基于置信度融合的自然场景文本检测方法
2021-08-27蒋志鹏潘坤榕张国林刘玉琪孙科学
蒋志鹏,潘坤榕,张国林,刘玉琪,张 瑛,孙科学,2*
(1.南京邮电大学 电子与光学工程学院,江苏 南京 210023;2.射频集成与微组装技术国家地方联合工程实验室,江苏 南京 210023)
0 引 言
在自然场景图像中包含大量文本,这些文本信息可以作为图像信息的说明和补充,因此从自然场景图像中定位文字区域并识别文本语义已经成为计算机视觉和文档分析领域重要的研究任务[1];该任务在图像检索[2]、图像中敏感词检测、盲人导航[3]、辅助驾驶[4]等领域具有广泛的应用。背景单一、颜色纹理统一的文本检测技术已经十分成熟,并且已有广泛的应用,例如身份证、发票单据等各种稿件中的文本检测与识别,但是由于自然场景背景复杂、光照不均匀、模糊遮挡等不同因素,都影响了文本检测的定位精度和召回率,给文本检测技术带来了新的挑战和难点[5-8]。
随着计算机硬件计算能力的提升和深度卷积神经网络在计算机视觉领域的应用,深度学习技术越来越多地应用在一般目标检测任务(SSD[9]、YOLO[10]、Faster-RCNN[11])中,促进了自然场景文本检测任务性能的提升和应用范围的扩大。深度卷积神经网络[12](convolutional neural network,CNN)中的卷积和池化运算对图像的平移、旋转和缩放具有较强的鲁棒性,其层层堆叠的结构能够将一些低层次的图像特征重组成一些高层次的语义特征,许多研究者将卷积神经网络应用到自然场景文本检测任务中进行特征提取。例如2014年,Girshick等人[13]提出了R-CNN算法,将深度学习技术应用到一般目标检测技术中,随后以R-CNN为基础的Fast-RCNN[14]和Faster-RCNN[11]算法相继问世。2015年,Jonathan等人[15]首次提出了全卷积网络(fully convolutional networks,FCN),该网络不包含全连接层,能够实现逐像素级别的预测和分类,对细小目标的位置信息感知能力更强,并且可以接受任意尺寸的图像输入。
