知识图谱技术在城市轨道交通企业档案数字化的初探
2021-08-28刘靖昌李杨广州地铁集团有限公司
文/刘靖昌、李杨,广州地铁集团有限公司
随着城市轨道交通行业快速发展,档案馆藏量急速增加,在人工智能技术广泛应用和数字化转型的大背景下,如何有效挖掘和利用城轨企业档案的价值,推动城轨企业科技创新与发展逐渐成为档案学界以及城轨行业关注的焦点。通过构建知识图谱模型,借助于NLP自然语言处理、实体抽取与实体融合等人工智能技术,细化档案数据解析颗粒度,提高档案知识的语义关联,以此解决档案利用中存在的现实问题,提高档案利用的深度,通过有效挖掘档案知识,实现档案知识智能搜索和个性化知识推送,提升城轨企业档案利用的服务水平。
城轨企业档案是城轨企业的财富,是城轨企业历史数据的重要载体,在城轨企业的生产活动、人才培养、科研创新等方面发挥着重要作用。档案多以非结构化数据为主,是企业的“暗数据”,也是企业亟待挖掘的一大“数据矿产”。随着城轨线路规模的飞速扩张,城轨企业档案将达到前所未有的体量,对传统的档案管理模式提出了新的挑战。目前,部分国内城轨企业档案管理具有一定的信息化基础,依托档案管理系统开展档案归档和档案利用等工作。在当前在人工智能技术广泛应用和数字化转型的大背景下,如何有效地开展档案知识开发,充分挖掘档案的价值,提升档案利用服务功能,更好地满足城轨企业发展的需求,已经成为城轨企业普遍关注的新课题。
一、城轨企业档案利用存在的问题
随着数字化时代的到来,以及新档案法的颁布实施,传统的档案管理及档案利用模式已经无法满足城轨企业档案管理的要求,更不能满足用户对档案利用越来越高的诉求,简要来说,主要存在以下问题:
1.档案全文检索能力差。经过多年的积累,档案的数据量不断增长,但是,目前档案管理系统中存储的大部分归档文件以纸质扫描件为主,且档案的元数据标注太少,导致无法实现档案全文检索功能,甚至有的档案系统题名检索功能都不全,检索命中率低,体验差,严重影响档案的利用效率和效果。
2.档案知识语义关联不足。目前档案系统主要以档案分类进行存储和管理,没有对档案文件中的内容根据实际利用的需要进行打标签和分类,由于是扫描的文件,知识单元的提取和加工较为困难,无法跨分类与其他档案知识进行关联,利用难度大。
3.档案利用流程复杂。目前档案利用服务多以档案系统与档案室借阅结合开展为主,在用户利用的过程中需要先查询到相关的档案题名,再通过借阅流程进行申请,审批通过后才能到档案室现场进行借阅,管理和服务的效率低。
二、知识图谱简介
知识图谱的概念最早由Google公司于2012年提出,并将其应用于提高搜索的准确率和提升用户的搜索体验。在2012年以后,知识图谱快速发展,现在全球知识图谱的构建案例除了有通用类的知识图谱如Wikidata、Freebase等,还有专业类的知识图谱如生物医学领域Linked Life Data、社交领域Facebook等。在国内,以百度、阿里、腾讯以及一些大数据公司均开始探索知识图谱在搜索引擎、电子商务、教育、医疗、安防、金融等行业和领域的应用,例如百度百科知识图谱、阿里巴巴商品知识图谱、XLORE多语言百科知识图谱等。
知识图谱的构建一般来说分为两部分,第一部分为概念层构建,即对知识图谱中的实体、属性及关系进行明确的界定,构建知识图谱本体模型;第二部分为数据层填充,即开展实体、属性及关系数据的填充工作。在知识图谱的构建中,数据可能包含大量的结构化数据、非结构化数据、半结构化数据等数据源,需要通过数据整合与知识抽取技术进行处理,通过知识融合技术完成实体对齐和本体对齐,并通过质量评估、知识更新、知识推理等过程,不断修正和补充,最终构造完整的知识图谱。
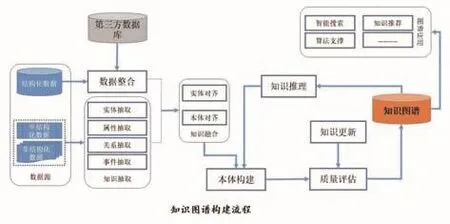
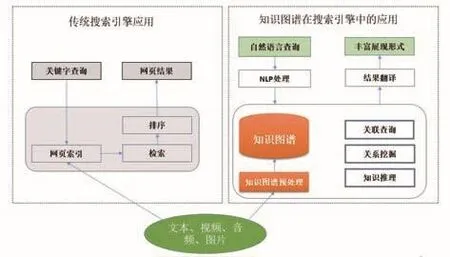
