迁移学习特征提取的rs-fMRI 早期轻度认知障碍分类
2021-09-11孔伶旭吴海锋曾玉陆小玲罗金玲
孔伶旭,吴海锋,2,曾玉,2,陆小玲,罗金玲
(1.云南民族大学 电气信息工程学院,云南 昆明 650500;2.云南省高校智能传感网络及信息系统创新团队,云南 昆明 650500)
阿尔兹海默症(Alzheimer's disease,AD)是最常见的一种老年痴呆症,占所有痴呆症的60%~70%[1]。AD 的形成原因尚未完全研究清楚[1],目前还没有任何药物可以阻止或逆转其发展,只有在AD 早期时通过一些治疗来改善症状和干预其进一步的恶化[2],从而减轻患者的病情和延长存活时间。因此,AD 的早期诊断对于该疾病的治疗具有非常积极的作用。在AD 发病之前,患者会经历早期轻度认知障碍(early mild cognitive impairment,EMCI),该阶段是老年正常认知衰退和痴呆症严重认知衰退的中间阶段,此时的大脑已具有轻微的认知和记忆障碍,但不会影响患者的日常生活,因此在临床检测中很难被发现。已有研究表明,患有EMCI 的个体患AD 的风险高于正常人,约为正常人的10 倍[3-5]。因此,准确诊断EMCI 对AD 的治疗有着十分积极的作用。
目前,较准确的EMCI 诊断方法为生物标志物诊断,如通过脑脊髓液完成[6],然而脑脊髓液抽取属有创诊断,且诊断过程也较为复杂。另外一种对EMCI 的诊断方法是让患者完成神经心理学问卷[7],再经神经心理学医师进行评估,但这种诊断往往带有一定主观性,只能作为一种辅助诊断方式。近年来,随着神经影像技术的发展,具有无创的核磁共振成像(magnetic resonance imaging,MRI) 和功能性磁共振成像(functional magnetic resonance imaging,fMRI)技术被越来越多的用于AD 的诊断中[8]。fMRI 反映了受试者执行特定任务时血氧水平依赖(blood oxygen level dependent,BOLD)信号的波动情况,相比MRI 数据,其不仅包含结构性信息还包含功能性信息,只是获取fMRI 数据需要设计合理的实验任务[9]。为避免实验任务因素对fMRI 数据的影响,越来越多的研究[10]表明静息态fMRI(resting state fMRI,rsfMRI) 可替代fMRI 来完成EMCI 的诊断。由于在rs-fMRI 数据获取时受试者不用完成任何特定任务,因此避免了实验任务对数据所带来的影响。
本文采用深度学习的分类方法,通过rsfMRI 数据来进行EMCI 分类,以辅助AD 的早期发现。首先将大脑划分成若干个兴趣点(region of interest,ROI)[11],依照ROI 从rs-fMRI 数据中抽取出时间序列来形成一个二维矩阵,再用一个二维卷积神经网络(convolutional neural networks,CNN)从该二维矩阵中提取特征信息,以此进行后面的分类。同时,为了提高运算速度和减少训练时间,CNN 采用迁移学习网络,用一种轻量化CNN 网络−拥有从ImageNet 数据库[12]中预训练权重的MobileNet 来提取ROI 的特征信息。
1 相关工作
AD 症被视为一种神经退化性疾病,疾病早期的症状常被误认为是正常的老化,错过了最佳诊断时机。AD 症的前期诊断一般通过病史收集和行为观察获得,耗时又耗力。若要较为准确的诊断,则需要进行详细的神经心理学检查才有可能判断是否存在认知障碍[13]。随着机器学习技术的发展,人们发现作为一种辅助诊断方法,机器学习可以提高诊断的效率和准确率。
