一种基于知识蒸馏的神经网络鲁棒性迁移方法
2021-08-25张维,易平
张 维,易 平
上海交通大学网络空间安全学院 上海 中国 200240
1 引言
深度学习模型在众多计算机视觉领域[1-3],取得非常出色的效果。人工智能算法已经渗透到了我们的日常生活中的方方面面,例如人脸识别系统,城市大脑等等。但是,深度学习算法极其容易被对抗样本攻破[4,36],通过在图像输入中,添加极其微小的扰动,就可以改变深度学习模型的决策。在一些对于安全性要求非常高的场景下,例如自动驾驶的感知,对抗样本的危害显得尤为明显,Eykholt等人[5]提出了一种通用的攻击框架,通过给路标添加扰动,使得机器将“右转”标识识别为“停止”标识,将“停止”标识识别为“限速”标识等等,这类标识在不同的拍摄角度下,都可以完成对相机感知系统的攻击,如下图1所示。对抗样本在自动驾驶场景下,会带来难以估量的损失,因此,防御对抗样本对于深度学习算法的应用具有重大价值。

图1 交通场景下的对抗样本Figure 1 Adversarial examples in traffic scenarios
因为对抗样本在深度学习领域潜在的安全风险,近些年来,对抗样本一直是学术界的研究重点,涌现了大批关于攻击与防御的工作。目前最有效的防御对抗样本的方法是对抗训练[6],对抗训练的思想非常简单但也非常有效,即在训练中将生成的对抗样本加入到训练集中,从而对网络进行迭代优化,将 min-max的优化结合到训练中。但是对抗训练的劣势也非常明显,生成强大的对抗样本需要多次迭代,即神经网络需要多次的反向传播,导致训练的代价大大增加,从训练时间长来看,对抗训练一般是正常训练的数倍,一定程度上限制了对抗训练的应用。
为了减少对抗训练的代价,近期出现了用迁移学习的方法提升模型鲁棒性的工作,即将神经网络的鲁棒性从一个模型中迁移到其他的任务上[7]。一种方法将神经网络的参数作为媒介迁移鲁棒性,将模型的基础层固定,仅在新的任务上微调最后几层的参数,微调后的网络仍然保留了非常不错的鲁棒性;另一种思路利用知识蒸馏[7-8]迁移模型的鲁棒性,将鲁棒模型作为教师网络,利用KL散度约束教师网络与学生网络之间的表征层特征,知识蒸馏使用的是模型的表征层特征作为迁移媒介。这两种思路,均取得了不错的白盒防御效果。
我们提出了一种鲁棒性迁移的方法(Robust-KD),不通过对抗训练,就可以获得具有很强白盒防御能力的模型。受注意力迁移[9]与鲁棒模型性质[10]启发,我们利用特征更加丰富的特征图作为知识蒸馏的媒介迁移鲁棒性,与表征层不同,浅层的特征图编码了低层次的特征,深层的特征图编码了高层次的语义特征,特征图包含的信息量更加丰富; 同时,我们在使用特征图作为约束的基础上,还加入了Jacobian矩阵的约束,Jacobian矩阵很好地反映了深度网络的梯度特征,我们通过计算特征图与输入层之间的Jacobian矩阵,并且使用了一种高效的方法,将Jacobian矩阵作为约束,融合到我们知识蒸馏模型的求解框架中。
迁移学习[11]的成功是计算机视觉的里程碑之一,在较大数据集上(例如 ImageNet[12])学到的特征,可以很好地迁移到其他任务上,预训练方法已经成为了深度学习领域最常见的一种方法。相应地,我们在ImageNet数据集上进行对抗训练,得到鲁棒的神经网络,该鲁棒网络很好地编码了通用的鲁棒性特征。在一些小的任务上(例如 Cifar10)进行知识蒸馏,以较小的代价,就可以获取很强的对抗样本防御能力。
通过在 ImageNet、Cifar100、Cifar10上的实验结果,显示了本文提出的知识蒸馏方案的有效性,特征图与 Jacobian矩阵的约束,很好的增强了模型的白盒防御能力。在扰动较小时,学生网络的防御能力甚至已经接近对抗训练,而且在干净样本的准确率上,本文提出的训练方法也非常可观,相较正常训练,并没有损失很多。
总之,我们的贡献可以概括为以下三点:
1) 提出了一种鲁棒性迁移的方法,可以以较低的代价(非对抗训练),获得不错的对抗样本防御能力。
2) 验证了特征图与 Jacobian矩阵约束,在提升模型鲁棒性上的有效性。
3) 做了大量的实验,为鲁棒性迁移提供了一个很好的基线。
2 背景与相关工作
我们回顾下对抗样本模型鲁棒性的一些概念,并介绍本文用到的基于梯度的攻击算法,目前的对抗样本防御算法以及知识蒸馏等等。
2.1 模型鲁棒性
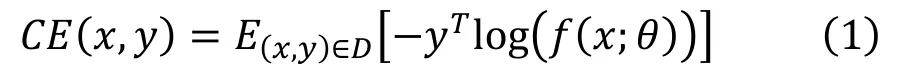
在干净的测试样本上,通过该训练目标得到的深度学习模型,可以获得非常不错的效果,但是在对抗样本上,该模型的准确率下降非常多。我们在这里给出鲁棒模型的定义,一个鲁棒的模型应该满足以下条件
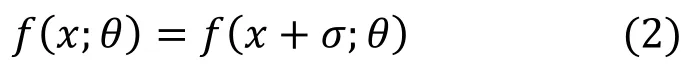
在鲁棒模型的定义下,鲁棒模型的决策并不会因为对抗扰动的加入而改变,因此鲁棒模型在对抗样本上依然会保留可观的准确率,在后续的实验部分,我们也会通过模型在不同扰动程度下的对抗样本上的准确率,表明我们方法的有效性。
2.2 基于梯度的攻击算法
生成对抗样本可以看成一个带有限制的优化问题,优化的目标方程为

