基于深度学习的极性电子元器件目标检测与方向识别方法
2021-08-28陈文帅任志刚吴宗泽付敏跃
陈文帅 任志刚 吴宗泽 付敏跃
电子元器件是电子设备的重要基础组成部分,在其生产、回收、焊接与检测中,首先需要对元器件进行正确分类.此外,在焊接和检测元器件的过程中,还需要对极性电子元器件的方向进行准确识别.因此,对电子元器件正确分类的同时能够对极性电子元器件的方向进行识别具有重要的研究意义[1].但随着电子元器件制造工艺的提高与需求的多样化,电子元器件变得更加微型化、多样化,这为电子元器件的分类与检测方向等问题带来了更严峻的挑战.
2012 年之前,图像分类和目标检测一度进入瓶颈期,发展相对停滞.随着计算机视觉的快速发展,深度学习在目标检测方面也取得了巨大的成功.得益于此,深度学习在计算机视觉方向的算法不断更新迭代,在文字识别[2]、医学图像识别[3−4]等方面得到了广泛运用.2012 年,Krizhevsky 等[5]提出了一个称为AlexNet 的深度卷积神经网络(Deep convolutional neural network,DCNN),其在大规模的视觉识别挑战(ImageNet large-scale visual recognition challenge,ILSVRC) 中实现了破纪录的图像分类精度,成为深度学习发展的一个重要里程碑.从此,深度学习进入高速发展阶段,许多计算机视觉应用领域的研究也都集中在深度学习方法上[6],其中包括目标检测及图片背景消减技术[7].
深度学习在目标检测领域的目标检测方法[8]可分为基于候选区域的目标检测方法和基于回归的目标检测算法.基于候选区域的检测方法采用了卷积神经网络代替人工特征的提取[9],常用的候选区域提取办法有SelectiveSearch[10]和Edge Boxes[11].常用来提取特征图的网络结构有VGG(Visual geometry group)[12]、ResNet[13]等.Faster RCNN(Region convolutional neural network)[14]是最具有代表性的算法之一,Faster RCNN 为了减少SelectiveSearch和EdgeBoxes 提取候选区域的时间,结合全卷积设计的候选区域思想[15],提出了用区域侯选网络(Region proposal networks,RPN)计算候选框,不仅提高了候选区域的质量与准确率,还将检测时间减少为原来的1/10.基于候选区域的目标检测方法需要分两步去分别训练两个复杂的卷积结构,虽然检测精确,但其有在训练与检测速度上缓慢的缺点.基于回归的目标检测算法为了解决这个缺点,不通过生成区域建议的方式,直接将目标检测的相关问题转化为回归问题[16],其结构相对简单,实时性更好,最具有代表性的算法有SSD(Single shotmultibax dctector)[17]和YOLO(You only look once) 系列算法[18−20].YOLO 算法简单地将图像均匀分为7×7 个部分,再利用卷积神经网络检测每一个部分是否有目标,最后对目标类别与位置进行预测.YOLO 就是通过节省生成区域建议的时间来大幅提高检测速度,但这也会对其精度带来一定的影响.
目前对于电子元器件分类研究的算法,主要分为两大类,如图1 所示,一类是基于传统的图像分类的方法,首先输入图像、然后经过复杂的程序提取图像的特征,再根据提取出来的特征进行分类.如杜思思等采取将最小二乘法和Hough 变换相结合[21],得到一种改进的直线段精确检测算法.另外一类是基于深度学习的分类方法,首先输入图像、然后经过卷积神经网络自动提取特征生成特征图、再根据特征图进行目标的定位与分类.如陈翔等[22]提出了一种基于卷积神经网络(AlexNet) 的电子元器件分类方法,其可以直接在输人图像上进行自动特征学习和分类,弥补了传统元件分类方法存在部分缺陷,但只能对图片进行分类,不能运用到单幅有多目标的场景并对目标进行定位.