基于卷积神经网络的自然场景文本检测技术主要包括特征提取网络、预测网络和非极大抑制算法。在传统的自然场景文本检测方法[16-17]中,非极大抑制算法基于预测文本框的分类置信度对重复检测的预测框进行筛选和合并。然而,该过程忽略了预测框的定位精度,使得一些定位更精确而分类置信度略低的预测框可能在非极大抑制步骤中被抑制,影响文本检测的准确率。
为了改善上述不足,文中设计了置信度融合的文本检测方法。在多任务预测网络中设计一个新的分支预测锚框与真实文本框的交并比IOU(intersection over union)值,将该值作为预测文本框的定位置信度。在非极大抑制算法中,用分类置信度与定位置信度融合的结果取代分类置信度,保留定位更精确的预测文本框,提高文本检测的准确率。
1 基于置信度融合的文本检测方法
1.1 方法总体设计
置信度融合的文本检测方法包括特征提取网络、多任务预测网络和非极大抑制算法等三个部分,网络结构如图1所示。其中特征提取网络的作用是从输入图像中提取多尺度的特征图;多任务预测网络的作用是对特征图上每个预定义的锚框的文本信息进行预测;非极大抑制算法的作用是对同一文本区域重复预测的预测框进行合并和筛选。研究者通常先将分类置信度低于阈值的预测框删除,再按照分类置信度对剩下的预测框进行排序,保留分类置信度最大的预测框,剩下的预测框则会被抑制。在以上过程中,那些定位更加精确而分类置信度略低的预测框可能会被抑制。因此文中将分类置信度和定位置信度进行融合以改进非极大抑制算法。
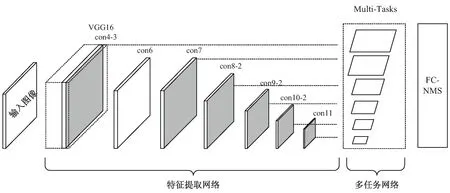
图1 置信度融合的文本检测模型网络结构
1.2 基于VGG的特征提取网络
VGGNet基础网络的泛化能力强、简洁实用,后续成为检测和识别任务中的主干网络。文中选择VGGNet网络并对其进行改进,作为特征提取网络的主干网络。
VGG-16一共包括13个卷积层和2个全连接层,它的网络结构参数列于表1。
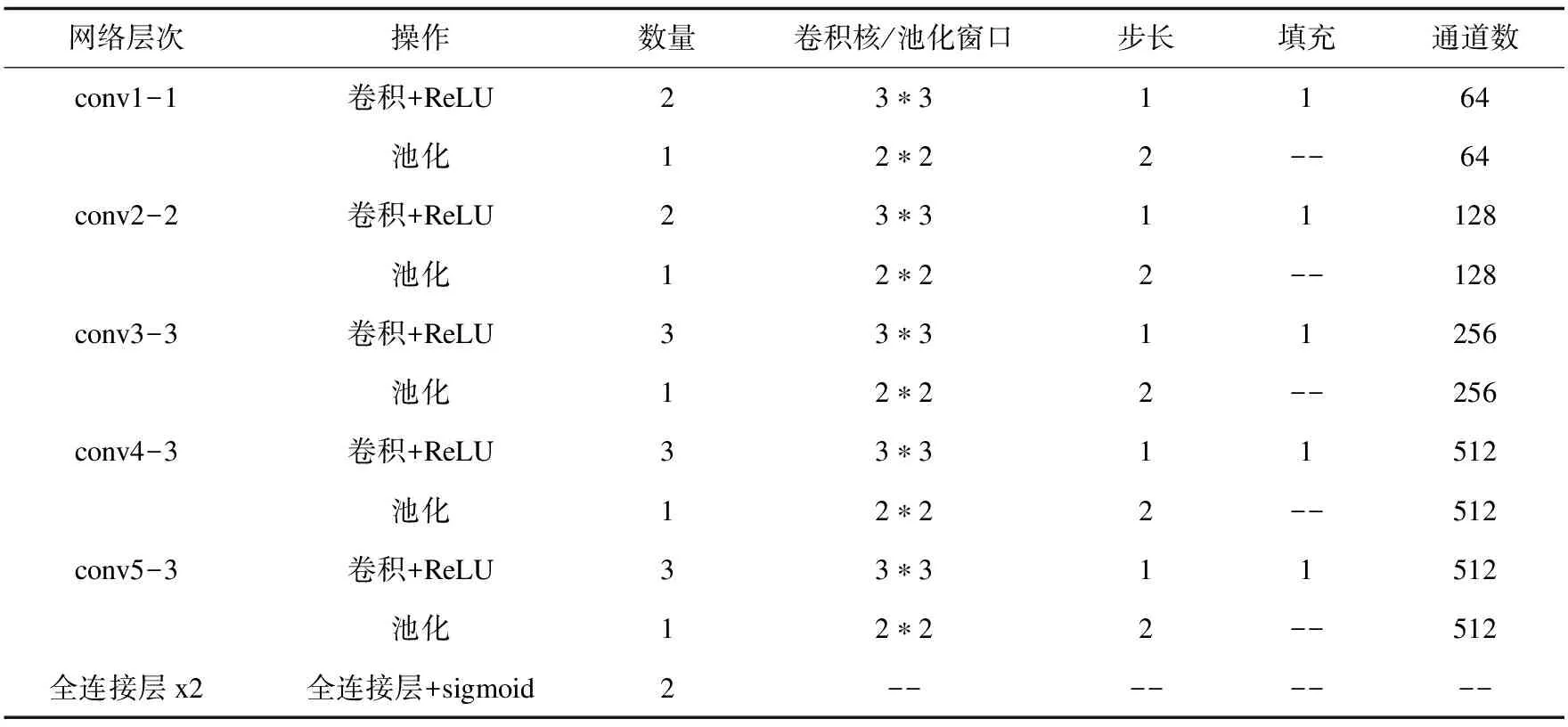
表1 VGG-16的网络结构
特征提取网络保留VGG-16的conv1到conv4层,将最后的两个全连接网络改成3*3的卷积层,为conv5,并在此基础上增加conv6到conv11,如图1灰色区域所示。其中conv4_3、conv7、conv8_2、conv9_2、conv10_2、conv11是文中在特征提取网络中抽取的多尺度特征图。
