能、发现用户个性化偏好具有重要的科学价值,在电商网站、社交媒体等各类推荐场景中具有广泛的应用前景. 需要说明的是,本文的长尾推荐方法仅考虑了用户对项目的评分矩阵信息,未来研究中可以围绕社交网络等多源信息的引入,进一步挖掘用户的个性化偏好,进而给出更加优良的长尾推荐方法.此外,进一步挖掘多样性与准确性、多样性与新颖性之间的内在关联,也值得继续深入探讨.
2.3 概率推断


3 实验结果与分析
3.1 数据集
3.2 评价指标

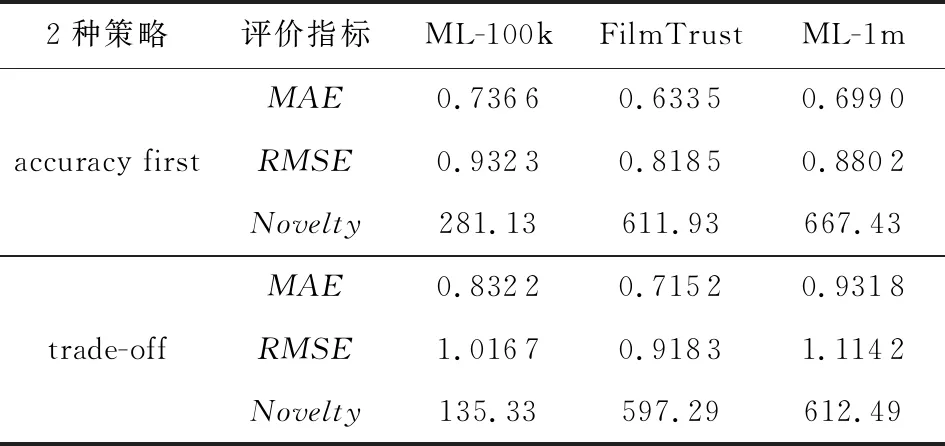
3.3 对比实验



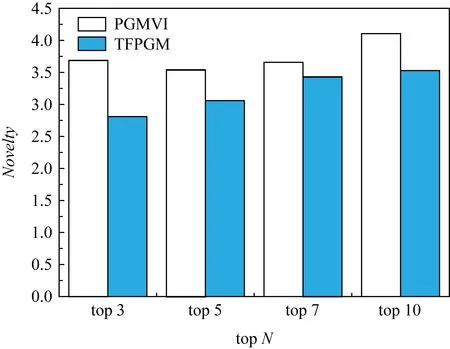
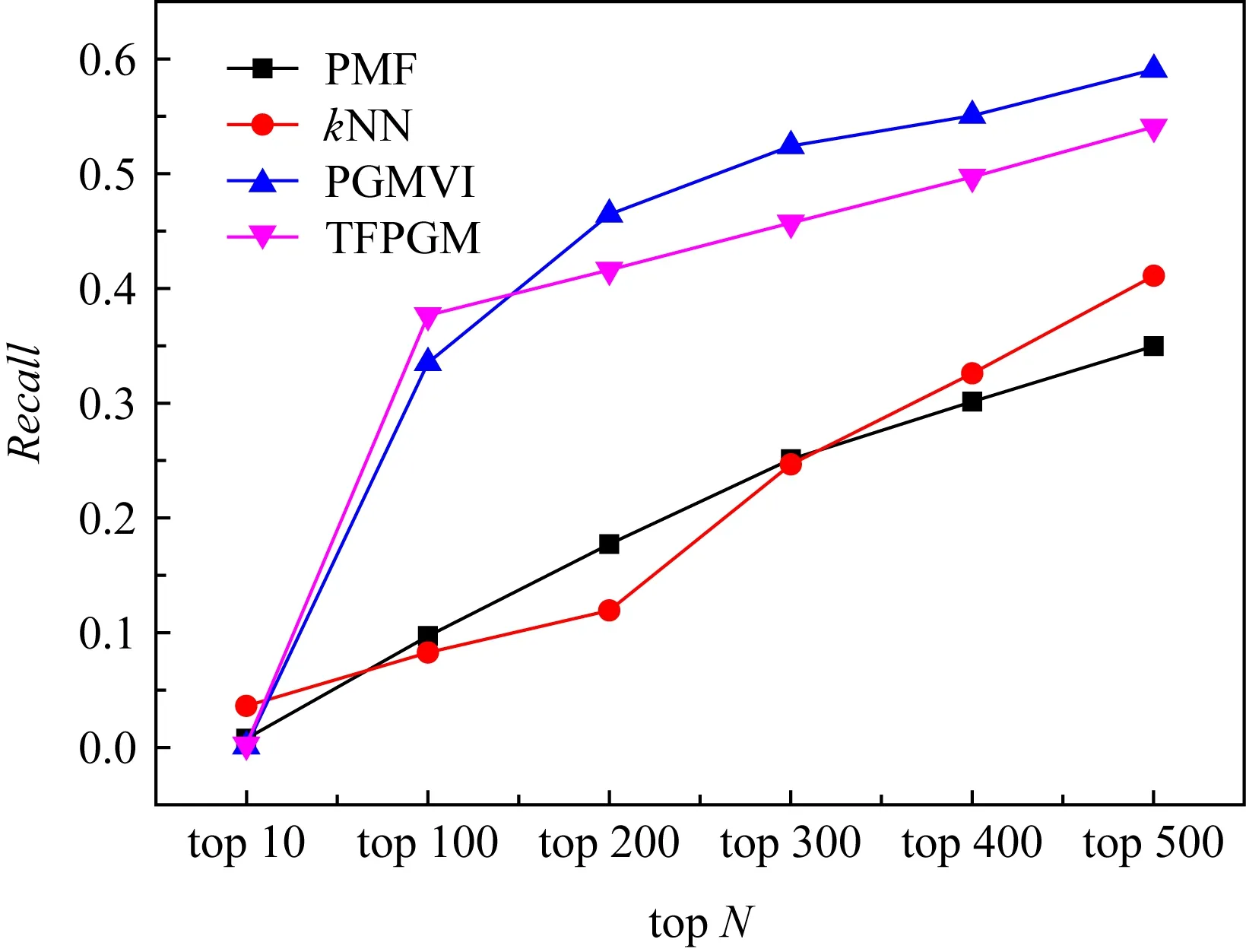
3.4 实验结果分析




4 总 结
