一种新的最大相关最小冗余特征选择算法
2021-09-11李顺勇王改变
李顺勇,王改变
(山西大学 数学科学学院,山西 太原 030006)
特征选择是数据挖掘、机器学习和模式识别中的一项重要技术,是当前信息领域的研究热点之一[1-3]。它在数据分析和预处理过程中起着非常重要的作用。特征选择在不改变特征原始表达的基础上,仅从特征集中筛选最能代表数据特点的最优特征子集。因此,不仅可以去除不相关和冗余信息,降低训练样本的维度和分类样本的复杂度,而且能很好地保持原始特征包含的信息,对于人们理解和判断观测来说更加容易。特征选择根据其是否与后续学习算法独立可以分为过滤式和封装式两种。过滤式特征选择方法独立于后续的学习算法,通过数据的本质属性对所有特征进行评分,在此评价过程中不会借用分类模型来完成[4-5]。其中具有代表性的方法有T 检验(Ttest)[6]、Fisher score[7]、信息增益(information gain,IG)[8]等。但是,过滤式特征选择方法往往会忽略特征之间的相关性。封装式特征选择算法与后续学习算法相关,利用学习算法的性能评价所选特征子集的好坏,因此在精度方面要优于过滤式特征选择[8-12]。基于特征选择的目的,已经有部分学者做了相关研究。例如,传统的基于空间搜索的最大相关最小冗余(minimal redundancy maximal relevance,MRMR)[13]算法,使用互信息来度量特征之间的冗余度以及与类别之间的相关度,并且利用信息熵和信息差两个函数来选取最优特征子集。但是,由于冗余度和相关度的评价准则单一,所以使得该特征选择算法的使用范围较窄。2018 年,郭凯文等[14]提出了基于特征选择和聚类的分类算法,特征选择标准采用的是传统的基于空间搜索的最大相关最小冗余准则,将信息差作为目标函数来求解最优特征子集。虽然该算法在目标函数中增加了相关度和冗余度的权重因子,但是,在求解最优特征子集的过程中需要对权重因子不断地赋值以寻求最优子集,计算量较大;2020 年,李纯果等[15]提出的基于排序互信息的无监督特征选择,是基于排序互信息反应的两属性之间的单调关系,用每个属性与其他属性之间的平均互信息,来衡量每个属性与排序学习的相关度,平均互信息最高的视为排序最相关的属性。但是,该算法忽略了特征与特征之间的冗余度,只在低维度且样本量较少的模拟数据集上进行了有效性验证,对真实数据集的特征选择效果不明了;2020 年,刘云等[16]提出了混合蒙特卡罗搜索的特征选择算法的优化,根据蒙特卡罗树搜索方法生成了一个初始特征子集,然后利用ReliefF 算法选择前k个特征组成候选特征集,最后,用KNN 分类器的分类精度评估候选特征,选择高精度的候选特征作为最佳特征子集。然而,ReliefF 算法是从同类和不同类中各选取k个近邻样本,求平均值得到各个特性权值,即特征与类别之间的相关性,并没有考虑特征与特征之间的冗余度。2020 年,周传华等[17]提出的最大相关与独立分类信息最大化特征选择算法,用互信息度量特征与类别之间的相关性,用独立分类信息综合衡量新分类信息和特征冗余,尽管在特征选择过程中综合考虑了特征与类别的相关性、特征之间的冗余性,以及特征包含的新分类信息,并结合最大最小准则对特征的重要性进行了非线性评价,但其目标函数与传统的MRMR 算法的目标函数类似,依然不能根据客户的实际需求进行特征选择。
针对上述特征选择算法中存在的冗余度和相关度的度量准则单一以及评价函数问题,提出了新方案。在冗余度度量准则方面引入了2 种不同的方法,在相关度度量准则方面引入了4 种不同的方法,从而组合衍生出8 种特征选择算法,提出了新的目标函数。
1 新的特征选择算法
MRMR 算法是最常用、最典型的基于空间搜索的特征选择算法。其中,最大相关即特征与类别间的相关度要最大,最小冗余即特征与特征之间的相关度要最小[18-19],该算法中,冗余度和相关度均是利用互信息作为度量准则,就效能而言,比只考虑特征与类别之间的相关度,或者只考虑特征之间冗余度的特征选择算法要好。但是,在现实生活中,我们面临的数据往往纷繁复杂,面对不同的数据,MRMR 算法呈现出的效果有较大差异,从而降低了该算法的适用范围。
