基于强化学习的浓密机底流浓度在线控制算法
2021-08-28袁兆麟何润姿姚超李佳班晓娟
袁兆麟 何润姿 姚超 李佳 班晓娟
在现代复杂过程工业生产中,对控制性能指标进行优化是不同控制算法、控制系统的首要任务.在冶金、采矿领域等复杂过程工业场景下,浓密机是一种被广泛应用的大型沉降工具,它通过重力沉降作用可以将低浓度的固液混合物进行浓缩形成高浓度的混合物,起到减水、浓缩的作用.在对浓密机进行控制时,底流浓度是核心控制指标.该参量与其他过程监控变量如进料流量、进料浓度、出料流量、泥层高度有着复杂的耦合关系.在大部分的实际生产过程中,浓密机底流浓度的控制一般是操作员根据个人经验,通过对底流流量设定值、絮凝剂流量设定值进行调节,间接地使底流浓度追踪其工艺设定值.但是由于浓密机运行过程具有非线性、多变量、高时滞等特点,操作员难以维持底流浓度持续稳定,浓度存在偏差的底流会导致产品质量退化以及增加工业生产成本.
浓密机是一种典型的复杂过程工业设备,关于过程工业设备优化控制的研究一直是工业界、学术界研究的热点问题.对于机械结构明确、且能够精确建立动态模型的工业设备,可以采用基于模型的优化控制方法,如:实时优化控制(Realtime optimization,RTO)[1]、模型预测控制(Model predictive control,MPC)[2]等.但由于浓密机系统机械结构复杂、部分变量难以观测,因此难以建立准确的数学模型近似其运转机理,导致基于模型的方法无法适用于此类复杂工业设备的控制.研究人员提出了基于数据驱动的控制方法来实现对此类无模型工业设备的控制.Dai 等[3]提出了用于解决赤铁矿研磨系统控制问题的数据驱动优化(Date driven opimization,DDO)控制算法.Wang 等[4]采用基于数据驱动的自适应评价方法解决连续时间未知非线性系统的无穷范围鲁棒最优控制问题.
近年来,基于强化学习[5−6]理论的最优控制技术,也称为自适应动态规划(Adaptive dynamic programming,ADP)[7−9]技术,是控制领域的研究热点话题.典型的自适应动态规划算法,如HDP、双启发式动态规划(Dual heuristic programming,DHP)、动作依赖启发式动态规划(Action dependent heuristic dynamic programming,ADHDP)[8]等均采用多个神经网络分别对被控系统动态模型、控制策略、策略评价模型进行建模.此类方法可以在模型未知的情况下以数据驱动的方式在线学习控制策略.Liu 等[10]提出了一种在线自适应动态规划算法用来解决离散时间多输入多输出仿射系统控制问题,且该方法仅需要训练少量网络参数.Liu 等[11]采用一种基于强化学习的自适应跟踪控制技术解决多输入多输出系统容错控制问题.Xu 等[12]采用拉普拉斯特征映射算法提取被控系统全局特征,并将该全局特征用于DHP 算法中以增强值函数网络的近似能力.
近年来,利用自适应动态规划方法解决过程工业控制问题也取得很大研究进展.Wei 等[13]将煤炭气化过程的最优追踪控制转化为双人零和最优控制问题,并采用迭代自适应动态规划方法求解最优控制率,同时给出了收敛稳定性的分析.Jiang 等[14]利用穿插学习策略迭代(Interleaved learning policy iteration,ILPL)实现了对浮选过程操作指标优化的控制,获得了比传统值函数迭代(Value iteration,VI)、策略迭代(Policy iteration,PI)算法更佳的控制效果.Jiang 等[15]将强化学习与举升方法结合(Lifting technology),实现了对浮选过程设备层与操作层双速率系统的最优控制.
上述算法均使用被控系统实时生成的数据对神经网络进行训练,该训练方法忽略了系统在短期内产生的历史轨迹数据对模型学习的影响.同时,在工业场景下进行设备在线控制对算法实时性要求较高.上述方法对于控制量的计算均依托于表征控制策略的神经网络,而对于控制网络或动作网络的训练将产生较大的时间开销.为了解决上述问题,本文引入了短期经验回放技术[16−17]以对短期内的系统运行轨迹数据进行回放训练.实验证明该技术有效增强了算法收敛稳定性,且在其他ADP 类在线控制算法中具有通用性.同时本文根据浓密机系统特性提出了一种迭代梯度优化算法,该算法可以在没有动作网络的情况下求解控制输入量.实验表明该方法能够在提升控制精度的同时,减少模型学习过程中产生的时间消耗.
本文主要贡献总结如下:
1)提出了一种基于ADP 算法架构的启发式评价网络值迭代算法(Heuristic critic network value iteration,HCNVI).该算法仅通过评价网络、模型网络和梯度优化算法即可求解系统最优控制输入.
2)提出了一种适用于评价网络训练的短期经验回放技术.训练评价网络时,将短期内系统运行轨迹数据共同用于模型训练,该方法可以有效增强评价网络收敛速度.
3)通过浓密机仿真实验验证了HCNVI 算法的有效性.实验结果表明本文提出方法在时间消耗、控制精度上均优于其他对比方法.
本文正文部分组织如下:第1 节,对浓密机沉降过程进行形式化描述.第2 节,HCNVI 算法介绍以及利用该算法实现浓密机在线控制.第3 节,通过两组仿真实验验证本文提出控制模型的有效性.第4 节对本文研究工作进行总结.
1 浓密过程控制问题描述
浓密机在采矿、冶金领域是重要的沉降分离设备,其运行过程如图1 所示.低浓度的料浆源源不断地流入浓密机顶部进料口.利用沙粒的密度大于水的特性以及絮凝剂的絮凝作用,料浆中沙粒不断沉降,并在浓密机底部形成高浓度的底流料浆.高浓度的底流料浆多以管道输送的形式流至其他工业设备进行后续加工处理.