不同尺度的特征图具有不同的感受野,提取不同层次的特征,通常越浅层的特征图感受野越小,通常可以提取一些边缘、局部特征,能够检测面积较小的文本区域,而越深层的特征图感受野越大,通常可以提取图像的一些语义特征,可以检测面积较大的文本区域。
1.3 多任务预测网络
(1)锚框设置。
多尺度特征图从特征提取网络输出后,文中会在特征图上密集采样锚框,设特征图的大小为N*N,将特征图的每个像素点(i,j)视为不同横纵比的锚框的中心坐标,那么像素点(i,j)处将会产生5种横纵比ar的锚框,如式(1):
ar=[1,3,5,7,10]
(1)
则每个N*N的特征图中会生成N*N*5个锚框。
由于不同输出层的特征图尺度不一样,每层的感受野大小也不同,因此每层特征图对应的锚框的面积也不一样,特征图越浅,感受野越小,锚框的面积也就越小。文中设计的特征提取网络一共输出6层特征图,将图1中从左往右的特征图依次记为特征图1到6,那么第k层特征图中的锚框面积大小如式(2):
(2)
式中,Smin表示最小锚框面积,即第一层特征图上的锚框面积;Smax表示最大锚框面积,即第六层特征图上的锚框面积;k表示特征图的层数。
每个锚框的宽和高的计算方式如式(3)和式(4):
(3)
(4)
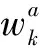
(2)文本框的预测和坐标计算。
接下来,多任务预测网络根据设计好的锚框预测特征图上每一个锚框的类别置信度scorecls、定位置信度scoreiou和每个锚框的坐标偏移量offsetloc,分别对应如图2中的“预测类别”分支、“预测交并比分支”和“坐标信息”分支。
图2中,“交并比预测”分支和“预测类别”分支分别采用两个卷积层和两个sigmoid激活函数,“坐标信息”分支采用两个卷积层和ReLU激活函数。卷积核采用3*5而非3*3的尺寸,这种卷积核的尺寸是针对文本狭长的矩形特征设计的,这样可以产生狭长的矩形感受野,有利于处理更大横纵比的文本。
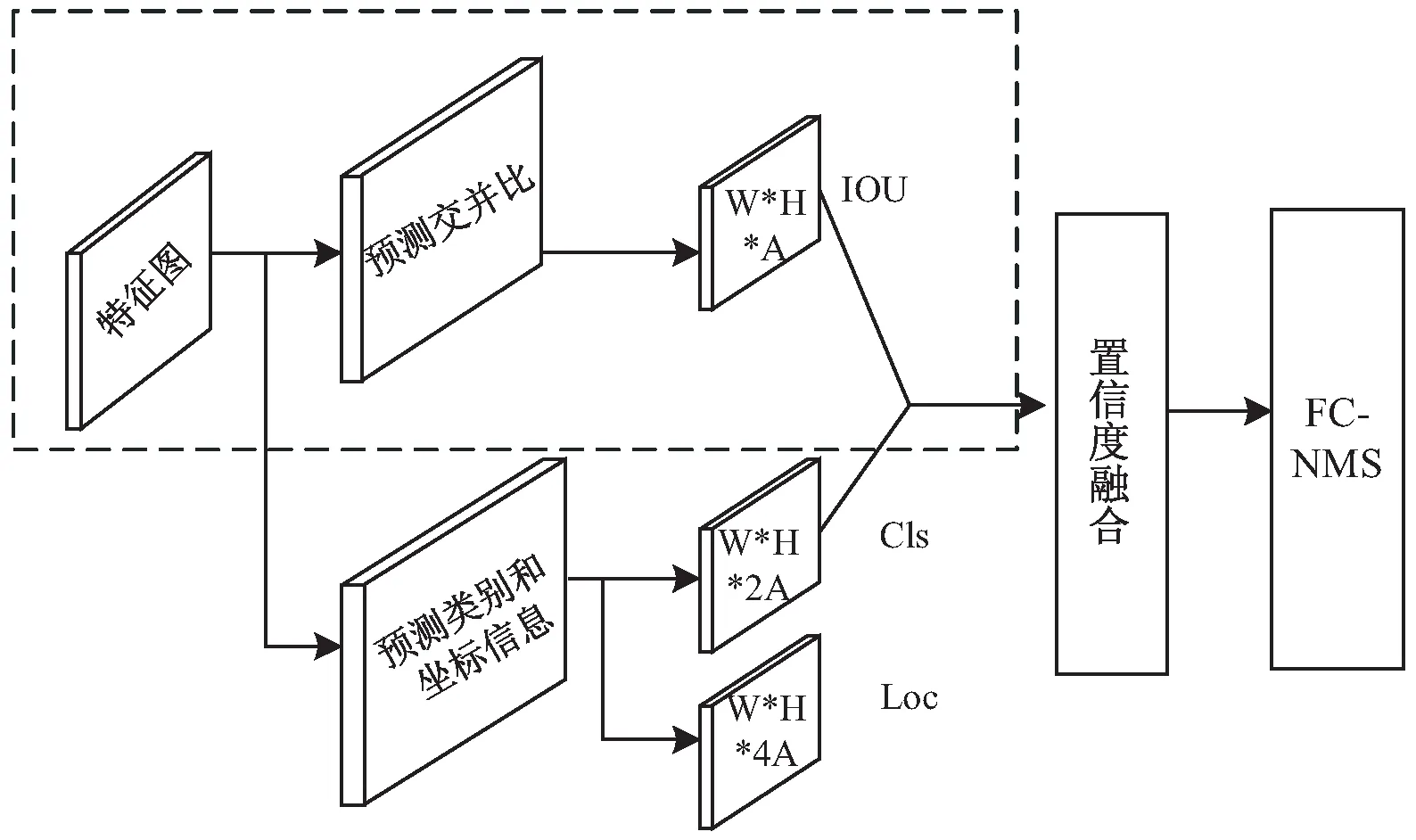
图2 多任务预测网络
