基于改进差分进化和回声状态网络的时间序列预测研究
2021-08-28许美玲王依雯
许美玲 王依雯
时间序列广泛存在于人类社会生活的方方面面,比如经济领域的生产总值、商品的销售量、股票的增长幅度等[1];天气领域中城市的降雨量、平均气温等[2−3];社会领域中城市交通流量、外来人口迁徙量及汽车能量消耗值等[4];工业领域中高炉炼铁的中心温度[5]、钢铁企业能源预测[6]和原油物性预测[7]等.
随着人工智能研究的不断发展,人工神经网络、支持向量机[8]等机器学习方法逐渐成为非线性时间序列建模和预测的主要工具.但是传统的人工神经网络如BP(Back propagation)神经网络[9]存在训练算法复杂、网络结构难以确定、易陷入局部最优和收敛速度慢等问题.支持向量机模型若训练样本过大,存在训练时间过长且效果不佳的问题.极限学习机(Extreme learning machine,ELM)[10]是针对单层前馈神经网络设计的新型学习算法,学习速度快,泛化性能好,但其静态前馈结构不适用于动态时间序列的建模.随着学者们的不断研究,发现回声状态网络(Echo state network,ESN)[11]在时间序列预测方面存在一定的优势,其训练算法简单,计算快速,且能保证解的全局最优性.虽然回声状态网络具有以上优点,但是也存在一些问题,例如储备池的适应性问题、稳定性问题及病态解的出现会影响网络的泛化能力,容易产生过拟合等.
近年来,众多学者们针对回声状态网络存在的问题进行一些改进.文献[12]提出一种基于L1 范数正则化的改进回声状态网络,将L1 范数作为惩罚项,防止模型出现过拟合现象,提高模型的稳定性.文献[13]利用改进的小世界网络优化泄露积分型回声状态网络,有效地改进了储备池神经元的连接方式,减少了稀疏连接的随机性,提高了储备池的适应性.文献[14]提出拉普拉斯回声状态网络解决了由于实际训练样本的数量小于隐藏层节点数存在的不适定问题并获得低维的输出权重.文献[15]提出一种鲁棒回声状态网络预测模型,采用更具鲁棒性的拉普拉斯分布代替高斯分布对数据的噪声进行描述,消除了异常点对模型泛化能力的影响.文献[16] 结合回声状态网络和Kalman 滤波,利用Kalman 滤波直接对网络的输出权值进行在线更新,扩展了算法的适用范围,提高预测精度.文献[17]利用遗传算法直接优化ESN,实现自适应非线性动力系统的控制.文献[18]采用人工鱼群算法优化回声状态网络,满足了聚氯乙烯聚合过程的实时控制要求.文献[19]利用粒子群优化算法对ESN 中未经训练的权重进行优化,提高网络的预测性能.
虽然已有学者采用智能优化方法优化回声状态网络参数,但由于回声状态网络的储备池包含节点较多、搜索空间较大,优化效果还有待改善.遗传算法(Genetic algorithm,GA)[17,20]通过模拟自然进化过程搜索最优解,但容易过早收敛,存在早熟现象.粒子群算法(Particle swarm optimization,PSO)[21]的鲁棒性较差而且容易陷入局部最优解,参数的初始化对粒子群算法的性能影响较大.蚁群算法(Ant colony optimization)[22]尽管具有较强的鲁棒性,但是有明显的经验性,收敛慢,对实际问题适用性不强.人工鱼群算法(Artificial fish,AF)[23]虽然不易陷入局部最优,但不适合同时优化不同范围或者范围相差较大的参数,而且人工鱼群算法本身较为复杂,效率低.研究中发现差分进化算法[24]简单,具有较强的全局搜索能力,寻优速度快,且能平衡局部及全局的信息来进行搜索,更具实用性,鲁棒性.教与学优化算法(Teaching-learning-based optimization,TLBO)[25]原理简单、易实现,需要调优的参数极少,且计算效率比传统的方法计算效率高.该算法自提出以来,已被广泛用于函数优化、神经网络优化、工程优化等领域.然而,每种算法都不是万能的,教与学优化算法也存在早熟收敛现象.综上,本文选用全局性较强的差分进化算法.
为使差分算法可以更加准确地找到最优解及适用性更强.本文提出一种改进的差分算法,一方面对缩放因子(Scale factor,F)和交叉概率(Cross rate,CR)采用自适应,另一方面对变异策略采用自适应.综上所述,本文利用改进的差分进化算法来优化回声状态网络中储备池的4 个重要参数,对每个个体都分配一个适合的F、CR和变异策略,使个体变异更加趋向于适应度好的个体,从而加快该算法的收敛速度,更准确地找到最优解,提高预测精度.
1 回声状态网络
Jaeger 等[11,26]提出的回声状态网络(Echo state network,ESN)是一种简化的递归神经网络,用稀疏连接的储备池代替全连接的隐含层,增强了对动态系统的建模能力,避免一般神经网络基于梯度下降原理的收敛速度慢、易陷入局部最优的问题.
1.1 ESN 基本原理
如图1 所示,回声状态网络是一种三层递归神经网络,由输入层、隐含层和输出层三部分组成,隐含层又称储备池,含有成百上千个稀疏递归连接的神经元,神经元之间的连接权值随机生成且固定不变.