第1 类传统的图像分类方法需要提取图像的多种特征,要对每一种类别的元器件找出其表示的特征,如蜂鸣器的特征用圆表示等.其有以下缺点:1) 传统图像分类方法对于图像的对比度要求很高,模糊、灰度化不明显、灰度不均匀等情况都会增加识别的误差;2) 对特征相似的目标识别效果不佳,比如同样类别的不同型号的元器件分辨准确率低;3) 需要人工提取特征,无法对包含上百种海量数据进行分类,每多一种分类,计算复杂度就上升一个等级.第2 类基于深度学习的分类算法,虽然有随着深度学习网络的加深计算量不断加大的缺点,但融入了反向传播[23]、权值共享、稀疏连接、池化、Dropout[24]等思想,简化了操作,并且大大降低了神经网络参数的量级,一定程度上减轻了计算量,使其更易于训练,而且深度学习算法能够自动的提取图像特征,自动学习各种各样的表征特征纹理,甚至能够表达完整的目标物,比人工提取的特征更具有描述力,其对于目标的理解的概念分布在神经网络不同的层中,最后形成了对不通目标物体的整体感知,并根据感知同时对目标进行分类与定位.
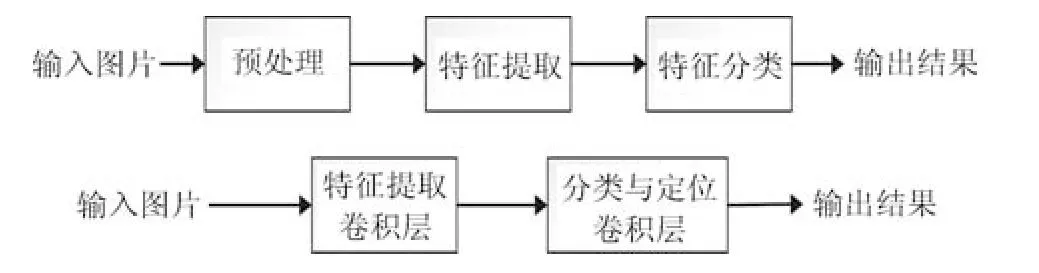
图1 基于传统和深度学习图像分类方法模型Fig.1 Traditional and deep learning image classification method based on model
本文的主要贡献主要有以下三个方面:1) 首次提出基于深度学习极性电子元器件类别与方向识别方法.通过把方向识别问题转化为分类问题,利用先进的目标检测算法进行分类,平均准确率(Mean average precision,mAP) 最优高达99.44%.2) 提出一种基于数据集设计遍历框(Anchor boxes) 的方法.根据训练集目标框长宽的分布结合算法提供的框来选取Anchor boxes 的个数与大小.3) 提出YOLOv3-BigObject 算法模型.对于大目标的数据集,通过对Anchor boxes 大小与个数的分析,压缩YOLOv3 的算法框架,减少了训练复杂度与时间,大幅减少对单张图片的检测时间.
本文组织架构如下:首先,在第1 节对数据集的构建与内容进行了详细介绍.在第2 节利用K-means 算法,基于数据集和目标检测算法设计了Anchor boxes 的大小与个数.在第3 节提出用于大目标检测的YOLOv3-BigObject 网络模型.在第4 节,我们通过进一步实验分析,验证了深度学习在该场景下的极性元器件方向识别的效果,分析了用K-means 算法设计Anchor boxes 的效果以及YOLOv3-BigObject 模型在检测时间上的提升效果,并用焊接有元器件电路板视频检测算法实际效果,最后,对全文工作进行了总结和展望.
1 数据集构建及预处理
深度学习的算法模型需要大量的数据进行训练,但目前还没有公开的、带类别标签的电子元器件的数据集,为了能够实现本文所提出的基于深度学习的极性电子元器件类别与方向识别,实验采取人工拍摄的方式采集数据集.采集设备为海康威视MVCE013-50 GM 130 万像素的CCD 工业相机,数据集1 一共采集2 000 幅大小为1 280×960 像素、包含3 种型号的二极管图片,如图2 所示.数据集2一共采集813 幅大小为1 280×960 像素、包含2 种型号且带有引脚的二极管图片,如图3 所示.目前深度学习算法还没有能够识别目标的具体倾斜角度,但可以通过把方向问题转换为分类问题达到粗略的方向识别的效果.根据二极管正极的朝向将其分为4类:上、下、左、右,每类角度范围为90◦,具体分类细节如图4 所示.为了训练出分类效果比较好的算法模型,首先对原始数据集进行数据增强的预处理,经过对图片分别逆时针旋转90◦、180◦、270◦与水平翻转、垂直翻转、水平垂直翻转等6 种方式将数据集扩增到原数据集的7 倍,其中,数据集1 具体分布如表1 所示,数据集2 具体分布如表2 所示,括号外的数字表示数据集包含该类的图片数量,括号内的数字表示数据集包含该类别的目标数量.