为了求解这个优化问题,在白盒攻击的场景下,可以将梯度反传到输入层,求解噪声使得交叉熵损失函数变大。一些工作已经被提出来求解上述的目标方程,这里我们给出一些简单的介绍。
2.2.1 快速梯度标志攻击
快速梯度标志攻击(Fast Gradient Sign Method,FGSM)[13],通过反向传播,将损失函数反传到输入层,并且通过梯度方向更新输入图片生成对抗样本,从而达到欺骗分类器的目的,其生成对抗样本的方法如下
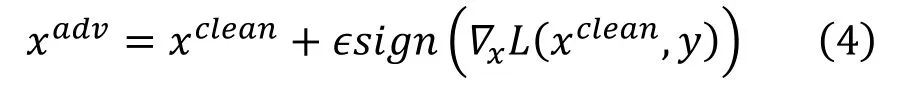
其中 ∇xL 是反传回输入层的梯度,是符号函数,∊ 一般用来调整FGSM攻击的扰动程度,∊ 越大,生成的对抗样本攻击能力越强。
FGSM算法较为简单,可以快速生成大量的对抗样本,但是生成的对抗样本大多攻击能力比较一般。
2.2.2 映射梯度下降法
映射梯度下降法(Projected Gradient Descend,PGD)[6],是 FGSM 算法的改进,可以看成是多步迭代版本的FGSM,PGD为了保证扰动满足 L2或者 L∞的限制,在迭代的过程中引入了映射的过程,将扰动映射回 L2或者 L∞的球中,其迭代过程如下
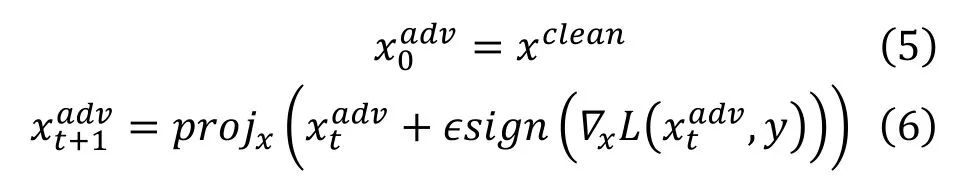
与FGSM相比,PGD算法攻击强度更强,但是生成对抗样本的耗时也是 FGSM 的数倍,大多数情况下,PGD迭代次数越多,生成的对抗样本攻击能力越强。
2.2.3 动量迭代梯度标志攻击
动量迭代梯度标志攻击(Momentum Iterative Fast Gradient Sign Method,MI-FGSM)[25],是由Dong提出的一种增强攻击迁移性的方法。过去的迭代式的攻击方法(PGD),黑盒攻击效果很差,迭代得到的解容易陷入局部最优点。Dong将优化器中常用的动量(Momentum)引入到对抗样本的生成中,其中梯度方法的积累公式如下

与 PGD攻击算法的区别在于,更新梯度的过程中,通过 μ 控制累积梯度的更新速度,从而很好的缓解了过拟合现象,大大提升了算法的黑盒迁移效果。
2.2.4 Carlini-Wagner攻击
Carlini-Wagner攻击(CW 攻击)[26],是一种基于优化的对抗样本生成方法,与 PGD算法不同,PGD算法通过投影的方法限制扰动的幅度,是非常粗粒度的; 而CW则是在优化的目标函数的中,加入了扰动的范数,在保证攻击效果的同时,使求解得到的扰动尽可能小。CW函数的优化目标为
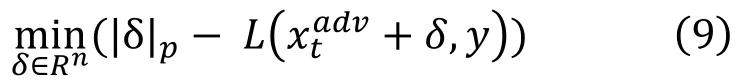
其中 |∙|p为扰动的范数,该目标函数保证了 CW 攻击能够以较小的扰动实现强有力的攻击。虽然相比PGD攻击算法,CW攻击可以构造出扰动更小的对抗样本,但是CW攻击的复杂度也比PGD攻击算法要高得多。
2.3 现有的防御算法
已有的防御方法可以分为两个主要流派,一种是使用对抗训练的防御方法,即在训练中实时生成对抗样本,并将生成的对抗样本作为训练集反哺给模型; 另一个是非对抗训练的方法,会更加关注于深度模型的一些性质。
2.3.1 对抗训练防御
对抗训练(Adversarial Training,AT)[6],是Madry提出的一种对抗样本防御的方法,也被称为 Madry Defense,是目前防御对抗样本最为有效的一种方式。Madry在[6]的工作中,将防御对抗样本定义为一个min-max优化的问题,生成对抗样本的目标是为了增大损失函数,使深度学习模型决策错误; 防御对抗样本又是为了减少这类样本的损失函数,这样就形成了一种对抗,Madry给出了一种求解方式

其中 σ 为对抗扰动,通过PGD算法求解得到。对抗训练在防御对抗样本上效果非常好,几乎对于所有基于一阶导数的攻击,都有着非常不错的防御效果。考虑到PGD攻击算法的复杂度,对抗训练的缺点同样非常明显,对抗训练的代价是正常训练的数倍,这也限制了对抗训练算法的应用。
后续也有非常多的工作改进对抗训练,Zhang等人[14]使用对抗样本与干净样本特征之间的距离作为目标函数,生成了更加高效的对抗样本,提升了对抗训练的效率。Zhang等人[15]从平滑模型决策边界出发,构造正则项,通关该正则项约束对抗样本与干净样本之间的决策偏差,提升了对抗训练得到的模型的泛化性。Qin[27]认为对抗的耗时是由神经网络的非线性导致的,Qin提出了一种正则化的方法,约束真实损失函数与估计的线性损失函数之间的差,从而惩罚梯度混淆,提升了对抗训练的效果。
2.3.2 非对抗训练防御
近几年也有一些不使用对抗训练的防御策略,Ross等人[16]分析鲁棒模型的性质,发现对抗训练得到的模型在输入层梯度上,与普通模型呈现出不同的模式,如下图2所示,Ross利用了这一特性,通关两次反向传播的方法[28]约束输入层梯度的Frobenius norm,取得了不错的防御效果。