图1 浓密过程示意图Fig.1 Illustration of thickening process.
对于浓密沉降控制过程的性能进行评价,其核心控制指标为底流浓度y.该因素受控制输入、系统状态参量、及其他外部噪音扰动影响.控制输入包括底流泵转速u1(k) 以及絮凝剂泵转速u2(k),系统状态参量为泥层高度h(k),外部噪音输入为进料流量c1(k)、进料浓度c2(k). 由于在部分工业场景中,上游工序产生的物料浓度、物料流量是不可控的.为了使提出的浓密机控制模型具有通用性,因此本文将进料状态作为噪音输入量.浓密机进料颗粒大小,进料成分都会对浓密机底流浓度产生影响.不过由于此类变量无法观测且波动较小,为了简化问题,本文假定其保持恒定.根据上述定义,其中u(k)[u1(k),u2(k)]T∈R2为可控制输入量,c(k)[c1(k),c2(k)]T∈R2为不可控但是可观测的噪音量,h(k)∈R为系统状态量,该参量是表征当前浓密机状态的重要参量,它可被间接控制但不作为控制目标.因此,浓密机系统可表述为式(1)形式的非线性系统,其中f(·) 为未知非线性函数.
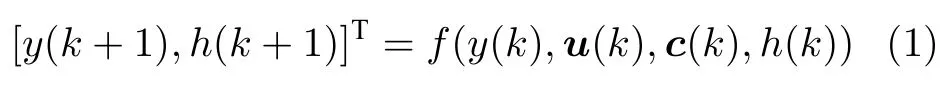
本文提出的浓密机底流浓度控制算法,可以根据当前底流浓度y(k)、泥层高度h(k)、进料流量c1(k)、进料浓度c2(k) 几个状态量,自动地调节底流泵速u1(k) 和絮凝剂泵速u2(k) ,使底流浓度y(·) 追踪其设定值y∗.
2 利用HCNVI 算法实现浓密机底流浓度在线控制
当前,工业场景下控制浓密机的方法主要依靠操作员手工控制.操作员根据生产经验给出絮凝剂添加量的设定值 (m3/h) 以及底流流量设定值(m3/h),浓密机内相配套的回路控制系统会根据设定值的大小自动调节絮凝剂泵速 (Hz) 与底流泵速 (Hz),使絮凝剂的实时流量、底流实时流量追踪操作员给出的设定值.然而,由于浓密机系统的复杂性,操作员难以实时、完整地掌握系统运行参数,因此无法及时、准确地设定目标点位.这导致在实际生产过程中,浓密机常常处于非最优工作状态,底流浓度大范围频繁波动,偏离理想的底流浓度.
对于浓密过程式(1),控制系统的首要目标是使底流浓度y(k) ,追踪其设定值y∗(k) .另外,为了保证系统运行安全与仪器寿命,控制输入必须满足一定的限制条件.综合上述指标因素,可以将浓密机控制问题转化为有约束的最优化问题式(2).
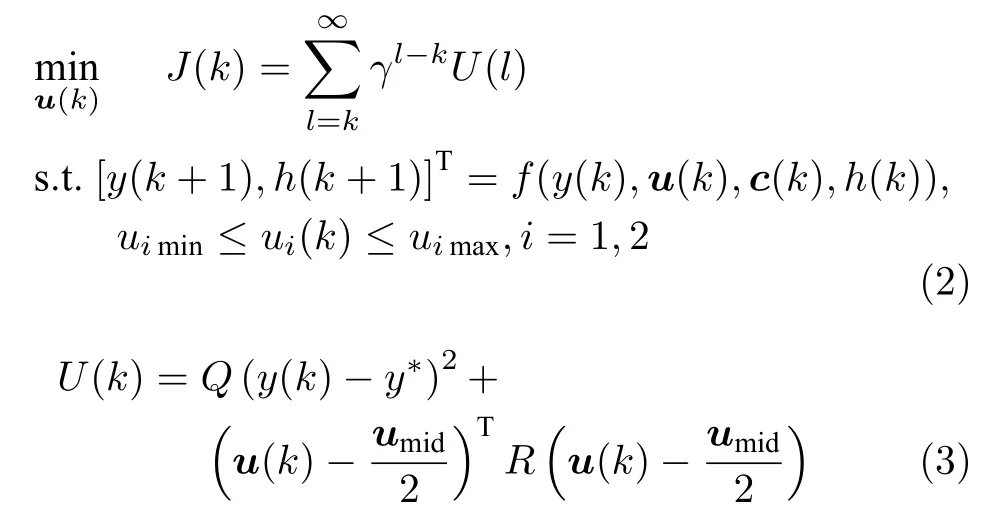
J(k)为折扣累计评价值函数,用来评估控制策略的好坏.式(3)是效用函数,代表在当前状态y(k)下,执行控制输入u(k) 需要承受的代价.γ ∈(0,1]是折扣因子,代表系统短期控制过程中产生的惩罚值在累计惩罚项所占比重.Q>0,R是对称正定矩阵,分别代表对ui(k) 的限制,umid
2.1 理论最优控制模型
本节根据对式(2)的定义,求解理想情况下最优控制输入u∗(k) .
式(2)可以表示为式(4)贝尔曼方程的形式:
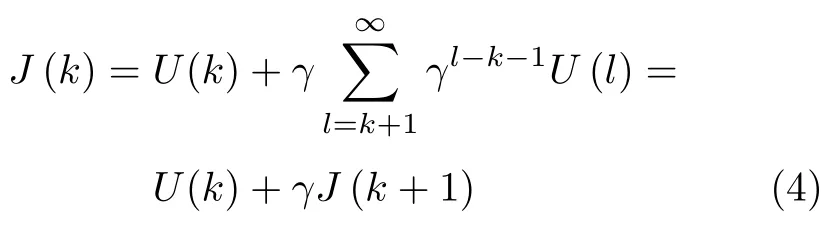
根据贝尔曼最优原则,第k时刻的最优评价值函数J∗(k) 满足离散哈密顿−雅可比−贝尔曼方程

