子树类型敏感的JavaScript引擎灰盒测试技术
2021-08-25王聪冲甘水滔王晓锋
王聪冲,甘水滔,王晓锋
1江南大学人工智能与计算机学院 无锡 中国 214122 2数字工程与先进计算国家重点实验室 无锡 中国214083
1 介绍
JavaScript引擎是浏览器的必要组成部分,其安全性一直备受关注[1],由于其代码量巨大、逻辑极其复杂,导致漏洞挖掘技术发展一直无法满足JavaScript引擎的安全测试需求,针对JavaScript引擎漏洞攻击事件层出不穷。通过对 CVE漏洞库统计,暴露在 Jerryscript[2]、ChakraCore[3]、SpiderMonkey[4]、JavaScriptCore[5]、V8[6]其高危漏洞条目超过 450条,其中ChakraCore和V8的数量分别超过150条和200条。并且在2020年上半年暴露的高危漏洞数量已超过2019年全年暴露的总数。具体如图1所示。通过进一步对过去JavaScript引擎漏洞暴露来源调查,模糊测试是发现JavaScript引擎漏洞的主流自动化检测方法[7]。
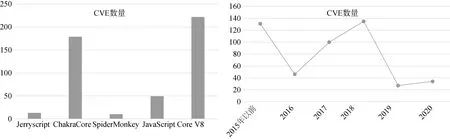
图1 主流JavaScript引擎的CVE漏洞暴露统计情况Figure 1 CVE vulnerability exposure statistics for mainstream JavaScript engines
模糊测试[8]通过不断自动构造随机非预期的输入数据给目标软件,实时监视目标软件运行异常信号,能有效发现软件存在的脆弱性[9]。模糊测试主要分为黑盒和灰盒模型,在2014年以前基本以黑盒模型为主,黑盒模型不具备程序信息反馈能力,具有运行速度快,能适应复杂规模代码软件等优点,但测试效率一直受限于随机性过大、代码覆盖能力弱等问题[10]。从 2015年开始,自经典灰盒测试系统AFL[11]问世以来,通过路径覆盖信息实时反馈,在文档解析、图片解析、音频解析等文件型输入的软件目标测试过程中达到较高代码覆盖率,发现大量未公开漏洞,并实现了向协议型[12]和内核型[13]对象应用扩展。灰盒模型已逐步成为最有效的主流模糊测试手段,并且和 libFuzzer[14]、honggfuzz[15]等灰盒工具集成在谷歌的可持续开源模糊测试服务OSS-fuzz[16]中,截止到2020年6月,OSS-fuzz已经在300个开源项目中发现了上万个可触发漏洞[17]。
模糊测试在JavaScript引擎的应用方法同样划分为黑盒和灰盒模型两类,其难点在于如何高效的生成并测试高质量的JavaScript代码测试用例。不同于文档解析等文件型测试例,JavaScript代码需要遵从严格的语法规范。JavaScript引擎在解析 JavaScript代码过程中,一旦遇见不符合JavaScript语法规则代码,就会终止对整个测试例的解析,从而无法触及JavaScript引擎的关键功能模块,难以达到理想的测试效果。然而,如果直接采用 AFL等灰盒工具的字节或比特级随机变异策略,极易破坏JavaScript代码的合法性,导致JavaScript引擎测试过程中效率极其低下。因此,JavaScript引擎模糊测试在过去以基于代码生成的黑盒模型为主,代表性工具有JSfunfuzz[18]、LangFuzz[19]、CodeAlchemist[20]。JSfunfuzz 通过JavaScript代码语法模板生成测试用例,容易产生合法的JavaScript代码,但需要花费大量的人力构建语法模板,而且容易漏掉有价值的语法模式。LangFuzz通过对已有合法JavaScript代码进行解析,转换为抽象语法树形式,将样本拆分成子树代码片段放入代码池中,并不断使用代码池中的子树替代当前测试用例的非终止节点来构建新的测试用例,这种方式极大提升了测试例自动生成能力,但仍然容易产生非法的代码,CodeAlchemist进一步引入控制流和数据流分析,定位和缓解未定义变量问题,进一步提升了代码生成的正确性。但总体来说,黑盒模型难以摆脱执行速度慢和代码覆盖能力弱等缺点。