图2 模型输入层梯度可视化Figure 2 The visualization of input layers’ gradient
与 Ross的策略类似,Hoffman等人[17]利用Jacobian矩阵作为神经网络的正则项约束网络求解,Hoffman从泰勒展开出发,证明了约束Jacobian矩阵的 L2范数可以使模型决策边界更加平滑,Hoffman给出了一个随机投影的策略,很好地将 Jacobian矩阵作为损失函数,加入到了神经网络的求解过程中。
Chan等[29]很好地运用了Ross提出的性质,他认为一个鲁棒模型的梯度图像应该与原始图像存在对应关系,所有 Chan构造了一种正则损失函数,使得模型梯度图像与原始图片相对应,大大增强了模型鲁棒性。还有一些工作[30-31]尝试从模型性质上,寻找对抗样本生成的边界,这类防御首先从理论上证明了边界的存在,再优化这个边界,使得对抗样本更难生成,从而达到增强模型鲁棒性的目的。
我们的工作首次尝试将Jacobian矩阵作为知识蒸馏的载体,在提升模型鲁棒性上取得了不错的效果。
2.3.3 对抗样本检测
上述两节主要关注的是模型鲁棒性,即模型对于对抗样本具有容忍性,可以将对抗样本分类正确,目前还有一种防御对抗样本的思路,即将异常的对抗样本检测出。对抗样本检测算法关注的是如何衡量正常样本的分布,从大量的数据中找出异常点,使用统计学的方法或者基于神经网络的方法挖掘异常特征。
Ma等人[32]提出了局部本征维度(Local Intrinsic Dimensionality,LID)的方法,检测对抗样本是否存在,LID通过 K-Means算法[33]刻画正常样本的分布,将干净样本聚类得到 N 个中心,越远离聚类中心的点,是对抗样本的概率越高。Meng等人[34]提出了一种基于重构误差检测对抗样本的方法,Meng训练了一个自编码器来实现样本的编码与解码,通过自编码器学习干净样本的分布,因为对抗样本并未出现在自编码器的训练数据中,对抗样本编码解码后得到的图像与输入图像差别大于干净样本编解码,通过这种方法实现对抗样本的检测。Xu等人[35]提出了一种基于特征压缩(Feature Squeezing)的对抗样本检测方案,该方法将原样本(0~255 bit)压缩到新的像素空间(0~8 bit),像素空间的压缩,可以减少对抗样本中微小扰动所带来的误差,将压缩后的图像结果与原样本结果比对,从而分辨出原样本是否为对抗样本。
2.4 知识蒸馏
知识蒸馏这个概念最早由Hinton等[8]提出,一般认为神经网络训练中编码了很强的先验知识,这些知识在不同的任务之间具有一定的迁移能力,Hinton设计了一种训练框架,该框架中含有两个神经网络,一个被称为教师网络,另一个为学生网络。Hinton先训练好教师网络,后将教师网络的输出作为学生网络的监督,这种范式常被用来训练轻量级网络,使用大网络的输入监督小网络,小网络可以保留接近大网络的性能。
Shafahi等人[7]首次用知识蒸馏的方法来训练鲁棒模型,Shafahai 使用在 Tiny-ImageNet[18]上对抗训练得到的模型作为教师模型,使用鲁棒模型的输出来监督新网络的学习,取得了非常不错的防御效果。这种模式很好地将迁移学习的思想融入到模型鲁棒性的增强上来,以教师网络输出与学生网络输出之间的KL散度约束迁移鲁棒性。
但是知识蒸馏是为了模型在干净样本上的准确率的提升而设计的,在鲁棒性迁移上,模型的输入是干净样本而不是对抗样本,我们猜测基于 KL散度的知识蒸馏并非是最优的选择,在本文中我们简单地探讨了在鲁棒性迁移场景下,知识蒸馏方法的改进。
3 神经网络鲁棒性迁移
我们的工作解决的是鲁棒性迁移的问题,即如何将鲁棒的教师网络的特征迁移到正在训练的学生网络中。我们的工作分为三部分叙述,第一部分是方法的概述; 第二部分是基于特征图的鲁棒性迁移;第三部分是基于Jacobian矩阵的鲁棒性迁移。
3.1 总览
首先简单介绍下我们的方法,教师网络在较大的数据集(例如ImageNet)上通过分类任务训练得到。我们期望该鲁棒网络的特征是可以迁移到多个任务上的,相较于 Hinton的早期版本的知识蒸馏,本文期望构建一个更加通用的方法。
受Li等人[19]与Shafahi等人[7]工作的启发,我们设计了一种蒸馏的框架,学生网络与教师网络在结构上保持一致,因为目标任务类别会与 ImageNet不一致,所以以神经网络中的特征图作为迁移鲁棒性的媒介,而非基于logits,方法的整体框架见下图3。
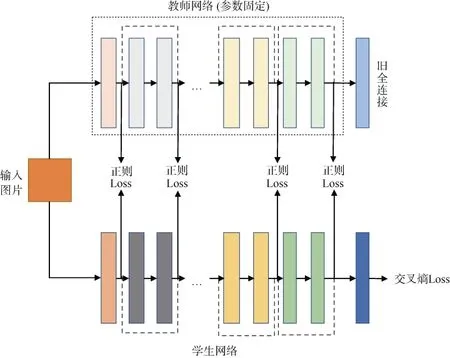
图3 鲁棒性迁移框架Figure 3 The framework of robustness transfer
假设教师网络为 fteacher,学生网络为 fstudent,教师网络与学生网络的特征图分为,,表示教师网络前向时输出的第 i个特征图(feature map),特征图满足

Shafahi等人[7]的知识蒸馏,只在最后一个特征层上约束(Global Average Pooling,GAP),池化的操作损失了大量的空间信息,其损失函数为

