基于深度卷积神经网络的樱桃分级检测
2021-09-12张永飞裴悦琨姜艳超魏冉周品志
张永飞,裴悦琨*,姜艳超,魏冉,周品志
(1.大连大学辽宁省北斗高精度位置服务技术工程实验室,辽宁 大连 116622;2.大连大学大连市环境感知与智能控制重点实验室,辽宁 大连 116622)
樱桃的大小反映了其质量水平,樱桃果梗的有无对保鲜时长至关重要,果梗缺损会导致其内部水分流失,加上其干枯和腐烂,会进一步影响到樱桃的品质。品质的好坏不仅影响着产品本身的价值,而且直接影响消费者的购买欲望,间接影响果农的经济收入。因此,对樱桃尺寸和果梗的实时检测研究很有必要。传统的樱桃检测方法主要是利用人工和机械进行分拣。人工分拣时会因疲惫、个人的主观意识不同产生误差,不仅费时费力、效率低,而且会影响分级的质量。采用机械分拣的方法大多是通过设计专门的硬件结构来检测水果的大小和质量[1],然而这些方法不仅会对樱桃表面造成损伤,而且分级误差较大。因此,采用机器视觉技术进行水果的实时检测分级是实现水果自动化分级进而商品化的关键性一步[2-3]。
近些年来,由于机器学习方法的引入,使得水果分级检测的准确率和检测速度得到了很大程度的提高[4]。朱坚民等[5]提出一种新的水果特征提取方法,利用该方法使得水果的检测速度和准确率得到了显著的提升。张玉华等[6]根据水果的特征信息进行分类训练,采用信息融合法将水果内外部特征信息融合,建立基于多传感器多信息融合的水果分级模型。苟爽等[7]利用草莓R、G、B通道灰度值标准差和平均值作为评价成熟度的特征参数,采用机器学习进行网络的训练,分级准确率高于90%。张青等[8]研究了草莓质量和形状在线分级的问题,采用阈值分割法提取草莓的周长和面积参数,利用多元线性回归分析建立草莓质量分级模型,质量分级准确率为89.5%,形状分级正确率为96.7%。余杨[9]针对苹果自动分级筛选能力低下的问题,提出了一种新的苹果外观多特征分级方法,综合分级方法准确率为95%,处理速度为7帧/s。Momin等[10]基于全局阈值彩色二值化处理图像算法,采用中值滤波和形态学分析方法将芒果分为大、中、小3个质量等级。对于草莓形状尺寸分级,Oo等[11]提出了一种简单有效的自动估计和分类的图像处理算法,利用该方法对草莓果实的二维图像进行直径、长度和顶点角的估计。结果表明,在没有花萼遮挡的草莓直径和长度估计精度分别为94%和93%,有花萼遮挡的草莓直径和长度估计精度分别为94%和89%。马本学[12]提出一种利用数学形态学方法对香梨果梗进行自动提取的新方法。肖爱玲等[13]采用了基于图像形态学的一种快速检测骏枣果梗方法对骏枣分级系统中果梗有无进行判别,检测速度平均为0.45 s/个,果梗识别准确率为92.7%,有无果梗误判率为0。综上所述,基于对水果形状、大小和有无果梗的检测方法,模型比较单一,只针对一种特定的水果适用,在检测不同类型目标的时候,需要设计不同的对象表征模型,且算法受周边环境的影响较大。
由于人工分拣和传统的图像处理方法面临检测速度和环境影响的局限性,樱桃的分级检测未在工业现场广泛应用。目前,卷积神经网络已是图像处理领域核心算法,由于其强大的特征提取能力已经广泛应用于人脸识别[14-16]、自动驾驶[17-19]、安防[20-23]、食品[24-25]等领域。然而,卷积神经网络目前一般用于分类,用于点的回归研究较少。因此为了满足樱桃分级系统的实际需求,本文提出基于深度学习的关键点检测算法对樱桃尺寸和有无果梗进行检测,能够实现实时检测,达到更高的准确率和更小的误检率,以期提升樱桃分级检测的自动化水平。
1 网络模型结构
本文提出的基于深度卷积神经网络的樱桃大小分级和有无果梗的检测模型的网络结构如图1所示。

