医学知识增强的肿瘤分期多任务学习模型
2021-09-11张恒何文玢何军焦增涛刘红岩
张恒,何文玢,何军,焦增涛,刘红岩
(1.中国人民大学 信息学院,北京 100872;2.医渡云(北京)技术有限公司,北京 100191;3.清华大学 管理科学与工程系,北京 100084)
肿瘤分期是评价肿瘤生物学行为的最重要指标之一,是根据个体内原发肿瘤数量以及扩散程度来描述肿瘤的严重程度和侵及范围的过程[1]。医院积累的电子病历文本(EHR)中蕴含了大量关于肿瘤的知识,运用机器学习和自然语言处理技术进行挖掘与知识提取,继而自动地给出分期诊断,是一项具有研究和实用价值的工作。目前肿瘤分期的过程尚依赖于医生的诊断经验或者一些专家手动编写的规则,流程复杂并且难以广泛应用。虽然神经网络模型已经被广泛地应用于各种互联网文本挖掘的任务中并且取得了很好的效果,但是在特定的医疗文本上处理肿瘤分期问题还没有合适的模型和方法。本文提出一种将深度学习与医学知识相结合的新方法,既借用了医疗大数据的优势,又弥补了传统神经网络缺乏医学知识的缺点。
1 肿瘤分期问题概述
肿瘤的TNM 分期分为T(tumor),N(Node),M(Metastasis)3 个维度,T分期用来表征原发肿瘤的部位以及大小,N分期判断局部淋巴结受累情况,M分期是指远处转移情况。医生参考T、N、M分期的结果制定更有针对性的临床诊疗方案。本文采用由美国癌症联合委员会(AJCC)开发的第8版癌症TNM 分期系统[2]作为标准。如表1 所示。