设第k层特征图的(i,j)位置处有一锚框b0=(x0,y0,w0,h0),多任务预测网络在(i,j)处输出(Δx,Δy,Δw,Δh,scorecls,scoreiou),scorecls、scoreiou为该预测文本框的分类置信度和定位置信度。假设该预测框的scorecls满足阈值,被认为是一个文本框,那么该预测文本框的中心坐标和宽高为b=(x,y,w,h),计算方式如式(5):
(5)
式中,x0,y0,w0,h0为锚框的中心坐标、宽和高;Δx,Δy,Δw,Δh为锚框与预测文本框之间的坐标偏移量。
1.4 改进的置信度融合的非极大抑制算法
在一般非极大抑制算法(NMS)中,当一个真实文本框存在重复检测时,分类置信度最大的那个文本框将会被保留。然而,由于分类置信度和定位置信度的不匹配,定位更准确而分类置信度偏低的文本候选框可能在NMS算法中被抑制,从而影响文本检测性能。本小节在非极大抑制算法中,用融合的分类置信度与定位置信度取代传统的分类置信度,改进后的NMS算法称为置信度融合的非极大抑制算法(FC-NMS)。
根据文献[18]中的分析,候选文本框的IOU值与定位置信度高度相关,而与分类置信度相关性较小。考虑到传统NMS方法中分类置信度的作用,与文献[18]中直接用定位置信度取代分类置信度作为NMS中候选框排序的依据不同,本小节将分类置信度scorecls与定位置信度scoreiou用不同的权重值进行融合,得到一个融合置信度scoreFC。将融合置信度作为NMS步骤中文本框排序的依据,scoreFC的计算方式如式(6):
scoreFC=Wcls×scorecls+Wiou×scoreiou
(6)
式中,Wcls=0.2、Wiou=0.8分别表示分类置信度和定位置信度的权重。
与传统NMS算法类似,在候选框集合中,将融合置信度scoreFC最高的文本框记为A,计算剩下的候选框与A的交并比IOU值,计算公式如式(7):
(7)
式中,A和B表示两个候选文本框,IOU(A,B)表示框A与框B的交集面积与并集面积之比,IOU越大,表示A与B重叠率越高。A与B的交集部分如图3所示。
图3中,框A与框B的交集部分是一个矩形。若框B与框A的IOU值大于阈值Qnms,表明框B与框A的重叠程度较高,将框B从候选框集合中删除,同时更新A的分类置信度。比如要删除框C,则框A的分类置信度重置为socreclsA,socreclsA的计算公式如式(8):
