基于深度神经网络的有遮挡身份验证
2021-09-10董艳花张树美赵俊莉
董艳花 张树美 赵俊莉











摘要:为解决人脸被部分遮挡也能完成身份验证的问题,提出一种基于深度神经网络的有遮挡身份验证方法。对人脸图像进行检测分块,将VGGNet-16三个全连接改为一个全连接,将其最后两个最大池化层改为平均池化层,用来提取人脸块的特征;并在PCANet的基础上添加并行模块,不仅提高网络提取特征能力,而且改善了PCANet对遮挡人脸特征丢失造成判别精度不够的缺点。研究结果表明,基于深度神经网络的有遮挡人脸平均识别精度达到96.62%。
关键词:新型冠状病毒;特征提取;遮挡判别;身份验证
中图分类号:TP391.41
文献标志码:A
收稿日期:2020-11-10
基金项目:
国家自然科学基金(批准号:61702293, 41506198)资助。
通信作者:张树美,女,博士,教授,主要研究方向为时滞非线性系统的分析与控制,图形图像识别与处理。E-mail: 15865578215@163.com
由于人脸图像含有丰富的特征信息,近年来人脸识别[1-2]被广泛应用在身份验证、人机交互、罪犯识别和智能视频监控等领域。但在自然真实的环境下,人脸图像采集往往受口罩、围巾、墨镜等多种遮挡方式的影响,导致通用的目标检测算法远远不能满足实际需求。国内外研究者一直致力于有遮挡人脸有效识别问题的研究,提出许多有效的算法[3-7]。如Sun等为了提取遮挡人脸图像鲁棒的深度特征识别多张人脸图像是否属于同一人,先后提出DeepID(deformable deep convolutional neural network for generic object detection,DeepID)[8]、DeepID2[9]及DeepID2+[10]网络结构,通过自下往上和不同大小黑块对人脸进行多尺度遮挡实验,验证了遮挡在20%以内,DeepID2+对遮挡人脸识别有较好的鲁棒性,为处理有遮挡人脸识别提供了新思路。但DeepID、DeepID2及DeepID2+等网络在人脸检测及深度特征学习时均过度依赖大量的训练样本和较多参数,所以Chan等[11]将卷积神经网络与局部二值模式(local binary patterns,LBP)的特征提取框架相结合,提出一种主成分分析的网络(principal components analysis network,PCANet),通过局部零均值化预处理和PCA滤波器提取主成分特征,极大的过滤掉图像中的遮挡特征,对遮挡人脸识别具有鲁棒性。基于上述有遮挡人脸识别算法的研究,在保证身份验证准确度的基础上,尽可能降低网络复杂度,本文提出一种基于深度神经网络的有遮挡身份验证,通过VJ(Viola-Jones)算法[12]训练一个级联分类器进行人脸检测,利用CFAN (coarse-to-fine auto-encoder networks)[13]定位人脸特征点实现人脸特征分块,通过改进(visual geometry group network-16,VGGNet-16)[14]对每个特征塊进行特征提取,训练出对应的人脸特征块模型,然后通过改进的PCANet网络进行口罩遮挡判别,最后根据特征提取及口罩遮挡判别的结果进行口罩遮挡身份验证。
