基于异构信息网络融合的专利技术主题识别研究*
2021-08-30田鹏伟
田鹏伟 张 娴
(1. 中国科学院成都文献情报中心知识产权研究咨询中心 成都 610041;2. 百度时代网络技术(北京)有限公司 北京 100085;3. 中国科学院大学经济与管理学院图书情报与档案管理系 北京 100190)
0 引 言
专利文献是记录技术创新过程与成果的重要载体,也是联系科技与经济两大范畴的重要信息介质。专利文本主题识别是采用文本数据挖掘手段发掘专利文献中具有可研究性及经济价值的主题信息,有助于把握技术创新前沿、预测技术发展趋势。然而,专利数据不同于一般的科学文献,其语言表述晦涩性、文本组织结构特殊性增加了文本主题识别的难度,削弱了通用文本挖掘方法直接套用于专利文本主题识别的应用效果。
目前专利文本主题识别相关研究大致可划分为三个阶段:(1)基于专利技术主题词、主题词关联关系表征,研究专利文本的主题[1];(2)采用共词分析方法、多元关系网络,对专利文献进行建模,获取专利文本的主题[2-4];(3)应用文本挖掘技术(如LDA等主题模型)分析专利文献,挖掘专利的主题[5-6]。现有研究局限主要体现在三方面:a.将专利数据视作普通文本数据处理[7]。专利文献用语晦涩,增加了文本处理难度,通用分词结果难以达到理想的技术主题挖掘效果。b.主题识别分析维度单一,缺乏多维视角[8]。主题识别研究多依赖于主题词共现网络,或发明人、专利权人、IPC等属性网络,少有涉及多维网络融合视角研究主题识别[9-12]。c.逐渐重视将多维、异构建模思维应用于专利分析,但针对专利技术主题识别方面的研究较少[13-14]。
异构信息网络(Heterogeneous Information Network,HIN)于2009年由Sun提出[15],也称元网络,指的是网络中至少存在两种及以上种类的节点对象类型、关系类型。按网络节点的同质、异质特性,异构信息网络可分为同质异构与异质异构,常见于图像处理、通信领域等[16]。异构信息网络融合指对已存在的若干信息网络进行融合使其拓扑结构合为一体,或对复杂系统中若干组实体重新构建网络。异构信息网络与专利文本主题识别相结合,有助于充分利用多维信息优势提升专利技术主题识别的准确性。