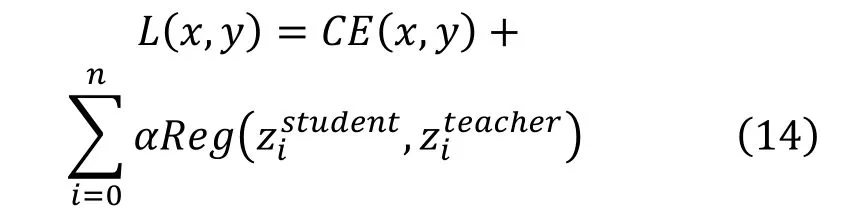
在下面两节中,我们将详细介绍正则项的设计。
3.2 基于特征图的鲁棒性迁移
在本部分,我们将介绍基于特征图约束的方法,以及约束方式的选择。在衡量两个分布时,通常选用的指标有KL散度[20]、L2距离、Cosine距离[21]等。
大多数知识蒸馏工作一般也使用的是 L2距离作为衡量教师网络特征与学生网络特征的指标。但是在实验中发现,因为教师网络训练的数据集与当前训练的数据集,会存在较大的分布上的差异,这种差异会导致学生网络与教师网络输出的特征图,在量级上存在些许差异,而 L2距离对于量级的变化极其敏感。
所以在训练中,我们引入了 Cosine距离作为衡量教师网络特征图与学生网络特征图之间差异的指标,Cosine距离的定义如下
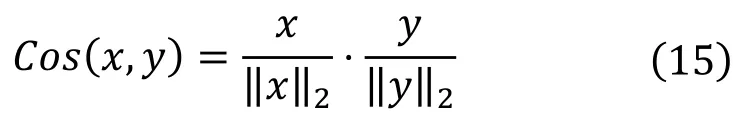
在具体实现时,教师网络的参数是固定的,且不进行反向传播的,对于目标数据集的图片输入,仅保留教师网络的每一层的特征图,对于学生网络,训练的损失函数为交叉熵损失与Cosine正则损失之和

通过这一损失函数,可以在不损失过多准确率的前提下,尽可能保留鲁棒教师网络的各层特征表达。为了提升效果,学生网络使用教师网络作为预训练模型,在教师网络的参数基础上微调,后面所有的实验也都建立在使用预训练模型的基础上。
3.3 基于Jacobian矩阵的鲁棒性迁移
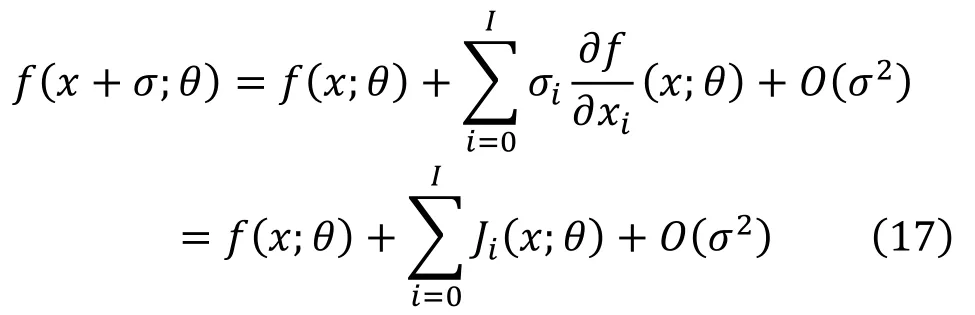
Ji为输入 xi对应的 Jacobian 矩阵,通过泰勒展开我们可以发现,模型对于噪声的响应,与Jacobian矩阵存在着非常高的关联性。对于一个鲁棒的 模 型 ,其 满 足即可以发现模型是否鲁棒与神经网络的 Jacobian矩阵具有非常强的相关性,对抗训练后的鲁棒性网络对于对抗样本是有一定的鲁棒性的,在鲁棒性知识蒸馏中,我们期望学生网络获得鲁棒的教师网络的 Jacobian矩阵性质,所以在此处我们将尝试以 Jacobian矩阵作为鲁棒性迁移的媒介,尝试从鲁棒教师网络中迁移鲁棒性。
与3.2一致,我们期望在神经网络的多层中间层中添加Jacobian约束,但是中间层的Jacobian矩阵维度极高,用来直接约束神经网络的求解不现实,所以需要设计一种降维的方法。受 Hoffman等人[17]工作的启发,这里我们引入了一种随机投影的方法,通过多次投影,去近似完整的Jacobian矩阵,从而大大降低了运算的复杂度。假定图片输入的维度为 I,中间特征层的维度为 O,那么中间特征层相对图片输入的Jacobian矩阵为 J∊RI×0满足
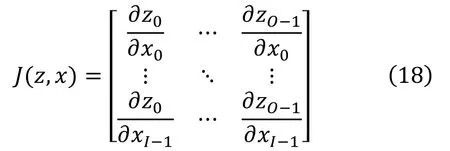
在训练时,每一次求Jacobian矩阵时,我们都会随机生成一个 L2范数为 1的 mask,这里记为M∊RO,通过mask与特征图相乘,求得中间特征图在 mask方向投影后的长度,通过这种方法,将特征图转化为标量,大大减少了计算复杂度,简化后的Jacobian矩阵为
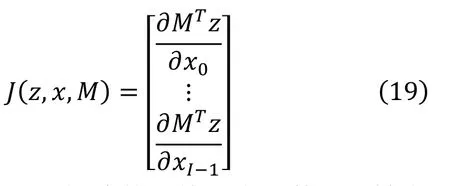
基于 Jacobian矩阵的训练损失函数可以被定义为
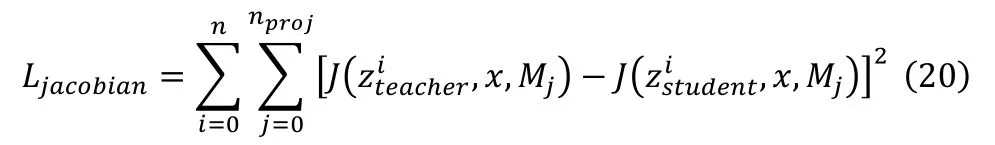
其中 nproj为投影映射的次数,nproj越大计算复杂度越高,但是能够更好地逼近特征图与输入之间的Jacobian矩阵。算法的具体流程见算法1。