1 基于深度神经网络的有遮挡身份验证
有遮挡身份验证就是利用计算机对人脸图像或视频进行人脸检测,将遮挡信息去除,从中提取有效的识别信息。基于已有的人脸数据库来验证一个或多个人身份的一项技术,本文提出一种基于深度神经网络的有遮挡身份验证方法,在已有遮挡和无遮挡的数据集上,利用VJ算法进行人脸检测,然后利用CFAN定位人脸特征点。因为本文主要研究的是口罩遮挡下的身份验证,所以根据定位的人脸特征点图像将一张人脸图像分为眼睛+眉毛、鼻子+嘴巴的特征块,然后通过改进的VGGNet-16对每个特征块进行特征提取,最后为了去除遮挡对人脸识别产生的不利影响,利用改进的PCANet网络进行遮挡判别,把判别出的未遮挡人脸特征块保留,丢弃遮挡人脸特征块,并用零向量填充丢失的特征部分,来保证遮挡下获得的人脸特征也能通过两个眼睛及眉毛的特征进行分类识别,最后分类器根据遮挡判别的结果进行遮挡人脸识别。基于深度神经网络的有遮挡身份验证流程如图1所示,主要分为人脸分块、特征提取、遮挡判别及人脸分类识别四部分。
1.1 人脸分块
本文使用VJ算法检测人脸,对训练集通过水平翻转、随机裁剪、多尺度等方式进行数据增强,利用由粗到精的自编码网络CFAN进行人脸特征点定位,根据特征点定位的结果对图像进行裁剪:将图像大小设置为260×260,以VJ算法检测到的左右眼及眉毛、鼻子及嘴巴的关键点为中心,分别裁剪出眼睛+眉毛特征块和鼻子+嘴巴特征块,裁剪示例图如图2所示。实验表明,每个人脸的特征块大小调整见表1,可以保证人脸纹理特征不变性的情况下进行便捷计算,这种分块的裁剪方式可以将人脸具有区分度的信息全部保留下来,并将这些特征块作为基于分块有遮挡身份验证的原图输入到后续改进的VGGNet-16特征提取及PCANet遮挡判别中,通过人脸图像分块的方式在特征提取过程中减少遮挡的干扰,并提取人脸更为精细的特征,有效提高有遮挡人脸识别的效率。
1.2 人脸特征块特征提取
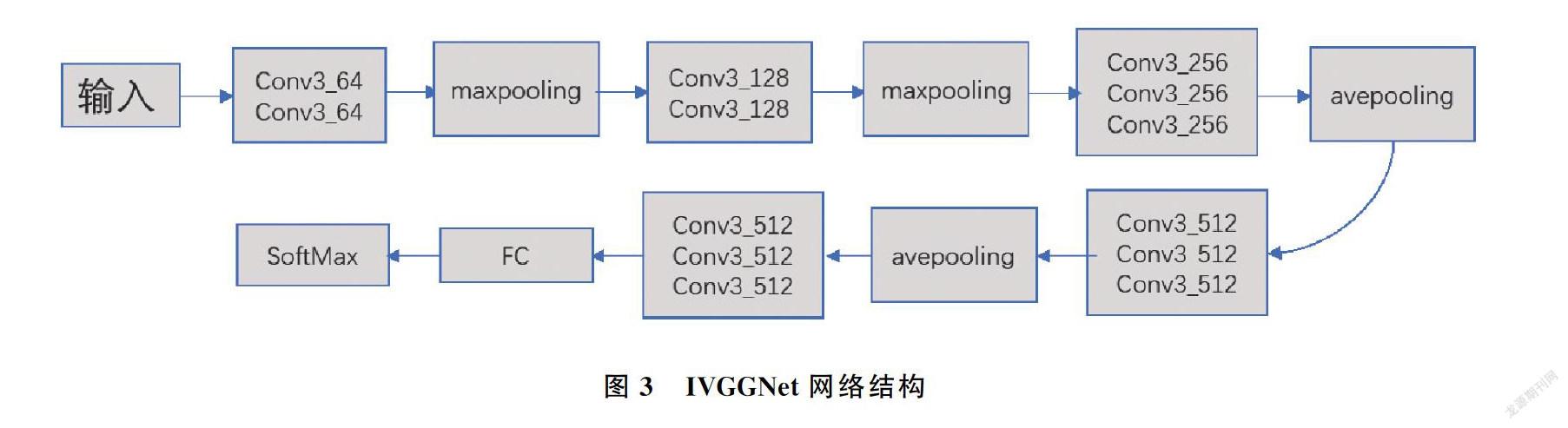
近年来针对人脸识别的深度学习网络模型不断更新迭代,许多网络识别干净人脸的准确度甚至超越人眼的感知能力,但基于深度学习的网络模型的训练和调优需要借助超大规模的数据集及强大的硬件平台,所以本文需要选择一个识别速度和分类精度都较高的神经网络用来提取人脸特征块的特征。表2展示的是目前常用的卷积神经网络各项参数对比。