本文尝试基于异构信息网络融合实现专利文本主题识别,提高专利技术主题识别的准确性。具体而言,利用专利文献中的主题词、发明人、专利权人、IPC分类号、引证信息等属性共同构建专利异构信息网络,通过融合运算形成融合网络,进而开展主题识别研究,期望探索一种基于异构信息网络融合的专利技术主题识别方法。
1 研究方法
1.1研究思路利用异构信息网络对专利文献数据集的多类特征属性建模。专利文献中特征项之间可抽象为直接或间接的矩阵表示,OVL叠加算法(overlap function)可用于计算两个关联矩阵间各节点的最小联通路径,且对术语权重大小的文档间差异测度敏感[17]。因此,本文采用OVL叠加算法以及线性加权[18-19]方法融合构建异构信息网络,形成专利异构信息融合网络。
本文提出的技术主题识别方法研究框架(见图1)包含:提取与技术主题密切关联的多个类型特征,构建专利异构信息网络;采用OVL算法及线性加权方法,融合所构建的异构信息网络,形成专利异构信息融合网络;基于融合后的网络进行聚类,识别专利技术主题。

图1 基于异构信息网络融合的专利文本主题识别方法研究框架
1.2专利异构信息网络建模
1.2.1 获取数据特征项 选取下述特征项构建网络:主题词[20](对标题与摘要经自然语言处理提取)、专利号(唯一标识)、发明人、专利权人、IPC分类号、专利引文等。
a.主题词抽取。对专利文献的标题、摘要进行通用的自然语言处理,提取关键词信息。然后,在尽可能保全关键词的前提下,剔除低频词汇,形成核心主题词集合。
b.其他特征项抽取。在上述主题词集合之外,抽取专利文献其它内部、外部特征信息,分别形成专利号集合、发明人集合、专利权人集合、IPC集合、专利引文集合、专利申请年集合;进行数据清洗,如专利权人、发明人名称规范与消歧、低频专利引文数据剔除等[21]。
1.2.2 构建专利异构信息网络 异构信息网络的重要特点在于节点的异质性与连边的复杂性。共现关系是海量文本挖掘中一种表征特征属性间相互关联的有效方法。例如,通过统计一组特征项在同一篇文献中出现的次数,体现特征项之间的关联关系、强度及结构变化[22-23]。
将前述主题词集合、其他特征项集合作为节点,其共现关系作为连边,构建网络。该网络中节点均是异质节点,各节点间存在多种连接关系,因此属典型的异构信息网络模型,如图2所示。
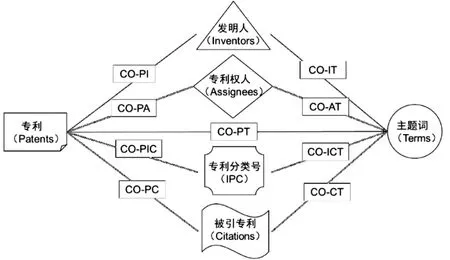
图2 专利异构信息网络模型示意