第k时刻,最优的控制输入u∗(k) 可以表示为

由于式(1)中f(·) 是复杂非线性函数,无法直接对式(5)进行求解,但可以利用算法1 以值函数迭代的方式求解最优值函数和最优控制律,其中x(k)用于表征系统状态,x(k)[y(k),h(k),c(k)T]T.根据文献[18],可以证明当i →∞时,值函数V i →J∗,控制律u i →u∗.
算法 1.值迭代算法
初始化:随机定义V0(·)

2.2 启发式评价网络值迭代算法
本节将基于算法1,提出一种启发式评价网络值迭代算法.该算法能根据浓密机系统产生的实时监测数据x(k) 进行在线学习,并产生满足 Ωu约束的控制输入量u(k),且最小化J(k) .算法整体结构如图2 所示.HCNVI 算法中包含两个神经网络,分别是模型网络和评价网络.神经网络均采用单隐层人工神经网络,其基本结构如图3 所示.模型网络的训练全部离线进行,在控制任务开始后,将不再对模型网络参数进行调整.控制动作决策算法根据浓密机实时反馈状态x(k) 计算控制变量u(k) 并用于浓密机系统控制,u(k),x(k) 被放入短期经验数据暂存区存储.模型训练时,由短期经验暂存区提供训练数据供模型训练.算法学习过程中,仅评价网络参数发生改变.

图2 HCNVI 算法结构示意图Fig.2 Structure diagram of algorithm HCNVI
评价网络.HCNVI 采用一个称为评价网络的神经网络来近似算法1 中的V(·) 函数.神经网络选择单隐层人工神经网络,其基本结构如图3 所示.评价网络的具体定义如下:

tanh(x)是网络的激活函数,网络输入层包含4 个节点,隐层包含14 个节点,输出层1个节点,Wc1和Wc2内参数均初始化为 −1 ∼1 之间的随机数.该模型采用由浓密机控制过程中产生的在线数据进行网络训练.为了保证算法更新的实时性,本文采用单步时序差分误差(Temporal difference error,TD error)[5]计算评价网络估计误差值,见式(10).
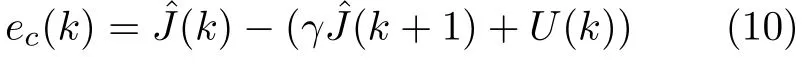
网络损失函数为Ec(k).通过极小化该目标函数,可以使评价网络根据被控系统反馈的状态信号及效用值信号,增量式地逼近对于当前控制策略的评价函数.使用链式法则可以计算损失值E c(k)对网络参数的梯度:
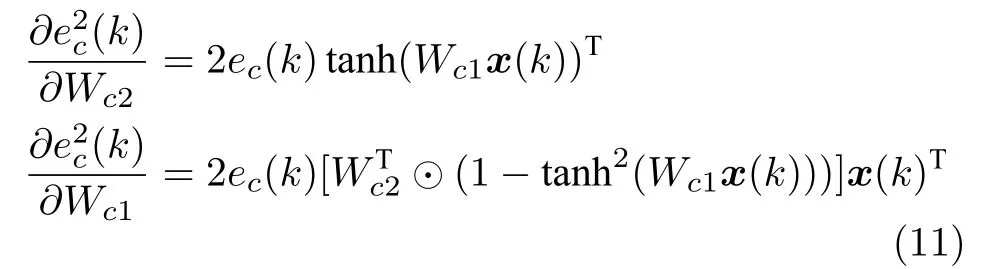
采用梯度下降算法对评价网络进行训练更新:

l c是学习率,由于浓密机所处环境的外界噪音是不断波动的,当外界噪音c(k) 改变时,网络需要根据训练数据快速收敛,l c需设定为固定值以保持学习能力.
由于不同物理量的取值差异很大,这会导致网络无法有效学习并且造成超参数设定困难.因此本文采用浓密机系统产生的离线数据中各参量的极值对所有训练数据利用式(13)进行归一化放缩.

模型网络.建立模型网络用来对系统动态进行建模,根据当前系统状态、外部噪音量、控制输入、预测下一时刻底流浓度和泥层高度变化.网络结构仍采用单隐层神经网络,如图3 所示.模型网络具体定义如下:

其中,ϕ(k)[xT(k),uT(k)]T,网络输入层包含6 个节点,隐层包含20 个节点,输出层2 个节点,W m1和Wm2内各个参数均初始化为 −1 ∼1 之间的随机数.通过梯度下降方法训练模型网络:

损失函数Em(k) 定义为:

对于模型网络,同样采用式(13)对训练数据进行放缩.模型网络的训练全部离线进行,在控制任务开始后,将不再对模型网络进行调整.
2.3 动作生成
大部分的ADP 类算法都是通过建立一个动作网络来计算控制输入,并利用评价网络输出值更新动作网络的参数.HCNVI 方法以HDP 算法架构为基础,去掉了动作网络,直接利用评价网络和模型网络计算控制动作.该方法可以在环境噪音改变时,使被控系统更快速地收敛,并且减少内存占用以及削减训练时间的消耗.
利用评价网络和模型网络计算控制动作u(k)的过程如算法2 所示.式(19)中在估计k+1时刻的折扣累计惩罚时,下一时刻浓密机系统所处外界噪音是未知的.不过由于真实工业环境下进料噪音都是连续变化的,很少出现突变,因此本模型用当前时刻噪音c(k) 来充当下一时刻噪音c(k+1) .
算法 2.利用迭代梯度下降算法计算控制动作
输入:第k时刻系统状态y(k),h(k),c(k)
输出:第k时刻的控制动作输出u(k)



图4 迭代梯度下降过程可视化Fig.4 Visualize the process of iterative gradient decline
2.4 短期经验回放
为了增加评价网络训练的准确性和收敛速度,本文进一步提出短期经验回放方法优化网络训练损失函数,并计算优化梯度.短期经验回放方法将式(10)的误差值计算方法修改为
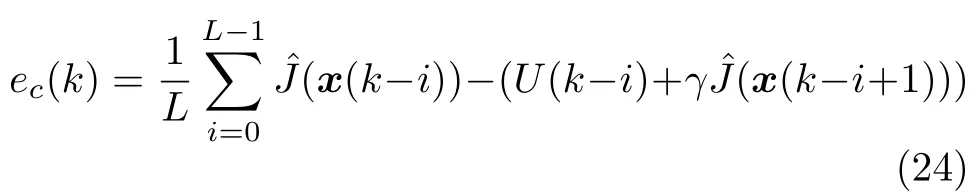
通过存储短期内被控系统的运行轨迹数据,在训练过程中,短期轨迹数据可以用来共同计算评价网络的损失值以及优化梯度方向.
HDP、DHP 以及本文提出的HCNVI 算法都是面向状态值函数进行建模的在线控制算法,其策略模块的更新都是以模型网络作为媒介,计算评价网络输出值对于控制输入u(k) 的梯度,并在此梯度基础上更新动作网络或者利用算法2 优化u(k) .因此对于u(k) 梯度估计的准确性极大地影响了策略模块的更新效果,进而影响整个控制系统的控制效果与收敛速度.u(k) 的梯度表达式为式(25)

对于浓密机等大型过程工业设备来说,系统的运行过程缓慢,短时间内系统状态不会发生剧烈改变,即x(k)≈x(k+1),且评价网络具有连续可微的性质.因此可以近似认为λ(k)≈λ(k+1) .同样,由于系统的运行过程缓慢会导致提供给控制模型学习的训练数据中系统状态参量分布非常集中,可以近似认为式(26)成立.