图2 数据集1 图片示例Fig.2 Image examples of the dataset 1

图3 数据集2 图片示例Fig.3 Image examples of the dataset 2

表1 数据集1 包含各类的图片数量和目标数量Table 1 The dataset 1 contains the number of images and targets of targets in each category

表2 数据集2 包含各类的图片数量和目标数量Table 2 The dataset 2 contains the number of images and targets of targets in each category

图4 方向识别转化为分类Fig.4 Direction recognition change to classification
2 Anchor boxes 的选取方法
在目标检测的深度学习算法中,每种算法都有基于某些数据集给出Anchor boxes 的大小与个数,如在FasterRCNN给出的9 个Anchorboxes[14],YOLOv2 提供的5个Anchorboxes[19],YOLOv3给出的9 个在不同大小特征图(Feature map) 的Anchor boxes[20],但默认算法提供的Anchor boxes不一定适用在某些特定场景下的数据集,如果过多,会造成训练时间过长、检测速度过慢、资源浪费等问题.因此,选取适合特定数据集的Anchor boxes至关重要.因此,本文结合具体应用背景,提出一种基于K-means 算法设计Anchor box 的方法,并且在Faster RCNN 与YOLOv3 上取得良好的效果.具体步骤如下:1) 计算训练集中每个目标框(Ground truth boxes,GT boxes) 与算法给出的Anchor boxes 的交并比(Intersection over union,IoU);2) 每个GT Boxes 选择与其IoU 最大的Anchor box 并统计每个Anchor box 被选到的个数,剔除计数为0 的Anchor boxes,选择计数不为0 的n个Anchor boxes 为初始化的聚类中心;3) 用Kmeans 算法进行聚类迭代计算,最终得到n个适合该数据集的Anchor boxes.
2.1 基于Faster RCNN 算法的Anchor boxes
Faster RCNN 算法[14]是根据设定的3 个长宽比例和3 种面积生成9 个Anchor boxes,这样设置难于直观调节大小,而且部分Anchor boxes 之间有关联,在特定数据集下,几乎得不到与训练集平均IoU 最大的Anchor boxes.相对来说,以长宽设置Anchor box 大小更为直观,这样能得到与训练集平均IoU 最大的Anchor box.在极性电子元器件的数据集1 和数据集2 中,其训练集需检测的目标长宽的分布如图5 所示,图中横坐标、纵坐标分别表示GT boxes 的宽度和高度,训练集所有GT boxes 用圆表示,星号为Faster RCNN 提供的9 个Anchor boxes,根据上述计算步骤,最远离原坐标的3 个Anchor boxes 计数为0,说明相比较其他Anchor box,这3 个距离GT boxes 比较远,训练集与其IoU 没有比其他6 个Anchor boxes 大.所以,对于该数据集,Faster RCNN 只要6 个Anchor boxes 足以满足数据集目标的大小.故选取算法提供的其他6 个Anchor boxes 作为K-means 算法初始聚类的点,经过多次迭代,最终得到适用于该数据集的Anchor boxes,即图5 中正方形的点.通过计算,算法提供的9 个Anchor boxes 与训练集的平均IoU 为0.6294,IoU 的均方差为0.08289.经过K-means 算法得到的6 个Anchor boxes 与训练集的平均IoU 为0.8,IoU 的均方差为0.0555.

图5 基于Faster RCNN 的Anchor boxes 和训练集的分布Fig.5 Distribution of training set and anchors boxes based on Faster RCNN
2.2 基于YOLOV 3 算法的Anchor boxes
YOLOv3 算法[20]采用多个Scale 融合的方式,利用3 种大小不一样的特征图分别检测大、中、小的目标,并在每个特征图上选择3 个Anchor boxes进行遍历,在对GT boxes 分布比较广的、目标比较小的数据集上效果比较好,但在特定数据集不一定需要3 种尺度的特征图.YOLOv3 虽然提出用Kmeans 算法根据数据集目标的长宽来选取Anchor box,但其初始化K-means 算法的聚类中心一般是在训练集中随机选取,而且聚类中心的个数需要自己设定.这样选取的Anchor box 随机性比较大,不一定是最佳选择,而且个数难于设定.在有极性电子元器件的数据集1 和数据集2 中,其训练集的GT boxes 转化后的分布如图6 所示.图中横坐标、纵坐标分别为GT boxes 的宽度和高度,训练集所有GT boxes 用圆表示,星号为YOLOv3 提供的9 个Anchor boxes 的分布,根据上述计算步骤,只有3 个Anchor boxes 的计数不为0.所以,对于该数据集,YOLOv3 只要3 个Anchor boxes 足以满足该数据集.故选取这3 个Anchor boxes 作为K-means 算法初始聚类的点.经过多次迭代,最终得到适用于该数据集的Anchor boxes,即图6 中正方形的点.通过计算,算法提供的9 个Anchor boxes 与训练集的平均IoU 为0.44768,IoU 的均方差为0.1136.经过K-means 算法得到的3 个Anchor boxes 与训练集的平均IoU 为0.6645,IoU 的均方差为0.0870.