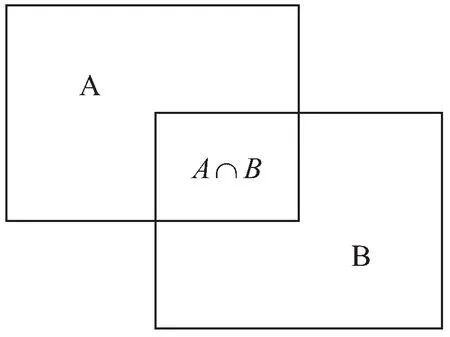
图3 矩形框A和B的交并比示意图
socreclsA=max(socreclsA,socreclsC)
(8)
式中,socreclsA表示框A的文本类别置信度,max表示求最大值,socreclsC表示框C的文本类别置信度。
置信度融合的非极大抑制算法(FC-NMS)的伪代码如算法1所示。
算法1:FC-NMS。
输入:Box={b1,b2,…,bn},cls,iou,Qnms
Box表示候选框的集合,bi表示第i个候选框
cls/iou/FC:映射每个候选框的分类置信度,定位置信度和融合置信度的函数
Qnms:FC-NMS的筛选阈值
输出:Result_Box:最终的预测文本框
1:Result_Box = None
2:while Box!= None:
3: box = argmax(FC)
4: c = cls(box)
5: delete box from Box
6: for bjin Box:
7: if IOU(box,bj) > Qnms:
8: c =max(c, cls(bj))
9: delete bjfrom Box
10: end if
11: end for
12: Result_Box = Result_Box∪{[box,c]}
13:end while
14:return Result_Box
2 文本检测器的训练
本章通过对交并比预测分支单独训练增强交并比网络的兼容性;通过旋转、平移、缩放等手段手动变换训练集中所有的真实文本框,从而生成候选文本框集。将该候选框集合中与真实文本框交并比小于0.5的候选框去除。然后从该候选集合中抽取训练数据对交并比网络进行训练。这种凭借经验增广的数据集为交并比网络带来了更好的性能和鲁棒性。
对于置信度融合的文本检测模型的初始化,文中用预训练的VGG-16模型的权重参数初始化VGG-16部分,用预训练的TextBoxes模型初始化卷积6~11层的权重参数。从第11层卷积开始往后的多任务网络中所有的参数都用均值为0,标准差为0.01的高斯分布进行初始化。
