基于机器学习简化MMPI量表的有效性研究
2021-09-10孙启科董问天王克冯超南崔霖李毓明于淏岿于滨石川纪俊
孙启科 董问天 王克 冯超南 崔霖 李毓明 于淏岿 于滨 石川 纪俊



摘要:针对传统MMPI量表中题目数量过多,许多应用场景下受试者依从性差的问题,提出使用机器学习算法对MMPI量表中的临床量表进行简化的方法,对6种经典机器学习算法的简化效果进行了比较,并在受试者测评数据上对原始和简化后测评结果的敏感度与特异度进行了对比分析。实验结果表明,使用最小绝对收缩和选择算子(LASSO)的算法在保持相近准确率的同时简化效果最好,平均减少了37.3%的男性和39.1%的女性受试者题目数量,并且简化后测评结果的敏感度与特异度仍能保持在原始测评结果的85%,缩短了测评时间,适用于更多的应用场景。
关键词:MMPI;机器学习;量表简化
中图分类号:TP181
文献标志码:A
收稿日期:2021-01-04
基金项目:
国家自然科学基金(批准号:61503208)资助;山东省自然科学基金(批准号:ZR2015PF002)资助。
通信作者:
石川,男,博士,副教授,主要研究方向为精神分裂症、抑郁症及双相障碍。E-mail:shichuan@bjmu.edu.cn
纪俊,男,博士,讲师,主要研究方向为转化医学、医疗大数据分析。E-mail:jijun@healai.com
明尼苏达多项人格测验(Minnesota Multiphasic Personality Inventory,MMPI)[1]是由明尼苏达大学教授Hathaway等共同制定的人格检测量表,在鉴别精神疾病方面有很好的信效度[2-3],并广泛应用在各个领域。近年来,社会竞争压力不断增加,中国精神疾病的患病率明显上升[4],精神疾病已成为危害中国人民身心健康的重要疾病之一[5] 。因此,一套高效简捷的人格检测工具对国民精神疾病筛查非常必要。中國使用的MMPI量表是宋维真翻译修订的版本[6],共有566道题目,信息量庞大,患者应用困难,往往要进行分段实施。