为了弥补JavaScript引擎黑盒模型的不足,软工顶级会议工作Superion[21]构建了基于JavaScript代码子树变异的灰盒模型,在 AFL模型中增加了子树变异阶段,以子树替代的方式去对种子变异,一定程度降低了AFL的JavaScript代码生成错误概率,同等测试环境下,其代码覆盖和漏洞发现能力明显优于黑盒模型。然而,Superion在变异阶段对子树类型并不敏感,这种盲目的子树替换策略导致生成的代码出现严重的类型错误和语法错误。
基于现有JavaScript引擎灰盒模型的不足,本文提出了一种基于子树类型敏感的JavaScript引擎灰盒测试技术,并且实现了灰盒测试系统ILS。ILS在路径反馈的模糊测试框架基础上[22],通过对 JavaScript代码进行精准语法分析,对子树集合进行类型识别和分类,并且在变异阶段构建了子树类型敏感的变异策略,使用同类型子树进行覆盖变异,不仅大幅提升了测试种子的有效率,而且带来了更高的代码覆盖能力和漏洞发现能力。本文挑选了Jerryscript、ChakraCore和JavaScriptCore三个常用JavaScript引擎作为测试对象,通过对 ILS和 CodeAlchemist、Superion等工具进行24 h性能测试对比,实验表明:在保持灰盒模型执行性能优势的情况下,错误率比Superion降低了36%,比CodeAlchemist降低了21%。在代码行覆盖率上,ILS相比Superion提升了72%,相比CodeAlchemist提升48%; 在函数覆盖率上,ILS相比 Superion提升 80%,相比 CodeAlchemist提升50%。在漏洞发现数量上,ILS相比Superion提升了100%。最后,ILS在这三个JavaScript引擎上总共发现了 26个未知 Bug,并均得到了厂商的确认和修复。
本文的贡献总结如下:
1) 面向 JavaScript引擎对象,提出了一种子树类型敏感的灰盒测试模型,并实现了相应原型系统ILS。
2) 与经典黑盒和灰盒测试工具相比,ILS能显著降低JavaScript代码测试用例的错误率,并且能大幅提高JavaScript引擎的代码覆盖能力。
2 背景与相关工作
本节先对 JavaScript引擎的基本工作原理进行描述,然后对 JavaScript引擎漏洞挖掘方法相关工作进行总结,最后进一步说明本文方法和传统方法的差异。
2.1 JavaScript引擎工作原理
JavaScript引擎是浏览器重要组成部分,是根据 ECMAScript[23]定义的语言标准来动态执行JavaScript字符串的重要程序。JavaScript引擎具有代码量大,工作原理和逻辑结构复杂等特点。JavaScript引擎动态解析JavaScript代码过程可以分为语法检查阶段和运行阶段,语法检查阶段包括词法分析和语法分析,运行阶段包括预解析和实际执行。其具体工作流程如图2所示: JavaScript引擎首先对 JavaScript代码进行语法分析得到抽象语法树(Abstract Syntax Tree,AST),然后进一步解析得到字节码(bytecode),在生成字节码的同时,优化编译器生成高度优化的机器代码,生成的机器代码最后替换原来的字节码。JavaScript引擎在优化代码的时候会使用未优化的字节码进行工作,有效提高了JavaScript引擎性能。
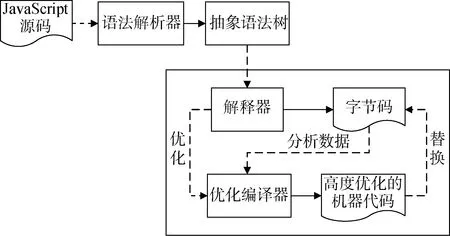
图2 JavaScript引擎工作流程Figure 2 JavaScript engine workflow
在JavaScript解析过程中,一旦遇到错误后面的代码就无法执行。在ECMAScript标准中定义了5种运行时错误: 语法错误(SyntaxError)、范围错误(RangeError)、引用错误(ReferenceError)、类型错误(TypeError)和URI错误(URIError)。如图3所示: 第1行中,var后面没有申明变量,直接进行赋值操作,不符合语法规则,就会抛出语法错误; 第2行中,一旦变量数值超出有效范围,便会抛出范围错误; 第 3行中,一旦引用一个不存在的变量时,便会抛出引用错误; 第4行中,当值的类型或参数不是预期类型时,便会抛出类型错误; 第5行中,使用全局URI处理函数遇见不正确参数时,便会抛出URI错误。由于URI错误很少在JavaScript解析过程中出现,因此本文只考虑前4种错误类型。