目前,知识图谱已广泛应用于智能搜索、知识推荐、知识问答等应用领域。以搜索引擎为例,知识图谱在搜索引擎中的应用如下图所示。
三、档案知识图谱的构建
随着大数据和人工智能技术的不断创新和突破,知识图谱的应用实践越来越广泛,也为城轨企业档案知识的利用提供了新的解决思路。通过构建档案知识图谱本体模型,结合知识抽取与知识融合技术,实现档案知识的细粒度加工、语义关联分析,以此提升档案知识利用效率,深化档案知识利用层次,充分发挥城轨企业档案的价值。
1.档案知识图谱本体模型构建
知识图谱的构建,首先要进行本体构建,即概念层构建,目前比较具有代表性的构建方法主要有METHONTOLOGY法、TOVE法、骨架法、斯坦福七步法、KACTUS工程法等。我们通过开展城轨企业档案业务调研和数据调研,对城轨企业档案知识体系进行了整理,结合档案知识的特点,确定核心概念、属性、关系,完成档案知识图谱本体模型构建。构建过程主要分为以下几步:
第一步,确定本体的构建范围。本体构建是为了增强档案知识关联,提高档案利用的效率和价值,而城轨企业档案中,以工程建设档案的利用需求更多,利用价值最高,因此,可以以工程建设档案为切入点,待达到预期的效果后再逐步扩展到其他类别档案。第二步,确定核心概念和术语。采用自顶向下的方法,与业务专家一起,进行数据收集和分析,初步定义工程建设档案顶层最抽象的概念,然后再逐层细化。第三步,定义关系。明确概念间的关系,包括关联关系、包含关系等。第四步,定义概念的对象属性,描述概念的内部结构。第五步,本体形式化,即本体实例的构建和展示,可以使用专业的本体构建工具Protégé,也可以使用其他制图工具,能清晰表示本体之间的关系即可。
2.知识抽取
在初步构建了本体模型之后,接下来就是数据层的工作了,通过知识抽取,需要完成实体、属性及关系数据的填充。由于档案数据量大、时间跨度长,数据来源包含以数据库类型为主的结构化数据和以文档、图纸、照片为主的非结构化数据。
对于结构化数据,可以采用D2R(注释:D2R是一个能够将关系数据库中的内容转换成RDF三元组的工具,由于知识图谱中储存的数据要求为三元组格式,而我们的结构化数据储存在关系数据库中,所以需要进行转换)将档案系统关系数据库中的数据映射到RDF中,实现数据的解析,抽取题名、案卷、人员、单位、合同、日期等实体,并获取相关实体的属性值及实体间的关系。
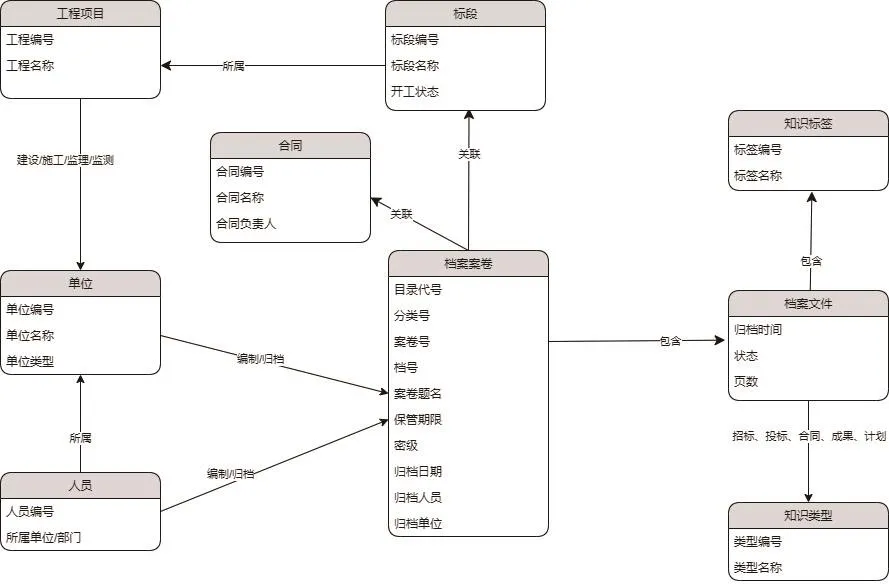
工程建设档案知识图谱本体模型实例
对于非结构化数据,其文档为了保留原始记录,大部分是以扫描的图片形式存入系统中,另外还存在部分尚未电子化的纸质档案。因此,在数据处理过程中,ORC文字识别显得非常重要。非结构化数据的处理过程中,首先要通过引入OCR文字识别算法,提取非结构化数据中的文字,再通过自然语言处理技术,对文字识别的档案内容完成元数据标注和知识标签提取,并通过实体抽取、关系抽取、属性抽取过程,将档案内容进行语义关联,从知识层面串联人员、单位、工程、项目、成果以及合同、图纸、报告等。
实体抽取主要是从档案内容中辨别和提取已定义实体的实例数据,如机构、线路、工程、标段、人员、知识标签、方案、指标等。实体抽取的完整性、准确率、召回率等直接影响知识图谱构建的质量和效率,为了提高实体抽取的效果,可以使用规则和监督学习相结合的方法提取档案中的实体,规则和监督学习相结合的方法既解决了单纯使用监督学习算法在准确率和召回率上的不足,又可以解决基于规则和词典抽取需要大量的专家参与的难题,且可以较好的适应数据变化的新需求。
关系抽取从文本中发现实体之间的语义关系,并将其映射到实体关系三元组上,关系抽取具体过程比实体抽取更为复杂。由于档案数据量巨大,通过使用特征标注的有监督机器学习方法完成关系的抽取,并通过基于规则的方法完成自动标注,同时人工介入进行校对,确定档案实体的语义关系类型,这样可以大大提高关系抽取的效率和质量。属性抽取主要实现对实体的完整描述,可以把实体的属性也看作是一种关系,即实体与属性值之间的一种名词性关系,所以属性抽取任务就可以转化为关系抽取任务。