在传统的机器学习分类技术中,支持向量机(support vector machine,SVM)是一类具有较高分类准确率的诊断方法[14],但SVM 的准确率依赖于提取的特征值,当特征值本身未能准确反映疾病的特征,则其准确率往往会达到一个瓶颈。近年来随着深度学习的兴起,出现了很多可以自动从分类数据中提取有效特征值的方法,如堆叠自动编码器(stacked auto-encoders,SAE)[15]和CNN[16]等,这些方法均使得分类准确率得到了很大的提高。通常,深度学习的网络较为复杂,权重数量巨大,且需要海量的训练数据作支持,这都使得深度学习的训练耗时耗力。然而,公开的AD 病症数据非常有限,AD 早期病症的数据更为稀少,因此深度学习的分类准确率将严重依赖于疾病数据的完备性。为了解决该问题,近年来迁移学习被提出来对AD 进行诊断,例如AlexNet[16]和VGG16[17]等。由于迁移学习网络已在其他数据库进行了预训练,只需在AD 数据库中只训练其顶层即可,因此可以缩短训练时间,并可减少分类对训练数据的依赖。然而,迁移学习的预训练网络是否对EMCI 的诊断有效,目前仍无文献进行报道,这也是本文关注的一个重点。
机器学习可以同神经影像学相结合以完成疾病的诊断,常用的影像技术包括电子计算机断层扫描(computed tomography,CT)、正电子发射型计算机断层显像(positron emission computed tomography,PET)、MRI 和fMRI[18]等,其中又以MRI 和fMRI 的低辐射和无创性而得到了广泛的关注。对于MRI,其成像较为清晰,且包含信息丰富,因此被广泛应用于对AD 的诊断[19]。通过对皮质体积、皮质厚度及皮质下体积等脑部结构数据,MRI 可以较准确预测MCI 到AD 的转变。然而,对EMCI 患者来说,其脑部结构变化并不明显,因此仅使用MRI 数据对EMCI 的检测还是具有一定限制。最近有研究表明,AD 还表现在某些脑区功能连接的变化上[20],而fMRI 又恰恰能反映功能连接特性,因此可以使用fMRI 数据来有效诊断AD 和EMCI。然而,采集fMRI 通常需要被试者完成特定的实验任务,因此fMRI 数据又往往与完成的任务有关。其实,大脑即使在不完成任何特定任务时,各脑区仍然在相互作用,存在一个默认的功能网络,而这种默认模式在一些认知障碍的大脑疾病中通常遭到了破坏,因此rsfMRI 也逐渐地用在EMCI 诊断中[21]。与fMRI 数据相比,rs-fMRI 的获取不需要被试者完成预先设定好的实验动作,仅需要被试者保持休息状态,因此避免了人为因素对数据的干扰。
通常,rs-fMRI 为一四维数据,用于深度分类网络需先降维。常用的一种降维方式是,将脑区划分成一些ROI,从这些ROI 中提取BOLD 信号,再从这些BOLD 信号提取特征值,如利用SAE[22]或受限玻尔兹曼机(restricted Boltzmann machine,RBM)[23]提取特征值,最后利用这些特征值进行分类。由于输入数据的降维不可避免带来信息丢失,而不降维又容易产生较复杂的分类网络,因此,在rs-fMRI 中如何解决分类网络的数据输入是本文需要关注的另一个重点。
2 问题提出
由于深度学习能自动提取特征值,且具有较高的分类准确率,因此本文将采用深度学习的方法来进行EMCI 的诊断。同时,由于rs-fMRI 无需完成任何实验任务,本文也采用rs-fMRI 数据来进行诊断。
将rs-fMRI 应用于深度学习的EMCI 诊断首先需要解决数据输入的问题,如图1 所示,既要保证输入到分类网络的数据降维后应包含丰富的分类信息,又能降低分类网络的复杂性,以确保较少的训练时间。

图1 特征提取的相关问题Fig.1 Issues related to feature extraction
若用Y表示一个被测试的rs-fMRI 信号,则该信号不仅包含脑区结构像信息,还包含时间信息,因此是一个NT×NX×NY×NZ的四维数据,其中NT表示时间维度,NX、NY和NZ分别表示脑区的3 个空间维度。目前,常用的CNN大多是针对二维图像的分类网络,因此rs-fMRI并不能直接拿来作为输入。当然,由于AD 影像数据的高维特性,近年来还出现了一些三维CNN网络[24],但作为四维的rs-fMRI 仍然无法被直接使用,需要进行降维。