1.3专利异构信息网络融合当前的信息网络融合处理方法各具优劣[24]。考虑到异质节点属性特征的融合性、术语权重差异测度的敏感性、联通路径计算的经济性,本文采用“矩阵运算”+“加权融合”思路进行异构信息网络融合处理。

f2=min (Wik[A:B],Wkj[B:C])
(1)
式(1)中,Wik表示从节点i到节点k的链接权重,[A:B]表示矩阵的行对象是A,列对象是B;min ()则表示计算由节点i通过节点k到达节点j的最小值。
(2)
式(2)中,f1是在f2的基础上计算经过B(bi)从A到C所有最小权重之和。
将公式(1)、(2)整合可得:
(3)
则OVL计算公式可定义为:
Wij[A:C]=OVL (Wik[A:B],Wkj[B:C])
(4)
将算法衍生于对更多数量矩阵的融合处理,如下所示:
Wij[A:E]=OVL (Wil[A:B],Wlm[B:C],Wmn[C:D],Wnj[D:E])
(5)
采用OVL方法对异构信息网络进行融合处理,分别采用OVL算法对图2中每条路径进行融合,即形成多个不同的P-T(Patents-Terms)融合矩阵,如图3所示。
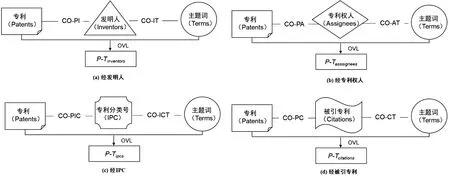
图3 OVL矩阵融合示意图
1.3.2 加权计算融合网络 采用加权融合对上述得到的多个Patents-Terms融合矩阵再次融合,最终形成统一、有效的融合矩阵,设为P-Tfusion(见图4)。计算公式如式(6)。

图4 矩阵加权融合示意图
(6)

1.4专利技术主题识别基于上述融合矩阵P-Tfusion,进行技术主题识别研究。聚类运算前需考虑是否对已有数据进一步降维处理,提高识别的准确性和有效性。
1.4.1 矩阵降维 常用数据降维手段有主成分分析(Principal component analysis,PCA)、奇异值矩阵分解(Singular value decomposition,SVD)等[25-26]。就降维原理而言[27-28],上述两种均可作为本文的降维工具,但使用PCA之前需明确知道降维后的维度k,而SVD则不需要提前指定维度,因此本文选用SVD,计算公式如式(7)。
(7)