据统计,青年男性需要42分钟填写[7],在体检场景下测试者依从性较差,难以有耐心全部完成,所以要对原始的MMPI量表进行简化,在保证结果一致性的前提下尽量减少题目,来提升量表的完成率。目前已有较多MMPI简化版本,例如MMPI-168[8],心理健康测查表(Psychological Health Inventory,PHI)[9]等,已经被证明其在筛查方面的有效性[10],但这种类型的简化量表均是采用因子分析法生成固定的简化版本的量表,筛查过程中无法保证筛查的针对性和全面性。本研究针对前399道题目进行简化,包括10个临床量表。采用决策树的特征选择将10个题组的题目进行重要性排序,再通过6种经典机器学习算法对10个题组进行建模分析,在保证结果一致性的前提下选出最优简化量表的算法,确保量表简化的准确性和全面性。
1 资料与方法
1.1 研究对象来源
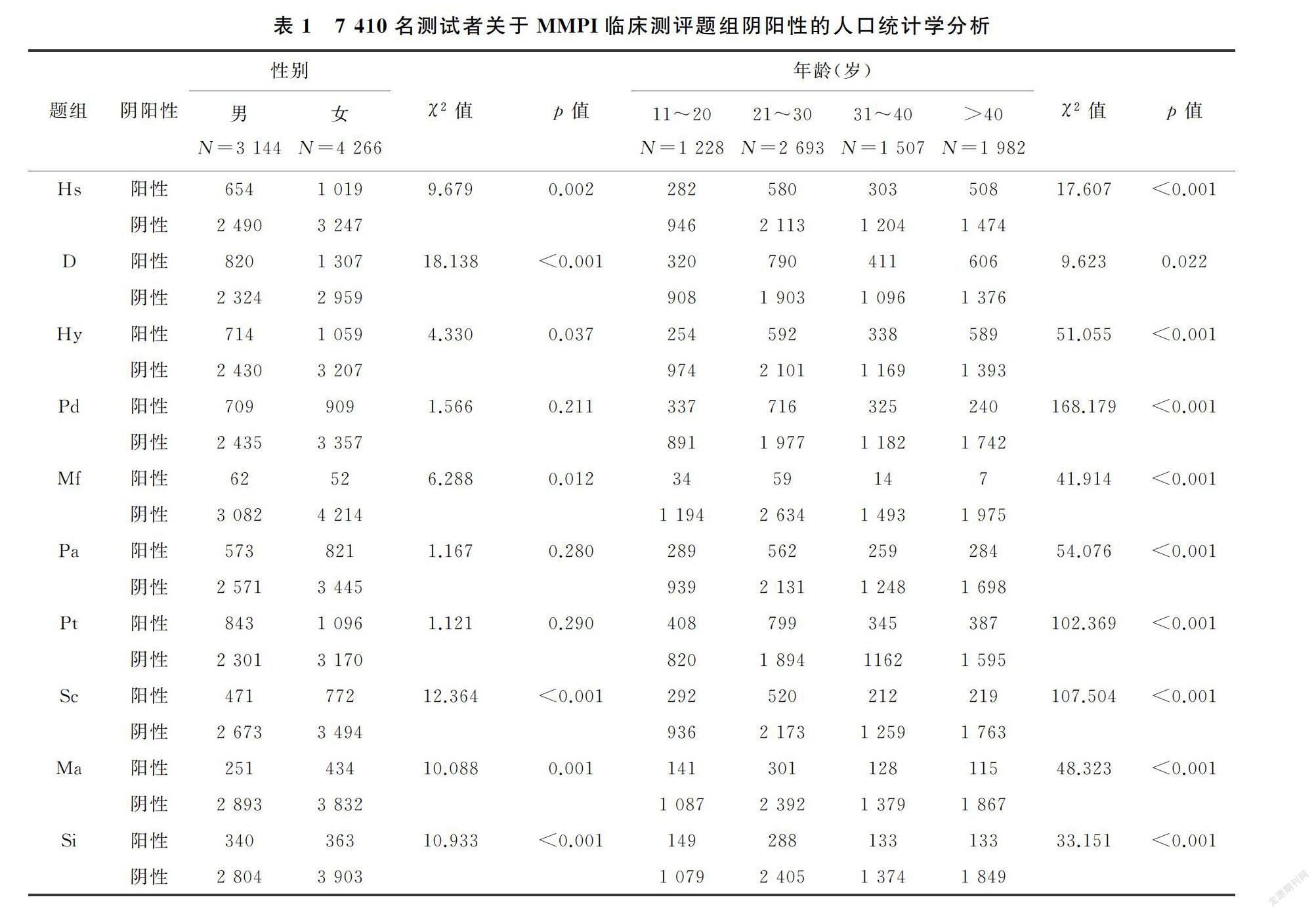
数据集来自北京大学第六医院疑似患有精神类疾病人群,从中抽取7 410名完成399道测评题目的患者。由于性别不同测评标准不同,所以将数据集分为3 144名男性与4 266名女性。由表1,测试者年龄因素对所有临床测评题组都有统计学意义(p<0.05);性别因素对临床测评题组Hs(疑病)、D(抑郁)、Hy(癔病)、Mf(男女子气)、Sc(精神分裂)、Ma(轻躁狂)、Si(社会内向)具有统计学意义(p<0.05)。
1.2 机器学习算法
本研究采用最小绝对收缩和选择算子(Least Absolute Shrinkage and Selection Operator,LASSO)[11]、梯度提升回归树(Gradient Boosting Regression Tree,GBRT)[12]、逻辑回归(Logistic Regression,LR)[13]、随机森林(Random Forest,RF)[14]、线性判别分析(Linear Discriminant Analysis,LDA)[15]、支持向量回归(Support Vector Regression,SVR)[16]6种经典机器学习算法进行训练和验证。