一种常用的降维方式是使用自动解剖标记(automated anatomical labeling,AAL)[25]图谱来得到一个NT×NA的二维ROI 时间序列,其中NA表示ROI 的数量。此时,原来的rs-fMRI 将从原来的四维降至二维,数据量得到了减少。然而,为了从ROI 时间序列数据提取特征值,仍然需要训练,以SAE 方法为例[22],设该网络共有NS个隐藏层,其每层隐藏层的神经元数量分别为S1,S2,···,SN,那么该网络总共的权重数量为
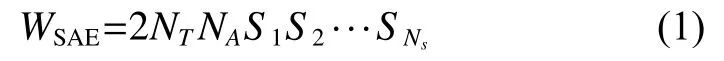
从式(1)看到,由于SAE 采用的是全连接网络,因此其权重的数量与神经元数量和隐藏层数相关,当这两者数量增大时将不可避免使得整个网络权重数变得庞大。当然,CNN 也可以自动提取特征值,目前的CNN 利用卷积运算对权重进行共享,相比全连接层可以减少权重数量。假设一个CNN 网络共有NC个卷积层,其中每个卷积层分别由L1,L2,···,LNc个特征图组成,特征图的大小分别为F1×F1,F2×F2,···,FNc×FNc,所使用的卷积核尺寸分别为M1×M1,M2×M2,···,MNc×MNc,若步长(stride)为1 时,那么该网络的总共的权重数量为
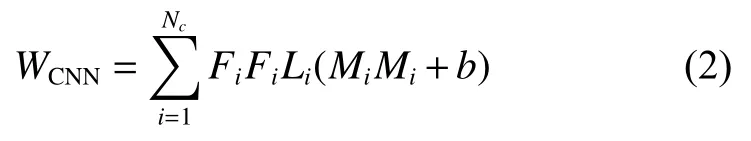
其中b是偏置数。式(2)的权重与其层数密切相关,通常CNN 在深度学习中的层数都较多,即使权重实现共享但权重数依然庞大。
利用脑区功能性连接网络理论来提取特征值的方法可以进一步对数据降维[20],其本质是求统计相关系数,若xt和yt分别为任意两个ROI 在第t时刻BOLD 信号,那么其相关函数可表示为
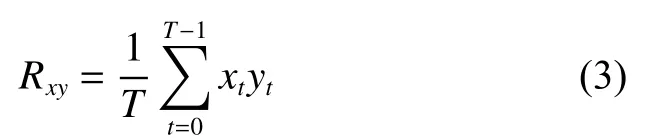
因此,对于一个NT×NA的二维ROI 时间序列求相关以后,其维度将变为相比原ROI 序列,数量得到了减少。然而由式(3)可知,Rxy是一个时间统计平均值,虽然去掉了时间维度NT,但也去掉了ROI 数据的瞬时量,不可避免地带来了部分信息丢失。因此,如何在数据降维、信息丢失以及训练时间寻找平衡将是本文主要研究的一个问题。
3 方法
3.1 总体框架
本文使用rs-fMRI 数据以及迁移学习的CNN 网络来对EMCI 进行诊断,方法总体框架如图2 所示,把患有EMCI 和正常控制组(normal control,NC)的rs-fMRI 数据进行配准、头动校正、颅骨剥离、归一化、平滑及滤波等预处理操作,然后使用AAL 对完成预处理数据提取ROI 得到相应的二维时间序列,随后输入到已预训练的迁移网络,以此得到瓶颈(bottneck)特征,最后将该特征输入到设计好的TOP 层中得到分类结果,完成疾病诊断。
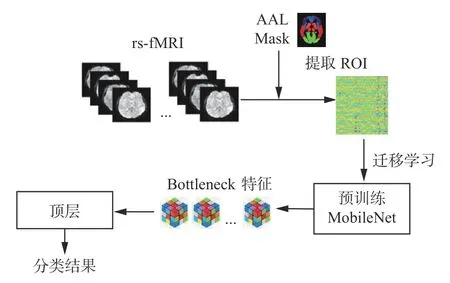
图2 算法总体框架Fig.2 Algorithm overall framework
3.2 迁移学习的特征提取
将一个具有脑区空间和时间维度的四维rsfMRI 信号直接作为分类器的输入,维度较高,可从其中提取ROI 时间序列来降维,但从ROI 时间序列提取特征值,仍需训练。如前所述,SAE 和CNN 网络提取特征将面临权重数庞大和训练时间增多的问题,而采用相关法提取特征又容易丢失瞬时信息,因此本文考虑采用迁移学习方法从ROI 提取特征值。
设Xs和DS分别是一源数据集中的二维图像矢量和对应标签,将一CNN 网络在该源数据集中进行预训练,使其满足:

预训练完成后,将由四维rs-fMRI 数据张量Y提取出来ROI 时间序列XT,输入到预训练完成的瓶颈层函数fbtneck(·),以此得到瓶颈层特征:

其中F即是从ROI 时间序列提取的特征值。若目标网络的顶层经训练后,使得XT及其对应标签DT满足

图3 给出了式(6)的迁移学习过程,图中预训练部分通常无需在本地端完成,即使瓶颈层的权重wb非常庞大,但由于可由第三方预先完成而获得,因此可大幅减少提取特征的训练时间。更重要的是,为保证提取瓶颈特征的有效性,训练和获取瓶颈层权重wb往往在一个非常巨大的源数据集中完成,如ImageNet 数据库[12],因此相比单纯无迁移的CNN,迁移网络可以解决目标数据集不足的情形,而目前获取大规模EMCI 的rs-fMRI数据仍存在一定困难。
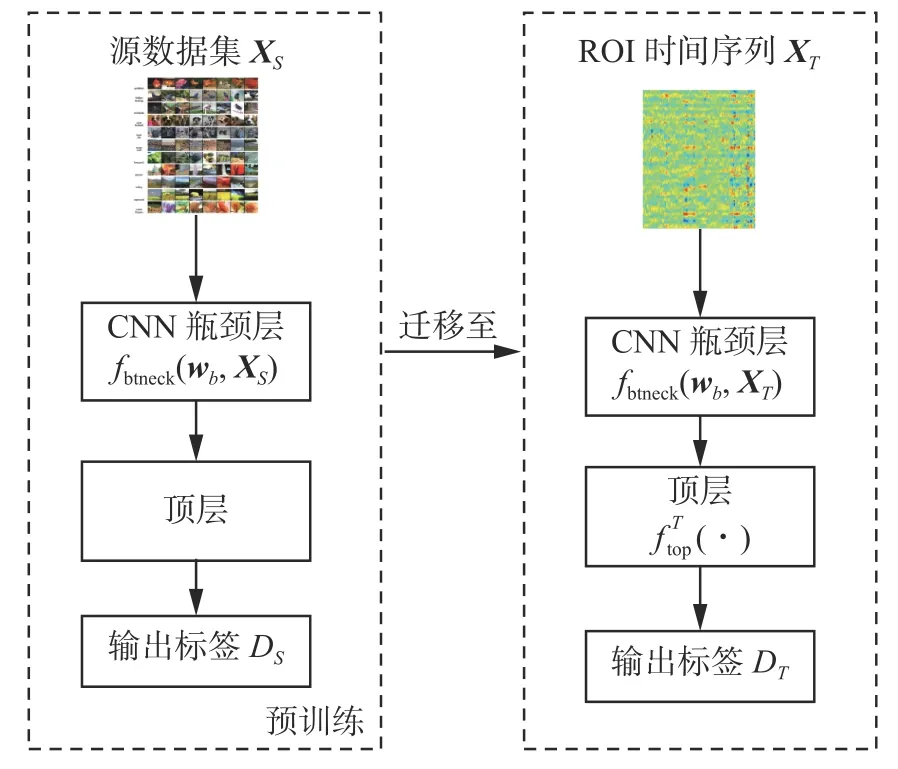
图3 迁移学习提取ROI 特征Fig.3 Transfer learning to extract ROI features
其实,图3 的EMCI 目标网络训练仅仅对一顶层网络进行训练,而顶层只是一个浅层神经网络,其权重wOt数量并不大,因此可保证训练能在短时间内完成。另外,由于瓶颈层特征F来源于ROI 时间序列,因此相比于求相关系数的特征值提取方法,其瞬时特征也得到了保留。当然,虽然fbtneck(·) 的权重可由预训练得到,但特征F也需通过fbtneck(·) 的计算得到,因此太复杂的可迁移CNN 会增大特征提取的计算量,本文将选用一种轻型的CNN 网络来实现迁移学习。
3.3 MobileNet 网络
作为一种轻型的CNN 网络,Mobilenet[26]使用深度可分离卷积替代原有的传统卷积以减少计算量,本文将采用该网络来作为迁移学习函数fbtneck(·)。深度可分离卷积将标准卷积分解成一个深度卷积和一个点卷积,如图4 所示。深度卷积将单个卷积核应用于每个输入通道,点卷积使用1×1 卷积核来组合输出,这种分解可大幅度地减少模型大小和计算量。
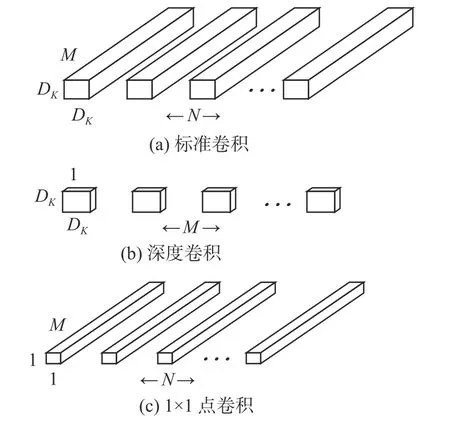
图4 深度可分离卷积Fig.4 Depth separable convolution
对于一个NT×NA的ROI 时间序列来说,设其输入通道为M,经过一个标准卷积层,则将产生一个N×NT×NA的特征图,N是输出通道数。若经过一个卷积核大小为DK×DK×M×N的标准卷积层,其中DK是卷积核维度,那么该标准卷积的计算成本为
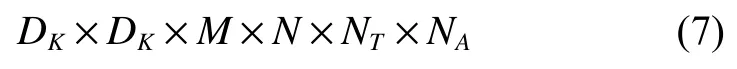
在深度可分离卷积中,先使用深度卷积为每个输入通道应用单个滤波器,那么深度卷积的计算成本为
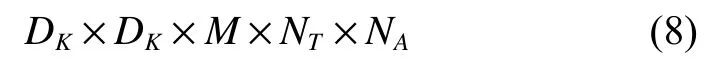
然后使用点卷积(1×1 的卷积核)来创建深度层的输出的线性组合,其计算成本为

所以深度可分离卷积的计算成本为
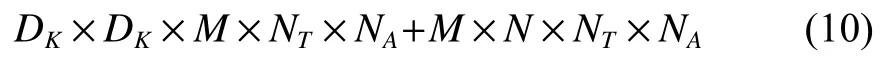
因此,深度可分离卷积的乘法次数与标准卷积之比为
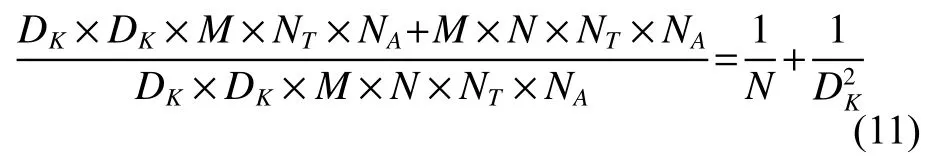
由式(11)可知,由MobileNet 得到瓶颈层所需计算量与相同规模网络比,可大大减少。因此从计算量角度,选择MboileNet 作为迁移网络是一个较好的选择。
3.4 顶层分类网络
将ROI 时间序列经预训练的瓶颈层MobileNet 就得到瓶颈特征,随后再将瓶颈特征输入到设计的顶层就可进行分类。顶层网络设计如图5 所示,主要包括全局平均池化层、Dropout 层、全连接层和输出层,其中全局平均池化层可将瓶颈层特征融合,Dropout 层可避免网络出现过拟合。因此,该顶层的权重数量为式中:NGAP×NGAP为瓶颈特征经过全局平均池化层的融合后得到的数据维度;Ci为第i层全连接层的神经元数;m为全连接层的总层数;r为Dropout层的权重丢弃率。由于在顶层中,经提取和融合后的瓶颈层特征维度已经降至很低,且层数m值较小,因此式(12)的权重数不会很大,保证了较少的网络训练时间。