从常用卷积神经网络的复杂度和分类识别精度进行分析,可知,相对于分类识别精度较高的ResNet-101(Residual Network-101)[15]和DenseNet(Dense Convolutional Network)[16],VGGNet-16的网络层数更少且运行速度更快;由于VGGNet-16采用16层的深层网络结构,可有效提取深层特征,相比于速度较快的AlexNet(Alex Network)[17]和SqueezeNet(Squeeze Network),VGGNet-16的分类识别精度高出10%左右,由此,本文选择VGGNet-16作为人脸特征块的特征提取网络。为使其在较小规模的训练数据和有限计算能力的条件下也能有效提取人脸高层特征,且单一的人脸区块相对于整个人脸来说需要提取的特征区域较小且更精细,本文对VGGNet-16网络结构、参数及损失函数做了微调,优化的网络结构称为IVVGNet(Improve Visual Geometry Group Network, IVGGNet)如图3所示。
根据深度学习神经网络特征提取的经验,网络越深的层越能提取有效的特征,且VGGNet-16网络通过使用3×3的卷积核和2×2的池化核不断加深网络深度进而提升了网络提取特征的性能,所以特征提取效果显著,IVGGNet为了维护VGGNet-16底层提取特征的有效性,参照DeepID和GoogLenet(Goog Le Network)[18]网络模型,由图3可知,将VGGNet-16三个全连接层改为一个全连接层,相比于提取整张人脸特征的VGGNet-16减少了网络参数量,提高该网络人脸特征提取的速度。同时将全连接层前的两个最大池化层改为3×3的平均池化层,能最大程度地保留图像提取的特征,提高VGGNet-16提取人脸特征的能力。
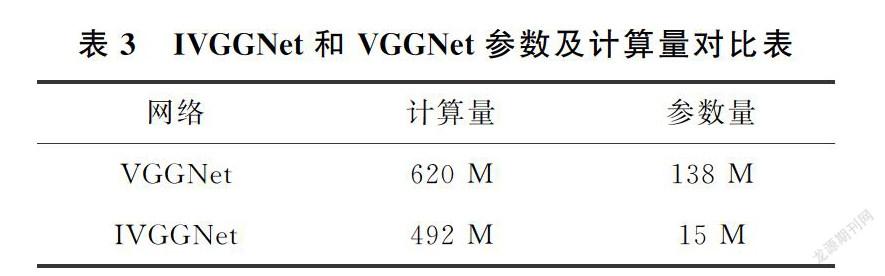
表3展示了IVGGNet和VGGNet在计算量和参数量上的区别。IVGGNet网络通过减少全连接层和利用平均池化层代替最大池化层,使参数量由原来的138 M减少到15 M,同时计算量从620 M减少到492 M不仅大大缩减了计算时间,而且节省了网络计算量所需空间。
由于VGGNet-16采用SoftMax分类器进行训练,得到的特征的类内距离较大,将导致错误识别人脸,而Center损失函数可以增加类间距离,同时缩小类内距离,因此本文通过SoftMax+Center损失函数来增强分类效果。SoftMax损失函数为
Ls= -∑mi = 1logewTyi xi+ byi∑nj = 1ewTyi xi+ byi (1)
Center损失函数为
Lc=12∑mi=1xi-cyi22(2)
SoftMax+Center损失函数为
L=LS+λLC(3)