表1 第8 版乳腺癌分期标准(部分)Table 1 8th edition of breast cancer staging criteria (part)
在现实场景中,不同分期的样本分布严重不均衡,以T分期为例,大多数样本集中在T1、T2两类,占总量的80%以上,这给运用深度学习方法解决肿瘤分期问题带来了挑战。此外,不同于通用领域的文本分类,肿瘤分期任务依赖于从文本中进行一定的医学推理,需要相当的医学背景知识,而非仅仅靠上下文就能很好地解决。
Hu 等[3]借助法律条文作为辅助信息,处理智慧司法中的罪名判定问题,受此启发,我们在本文中首次引入医生进行诊断时所参考的医学属性,并且将其是否能从文本中推断得到作为一种标注信息。这些特征包括是否侵犯胸壁、是否橘皮样变、是否侵犯腋窝、是否炎症型癌症等。这些标注信息与最终的分期结果存在内在的联系。
在此基础上,本文提出了一种多任务学习的机制,同时预测肿瘤分期结果以及上述医学属性的存在。我们提出了针对特定医学问题的机器阅读理解任务,并使用双向注意力机制生成问题的表示与电子病历文本的表示,融合两方面的表示推断最终的分期。这些问题可以为肿瘤分期提供额外的知识,更好地对样本不均衡的类别进行区分,也实现了不同肿瘤分期之间的知识迁移。
2 相关研究工作
2.1 文本分类
Kim 等[4]提出TextCNN 模型,借鉴图像识别中的卷积网络捕捉N-gram 信息用于文本分类。Tang 等[5]利用门限循环网络捕捉文本的序列特征,避免训练中的梯度爆炸问题。Joulin 等[6]提出FastText 模型,仅使用全联接层和N-gram 特征就取得了很好的效果。Johnson 等[7]提出DPCNN模型,提出深度堆叠的CNN 模型可以提高单层卷积的效果,具有更强的表征能力。Yao 等[8]提出一种基于图卷积的模型TexGCN 利用词与文档的贡献信息对文本节点和单词节点构建图,将文本分类看作节点分类。Sun 等[9]使用在预训练模型BERT 的基础上进行微调用于文本分类任务。
上述研究均是通用领域的文本分类方法,采用的多是样本分布均匀的数据集。针对肿瘤分期问题的医疗文本数据集及研究较少。医疗文本普遍存在表述不规范、使用大量医学术语、难以进行语义理解等问题,增加了分类的难度。
2.2 不均衡分类
难度由于医疗电子病历数据的严重不均衡,直接应用深度学习模型效果不佳。不平衡分类问题在机器学习领域受到广泛关注,由此产生了小样本学习等研究领域。
不平衡分类的解决办法中,一种是数据层面的改进,采用过采样技术与欠采样技术对数据集进行平衡。通过复制样本或者消减样本达到总体平衡。另一种是从模型层面改进,通过引入外部知识,帮助神经网络对样本量较少的类别也能够很好地学习。本文主要探讨第2 种。
Hu 等[3]提出一个多任务学习的罪名预测模型,针对法律文书类别不均衡的问题,引入10 个有判别作用的区分性属性(盈利、死亡情节、暴力行为等)作为判定罪名的中间依据,通过联合学习罪名预测任务与相关属性预测任务提升了预测准确率。Elhoseiny 等[10]提出引入类标签的文本描述在文本特征和视觉特征之间建立一种映射关系,提升了小样本分类的效果。此类方法可以自动地学习标签或属性的向量表示,但是这种向量只从各属性在文本中的贡献中学习得到,对分类的增益较弱。