图3 JavaScript引擎解析代码过程中常见的运行时错误类型Figure 3 Common runtime errors in the process of JavaScript engine parsing code
2.2 JavaScript引擎漏洞挖掘相关工作
经典程序分析方法符号执行[24-27]和污点分析[28-31]需要对测试软件的指令进行逐条解析,分析速度慢,当处理复杂代码对象JavaScript引擎,符号执行极其容易受限于路径爆炸和复杂约束不可解问题,污点分析极易遭受内存爆炸、过度污染和欠污染问题[32],难以在JavaScript引擎分析中产生作用,在过去鲜有针对JavaScript引擎的符号执行和污点分析工作。另外,经典静态分析工具 Coverity[33]、Klockwork[34]、Fortify[35]只对程序语言敏感,因此也能适用于JavaScript引擎分析,但虚报率高,需要大量人力去验证静态报告的真实性。针对JavaScript引擎适配和优化的静态分析工作[36-38]更多关注如何降低JavaScript引擎运行开销。
相比之下,模糊测试具有速度快、能适应于复杂代码对象等优势,具备直接发现可触发漏洞的能力。因此,本文在相关工作部分主要关注模糊测试方法,从测试例生成方法上看,模糊测试大体可分为基于变异的模糊测试方法和基于生成的模糊测试方法,以下分别针对JavaScript引擎对这两类相关工作进行归纳。
2.2.1 基于生成的模糊测试方法
基于生成的模糊测试方法借助手工构建的输入语法模型生成有效的输入数据,在一个理想的输入语法模型支持下,才能测试重要功能模块。在JavaScript引擎模糊测试应用上,基于生成的模糊测试技术一直是发展的重点,主要发展路线可概括为以下三点: 1)不断提升语法模型的自动化生成能力;2)不断丰富生成的 JavaScript代码模式; 3)不断消减JavaScript代码的错误率。
在代码自动生成能力提升方面,早期的代表性工具有 Peach[39],在应用到 JavaScript引擎测试上,需要为每个对象创建模板文件,需要划分好随机字段和确定字段,这将消耗大量的人力和时间成本。JSfunfuzz基于JavaScript语法模板,根据公开漏洞样本中学习已有特征生成测试用例,只能适应SpiderMonkey解析引擎,扩展性能力差。CodeAlchemist、DIE[40]等方法通过对初始代码样本构建语法特征抽象模型,尽量保留有价值的控制流和数据流特征,在该基础上构建变异策略生成新的代码样本; Skyfire[41]、Montage[42]等方法进一步提升了代码生成的自动化能力,在已有训练代码样本基础上,采用学习的方式生成新的代码样本; 以上几种方法对初始代码样本极其敏感,人力成本主要体现在初始代码样本筛选上,在实际应用过程中,这些模型更多借助标准测试集和公开漏洞触发样本,最后均达到了较为理想的代码生成效果。
在 JavaScript代码语法模式生成能力方面,Peach、JSfunfuzz主要依赖已有语法模板,不容易推导新的语法模式。Skyfire利用带概率的上下文敏感语法(PCSG)从大量样本中学习语法和语义规则,在代码生成过程中优先选择低概率的语义产生规则以生成分布合理的测试用例。CodeAlchemist会按照JavaScript语句的粒度分解种子文件,针对每个块语句生成多种变体提升代码块的丰富性,通过对多个代码块组合产生嵌套循环等结构。Montage从Test262[43]数据集中收集了超过3万个JavaScript代码样本,通过对代码样本中变量和函数等标识符重新命名和子树分片,形成 LSTM 模型的初始训练数据,能有效学习出JavaScript代码中的控制流和数据流依赖关系,从而推导出传统模型能力之外的语法模式,该系统经过一个半月的测试,共发现了 34个未知Bug。DIE以公开漏洞库可触发漏洞样本为基础,识别并保留其中隐式的循环、特定跳转结构信息以及抽象语法树类型信息,这些特征的保留有助于模糊测试阶段集中在容易引发脆弱性的功能模块(JIT优化模块)上进行,最后发现了48个未知Bug。
在JavaScript代码错误率消减方面,JSfunfuzz在已有种子模板基础上,结合实现预先准备好的函数、对象、操作符等JavaScript代码特征库,随机填充可写字段,生成可用测试例,由于缺乏各语句和语句间的合法性检查,这种方式会带来较严重的语法错误、引用错误和类型错误。LangFuzz在生成代码的过程中,用当前已有的变量去替代生成的代码片段中未知变量,但无法避免变量在使用后才声明,而且会增加该变量对象的重复使用概率,从而导致大量的引用错误。Skyfile在生成测试用例的过程中,也没有考虑变量定义、使用等情况,同样容易造成运行时错误。针对这一问题,CodeAlchemist提出使用数据流分析技术确定未定义变量和已定义变量,并结合运行时插桩技术探测已执行变量的类型。CodeAlchemist在 JavaScript代码生成过程中,不断向代码尾部扩展代码片段,每次扩展代码片段都会确保其中的变量在之前已经被定义并且具备正确的类型,CodeAlchemist的优化方法能有效降低LangFuzz方法中存在的错误率,相比 JSfunfuzz,能生成超出 5倍以上的有效测试例。Montage采用LSTM 模型推导不同代码片段之间的关联关系,能有效学习出类似变量定义和使用的先后次序等信息,有效降低非学习代码生成策略存在的引用错误率。DIE通过保留的结构化语义和类型信息,能有效提升变异的准确性,大幅增加了种子的有效率,相比CodeAlchemist,可以降低一半的代码错误率。
2.2.2 基于变异的模糊测试方法
基于变异的模糊测试方法[44-48]通过对已有的测试例进行随机变异产生新的测试例,可以不依赖输入语法模型,正由于其模型简单易用,对人工经验依赖小,相比基于生成的模糊测试方法而言,在非结构化语法输入对象中应用尤为广泛[49-51]。但对于JavaScript代码等结构化语法输入,变异策略需要考虑结构化语法特征,不然会引发严重的错误率。在JavaScript引擎模糊测试应用上,基于变异的模糊测试技术发展历程可概括为: 1)从黑盒模型逐步转向带路径覆盖信息反馈的灰盒模型; 2)从随机变异策略逐步发展为JavaScript代码语法语义敏感的变异策略。
IFuzzer[52]为针对JavaScript引擎的黑盒模型,首先把JavaScript代码样本转换为树的形式,再采用遗传算法对测试样本进行选择、交叉和变异,选择阶段主要参考适应度函数值大小对代码样本进行优先选择,并对代码中子树节点进行交叉变异生成新的测试例,该方法和LangFuzz相比,发现了SpiderMonkey上 LangFuzz之外的 16个未知 Bug。Fuzzilli[53]会把JavaScript代码样本转换为中间代码,中间代码的每条指令由输入变量、操作码以及输出变量构成,在中间代码上进行变异不仅有助于继承已有控制流和数据流特征,还能降低代码错误率。不同于AFL,Fuzzilli在测试过程中忽略了边的循环次数,这样容易丢失覆盖JIT优化功能模块的高价值测试例。近几年业界在JavaScript引擎模糊测试的变异策略上增加了子树分析,以子树为变异单位进行变异操作,如 Montage、CodeAlchemist、Nautilus、Superion。其中,Superion充分发挥AFL的优势,在其基础上添加子树变异阶段,和AFL、JSfunfuzz对比,大幅提升JavaScript引擎对象上的代码覆盖能力和漏洞发现能力。但以上工作普遍没有对子树进行类型分析,对子树类型的不敏感会极大削弱变异策略的种子生成效率。
2.3 本文方法与已有方法区别
根据以上相关工作分析可知,子树变异和路径覆盖反馈能力是当前多个JavaScript引擎模糊测试的重要方法特征,但这些工作普遍缺乏对子树的类型分析,容易导致严重的 JavaScript代码错误率,从而丢失一些子树类型敏感的脆弱路径。本文根据当前工作的不足,构建了一个具备子树敏感变异能力和路径覆盖反馈能力的灰盒测试系统ILS。表1更清晰展示 ILS和现有工作的方法差异,主要从是否具备路径反馈能力、是否考虑JavaScript语法结构特征、是否采用子树覆盖变异、是否考虑同类型子树覆盖操作、是否开放工具源码、是否自动化程度较高这几个方面进行比较。