图1 模型结构图Fig.1 Model structure diagram
网络结构主要包括输入层、模块1、模块2、全局平均池化和输出层。模型采用的是全卷积网络结构,利用反卷积层对最后一卷积层的特征图进行上采样,使其恢复到与输入图像相同的尺寸,从而可以对每一个像素都产生一个预测,同时保留了原始输入图像中的空间信息。网络输入为R、G、B三通道图像(三原色R表示红色,G表示绿色,B表示蓝色,像素大小为416×416),使用深度卷积层自动捕捉樱桃的关键点信息,能够提取有效信息并提高模型的训练速度。模块1中的残差连接可以增加网络深度,使得特征映射对输出的变化更加敏感,模型拥有更强的表达能力;模块2采用步长为2的卷积层缩小特征图谱尺寸,使其成为更低维表征;为了对整个网络在结构上达到正则化、防止过拟合,该模型采用了全局平均池化代替了全连接层,直接剔除了全连接层中黑箱的特征,赋予了每个通道实际的意义。基于特征提取网络得到特征向量进行全局平均池化,建立4个分支用于上、下、左、右4个关键点坐标的回归,形成了最终的特征表示,建立端到端的樱桃关键点检测。
模块1由2个3×3卷积和1个1×1卷积组成,并采用了残差连接,如图2所示。
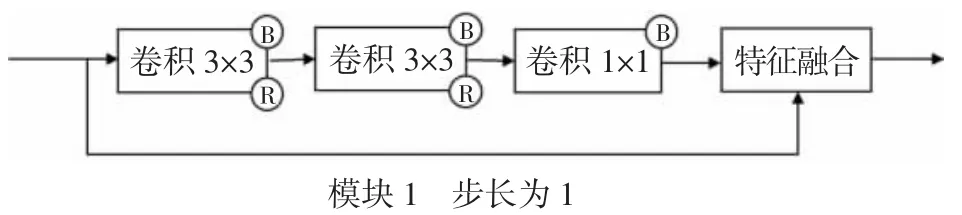
图2 残差连接块Fig.2 Residual connector block
残差连接能够保证网络的深度,使得特征映射对于特征信息更加敏感,而且又能减缓深层网络的梯度消失。模块2由1个3×3卷积和1个1×1卷积组成,无残差连接,如图3所示。

图3 无残差连接块Fig.3 Residual-free connector block
3×3卷积步长为2取代池化操作降低特征维度,减少参数量,提升运算速度。经全局平均池化形成最终的特征向量后,由4个分支分别对上、下、左、右4个关键点坐标进行回归,最终分别计算上下两点之间和左右两点之间的欧氏距离,通过与设定的阈值进行比较,从而达到分级的目的。在进行关键点回归的同时,分别赋予上(0.2)、下(0.2)、左(0.3)、右(0.3)4个点不同的权重,以着重突出樱桃大小的检测比有无果梗的判别更加重要。模块中采用深度可分离卷积,将逐通道卷积和逐点卷积两个部分结合起来,用来提取图像特征,相比常规的卷积操作,其参数数量和运算成本比较低。在卷积之后使用批量归一化,允许模型使用较大的学习率,减弱对初始化的强依赖性,保持隐藏层中数值的均值、方差不变,让数值更稳定。为了在移动端float16的低精度时也能有很好的数值分辨率,网络中使用的激活函数为ReLU6,如图4所示。
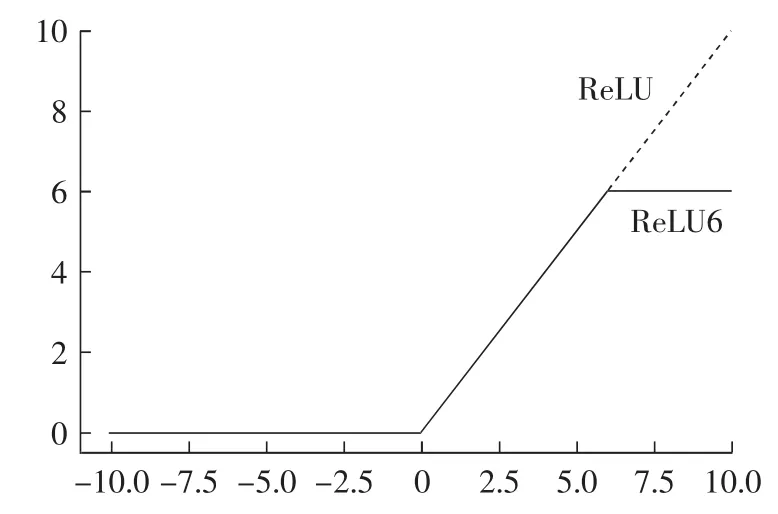
图4 激活函数曲线图Fig.4 Activation function curve
ReLU6定义见公式(1)。