图1 ESN 结构示意图Fig.1 Structure of ESN
ESN 的状态方程和输出方程如下:

式中,u(t)∈RM×1是M元输入向量,y(t)∈RM×1是M元输出向量,bx ∈RN×1为输入偏置,b ∈RM×1为输出偏置.由当前时刻t的输入u(t) 和前一时刻t−1 的储备池内部状态x(t −1) 通过激活函数的映射得到当前时刻的状态x(t)∈RN×1.φ(·)为神经元的激活函数,可以选取Sigmod 函数或者tanh 函数.输入连接矩阵Win ∈RN×M的元素在区间[−1,1]取值.Wx ∈RN×N为储备池内部连接矩阵,稀疏连接.通过伪逆求得输出连接矩阵w ∈RN×M.输入连接矩阵Win和内部的连接矩阵W x随机生成,且在回声状态网络的训练阶段始终保持不变.网络只需求输出连接矩阵w,因此降低了计算复杂度.
1.2 网络关键参数
回声状态网络的核心是储备池,储备池性能的好坏取决于4 个重要的参数:储备池规模N、储备池的谱半径R、稀疏度D以及输入变换因子S,如何选取这4 个参数至关重要.下面介绍储备池的参数选择对模型性能的影响.
1)储备池规模
储备池的规模N即为储备池中神经元数目,是影响ESN 预测性能最重要的参数.N的值过大,造成过拟合;N的值过小,造成欠拟合.
2)储备池的谱半径
谱半径R为内部连接矩阵Wx的最大特征值的绝对值.R的取值范围一般为[0,1]之间,但对于不同的时间序列其取值将视情况而定.
3)稀疏度
储备池内部神经元连接的稀疏程度称为稀疏度D.储备池的神经元之间不是全连接,而是少部分连接.具体实现方法是使储备池的连接权值W x中的大多数元素等于零.Jaeger 等认为稀疏度D ∈[0,0.1]即可保证储备池具有足够的动力特性.
4)输入变换因子
输入变换因子S是指在信号输入储备池前缩放的比例因子,表征输入连接权值的取值范围.根据式(1)可知,其大小决定激活函数的工作区间,也决定了输入对储备池的状态变量作用的强度.其取值范围通常在[0,1]之间.
回声状态网络参数的选择往往会针对数据的不同特性而变化,因此如何选择适合不同数据的储备池参数是本文研究的重点.本文采用差分进化算法来自动选择适合当前数据的储备池的参数,提高网络的预测性能.
2 改进差分进化算法
差分进化算法(Differential evolution,DE)是基于群体智能的优化算法[24].由于算法简单易于实现、鲁棒性好、搜索能力强等优点被广泛应用于电力、炼油、工业及科学研究等领域[27−28].
2.1 差分进化算法
一般来说,常常选用差分进化算法解决模型参数优化问题.标准的差分进化算法包括4 个操作:初始化、变异、交叉和选择.下面介绍这4 个操作的具体实现.
1)随机初始化个体数量为NP,迭代次数为G的一个种群,记X(X1,G,X2,G,···,X i,G,···,X NP,G),其中Q为待优化问题的维数,初始化公式:

