情感子句预测与原因子句提取方法
2021-08-23陆丁天张志远
陆丁天,张志远
(中国民航大学 计算机科学与技术学院,天津 300300)
0 引 言
近年来,文本情感分析引起学术界与工业界的研究兴趣,对带有各种情感色彩的评论文本进行情感分析具有很大的研究和应用价值[1]。
Zhang Y等[2]认为文本情感分析建模面临的主要挑战是如何捕捉文本的局部语义信息、情感依赖信息以及情感表达关键部分;于是提出CCLA模型,提取这3类信息特征并融合得到完整的句子特征进行情感分析。卷积神经网络(CNN)更加关注局部特征,对文本情感分析的准确率有一定影响[3,4]。RNN能提取文本上下文语义信息,但其存在梯度爆炸和梯度消失问题,故常用LSTM来代替RNN进行文本情感分析任务[5-8]。然而LSTM是一个有偏模型,其更多注重句子末尾的词,当关键词不在句子末尾时,LSTM就无法很好捕获句子语义信息来进行文本分类任务,于是又常用双向的LSTM来代替单向的LSTM进行文本情感分析任务[9]。Bahdanau等[10]对Encoder-Decoder神经机器翻译方式的改进引出了注意力机制。注意力机制是用来表示文本句子中的词与输出结果之间的相关性,表示句子中每个词与句子相对应标签之间的重要程度[11,12]。注意力机制与深度学习模型的结合大大提高了文本情感分析的效果[13]。
然而,知道情感倾向还需知道其产生的原因,因此目前相关研究重点正从日趋成熟的文本情感分析向挖掘文本情感的产生原因深入,即文本情感原因发现[14]。情感原因发现与抽取最早是由Lee等[15]提出。此后Gao K等[16]提出了基于规则的词水平原因提取模型。基于词水平的情感原因提取任务的语料库构建需要大量复杂的标注,使得语料库规模很小,无法为机器学习提供足够信息。为此Gui等[17]使用新浪都市新闻建立了一个带标注且以子句作为原因提取基本单元的语料库,并提出了一种基于事件驱动的多核SVM情感原因提取方法。即使训练集有限,仍然可以提取足够的特征进行分析。Li X等[18]认为情感子句与原因子句之间有相互作用的关系,于是提出了一种基于多注意力的神经网络模型(MANN)来捕捉情感分句与候选分句之间的相互关系。
传统的情感原因提取需要预先标注情感标签,该方式增加了人工成本,限制了情感原因提取任务在现实中的使用。为此Xia R等[19]提出情感-原因对提取方法Inter-EC,所提方法分两步,先通过两个子任务分别进行情感提取和原因提取,最后得到一个情感子句集合和原因子句集合;然后通过笛卡尔积将情感子句集和原因子句集构造成对,再训练一个过滤器将没有包含因果关系的情感-原因对剔除。此方法为情感原因提取任务的研究提供了一种思路。然而Inter-EC模型存在两个问题:①在情感子句提取时,句子特征不完整,使得情感子句提取效果不够好;②在原因提取时,情感和原因之间的联系体现的不够充分,使得原因提取效果不够好。为此本文在Inter-EC模型的基础上提出了一种基于注意力的情感子句预测与原因子句提取模型(emotion prediction & cause extraction model,EPCEM),实验结果表明该模型具有不错的效果。
1 方法描述
1.1 任务定义
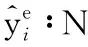
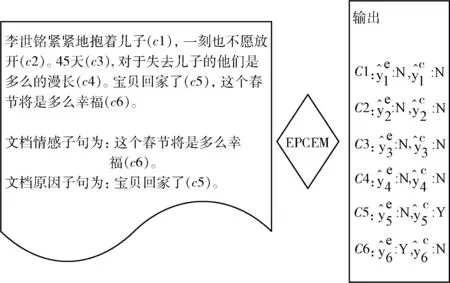
图1 情感子句预测与原因子句提取任务示例
1.2 模型描述

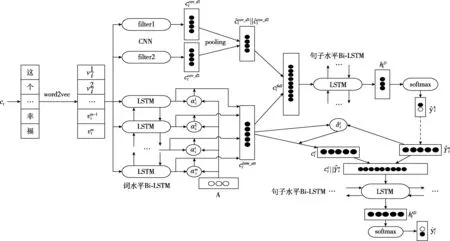
图2 EPCEM模型
1.2.1 情感子句预测部分
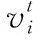
(1)

(2)
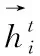
(3)
(4)
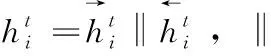
为获得情感表达的关键部分,将Bi-LSTM的输出作为注意力层的输入。注意力机制的定义如下
(5)
(6)
(7)