本文借鉴了上述思想,引入医学属性对应的文本描述作为启发信息,并将其作为问题进行机器阅读理解模型的训练,模型学习的是多个具有实际意义的医学属性与文本的关系,即将肿瘤分期拆解为对多个医学属性是否存在的判断,相当于在文本与分期结果中引入了一层中间映射,且增加了监督信息。即使是样本较少的类别,也更加容易进行学习,由此减弱了类别不均衡带来的影响 。
2.3 机器阅读理解
机器阅读理解技术是自然语言处理的重要研究领域,其目标是给定一段文本,给出答案或者指出答案的位置。本文借鉴机器阅读理解的思想,将医学问题对应结果的预测视作一个多标签二分类问题。
Cui 等提出了双向注意力机制[11],计算了问题−上下文(Q2C)和上下文−问题(C2Q)两个方向的注意力信息,双向注意力机制为许多机器阅读理解模型所采用。
Seo 等[12]在BiDAF 模型中提出双向注意力流,获取注意力矩阵以后,没有把上下文和问题编码为固定大小的向量,而是由后续的编码模块继续处理,减少早期加权求和造成的信息损失。实验表明双向注意力对结果的提升尤为重要。本文将双向注意力引入肿瘤分期任务,来捕捉上下文和问题间的关系,并对注意力的形式做了改进。
3 医学知识增强的多任务学习肿瘤分期模型
3.1 肿瘤分期相关医学属性
本文选取了医生在推断肿瘤分期时重点观察的医学属性,如表2 所示,这些医学属性与分期结果有一定的对应关系,可以作为肿瘤分期的推断依据。本文针对每个医学属性定义“阅读理解问题”,然后基于病历文本回答该问题,即文本中是否蕴含了该属性及其相关特征,结果要么为“是”,要么为 “否”。所以本文将此任务转化为一个给定问题的机器阅读理解问题。
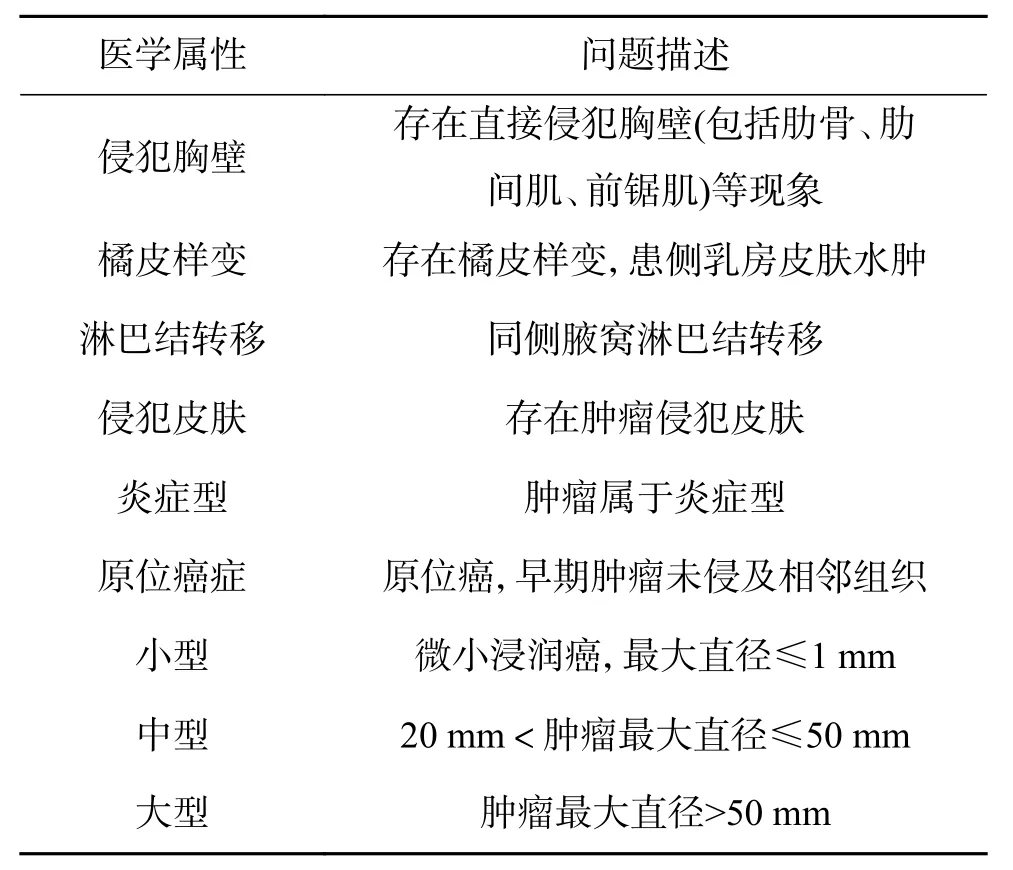
表2 医学属性及对应“问题”描述(部分)Table 2 Description of medical attributes and corresponding “questions” (part)
3.2 问题定义
肿瘤分期。给定一个电子病历文本,记作序列D={w1,w2,…,wN},其中N为文本的长度,wi是文本的第i个元素,肿瘤分期任务的目标是根据D推测其相应的分期结果yT、yN、yM,且yT∈{Tis,T1,T2},yN∈{N0,N1,N2,N3},yM∈{M0,M1}。
机器阅读理解。将表2 中的每种医学属性对应的问题描述当作问题,设每个问题由M个字符组成,假设一共有K个医学属性,对应K个问题任务目标是根据D推测每个问题对应的答案p={p1,p2,…,pk},且有pi∈{0,1}。
3.3 模型介绍
本文借鉴Hu 等[3]提出的Attribute-based LSTM 和Seo 等[12]提出的双向注意力机制,提出医学知识增强的多任务学习(KEMT)模型,包括输入层、文本编码层、双向注意力层和输出层,如图1 所示。
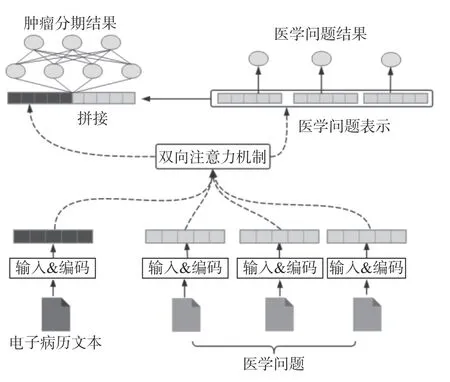
图1 模型结构Fig.1 Model structure
输入层。负责将输入文本D转化为向量序列。由于医疗文本切词复杂,模型的效果随切词粒度不同存在很大差异。本文使用字符级的表示,能更好地捕捉上下文语义,避免未登录词(OOV) 现象。记E∈R|V|×d为输入层字符嵌入矩阵,|V|为字典的大小,即所有病历文本中出现的不同字符数,d为输入层字符向量的维度,N为本段文本的字符数。
经过输入层后,输入文本转化为字符向量序列X={x1,x2,…,xN}。
编码层。对电子病历文本和问题文本进行分别编码,编码层结构如图2 所示。