其中,m表示mini-batch包含的样本数量,n表示类别数, cyi表示yi个类别的特征中心,xi表示全连接层之间的特征,λ用来控制SoftMax及Center的比重。Center损失函数在训练过程中,逐步减少某类成员到该类的特征中心的距离,并增大其他类成员和该中心的距离,从而得到更好的分类结果。
为得到具有区分度的人脸特征,本文将两种特征块的训练数据集分别输入到IVGGNet网络模型中进行特征提取,将分别获得眼睛+眉毛、鼻子+嘴巴区域的人脸特征,通过这两部分特征能够完整地组合成一张人脸的所有特征。
1.3 基于PCANet遮挡判别
本文主要是为了解决新冠疫情下口罩遮挡时员工打卡上班的身份验证问题,为此研究对比近年来用于遮挡人脸识别的卷积神经网络,各参数如表4所示。可知PCANet相比于DeepID2、DeepID2+、Inception-ResNet-v1[19]的识别率较低,但其网络层数最少,结构简单,且对遮挡人脸识别自带鲁棒性,所以本文选择PCANet判别输入的人脸特征块是否存在口罩遮挡,输出人脸特征或有口罩遮挡两类判别结果,实现对有口罩遮挡的人脸判别。
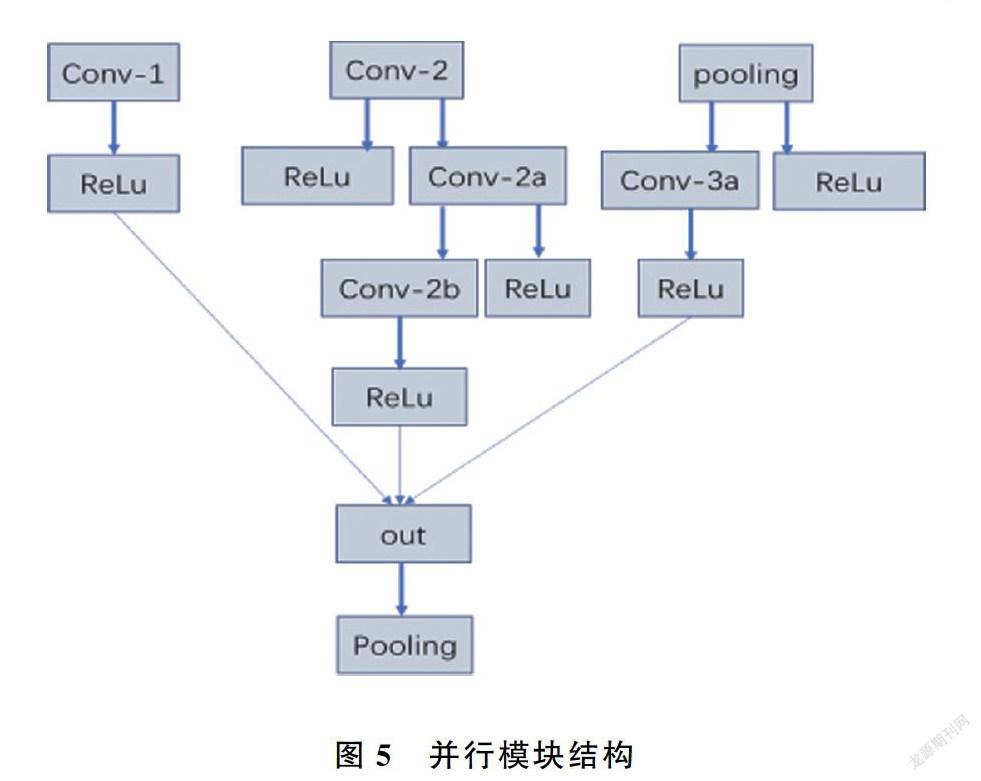
但PCANet只有两个卷积滤波层进行不同信息的特征表示,且该网络在构建卷积核时均是利用PCA的前k个最大的特征值对应的特征向量来完成的,却丢弃了剩余的特征向量。實际上,被丢弃的特征向量中也存在一部分有用的辨别信息,丢弃后会损失这部分辨别信息。所以为简单有效的提高遮挡判别效率,并受GoogleNet网络中的Inception模块的启发,将PCANet网络进行改进,提出并行卷积池化处理模块,可以提取不同的特征并融合起来输出给下一层。改进的PCANet网络称为In_PCANet(Inception principal components analysis network),结构设计如图4所示。
该网络模型设置了不同的层结构,不同层结构将产生不同的特征向量,其中并行模块包含三个不同的并行路径,用来分别提取三种不同的特征,并在out中进行组合,通过实验发现,并行模块是创建抽象特征表示的有效方法,能够创建多条不同路径提取不同的特征,从而有效地改善对遮挡人脸特征丢失造成判别精度不够的缺点,通过采用1×1或3×3的小卷积核,加强了对遮挡人脸特征的表征能力且大大缩短了神经网络的训练时间。与PCANet相比,该网络结构首先通过并行结构的三个不同路径进行特征提取,并将提取的特征进行融合,然后将提取的特征送到含有K1个卷积核的卷积层中进行零均值化及PCA滤波卷积操作,得到前K1个最大特征值所对应的特征向量来构建卷积核,为了保证每层映射后的特征均能重构原图像,在卷积操作前对样本均做了边缘填充,接着将得到的映射输入到含有K2个卷积核的卷积层进行零均值化及PCA滤波卷积操作,得到前K1×K2个最大特征值所对应的特征向量来构建卷积核,为获得更强表达性的特征,采用Heaviside阶跃函数对得到的特征进行二值化及哈希编码。同PCANet一样,In_PCANet最后也是通过SVM分类器做最后的遮挡判别分类。