Xmax和Xmin分别为种群个体范围的上限和下限,rand(⋅)函数表示生成范围在(0,1)之间的随机数.
2)变异操作则是利用变异策略来产生新的个体,有利于后代进行搜索以便找到最好的解.变异策略有:
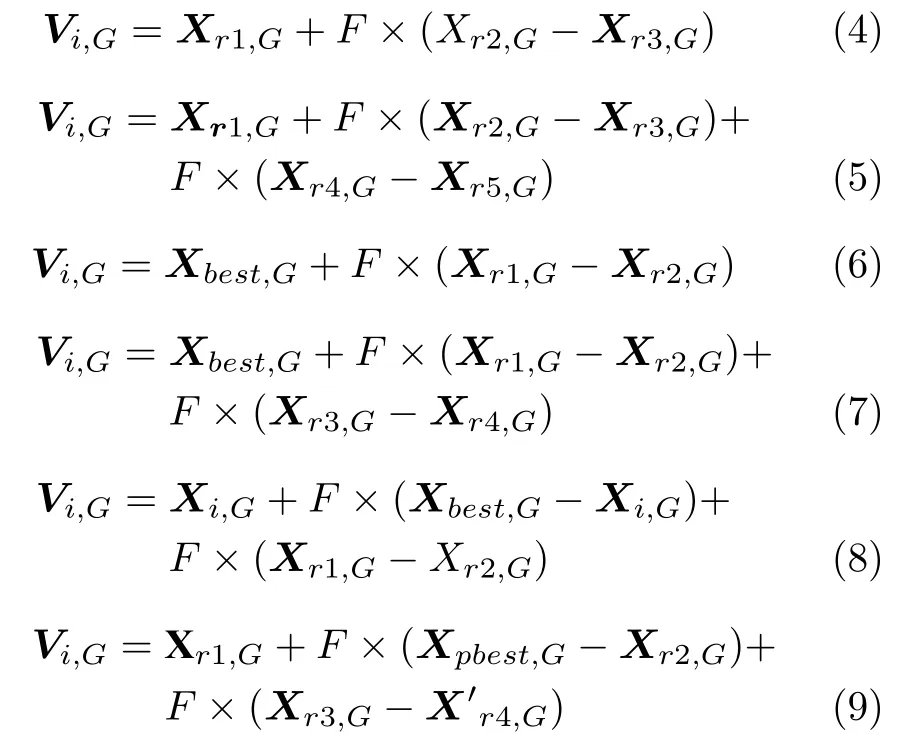
得到变异种群V G(V1,G,V2,G,···,V i,G,···,V NP,G),其中V i,G代表变异的新个体,i1,2,···,NP,j1,2,···,Q.r1,r2,r3,r4,r5为随机生成的数,代表不同于i 的个体,Xbest,G代表当前种群适应度最好的个体,F为缩放因子.变异策略“DE/current-to-pbest/1”由Zhang 等提出[29],如式(9),将当前种群按适应度排序,选择出适应度较好的前p%个个体,Xpbest,G从中随机选择.该变异策略带有小范围的外部存档arch 来存储迭代时竞争失败的父代个体,大小为NP.若外部存档arch 的个体数大于NP,则随机删除多余的个体.从当前种群和外部arch 中随机选择,提高种群多样性.F为缩放因子,其决定着每个个体变异的尺度来得到新的个体,因此它对差分算法的性能有着决定性影响.
3)交叉操作的交叉公式为:

其中,i1,2,···,NP,j1,2,···,Q,生成的试验向量为U G(U1,G,U2,G,···,U i,G,···,U NP,G),每个试验个体为CR为交叉概率因子.
4)选择操作就是对新旧个体进行淘汰制操作,规则就是比较新旧个体的适应度,适应度好的个体顺利进入下一代,适应度差的就被淘汰,以此来获得适应度较好的种群.选择公式:
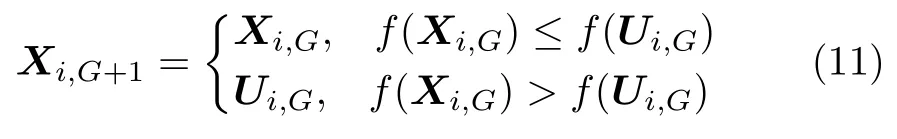
式中,Xi,G为第G代的第i个个体,如果目标矢量X i,G的适应度比试验矢量Ui,G适应度好,则X i,G进入下一代成为Xi,G+1;反之,Ui,G进入下一代成为X i,G+1.
2.2 参数的自适应
在标准的差分进化算法中,缩放因子F和交叉概率CR是一个确定值,意味着种群中的每个个体都是用同样的F和CR来进行后面的变异和交叉操作,但是合适的参数选择通常与个体成员相关,不同的个体对应着不同的控制参数.为了使参数F和CR的选择适合每一个个体,本文采用自适应方法,控制参数在进化的过程中根据个体适应度之间的关系自适应变化.
1)缩放因子F的自适应
从变异策略方程式可知,差分矢量实际上是对基向量各维的扰动,F则控制扰动量的大小.如果生成差分矢量的两个个体Xp,G和Xq,G在搜索空间中离得很远,则生成的差分矢量比较大,此时F应减小,否则对基向量Xb,G的各维的扰动量太大,将会使变异个体超出整个搜索空间,不利于局部搜索.如果Xp,G和Xq,G在搜索空间中的位置相近,则生成的差分矢量的值 (X p,G −X q,G) 就会很小,此时F应增大,否则基向量Xb,G的各维的扰动量太小,就起不到变异的作用,不利于在进化初期的全局搜索.因此,本文采用自适应策略为每个个体选择合适的缩放因子F i,在全局搜索和局部搜索之间取得平衡.

式中,fb,f p,f q分别为个体Xb,G,X p,G,X q,G的适应度,F l和F u分别为F i给定的最小值和最大值.上式表明如果Xp,G和Xq,G的适应度相差很小,说明这两个个体在搜索空间里离得很近,则F i取值大,以防止对基向量的各维扰动过小;如果Xp,G和X q,G的适应度相差很大,说明这两个个体在搜索空间里位置离得很远,则F i取值小,以限制扰动量过大.
2)交叉概率CR的自适应
从交叉策略方程式可知,CR是来控制变异矢量Vi,G对试验矢量Ui,G的贡献的.如果CR过大,则控制变异矢量Vi,G对试验矢量Ui,G的贡献越多,对目标矢量的破坏也就越大,从而使原本适应度很好的个体结构遭到破坏,不利于种群的进化.如果CR过小,则不易产生新的个体,会使整个搜索过程缓慢甚至停止,不利于种群后代的搜索.因此,CR的取值应该根据个体的适应度的变化而变化,对适应度很好的个体,此时CR应减小,避免对该个体造成破坏,使其进入下一代的机会更大;对适应度差的个体,此时CR应增大,有利于改变该个体的结构则使产生适应度好的个体的可能更大.每个个体的交叉概率CR i计算如下:

式中,CR u,CR l是CR i给定的最大值和最小值,fmin和fmax分别代表第i个个体的适应度、种群适应度的平均值、最优个体的适应度和最差个体的适应度.上式表明如果当前第i个个体的适应度大于当前种群适应度的平均值,说明该个体不好,此时CR应增大;如果该个体的适应度小于当前种群适应度的平均值,说明该个体性能好,此时CR应减小,使该个体更可能进入下一代.
2.3 变异策略的自适应
在标准的差分进化算法中,变异策略只使用一种,意味着种群中的每个个体都使用同样的变异策略进行变异,但是合适的变异策略选择通常与问题和初始的种群息息相关,不同的优化问题对应着不同的变异策略,且初始化具有随机性.为了使变异策略的选择独立于优化问题和初始化,根据文献[30],本文采用自适应方法,使变异策略在进化的过程中,在指定的策略池中内自适应地选择,策略池包括的策略:“DE/rand/1”、“DE/rand/2”、“DE/targetto-best/1”和“DE/current-to-pbest/1”[29],如式(4)、(5)、(8)、(9).
首先在LP代及LP代之前,策略池中的每个策略被选择的概率是一样的,假设策略池有M个策略,那么初始时每个变异策略被选择的概率是 1/M.每次迭代时,将通过第m个策略生成进入下一代个体的数量记作,将通过第m个策略生成的个体没有成功进入下一代的个体数量记作.从LP+1 代开始,根据之前和的记忆,来更新策略池中每个策略被选择的概率.例如,在G代时,第m个策略被选择的概率为:

式中,m1,2,···,M,G>LP,表征当前G代中第m个策略生成的试验矢量成功进入下一代的可能性大小.为了使每个策略被选择的概率和为1,则将除以各个策略的成功率的和.为避免变异策略生成进入下一代个体的成功率为0,本文中ε的值设为0.01.
3 改进的差分进化算法优化储备池参数
ESN 优点在于网络学习过程中仅需调节储备池到输出层之间的输出连接权值,而其他连接权值一般都随机赋值后保持不变.储备池参数设置直接影响ESN 的预测性能,人工调节参数既费时又不能选择出最适合的参数值,所以本文提出基于改进的差分进化算法优化回声状态网络(Improved differential evolution-echo state network,IDE-ESN)的参数.本文将实验数据分为训练集、测试集两部分,目标函数为训练集误差最小.具体阐述如算法1 所示,流程图如图2 所示.

图2 IDE-ESN 算法流程图Fig.2 Flow chart for IDE-ESN
4 仿真实验
为验证本文所提模型的有效性,本文选择Lorenz 时间序列、大连月平均气温−降雨量数据集进行仿真实验.同时,在相同的数据集上,与人工鱼群[18]优化ESN(AF-ESN)、粒子群[19]优化ESN(PSOESN)、教与学优化算法[25]优化ESN(TLBO-ESN)和极限学习机预测模型(ELM)[10]的仿真结果进行比较.模型预测性能好坏的评价指标为均方根误差(Root mean square error,RMSE)、平均对称绝对误差(Symmetric mean absolute percentage error,SMAPE)和标准化均方根误差(Normalized root mean squared error NRMSE).RMSE、SMAPE 和NRMSE 的计算公式定义如下:

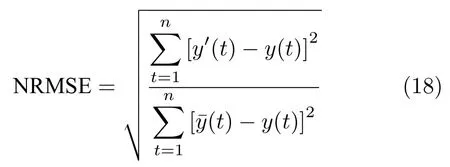
式中,y(t) 为测试数据的真实值,y′(t) 为网络预测值,为真实值的平均值,n为测试集的大小.
4.1 Lorenz 时间序列
Lorenz 系统方程描述如下:
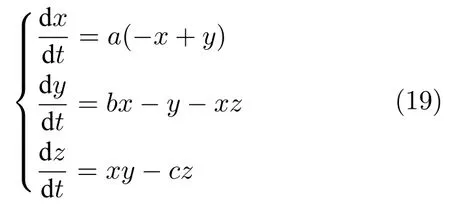
当a=10、b=28 和c=8/3 时,系统是具有混沌特性.采用龙格库塔方法产生2 500 组离散时间序列.
算法 1.改进差分进化回声状态网络
步骤 1.随机初始化种群X(X1,G,X2,G,···,X i,G,···,X NP,G),NP为种群个体数,G=0 为初始代数.种群个体的每一维代表储备池的一个参数,每一个参数都有选择范围,因此对个体的每一维进行约束.
步骤 2.将个体的每一维分别赋值给储备池对应的参数:储备池规模N,稀疏度D,谱半径R和输入变换因子S,进行适应度评价,选出最优个体.适应度评价为计算ESN 模型在训练集上的均方根误差.
步骤 3.根据式(12)来选择每个个体对应的缩放因子F i.
步骤 4.当迭代次数G ≤LP时,在变异策略池中随机选择变异策略,生成变异个体Vi,G.当迭代次数G>LP时,根据前G −LP代得出的和依式(14)和(15)计算每个变异策略被选择的概率,并选择概率最大的变异策略来产生变异个体Vi,G.
步骤 5.用式(13)为每个目标个体选择CR i,通过交叉策略,即式(10)来生成试验个体Ui,G.
步骤 6.通过对原个体与试验个体进行适应度评价比较,选出适应度好的个体来进行种群更新.即若f(X i,G)>f(U i,G),则若f(X i,G)≤f(U i,G),则X i,G+1X i,G,+1.并更新最优个体.
步骤 7.在迭代的过程中,种群中的个体慢慢趋于相同,为了增加种群的多样性,避免陷入局部最优,在迭代次数大于5 时,随机选取NP/5 个体,根据Logistic 混沌映射产生与原个体差异较大的新的个体.若迭代次数G大于最大迭代次数Max iteration,执行步骤8;反之执行步骤3.
步骤 8.输出最优个体,在测试集数据上进行验证.
改进的差分进化算法优化ESN 模型参数的范围设定:储备池规模N范围设为[20,100]、稀疏度D范围设为[0.01,0.5]、谱半径ρ范围设为[0.1,1]及输入变换因子S范围设为[0.0001,0.1];种群大小NP 设为25,最大迭代次数设为30.缩放因子F的范围设为[0.1,0.9],交叉概率CR的范围设为[0.1,0.9].前 70%数据用于训练,30% 数据用于测试,其中训练样本中舍弃前50 个样本产生的状态以消除初始暂态的影响.人工鱼群优化ESN 模型及粒子群优化ESN 模型的参数设置同改进差分优化ESN 模型.表1 给出了对于Lorenz 序列IDEESN 选出的最好的参数值.

表1 Lorenz-x(t)序列:IDE-ESN 模型参数Table 1 Lorenz-x(t)series:parameters in IDE-ESN
表2 给出了不同模型对Lorenz-x(t)的单步预测结果,可以看出本文所提模型在RMSE、SMAPE及NRMSE 方面均好于其他对比模型,更具优势.其中,人工鱼群优化ESN 模型的预测精度不及粒子群优化ESN 模型,可以看出同时优化多个范围不同的参数时,人工鱼群优化ESN 模型存在局限性.图3 给出了IDE-ESN 对Lorenz-x(t)测试数据的预测曲线和误差曲线.从图中可以看出,预测误差很小,IDE-ESN 能够很好地拟合Lorenz-x(t)序列.得到各个算法误差指标如表2 所示.