表1 ILS与现有相关工作的方法差异Table 1 The difference between ILS and existing JavaScript engine fuzzers
为了更直观地展示 ILS在漏洞检测能力上的提升,图4和图5给出了具体案例分析。如图4,Jerryscript引擎暴露的 CVE-2018-11418和 CVE-2018-11419两个缓存区溢出漏洞,二者的触发漏洞样本仅体现在RegExp函数中的参数有所不同,如果对CVE-2018-11418的漏洞触发样本中的参数部分进行变异就能快速的触发漏洞CVE-2018-11419。在后续的实际测试中,ILS通过同类型子树覆盖,提取CVE-2018-11418中的子树信息,发现如图5的两个未知缓存区溢出漏洞bug-3870和bug-3871。可以发现,这两个新漏洞样本只替换了CVE-2018-11418样本中RegExp函数的参数,该参数内容通过语法树解析得到的是同一种子树类型。
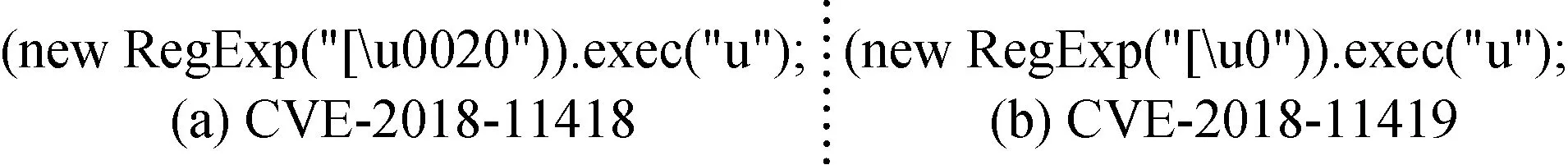
图4 已知的Jerryscript漏洞Figure 4 Existing Jerryscript vulnerabilities