本文In_PCANet中的并行模块是由卷积层、池化层和激活函数ReLU组成,并在3×3的卷积核之前采用1×1的小卷积核来实现降维,从而降低特征图像的计算量。通过实验发现,使用一个并行模块可以提取充分的特征,识别率得到提高,且不会增加较多的运算成本,而使用多个并行模块会增加特征提取的时间,但识别率达到一定水平就不再增加,所以根据识别率和时间的最优规划,本文选择使用一个并行模块。该模块的结构如图5所示。
为有效区分鼻子及嘴巴特征点是否存在口罩遮挡,本文将无口罩遮挡人脸的特征点图像及有口罩遮挡人脸的特征点图像作为遮挡判别的训练集,则输入的图像只有属于人脸特征块和有口罩遮挡特征块两种类别,因此本文在In_PCANet网络的基础上添加多分类器用于人脸区块的二分类上,经过In_PCANet的处理后只能输出未被遮挡的人脸特征块或有遮挡的人脸特征块两类判别结果。输入图像经In_PCANet遮挡判别示例图如图6(a)、图6(b)所示。可知,输入眼睛+眉毛图像及含口罩遮挡的图像后,In_PCANet及多分类器将对输入图像进行口罩遮挡判别,分别输出其特征块对应眼睛+眉毛、鼻子+嘴巴及口罩遮挡的概率,通过设定每类特征块输出概率的阈值为90%,大于该阈值的概率为有效判别概率,然后取有效判别概率中最大的概率类别作为最终输出判别结果的依据,如图6(a)所示,眼睛+眉毛概率超过阈值,且其概率最高,所以判别出输入的图像是属于人脸眼睛+眉毛的特征,最终判别输出结果为人脸特征块;而图6(b)所示口罩遮挡的概率最高,所以判别出输入的图像是有遮挡的人脸图像,最终判别输出结果为遮挡特征块。综上所述,数据集通过In_PCANet及多分类器的遮挡判别网络进行分类判别,可以获得一张完整人脸图像中哪个特征块被遮挡,哪个未被遮挡,为后面人脸分类识别奠定基础。而整个遮挡判别网络通过对输入的人脸分块特征图利用In_PCANet学习适合各个特征块的滤波器,并将多分类器完成二分类问题,也极大地降低了遮挡判别的时间复杂度,同时提高了分类效率。
1.4 身份验证
本文结合IVGGNet对人脸特征块的特征提取及In_PCANet对人脸特征块的遮挡判别结果,使用最近邻分类器对人脸特征块进行分类识别,将IVGGNet提取的各个未被遮挡的特征块进行顺序拼接,最终生成一张人脸的特征如下:F=( feye,fnose+mouse),分别表示眼睛+眉毛、鼻子+嘴巴特征块提取的特征,然后将In_PCANet遮挡判别的遮挡特征块丢弃,用零向量填充丢失的特征部分,保证口罩遮挡下获得的人脸特征也能通过眼睛+眉毛的特征进行人脸分类识别。身份验证对测试输入的特征块及数据库已存的特征块进行比较时,若其中一个特征块是被零填充的,则另外一个特征块也被置为零,利用欧式距离的方法对两个特征块进行特征相似度度量,取最相似的特征表示人脸身份验证的结果。