1.4.2 专利技术主题聚类与可视化 目前已有多种文本聚类方法研究,如基于数据分类的K-means、K-medoids、PAM,基于层次聚类的BIRCH、CURE、ROCK,基于聚类簇密度的DBSCAN、OPTICS、Mean-shift等[31]。由于聚类工具与算法并非本文研究重点,因此选用经典聚类算法K-means,用于验证异构信息网络融合前后的专利技术主题识别效果。聚类效果评价,采用Silhouette Coefficient(轮廓系数)[32]计算聚类的全局最优系数,具体如下:
采用K-means将待分类数据分为了k个类,对于类中每个向量i,分别计算它们的轮廓系数,有:a(i)=average(向量i到同类中的所有其它点的距离),b(i)=min(向量i到非同类中的所有点的平均距离)。
如图5所示,对于向量i,有:
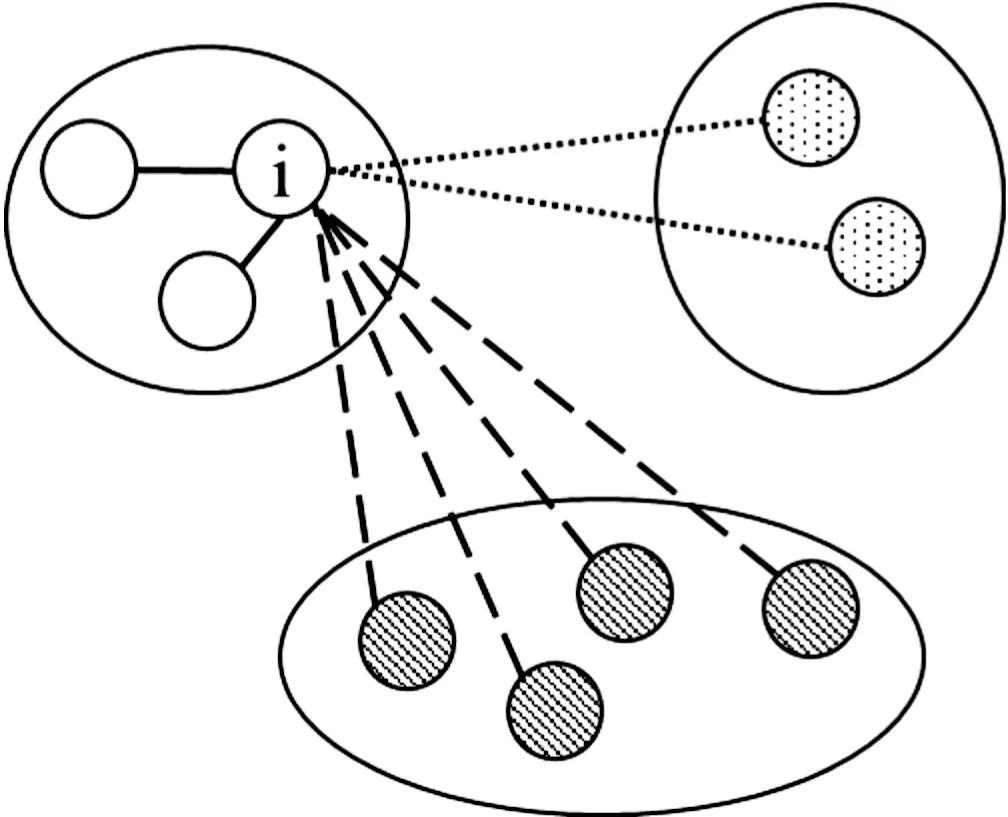
图5 聚类轮廓示意图
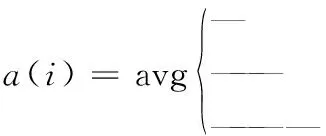
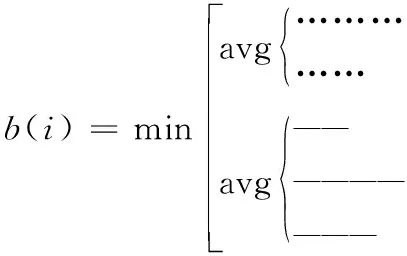
(8)
则,向量i的轮廓系数为:
(9)
其中,a(i)表示向量i到同一簇内其他点不相似程度的平均值;b(i)表示向量i到其他类的平均不相似程度的最小值。可见,轮廓系数的值介于[-1,1],越趋近于1代表内聚度和分离度都相对较优。求取所有节点的轮廓系数平均值,就是该聚类结果的总轮廓系数。
可视化是直观考察主题识别聚类效果优劣的重要手段,尤其Origin工具的三维旋转功能有助于清晰展示。本文采用Origin工具对融合处理前后网络的主题聚类结果可视化呈现,以对比技术主题识别效果。
2 实证分析
2.1数据获取与预处理本文选择工业机器人技术领域开展实证分析。实证数据来自科睿唯安(Clarivate Analytics)的德温特创新索引(Derwent Innovation Index,DII),通过概念及相关要素组配制定检索策略。鉴于实验数据处理能力,将检索年限设定为2014-2015年,对检索结果人工排杂后共获得14 331件专利记录。