该式表明短期内系统状态点x(k −t) 都在以x(k)为中心,δ为半径的领域内.通过式(24)将短期L条数据共同用于评价网络训练,可以使评价网络在x(k) 的邻域内学习地更佳充分,进而更准确地估计λ(k) .
为了更直观地展示增加短期经验回放对评价网络学习过程的影响,本文对第3.1 节实验1 中的评价网络进行了可视化,实验结果如图5 所示.该实验中采用等高线图对评价网络的输出值进行展示,其中图5(a)代表不使用经验回放,利用式(10)训练网络,图5(b)代表使用短期经验回放,回放数据点数L为2,利用式(24)训练网络.对于两种算法,分别绘制了连续四次迭代中,评价网络在更新后对不同泥层高度h(·) 和底流浓度y(·) 的评价值.图中横纵坐标分别代表被归一化后的泥层高度和底流浓度.根据实验结果发现.在图5(a)中评价网络的输出值在不同输入下基本趋同.且在当前时刻系统状态点附近,网络输出值的梯度很小.说明单数据点更新会造成评价网络很快地遗忘历史数据,导致网络输出值整体漂移,难以稳定地学习到正确的局部梯度.在图5(b)中,当前系统状态 (h(k),y(k)) 所处临域内,网络输出值具有较大差异,局部梯度值可以被较好地保持.准确的梯度λ(k) 可以提高∇u(k)估计的精确度,因此对短期数据进行回放训练可以更好地指导控制策略输出更优控制动作,促使评价网络和被控系统快速收敛.同时,当经验回放数据量式(24)中L的过大,会导致性能的退化.其原因在于本文提出的方法是同策略(On-policy)强化学习方法,而时间相差较远的历史数据点不能表征由当前控制策略产生的控制轨迹,因此评价网络会学习到错误的评价值.另外,L过大将不再满足性质式(26),过多的历史数据回放将不再有助于评价网络学习x(k) 处的梯度值λ(k),进而不会提高对∇u(k)估计的精确度.通过实验观察,一般将L限定在 5 以内,本文也将这种经验回放方法称为短期经验回放.
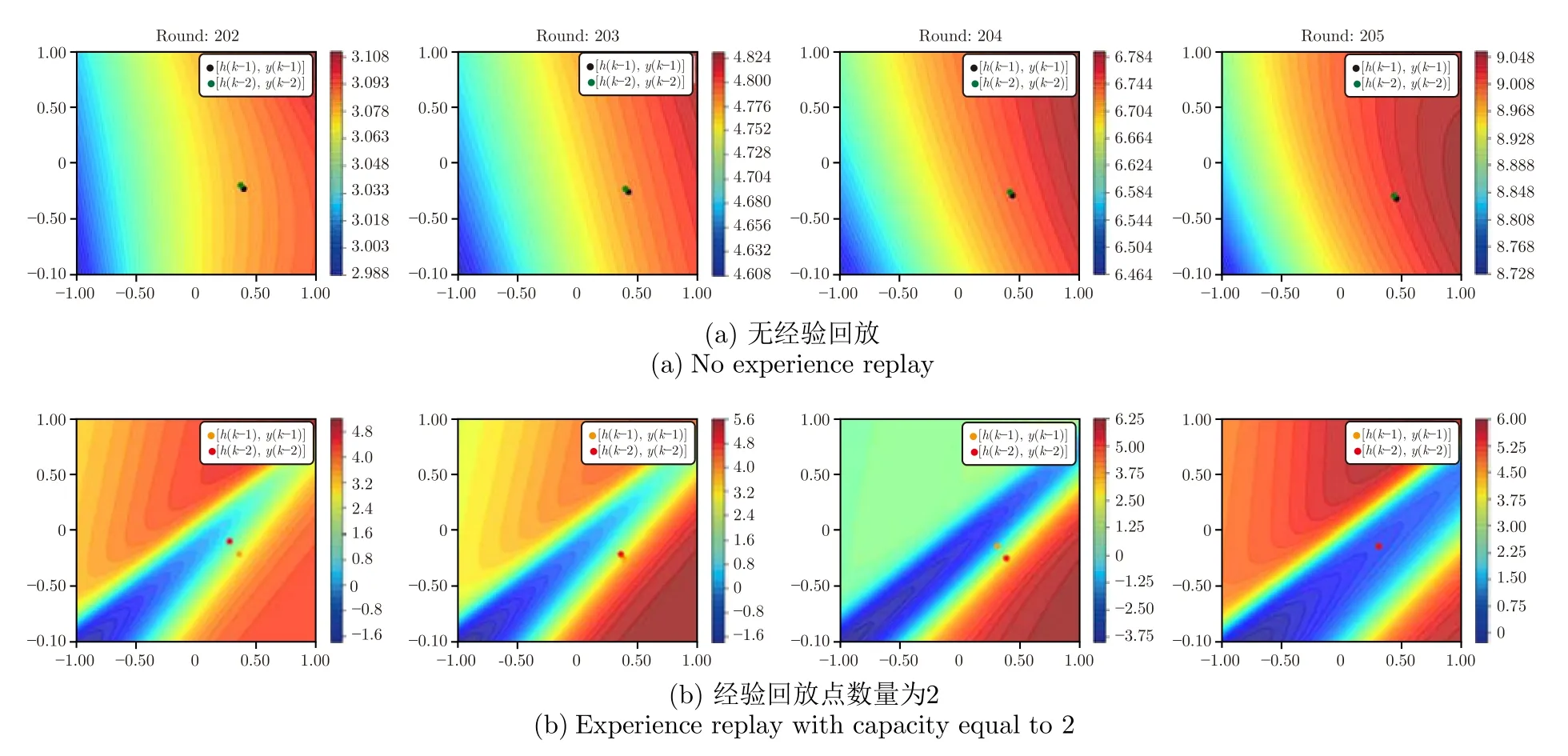
图5 短期经验回放对评价网络的输出值的影响Fig.5 The effect of short-term experience replay on critic network
将HCNVI 算法用于浓密机控制的具体流程如算法3 所示.
算法 3.利用HCNVI 算法实现浓密机在线控制


3 浓密机仿真实验
浓密机仿真模型.由于在真实工业场景下进行浓密机控制实验成本较高,本节采用浓密机仿真模型验证本文提出控制算法的有效性,模型构建方法参考了文献[19−24].该仿真模型建立在如下假设基础上:
1)进料都是球形颗粒.
2)絮凝剂在浓密机的静态混合器中作用完全.
3)流体的扩散以固液混合物形式进行.
4)忽略颗粒间相互作用、浓密机中把机中轴的影响.
模型推导过程中出现的变量如表1~表3所示

表1 参量定义Table 1 Variables definition

表2 仿真模型常量Table 2 Definitions for constant variables

表3 部分变量计算方法Table 3 Definitions for part intermediate variables
由文献[23],可得泥层高度与泥层液固质量比之间的关系.

根据固体守恒定律,泥层内固体质量变化量等于由进料导致泥层内固体量增加量与底流导致泥层内固体减少量的差.因此可以建立泥层内平均单位体积含固量与粒子沉降速度的关系.
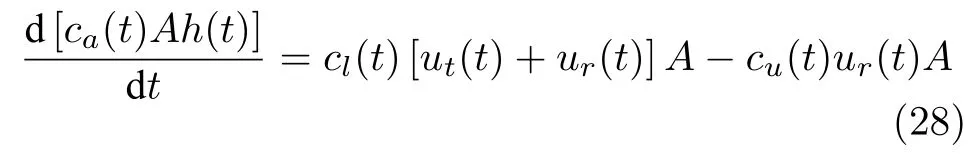
对式(28)做变形可得式(29):