图3 Lorenz-x(t)序列:IDE-ESN 的预测曲线及误差曲线Fig.3 Lorenz-x(t)series:prediction and error curves obtained by IDE-ESN

表2 Lorenz-x(t)序列:测试集仿真结果Table 2 Lorenz-x(t)time series:prediction results on the test dataset
表3 给出对于Lorenz 序列不同模型在30 次迭代次数下运行时间,可以看出AF-ESN 模型运行时间最长,该模型的时间复杂度最大.PSO-ESN 的时间复杂度最小,本文所提模型IDE-ESN 运行时间虽然比PSO-ESN 长,但是预测精度高,综合来看,IDE-ESN 模型更具优势.图4 给出对于Lorenz 时间序列,本文所提出的改进的差分进化算法优化ESN(IDE-ESN)、粒子群优化ESN(PSO-ESN)、人工鱼群优化ESN(AF-ESN)及教与学优化算法优化ESN(TLBO-ESN)在迭代过程中的适应度值(Fitness)的变化曲线图.为更能清楚地显示各个模型适应度曲线的差别,对适应度的值取以30 为底的对数.从图中可以看出IDE-ESN 算法在迭代的过程中,误差越来越小,收敛速度较快并最终稳定于较小的适应度值.

图4 Lorenz-x(t)序列:不同模型的适应度曲线Fig.4 Lorenz-x(t)series:the curves of fitness for different models

表3 Lorenz-x(t)序列:不同模型的运行时间Table 3 Lorenz-x(t)series:run time of different models
4.2 大连月平均气温 − 降雨量序列
大连市月平均气温和月降雨量数据集包括从1951 年1 月到2001 年12 月的数据记录值,采样间隔为月.大连月降雨量序列作为实验数据的第二维,来辅助大连月平均气温的预测.70% 的数据用于训练,30% 数据用于测试,其中训练样本中舍弃前50个样本产生的状态以消除初始暂态的影响.储备池规模N范围设为[20,100]、稀疏度D范围设为[0.01,0.5]、谱半径R范围设为[0.1,1]及输入变换因子S范围设为[0.0001,0.1];种群大小NP设为25,最大迭代次数设为30.缩放因子F的范围设为[0.1,0.9],交叉概率CR的范围设为[0.1,0.9].为证明本文所提模型有效性,对于PSO-ESN、AF-ESN模型,设置同样的储备池参数范围、种群大小及迭代次数.表4 给出本文所提出的模型选出的最适合大连月平均气温−降雨量序列的储备池参数.