利用DDA(Derwent Data Analyzer)和Python的NLP工具进行数据预处理。提取6项属性特征值:专利号(Patent Numbers)、专利权人/申请人(Patent Assignees)、发明人(Inventors)、IPC分类号(International Patent Classifications)、引证专利号(Cited Patent Numbers)、主题词(Keywords)。规整发明人、机构申请人项名称;对Title和Abstract项进行NLP处理抽取关键词(词组),去除停用词、主题无关词,自定义TF-IDF算法选取高频词;去除被引频次低于2的离散数据。最终得到待分析的数据集合。数据预处理操作详见表1。
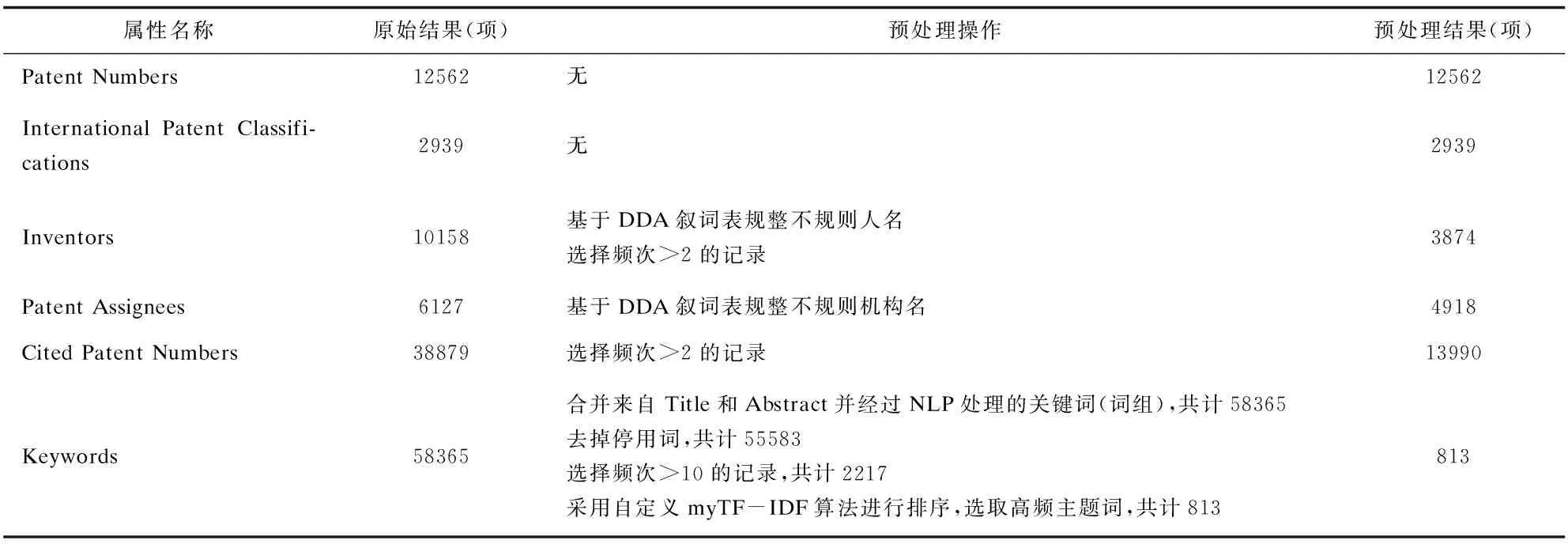
表1 实证数据预处理结果
2.2异构信息网络融合分析
2.2.1 异构信息网络构建 利用DDA抽取9个共现矩阵,构建9个异构共现网络:CO-PI(专利-发明人共现)、CO-IT(发明人-主题词共现)、CO-PA(专利-专利权人/申请人共现)、CO-AT(专利权人/申请-主题词共现)、CO-PIC(专利-IPC共现)、CO-ICT(IPC-主题词共现)、CO-PC(专利-被引专利共现)、CO-CT(被引专利-主题词共现)以及CO-PT(专利-主题词共现)。
2.2.2 异构信息网络融合 第一步,OVL融合。提取该异构信息网络中的4条路径:Patents-Inventors-Terms、Patents-Assignees-Terms、Patents-IPCs-Terms、Patents-Citations-Terms;分别采用OVL算法融合,形成4个不同的P-T(Patents-Terms)矩阵:P-Tinventors、P-Tassignees、P-Tipcs、P-Tcitations。
第二步,对以上4个P-T矩阵进行加权融合,形成P-Tfusion矩阵。
第三步,确定加权系数。加权系数的计算通过聚类系数K值进行逆向推导。
a.聚类系数K值确定。K值选择原则是在保证聚类团体较为集中的前提下,力求类更多,即K值更大。考虑到计算的时间与空间复杂度,采用控制变量法,设定α=β=γ=θ=0.25,并设置网络聚类系数K(3≤K≤50)进行迭代运算,锁定可能的聚类范围,如图6所示。

图6 聚类系数K值确定
由于网络聚类轮廓系数取值范围为[-1,1],且对比参照组与实验组发现,K=4时对应的聚类轮廓系数最大(不考虑K=2,因不含实际意义),因而取K=4。
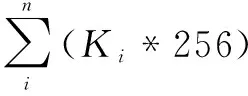