2 实验结果与分析
2.1 实验数据集
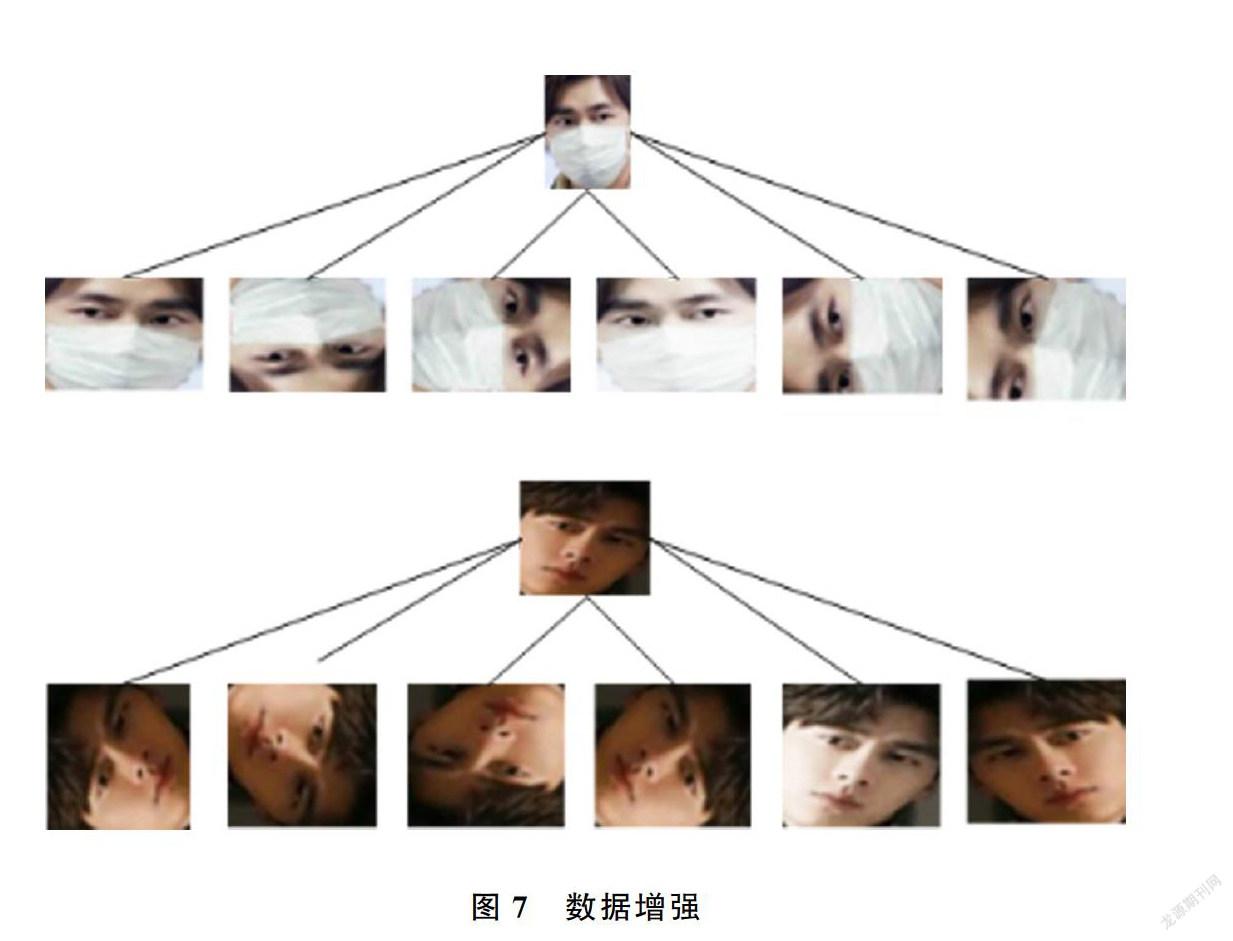
武汉大学国家多媒体软件工程技术研究中心收集了大量口罩人脸数据集MFRD,包括经网络爬取,整理清洗和标注处理的真实口罩人脸识别数据集和在Webface、LFW公开数据集上人工添加口罩的模拟口罩人脸识别数据集。真实口罩人脸识别数据集包含525人的5千张口罩人脸和9万张不戴口罩人脸,分别存放在各自名字的文件夹下;模拟口罩人脸识别数据集包含1万人的50万张图片,但没有标注参与者的名字。由于本文要实现身份验证,所以采用MFRD中真实口罩人脸数据集,选择其中100人对应的戴口罩和不戴口罩图片,其中不戴口罩的图片相对充足,但图像尺寸不统一或姿态多样性不利于本文实验的模型训练,且戴口罩的数据相对较少,所以需要对这100人的人脸数据进行批量数据增强,通过水平翻转、随机裁剪、多尺度及颜色渲染等方式,最后分别得到每人300张无口罩遮挡图片和300张戴口罩图片用于实验。选择数据集的80%做训练集,剩余20%做测试集,数据增强示例图如图7所示。本文所有算法均在Windows10 64位操作系统下基于Tensorflow深度学习框架用Python语言编写,使用CUDA10.0版本的GPU加速器,在训练模型时均采用随机梯度下降(Stochastic Gradient Descent,SGD)优化模型。
2.2 实验结果分析
本文通过CFAN算法将人脸图像数据集裁剪为指定的眼睛+眉毛、鼻子+嘴巴特征区块,利用IVGGNet对特征块进行特征提取,然后将提取的特征输入In_PCANet网络进行特征块遮挡判别,最后利用最近邻分类器实现人脸分类识别。为对比分析IVGGNet、VGGNet人脸识别的性能,利用数据集中100个人的6万张干净人脸图像对IVGGNet、VGGNet实验对比,获得实验分析如表5所示。可知在相同阈值及数据集的条件下,IVGGNet人脸识别比VGGNet具有明显的优势,识别准确率提高了14.2%,运行帧率也提高了1.7FPS。其主要原因在于将VGGNet16中全连接前的两个最大池化层改为平均池化层,最大程度地保留了提取的图像特征,进而提高了人脸识别率;又将三个全连接层改为一个全连接层,极大地减少了网络的参数量,使人脸识别速度也得到相应的提高,进一步验证了IVGGNet在人脸识别上的可行性,为后续提高分块有遮挡人脸识别效率奠定基础。
由于本文在In_PCANet口罩遮挡判别时利用多分类器实现人脸二分类问题,且每个判别模型都保留两个以上的人脸特征点进行判别,可以在较短的时间内达到较高的判别效果,所以在人脸特征块及分辨率足够充足的条件下,本文训练的In_PCANet网络模型可以对有口罩遮挡的人脸进行准确的判别,结果如表6所示。基于In_PCANet口罩遮挡判别对眼睛+眉毛、鼻子+嘴巴都能达到98%以上的判别结果,而基于PCANet遮挡判别对特征块的判别效率均低于97%,表明通过添加并行模块的PCANet有利于提取人脸特征并提高识别效率,且对口罩遮挡的识别也高达96.7%,表明该方法对有遮挡人脸判别的有效性,为存在有口罩遮挡的人脸识別提供较高的判别效果,促进戴口罩下的人脸高效率识别。