图5 顶层设计Fig.5 Top-level design
另外,顶层中的一些参数设定会影响最后的分类结果,如全连接层层数m、Dropout 层的权重丢弃率r和全连接层的神经元数Ci。如何选择合适的参数值可通过实验来进行实际测试,这部分的内容将在下一节实验中作详细讨论。
3.5 算法训练
最后给出本文EMCI 分类算法训练的步骤,如下所示:
1)预处理:对rs-fMRI 信号的观测值Y进行配准、头动校正、颅骨剥离、归一化和平滑及滤波等,并分成训练集和验证集;
2)ROI 提取:由AAL 图谱从预处理数据中提取ROI 时间序列XT;
3)瓶颈特征提取:由fbtneck(wb,XT) 获取瓶颈特征;
5) 验证:由验证集,通过式(6) 得到分类结果,并计算分类准确率;
6)重复执行步骤4)~5)至分类准确率收敛。
4 实验设置及结果
4.1 数据来源及预处理
在本实验中,所采用的rs-fMRI 数据均来源于阿尔茨海默病神经影像学数据库(Alzheimer’s disease neuroimaging initiative,ADNI),其网址为http://adni.loni.usc.edu/。在该数据库中,我们选择了ADNI-2 阶段的rs-fMRI 数据,其具体参数详见表1,从中我们分别得到了32 个EMCI 和正常对照组(normal control,NC)的可用的被试数据,且两组被试内的年龄和性别分布没有明显差异。
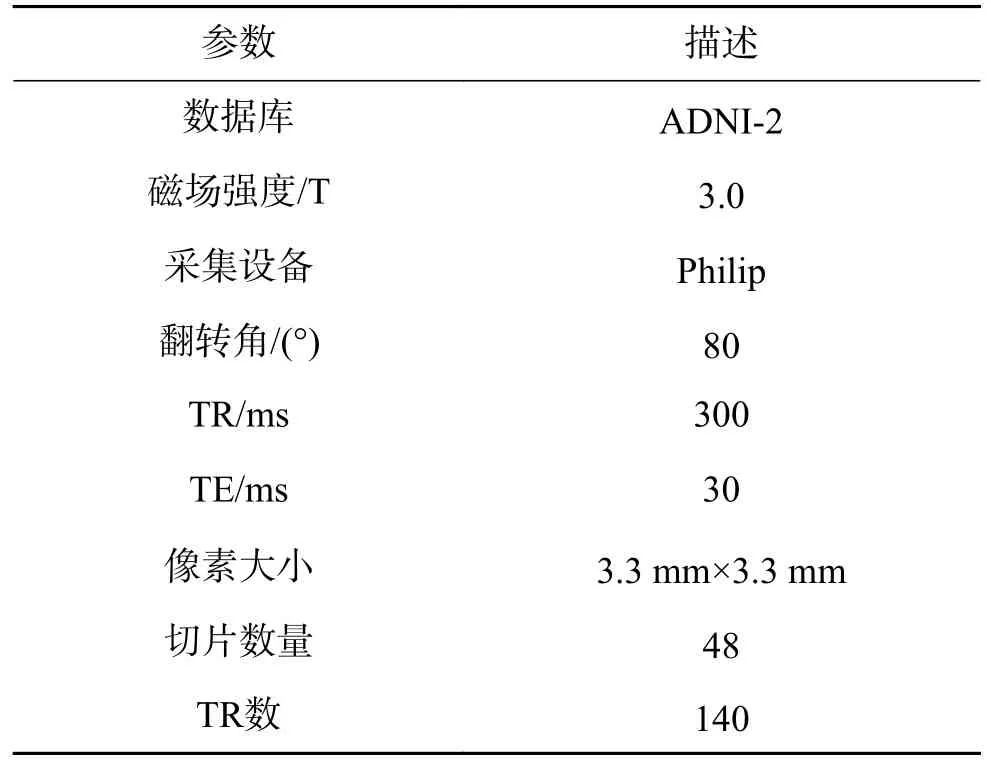
表1 rs-fMRI 数据相关参数Table 1 rs-fMRI data related parameters
数据预处理采用数据处理和脑成像分析(data processing &analysis of brain imaging,DPABI)工具箱[27],具体过程如下:
1) 去除每个被试者前10 帧图像,仅保留130 帧图像;
2)以第48 帧图像为基准对所有的图像进行校准,使每个切片上的数据具有相同时间点;
3)对所有被试进行头动校正,将头动校正到同一位置,并为接下来的图像质量控制提供数据;
4)将与rs-fMRI 数据匹配的MRI 数据进行颅骨剥离,然后同功能图像进行配准,将MRI 数据变换到rs-fMRI 数据的空间,使得rs-fMRI 数据可以被分割成脑脊髓液、灰质和白质信号;
柴油在装卸过程中,因密封不良、管道破损、管道超温超压、仪表失灵等原因造成油品泄漏,泄漏的液体及其挥发出的蒸气可能形成爆炸性可燃气体。如遇火源,则可能发生火灾甚至爆炸事故。
5)去除一些混淆因素,将全局平均信号、脑脊髓液和白质信号被作为无关变量去除,且以6 个头动参数(包含3 个转动参数和3 个平动参数)去除头动带来的影响;
6)评估被试者头部的旋转和平移,发现所有参与者都没有表现出过度(任一方向平移超过2 mm 或任一方向转动超过2°)的头部运动;
7)进行归一化和平滑,并将所有数据都过滤到一个频率范围(0.01~0.08 Hz);
8)使用AAL 图谱将大脑分为116 个ROI,如图6 所示,每个半脑球包含58 个区域,最后得到一个116 ×130 的矩阵,其中列为兴趣数,行为时间维度;最后根据所有被试的头动情况,图像成像质量以及结构和功能像的配准质量对数据进行过滤,最终分别得到了32 个EMCI 和NC 图像。
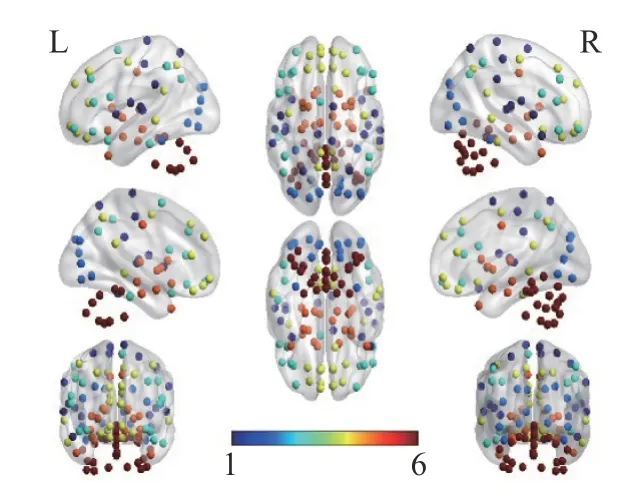
图6 大脑节点Fig.6 Top-level design
4.2 实验方法
在实验中,采用两种方法对rs-fMRI 进行降维,一种仅通过AAL 提取ROI,一种为提取ROI 后再求pearson 相关系数,因为pearson 相关系数通常用于衡量功能连接的强度[28],因此也可以使用它来衡量不同大脑区域之间的功能连接。其具体参数详见表2。在对数据降维后,采用两种方法提取特征值和分类,分别采用SAE 和迁移网络MobileNet,具体参数也由表2 列出,由此我们分别得到以下4 种方法的分类结果:
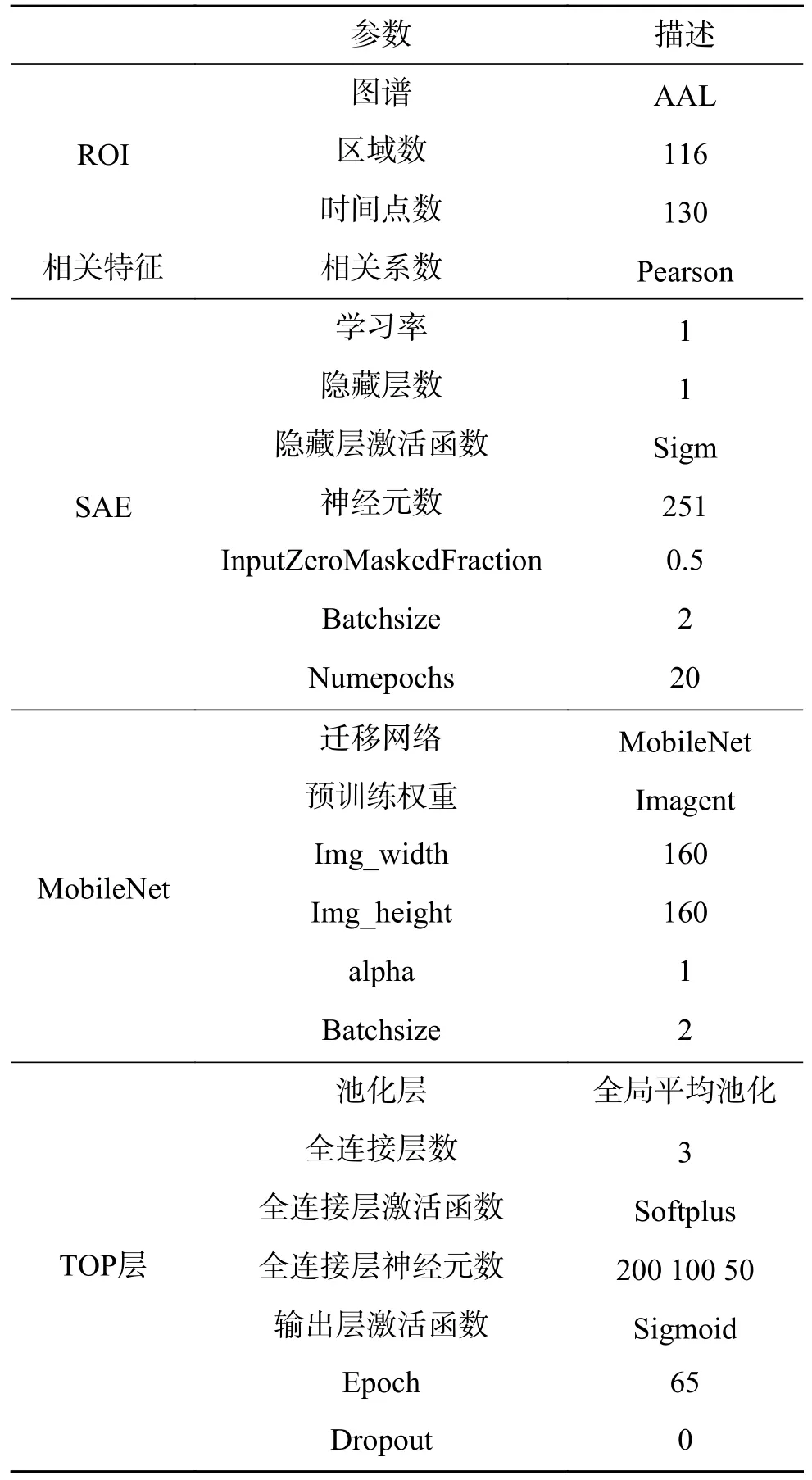
表2 相关实验方法参数Table 2 Related experimental method parameters
1)SAE_ROI:由AAL 得到ROI,再由SAE 提取特征值后分类;
3)Transf_Corr:由AAL 得到ROI,再求pearson 相关系数,再由MoblieNet 提取pearson 相关系数特征值后进入TOP 层分类;
4)Transf_ROI:由AAL 得到ROI,再由MoblieNet 提取ROI 特征值后进入TOP 层进行分类,计算步骤也可参见表1。
以上方法的分类方法都将采用k折交叉验证以防止发生过度拟合问题[29],其中k取5。实验中分类准确率计算过程为:将总数据样本随机分成5 份,选择其一作为验证集,其余4 个作为训练集,每个子样本用作测试集一次,交叉验证重复5 次,分类准确率就为5 次分类结果的平均值。为了避免实验的偶然性结果,最终分类准确率结果为重复以上实验10 次后的平均值。
除了统计分类准确率,实验还使用敏感性和特异性来评估分类方法的性能。灵敏度为检测出真阳性数与实际真阳性数比值,越大的值检测EMCI 的性能越好。特异度为检测出真阴性数与实际真阴性数比值,越大的值检测非EMCI 的性能越好。
另外,文中所用的SAE 基于DeepLearnToolbox-master,下载地址为https://github.com/xiayuan/DeepLearnToobox-master。MobileNet 采用tensorflow 平台中函数,下载地址为https://github.com/tensorflow/models/treemaster/research/slim,使用的预训练权重为Imagent 公开的数据,下载网址为https://github.com/fchollet/deep-learningmodels/releases/tag/v0.6。
4.3 分类性能
首先,给出各方法的分类准确率,如表3 所示。从表3 可以看到,SAE_ROI 的分类准确率为59%,其余3 种方法均超过了59%,这表明利用SAE 提取ROI 特征的方法分类准确率并不高。在用相关系数降维的方法中,利用迁移学习提取相关系数特征值的方法要优于用SAE 的方法约0.17%。分类准确率最高的是利用迁移学习提取ROI 特征值的方法,它能使分类准确率达到约74%,与其余的SAE_ROI、SAE_Corr 和Transf_Corr3 种方法的分类准确率相比,分别提升了近14.67%、10.17%和10%。该结果也表明了,利用迁移学习提取ROI 特征值在分类信息的损失上要小于提取相关系数特征值,因此分类准确率也得到了提高。
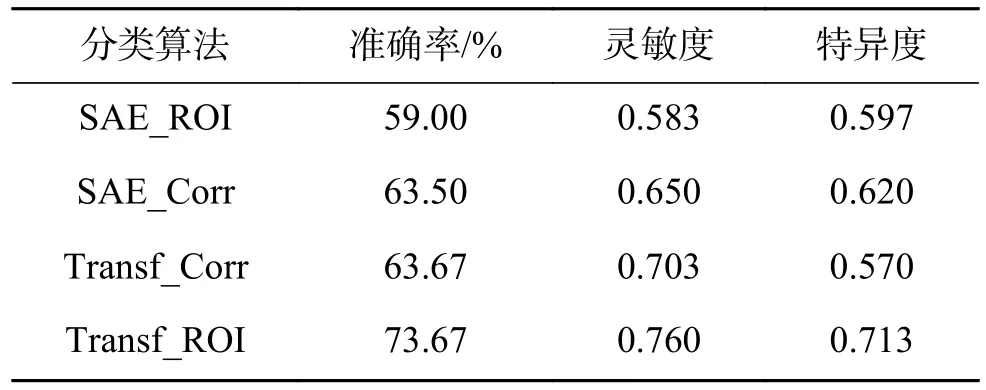
表3 分类方法的分类准确率Table 3 Classification accuracy of classification method
表3 还给出了灵敏度和特异度的实验结果。从该结果中可以发现,Transf_ROI 的灵敏度为0.760,高于Transf_Corr(0.703)、SAE_Corr(0.650)和 SAE_ROI(0.583)。而Transf_ROI 的特异度为0.713,这在所讨论的方法中也是最高的,高于Transf_Corr(0.570)、SAE_Corr(0.620) 和SAE_ROI(0.597)。