2.2.3 专利技术主题识别 对融合矩阵P-Tfusion降维处理,k-means算法聚类,然后在领域专家参与下解读聚类结果并予以主题命名。表2列举了专家参与下的部分聚类主题识别结果。
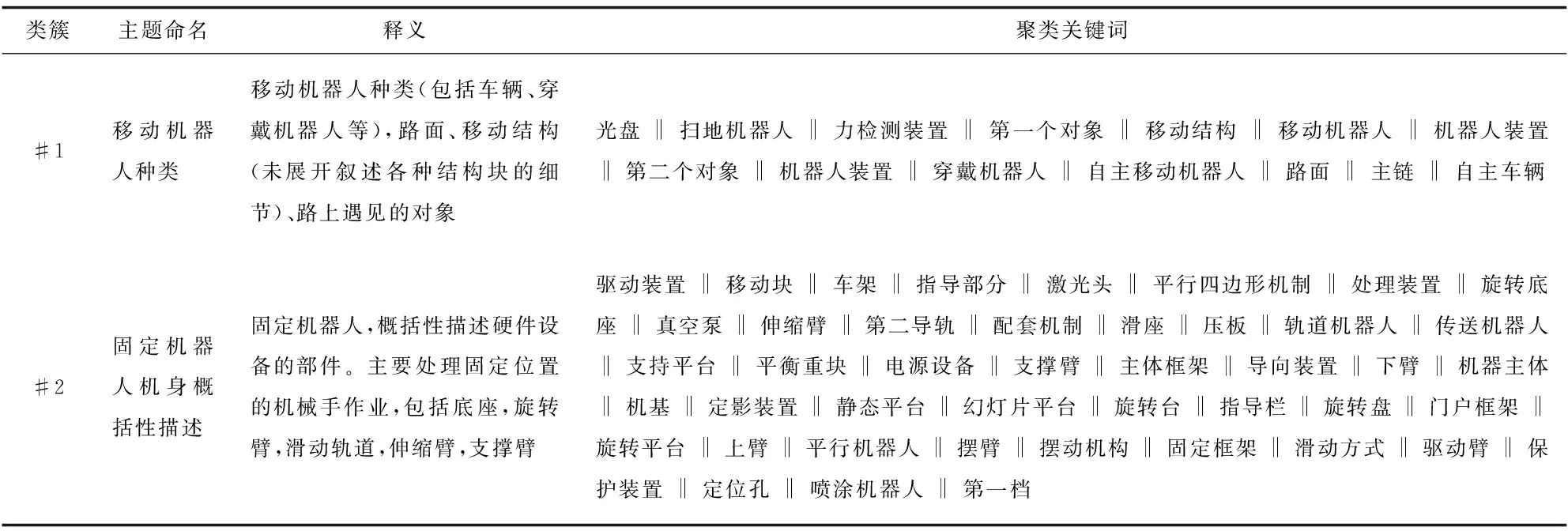
表2 工业机器人专利聚类主题识别结果(异构融合网络P-Tfusion,部分)
2.3对比分析与结果讨论为验证异构信息网络融合方法在专利主题识别中的应用效果,本文采用关键词直接共现CO-PT进行主题聚类识别作为对照组P-Treference,与实验组P-Tfusion主题识别结果相对比,分别采用可视化、专家解读两种对比途径。
2.3.1 可视化对比 利用Origin工具可视化,对比观测两组聚类结果的主题向量空间结构分布。结果表明,实验组P-Tfusion的聚类识别结果优于对照组P-Treference,篇幅原因,此处例举正视、正视左旋45度、正视右旋45度视图,详见图7。

续表2 工业机器人专利聚类主题识别结果(异构融合网络P-Tfusion,部分)
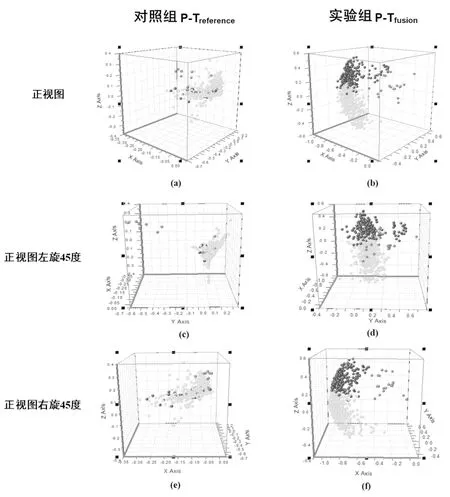
图7 专利技术主题识别结果可视化对比
如图7所示,对照组P-Treference的聚类结果,其正视图(图7a)、左视图(图7c)、右视图(图7e)的空间分布结构性均不具备明显区分度,部分重叠交叉状态较为严重。实验组P-Tfusion的聚类识别结果可视化效果较为清晰,除左视图(图7d)显示出部分重叠,正视图(图7b)、右视图(图7f)均呈现出较好的区分度,尤其右视图表现出聚类结果具有几近完全清晰的区分度,三维空间中点对之间的区分性更高、簇间间隙更明显。
2.3.2 专家解读 在领域专家参与下对与P-Tfusion(表2)同时段的对照组P-Treference进行主题聚类结果解读与命名,结果如表3所示。
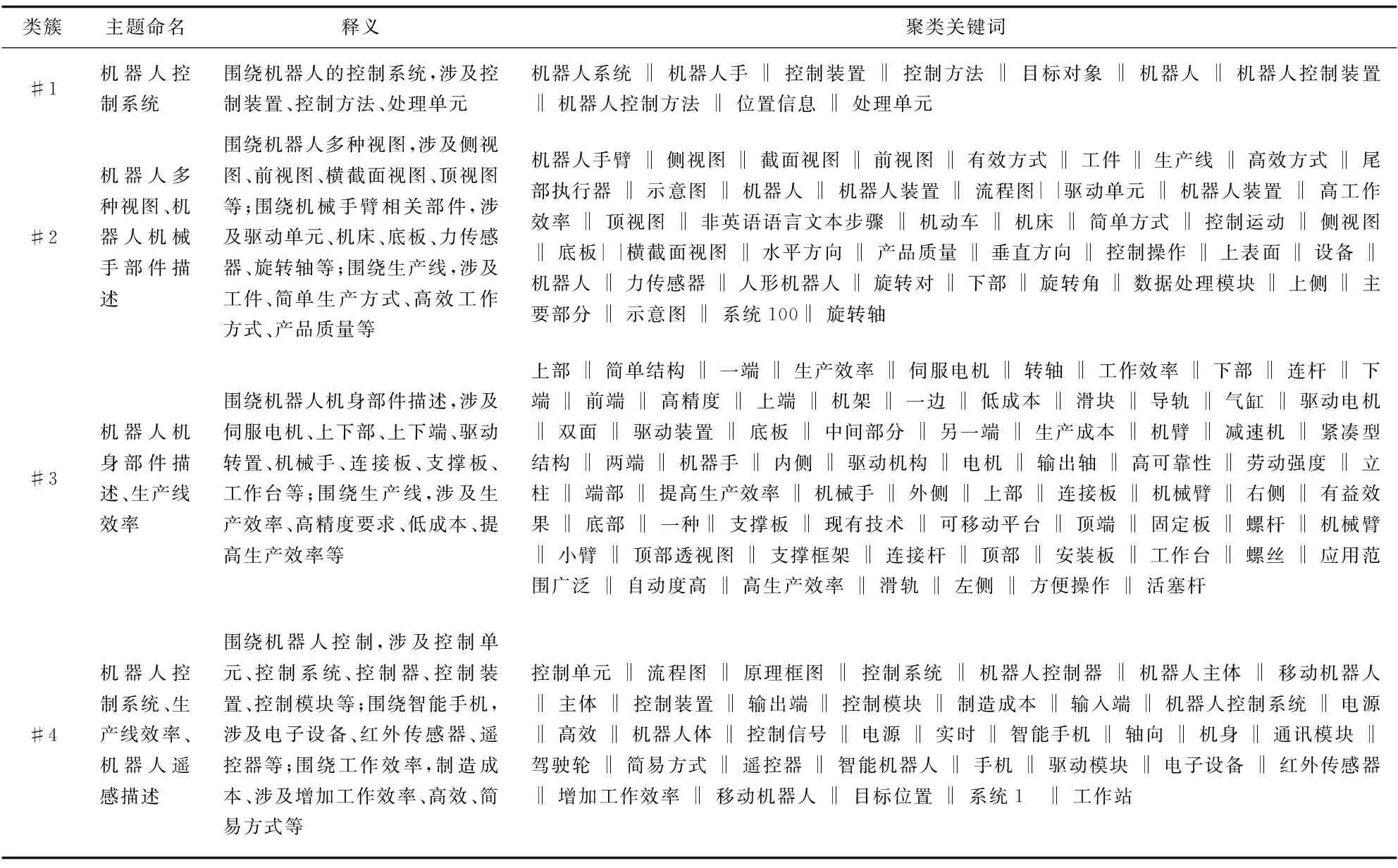
表3 工业机器人专利聚类主题(关键词直接共现网络P-Treference,部分)
对比发现,实验组P-Tfusion4个聚类内部间隙紧密,类间间隙较清晰,未出现明显重叠。对照组P-Treference4个聚类中,#1与#4在控制系统方面存在部分重叠,#2与#3在描述机器人机械手与机器人机身时存在被包含关系,#3与#4之间在生产线效率问题上存在交叉。
