基于KPLS鲁棒重构误差的高炉燃料比监测与异常识别
2021-08-28周平刘记平梁梦圆张瑞垚
周平 刘记平 梁梦圆 张瑞垚
高炉炼铁是钢铁生产制造流程的前端关键工序,其作用就是将固态的铁矿石通过复杂高温、高压等物理化学变化和多相多场耦合效应,在焦炭、煤气等作用下还原成液态铁水,为后续炼钢提供铁水原料.如图1 所示,一个典型高炉炼铁过程主要由高炉本体、上料系统、送风系统、喷吹系统、渣铁处理系统以及高炉烟气净化系统等组成[1−2].由于炼铁高炉内部在高温、高压条件下进行着复杂气-固、气-液、固-固、固-液等多相转换,众多变量和参数之间错综复杂和相互耦合,被公认为是最复杂的逆流反应器[3].高炉炼铁是典型的高能耗、低效率过程,其运行能耗约占钢铁生产总能耗的50%以上,生产成本占钢铁生产总成本的70%左右.因此.降低炼铁能耗对钢铁行业的节能减排、低成本可持续生产具有重要意义[1,4].图1 为高炉炼铁能耗示意图,其中焦炭和煤粉等燃料消耗约占高炉炼铁总能耗的80%左右,因此降低高炉燃料消耗是高炉炼铁节能降耗的重中之重[5].高炉燃料消耗影响因素众多,例如热风温度、富氧量等高炉操作变量和过程变量,都能直接或间接地影响高炉燃料消耗.高炉燃料比(即生产1 吨铁所消耗的焦炭、焦丁、煤粉等燃料量)作为反映高炉燃料消耗的最主要指标,对高炉操作人员执行高炉操作制度具有重要指导作用.随着节能减排,倡导绿色生产以及降低成本的需求日益迫切,对高炉节能减排的学术研究与工程实践也越来越多.文献[6−7]基于物流平衡与能量平衡原理建立高炉能耗模型,并从工艺角度进行节能分析与优化.文献[8−9]分别采用支持向量机、神经网络等智能建模技术建立了高炉能耗模型,实现了能耗的在线估计;文献[10−11]提出基于专家系统、神经网络的过程监测方法,并将其应用于高炉炼铁过程.但是这些方法没有对高炉能耗异常工况进行识别,因而不能提供减少能耗及其波动的操作指导,实际工程意义不大.另外,上述方法需要大量带有故障标签的数据去训练模型,而高炉实际运行中很难获取大量带标签的故障数据.因此,针对能耗异常先验知识少的高炉炼铁过程,需要研究如何利用高炉运行操作变量和状态变量数据与监测变量燃料比的关系,对高炉燃料比进行监测,并尽可能早地识别影响燃料比异常波动的关键因素及其低能耗调节的有效方法,这对高炉炼铁过程的节能降耗具有重要意义.随着现代工业生产的大规模和复杂化,工业过程的安全监测、故障诊断与识别成为工业用户关注的重要问题.近年来,随着新型传感技术与计算机技术的快速发展和广泛应用,使得工业生产能够获得比以往更多的生产过程运行数据.因此,如何从海量数据中进行有效数据挖掘,使其服务于生产安全监测与诊断,成为现代工业工程的热点问题.文献[12−13]利用系统在正常和故障情况下的历史数据训练神经网络或者支持向量机等机器学习算法用于故障诊断,但诊断精度与故障样本的完备性和代表性有很大关系,因此难以用于无法获得大量故障数据的复杂工业过程.文献[14]针对线性相异分析在监测非线性过程时存在的不足,引入一个核相异指数来定量评价非线性数据分布结构之间的差异,从而反映非线性过程的相关性和操作条件的变化,取得较好的非线性过程监测效果.