联立式(29),式(27),可得泥层高度h(t) 与底流浓度cu(t) 的一阶变化率

在该仿真模型中,絮凝剂泵速f f和底流泵速f u是控制输入u[f u,f f]T,进料泵速f i和进料浓度c i是外部干扰量c[f i,c i]T,底流浓度c u为控制系统追踪变量yc u. 理想的控制系统能够在外界干扰量c不断波动下,通过在合理范围内调节u,驱使y追踪其设定值y∗. 根据真实生产情况对部分变量做如下定义:umin[40,30]T,umax[120,50]T,ymin280,ymax1200,cmin[40,30]T,cmax[120,50]T,y∗680.接下来本节将基于浓密机仿真模型式(30)、式(31),分别进行两组实验验证在两种类型噪音量c(k) 输入下HCNVI 模型的控制效果,并与其他算法进行比较.
3.1 实验1:恒定 − 阶跃型噪音输入下浓密机控制仿真实验
第一组实验中设置干扰量输入c为恒定值,并在某一时刻为其增加阶跃突变,噪音输入量如图6所示.该实验用来验证控制模型能否在浓密机外在环境发生大幅度变化下,快速寻找到u∗,使被控模型达到理想收敛稳态.
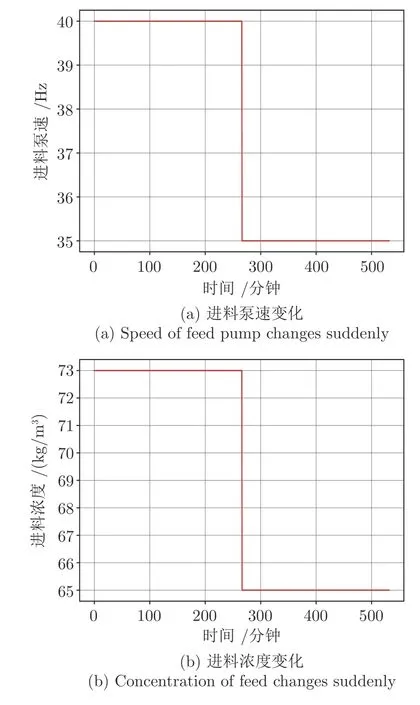
图6 噪音量变化曲线Fig.6 Noise input in the simulation experiment
使用本文提出的HCNVI 算法与HDP、DHP、ILPL 算法进行对比实验.仿真实验参数如下:迭代轮次T270,仿真步长T d120 s,Q0.004,γ0.6,N a4 000,N c500,ϵc0.001,ϵa0.0001,l m0.01,l c0.01,l a0.009,l u0.4,L c2,L m[0.01,3].其中HDP、DHP 算法也使用短期经验回放,回放点数L为2.实验中HDP、ILPL、HCNVI 的评价网络结构相同,且网络参数初始化为相同数值.实验结果如图7 所示.

图7 HCNVI 与其他ADP 算法在恒定噪音输入下的对比Fig.7 HCNVI versu other ADP algorithms under stable noisy input
根据实验结果可以发现,对于不同控制算法,由于网络参数初始值均为随机设定值,训练初期底流浓度有较大幅度的波动,且在设定值两侧持续震荡.随着各个控制模型的学习,系统状态与网络参数不断趋于平稳,直到某一时刻底流浓度开始稳定并与设定值重合且不再产生波动,此时控制模型参数也不再发生变化,被控系统和控制模型同时收敛到最优态.从效用值变化曲线也可以看出,早期由于底流浓度与其设定值偏差较大,效用值较高.但是随着模型与系统趋于稳态,效用值u(k) 不断缩减直到接近于0 的位置.到达270 分钟时,系统进料浓度、进料流量发生突变,底流浓度无法维持稳态,开始远离设定值.控制模型根据噪音量改变后的系统所产生的轨迹数据重新训练,将底流浓度拉回设定值位置.由于在第一阶段控制模型已经到达过一次稳态,在第二阶段仅需要少量迭代就可以使系统重归理想收敛稳态.通过观察不同控制算法产生的系统轨迹,可以发现不同控制算法到达最优态所需的时间有较大差别,且在收敛到最优态的过程中,底流浓度的波动也有较大差异.在实验第一阶段,为使系统达到稳态,HCNVI 算法所需要的迭代次数更少,训练过程中产生的底流浓度振幅也更小.并且在噪音量改变后,HCNVI 算法可以迅速地使模型重归最优态,且底流浓度几乎未发生大幅度波动.
HCNVI 的快速收敛能力主要来源于其采用迭代算法2 得出的u(k) 严格满足式(7)的最小化条件,可以使评价网络更快地收敛到最优评价值函数.而其他ADP 算法中引入了动作网络,这会使策略的更新存在一定的滞后性,进而拖慢评价网络的训练速度.
为了验证短期经验回放技术对控制算法性能的影响,本文分别对比了无经验回放、使用短期经验回放 (L2) 情况下HDP、HCNVI 的控制性能.对比结果如图8 所示.在本实验中,仅比较了两种算法的效用值变化,效用值越快地收敛到0 说明算法控制效果越佳.通过观察图8(a)和图8(b)中无经验回放情况下的效用值变化曲线,可以发现曲线波动较大.相比于使用短期经验回放,无经验回放情况下控制模型需要更多的迭代轮次才能够使系统达到收敛.特别是在图7(a) 的HCNVI 的实验中,270 分钟时系统噪音输入量改变,效用值开始剧增,底流浓度开始偏离设定值,评价网络的学习结果如图5(a)中的第4 部分所示.评价网络对当前状态点x(k)的局部梯度估计有较大偏差,使得利用算法2求解的u(k) 并没有驱使底流浓度向其设定值移动,被控系统无法收敛.但在增加了短期经验数据回放后,无论是本文提出的HCNVI 算法还是HDP算法,效用函数值可以快速收敛至最低点,有效实现对被控系统的控制.该实验结果表明短期经验回放技术对于控制模型的收敛速度改善效果明显,且对不同ADP 算法具有通用型.