图6 基于YOLOv3 的Anchor boxes 和训练集的分布Fig.6 Distribution of training set and anchor boxes based on YOLOv3
3 YOLOv3-BigObject
YOLOv3 算法的网络结构以Darknet-53 为基础,在第36,61,79 层分别形成大小为52×52,26×26,13×13 的特征图,如图7 所示,3 种特征图对应的Anchor boxes 大小分别为((10,13),(16,30),(33,26)),((30,61),(62,45),(59,119)),((116,90),(156,198),(373,326)).结合特征金字塔网络(Feature pyramidnetwork,FPN)[25]的思想,后面生成的特征图融合前面生成的特征图,可以提高对中小物体检测的准确率,最终在82,94,106 层分别经过输出对大,中,小目标的检测结果.根据前面YOLOv3 在极性电子元器件的数据集上得到适用于该数据集的3 个Anchor boxes:((118,175),(190,102),(185,154)).显而易见,该数据集都是大目标,这3 个Anchor boxes 与算法在13×13 特征图对应的Anchor boxes ((116,90),(156,198),(373,326)) 最为接近,在13×13 特征图上进行遍历能有最好的结果.其他两种特征图在该数据集上明显多余,基于此,我们对YOLOv3 结构进行改进,删减生成52×52,26×26 特征图的结构,保留中间的下采样结构,把原来106 层的结构缩减为46 层的结构,如图8 所示.

图7 YOLOv3 的网络结构Fig.7 YOLOv3 network structure

图8 YOLOv3-BigObject 的网络结构Fig.8 YOLOv3-BigObject network structure
YOLOv3-BigObject 具体的网络结构如图9 所示,由YOLOV3 的Darknet-53 结构改进得到,它主要由5 个下采样层、11 个残差块、1 个平均池化层、1个全连接层组成.下采样层、残差块中的卷积层依次包含有二维卷积(Conv2d)、批归一化(Batch normalization,BN)、LeakyReLU.其中,BN 的目的是为了防止梯度消失,在不破坏特征分布的情况下将输入控制在一个稳定的范围内,使网络中每层输入数据分布比较稳定,并且可以加速模型的学习速率,式(1) 为其计算公式,其中y为经过BN 后的输出,x为BN 的输入,γ,β分别为可学习的缩放参数与偏移参数,ε是趋向于0 的参数,预防式中分母为0.

图9 YOLOv3-BigObject 的内部网络参数设置结构Fig.9 The Internal network parameter setting structure of the YOLO v3-BigObject
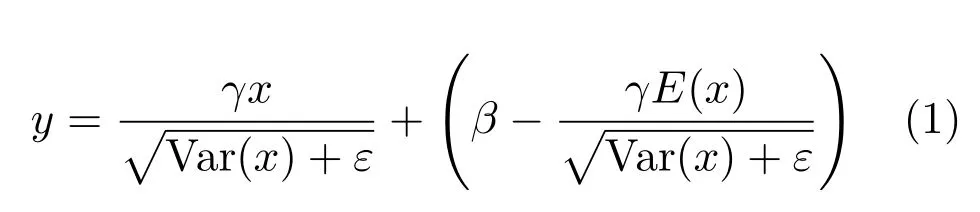
在经过BN 后,BN 所得的结果输入激活函数中,在此算法结构中的激活函数为LeakyReLU,如式(2) 所示,LeakyReLU 是一个非饱和激活函数,而且给所有负值赋予一个非零斜率,以解决梯度消失、加快收敛速度、避免神经元死亡等问题.