针对MRMR 算法存在的问题,提出一种新的最大相关最小冗余特征选择算法(new algorithm for feature selection with maximum relation and minimum redundancy,New-MRMR)。这里New-MRMR 算法仅是新提出的一个特征选择的框架,在度量特征与特征之间冗余度时选用了2 种评价准则,在度量特征与特征之间相似度时选用了4 种评价准则,从而衍生出8 种特征选择算法,当面对不同的用户需求时,选用不同特征选择算法,使得新提算法的适用范围更广。具体的特征选择流程见图1。
图1 可以看出,特征选择算法的基本流程为:先对原始数据集进行预处理,将原始数据集分为测试集和训练集,然后,在训练集上选择不同的冗余度和相关度评价准则来训练模型,进行特征选择,得到最优特征子集,最后,利用测试集来验证模型的有效性。
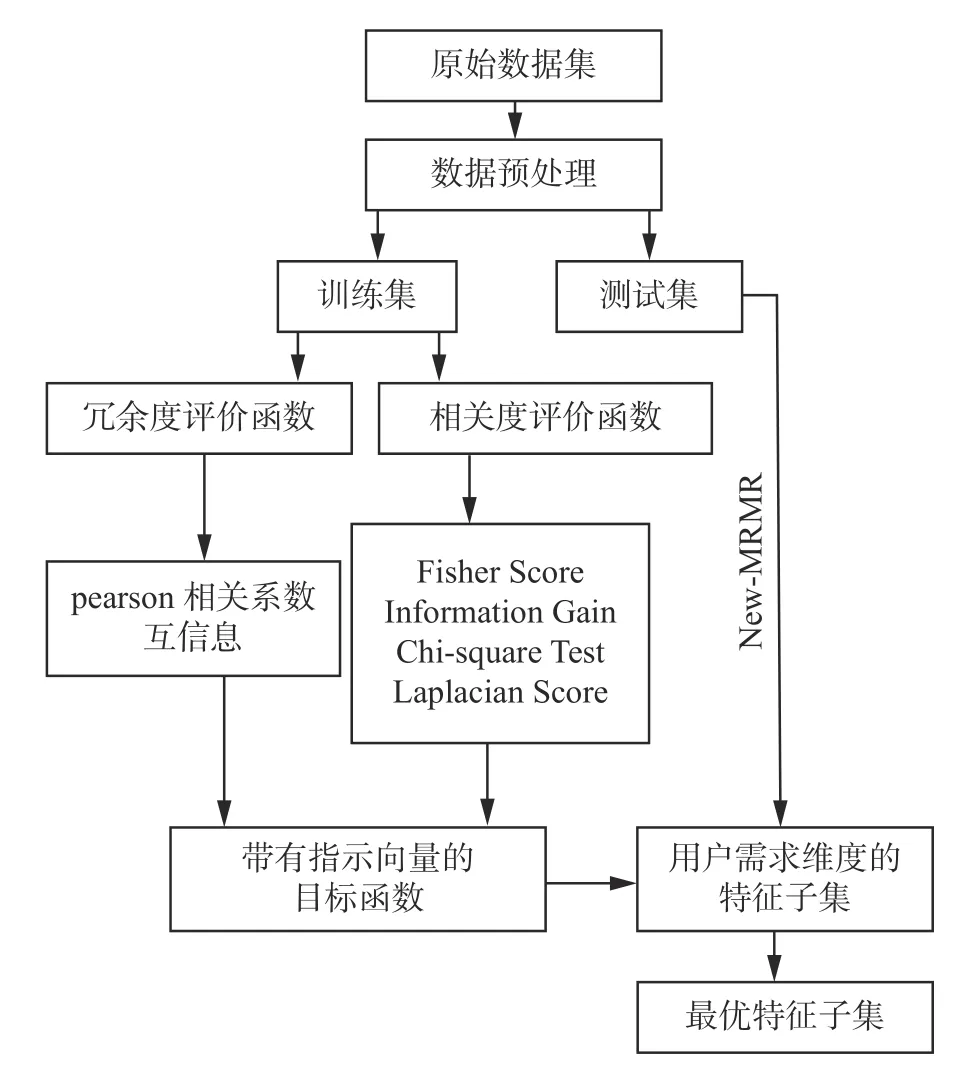
图1 New-MRMR 特征选择流程Fig.1 New-MRMR feature selection flow
1.1 冗余度评价准则
特征选择是为了去除原始特征集中的冗余特征,达到降维目的。因此,利用冗余度评价可以作为New-MRMR 特征选择算法的一部分,其基本思想是:两个特征的相关度越大,则这两个特征冗余度也越高。但是,由于评价特征之间冗余度以及特征与类别之间相关度的准则众多,且目前缺乏相关研究给出具体哪种方法更适用于哪种数据类型。所以,本文新提出的算法仅采用了Pearson 相关系数[14]以及互信息[14]两种准则来度量特征之间的冗余度。
1.2 相关度评价准则
在特征选择过程中,通常优先选择与类别相关度较大的特征,而特征的重要度在一定程度上反映了与类别的相关度大小,因此,相关度的度量准则就转化成了特征重要度的衡量。衡量特征重要度的评价准则有很多,例如:Fisher score[7]、信息增益(information gain,IG)[8]、Laplacian Score[20]、Chi-squar Test[21-22]等。Fisher score 主要是按照类内距离小,类间距离大的原则,选出包含鉴别信息比较多的特征,其值越大,说明该特征越重要,与类别的相关度越大;信息增益是通过计算某特征被使用前后的信息熵来为该特征进行打分,信息增益越大,说明该特征越重要,与类别的相关度越大;Laplacian Score 是根据拉普拉斯特征映射等对单个特征评分,然后选出方差和局部几何结构保持能力较强的特征,其分值越高,特征越重要。New-MRMR 算法也采用这4 种评价准则作为相关度的度量准则。
1.3 目标函数
基于特征选择和聚类的众多分类算法中,目标函数常采用加权的信息差方式,并且通过对权重信息不断赋值来求解最优特征子集,不能根据不同用户实际需求的维度求解最优特征子集。因此,本文提出了一种新的目标函数,引入了一个指示向量 λ 以及参数k来表示所选的特征维度。具体目标函数如下:

式中:k为用户需求的实际数据维度;D为冗余度矩阵;C为特征与类别之间的相关性矩阵。λ=[λ1λ2··· λn]T,n为原始特征集的特征数。当λi取值为0 时,说明对应的特征不会被选择进最终的特征子集,λi取值越大时,表明其对应的特征越容易被选进最终的特征子集。
对于该目标函数的求解,与最优化标准二次规划问题[23]相似,本文采用成对更新方法[24]来求解以上目标函数的最优解。
2 实验结果与分析
2.1 数据集信息及评价指标
为验证New-MRMR 算法的有效性,本文使用了4 个真实的UCI 数据集。先利用新提出的算法处理原始特征,进而使用支持向量机对所得到的特征子集进行分类实验,最后比较各种算法在测试集上的分类准确率(classification precision,CP)。相关定义如下:
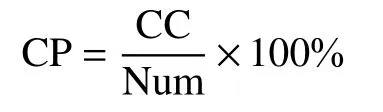
式中:CC(correct classification,CC)为正确分类的样本数量;Num 为样本数量总数。
表1 为4 个UCI[25]数据集的具体信息:

表1 实验数据集Table 1 Experimental data set
实验中,与新提算法进行对比的特征选择算法分别是:Fisher Score、基于Information Gain 的方法、基于Laplacian Score 的方法、基于Chi-squar Test 的方法、基于MRMR 的方法。表2 列出了以上方法。
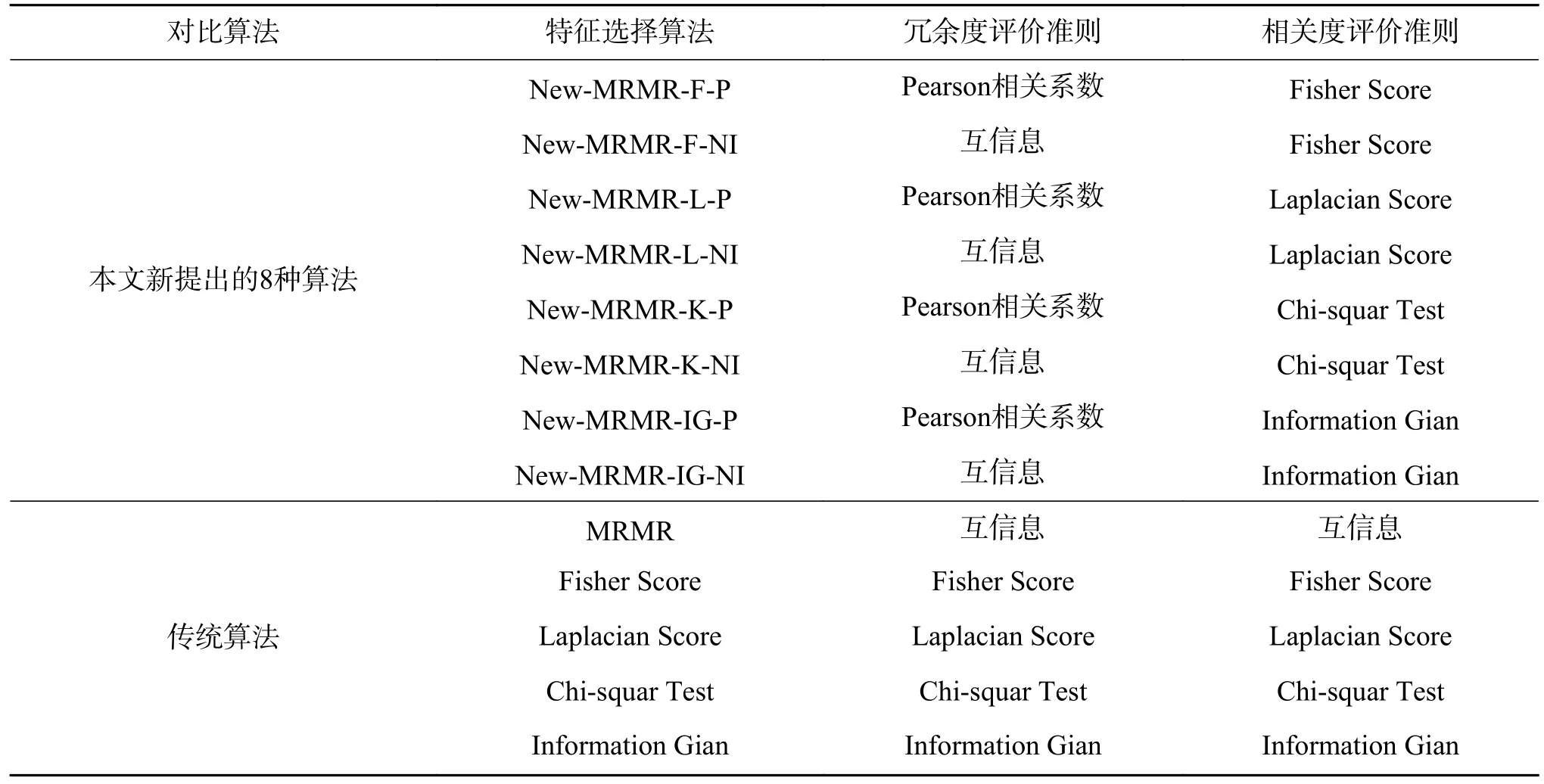
表2 新提出的8 种特征选择算法与其他算法对比Table 2 Comparison of 8 newly proposed feature selection algorithms with other algorithms