定位置信度scoreiou经过标准化后的取值范围为[-1,1]。训练和测试图像的大小均为700*700,训练时的数据批量大小为16张图像,迭代次数为12万次,学习率的初始值设为0.001,在迭代6万次后,学习率调整为0.000 1,权重衰减系数和动量分别设为0.000 1和0.9。优化算法采用随机梯度下降法。本章中训练交并比网络用IOU损失函数[19],训练坐标偏移量回归任务用smooth-L1作为损失函数,而文本分类任务采用交叉熵作为损失函数。
3 实验与结果分析
3.1 数据集与评价指标
3.1.1 数据集
文中采用ICDAR2011和ICDAR2013这两个水平文本数据集进行实验。ICDAR2011包括229张训练图像、251张测试图像,对文本区域进行单词级别的标注。ICDAR2013包括229张训练图像、233张测试图像,对文本区域进行字符级别和单词级别的标注。这两种数据集中的图像都来自于日常生活中的拍摄,数据样本的分布充分考虑了自然场景图像可能受到的光照不均匀、曝光过度、遮挡、模糊等影响,覆盖了大部分复杂场景。使用这两个数据集能够对文中方法进行客观公正的评价。
3.1.2 评价指标
当文本检测器输出一个预测文本框D时,可以利用公式(7)计算D与真实文本框G的交并比IOU(D,G),并设置一个交并比阈值0.7,如果D与G的IOU值大于该阈值,就认为预测出的D是与G匹配的检测正确的文本框。
按照预测文本框的正例和反例、真实文本框的正例和反例,可以将检测结果分为四种不同的组合情况,并据此对模型检测正确的文本框数量、检测错误的文本框数量、未检测出的文本框数量进行统计,统计规则列于表2。

表2 预测框与真实文本框的匹配数量
表2中,第一列的中间两行分别表示预测结果为文本框和非文本框的情况,第一行的中间两列表示实际情况下为文本框和非文本框的情况。预测为文本框实际也为文本框的为True Positive(TP),表示预测正确的文本框数量;预测为文本框实际不是文本框的为False Positive(FP),表示误检的文本框数量;预测不是文本框而实际是文本框的为False Negative(FN),表示漏检的文本框数量。所有预测出的文本框的数量记作preT,所有实际的文本框的数量记作GTT。
3.2 实验结果分析