如果对输出值不加限制,那么输出范围就是0到正无穷,而低精度的float16无法精确描述其数值,带来精度损失。
2 试验设置
2.1 试验环境
试验硬件设备主要由图片采集设备、计算机处理单元、辅助照明系统组成,如图5所示。
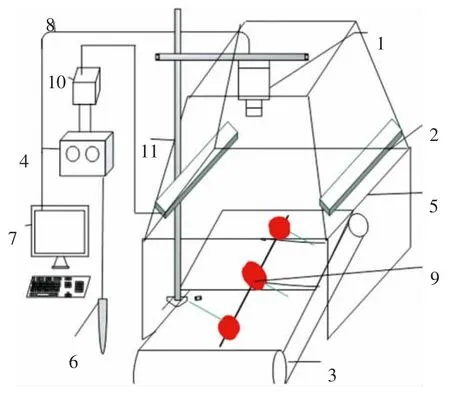
图5 硬件框架图Fig.5 Hardware block diagram
传送带将樱桃均匀地分散在图像的采集区域。图像采集设备包括Basler(acA2000-50GC)工业相机、频闪控制器和激光光电开关,通过频闪控制器和激光光电开关触发相机拍照。计算机处理单元inter(R)Core(TM)i7-1065G7CPU@1.30GHz(8CPUs),-1.5GHz,GPU NVIDIA GeForce MX350运行内存为16 G并配置P0OE千兆网卡。辅助照明系统由发光二极管(lightemitting diode,LED)光源漫光片和梯台型光源罩,灯罩上涂有纳米漫反射涂料,保证图像采集区域的光照强度均匀,避免了樱桃表面的反射和底部阴影。
2.2 图像采集
樱桃在传送带的作用下匀速向前转动,当传送带经过频闪控制器时,将会触发图像采集设备进行图像采集,并通过POE千兆网卡传输给计算机处理单元进行存储。首先,将采集的图像保持长宽比例进行缩放为416×416,剩下部分采用灰色填充。采用图像质量评价筛选出3 505张樱桃图像,对樱桃果体两侧和果梗首末两端进行关键点坐标标注,如图6所示。

图6 樱桃标注示意图Fig.6 Schematic diagram of cherry labeling
然后将3 505张具有标注信息的樱桃图像数据集按照7∶2∶1随机划分为训练集(2 524张)、验证集(631张)和测试集(350张)。其中,训练集和验证集(共3 155张)按照樱桃尺寸和有无果梗分为大(637张)、中(1 665张)、小(853张)、有果梗(2 048张)、无果梗(1 107张),测试集(350张)按照樱桃尺寸和有无果梗分为大(28张)、中(167张)、小(155张)、有果梗(138张)、无果梗(212张),分布如图7和图8所示。