3.知识融合
在完成档案知识图谱模型构建,并抽取实体、属性、关系等数据进行填充之后,一个初步的档案知识图谱就完成了。然而,通过知识抽取获得的数据往往都存在歧义性问题,需要引入知识融合的相关技术。知识融合包括概念层和数据层两方面,概念层主要是本体对齐,即确定概念、关系、属性等本体间关系的过程,通过机器学习算法对本体间的相似度进行计算来完成。知识融合在数据层的工作包括共指消解和实体对齐,共指消解是将同一信息源中同一个实体的不同表述实现消歧;实体对齐是将不同信息源中同一实体进行统一,使信息源之间产生联结。我们可以通过Dedupe工具(注释:Dedupe是一个python库,使用该工具只需用户标注计算过程选择的少量数据,即可有效地对结构化数据快速执行模糊匹配,相似计算等操作)开展知识融合的工作,将来自于不同来源和不同文件的数据中对同一实体的不同表达融合起来,解决冗余数据的问题,提高知识图谱的质量。
四、知识图谱在档案利用中的具体应用
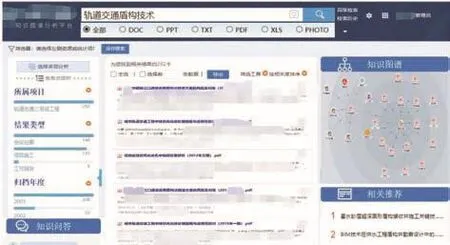
1.档案知识的智能全文搜索
传统的搜索引擎是基于关键词或字符串的,并没有对查询的目标和用户的查询输入进行理解,因此搜索的准确度较低,体验差。而智能搜索引擎,除了需要自然语言处理技术之外,更少不了知识图谱技术,Google和百度等互联网搜索引擎就是最早的实践者。在档案搜索中加入知识图谱技术,使得搜索引擎可理解用户的检索需求,并向用户展示档案知识图谱的全貌,揭示档案实体间的关系,甚至将检索结果显示为结构化的档案知识。在查询具体的项目档案时,可以结构化汇聚展示该项目过程的各种数据,如项目可行性分析报告、立项报告、招投标资料、合同文件、项目计划、项目人员、成果文档、会议纪要等,也可以通过图谱获取与该知识点相关的其他知识或相似的项目,通过这种方式实现整个档案知识图谱的关联查询。
2.档案知识推荐
知识推荐可以基于用户属性、用户行为、业务场景进行分析,为用户主动推荐其感兴趣或与当前工作相关的知识内容。档案知识推荐转变传统的被动式档案利用服务模式,通过收集和调查档案使用部门、用户的需求,结合系统内用户动态行为,如其访问频率、页面停留时间以及检索行为等数据,实时洞察用户行为意图,主动为其推送潜在感兴趣和当前需要的档案知识,进一步精准和高效的开放与共享档案知识成果。
3.档案知识问答
智能问答嵌入拟人化的语义理解能力,用户可用自然语言提问,其背后就是通过知识图谱作为问答系统的知识来源,实现问答智能化,提高问答效率。
五、总结
通过探索,期望对轨道交通企业的档案利用提供一种可行的思路,利用知识图谱提升档案服务和利用水平,实现档案管理数字化、档案利用智能化。
1.提升档案管理数字化水平。在数字化的大环境下,档案数据量不断增加,由于档案的内容和结构相对于互联网数据规范性更高,因此具有更高价值。基于知识图谱的档案管理,更重视档案使用人员的需求,通过档案数据的知识化提取和关联分析,细化档案管理粒度,主动挖掘档案深层次的价值和知识。
2.提高档案利用效率和效果。通过计算机可识别、具有较强操作性以及富含语义关系的档案知识图谱模型,可以揭示和关联档案知识。通过档案知识图谱数据层实例的填充和聚合,采用知识抽取与知识融合等技术,实现档案的精细化加工,实现档案资源知识语义关联,提高档案利用效率和效果。
虽然知识图谱技术的试点应用看到了一定的效果,但其应用还需要不断深化和完善,由于档案知识一个动态更新的,在完成知识图谱建设后,为持续完善档案的语义关联,需要对档案知识之间深层次关系开展推理和挖掘,通过知识推理和知识更新,不断更新和完善档案语义关联。本文目前没有进行档案知识推理的应用探索,因此如何实现档案知识图谱的知识推理,进一步完善和填充档案知识图谱是非常具有挑战性的。