算法1 基于J a c o b i a n矩阵的鲁棒性迁移输入: 目标数据集D,教师网络f teacher,学生网络f student学习率β,随机投影次数 n proj输出: 鲁棒的学生模型 f student teacher… ← f teacherimages/BZ_69_1887_1137_1929_1179.pngximages/BZ_69_1929_1137_1971_1179.png ▷ 前向计算教师网络特征图z 0 student,z 1 student… ← f s t u d e n timages/BZ_69_1889_1268_1931_1310.pngximages/BZ_69_1930_1268_1972_1310.png ▷ 前向计算学生网络特征图f o r j ∊ images/BZ_69_1517_1397_1559_1439.png0,1,...,n proj-1images/BZ_69_1839_1397_1881_1439.png d o生成随机m a s k M j b e g i n f o r t r a i n i n g I t e r a t i o n d o从 D 中随机采样 (x,y)z 0 t e a c h e r,z 1 i ,x,M jimages/BZ_69_1836_1531_1878_1573.png ▷ 计算学生网络J a c o b i a n矩阵J s t u d e n t i ← J■z t e a c h e r i ,x,M jimages/BZ_69_1835_1664_1876_1705.png ▷ 计算教师网络J a c o b i a n矩阵L j J t e a c h e r i ← J■z t e a c h e r i images/BZ_69_1795_1806_1837_1848.png2 ▷ 计算教师网络与学生网络J a c o b i a n矩阵损失e n d L o s s←C Eimages/BZ_69_1572_2001_1614_2043.pngx,yimages/BZ_69_1653_2001_1695_2043.png+∑ ∑ L j i← ■J s t u d e n t i -J t e a c h e r n i=0 ▷ 更新总损失n p r o j j=0 i函数更新 f student 参数e n d r e t u r n f student e n d
3.4 小结
我们的方法是基于特征图的约束与基于Jacobian矩阵约束的结合。特征图的约束可以很好地使学生网络保留教师网络的特征,而 Jacobian的加入在梯度上进一步约束网络的求解,最终的损失函数为

α 与 β 为正则项损失函数的权重。
4 实验结果及其分析
我们在 Cifar10、Cifar100、ImageNet上进行了大量的实验,将从实验设置、基于特征图与Jacobian矩阵约束的作用、约束特征层深度影响、Cosine距离的作用、损失函数权重的影响、 nproj选取、不同数据集上算法效果等方面论述我们提出的方法的有效性。所有实验均在白盒攻击场景下进行。
4.1 实验设置
本部分工作主要是为了验证我们的算法在模型鲁棒性迁移上的效果,我们的教师网络与学生网络均保持一致,使用的是 ResNet50[22],这里的网络是针对32*32大小的图像重新设计的网络,在Cifar10、Cifar100、32*32大小的ImageNet上可以获得非常不错的效果。
在本部分中,为了保证算法的泛化性尽可能强,我们在评估评估算法的时候,使用了多种攻击算法,包含FGSM,L2PGD攻击算法,L∞PGD攻击算法,这些算法均为无目标攻击。对于L∞攻击算法,我们攻击的最大扰动分别选取了,对于 L2攻击算法,我们攻击的最大扰动分别选取了0.25与0.5,对于迭代式的攻击,假设最大扰动为 ∊ ,攻击的步长为如无特殊说明,本部分的实验 PGD 攻击算法的迭代次数均为7。
对于鲁棒性教师网络,我们分别在 ImageNet、Cifar100这两个数据集上,通过对抗训练的方法得到了两个鲁棒的模型,对抗训练中使用的攻击方法是L2PGD攻击算法,攻击最大扰动为0.5,训练使用的是带有momentum的SGD[23]算法,momentum为0.9,weight decay为5e-4,在ImageNet数据集上,我们会将图片变换成32*32的大小。
对于学生网络,学生网络在训练时的输入均为干净的样本,教师网络的参数固定,学生网络训练的超参数与教师网络保持一致,为了加快训练速度,学生网络均使用了对抗训练后的教师网络作为预训练模型,α 选取为 50,β 选取为 5e-3。
本文所有实验均在 Pytorch[24]框架下实现,本部分会涉及算法效率的比对,所有的实验均在 Tesla v100-sxm2 显卡下运行。
4.2 算法效果
这部分在Cifar10数据上对比算法效果,通过准确率来评价模型鲁棒性的强弱,如果该模型能够将越多的对抗样本分类正确,那么则说明该模型的鲁棒性越强,防御对抗样本的能力越强。
我们首先在Cifar10上以正常训练以及对抗训练两种方式,训练了两个模型作为我们的基线,为了对比公平,这两个模型同样也使用了预训练模型。我们在同样的设置下,复现了Shafahi[7]的工作,通过与Shafahi[7]工作的对比,来体现我们算法优越性。我们同样比对了分为去除掉基于特征的约束项与去除掉基于 Jacobian矩阵的约束项的效果,在本部分中nproj为1。在PGD攻击上的效果如下表1所示。
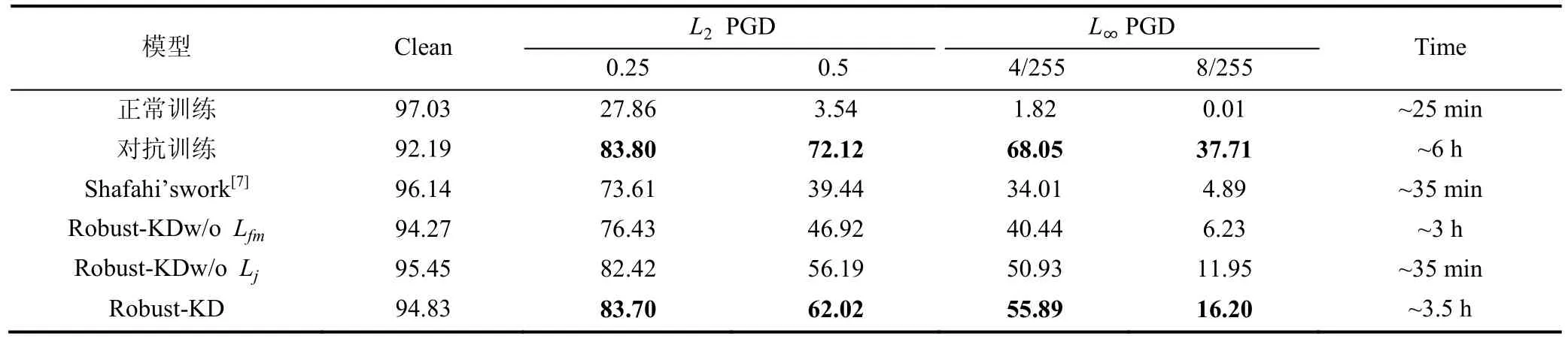
表1 PGD攻击算法在Cifar10上的分类准确率(%)Table 1 Accuracy(%) of PGD attack on Cifar10
通过对比,可以发现我们的算法在对于鲁棒性蒸馏的效果非常好,在受限的训练时间下,可以获得接近对抗训练的防御效果,此外我们的防御方法在干净样本上依然保留了很高的准确率。相较于Shafahi等人[7]的工作,我们的鲁棒性迁移的效果更强,可以将更多的对抗样本识别正确。因为计算Jacobian矩阵要进行多次反向传播,所以虽然带入Jacobian约束的防御方法在防御效果上有一定提升,但是需要耗费非常多的计算资源。
同样,我们还在 FGSM 攻击算法上测试了我们的防御模型,如下表2所示。