图7 训练集、验证集、测试集樱桃尺寸分布图Fig.7 Cherry size distribution of training set,verification set and test set

图8 训练集、验证集、平共处测试集有无果梗分布图Fig.8 Training set,verification set and test set have no fruit stem distribution
2.3 损失函数
为了缓解梯度爆炸对模型再更新权重的影响,采用Smooth L1损失函数能够使距离中心较远的点和异常值不敏感、可控制梯度的量级在训练时不容易跑飞,从而解决梯度爆炸的问题。Smooth L1从两个方面限制梯度:1)当预测值与真实值差别过大时,梯度值不至于过大;2)当预测值与真实值差别过小时,梯度值足够小。损失函数见公式(2),其中,x=f(xi)-yi,为真实值和预测值的差值。

2.4 评价指标
樱桃尺寸大小和有无果梗检测模型的评价标准采用平均绝对误差(mean absolute error,MAE),即观测值与真实值的误差绝对值的平均值,平均绝对误差能更好地反映预测值误差的实际情况,见公式(3)。

式中:fi为预测值;yi为真实值。
2.5 模型训练参数
模型训练采用Adam优化器,初始学习率为1×104,学习率衰减策略为每2个迭代轮次验证集损失不再下降时,学习率衰减为原来的一半。在模型训练初期,使用较大的学习率进行模型优化,随着迭代次数增加,学习率会逐渐进行减小,保证模型在训练后期不会有太大的波动,从而更加接近最优解。为了防止模型过拟合,在全连接层采用随机丢弃20%的神经元,并采取早停策略,每经过5个迭代轮次验证集损失不再下降,则模型训练停止,能够有效缓解过拟合的发生,在一定程度上达到正则化的效果,从而增强模型的泛化能力。
3 试验结果及分析
为验证本文提出模型对樱桃大小的检测和有无果梗判别的检测效果,选取了经典的卷积神经网络模型VGG19、Resnet50作为对比,模型分级检测效果见表1。

表1 模型分级检测效果Table 1 Model grading test effect
由表1可知,在350张测试样本集上测试,本研究提出的模型效果最优,平均绝对误差为6.12,网络具有更强的特征提取能力,检测精度更高。
模型训练使用了3 155张樱桃图像数据训练模型,训练集和验证集损失收敛情况如图9所示,训练过程的学习率衰减情况如图10所示。
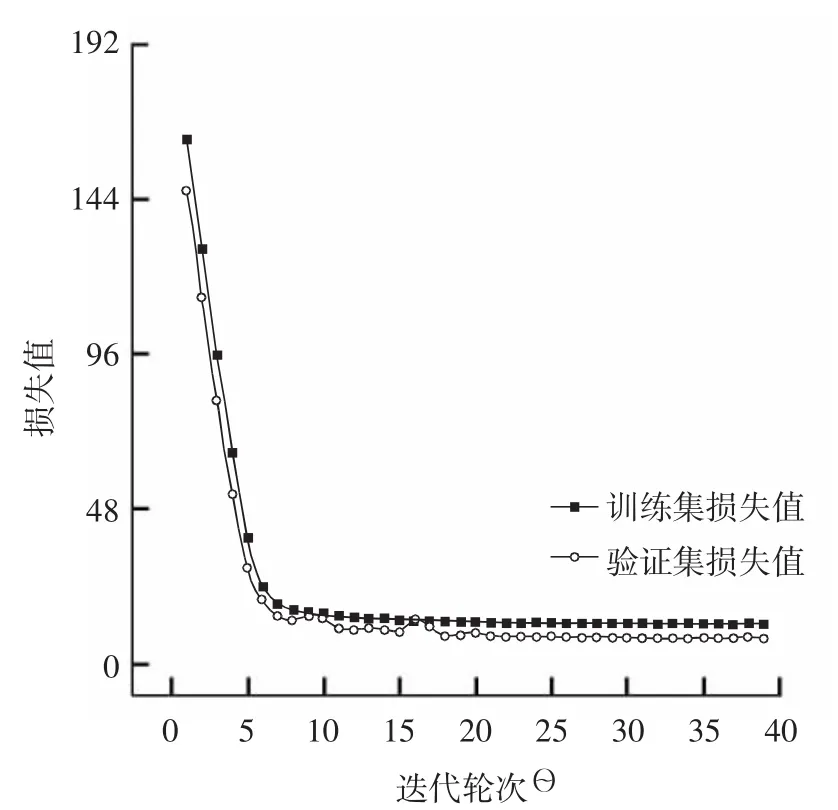
图9 训练集、验证集损失函数曲线图Fig.9 Loss function curves of training set and verification set