1.3 量表简化过程
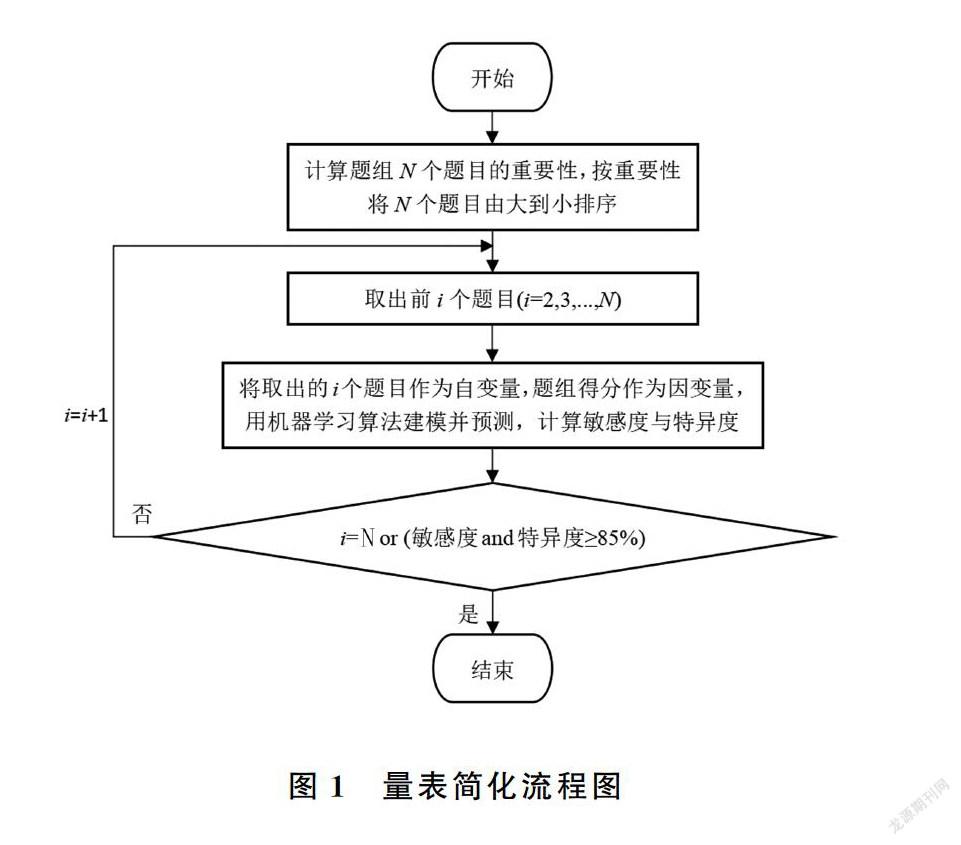
每个题组的题目简化流程如图1所示。
(1)计算题目重要性:选择平均绝对值误差(Mean Absolute Error,MAE)[17]作为评价指标,根据决策树的特征选择将题组内各题目进行重要性排序,并按重要性从大到小调整组内题目作答顺序。
(2)机器学习预测建模:首先取测评者前2个题目的答案,选用6种经典机器学习算法训练模型,自变量是测评者作答题目的答案,因变量是题组得分。预测出题组得分后,根据该题组常模原始分将预测得分筛选阴阳性,得出与真实阴阳性的混淆矩阵,计算出敏感度和特异度,如果敏感度和特异度都大于等于85%或者此时所有题目都用于建立模型,则结束,否则,跳至步骤(3)。
(3)迭代计算:根据重要性由大到小依次向模型中添加题目,重复步骤(2),直至敏感度和特异度均达到85%或该题组内所有题目均做完为止,剩余题目即为题组内删除的题目。
1.4 评价指标
根据中国常模标准[18],将真实得分与预测得分划分阴阳性,得到混淆矩阵,题组内预测以敏感度和特异度作为衡量标准。本研究,按重要性由大到小依次向模型中添加题目,当模型的敏感度与特异度均达到85%,题组剩余的题目为需要删除的题目。
2 结果
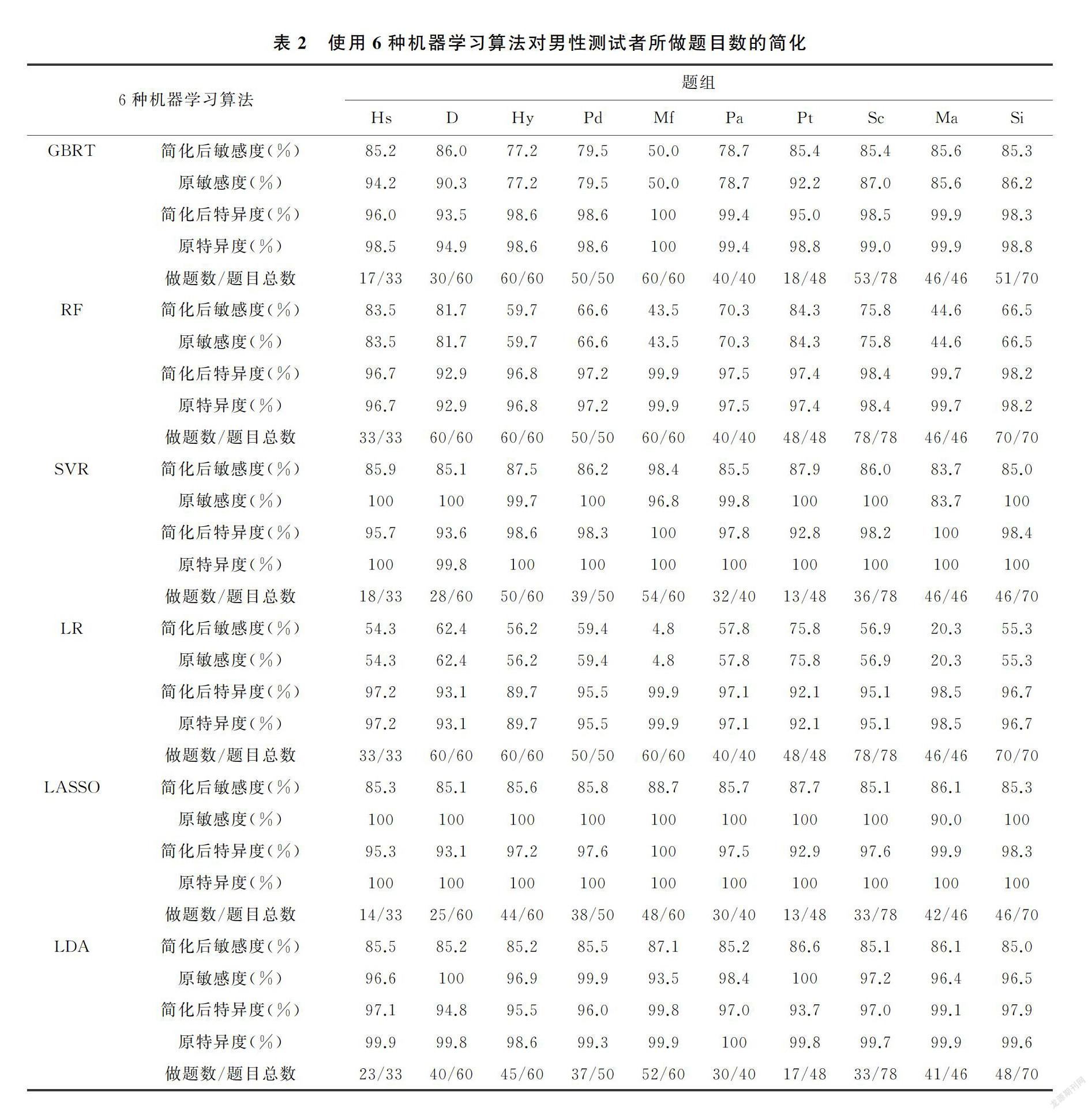
通过6种经典机器学习算法预测MMPI量表原有10个题组的敏感度与特异度,如表2、3所示,其中LASSO和LDA算法预测的最精准,均可达到90%以上。男性测试者通过机器学习算法预测10个题组的敏感度与特异度均达到阈值时,采用GBRT、SVR、LASSO、LDA算法简化后的量表分别只需要做298、264、
250、260道题目。女性测试者通过6种经典机器学习算法预测10个题组的敏感度与特异度均达到阈值时,采用GBRT、SVR、LASSO、LDA算法简化后的量表分别只需要做292、253、243、250道题目。其中LASSO算法在保证较高的敏感度与特异度的条件下所需要做的题目数量最少。推断出组内简化时LASSO算法更可行。通过LASSO算法简化量表,男性测评者由原来的399道题目优化为250道题目,缩短了37.3%的测评时间,女性测评者由原来的399道题目优化为243道题目,缩短了39.1%的测评时间。