为进一步验证基于深度神经网络的口罩遮挡人脸识别的有效性,利用有口罩遮挡人脸数据集对IVGGNet在人脸分块思想下进行实验,为对比分析,利用IVGGNet网络对全局人脸进行口罩遮挡人脸识别,并设置相同参数bach_size=16,iteration=1 200,learning_rate=0.005,epoch=300的情况下进行模型训练,然后通过对后期人脸分类识别中设置阈值0.85,来判别该人脸是否是数据库中已经存在的人脸,大于该阈值就认为已存在,直接识别出是谁,小于该阈值就认为不存在,被存入数据库中,基于分块的IVGGNet有口罩遮挡人脸识别和基于全局的IVGGNet有口罩遮挡人脸识别效果如表7所示。可知,在相同阈值的控制下,基于全局的IVGGNet口罩遮挡人脸识别的效果无论是在戴口罩还是不戴口罩情况下的人脸识别都明显低于基于人脸分块的IVGGNet人脸识别效果,进一步验证了基于人脸分块的IVGGNet有口罩遮挡人脸识别高效性。主要原因来自于人脸分块能够提取面部的局部特征,从感受野的范围考虑,基于分块的人脸识别感受野会大于基于全局的人脸识别感受野,虽然可以通过加深网络层次来扩大感受野的范围,但将导致网络参数增多,从而降低识别的速度;在数据有限的情况下,需要描述的特征越简单,网络参数的优化越容易,相对于全局人脸识别,基于分块的人脸识别可以更简单的学习不同区域的特征,进而提高口罩遮挡人脸识别效果。
3 结论
本文提出一种基于深度神经网络的有遮挡身份验证方法,在保证身份验证准确度基础上,尽可能降低了网络的复杂度。利用人脸特征块,并结合遮挡判别结果提取的特征,对遮挡身份验证具有较强的鲁棒性,经实验表明该方法可高效识别有遮挡人脸。实验结果表明,人脸特征块经过In_PCANet遮挡判别网络处理后对口罩遮挡的判别率达到96.7%,对有口罩遮挡和无遮挡识别率分别为95.73%和97.52%。在相同实验环境下,基于全局的IVGGNet有遮挡身份验证对有口罩遮挡和无遮挡识别率分别为84.62%和91.84%,表明基于分块的有遮挡身份验证效果显著,为员工上班戴口罩也能顺利完成打卡任务提供了理论基础,总之,基于深度神经网络的有遮挡身份验证,不仅可以应用在新冠疫情下人脸佩戴口罩进行人脸识别的场景,对于平时人们不戴口罩进行人脸识别时也同样适用。
參考文献
[1]衣柳成,魏伟波,刘小芳.基于GoogLeNet的智能录播系统中站立人脸的检测与定位[J].青岛大学学报(自然科学版),2019,32(4):91-95.