基于ICDAR2011数据集对候选框的分类置信度和定位置信度的融合系数作了对比实验,实验结果列于表3。表3中,Wcls表示分类置信度的系数,Wiou表示定位置信度的系数。第一行实验结果表示在非极大抑制算法中仅用分类置信度作为排序依据,即原始方法。随着定位置信度的加入和比重的增大,文本检测的召回率逐渐提高,但是当完全用定位置信度替代分类置信度(表3最后一行)时,虽然召回率提高了,但是准确率也有所下降,这可能是因为提高召回率的过程中除了保留了许多正确的文本框也引入了一些误检的文本框。因此文中选取0.2作为分类置信度的系数、0.8作为定位置信度的系数。
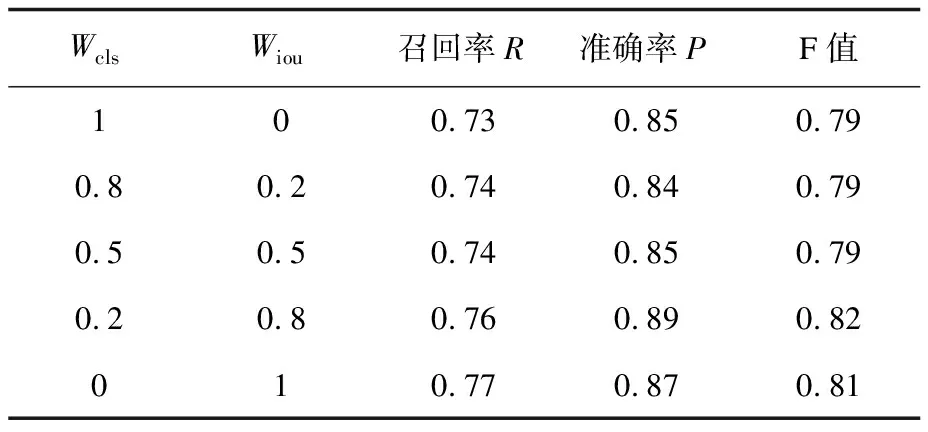
表3 不同融合系数的实验对比
文中提出的置信度融合非极大抑制算法(FC-NMS)的文本检测方法(下文简称为文中方法)与其他方法在数据集ICDAR2011和ICDAR2013上的性能对比结果列于表4和表5。
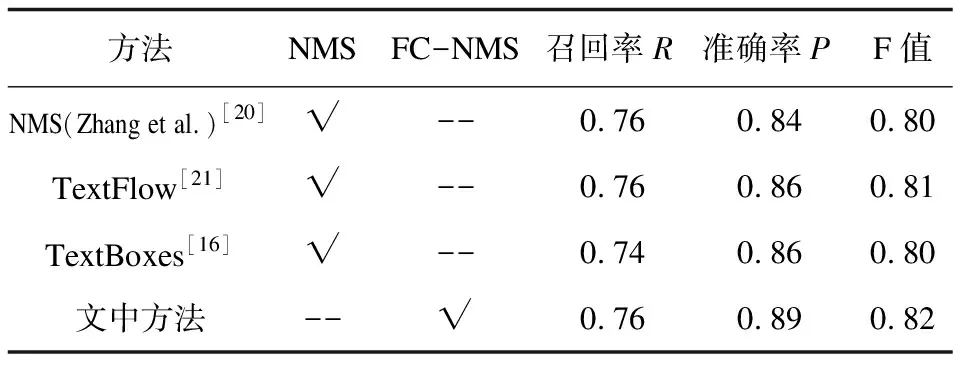
表4 基于ICDAR2011的实验结果
由表4和表5可以看出,文中方法与基准方法(TextBoxes)相比,F值提高了1%,主要性能提升体现在准确率上;在ICDAR2011数据集上,比TextBoxes在准确率上提升了3%;在ICDAR2013数据集上,比TextBoxes在准确率上提升了2%,这主要是因为在非极大抑制算法中融合了定位置信度,使得分类置信度较低但定位置信度较高的预测框能够保留下来。综上所述,置信度融合的文本检测方法可以有效提高文本检测的准确率,改善文本检测的性能。
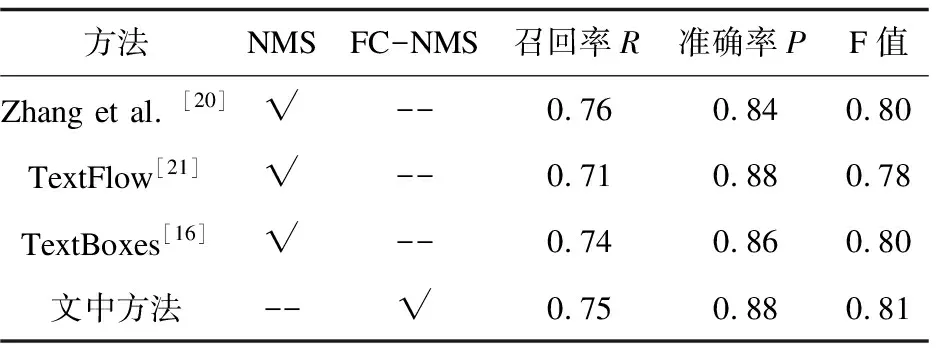
表5 基于ICDAR2013的实验结果
4 结束语
提出了一种置信度融合的自然场景文本检测方法,使得检测的文本框更加紧致,包含的背景区域更少,能够有效提高自然场景文本检测的准确率。然而,文中对新设计的交并比分支进行单独训练时,需要自行准备训练数据,并对数据翻转、缩放等增广操作,这种数据准备方式可能会使数据覆盖范围受限,从而影响模型的训练效果,降低定位置信度预测效率。因此未来的工作可以继续探究交并比分支训练时对数据集的需求,满足模型训练需求。