本研究采用克朗巴哈系数(Cronbach's α)[19]计算删除题目前后的信度变化。如表4所示,4种算法对于男性测试者的Hy、Pd、Mf、Pa、Pt、Sc、Ma、Si题组删除题目后的信度系数均在0.7以上;Hs、D题组删除题目后的信度系数均在0.7以下。Hy、Pd、Mf、Pa、Pt、Sc、Ma、Si题组删除题目前后的信度系数变化范围在0~0.1之间;Hs、D题组变化超过0.1。如表5所示,4种算法对于女性测试者的Hy、Mf、Pa、Pt、Sc、Ma、Si题组删除题目后的信度系数均在0.7以上;Hs、D题组删除题目后的信度系数均在0.7以下;Pd题组通过GBRT算法删除题目后信度系数大于0.7,其它3种算法信度系数均小于0.7。Hs、Hy、Mf、Pa、Pt、Sc、Ma、Si题组删除题目前后的信度系数变化范围在0至0.1之间,D题组变化超过0.1。
3 讨论
近些年来,多位学者提出基于机器学习简化量表的方法,例如用于注意力缺陷多动障碍行为区别的社交反应量表(Social Responsiveness Scale,SRS)[20]和用于自闭症诊断的自闭症诊断观察量表(Autism Diagnostic Observation Schedule,ADOS)[21],中文双相情感障碍诊断清单(Bipolar Diagnosis Checklist in Chinese, BDCC)[22] 和基于梯度提升回归树的症状自评量表简化[23],均是利用机器学习算法分析大量临床测评数据训练分类器实现量表简化,并通过对照简化前后结果的敏感性和特异性以验证其一致性。本研究经过题组内的筛选,删除MMPI部分题组内的题目,达到使用部分题目就能够较为准确的预测出各个题组阴阳性的目的。但是由于男女子气量表的阳性数据量不足,机器学习模型无法通过足够多的阳性数据学习到其中蕴含的关联性,是的预测结果不够准确,因此还需要尽量收集更多的阳性数据,来提高简化量表的准确性。