表2 FGSM攻击算法在Cifar10上的分类准确率(%)Table 2 Accuracy(%) of FGSM attack on Cifar10
在 FGSM 下,我们的算法同样有非常不错的防御效果,在扰动为的FGSM攻击算法下,可以获得接近对抗训练的效果。此外,在更加强大的 PGD攻击下,我们测试了模型的效果。一般来说,PGD攻击算法的迭代次数越大,相应的攻击越强,此处我们分别测试了迭代次数为0、7、25、100、250与1000的白盒攻击下,模型的准确率。下图4展示了模型防御 0.5扰动下不同迭代次数的 L2PGD攻击的效果,下图5展示了模型防御扰动下不同迭代次数的L∞PGD攻击的效果。
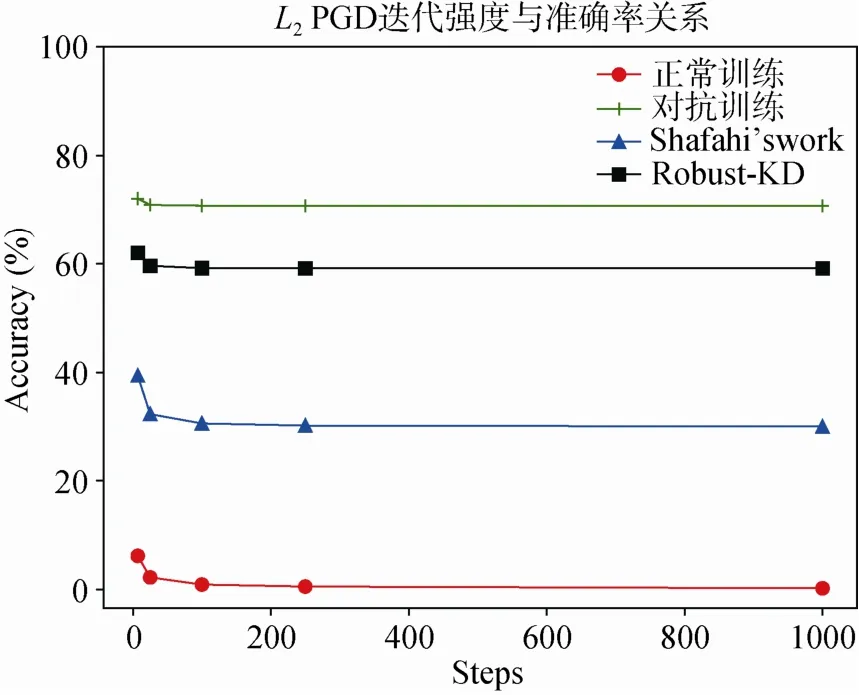
图4 L2 PGD迭代强度与准确率(%)的关系Figure 4 The relationship between steps of L2 PGD attack and accuracy (%)
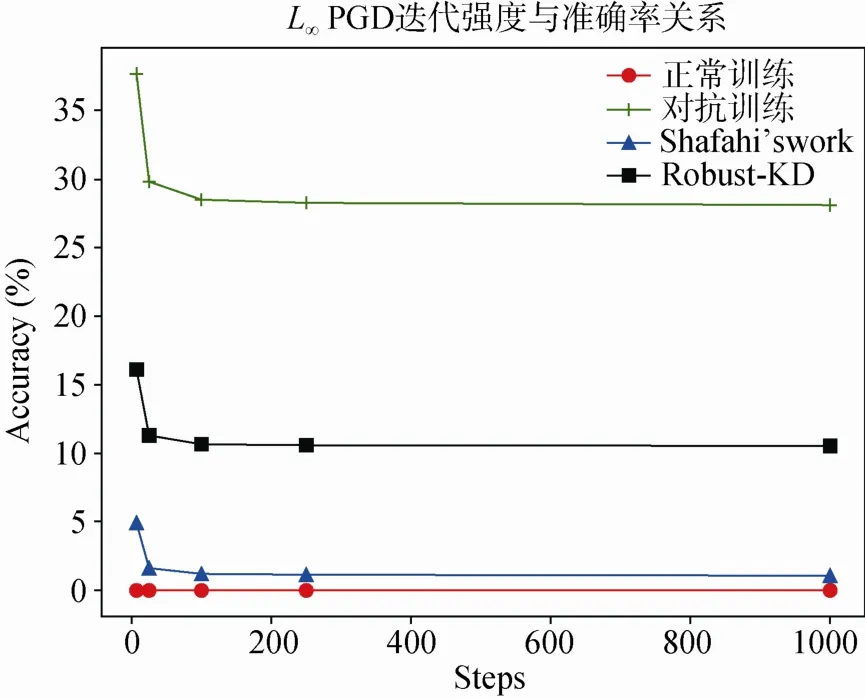
图5 L∞ PGD迭代强度与准确率(%)的关系Figure 5 The relationship between steps of L∞ PGD attack and accuracy (%)
甚至在1000-step的PGD攻击下,我们的模型依然保留了可观的准确率。
4.3 消融实验
在本部分中,我们进行了一系列的消融实验,对比分析各个模块的作用。
4.3.1 不同特征层约束
ResNet50共有4个res-block,4.2中的实验对所有的 res-block输出的特征图上都添加了约束,这样对神经网络的浅层特征以及深层特征都有非常好的约束,可以大大提升算法效果。
本部分想要分析约束在 res-block上的效果,实验设置与4.2保持一致,nproj为1,下表3中给出了实验结果。
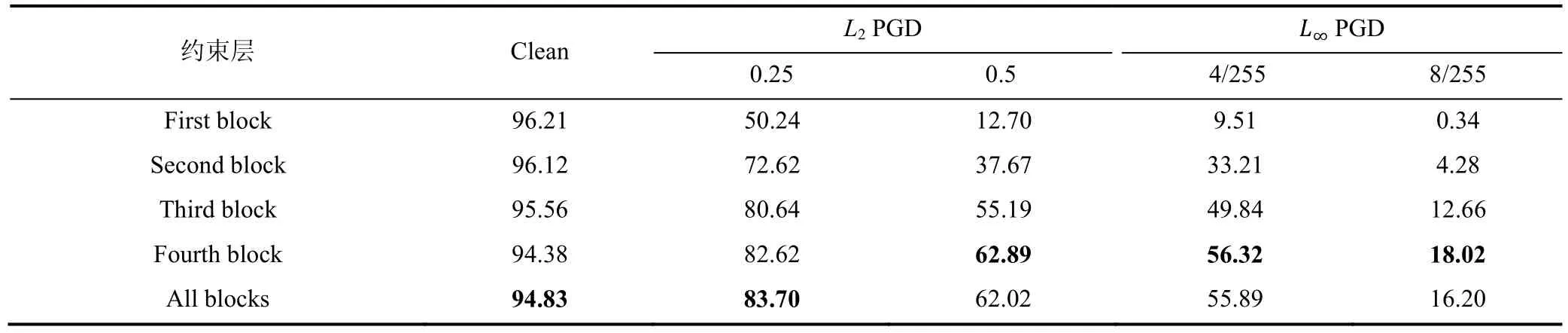
表3 约束层对于PGD攻击算法在Cifar10准确率(%)的影响Table 3 The influence of the constraint layer on the accuracy (%) of the PGD attack on Cifar10
可以发现,随着添加约束的特征层越来越深,鲁棒性迁移的效果越好,仅在最后一层添加正则的防御能力与在所有层添加正则的模型效果相当。
4.3.2 损失函数权重
本部分对损失函数权重的选取进行对比实验,考虑到我们的方法包含两个正则项,这里我们分两部分进行实验。一部分是基于特征图的正则项的权重选择; 另一部分是基于Jacobian矩阵的正则项的权重选择。基于特征图的鲁棒性迁移的消融实验结果见下表4。