表4 大连月平均气温:IDE-ESN 模型参数Table 4 Dalian monthly average temperature-rainfall series:parameters in IDE-ESN
图5 给出了IDE-ESN 模型对大连月平均气温−降雨量序列测试数据的预测曲线和误差曲线.从图中可以看出,本文模型能够很好地拟合大连月平均气温−降雨量序列曲线,绝对误差较小.表5给出了不同模型对大连月平均气温−降雨量序列的单步预测结果,可以看出本文所提模型在RMSE、NRMSE 方面均好于其他对比模型.从表5 可以看出虽然PSO-ESN 模型的RMSE 小于AF-ESN,但是SMAPE 却很大,说明PSO-ESN 模型不能很好地预测出大连月平均气温的序列趋势.而AF-ESN虽然能够较好地拟合出序列的变化趋势,但是在RMSE 和NRMSE 方面误差较大,说明在某些点上的预测上存在较大偏差.本文所提IDE-ESN 模型无论在RMSE 方面还是NRMSE 方面都小于其他对比模型,具有明显优势.
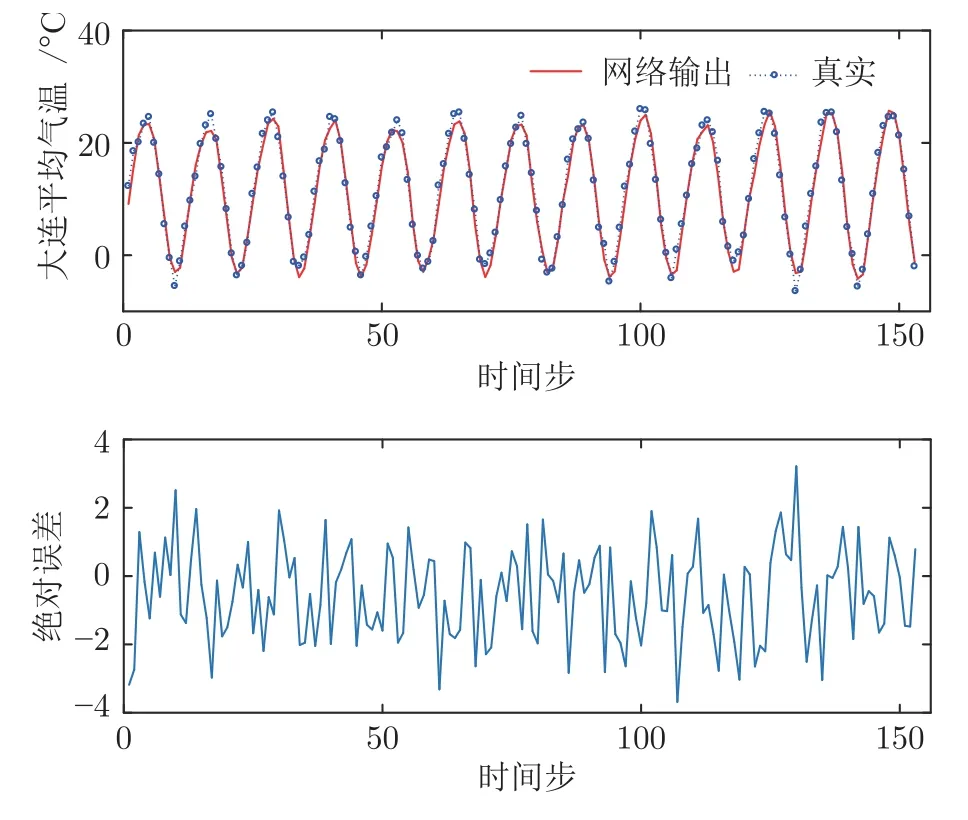
图5 大连月平均气温:IDE-ESN 的预测曲线及误差曲线Fig.5 Dalian monthly average temperature series:prediction and error curves obtained by IDE-ESN

表5 大连月平均气温:测试集仿真结果Table 5 Dalian monthly average temperature series:prediction results for the test dataset
图6 给出对于大连月平均气温数据集,IDEESN、PSO-ESN、AF-ESN 及TLBO-ESN 在迭代过程中的适应度值的变化曲线图,从图中可以看出IDE-ESN 算法较快收敛,且误差较小.表6 给出对于大连月平均气温数据集不同模型在30 次迭代次数下的运行时间,可以看出AF-ESN 模型运行时间最长,该模型的时间复杂度最大.IDE-ESN 模型运行时间略大于PSO-ESN 模型,TLBO-ESN 模型运行时间是本文提出模型运行时间的两倍.PSOESN 模型虽然运行时间最短,但预测精度较差.

表6 大连月平均气温:不同模型的运行时间Table 6 Dalian monthly average temperature series:run time of different models

图6 大连月平均气温:不同模型的适应度曲线Fig.6 Dalian monthly average temperature series:the curves of Fitness for differential models
5 结论
本文针对不同的时间序列,利用改进的差分进化算法来动态选择回声状态网络的参数,以适应于不同时间序列的动力学特性,从而提高预测精度和泛化性能.对于标准的差分进化主要有两方面的改进:1)对于算法的控制参数的自适应选择,主要包括缩放因子F和交叉概率CR;2)变异策略的自适应选择.对两组时间序列进行预测,仿真实验结果表明,本文所提出的模型较其他预测模型有了很大的改善,既具有较高的预测精度,又具有较快的收敛速度和运行速度,在时间序列预测分析中具有实用性和有效性、普遍性.