类似方法还有基于主成分分析(Principal component analysis,PCA)的监测方法,不同是的PCA 通过降维方式提取高维变量数据的主要信息,从而对过程运行状况与故障进行分析.作为数据驱动多变量统计过程监测(Multivariate statistical process monitoring,MSPM)的主流技术[15−17],偏最小二乘(Partial least squares,PLS)监测方法更注重过程变量与监测变量(如高炉炼铁过程燃料比)之间的关联关系以及影响监测变量的故障或异常工况[18−20].PLS 的主要优点是可以建立过程变量与监测变量之间的关系模型,能够有效解决多变量系统的相关性、数据样本和故障先验知识少的问题.然而,常规PLS 是线性降维投影方法,很难捕捉生产过程的非线性特性[21].为解决该问题,可通过两种方法来对常规线性PLS进行扩展,其一是调整PLS 内部模型,其二是调整PLS 外部模型.如Wold 和Qin 等[22−23]分别基于二次函数和神经网络模型建立PLS 的非线性内模型,即过程变量得分主元和监测变量得分主元之间的非线性模型,从而解释生产过程的非线性关系;Rosipal 和Baffi 等[21,24]分别利用核函数和带有权重更新的神经网络模型建立PLS 的非线性外模型,即通过将过程输入变量变换到高维空间,并在此空间执行线性PLS 算法,从而实现非线性过程监测.基于核函数的PLS 又称为核函数潜投影结构(KPLS),与其他非线性PLS 方法相比,KPLS 的优点在于可以避免非线性优化,因而成为较为流行的过程监测与诊断方法.但是,基于KPLS 的过程诊断方法在很多情况下难以找到特征空间到原始过程变量空间的逆映射函数,从而增加了故障识别的难度[25].为此,Cho 和Shao 等[20,26]通过计算当前时刻变量对统计量的一阶偏导数值来确定故障变量,并认为异常时刻有最大偏导数的过程变量为故障变量.但是这种方法难以适用于KPLS,因为基于核的非线性映射是不可微函数,并且在很多情况下不是显式的形式.针对基于核函数的非线性过程故障识别问题,文献[27−28]提出一种基于重构误差的故障指标,即利用两种平方误差的比值,一种是SPE(Squared prediction error)即Q 统计量,另一种是基于变量相关性,用其他变量去估计过程变量中的一个,并用此变量的估值和剩余变量来计算Q 统计量.这种方法的核心思想是当重构的变量是故障变量时,此变量的故障指标会比非故障变量的指标值偏小.目前,该方法在连续搅拌釜式反应器(Continuous stirred tank reactor,CSTR)的模拟实验中获得较好的诊断效果[25].本文针对先验故障知识少的非线性高炉炼铁过程燃料比监测和故障识别问题,基于文献[27−28]的思想,提出一种基于KPLS 鲁棒重构误差的新型故障识别方法.该方法通过分析Gram矩阵和高维特征空间映射矩阵的关系,重构原始过程变量,以原始过程变量的重构误差构造故障识别指标并给出指标控制限.同时,所提方法引入迭代去噪算法以减少异常数据对原始空间正常估值的影响,从而增强算法的鲁棒性.数值仿真及基于实际高炉实际数据的工业试验表明所提方法能够准确识别引起高炉燃料比异常变化的影响因素,从而给出高炉的调节方向,指导高炉操作人员调节高炉操作制度,使高炉在顺行的前提下,朝着降低能耗的方向运行.此外,基于KPLS 鲁棒重构误差的新型故障识别方法不仅可以监测出正常工况下影响燃料比异常变化的潜在影响因素,还可以监测出异常工况下影响燃料比异常变化的关键因素.