2.2 实验结果对比分析
特征选择过程是剔除原始数据集中的不相关以及冗余特征,达到数据降维目的。为验证以上各种算法在数据降维和用支持向量机分类后的分类准确率,表3 给出了以上各种算法在数据集isolet上的实验结果,即经支持向量机分类后,计算得到的分类准确率达到最大时所选择的特征数。
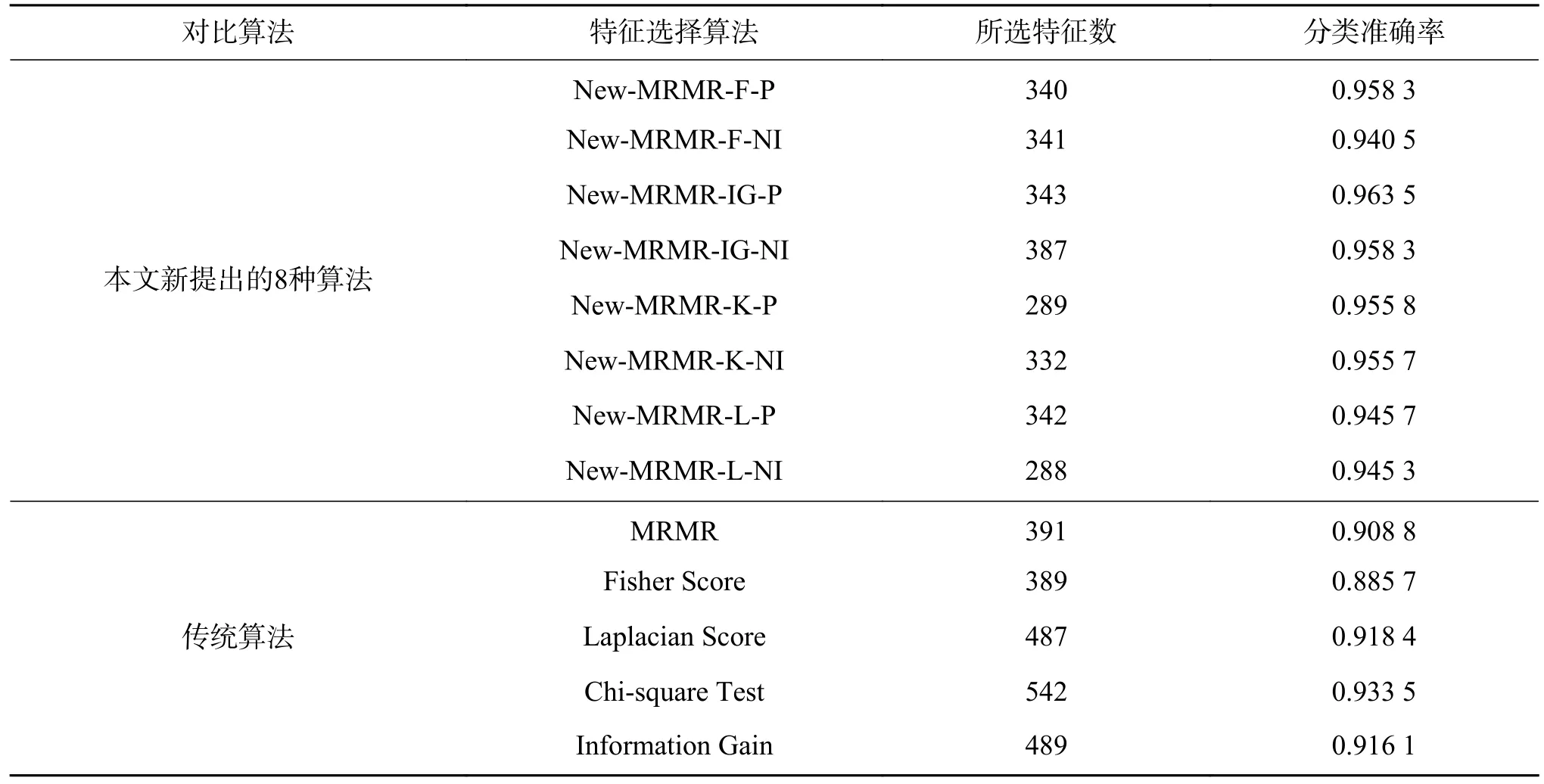
表3 分类准确率最大时,数据集isolet 上各种算法分别所选择的特征数Table 3 Number of features selected by various algorithms when the Classification precision is maximum on the isolet dataset
由表3 可以看出,由以上各种算法对数据集isolet 进行特征选择后,利用支持向量机对所选特征子集进行分类,本文新提出的8 种特征选择算法的分类准确率,均高于传统的5 种特征选择算法,尤其是新提出的算法New-MRMR-IG-P,其分类准确率达到了0.963 5,远高于传统的5 种特征选择算法。在保证准确率的情况下,其所选的特征数也均小于传统的5 种特征选择算法。可见,本文新提出的特征选择算法在数据降维方面效果更佳。
图2 是在数据集isolet 上,本文新提出的特征选择算法New-MRMR-F-NI、New-MRMR-F-P,传统特征选择算法MRMR、Fisher Score 在不同维度下的分类准确率变化趋势。
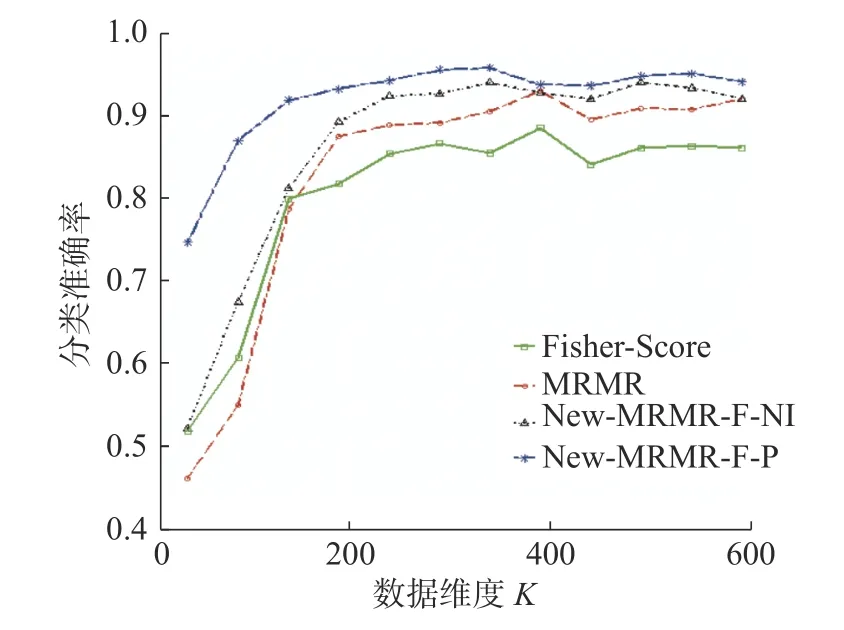
图2 New-MRMR-F-NI、New-MRMR-F-P、Fisher-Score、MRMR 在数据集isolet 上分类准确率的变化趋势Fig.2 Correct classification trend of New-MRMR-F-NI,New-MRMR-F-P,Fisher-Score,MRMR on the dataset isolet
从图2 可以看出,对于在不同维度下的分类准确率,新提出的特征选择算法New-MRMR-FNI、New-MRMR-F-P 明显高于传统算法Fisher Score、MRMR。所以,对于减少原始特征集中的冗余和不相关特征,New-MRMR-F-NI、New-MRMR-F-P 有更好的优势。
不同维度下,本文新提算法New-MRMR-KNI、New-MRMR-K-P,传统算法MRMR、Chi-Square-Test 在数据集isolet 上的分类准确率变化趋势见图3。

图3 New-MRMR-K-NI、New-MRMR-K-P、Chi-Square-Test、MRMR 在数据集isolet 上分类准确率的变化趋势Fig.3 Correct classification trend of New-MRMR-K-NI、New-MRMR-K-P、Chi-Square-Test、MRMR on the dataset isolet
图3 显示,不同维度下,New-MRMR-K-P 的分类准确率曲线明显高于传统特征选择算法,并且,在所选特征子集数为289 时,其分类准确率达到了最高,既很好地去除了原始特征集中的冗余和不相关特征,又保证了分类准确率。此外,算法New-MRMR-K-P 除了在维度为195 时的分类准确率与传统算法MRMR 相近之外,在其他维度上的分类准确率均高于Chi-Square-Test、MRMR。可见,本文新提出的特征选择算法效果更佳。
不同维度下,新提出的特征选择算法New-MRMR-L-NI、New-MRMR-L-P,传统特征选择算法MRMR、Laplacian-Score 的分类准确率变化趋势见图4。
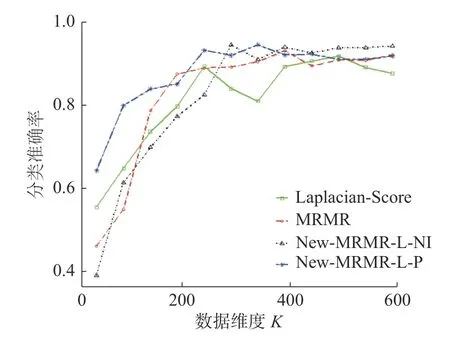
图4 New-MRMR-L-NI、New-MRMR-L-P、Laplacian-Score、MRMR 在数据集isolet 上,分类正确的变化趋势Fig.4 Correct classification trend of New-MRMR-L-NI、New-MRMR-L-P,Laplacian-Score,MRMR on the dataset isolet