图7 给出了采用Transf_ROI 方法所提取的特征值结果图,其中图7(a)是在TOP 层分类网络的第3 全连接层所提取的所有NC 特征值均值,图7(b)是相应所有EMCI 特征值均值。从图中可以看到,虽然两幅特征值图的绝大部分像素值均在50 左右,但是还是存在一定的差异性。例如,对于EMCI 组,其在第13 列的3、17、35 和50 行的像素值一道道200 左右,而NC 组相应位置仍在50 左右。该结果也与表3 的结果一致,表明利用迁移学习提取特征值在两个组别确实存在差异性,因而可以将两个组别的被试进行分类。
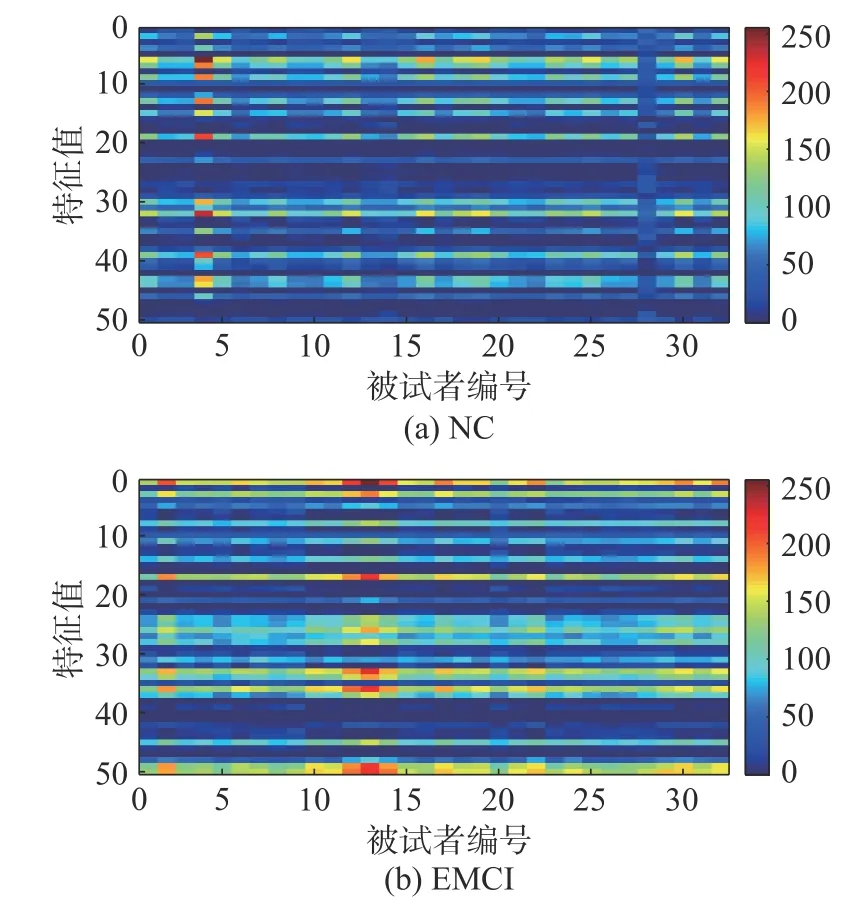
图7 Transf_ROI 中第3 层全连接层中提取的特征值Fig.7 Feature values extracted from the 3rd fully connected layer in Transf_ROI
图8 给出了4 种分类方法在10 次实验中的分类准确率波动情况,整体看,其曲线由高到低排列大致是Transf_ROI、Transf_Corr、SAE_Corr以及SAE_ROI,与表3 中的结果一致。并且在10 次实验中,Transf_ROI 方法在7 次实验中都取得了最高的分类准确率,这也表明,不仅在平均值上Transf_ROI 方法分类准确率较高,而且对于单次实验,Transf_ROI 的方法的分类准确率也大概率高于其他方法。同时,在10 次实验中,Transf_ROI 和Transf_Corr 的分类准确率分别稳定在70%~80% 和60%~75%,而SAE_Corr 和SAE_ROI 的分类准确率在10 次实验中的波动较大,可能是由于数据量不足。
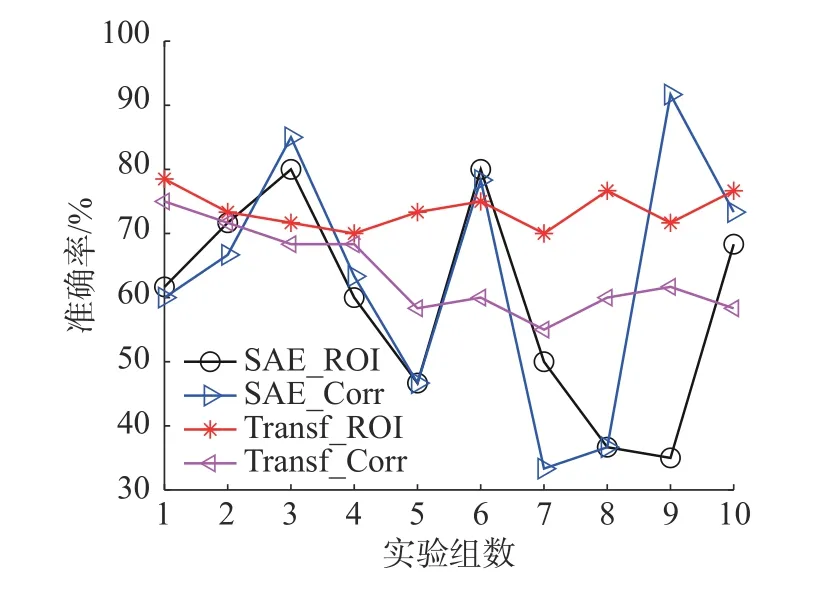
图8 10 次实验中的分类准确率Fig.8 Classification accuracy in ten experiments
4.4 分类时间
给出在不同数据输入及不同模型的条件下提取特征时间和分类时间,其中提取特征时间为分别从时间序列数据及相关系数数据中提取特征以供分类网络所占用的时间;分类时间是对全部的被试者,将其从时间序列数据及相关系数数据中提取到的特征,送入分类网络获得分类结果所用的时间。所有实验方法均在Inter(R) Core(TM) i5-6300HQ(4 核)的中央处理单元(central processing unit,CPU)环境下运行,未采用任何图形处理器(graphics processing unit,GPU)。表4 给出了在不同模型和不同数据输入时的提特征取和分类时间,从表中可以看出,与SAE 方法相比,Transf 方法在特征提取时所用的时间减少了近80%,且所用的分类时间也都有减少,网络总运行时间减少了约60%。这都表明在相同的环境下,使用迁移学习对EMCI 进行分类所耗费的时间少于SAE 的方法,其原因也在于迁移学习其实具有更少的权重数量。

表4 模型性能指标Table 4 Model performance indicators s
4.5 顶层网络参数设置
本文主要分析Transf_ROI 的顶层网络的全连接层数对分类性能的影响,其最终参数在表2 列出。在这里,给出不同的顶层网络参数设置对最终分类结果带来的不同影响。图9 分别给出了采用Transf_ROI 中池化层所提取的NC 组和EMCI 组特征值的结果图,从图中可以看到,两个组别的大部分像素值均在50 左右,当然,存在一部分像素值超过了150,但其所在两个组别的位置也没有存在明显差异性。该结果表明,仅靠池化层提取的特征还不能将两组进行区分,需要加入全连接层。

图9 Transf_ROI 中池化层中提取的特征值Fig.9 Feature values extracted from the pooling layer in Transf_ROI
全连接层的层数也会对实验结果产生影响,图10 和图11 分别给出了在1~4 层全连接层时的分类准确率和运行时所用的迭代次数。从图10中可以看出,在使用3 层全连接层时,分类准确率最高,且在10 组实验中,有6 次是最高值。如图7所示的第3 层全连接层中提取的特征值的组间差异性明显大于如图9 所示的池化层中提取的特征值的组间差异性,因此加入全连接层是十分有必要的。