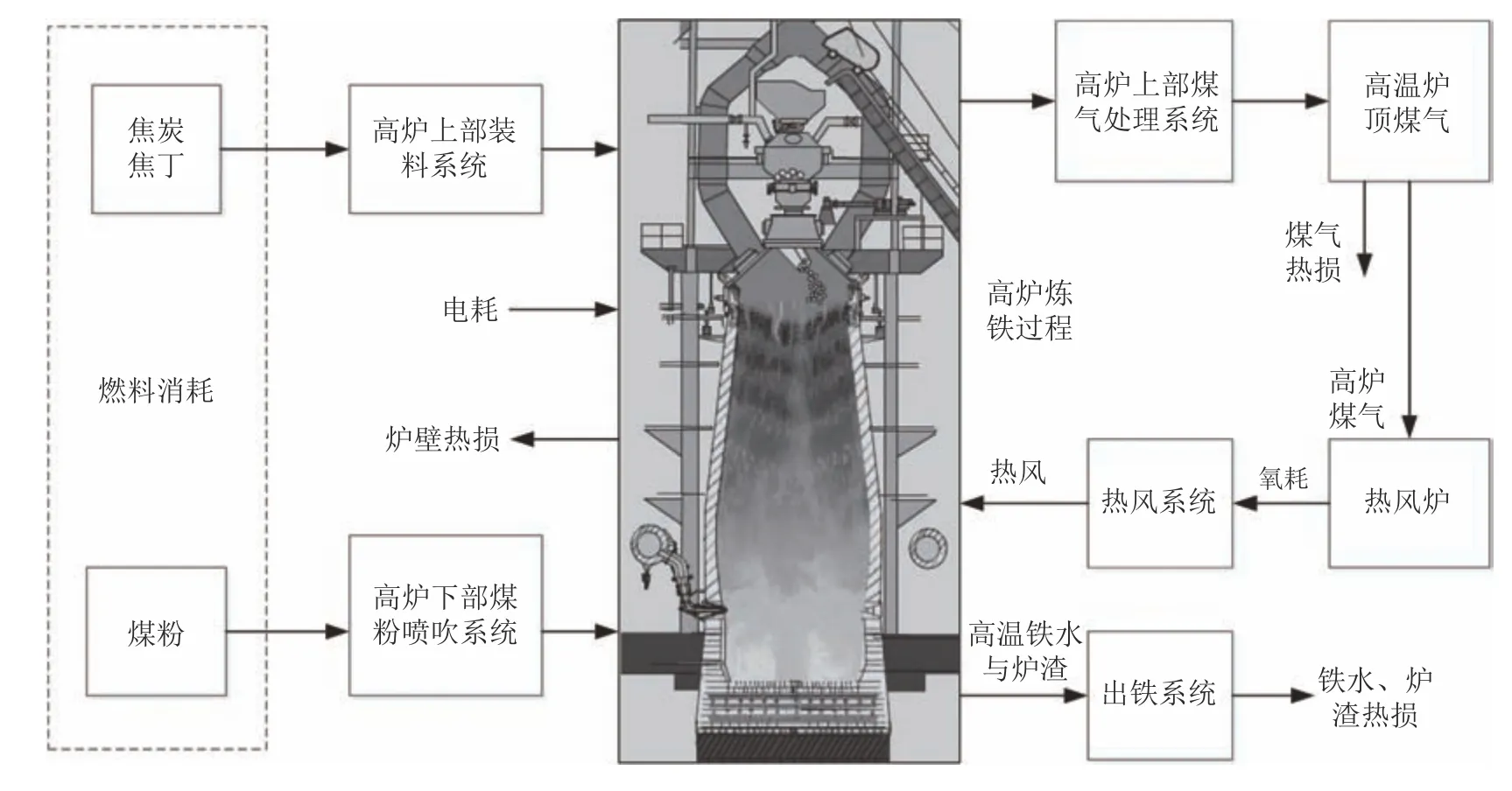
图1 高炉炼铁过程能耗示意图Fig.1 Schematic diagram of energy consumption in blast furnace ironmaking process
1 基于KPLS 的非线性过程监测方法
由于基本PLS 是一个线性降维投影方法,无法描述过程的非线性特性,Dunia 等[27]提出利用核函数将原始数据投影到高维空间,并在高维空间运行PLS 算法,以此来描述过程的非线性.其基本思想是:如果核函数满足Mercer 条件[27],则KPLS 只需利用核技术在原始过程数据空间进行点积运算,不需要具体的非线性映射函数,即可实现非线性PLS.
设非线性系统的过程变量为X[x1,x2,···,x n]T∈Rn×m,待监测变量(如质量变量)为Y[y1,y2,···,y n]T∈Rn×p,其中n为数据数,m为过程变量数,p为质量变量数.定义ϕ为非线性映射,用于将过程变量从原始空间映射到特征空间F.KPLS利用核函数将原始输入数据映射到特征空间F:x →ϕ(x)∈F,并在特征空间执行线性PLS 算法.设映射矩阵Φ[ϕ(x1),ϕ(x2),···,ϕ(x n)]T∈Rn×f,为简化计算,令即输入变量映射到特征空间的均值为零.定义Gram 矩阵KΦΦT∈Rn×n,K ijk(x i,x j)〈ϕ(x i),ϕ(x j)〉,通过核映射和内积运算,即ϕ(x i)Tϕ(x j)k(x i,x j),避免计算原始输入空间到特征空间的非线性映射矩阵 Φ,直接得到Gram 矩阵K. 另外,基于非线性迭代的KPLS 可以避免求解Gram 矩阵的特征值,通过迭代的方式直接求得Gram 矩阵的特征向量和得分向量[29].
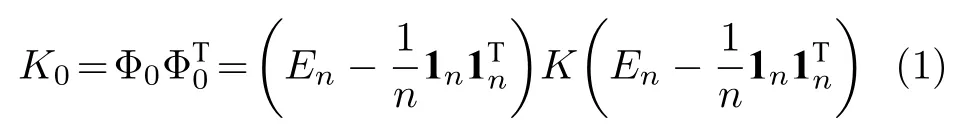
式中,K0为中心化后的K,E n为n×n的单位矩阵.对于新数据∈Rm,k1,···,N,对应映射向量为,当采样数为N时,对应特征向量为Φnew,从而对Φnew中心化得其中 Φmean为训练集特征矩阵的均值[27],1N为N维全1 列向量,为中心化后的新样本特征向量,新样本的Gram 矩阵Knew中心化可按下式计算:
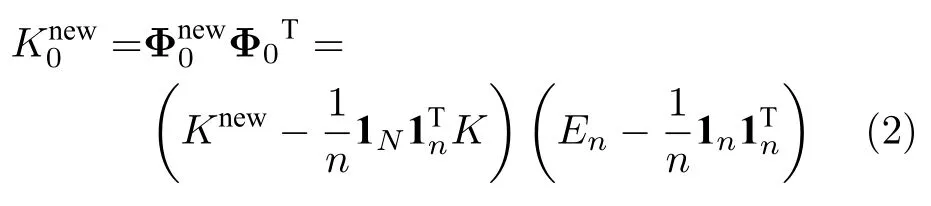
在高维特征空间,KPLS 模型如下所示:
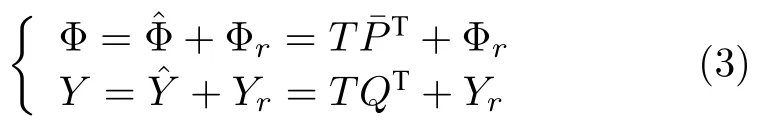
引入核技术,上述模型可变换成如下形式:
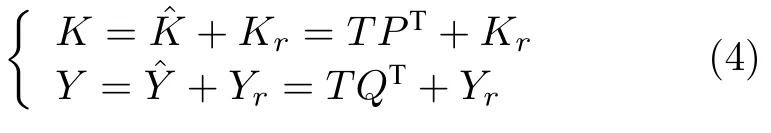
基于KPLS 算法的统计量和SPE 统计量计算公式如下所示:

式中,A为KPLS 主元个数,可由交叉验证方法得到,tnew为新采样数据分向量,计算公式为:
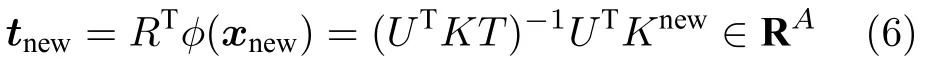
式中,RΦTU(TTK U)−1,TΦR,Λ−1(1/n−1)TTT,T为KPLS 训练集得分矩阵.
则SPE 统计量可按如下公式计算:

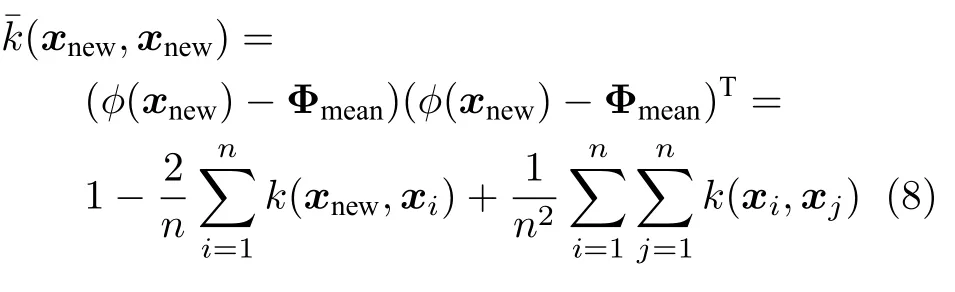
式中,xi,x j为训练集数据.
2 基于KPLS 鲁棒重构误差的故障识别方法
燃料比异常时,需要识别过程变量中造成燃料比异常的关键变量,从而指导操作人员有针对性的调整高炉操作制度,减少异常工况造成的损失.基于KPLS 的故障识别是非线性过程监测中的一个难题,至今还没有一个确定的理论体系对非线性故障变量进行识别.基于PLS 的质量监测可以通过贡献图的方法对故障进行识别[30],即对统计量或SPE统计量的贡献值较大的变量为故障变量.而基于核函数的非线性过程监测通过非线性映射改变原始过程变量之间的相关关系,在很多情况下很难找到特征空间到原始过程变量空间的逆映射函数[18,31],加大了非线性故障识别的难度.针对这些问题,Sang等[28]提出基于KPCA(Kernel principal component analysis)误差重构的故障识别方法,并在连续搅拌釜反应器进行仿真实验验证,取得较好效果.本文针对基于KPLS 的非线性质量监测故障识别难题,将鲁棒重构误差计算方法应用于基于KPLS的故障识别,提出基于KPLS 鲁棒重构误差的非线性系统故障识别方法,具体如下:
2.1 故障识别算法
鲁棒重构误差估计方法是迭代去噪估计的扩展[32−33].基于KPLS 的鲁棒重构误差方法首先建立过程的KPLS 模型,并在原始输入空间而不是特征空间重构输入变量,输入变量的重构值为正常时刻的估计值.设X[x1,x2,···,x m]T∈Rm×n为过程变量训练集,Y[y1,y2,···,yp]T∈Rp×n为监测(质量)变量,m,p分别为过程变量个数和质量变量个数.KPLS 首先通过非线性函数将数据映射到特征空间F:x →ϕ(x)∈F,然后建立特征与质量变量的PLS 监测模型.定义特征空间数据矩阵为Φ(X)ΦT[ϕ(x1),ϕ(x2),···,ϕ(x n)]∈Rf×n,且0,则过程变量在特征空间的方差矩阵C以及Gram矩阵K可表示成:
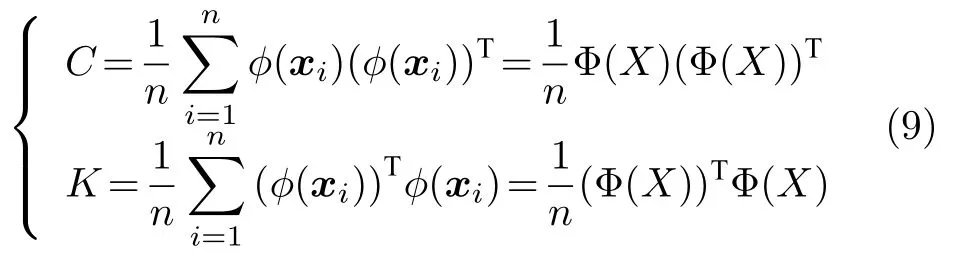
式中,K i,j〈ϕ(x i)·ϕ(x j)〉k(x i,x j)exp(−norm(x i−x j)2/c).对Gram 矩阵进行特征分解得:

式中,P[p1,p2,···,p A]∈Rn×A为K的特征向量,λi为对应特征值,A为KPLS 的主元个数,对上式两边同时乘以 Φ(X) 则有下式成立:

设V[v1,v2,···,v A]∈Rm×A为过程变量的方差矩阵C的特征向量矩阵,则下式成立:

设新观测到的过程数据为xnew∈Rm,在高维特征空间的非线性映射值为ϕ(xnew) ,则ϕ(xnew) 在V坐标系上的得分向量为:

式中,knew为新观测的数据在高维特征空间的Gram矩阵.
注 1.此处得分向量h与前文得分向量t不同,得分向量h是由新观测数据的高维映射ϕ(xnew) 在V坐标系上投影得到,表示投影关系;得分向量t是由新观测数据的高维映射ϕ(xnew) 根据KPLS 模型求得的主元.
由于ϕ(xnew) 的估计值,设存在投影矩阵PH使得PHϕ(xnew)成立,为了能够在原始数据空间识别故障变量,需要在原始过程变量空间而不是在特征空间重构数据.如存在向量z ∈Rm满足ϕ(z)P Hϕ(xnew),则可将z作为xnew的一组重构数据.因此重构xnew可转化为求解如下优化问题:
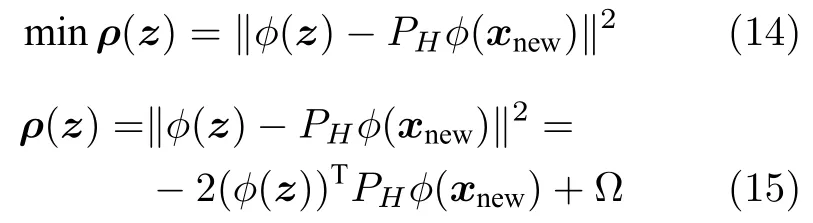
式中,Ω 为确定常数项,又因为P Hϕ(xnew)V hT,VΦ(X)P,则上述优化问题转化为:
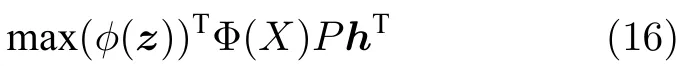
即
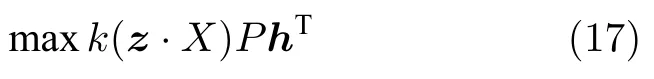
应用梯度下降求解上述优化问题
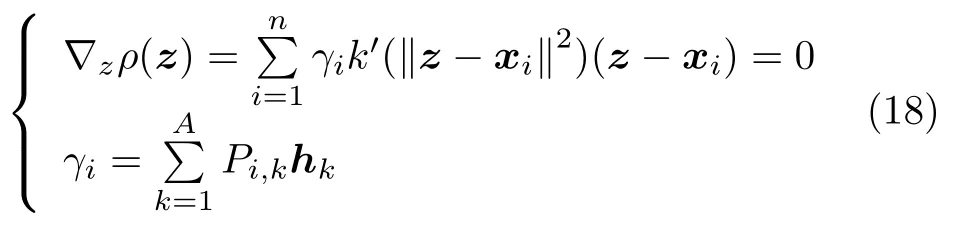
对于高斯核函数k(x·y)exp(−‖x −y‖2/c),所得最优解为

为了简化计算,采用迭代方式[32]求解z:
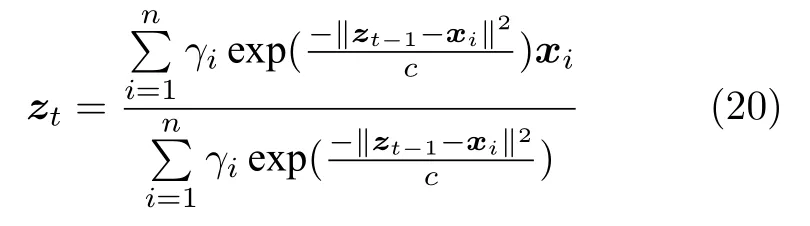
由于主元变量对过程变量中的异常值敏感,会影响对过程数据重构值的精度,针对此问题,进一步采用Takahashi 提出的改进鲁棒重构方法[33],即在更新重构值的同时更新得分向量h:
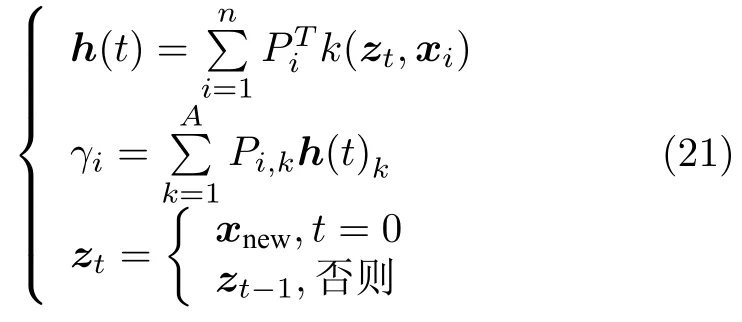
为了解决迭代不收敛问题,设xnew,i,i1,2,···,m为新观测数据的第i个变量,定义数据的确定性指标为βi ∈R,i1,2,···,m以及数据确定性指标矩阵为B(t)diag{β1,β2,···,βm}∈Rm×m. 采用新观测数据和重构数据的差值来估计数据的确定性:当差值较大时,认为新观测数据是正常数据的可能性小,因此减少此数据的确定性βi;当差值较小时,认为新观测的数据是正常数据的可能性大,并以此来修改第次迭代的观测数据重构值,使原始观测数据在下一时刻重构值中占比较大,从而减少迭代次数,使迭代估计尽快收敛.当t>0 时,重构数据的迭代可由下式替代:
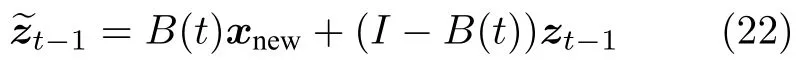
式中,I是维数为m×m的单位矩阵.这里,前述定义的数据确定性指标可按下式计算:
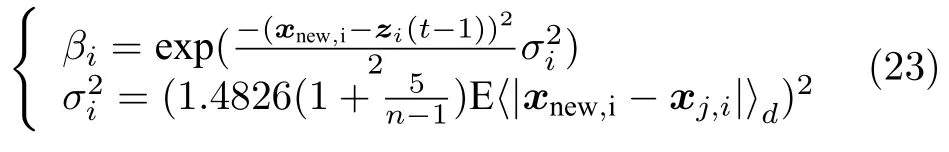
式中,E〈|xnew,i−x j,i|〉d表示前d个新观测数据与训练数据差值最小值的均值,i1,2,···,m,j1,2,···,n.因此原始数据t次迭代重构值可按下式计算:

最后,所提基于KPLS 鲁棒重构误差的故障识别算法实现步骤总结如下所示:
步骤 1.给定重构数据的初值z0xnew;
步骤 2.根据式(23)计算数据的确定性矩阵βi;
步骤 3.根据式(22)修改上次迭代重构值
步骤 4.根据式(21)更新观测数据得分向量h及γi;
步骤 5.根据式(24)计算当次迭代重构值z t;
步骤 6.若‖z t −z t−1‖<10−5,则输出新观测数据的重构值,反之令zt−1z t,返回步骤2.
2.2 故障识别指标
利用KPLS 鲁棒重构误差识别算法得出的变量正常估值与真值的误差,同时考虑识别算法对不同变量估值精度来构造故障识别指标,如下所示:

式中,Xi表示第i个变量的所有采样数据,为第i个变量的鲁棒重构估计值,x i为第i个变量新的采样值,表示相应的重构估计值.
由于不同变量的估计精度不一样,因此为了统一误差贡献值,需要对每个变量的故障指标值进行归一化处理.当第i个变量发生故障时,故障指标值会大幅度增加,未发生故障的指标值不会增加太多.从而只需比较所有变量的指标值的大小就可以识别出异常变量.式(25)所示故障识别指标的本质是原始特征变量的重构误差,与SPE 统计量类似,因此故障识别指标的控制上限可按下式计算:

式中,g2s/(2µ),h22µ2/s,µ为的均值,s为的方差,α为控制限的置信水平.在实际工业过程中,可以用训练数据集中所有变量的故障识别指标和均值加3 倍方差的均值计算该控制限.
3 数值仿真
为了验证所提方法,首先进行数值仿真.为此,考虑文献[34]研究的非线性系统,该系统包括18个输入变量X[x1,x2,···,x m]∈Rn×m,m18和1 个输出变量.输入变量中,[x1,x2,···,x10]∼U(−1,1),x1,x2,x3与输出变量呈非线性关系,x4,x5与输出变量呈线性关系,x6,x7,x8,x9,x10是独立于输出变量的噪声变量,另外增加4 个与x1,x2,x3,x4呈线性关联的变量x11,x12,x13,x14,两个呈现非线性关联的变量x15,x16,以及与独立噪声变量呈非线性关系的变量x17,x18. 因此,输入变量可分为两类,一类是与输出变量相关的,另一类是看作不同来源的噪声e,这里e∼N(0,0.1) .综上该系统可用下式表示:数值仿真时,首先产生200 组数据作为正常的训练样本,之后产生400 组数据作为测试样本,在测试样本中前200 组数据为正常样本,从201 个样本开始加入如下三类故障:

故障 1.对变量3 加入幅值为 0.5(k −200) 的漂移变化,即
故障2.对变量4 加入幅值为5 的阶跃扰动,即
故障 3.对变量4 和15 分别加入幅值为8 和5的阶跃扰动,即和,对变量14和17 分别加入幅值为0.1和0.05且故障时刻为200 到300 采样点的漂移变化,即x14和
故障1和故障2用于验证故障识别方法对不同类型故障的识别能力,故障3 用于验证本文所提故障方法对多变量故障的识别能力.
数据仿真时,参数设置如下:高斯核函数宽度设置为165,交叉验证选取主元个数为5.T2统计量根据Mahalanobis 距离定义,能够对KPLS 得分进行监测,SPE 统计量由欧几里得距离定义,对KPLS 残差进行监控.一般来说,只有当T2统计量和SPE 统计量都处于控制限以下时表示过程正常运行,当T2统计量或SPE 统计量至少有一个在控制限以上时表示过程发生异常.针对上述3 类故障,所提方法KPLS 监测效果如图2、4、6 所示,可以看出故障发生时所提方法能够及时有效地监测出上述3 类故障.图3、5、7 显示了所提故障方法在两种故障指标下均能有效识别故障,即系统运行正常时,每个过程变量的故障指标均在控制限以下.而当故障发生时,所提方法能够快速显示故障源所在,说明基于所提鲁棒重构误差的故障识别方法能够有效识别出系统中不同类型的故障以及多变量故障.
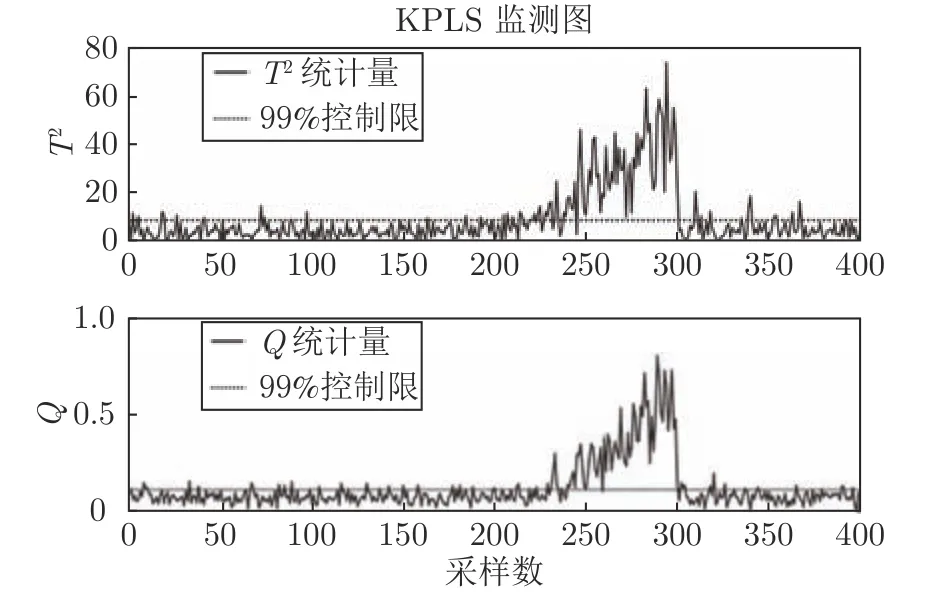
图2 故障1 的KPLS 监测图Fig.2 KPLSmonitoring chart for fault 1
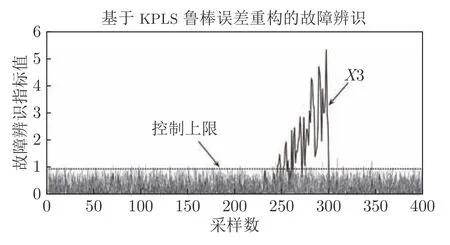
图3 故障1 的故障变量识别图Fig.3 Fault variable identification map of fault 1
4 工业数据验证
4.1 高炉燃料比监测效果
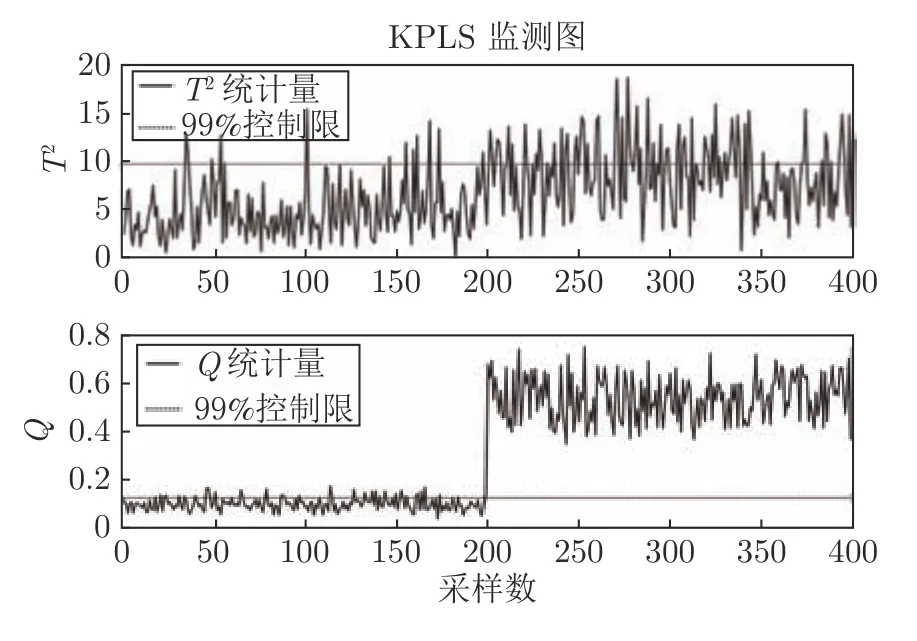
图4 故障2 的KPLS 监测图Fig.4 KPLSmonitoring chart for fault 2
选取柳钢有效容积为2 650 m3的2 号高炉的实际工业运行数据对所提方法进行数据测试.根据工艺机理,确定影响燃料比的主要过程变量包括矿批、焦批、焦丁等高炉上部调剂变量,冷/热风流量、富氧量、设定喷煤等高炉下部调剂变量,另外还有顶压、压差、理论燃烧温度、炉腹煤气量等计算或测量变量.由于过程变量为37 个,根据经验原则,选取高斯核函数宽度为185,通过交叉验证KPLS 主元个数为8.

图5 故障2 的故障变量识别图Fig.5 Fault variable identification map of fault 2

图6 故障3 的KPLS 监测图Fig.6 KPLS monitoring chart for fault 3
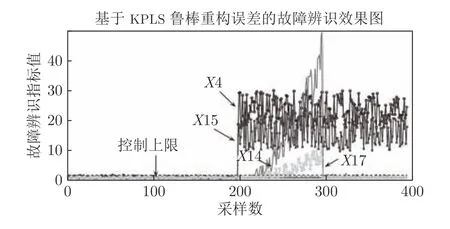
图7 故障3 的故障变量识别图Fig.7 Fault variable identification map of fault 3
图8 为基于实际工业数据的高炉燃料比监测曲线,图中可以看出T2统计量监测曲线共出现5 次报警,其中第1 次报警为鼓风湿度波动异常,第2 次报警与第4 次报警均为休风检修,第3 次报警为休风下料,第5 次报警为管道行程异常工况.高炉燃料比监测重要意义是用于及时发现和识别过程中引起燃料比异常波动的潜在故障源.通常,初步监测与识别的故障源不一定会影响高炉顺行和燃料比,例如图8 和图9 监测的第一次报警.可以发现,第一次报警出现时,燃料比的休哈顿控制曲线仅仅在30 和50 时刻显示异常,因而图8 高炉燃料比监测报警实际上并未引起燃料比的异常波动.详细原因还需做进一步的故障识别分析,即下节内容.