图4 显示,在特征维度为342 的时候,算法New-MRMR-L-P 的分类准确率就已经达到了最高,并且大于传统算法Laplacian-Score、MRMR 的最大分类准确率。此外,在分类准确率达到最高时,算法New-MRMR-L-NI 所选的特征子集数仅为288,远小于传统算法Laplacian-Score、MRMR 所选的特征子集数。因此,新提出的算法New-MRMR-L-NI、New-MRMR-L-P 对于特征选择效果更好。
不同维度下,新提出的特征选择算法New-MRMR-IG-NI、New-MRMR-IG-P,传统特征选择算法MRMR、Laplacian-Score 的分类准确率变化趋势见图5。
由图5 可以看出,在不同维度下,算法New-MRMR-IG-NI、New-MRMR-IG-P 分类准确率的曲线,均高于传统的两种特征选择算法Information-Gain、MRMR 所代表的曲线。分类准确率越高,表明所选特征子集越好。可见,新出的算法New-MRMR-IG-NI 以及New-MRMR-IG-P 在特征选择方面更加有效。
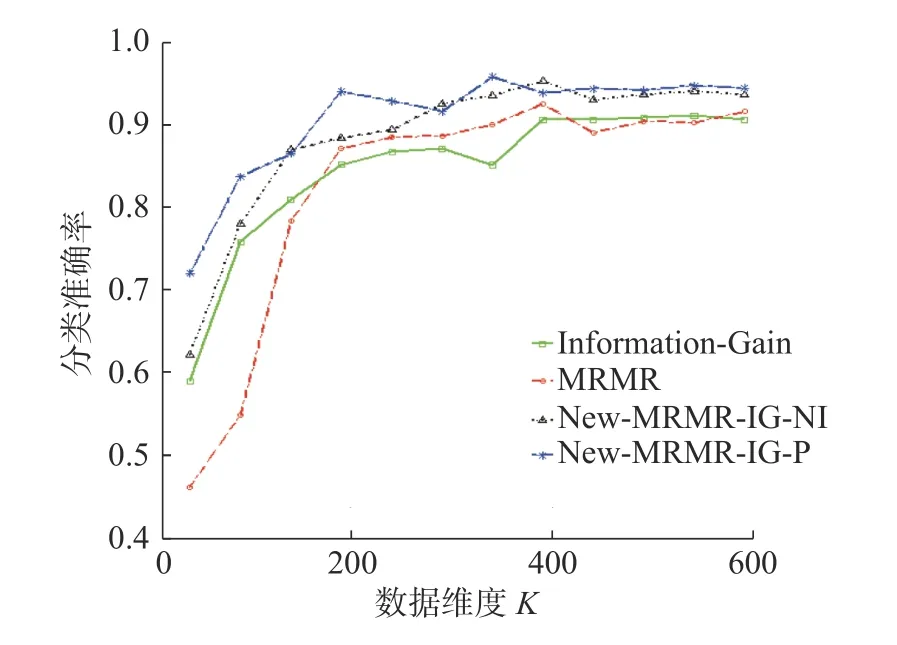
图5 New-MRMR-IG-NI、New-MRMR-IG-P、Information-Gain、MRMR 在数据集isolet 上,分类准确率的变化趋势Fig.5 Correct classification trend of New-MRMR-IG-NI,New-MRMR-IG-P,Information-Gain,MRMR on the dataset isolet
表4 给出了以上各种算法在数据集waveform 上的实验结果,即经支持向量机分类后计算得到的分类准确率达到最大时所选择的特征数。
表4 显示,在数据集waveform 上,本文新提出的算法New-MRMR-F-P 的最大分类准确率达到了0.953 4,远大于传统特征选择算法的分类准确率;并且New-MRMR-F-P 在分类准确率达到最大时,所选的特征子集数仅为17,小于传统的5 种特征选择算法在分类准确率达到最大时所选的特征子集数。除此之外,本文新提出的其余特征选择算法的分类准确率,也均大于传统的特征选择算法的分类准确率,且所选特征子集数相对来说较小。因此,综合考虑分类准确率以及所选特征子集维度两个方面,本文新提算法特征选择效果更加明显。

表4 分类准确率最大时数据集waveform 上各种算法分别所选择的特征数Table 4 Number of features selected by various algorithms when the Classification precision is maximum on the waveform dataset
不同维度下,本文新提出的特征选择算法New-MRMR-F-NI、New-MRMR-F-P,传统特征选择算法MRMR、Fisher Score 在数据集waveform 上的分类准确率变化趋势见图6。
由图6 看出,在数据集waveform 上,New-MRMR-F-P 的表现最好,其所代表的曲线远高于传统的特征选择算法MRMR、Fisher-Score 所代表的曲线。此外,虽然在维度为24 时,算法New-MRMR-F-NI的分类准确率低于传统算法MRMR、Fisher-Score。但是,在其余维度上,New-MRMR-F-NI 的分类准确率均高于MRMR、Fisher-Score。综合分析,本文新提算法New-MRMR-FNI、New-MRMR-F-P 的特征选择效果更好。
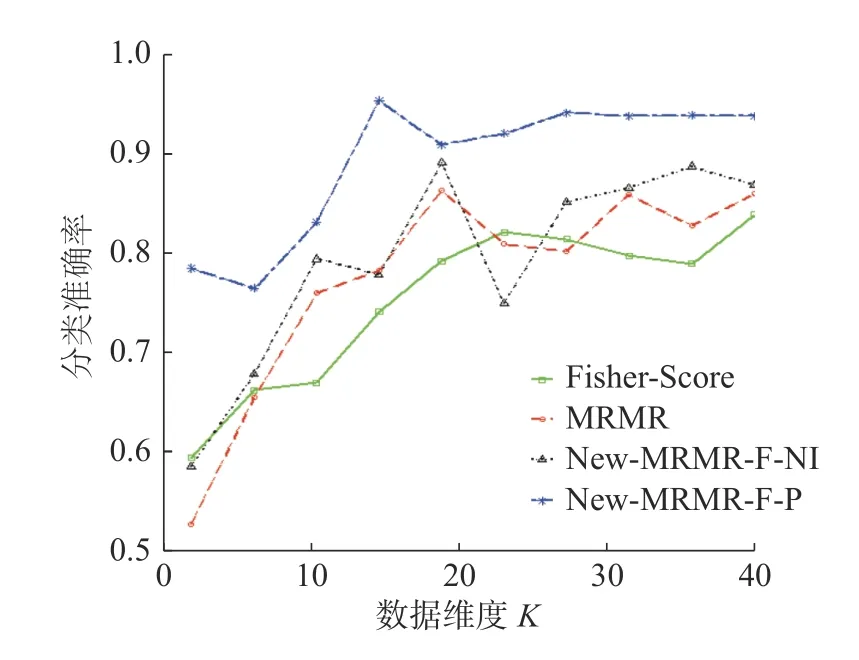
图6 New-MRMR-F-NI、New-MRMR-F-P、Fisher-Score、MRMR 在数据集waveform 上,分类准确率的变化趋势Fig.6 Correct classification trend of New-MRMR-F-NI New-MRMR-F-P,Fisher-Score,MRMR on the dataset waveform
不同维度下,算法New-MRMR-K-NI、New-MRMR-K-P 以及传统特征选择算法MRMR 以及Chi-Square-Test 在数据集waveform 上的分类准确率变化趋势见图7。