图8 短期经验回放对HDP 与HCNVI 的影响Fig.8 The influence of short-term experience replay on HDP and HCNVI
另外本文进行了十组实验来对比HCNVI 算法在时间上的优势.选取HDP 算法作为参考对象,T270,结果如图9 所示.由于每次实验中网络初始值不同,系统运行轨迹以及模型训练过程也不同,因此每组实验中模型学习以及控制所需的累积时间略有差异.但是从多次实验结果可以看出,由于HCNVI 算法中去掉了动作网络,仅需要训练评价网络,所以模型整体训练时间大大缩减,尽管算法2 中计算控制输入所需时间相比于HDP 算法直接利用动作网络前向传播求解控制动作所需时间长,但是HCNVI 算法总消耗时间明显少于HDP 算法.
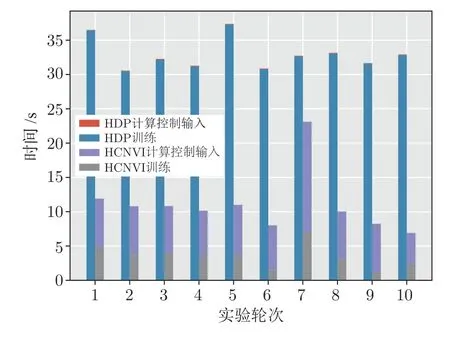
图9 实验一中HDP 与HCNVI 在时间消耗上的对比Fig.9 Comparison of time consuming in HDP and HCNVI in Experiment 1
前人研究表明[25−26],在启发式动态规划类算法中,去掉动作网络可以有效减少模型训练时间.但是在某些复杂系统控制问题中,去除动作网络会使模型难以拟合复杂策略函数,最终导致控制效果变差.在本文的实验中,由于浓密机系统运行缓慢且具有较高时滞性,当前时刻控制输入量u(k) 对的影响较小,即对的影响较小.因此利用算法2 求解的u(k) 满足式(7)的最小化条件.而在HDP、DHP、ILPL 等方法中采用神经网络拟合出的控制策略,难以输出严格满足式(7) 的u(k),算法2 的最优性代表HCNVI 可以最大程度地利用评价网络给出的协状态信息优化当前控制策略,进而获得更高的控制效果.但HCNVI 方法也具有一定的局限性,当被控系统状态变化速率较快,随u(k) 变化的分布函数不再是单峰函数,算法2 求解出的u(k) 极容易陷入到局部最优解,算法控制效果及收敛速度必然变差.而此时在HDP、DHP、ILPL 等方法中采用神经网络拟合的控制策略往往能够给出相对更优、鲁棒性更强的控制动作u(k),其控制效果与收敛速率必然优于HCNVI 算法.
3.2 实验2:高斯噪音波动输入下浓密机控制仿真实验
实验1 中仿真模型的进料状态是恒定的,只在某一时刻产生突变,其目的是为了更好地观察不同控制算法的收敛速度.而真实工业场景下,浓密机的进料浓度和进料流量是实时波动的.在本节实验中,进料流量和进料浓度两个噪音量持续波动,用来模仿真实工业场景下的浓密机系统环境.噪音输入的单步变化增量服从高斯分布,进料波动变化如图10 所示.