图10 学习率迭代曲线图Fig.10 Iterative curve of learning rate
由图9和图10曲线图可知,模型迭代初期,训练集和验证集损失迅速降低,模型趋于局部最优解,开始收敛缓慢,验证集损失值出现振荡,此时学习率衰减策略生效,防止模型收敛结果越过最优解,经过6次学习率衰减之后,验证集损失值不再下降,经过40个迭代轮次后停止,模型收敛至最优解,并且未出现过拟合情况。
3.1 模型分级检测结果
针对350张樱桃图像的分级检测结果见表2。

表2 樱桃分级检测结果Table 2 cherry grading test results
由表2可知,樱桃大小检测准确率为93.14%,有无果梗判定准确率为90.57%。大樱桃准确分检的概率为75.00%,平均绝对误差值为8.094 4;中樱桃准确分检的概率为91.02%,平均均方误差值为6.217 2;小樱桃准确分检的概率为98.70%,平均均方误差值为5.716 2;樱桃有果梗准确分检的概率为94.87%,平均均方误差值为3.071 4;樱桃无果梗准确分检的概率为87.78%,平均均方误差值为6.530 9,其中350个樱桃批量测试样本,在线分级检测总用时10.5 s左右,平均速度约为33个/s,能够满足在线检测的实时性要求。
3.2 模型检测结果分析
针对大、中、小3种樱桃的有无果梗图像检测结果如图11所示。

图11 樱桃真实标注与预测结果Fig.11 Real labeling and prediction results of cherry
从图11中可以看出大樱桃的分级检测结果整体偏小,结合表2可知大樱桃的平均绝对误差最大,主要是因为工业相机景深导致樱桃边缘像素模糊,其次光源直射樱桃产生的光斑和阴影对樱桃关键点回归带来一定的影响,可通过选择大景深相机,调整光源照射角度或选择特定光源来解决。此外,训练样本集中大樱桃所占比例为27.38%,中樱桃所占比例53.45%,样本分布不均衡,对大樱桃的检测结果偏小,可通过增加大樱桃样本数量和数据增强方式优化样本数据分布,进一步提升模型效果。模型对小樱桃的检测效果较好,主要是由于樱桃大小匹配相机景深,拍摄图像质量高,樱桃边缘较为清晰。因此,图像质量对于樱桃的关键点回归至关重要。
4 结论
目前,卷积神经网络一般用于分类,用于关键点的回归研究较少,针对樱桃分级问题,本文提出基于深度学习的关键点回归算法,实现了樱桃的分级检测和有无果梗的精确判别,樱桃大小尺寸检测准确率为93.14%,有无果梗判定准确率为90.57%,检测速度为33 fps,在实现高精度的同时,极大地提升了检测速度,具有很大的实用价值。通过对大、中、小、有无果梗樱桃的不同情况分析,可通过优化图像采集质量和调整光源等方法进一步改善模型检测效果。此外,还可通过增加训练集样本数量或图像增强方法优化数据分布,建立合理的回归逻辑,进一步提升樱桃大小和有无果梗的识别效果,推动樱桃分级的工业化应用。