图5 ILS新发现的漏洞Figure 5 New bugs found by ILS
3 ILS系统设计与实现
3.1 整体工作流程
本文所提出的ILS方法在AFL基础上进行扩展,更改了AFL的变异策略。ILS使用一种基于子树类型敏感的JavaScript引擎灰盒测试方法,降低了AFL在生成JavaScript代码时的错误概率,并具有更高的代码覆盖能力和漏洞发现能力。
AFL是谷歌开发的标杆性灰盒测试系统,它的工作流程如图6中的Execution所示,可以分为两步:对目标程序进行插桩和对已插桩的程序进行模糊测试。在插桩阶段,AFL对目标程序编译时,在每个基本块插入一段代码,用来记录当前基本块和上一个基本块的信息,主要代码如下:
1 cur_location =
2 shared_mem[cur_location ^ prev_location]++;
3 prev_location = cur_location >> 1;
cur_location的值是随机产生的,用来标记当前基本块,shared_mem数组记录上一个基本块和当前基本块这条边的命中次数,如果命中次数的分类发生改变,则认为产生了新的覆盖率,prev_location表示上一个基本块的标记值,右移一位是为了区分基本块的执行顺序。插桩完成后,AFL对已插桩的目标程序进行模糊测试,可以分为如下5个步骤:
1) 从输入队列(包括初始种子和产生新路径的测试用例)中挑选出一个种子;
2) 保证覆盖率不变的情况下减小种子的长度;
3) 对种子进行变异生成新的测试用例;
4) 执行新的测试用例,并监控目标程序执行状态;
5) 根据目标程序执行结果更新输入队列,然后转到步骤1。
通过不断循环上述5个步骤,AFL持续对目标程序进行测试,如果在步骤4中目标程序发生崩溃,则记录崩溃信息,并保存产生唯一崩溃的测试用例。
ILS的整体工作流程如图6所示,可以分为初始种子预处理和运行两部分,图中蓝色框部分是 ILS在AFL基础上增加的工作。ILS首先在初始种子预处理阶段通过相关语法分析工具对初始种子进行语法分析生成抽象语法树,然后对得到的抽象语法树进行类型识别和分类构建相同类型子树池,最后在变异阶段对测试输入增加语法分析,从同类型子树池中随机挑选出子树进行覆盖变异。下面,本文详细讨论ILS方法的实现细节。
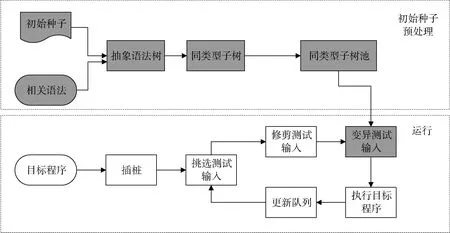
图6 ILS工作流程Figure 6 The workflow of ILS
3.2 初始种子预处理
ILS对初始种子进行语法分析得到抽象语法树,在语法树层次对子树进行类型识别,并按类型分类构建子树池,详细内容如算法1所示。算法输入为初始种子seeds和相关语法G。依次从seeds中选择一个seed进行解析,首先根据语法G将测试输入in解析成抽象语法树AST(第4行),解析过程中如果出现错误,则说明测试输入in是和语法无关的,将其舍弃(第 5~7行)。如果成功解析得到抽象语法树seed_ast,则依次访问语法树的每个节点,获取节点的类型和内容,并保存到typetree数据集合中(第8 ~12行),typetree是一个map容器,它的key为子树的类型,value是一个set容器,保存子树的内容。对所有的初始种子解析完成后,可以得到所有子树类型和子树内容集合typetree。根据typetree集合中每个类型的名字tree.id在数据库中创建对应的表,并在表中插入该类型的所有子树tree[id]构建同类型子树池(第 14~17 行)。