4 实验分析
4.1 实验设置
本文实验的显卡设备为NVIDIA GeForce GTX 1080 Ti.实验分为三部分:实验1 用于证明本文所选取Anchor boxes 的方式在准确率上有一定的提升,我们分别用Faster RCNN 和YOLOv3算法对其进行验证,并在测试集中进行测试.在Faster RCNN 的实验中,设置的Batch size 为1,训练步数为140 000;在YOLOv3 的实验中,设置的Batch size 为64,训练步数为50 000.实验2 用于证明YOLOv3-BigObject 网络结构有显著的提升效果,我们分别用YOLOv3 的网络结构和YOLOv3-BigObject 进行训练和测试,训练方式和实验1 相同,然后对比两者的训练与测试情况.实验3 用于验证算法的性能,检验增加类别后算法的鲁棒性,在数据集1 的基础上增加数据集2 作为该实验的数据集.
4.2 基于K-means 算法设计Anchor boxes 的实验结果
在实验1 中,用数据集1 进行实验,经过调节学习率、数据增强等步骤,我们设计的深度学习算法能够很好地识别极性电子元器件的类别与方向,如图10 所示,标签第1 个数字是表示种类,后面的数字表示方向.在Faster RCNN 算法中,我们用算法提供的9 个Anchor boxes 与K-means算法设计的Anchor boxes 进行实验对比,原Anchor boxes 与训练集的平均IoU 为0.7037,Faster RCNN (VGG-16)、Faster RCNN (ResNet101) 在测试集中的mAP 分别为93.77% 和97.05%.经过K-means 算法设计Anchor boxes 的大小与个数,所设计的6 个Anchor boxes 与训练集的平均IoU 为0.8577,Faster RCNN (VGG-16)、Faster RCNN(ResNet101) 在测试集中的mAP 分别为94.95%和97.36%,mAP 分别提高了1.18%、0.31%.在YOLOv3 算法中,用算法提供的9 个Anchor boxes进行训练,Anchor boxes 与训练集的平均IoU 为0.5728.在测试集中的mAP 为99.22%.经过Kmeans 算法选取Anchor boxes 的大小与个数,我们所选取的Anchor boxes 与训练集的平均IoU 为0.7362,最终在测试集中的mAP 为99.31%.图11和图12 分别是Faster RCNN 和YOLOv3 训练过程中损失函数(Loss) 的下降曲线.由上面的实验结果可知,经过K-means 算法对特定数据集提取Anchor boxes 的个数与大小在测试集上表现得更优异,两种算法都大大提高了与训练集的平均IoU.这样选取的方式使网络在学习Anchor boxes 回归时复杂度降低,进一步提高了检测的精度.在Faster RCNN中,经过K-means 算法选取的Anchor boxes 在训练时的Loss 的收敛速度与收敛效果比9 个Anchor boxes 表现得更好.

图10 测试集结果展示Fig.10 The display of test sets result

图11 Faster RCNN (ResNet101) 的Loss 曲线Fig.11 The loss curves of Faster RCNN (ResNet101)