4 结论
本研究对比6种经典机器学习算法的简化结果,发现LASSO相对于其他算法预测精度更高,适合于区分高维度和多重共线性的数据,而MMPI量表中的每个量表都有33~78個题目,属于高维数据,因而适合采用LASSO算法。LASSO算法对异常值的鲁棒性强,可以灵活处理各种类型的数据,包括连续值和离散值。在保证组内题目预测的敏感度与特异度相近的情况下,LASSO算法采用的特征数量即题目数量最少、简化效果最好。简化后的量表与全量表相比,在保证各题组拥有较高信度和测评结果的敏感度与特异度均达到85%以上的前提下,男性平均减少37.3%的测评时间,女性平均减少39.1%的测评时间。在后续研究中,可以通过收集更多的MMPI测评数据,尝试其他算法来训练更精准模型,从而推动基于机器学习在精神科量表简化研究与应用。
参考文献
[1] HATHAWAY S R, MCKINLEY J C. A multiphasic personality schedule (minnesota): III. The measurement of symptomatic depression[J]. Journal of Psychology Interdiplinary & Applied, 1942, 14(1):73-84.
[2]纪术茂,陈佩璋,纪亚平,等. MMPI中文版的结构效度研究[J]. 中国临床心理学杂志, 1996(1):20-23.
[3]邹义壮,赵传绎. MMPI临床诊断效度的研究[J]. 中国心理卫生杂志, 1992(5):211-213+238.
[4]杨文双,王志仁,张小璐,等.新冠肺炎疫情期间封闭管理医护人员心理健康状况[J].精神医学杂志,2020,33(2):84-87.
[5]陈祉妍, 刘正奎, 祝卓宏,等. 我国心理咨询与心理治疗发展现状、问题与对策[J]. 中国科学院院刊, 2016, 31(11):1198-1207.
[6]宋维真. 中国人使用明尼苏达多相个性测验表的结果分析[J]. 心理学报, 1985(4):346-355.