算法1.初始种子预处理输入: seeds: 初始种子,G: 相关语法1: type = ∅2: typetree[id][text]= //id is the type name,∅text is the set of subtree’s contexts 3: foreach seed in seeds do 4: parse seed into AST seed_ast according to G

5: if there are any parsing errors then 6: return 7: endif 8: ctx = VISIT(seed_ast) // ctx is the visiting node according to G 9: while ctx do 10: typetree[TYPEID(ctx)]= typetree[TYPEID(ctx)]∪ {GETTEXT(ctx)}11: VISITCHILDREN(ctx)12: endwhile 13: endfor 14: foreach tree in typetree do 15: CREATETABLE(tree.id)16: INSERTTABLE(tree[id])17: endfor
3.3 同类型子树变异
根据3.2节中得到的同类型子树池,更改AFL的变异策略,使用同类型子树覆盖变异生成新的测试用例进行模糊测试。算法2介绍了ILS同类型子树变异过程,算法输入为测试输入in,相关语法G和同类型子树池 typetree,输出为新生成的测试用例集合T。首先使用语法G对测试输入in进行解析,解析过程和算法1解析相同(第3~6行)。解析完成后,依次访问抽象语法树的每个节点,获取节点的类型和内容,并保存到 subtree数据集合中,此步骤和算法 1中访问语法树相同(第7 ~ 11行)。获取语法树所有节点类型和内容信息后,对语法树in_ast进行替换变异,依次选择子树类型集合tree[id],并把in_ast中tree[id]类型的每个子树s随机替换为子树池typetree[id]中同一类型的子树typetree[id][random],生成新的测试用例ret,并保存到集合T中(第12~20行)。最后返回测试用例集合T(第21行)。
参考其他相关工作中对单个测试用例变异的次数,本文选择单个测试用例最大变异次数为10000。通过 10000除以这个测试用例中的子树类型数目,再除以该类型子树个数得到每个子树的平均变异次数(第 14行),这样保证测试用例中每个子树都能被替换,并且保证每个子树类型的总替换次数相同。

算法2.同类型子树变异输入: in: 测试输入,G: 相关语法,typetree[id][text]: 同类型子树池输出: T: 新生成的的测试用例集合1: T= ∅2: subtree[id][interval]= ∅ //id is the type

name,interval is the set of subtree’s location 3: parse in into AST in_ast according to G 4: if there are any parsing errors then 5: return 6: endif 7: ctx = VISIT(in_ast) // ctx is the visiting node according to G 8: while ctx do 9: subtree[TYPEID(ctx)]= subtree[TYPEID(ctx)]∪ { GETTEXT (ctx)}10: VISITCHILDREN(ctx)11: endwhile 12: foreach tree in subtree do 13: foreach s in tree[id]do 14: count = 10000/subtree.size()/tree[id].size()15: foreach i in count do 16: ret = replace s in in_ast’s copy with typetree[id][random()]17: T = T ∪ {ret}18: endfor 19: endfor 20: endfor 21: return T
以下本文用一个例子详细介绍ILS的工作流程。使用图7a作为算法1中的初始种子,图7b作为算法2中的测试输入。图7a经过语法解析得到图8所示语法树,其中每一个非叶子节点和它的所有孩子节点表示一颗子树,该非叶子节点的类型表示了这颗子树的类型。从 program根节点开始访问该语法树,到

图7 输入种子和测试用例Figure 7 The original seed and test input

图8 抽象语法树ASTFigure 8 Abstract Syntax Tree
从表2中可以看到,在不同的类型中,可能它们的子树是相同的,如图4红色框部分的子树 a(),它的类型有 FunctionBody、ExpressionSequence、ArgumentsExpression 3种。这增加了子树类型的丰富性,在 ILS子树变异过程中可以更有效的生成新的测试用例。

表2 图7a通过语法分析得到的类型和内容Table 2 The type and context obtained through syntax analysis from figure 7a

在同类型子树替换变异阶段,对图7b通过语法分析得到表3。依次选择表3中的Id的每个子树替换为表2中相同Id的子树,可以得到3个新的测试用例,如下所示:在语法解析过程中还能得到 Program、SourceElements、Statement等类型的子树,第一个类型表示整颗语法树,进行整个语法树替换变异是没有意义的,第二、三个类型表示的是这个子树的源元素和状态,在整个语法树中会多次出现,但是并没有实际意义,所以删除这些无用的类型,只保留具有一定意义的子树类型,如表2中一共得到10种不同有意义的类型。