表4 基于不同权重特征图约束的鲁棒性迁移在Cifar10上的准确率(%)Table 4 Accuracy(%) of robustness transfer based on feature map constraints under different weights on Cifar10
当 α 为5e-1或者5e-2时,在没有损失过多干净样本准确率的前提下,模型防御能力最强。基于Jacobian矩阵的鲁棒性迁移的消融实验结果见下表5。

表5 基于不同权重Jacobian约束的鲁棒性迁移在Cifar10上的准确率(%)Table 5 Accuracy(%) of robustness transfer based on Jacobian constraints under different weights on Cifar10
当 β 为5e-3或者5e-4时,在没有损失过多干净样本准确率的前提下,模型防御能力最强。
4.3.3 Cosine距离的效果
在基于特征图的鲁棒性迁移部分中,我们使用了Cosine矩阵作为我们的约束方式而非 L2距离。在本部分实验中,我对特征图之间的 L2损失函数进行了一些实验,本部分并没有引入Jacobian矩阵约束。我们不断调整 L2损失函数的权重,实验效果如下表6所示。

表6 Cosine距离与L2距离在Cifar10上的准确率(%)的对比Table 6 Accuracy(%) on Cifar10 under Cosine distance and L2 distance
从上表中,可以看出相较于 L2距离,Cosine距离在约束特征图上效果略好。
4.3.4 nproj 的选取
在本部分,我们验证了在Jacobian约束中 nproj的作用,考虑到效率问题,在本文的大部分实验上,我们均使用 nproj=1 的设定。在本部分中,我们验证了 nproj增大的效果,在实验中,考虑到复杂度,本部分实验的约束仅添加在最后一个 res-block,其仅使用了 Jacobian矩阵作为鲁棒性迁移的媒介,实验结果见下表7。