[2]李明生,赵志刚,李强,等.基于改进的局部三值模式和深度置信网络的人脸识别算法[J].青岛大学学报(自然科学版),2019,32(4):79-84.
[3]ZAFEIRIOU S, TZIMIROPOULOS G, PETROU M. Regularized kernel discriminant analysis with a robust kernel for face recognition and veri-fication[J].IEEE Transactions on Neural Networks and Learning Systems,2012,23(3):526-534.
[4]LI X X, DAI D Q, ZHANG X F. Structured sparse error coding for face recognition with occlusion[J]. IEEE Transactions on Image Pro-cessing,2013,22(5):1889-1900.
[5]WEI X, LI C T, HU Y. Robust face recognition with occlusions in both reference and query images[C]//2013IEEE Conference on Computer Vision and pattern recognition workshops(CVPRW).Inst Super Tecnico,lisbon,PORTUGAL,2013.
[6]LI X X, LIANG R, FENG Y. Robust face recognition with occlusion by fusing image gradient orientations with markov random fields[C]//International Conference on Intelligent Science and Big Data Engineering. Springer International Publishing,2015: 431-440.
[7]周孝佳,朱允斌,张跃.基于分块的有遮挡人脸识别算法[J].计算机应用与软件,2018,35(2):183-187.
[8]SUN Y, WANG X, TANG X. Deep learning face representation from predicting 10,000 classes[C]// 27th IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Columbus, 2014: 1891-1898.
[9]SUN Y, CHEN Y, WANG X. Deep learning face representation by joint identification-verification[C]// 28th Conference on Neural Information Processing Systems (NIPS). Montreal, 2014,27: 1988-1996.
[10] SUN Y, WANG X G, TANG X O. Deeply learned face representations are sparse, selective, and robust[C]// IEEE Conference on Computer Vision and Pattern Recognition(CVPR). Boston,2015:2892-2900.
[11] CHAN T H, JIA K, GAO S. PCANet:A simple deep learning baseline for image classification?[J]. IEEE Transactions on Image Processing,2015,24(12):5017-5032.
[12] VIOLA P A, JONES M J. Rapid object detection using a boosted cascade of simple features[C]//IEEE Computer Vision and Pattern Recognition(CVPR), 2001:511-518.
[13] ZHANG J, SHAN S G, KAN M. Coarse to fine auto-encoder networks (cfan) for real-time face alignment[J].Electronic Journal of Qualitative Theory of Diferential Equations.2014,(50):1-15.
[14] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J]. Computer Science,2014:1409-1556.
[15] HE K M, ZHANG X Y, REN S Q. Deep residual learning for image recognition[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Seattle,2016:770-778.
[16] HUANG G, LIU Z, LAURENS V D M. Densely connected convolutional networks[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).2017:2261-2269.
[17] KRIZHEVSKY A, SUTSKEVER I, HINTON G. ImageNet classification with deep convolutional neural networks[J]. Communications of the Acm.2017,60(6):84-90.
[18] SZEGEDY C, LIU W, JIA Y. Going deeper with convolutions[C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston,2015:1-9
[19] 徐迅,陶俊,吳瑰.基于卷积神经网络的带遮蔽人脸识别[J].江汉大学学报(自然科学版),2019,47(3):246-251.
Authentication with Occlusion Based on Deep Neural Network
DONG Yan-hua, ZHANG Shu-mei, ZHAO Jun-li
(School of Data Science and Software Engineering, Qingdao University, Qingdao 266071, China)
Abstract:
In order to solve the problem that authentication can be completed even if the face is partially occluded, a occlusion authentication method based on deep neural network is proposed. The face image is detected and divided into blocks, the three full connections of VGGNet-16 are changed to one full connection, and the last two maximum pooling layers are changed to average pooling layers to extract the features of the face block; and add parallel module on the basis of PCANet, which not only improves the ability of the network to extract features, but also improves the PCANet's shortcomings of insufficient discrimination accuracy due to the loss of occluded facial features. The research results show that the average recognition accuracy of occluded faces based on deep neural networks reaches 96.62%.
Keywords:
COVID-19; feature extraction; occlusion discrimination; identity verification