表3 图7b通过语法分析得到的类型和内容Table 3 The type and context obtained through syntax analysis from figure 7b
和ILS相比,Superion的子树替换策略是无类型的,这样在替换的时候会造成很多错误,如图7b中的数字1被图7a中的a()替换,生成var a = a(),会造成TypeError。但是ILS同类型子树替换策略就会减少这类问题,Literal类型的数字1只能被表2中同类型的true子树替换,生成新的测试用例var a = true,可以顺利被解析引擎运行。
3.4 实现细节
本文在AFL基础上,使用C/C++语言实现子树类型敏感的灰盒模糊测试系统 ILS。该系统使用ANTLR 4[54]作为语法分析工具对初始种子进行词法分析和语法分析,获取初始种子的类型和子树构建同类型子树池,在子树变异阶段,使用ANTLR 4对测试输入进行词法分析和语法分析,随机从子树池中挑选同类型的子树替换测试输入中的每个子树生成新的测试用例。
该系统充分利用了 AFL的优势,能够对目标进行快速测试,并通过覆盖率反馈,提高对目标的代码覆盖率,增加发现漏洞的概率。而且该系统容易扩展,扩展相关的语法可以对其他结构化语法输入对象(如XML解析器)进行测试。
4 实验与测试分析
4.1 实验设置
为了验证 ILS的有效性,本文将此模型与Superion和CodeAlchemist进行实验对比,在表1所列出的开源工具中,Superion是基于子树变异的模糊测试方法中的典型工具,在相关JavaScript引擎中发现了23个未知的Bug,CodeAlchemist是基于生成的模糊测试方法中的典型工具,在相关JavaScript引擎中发现了11个未知的Bug。本文与这两个工具进行实验对比,可以体现出ILS方法的先进性。
本文分别从漏洞发现能力、代码覆盖能力、测试例有效率、执行速度4个方面进行性能对比: 漏洞发现能力最能体现出工具的有效性; 代码覆盖能力是衡量测试结果好坏的基本标准,能够整体上体现出模糊测试工具的效果; 生成测试用例有效性对于JavaScript引擎的模糊测试来说尤其重要,一般随机变异产生的测试用例都不能被JavaScript引擎解析运行; 执行速度是模糊测试工具中重要的一环,表示时间效率。
本文选择三个开源的JavaScript引擎JerryScript、ChakraCore和 JavaScriptCore作为测试对象,JerryScript版本为2.2.0,ChakraCore版本为1.12.0.0-beta,JavaScriptCore版本为2.27.4。JerryScript是三星集团开发的轻量级物联网JavaScript引擎,适用于嵌入式设备,只需要很低的CPU的性能和内存空间。ChakraCore是 Microsoft Edge浏览器中 Chakra JavaScript引擎的核心部分。JavaScriptCore是WebKit浏览器的JavaScript解析引擎部分,WebKit是一个跨平台的浏览器引擎,它支持 Safari、iBook和 App Store,以及各种Mac系统,iOS和Linux平台。
为了平衡实验的系统资源开销,本文对这 3个模糊测试工具都只使用 4个并行进程进行实验,保证同时运行4个JavaScript引擎,在一定程度上体现系统资源的公平性。
在测试用例方面,对 JerryScript引擎收集了1698个测试用例,对ChakraCore引擎收集了1766个测试用例,对JavaScriptCore引擎收集了2713个测试用例。
实验中所用机器为带有 64G内存的 Dell PowerEdge R740,操作系统为64位的Ubuntu 18.04。本文参考其他相关工作的测试时间,一般测试时间为24 h,所以本文也对JavaScript引擎测试24 h。由于模糊测试具有随机性,所以重复进行 10次实验,对代码覆盖率、测试例有效率、执行速度取平均值进行对比,并对比10次实验的漏洞发现总数。
4.2 漏洞发现能力
重复进行10次24 h实验后,Bug发现情况如表4所示。在Bug发现率方面,ILS相比于Superion提升了100%。CodeAlchemist并不支持对JerryScript引擎进行测试,而且在ChakraCore和JavaScriptCore引擎中都没有发现Bug。表5详细列出了截止本文写作时间,ILS发现的所有Bug具体信息,共发现26个不同的Bug。在JerryScript引擎中,共发现22个Bug,包括1个Use-After-Free、3个Buffer Overflow、2个Stack Overflow、1个 Memory Corruption和 15个Assertion Failure。在ChakraCore引擎中,一共发现3个Assertion Failure。在JavaScriptCore引擎中,一共发现1个 Memory Corruption。由于CodeAlchemist并没有发现Bug,所以没有放入表5中进行对比。