图8 高炉燃料比监测曲线Fig.8 Blast furnace fuel ratio monitoring curve

图9 高炉燃料比休哈顿图及残差图Fig.9 Blast furnace fuel ratio Hughton diagram and residual map
4.2 基于KPLS 鲁棒重构误差的燃料比异常识别效果
图8 和图9 所示高炉燃料比第一次异常报警时燃料比参数仍然在休哈顿控制图的正常范围内,为此进一步利用KPLS 鲁棒重构误差识别算法进行异常识别,结果如图10 所示.图10 上部是故障指标1 识别结果而图10 下部是故障指标分解图.为了说明问题,图10 下部分解图包含全部异常变量和部分正常变量,并给出变量的分组.可以看出,所提识别算法给出并给出变量的分组.可以看出,所提识别算法给出的异常变量为鼓风湿度.通过查阅交班记录及相关数据可知,1~50 采样时刻所对应的时间段,炼铁现场大气湿度波动大即鼓风湿度异常,因此所提方法能够正确识别故障源.鼓风湿度的波动会影响风口理论燃烧温度,即燃料燃烧的火焰温度.通常,鼓风湿度变化10 g/m3时,会引起风口理论燃烧温度60~70◦C 的变化以及吨铁炉腹煤气量1%的变化,从而影响炉缸热状态以及煤气初始分布.由于水蒸气分解时需要消耗热量,在相同情况下,鼓风湿度的增加会显著增加燃料消耗.因此,根据图11 所示高炉操作变量对高炉工况影响的传播作用流程,在鼓风湿度异常时,为了稳定炉况以及低燃料比运行,应当适当调节风温、喷煤、富氧等参数.另外,从图10 所示燃料比异常识别曲线可以看出,理论燃烧温度、炉腹煤气量、炉腹煤气指数仍然处于正常范围内.结合交班记录可知,鼓风湿度异常时,及时调节风温、富氧、喷煤等操作变量,使得燃料比恢复正常.这从图9 燃料比的休哈顿和残差图也可看出燃料比未发生异常.因此,在炉况波动时,由于操作人员的及时调整,并未破坏高炉顺行,因此说所提方法可以监测出正常工况下影响燃料比异常变化的潜在影响因素.图8 和图9 监测的管道行程异常工况会直接影响高炉燃料比指标.通常,管道发生时必须先稳定炉况,并在炉况顺行的前提下,通过燃料比监测结果来调控高炉以达到稳定燃料比的目的.此外,由于高炉燃料比与高炉透气性等相关运行性能指标以及风温、富氧等操作变量具有重要关系,是高炉运行状况的一个量化描述,能够表示高炉运行的健康状态,因此高炉燃料比监测不仅能够监测燃料比,也能间接地反映高炉的运行状况.表1 为部分高炉过程变量故障识别控制限减去故障识别值的差,当差为负时表明过程变量为异常.从表1 和图12 的故障识别数据与图可以看出:在管道异常工况出现前,高炉顶压风量比首先出现异常,随后高炉透气性、鼓风动能、炉腹煤气量以及炉腹煤气指数都出现较大波动且部分时刻超出正常控制限,之后高炉上下部调节参数中的块矿、烧结比、冷风流量、设定喷煤量也出现较大波动.根据高炉交班记录可知,由于顶压风量的设置不当,高炉透气性、阻力系数等关键运行性能指标波动较大,而之后的高炉上下部调节参数波动幅度较大,使得高炉炉温波动异常,进而使得高炉燃料比出现较大波动.由此可知,所提基于KPLS 鲁棒重构误差的高炉燃料比监测不仅可以监测出正常工况下影响燃料比异常变化的潜在影响因素,还可以监测出异常工况下影响燃料比异常变化的关键因素.

图10 鼓风湿度异常时高炉燃料比异常识别曲线Fig.10 Blast furnace fuel ratio anomaly identification curve when blast humidity is abnormal

图11 高炉操作调节关联图Fig.11 Association diagram of blast furnace operation adjustment

图12 管道行程异常工况时高炉燃料比异常识别曲线Fig.12 Abnormal identification curve of blast furnace fuel ratio in abnormal pipeline condition

表1 部分过程变量控制限与故障指标值的差值Table 1 The value of the control limit is reduced to the value of the fault index for part process variables.
5 结论
为了解决先验故障知识少的高炉炼铁过程燃料比非线性监测与异常识别难题,本文将鲁棒重构误差计算方法应用于基于KPLS 的故障识别,提出基于KPLS 鲁棒重构误差的非线性系统故障识别方法.该识别方法首先建立待监测变量与过程变量的KPLS 模型,然后利用从数据中提取负载向量并采用鲁棒去噪算法估计原始过程变量的正常值.该算法不仅可以给出故障变量,还可以估计出故障变量的正常值,提高识别准确度.当故障变量为操作变量时,可以依照故障变量的估计值以及相应操作制度来进行故障(异常)修正和过程操作调整.具有不同类型故障的数值仿真验证了所提算法的有效性.最后,基于实际工业数据的高炉燃料比监测与异常识别表明:所提方法可以有效监测高炉燃料比参数,并正确识别影响燃料比异常变化的关键因素,是一种非常有效的非线性过程的在线监测与异常识别.但是,由于所提方法在判断异常时需要确定置信度,该置信度目前只能凭经验来确定,因而具有一定的主观性.