图2 编码层Fig.2 Encoder layer
编码层中,模型借鉴DPCNN[7]中的Region embedding 方式对输入文本片段进行嵌入表示,在后面的多层卷积中,使用两层等长卷积代替传统的窄卷积,使得每一个位置的向量都包含了上下文的信息。在卷积块的输入与输出间使用残差连接。

式中:z为输入卷积层的向量;f代表两层等长卷积;z′为卷积层的输出向量;编码层也可以采用其他自然语言处理模型,如BERT,并不限定采用CNN 模型,主要目的是提取文本的基本特征。
注意力层本文将病历文本经过编码后获得的表示记为C,且C∈Rd×N,d为向量的维度,N为病历文本的长度。每个问题经过编码后的表示记为Q∈Rd×M,M表示问题Q的长度。首先计算文本表示C与问题Q的注意力分数矩阵S,其第i行第j列的取值Si,j如式(2)所示。

式中:⊙表示逐元素相乘,且S∈RN×M,qj和ci分别表示问题描述的第j个字符向量和病历文本的第i个字符向量。W0是一个可以训练的权重。
将病历文本看作回答问题的上下文信息,将S相似度矩阵每一行经过softmax 层可以得到上下文−问题 (context-to-query)方向的注意力,因为S中每一行表示的病历文本中第i个字符与问题中每个字符间的相似度。将得到的C2Q 注意力与Q做点积,如式(3)所示:

式中:A为N×d的矩阵,即用Q中的所有词表示病历文本的每一个词。得到A以后与病历文本表示C进行拼接,得到融合问题信息的文本表示的一行,如式(4)所示:

式中:a为A的一行,将K个Q分别经过注意力机制得到的向量表示做平均池化操作,得到最终的文本表示C¯,如式(5)所示:
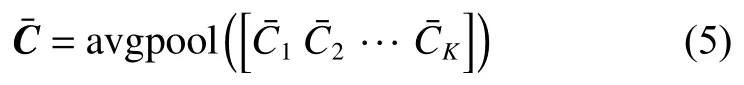
将S相似度矩阵每一列经过softmax 层可以得到query-to-context (Q2C)方向的注意力,计算的是对每一个问题中的词,文本中哪些词和它最相关,计算方法是取相似度矩阵中最大的一列,对其进行 softmax 归一化然后计算病历文本向量的加权和,如式(6)所示:


式中:pi是问题i所对应的医学属性是否在文中存在的概率,本文把其视作一个二分类问题,Wi和bi是输出层的权重和偏置。
对于病历文本的表示使用最大池化获取全局的表示e=[e1e2···ed],其中d为向量的维度。

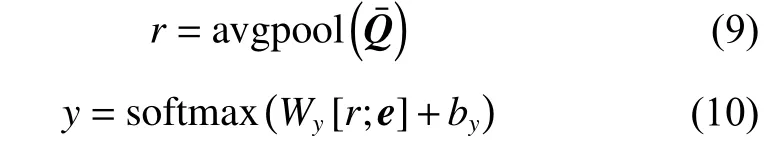
这里r是K个问题向量的平均池化,r和e是采用拼接的方式输入给最终的预测层,Wy和by是分类输出层的权重和偏置,y为最终在各个分期类别上的概率。
3.4 损失函数
本模型采用联合学习的方法,损失函数分为两部分。一部分为肿瘤分期的预测概率与真实值之间的交叉熵损失 Lc:
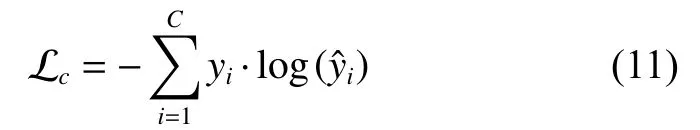
式中:yi代表肿瘤分期的真实结果;是网络预测得到的概率分布;C为对应肿瘤分期的种类数(T分期为5,N分期为4,M分期为2)。另外一部分,对于第j个问题的预测结果,利用式(12)计算二分类交叉熵损失 Lq,j:
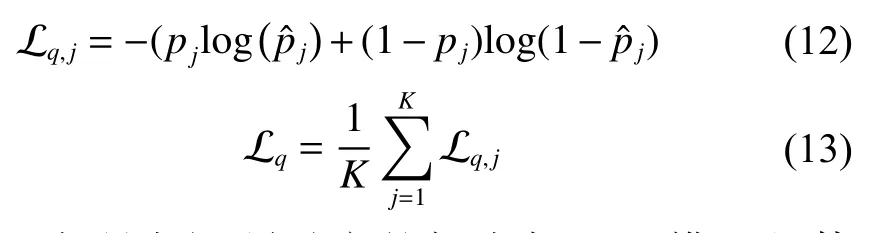
Lq为所有问题对应的损失加和。模型整体的损失函数由上述两个损失函数加和而成:

其中 α 是超参数,用来平衡损失函数中两部分的比重。
4 实验设置及结果分析
4.1 数据集构建
目前尚未有公开的适用于肿瘤分期数据集,于是我们与医疗AI 公司医渡云合作构建了实验数据集,主要来自医渡云医学专家基于临床经验撰写的部分病历内容,包括病人的病理诊断,现病史信息等。针对T分期、N分期、M分期3 种标准构建了3 个数据集详情如表3 所示。

表3 各数据集信息统计Table 3 Statistics of data sets
在搜集的肿瘤电子病历数据中,具有显著的类别分布不均衡的现象,以T分期的数据集为例,如表4 所示共分为5 类,较高的T下标值意味着更大的肿瘤和/或更广泛地扩散到附近的组织(Tis指没有更深入地侵入其他组织的原位癌,Tis是Tissue 的缩写)。可以看到T1、T2类别的样本较多,T3、T4、Tis样本较少。所以我们在预处理阶段使用上采样的方法,复制样本数较少类别的样本,使各类别的样本数均与样本数最多的种类一致。

表4 T 分期数据分布Table 4 Data distribution of T stage
4.2 评价指标与基准模型
本文采用文本分类中常用的精确率(Precision),召回率(Recall),F1值作为模型评价指标。
本文选取多种经典的文本分类模型作为基准模型,分别是:
TextCNN:Kim 等[4]提出的TextCNN;
BLSTM:双向的LSTM 加max-pooling;
FastText:Joulin 等[6]提出的浅层模型;
DPCNN:Johnson 等[7]提出的多层卷积网络。
4.3 实验参数设置
本文使用PyTorch[13]实现了所有的模型,设置最大训练轮次为100 轮。使用Adam[14]作为模型优化算法,初始学习率设置为0.001,Dropout[15]的大小设置为0.5,batch 的大小设置为64,损失函数里的权重参数 α 设置为0.5。输入向量的维度设置为128 维,采用标准正态分布随机初始化,文本最大长度设置为512。对基准模型中的TextCNN模型,卷积核大小设置为(3、4、5),BLSTM 的隐藏层大小设置为128 维。
4.4 实验结果与分析
改进后的KEMT 模型与上述基准模型对比如表5 所示。

表5 T 分期实验结果Table 5 Results of T stage experiment %
从表5 可以看出,本文提出的KEMT 模型的各指标均超过了基准模型,比基准模型的最好结果分别提升了5.8%、1.7%、3.5%。为了说明我们的模型在小样本类别上的有效性,图3 展示了各个类别上的效果对比。

图3 KEMT 与DPCNN 的F1 对比Fig.3 F1-score of KEMT and DPCNN
如表6 所示,KEMT 模型在Macro-F1值上超过了基准模型在小样本类别上的值,显示出模型在样本数量极度不均匀的情况下,对小样本类别也有不错的分类效果。基准模型中F1值最大的为T2(93.8%),最小值为T4(83.1%),相差10.7 个百分点,而KEMT 模型中F1最大值T2(95.2%)和最小值T4(91%)相差4.2 个百分点。以上结果均显示出KEMT 模型的效果在各类别上更均衡。