表7 不同 nproj 下PGD攻击算法在Cifar10上的准确率(%)Table 7 Accuracy (%) of the PGD attack on Cifar10 under different nproj
随着 nproj的增加,算法效果有一定程度上的提升,但是带来的提升非常有限,而时间复杂度增长非常多,所以在本文的实验中,我们使用 nproj=1的设置。
4.3.5 算法泛化性验证
本部分之前的教师模型是在 ImageNet上训练的,目标数据集是 Cifar10,无法证明当前我们算法泛化能力。所以在本部分中,我们分别测试了ImageNet迁移 SVHN,ImageNet迁移 Cifar100,Cifar100迁移 Cifar10等情况,证明我们的方法在不同源数据集与目标数据集上,均有客观的效果。算法效果见下表8。
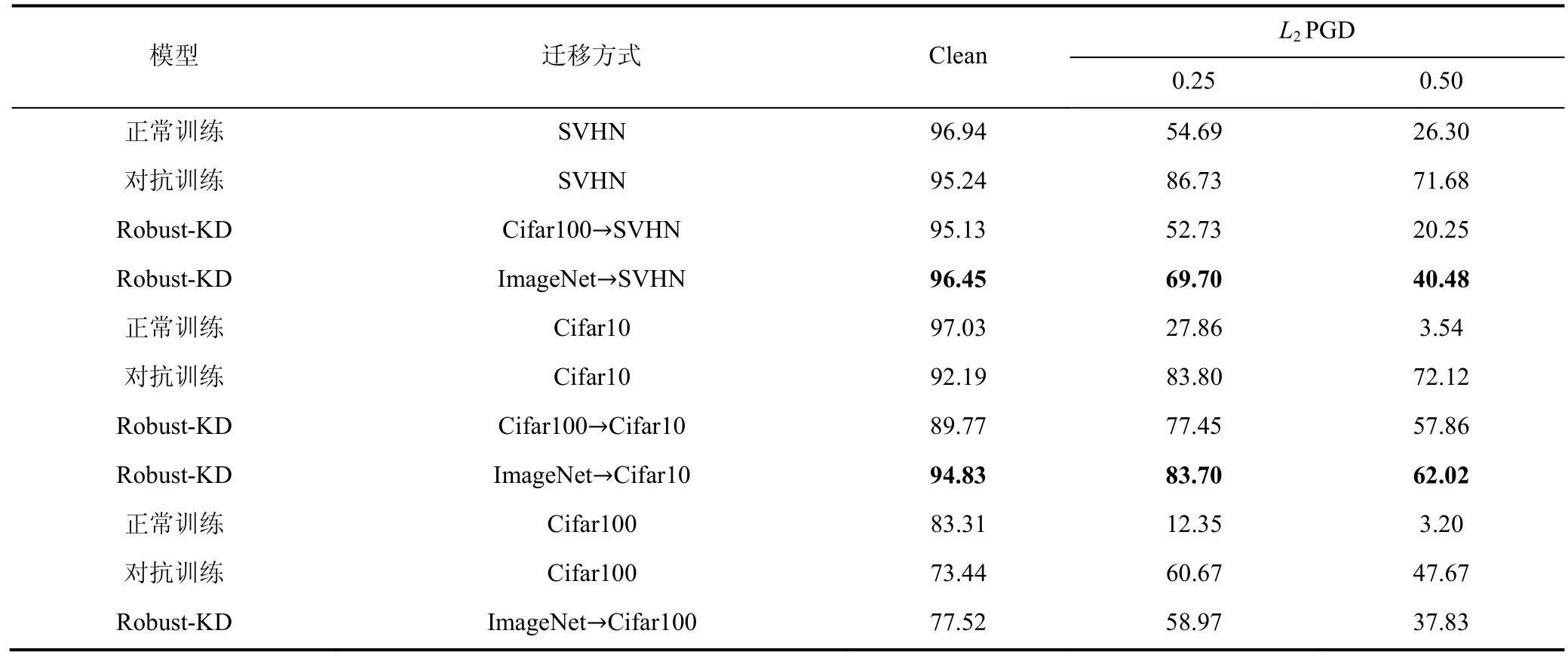
表8 不同源与目标数据集下PGD攻击算法的准确率(%)Table 8 Accuracy (%) of the PGD attack under different source and target datasets
可以看出,ImageNet迁移Cifar10的效果要好于Cifar100迁移Cifar10,教师网络的效果好坏,一定程度上也会影响学生网络的好坏。在 Cifar100数据上的效果也证明了我们鲁棒性迁移算法的泛化能力,在不同数据集上,可以获得不错的效果。但是在SVHN的数据集上,虽然ImageNet迁移SVHN依然有着不错的效果,但是与 ImageNet迁移 Cifar10、Cifar100相比,效果要差了不少。因为Cifar100数据集与 SVHN存在非常低的相似性,所以迁移地效果非常不理想,但这同样也验证了在 ImageNet中提取的鲁棒性特征的泛化性是不错的。
4.3.6 同源数据集之间的迁移效果
对于上述实验,我们验证的是不同数据之间的迁移效果,在迁移学习中,源数据集与目标数据集之间的相关性也是衡量算法指标的重要考量因素。考虑到上一节中的现象,在本节我们将验证同源数据集之间鲁棒性迁移的效果。
在本节,我们将数据集平均切分为两部分,例如 SVHN的训练集切分为 SVHN+、SVHN-,在SVHN+与SVHN-之间迁移模型的鲁棒性。同源数据集之间的鲁棒性迁移效果如下表所示。
表9的结果显示,同源数据集之间的鲁棒性迁移效果非常接近对抗训练,尽管 SVHN+或者Cifar10+的数据量远不及ImageNet,但是与目标数据集之间的相似度更高,防御效果也更强。因此,在鲁棒性迁移中,源数据集与目标数据集之间的相似度也是需要考虑一个方面,在后续的研究工作中,我们也将深入研究这个现象。
5 结论
在本文中我们提出了一种鲁棒性迁移的方法,用来解决对抗训练高时间复杂度的问题。在我们的工作中,可以从一个鲁棒的教师网络中,将鲁棒性迁移到一个网络中,通过这种迁移方法,可以以比较低的代价,获得一个防御能力相对较强的网络。
我们的工作从基于特征图的正则与基于Jacobian矩阵的正则出发,通过这两种约束,使神经网络在新的任务上,依然保留了一部分教师网络中的鲁棒性特征。我们进行了相关实验,证明了我们提升的算法的有效性。
我们的算法还有很多可以改进的方向,一是如何进一步优化 Jacobian矩阵的约束,进一步降低算法的耗时,二是可以更加深入地分析神经网络的性质,针对鲁棒性模型的特性,设计更加有效的迁移方法。此外,在原数据与目标数据集之间的相关性还有更多可以挖掘的地方。在后续的工作中,我们将在这些方面优化改进。