表4 24 h Bug发现情况对比Table 4 The comparison of Bug discovery in 24 hours

表5 ILS发现的BugTable 5 The Bugs found by ILS
① https://github.com/jerryscript-project/jerryscript/issues/created_by/owl337
② https://github.com/microsoft/ChakraCore/issues/created_by/owl337
③ https://bugs.webkit.org/show_bug.cgi?id=212460
4.3 代码覆盖提升
在模糊测试中,代码覆盖率是衡量测试结果好坏的基本标准,能够整体上体现出模糊测试工具的效果,代码覆盖率越高,越有可能发现新的Bug。
本文分别对JerryScript和JavaScriptCore进行了覆盖率对比实验,并使用 afl-cov[55]收集覆盖率信息,结果表明ILS、Superion和CodeAlchemist对代码行覆盖率和函数覆盖率都有提升,ILS提升效果更好。因为CodeAlchemist不支持测试JerryScript解析引擎,所以没有进行JerryScript解析引擎的覆盖率对比。
对于JerryScript,实验结果如图9所示。在代码行覆盖率方面,ILS相比于Superion提升48%,在函数覆盖率方面,ILS相比于Superion提升41%。
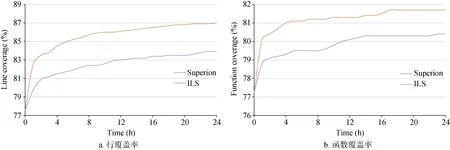
图9 JerryScript引擎覆盖率对比Figure 9 The comparison coverage rate of JerryScript
对于JavaScriptCore,实验结果如图10所示。在代码行覆盖率上,ILS相比Superion提升了72%,相比CodeAlchemist提升48%; 在函数覆盖率上,ILS相比Superion提升80%,相比CodeAlchemist提升58%。

图10 JavaScriptCore引擎覆盖率对比Figure 10 The comparison coverage rate of JavaScriptCore
4.4 测试用例有效率提升
生成测试用例有效性对于JavaScript引擎的模糊测试来说非常重要,一般的模糊测试工具如 AFL,随机变异产生的测试用例基本上都是无效的,因为如果不符合对应的语法规则,解析引擎将拒绝继续执行,所以很难发现系统运行时的Bug。
图11显示了生成测试用例错误率的实验结果,ILS、Superion和 CodeAlchemist的平均错误率分别是46.16%,58.74%和72.49%。因为ILS在替换子树时没有对子树的引用进行检查,所以 ILS的ReferenceError错误是最多的,但是ILS能有效的减少其他的错误率,种子测试有效率比 Superion提升了36%,比CodeAlchemist提升了21%。
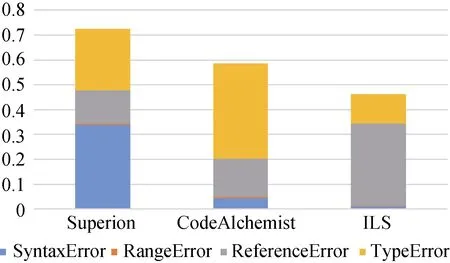
图11 生成种子错误率对比Figure 11 The error Comparison of new seeds
4.5 执行性能分析
执行速率表示单位时间内调用目标软件运行的次数,执行速度越快,越有可能在短时间内发现新的Bug。
本文统计10次实验每个工具生成的测试用例个数,并平均计算得到每个JavaScript引擎每秒运行次数,结果如表6所示。由于ILS和Superion都是基于AFL开发的,具有AFL的forkserver模式加速,所以执行速度快,CodeAlchemist是自己控制JavaScript引擎执行,并没有对执行速度进行优化,所以性能较低。在 JerryScript引擎中,平均执行速率 ILS比Superion每秒降低了3.03次; 在Chakracore引擎中,平均执行速率ILS比Superion每秒降低了1.01次; 在JavaScriptCore引擎中,整体平均执行速率 ILS比Superion每秒降低了2.6次。

表6 每秒执行速率对比Table 6 The execution rate pre second comparison
ILS执行速率比Superion有所降低。但总体来说相差不大,在覆盖率提升显著的情况下,这个执行速率的差异是可以接受的。
5 总结与讨论
本文详细分析了针对JavaScript引擎的模糊测试技术,并在路径反馈的模糊测试框架基础上提出一种基于子树类型敏感的JavaScript引擎灰盒测试方法ILS。该方法通过对JavaScript代码进行语法分析,把子树进行识别分类,并在变异过程中使用同类型子树进行替换变异。实验结果表明,该方法能显著提升生成测试用例的有效率,并具有更高的代码覆盖能力,而且发现了26个新的Bug。
ILS在下一步工作中,将结合基于生成的模糊测试技术,对JavaScript代码进行更细粒度的控制流分析和数据流分析,在子树替换变异过程中消除引用未知变量,进一步消除引用错误以提升代码生成的有效率。