图7 显示,维度为20 时,New-MRMR-K-NI 的分类准确率就达到了最大,大于MRMR、Chi-Square-Test 的最大分类准确率。并且其所选特征子集数小于MRMR、Chi-Square-Test 的最优特征子集数。此外,算法New-MRMR-K-P 的分类准确率曲线高于MRMR、Chi-Square-Test 的分类准确率曲线。所以,在waveform 数据集上,本文新提出的算法New-MRMR-K-NI、New-MRMR-K-P 的特征选择效果更好。
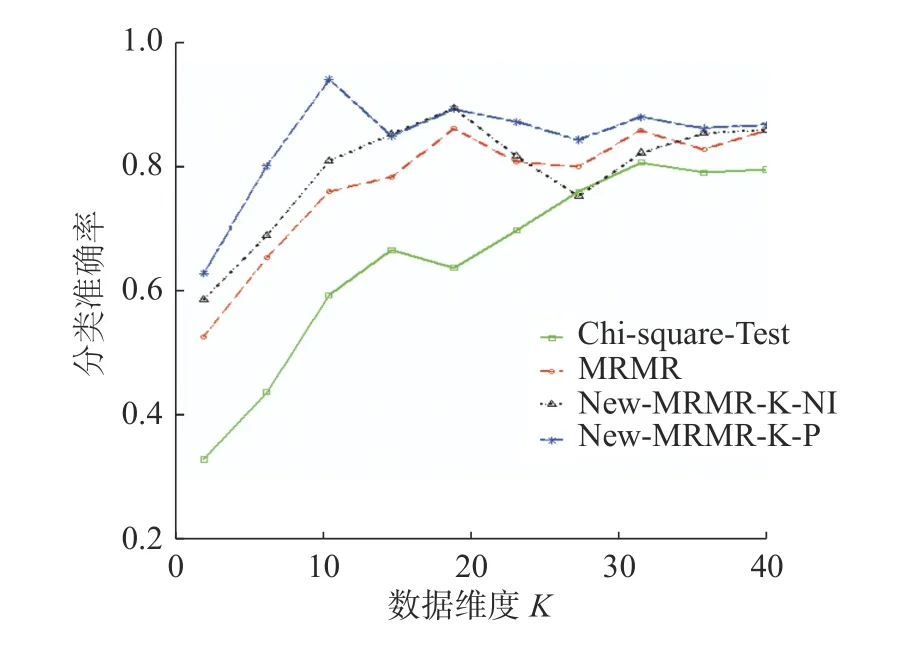
图7 New-MRMR-K-NI、New-MRMR-K-P、Chi-Square-Test、MRMR 在数据集waveform 上,分类准确率的变化趋势Fig.7 Correct classification trend of New-MRMR-K-NI,New-MRMR-K-P,Chi-Square-Test,MRMR on the dataset waveform
不同维度下,算法New-MRMR-L-NI、New-MRMR-L-P,传统特征选择算法MRMR、Laplacian-Score 在数据集waveform 上的分类准确率变化趋势见图8。
图8 显示,New-MRMR-L-NI 的分类准确率高于传统算法MRMR、Laplacian-Score。在分类准确率达到最大时,New-MRMR-L-NI 所选特征子集数仅为20,小于MRMR、Laplacian-Score 的最优特征子集数。另外,新提算法在多数维度上均大于传统算法MRMR、Laplacian-Score 的分类准确率。由于分类准确率越高,特征选择效果越好,所以,在数据集waveform 上,New-MRMR-L-NI、New-MRMR-L-P 的特征选择效果更好。
图8 New-MRMR-L-NI、New-MRMR-L-P、Laplacian-Score、MRMR 在数据集waveform 上,分类准确率的变化趋势Fig.8 Correct classification trend of New-MRMR-L-NI,New-MRMR-L-P,Laplacian-Score,MRMR on the dataset waveform
不同维度下,New-MRMR-IG-NI、New-MRMRIG-P、传统算法MRMR、Information-Gain 在数据集waveform 上分类准确率变化趋势见图9。
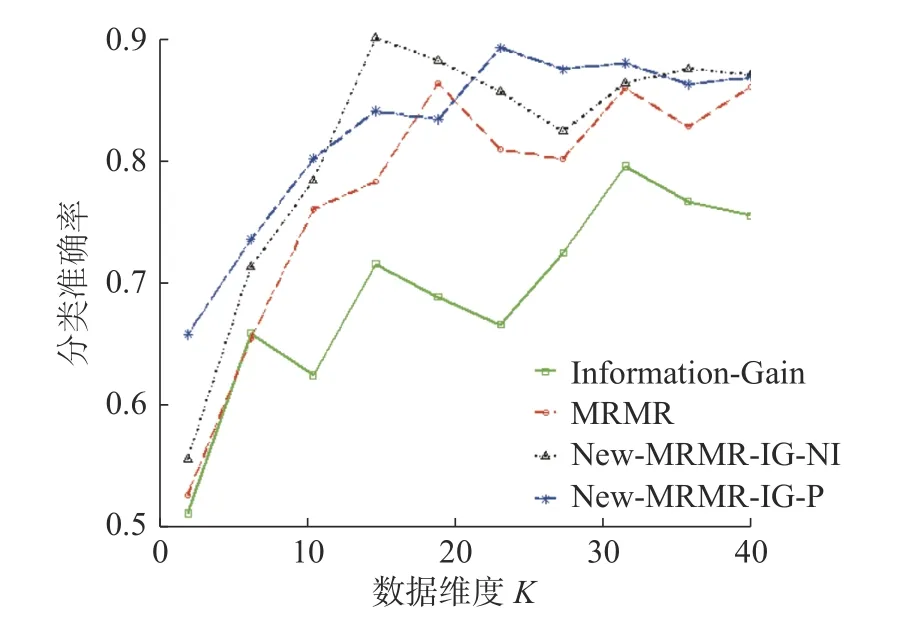
图9 New-MRMR-IG-NI、New-MRMR-IG-P、Information-Gain、MRMR 在数据集waveform 上,分类准确率的变化趋势Fig.9 Correct classification trend of New-MRMR-IG-NI,New-MRMR-IG-P,Information-Gain,MRMR on the dataset waveform
图9 显示,在数据集waveform 上,算法New-MRMR-IG-NI 的分类准确率的曲线高于传统的算法MRMR、Information-Gain 的分类准确率。且算法New-MRMR-IG-P 的分类准确率在维度为24 时达到最大。维度为11 时,New-MRMR-IGP 的分类准确率略低于MRMR、Information-Gain,但是,在其余维度上均大于MRMR、Information-Gain。综上分析,在数据集waveform 上,本文新提出的特征选择算法效果明显。
表5 给出了以上各种算法在数据集clean 上的实验结果,即经支持向量机分类后,得到的分类准确率达到最大时所选择的特征数。

表5 分类准确率最大时数据集clean 上各种算法分别所选择的特征数Table 5 Number of features selected by various algorithms when the Classification precision is maximum on the clean dataset
由表5 可以看出,在分类准确率方面,本文新提出的算法的最大分类准确率均高于5 种传统的特征选择算法。在分类准确率达到最优时所选的特征子集数方面,尤其是算法New-MRMR-K-NI,其所选的特征子集数仅20,远小于原始的特征子集数。所以,对于数据集clean 而言,本文新提出的特征选择算法更加有效。