图10 噪音量变化曲线Fig.10 The fluctuation of noisy input

本实验中HCNVI 控制器参数与第3.1 节实验1 中的算法参数相同,迭代轮次T270,仿真步长T d120 s.利用该仿真模型再次对比HCNVI 与其他算法控制性能的差异,结果如图11 所示.
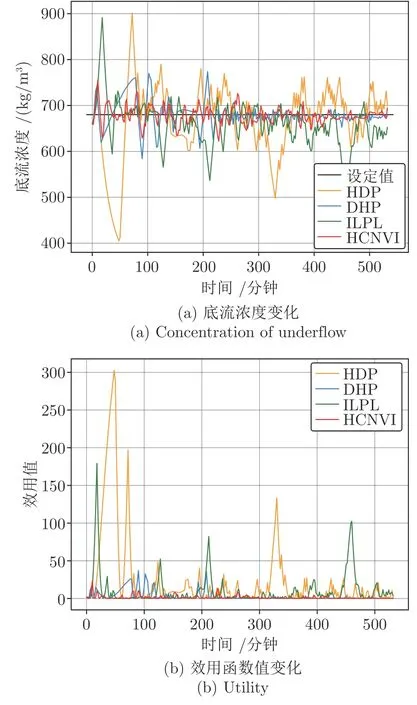
图11 HCNVI 与其他ADP 算法在波动噪声输入下的对比Fig.11 HCNVI versu other ADP algorithms under fluctuate noisy input
通过观察实验结果发现在环境噪音连续变化条件下,浓密机底流浓度会发生持续震荡.随着对模型参数的不断训练,各个算法的控制性能趋于平稳,由于进料噪音导致的底流浓度波动稍有减弱.对比不同控制算法的控制性能,可以发现HCNVI 相比于其他ADP 算法能够更快地将底流浓度锁定在设定值临域范围内,且浓度振幅小于其他算法.从效用值变化曲线也可以看出,相比于其他算法,HCNVI算法的效用值整体较小,且在训练后期几乎0.
该实验结果与第3.1 节实验1 中进料噪音突变条件下的实验结果相吻合.HCNVI 算法在外界噪音频繁改变时,可以更快地响应外部变化,快速调节评价网络参数,将底流浓度稳定在目标值附近.其他算法由于增加了动作网络产生了训练滞后性,进而导致无法快速适应外部环境的变化,使其控制性能差于HCNVI.
表4 给出了不同算法在第3.1 节实验1 和第3.2 节实验2 中底流浓度控制性能指标对比结果.相比其他算法,HCNVI 算法可以更好地控制底流浓度稳定在其设定值附近,其控制总体稳定性(由MSE、IAE 体现)、控制鲁棒性(由MAE 体现)更佳.在过程工业控制场景中,控制系统的MAE 指标尤为重要,某一工序的物料性质发生剧烈波动会使下游物料加工工序出现连带波动,严重影响生产的稳定性和最终产品的质量.HCNVI 算法在MAE指标上的优势证实了其在过程工业控制问题中的适用性.
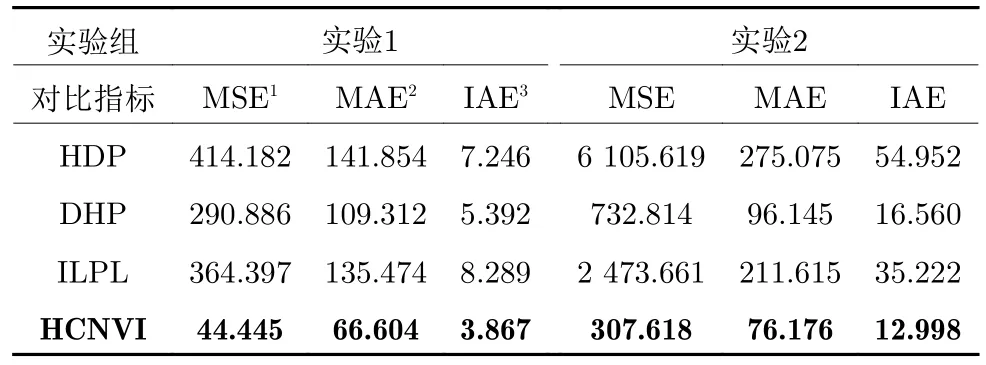
表4 不同控制算法之间性能分析Table 4 Performances analysis of different algorithms
图12 展示在环境噪音持续变化条件下,不使用经验回放和使用短期经验回放 (L2) 两种情况下HCNVI 算法控制性能.在无经验回放情况下,底流浓度稳定性明显较差,且效用值明显较高,使用短期经验回放 (L2) 后模型控制效果较好.实验结果表明,短期经验回放技术在环境噪音持续变化下仍对模型控制效果与收敛速度有重要促进作用.
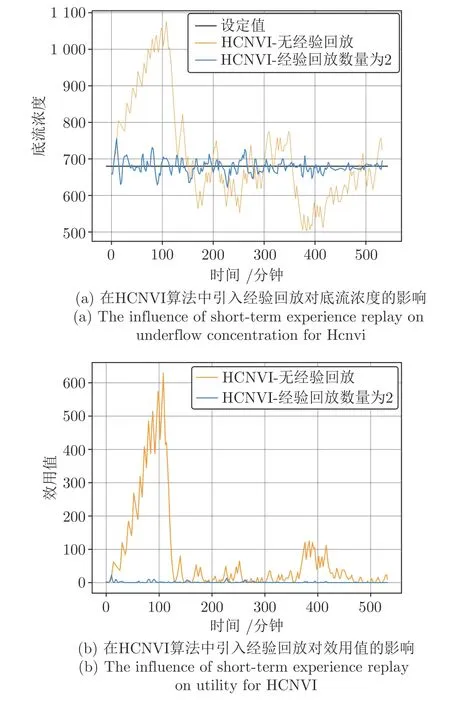
图12 噪音持续变化下短期经验回放对HCNVI 的影响Fig.12 The influence of short-term experience replay on HCNVI
为了展现在噪音持续变化条件下,HCNVI 算法在时间上的优势,再次重复了10 次实验对比了HCNVI 算法与HDP 算法的时间消耗,T270 .实验结果如图13 所示.在噪音持续变化环境下,HCNVI算法和HDP 算法的总时间消耗相比于图9中的结果均有增加.这是由于当外部环境存在持续扰动时,被控系统和控制模型参数不再如第3.1 节实验1 中达到稳定态,而是始终处于震荡状态,被控系统轨迹数据不断变化.每轮学习过程中,为了满足评价网络的精度ec(k)2<ϵc所需要的训练迭代次数增加,进而导致评价网络训练所需时间及模型总体训练时间增加.但通过横向对比HCNVI 算法与HDP 算法的总时间消耗,HCNVI 算法在训练和执行控制过程中所需的总时间消耗仍明显少于HDP,说明利用算法2 替代动作网络所产生的时间消耗削减在噪音连续波动条件仍十分明显.

图13 实验二中HCNVI 算法与HDP 算法在时间消耗上的对比Fig.13 Comparison of time consuming in HDP and HCNVI in Experiment 2
4 结论
本文提出了基于强化学习的自适应控制算法HCNVI,该算法通过构建用于识别系统动态方程的模型网络以及用于估计折扣累计代价的评价网络来解决浓密机控制问题.该方法可以在对浓密机系统未知的情况下,仅利用浓密机系统输出数据以及历史运行数据即可实现在线学习并获得较好的控制效果.另外本文提出的短期经验回放技术可以很好地增强评价网络训练的稳定性,在其他自适应动态规划算法中也具有较好通用性.根据仿真实验验证结果可以发现,相比其他在线ADP 算法,由于HCNVI算法模型结构简单,且具有较高的学习敏捷性,因此在浓密机仿真系统控制问题中,HCNVI 算法消耗了更少的训练时间但获得了更优的控制效果.但是HCNVI 算法也存在自身的局限性,其去掉动作网络的可行性是建立浓密机具有运行缓慢、稳定的特性基础之上的.但是当被控系统相对复杂且不再具有此特性时,如系统状态量变化过程并不连续或系统运行速度较快,HCNVI 依靠迭代算法求解的控制量难以保持最优性,控制性能极有可能产生退化.如何使HCNVI 算法以及其他无动作网络类自适应动态规划类算法适用于此类复杂被控系统,在优化训练时间消耗的同时保证其控制性能与收敛速度,将是未来非常有意义的研究方向.