图12 YOLOv3 和YOLOv3-BigObject 的Loss 曲线Fig.12 The loss curves of YOLOv3 and YOLOv3-BigObject
4.3 YOLOv3-BigOb ject 网络的实验结果
在实验2 中,用数据集1 进行实验,检验YOLOv3-BigObject 在极性元器件分类与方向识别的效果,通过对YOLOv3 和YOLOv3-BigObject网络结构的训练和测试,结果如表3 所示.在经过50 000 次迭代后,YOLOv3-BigObject 在测试集中的mAP 为99.44%.相比于YOLOv3 网络结构,mAP 提高0.13%,两者mAP 相近.但YOLOv3-BigObject 的检测速度几乎是YOLOv3 的一半.YOLOv3-BigObject 在训练过程的Loss 下降得比较缓慢,如图10,其主要原因是,预训练模型中每一层负责感知的特征已经学习形成,改变结构后,对目标物体的整体感知不全,相当于每层需重新学习感知对应的特征,这是Loss 下降缓慢的最主要原因.综上所述,YOLOv3-BigObject 网络结构在大目标检测上有与原来网络结构相当的准确率的基础上,将检测速度大约提高到原来的两倍.
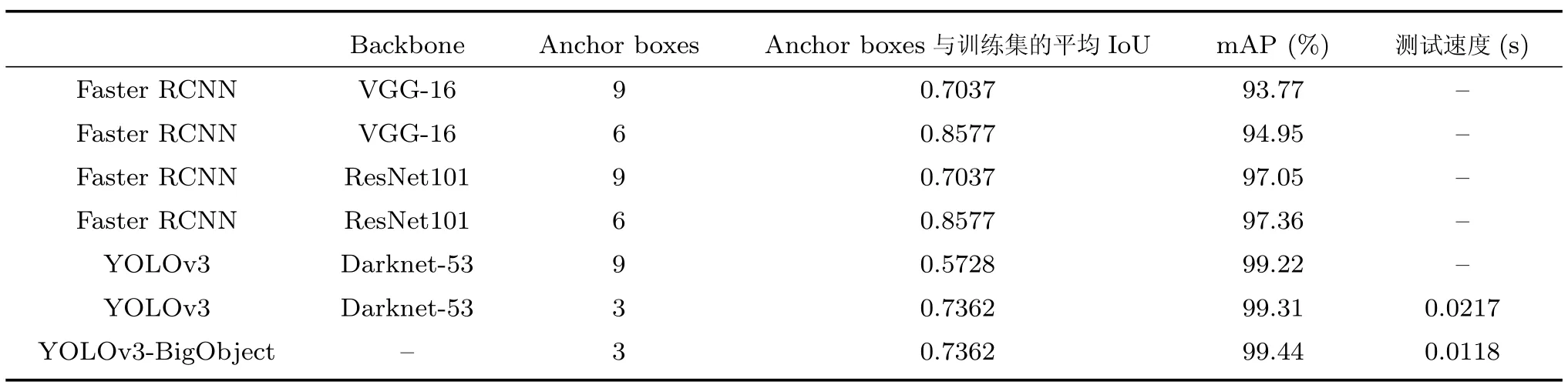
表3 数据集1 的实验结果Table 3 Experimental result of dataset 1
4.4 增加数据集的实验结果
我们在数据集1 的基础上,进一步增加了数据集2 对算法进行实验验证,实验结果如表4所示,结果显示运用K-means 算法设计Anchor boxes 后,Faster RCNN 与YOLOv3 的算法性能依然得到了一定程度的提升,而且实验效果比在FPN、SSD 等算法中表现得更好.在本实验中,YOLOv3-BigObject 的mAP 高达0.9920,证明了YOLOv3-BigObject 即使在增加种类后的情况下,也具有比较好的性能.为了进一步更好地检验算法的性能,我们选用了一个焊接有数据集1 和数据集2中的5 种型号的元器件电路板,但不是用来拍摄制作数据集的元器件对焊有元器件的电路板进行视频拍摄,并用YOLOv3-BigObject 生成的算法模型对视频进行检测,结果如图13 所示.实验结果显示我们的算法能够很好地检测出电路板上元器件的类别与方向,进一步证明了我们的算法具有很好的鲁棒性和实用性.

图13 视频检测结果Fig.13 Video experimental result

表4 数据集1 和数据集2 的实验结果Table 4 Experimental result of datasets 1 and 2
5 总结与展望
本文提出了一种基于深度学习的算法,实现了极性电子元器件的类别与方向检测.实验结果表明,我们所改进的深度学习算法在电子元器件的类别分类上比传统算法和卷积网络上表现得更好,而且还能进一步识别类别的方向.通过K-means 算法设计Anchor boxes 的方式提高了深度学习算法检测的准确率和速度.本文也对YOLOv3 网络结构进行了压缩改进,其在检测大目标提高准确率的同时,将检测时间几乎缩小到一半,进一步达到实时检测的效果,最后将算法模型运用到焊接有元器件的电路板上检测,得到很好的效果.本文所提出的方法在极性电子元器件类别、方向识别、定位、焊接和检测等方面也同样有很大的应用潜力.虽然本文在极性电子元器件目标检测与方向识别上能够得到很好的识别效果,但其仍然有很大的改进空间,主要有两个方面:一是类别增多问题,二是方向识别提升精度问题.在第一个方面,类别增多使分类更加复杂,未来可以进行如下展望:1) 建立更加庞大规范的数据集;2) 在达到算法模型能够高准确率分类的最大类别数时,对电路板进行划区域或划种类对模型进行训练.在第二个方面,如何进一步将方向识别的精度提升到具体多少度,可以考虑下面几个方面:1) 与其他回归方法结合的方式得到具体角度;2) 借鉴文本检测的思想,用带角度(如:与水平线夹角每转30◦为一个Anchor) 的Anchor 加上回归方法得到具体的角度;3) 用语义分割的方法识别出每个元器件的区域,再对元器件区域用传统图像处理的方法进行边缘检测等操作得到具体角度.