不同维度下,算法New-MRMR-F-NI、New-MRMR-F-P、传统特征选择算法MRMR、Fisher Score 在数据集clean 上的分类准确率变化趋势见图10。
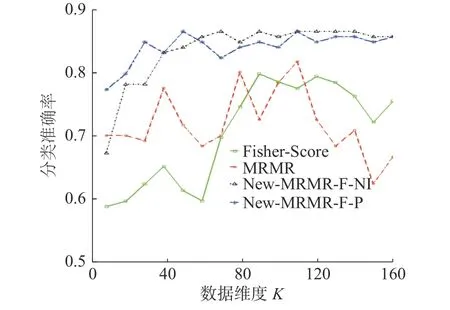
图10 New-MRMR-F-NI、New-MRMR-F-P、Fisher-Score、MRMR 在数据集clean 上分类准确率的变化趋势Fig.10 Correct classification trend of New-MRMR-F-NI,New-MRMR-F-P,Fisher-Score,MRMR on the dataset clean
由图10 可以看出,本文新提算法New-MRMRF-NI、New-MRMR-F-P 的分类准确率曲线均MRMR、Fisher-Score 的分类准确率的曲线之上。由此可见,在数据集claen 上,算法New-MRMR-FNI、New-MRMR-F-P 的特征选择结果更优。
不同维度下,算法New-MRMR-K-NI、New-MRMR-K-P、传统特征选择算法MRMR、Chi-Square-Test 在数据集clean 上的分类准确率变化趋势见图11。
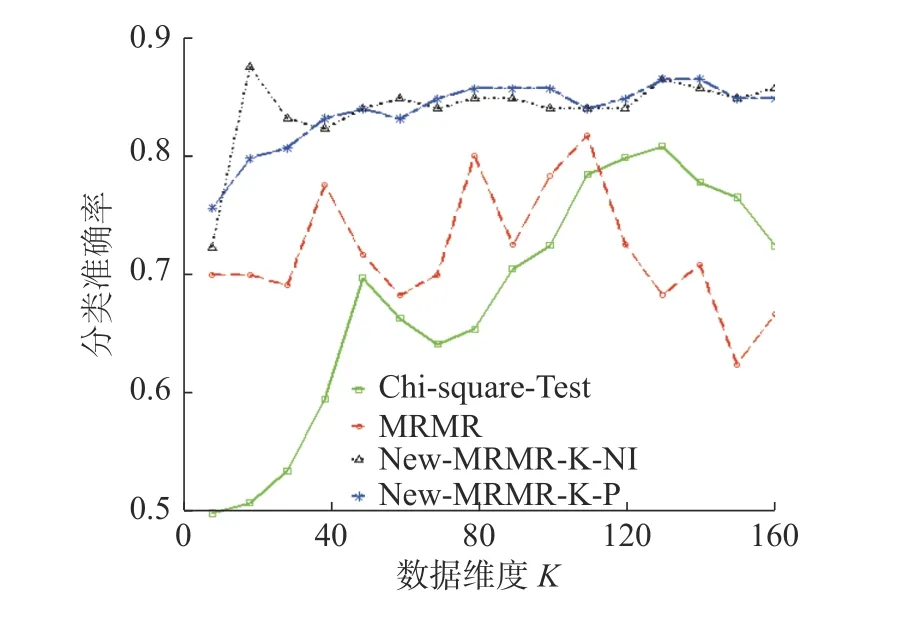
图11 New-MRMR-K-NI、New-MRMR-K-P、Chi-Square-Test、MRMR 在数据集clean 上,分类准确率的变化趋势Fig.11 Correct classification trend of New-MRMR-K-NI,New-MRMR-K-P,Chi-Square-Test,MRMR on the dataset clean
图11 中,New-MRMR-K-NI、New-MRMR-KP 的分类准确率的曲线均在传统的特征选择算法MRMR、Chi-quare-Test 之上,尤其是New-MRMRK-NI,当分类准确率达到最大时,所选的特征子集数为20,远小于两种传统算法所选择的最优特征子集数。可见,在数据集clean 上,算法New-MRMRK-NI、New-MRMR-K-P 的特征选择效果更优。
不同维度下,算法New-MRMR-L-NI、New-MRMR-L-P、传统特征选择算法MRMR、Fisher Score 在数据集clean 上的分类准确率变化趋势见图12。
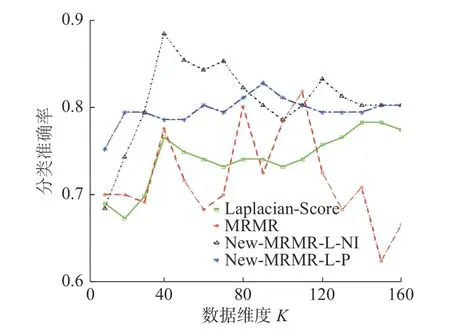
图12 New-MRMR-L-NI、New-MRMR-L-P、Laplacian-Score、MRMR 在数据集clean 上分类准确率的变化趋势Fig.12 Correct classification trend of New-MRMR-L-NI,New-MRMR-L-P,Laplacian-Score,MRMR on the dataset clean
图12 可以看出,维度为40 时,算法New-MRMRL-NI 就达到了最大分类准确率,且高于传统算法MRMR、Laplacian-Score 的分类准确率。此外,虽然在维度为110 时,New-MRMR-L-P 的分类准确率略低于MRMR,但在其余维度上的分类准确率均高于MRMR、Laplacian-Score 的分类准确率。
可见,在数据集clean 上,新提算法New-MRMR-L-NI、New-MRMR-L-P 的特征选择效果更好。
不同维度下,算法New-MRMR-IG-NI、New-MRMR-IG-P、传统特征选择算法MRMR、Fisher Score 在数据集clean 上的分类准确率变化趋势见图13。
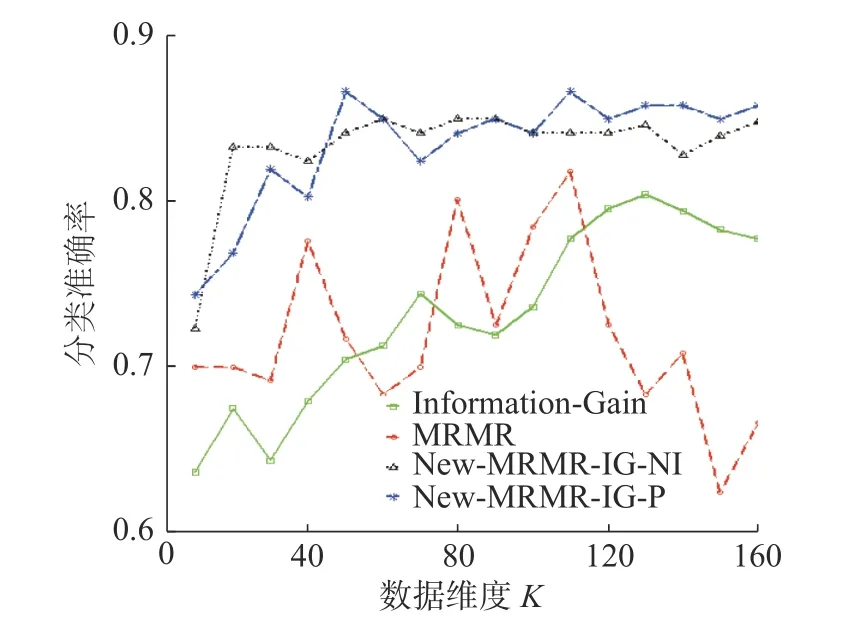
图13 New-MRMR-IG-NI、New-MRMR-IG-P、Information-Gain、MRMR 在数据集clean 上分类准确率的变化趋势Fig.13 Correct classification trend of New-MRMR-IG-NI,New-MRMR-IG-P,Information-Gain,MRMR on the dataset clean
图13 显示,本文新提算法New-MRMR-IGNI、New-MRMR-IG-P 的分类准确率曲线均在传统算法的分类准确率曲线之上。所以,对于数据集clean,本文新提出的两种特征选择算法New-MRMR-IG-NI、New-MRMR-IG-P 所选择的特征子集更加有效。