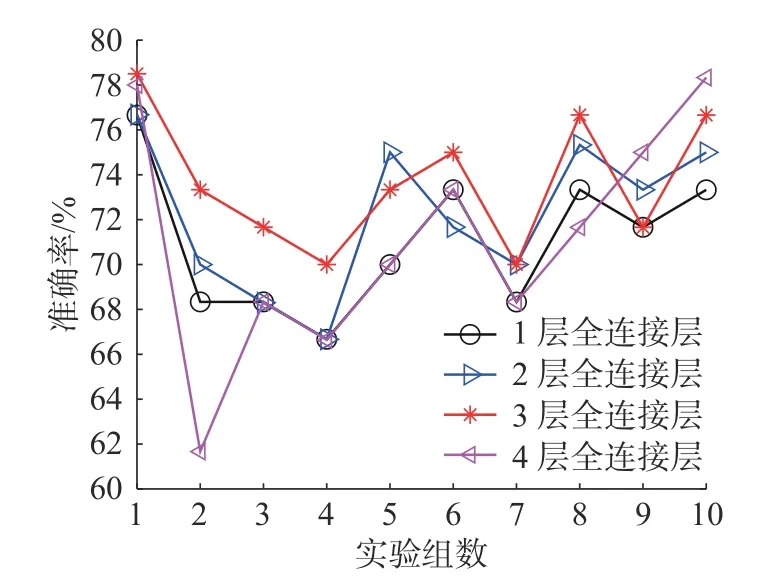
图10 TOP 层具有1、2、3 和4 个全连接层时的测试精度Fig.10 Test accuracy when TOP layer has 1,2,3 and 4 fully connected layers
而在图11 中可以看出,随着全连接层层数的增多,迭代次数在相应地减少,但减少的程度在降低。根据图10 和图11 综合考虑分类准确率和迭代次数后,我们的实验选用了3 层全连接层的设置。

图11 TOP 层具有1,2,3 和4 个全连接层时的EpochFig.11 Epoch when TOP layer has 1,2,3 and 4 fully connected layers
5 讨论
针对rs-fMRI 数据的EMCI 分类问题,本文采用迁移学习MoblieNet 网络对ROI 时间序列进行特征提取,再进入到分类网络进行分类。实验结果表明,本文的方法较传统方法的分类准确率有所提升,且运行时间也有较大程度的减少,但还有以下几点需要进一步进行讨论。
实验中,本文方法的分类准确率为73.67%,虽然比其他几种传统方法高,但低于文献[22]给出的86% 的分类结果,该文献采用SAE 来提取Pearson 相关系数的特征,其主要原因在于,所使用的数据集较小,被试者数为64,而文献[22]所用被试数为170。虽然本文所采用的ADNI-2 数据库中,有关EMCI 的rs-fMRI 数据确实较多,但与其对应的MRI 数据却相对较少。没有对应MRI 数据将无法进行良好配准,这会导致一些混淆变量不能有效去除,如脑脊液和白质等,而该混淆变量又会影响分类结果。因此,最后能够满足实验条件的rs-fMRI 数据量就较小。当然,实验中的所采用方法无论是迁移学习还是传统方法,面向的数据集是相同的,即本文方法的性能提升是在同样数据条件下所获得的。在未来的工作中,我们将会尝试更多的可用数据,以进一步来验证本文的研究。
另外,在顶层参数设置的实验中,仅给出了全连接层数的实验结果,而未对其他参数作进一步讨论,这主要是因为相对于其他参数,全连接层数对分类结果的影响比较大。对于激活函数,我们也尝试了一些常用的函数,如ReLu、Softplus 等[30],但发现这些函数的分类结果并没有较大差别,因此选择了较为常见的Softplus。当然,还有一些参数对顶层性能也非常重要,例如全连接层节点数。节点数量可以根据经验确定,若节点数太小,网络将无法适应复杂分类,若节点数太大,会增加训练时间且可能产生过拟合。在本文的顶层网络中,将3 个全连接层的节点数分别设置为200、100 和50。最后还有一个重要的顶层参数是Dropout 层的神经元丢弃率,将其值设为大于0 时,会降低分类网络对训练数据的拟合程度,从而得到较低的分类准确率,因此最后将其设置为0。
6 结束语
针对通过rs-fMRI 信号来诊断EMCI 问题,本文提出了一种采用MobileNet 的迁移网络来提取ROI 时间序列特征的方法。对于4D 的rs-fMRI信号,采用迁移学习来提取特征值可以使网络的训练时间大幅度下降,并能减少瞬时信息的丢失。本文在实验中,采用了ADNI-2 的rs-fMRI 数据,并用DPABI 工具箱对这些数据进行预处理,将本文算法与从相关系数提取特征值的方法进行了对比,结果显示本文算法的分类准确率比传统的相关系数方法提高了约10%,而网络的分类时间大约只有用SAE 提取相关系数特征方法的25%。该结果说明,ImageNet 数据库中预训练的迁移网络从ROI 提取特征的分类准确率要高于从脑区网络的功能性连接提取特征的方法,并且这种方法还可减少特征提取的时间和分类网络运行时间。