[7]贡京京,苗丹民,肖玮,等.青年男性MMPI-215F量表应答时间效应分析[J].中国行为医学科学,2006(6):534-535.
[8]HOFFMANN T, DANA R H, BOLTON B. Measured acculturation and MMPI-168 performance of native American adults[J]. Journal of Cross Cultural Psychology, 1985,16(2):243-256.
[9]宋维真,莫文彬. 心理健康测查表(PHI)的编制过程[J]. 心理科学, 1992(2):36-40.
[10] NEWMARK C S. Brief synopsis of the utility of MMPI short forms[J]. Journal of Clinical Psychology, 1981,37(1):136-137.
[11] TIBSHIRANI R. Regression shrinkage and selection via the Lasso[J]. Journal of the Royal Statistical Society. Series B (Methodological),1996,58(1):273-282.
[12] 郭银景,宋先奇,杨蕾,等. 基于梯度提升回归树的井下定位算法[J]. 科学技术与工程, 2019,19(8):143-149.
[13] 于立勇,詹捷辉. 基于Logistic回归分析的违约概率预测研究[J].财经研究,2004(9):15-23.
[14] BREIMAN L. Bagging predictors[J]. Machine Learning, 1996,24(2):123-140.
[15] FISHER R A. The use of multiple measurements in taxonomic problems[J]. Annals of Eugenics, 1936,7(2): 179-188.
[16] ALEX J S, BERNHARD S. A tutorial on support vector regression[J]. Statistics & Computing, 2004,14(3):199-222.
[17] WANG W J, LU Y M. Analysis of the mean absolute error (MAE) and the root mean square error (RMSE) in assessing rounding model[J]. IOP Conference Series: Materials Science and Engineering,2018,324(1):1-5.
[18] 夏朝云. MMPI中國常模与精神分裂症及躁狂症的诊断[J]. 上海精神医学, 1992, 4(1):39-41.
[19] 游雅媛. 认知诊断Cronbach's α系数属性信度点估计和区间估计研究[D]. 南昌:江西师范大学, 2019.
[20] DUDA M, MA R, HABER N, et al. Use of machine learning for behavioral distinction of autism and ADHD[J]. Translational Psychiatry, 2016,6(2):1-3.
[21] WALL D P, KOSMICKI J, DELUCA T F, et al. Use of machine learning to shorten observation-based screening and diagnosis of autism[J]. Translational Psychiatry, 2012,2(4):1-6.
[22] MA Y T, JI J, HUANG Y, et al. Implementing machine learning in bipolar diagnosis in China[J]. Translational Psychiatry, 2019,9(1): 1-7.
[23] 刘金铭,于淏岿,冯超南,等.基于梯度提升回归树的症状自评量表(SCL-90)简化[J].青岛大学学报(自然科学版),2020,33(2):32-37.
Research on the Validity of Simplifying MMPI Scale Based on Machine Learning
SUN Qi-ke1a, DONG Wen-tian2, WANG Ke3, FENG Chao-nan4, CUI Lin4,
LI Yu-ming4, YU Hao-kui4, YU Bin4, SHI Chuan2, JI Jun1a,1b,4
(1a.College of Computer Science&Technology, b.Medical College,Qingdao University,Qingdao 266071,China;
2.Peking University Sixth Hospital,Beijing 100083,China;3.Qingdao Municipal Hospital,Qingdao 266011,China;
4.Beijing Wanling Pangu Technology Co.,Ltd.,Beijing 100089, China)
Abstract: There are too many questions in the traditional MMPI scale and the subjects' compliance is poor in many application scenarios. A machine learning algorithm is proposed to simplify the clinical scale in the MMPI scale. The simplification effects of six classical machine learning algorithms are compared, and the sensitivity and specificity of the original and simplified evaluation results are compared and analyzed on the subject evaluation data. The experimental results show that the algorithm using the minimum absolute contraction and selection operator (LASSO) has the best simplification effect while keeping similar accuracy to reduce the number of subjects by 37.3% for men and 39.1% for women on average, keep the sensitivity and specificity of the simplified evaluation results at 85% of the original evaluation results, thus shortening the evaluation time and being suitable for more application scenarios.
Keywords:
MMPI; machine learning; shorten scale