表6 给出了以上各种算法在数据集Parkinson’s Disease 上的实验结果,即经支持向量机分类后,得到的分类准确率达到最大时所选择的特征数。
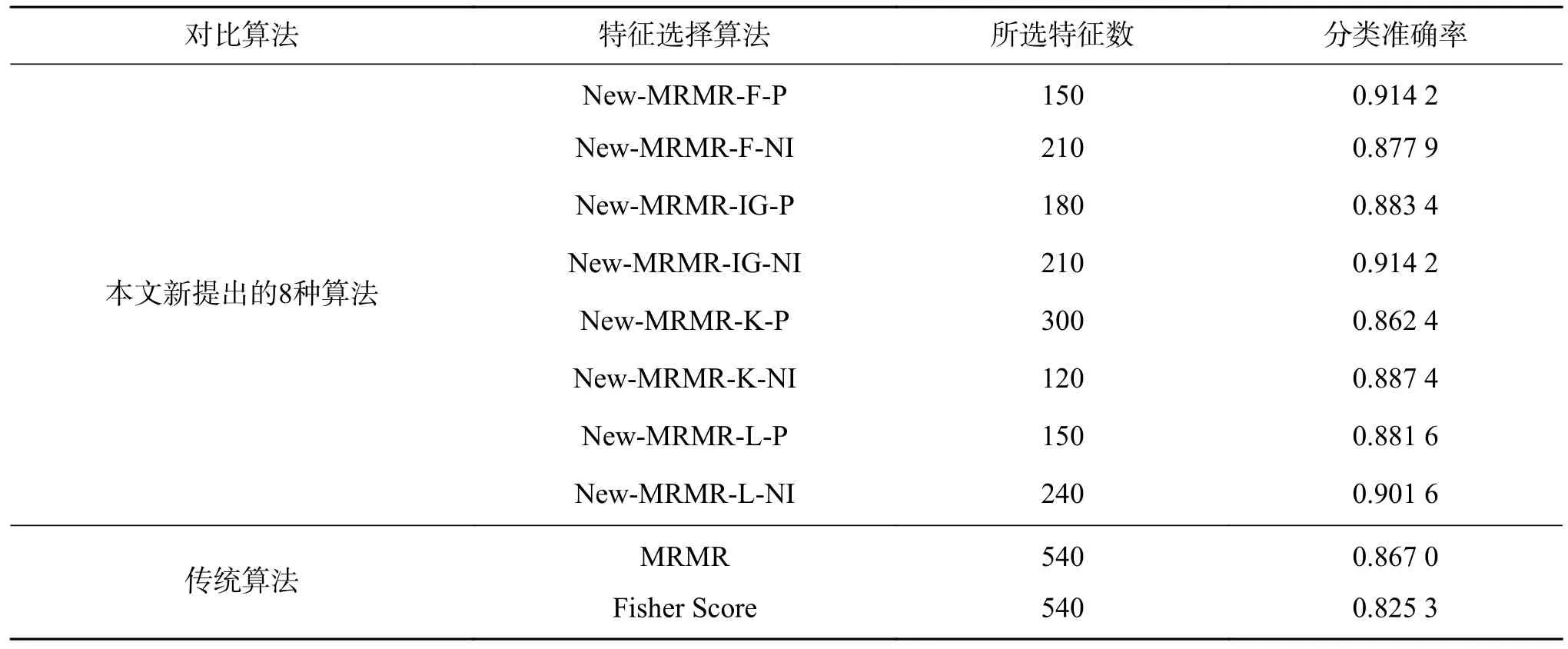
表6 分类准确率最大时,数据集Parkinson’s Disease 上各种算法分别所选择的特征数Table 6 Number of features selected by various algorithms when the Classification precision is maximum on the Parkinson’s Disease dataset

续表 6
表6 显示,算法New-MRMR-F-P 的分类准确率高达0.912 4,且此时所选择的特征子集数仅为150,远小于传统的5 种算法的最优特征子集数。另外,除了New-MRMR-K-P 的分类准确率略低于传统算法MRMR 的分类准确率之外,新提出的其余算法均大于传统特征选择算法。由此可见,本文新提出的特征选择算法在数据集Parkinson’s Disease 上的特征选择效果更好。
不同维度下,算法New-MRMR-F-NI、New-MRMR-F-P,传统特征选择算法MRMR、Fisher-Score 在数据集Parkinson’s Disease 上的分类准确率变化趋势见图14。
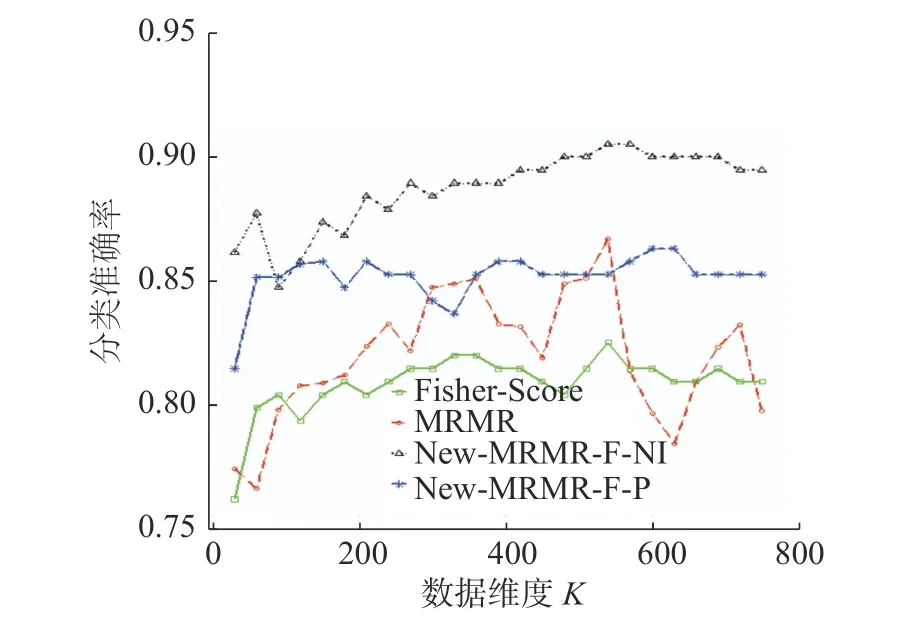
图14 New-MRMR-F-NI、New-MRMR-F-P、Fisher-Score、MRMR 在数据集Parkinson’s Disease 上分类准确率的变化趋势Fig.14 Correct classification trend of New-MRMR-F-NI,New-MRMR-F-P,Fisher-Score,MRMR on the Parkinson’s Disease dataset
图14 显示,算法New-MRMR-F-NI 的分类准确率曲线在传统算法MRMR、Fisher-Score 的分类准确率曲线之上。在维度为540 时,New-MRMRF-P 的分类准确率略低于MRMR 的分类准确率。但是,在其余维度上,New-MRMR-F-P 的分类准确率均高于传统算法MRMR、Fisher-Score 的分类准确率。更重要的是,在达到最大分类准确率时,New-MRMR-F-NI 所选的特征子集数仅为210,远低于MRMR、Fisher-Score 的最优特征子集数。所以,在数据集Parkinson’s Disease 上,本文新提出的算法特征选择效果更好。
不同维度下,本文新提算法New-MRMR-FNI、New-MRMR-F-P、传统算法MRMR、Fisher-Score 在数据集Parkinson’s Disease 上的分类准确率变化趋势见图15。

图15 New-MRMR-K-NI、New-MRMR-K-P、Chi-Square-Test、MRMR 在数据集Parkinson’s Disease 上分类准确率的变化趋势Fig.15 Correct classification trend of New-MRMRK-NI,New-MRMR-K-P,Chi-Square-Test,MRMR on the Parkinson’s Disease dataset
由图15 可见,在绝大多数维度上,New-MRMRF-NI、New-MRMR-F-P 的分类准确率均高于MRMR、Chi-Square-Test 的分类准确率。在维度为120 时,New-MRMR-F-NI 就已然达到了最大分类准确率,大于MRMR、Chi-Square-Test 的最大分类准确率。由此可见,在数据集Parkinson’s Disease 上,本文新提算法特征选择效果更好。
不同维度下,本文新提出的特征选择算法New-MRMR-F-NI、New-MRMR-F-P 以及传统特征选择算法MRMR 以及Fisher Score 在数据集Parkinson's Disease 上的分类准确率变化趋势见图16。
由图16 可以看出,算法New-MRMR-L-P 的分类准确率的曲线高于传统算法MRMR、Laplacian-Score 的分类准确率曲线,并且,在维度为240 时,New-MRMR-L-NI 就已经达到了最大分类准确率,远小于MRMR 达到最大分类准确率时所选择的特征子集数(540)。由此可见,在数据集Parkinson’s Disease 上,本文新提算法特征选择效果更好。