表6 小样本类别Macro-F1Table 6 Macro-F of category %
为了说明模型的有效性,接下来采用同样的方法对N分期和M分期数据集进行实验。实验结果如表7 和表8 显示,KEMT 模型在N分期与M分期标准下均取得了良好的效果。
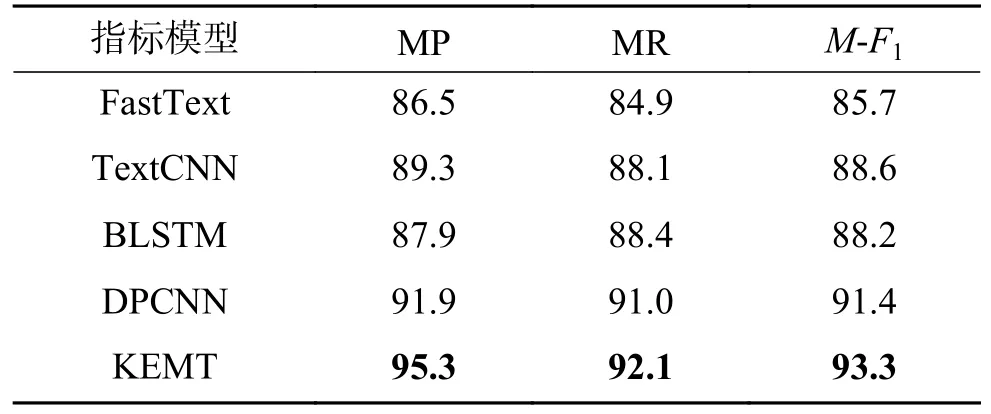
表7 N 分期实验结果Table 7 Results of N stage experiment %
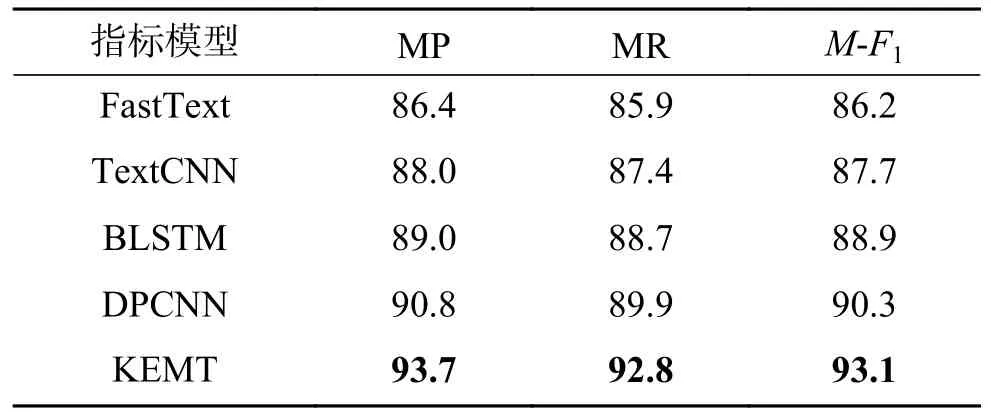
表8 M 分期实验结果Table 8 Results of M stage experiment %
4.5 有效性说明
为了说明注意力机制的有效性,本文还设计了两组消融实验:
1)w/o attention,即去掉模型中的注意力机制模块。则模型退化为将病历文本和问题分别编码。
2)w/o concatenation,即保留双向注意力模块,但直接用文本表示r进行最终的分类。
从表9 可以看到,移除注意力模块以及医学领域知识后,模型的Macro-F1(M-F1)值分别下降了5%和4%,由此可见,双向注意力机制和医学领域知识对于模型的效果是有显著影响的。

表9 注意力机制有效性Table 9 Effectiveness of attention mechanism
4.6 样例阐释
本文选取了一个直观的样例,来对于注意力机制如何帮助预测分期结果进行了说明。该样例的真实分期标签和KEMT 模型预测的结果均为T4,一个显著的特征是病人的电子病历中是否有隐含医学属性“橘皮样变”的出现。将 “橘皮样变”这个属性对应的注意力用热力图可视化出来。背景颜色越深的词,具有的注意力权重值更大,通过热力图显示,可以清楚地看到,注意力机制可以捕捉与医学属性相关的关键模式。如图4所示。

图4 注意力机制热力图Fig.4 Heat-map of attention mechanism
5 结束语
本文充分利用医生诊断肿瘤分期时所依据的医学属性,将属性对应的文本描述作为问题,提出了面向医学问题的机器阅读理解任务和知识增强的多任务学习(KEMT)肿瘤分期模型,实现了医学问题答案预测和肿瘤分期两种任务之间的知识迁移。实验结果表明该方法一定程度上解决了数据集不均衡带来的分类效果不佳的问题。
然而本文仍有需要改进的地方,比如医生实际运用的知识更复杂,本文对于分期的划分目前还是粗粒度的,在每一种分期下还有更细粒度的划分,如果要达到更精细的分类,需要制定更精细的医学属性信息。
近来,图神经网络和预训练模型兴起,在多项任务中有巨大潜力,下一步我们也将探索这些新方法运用到肿瘤分期问题中,希望能够引入更多有效的医学知识,提升肿瘤分期问题的模型效果。