2.3.3 结果讨论 可视化观测显示,基于异构信息网络融合(以下简称“融合网络”)处理得到的技术主题识别结果与未经融合网络(以下简称“非融合网络”)得到的技术主题识别结果相比,其主题向量空间分布的结构边界更清晰、区分度更明显。
同时,聚类主题判读命名对比显示,融合网络主题识别结果具有更强的主题关联,非融合网络的主题识别结果相对更偏向通识性、常规性描述,对技术细节内部揭示深度较弱。如,非融合网络主题识别结果中描述机器人的控制系统、机身描述、生产效率、多视图,这些技术主题对于机器人领域而言更属通用技术,不具显著特殊性,且关键词描述概括性较高。领域专家对比判断认为,融合网络的专利技术主题识别结果相对更全面,既包括了概括性机身描述,也包括关键性部件详细描述,并且还识别出了前沿性机器人种类挖掘等主题。究其原因,融合网络融合了专利信息的多类特征属性,蕴涵了更丰富的显性与隐性信息。
综上,基于异构信息网络融合的专利技术主题识别方法,在开展既定领域专利技术主题识别中具有可行性。相对于非融合的网络模型,本文提出的方法得到技术主题结果在全面性、深入性方面更具优势,各主题的类中集中性更好,类间区分度更高、交叉性与重叠度更低,并且有助于发掘出领域内前沿性技术。
3 结 语
当前,专利文本主题识别大多基于单一关联关系分析,难以全面挖掘专利数据中更多隐性关联信息。本文采用多维、异构建模思维,提出了一种基于异构信息网络融合的专利技术主题识别方法,对专利信息进行异构建模,结合OVL算法对异构信息网络融合,在此基础上识别专利技术主题。以工业机器人领域为例的实验对比结果显示,异构融合的专利信息网络可以有效提高技术主题聚类的全面性与准确性。
未来,关于异构信息网络融合的专利技术主题识别研究,需要关注以下两方面:一是优化多维关系特征获取。专利大数据环境下,专利信息间蕴涵的直接、间接关联日渐丰富,不同维度的关联关系对技术主题表征的侧重、强度有所差异,要尽可能深挖更多关联类型,构建更丰富的多维信息关系体系。二是深入开展网络融合算法应用研究。网络融合方法多样,但目前应用于文本主题识别的研究尚不多见,本文应用OVL算法开展了有限的探索。不同融合算法在概念、方法上有所差异,针对异质文本信息特征,找寻更具有效性、适用性及计算经济性的融合算法是未来该研究方向的重要研究命题。