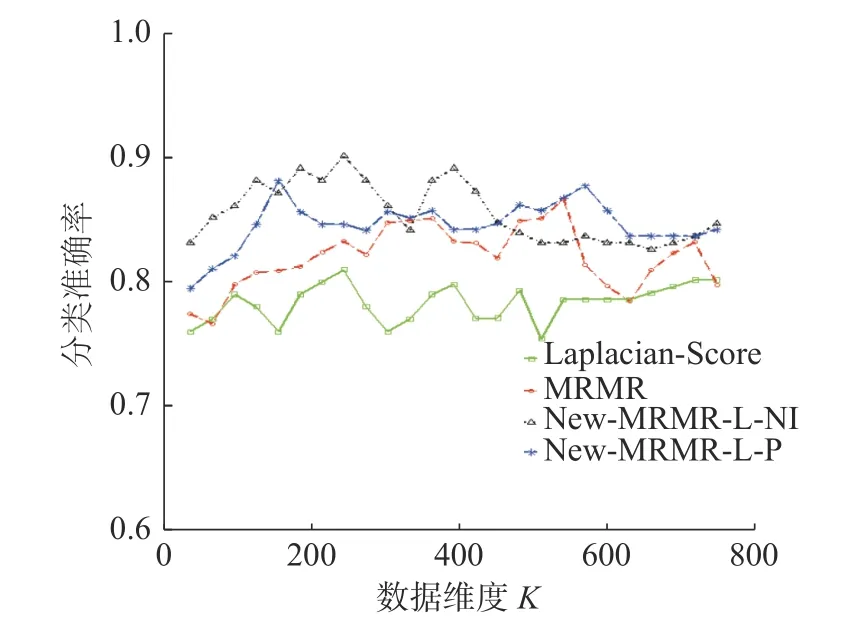
图16 New-MRMR-L-NI、New-MRMR-L-P、Laplacian-Score、MRMR 在数据集Parkinson’s Disease上分类准确率的变化趋势Fig.16 Correct classification trend of New-MRMR-L-NI,New-MRMR-L-P,Laplacian-Score,MRMR on the Parkinson’s Disease dataset
不同维度下,本文新提算法New-MRMR-FNI、New-MRMR-F-P 以及传统算法MRMR、Fisher Score 在数据集Parkinson’s Disease 上的分类准确率变化趋势见图17。
由图17 可以看出,在维度为120 和540 时,New-MRMR-IG-P 的分类准确率与算法MRMR 的分类准确率较为接近,但在其余维度上,其分类准确率均大于MRMR 的分类准确率。而且,在分类准确率达到最大时,New-MRMR-IG-P 所选择的特征子集数仅为180,远小于MRMR 的最优特征子集数。此外,New-MRMR-IG-NI 的分类准确率的曲线高于算法MRMR、Information-Gain 的分类准确率曲线。由上述分析可知,针对数据集Parkinson’s Disease 而言,本文提出算法在整体上比传统算法选择结果更好。
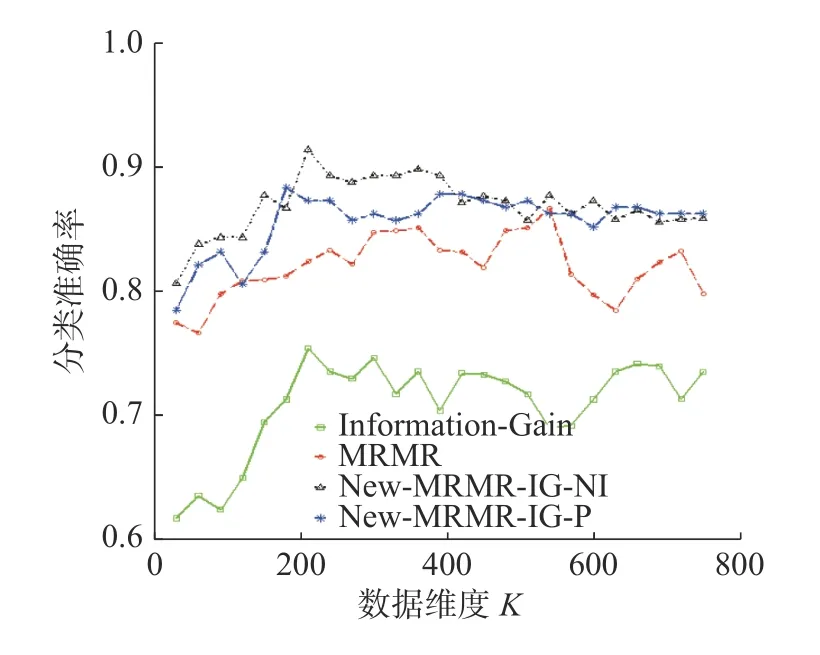
图17 New-MRMR-IG-NI、New-MRMR-IG-P、Information-Gain、MRMR 在数据集Parkinson’s Disease 上分类准确率的变化趋势Fig.17 Correct classification trend of New-MRMRIG-NI,New-MRMR-IG-P,Information-Gain,MRMR on the Parkinson’s Disease dataset
2.3 实验结果的T 检验
为更加有效地证明本文新提的8 种特征选择算法的有效性,以下采用成对单边T 检验来证明其有效性。原假设为:本文新提算法与传统算法的特征选择效果相同;备择假设为:本文新提算法的特征选择效果优于传统特征选择算法。表7为假设检验结果,其中包含了检验的统计量,置信区间以及P值。
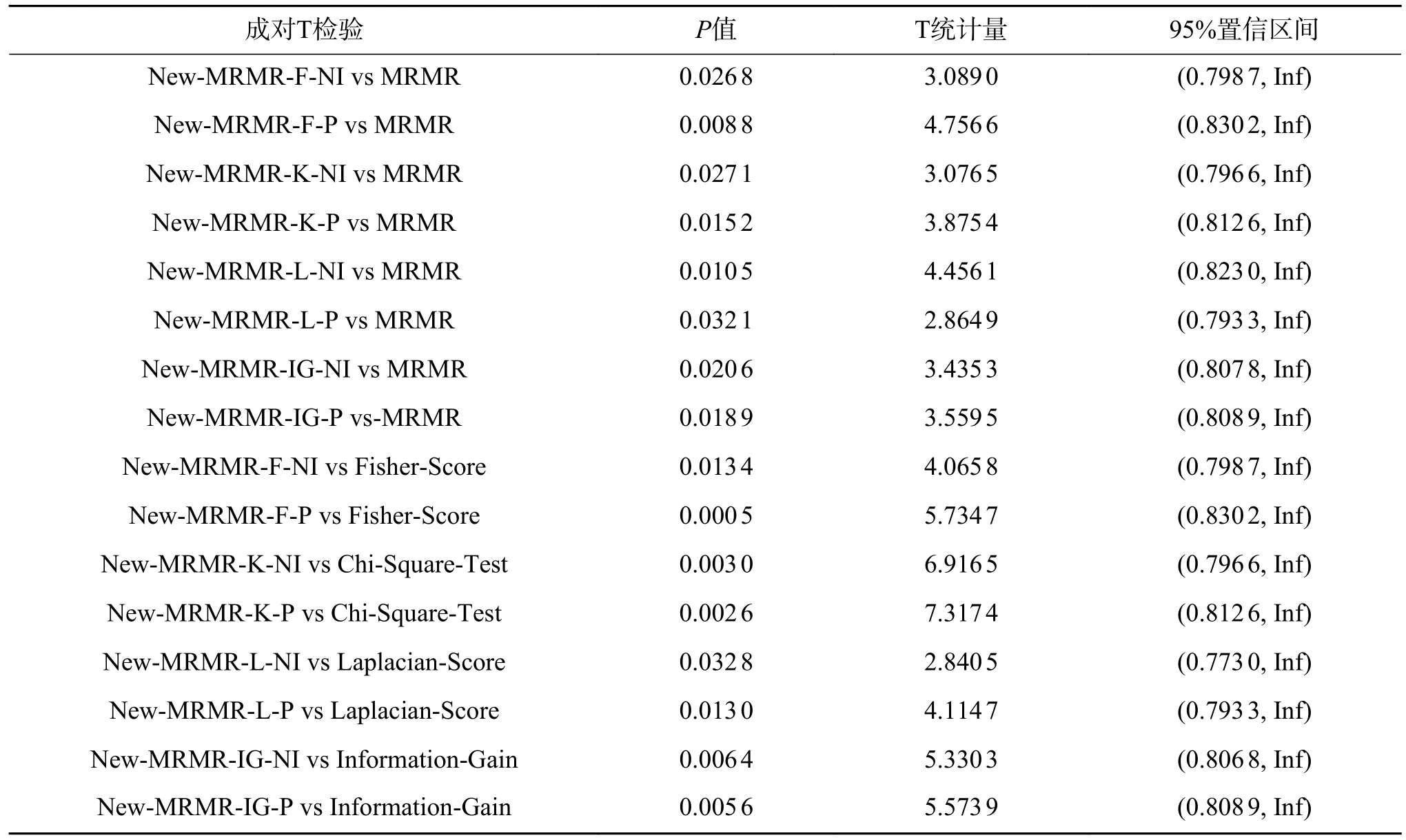
表7 新提算法与传统算法的成对单边T 检验的检验结果Table 7 Test results of paired unilateral T-test between the new algorithm and the traditional algorithm
由表7 可以看出,成对单边T 检验的P值均小于0.05,所以拒绝原假设,故认为本文新提出的8 种特征选择算法的特征选择结果优于传统特征选择算法的特征选择结果。
综上分析,从分类准确率以及假设检验的结果可以看出,本文新提出的8 种特征选择算法所选择的特征子集更优,特征选择效果更好。
3 结束语
虽然传统的基于特征选择的分类算法的理念已较为新颖,但是还是存在一定的提升空间。一方面,传统的基于特征选择的分类算法在特征选择过程中采用的度量特征之间冗余度以及与类别的相关度的评价准则单一;另一方面,它只考虑了特征与类别之间的相关度而忽略了冗余度;最后,其目标函数也存在缺陷,不能根据用户实际的维度需求来选择特征子集。本文针对这些问题引入了4 种不同的相关度评价准则以及两种不同的冗余度评价准则,目标函数中引入了指示向量λ来刻画用户实际的数据维度需求,从而组合成8 种新的特征选择算法,利用支持向量机对这8 种算法选择得到的特征子集分类。在4 个真实的UCI 数据集上进行了实验,利用分类准确率和T 检验验证了新提出的算法的有效性。
最后需要指出,评价特征冗余度和相关度的方法有多种,本文仅用了2 种评价冗余度的方法和4 种评价相关度的方法,但是其他评价冗余度和相关度的方法也可以适用于New-MRMR 框架,此外,新提特征选择算法在不同数据集上表现性能不同。因此,后续研究中,会更深入地研究和挖掘数据本质,尝试利用足够多的数据集以及评价相关度和冗余度的方法来深入探索具体哪种算法更适合哪种领域。