(8)
(9)
(10)
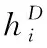
(11)
1.2.2 原因子句提取部分
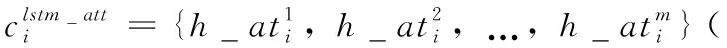
情感与原因之间是有联系的,找到与情感信息相关联的上下文语义信息是确定原因的先决条件,为找到与情感信息相关的原因信息,引入一种情感导向的注意力机制,该机制能够对通过带有注意力的词水平Bi-LSTM获得的句子特征进行加权表示,以获得与情感相关的句子特征。情感引导的注意力机制的使用定义如下
(12)
(13)

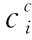
(14)
(15)
(16)
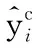
(17)
模型的损失函数由两部分的交叉熵损失组成
LP=λLe+(1-λ)Lc
(18)
其中,Le为情感子句预测部分的交叉熵损失,Lc为原因子句提取部分的交叉熵损失,λ为权衡参数。
2 实 验
2.1 数据集
本文使用情感原因分析ECPE数据集[19],数据集一共有1945篇文档,每篇文档由多个分句构成。数据统计信息见表1。模型训练集大小与测试集大小的比例为9∶1。

表1 ECPE数据集统计信息
2.2 模型参数设置
使用word2vec预训练好的微博语料库词向量,词向量维度为300维。对于未登录词,采用均匀分布U(-0.01,0.01)来随机初始化词向量。CNN窗口大小为3和4,每个窗口过滤器数量为100。Bi-LSTM的隐藏层单元个数为100。模型训练时,Adam优化算法的初始学习率为0.005,Batch大小为32,dropout为0.8,L2正则化的权重设置为10-5。
2.3 评价指标
评价指标实验结果评估采用精确率p(Precision)、召回率r(Recall)和f1值来进行评估。定义如下
(19)
(20)
(21)
其中,correct_causes为原因子句预测标签与真实标签一致且为Y的数量;proposed_causes为原因子句预测标签为Y的数量;annotated_causes为真实标签为Y的原因子句数量。情感子句预测部分的评价指标与原因子句提取的评价指标相似。
2.4 实验结果分析
2.4.1 不同词向量表示
为了评估不同词向量表示对模型的影响,使用不同的向量表示对模型进行评估。Rand200d:词向量随机初始化为200维;w2v200:通过Word2vec预训练好的微博语料库词向量200维;Rand300d:词向量随机初始化为300维;w2v300:通过Word2vec预训练好的微博语料库词向量300维。
不同词向量表示对模型的影响见表2,在情感子句预测上,用预训练好的微博语料库词向量得到的f1比随机初始化方式得到的f1值高了近10%,其中300维的预训练词向量比200维的预训练词向量效果更好;在原因子句提取上,预训练得到的f1值比随机初始化得到的f1更是高出了10%。从而验证,词向量用随机初始化的方式得到的结果较差;预训练词向量对句子特征表示是有效的,预训练的词向量能提高情感子句预测与原因子句提取的效果。
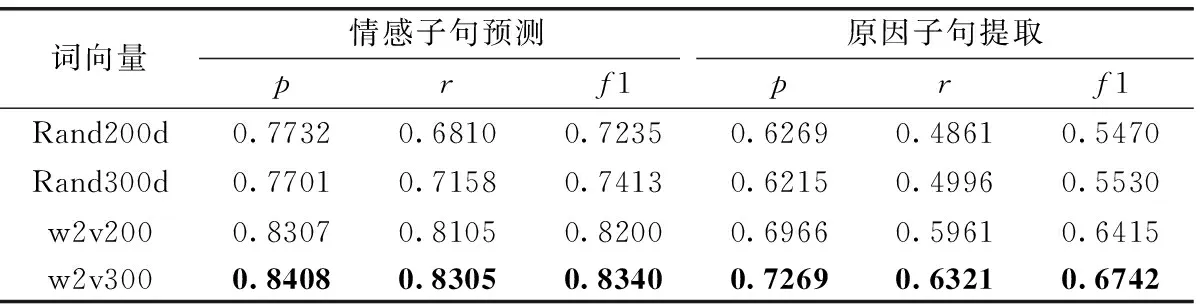
表2 不同词向量表示对模型的影响
2.4.2 CNN窗口大小对模型的影响
目前大部分情感分类模型仅仅使用Bi-LSTM加上注意力来提取句子的上下文语义依赖信息和与情感相关的关键部分来进行情感分析。然而在进行情感分析时,一个完整的句子特征要包含局部语义信息、上下文语义依赖信息以及情感表达的关键部分。为验证结论,在情感子句预测部分,模型提取句子特征时,进行了融入局部语义信息和不融入局部语义信息的实验。实验结果见表3,从表3中可以看出,在进行句子特征提取时,融入局部语义信息使句子特征更完整,能提高情感子句预测的效果,并且CNN窗口大小为{3,4}(注:表示窗口大小分别为3和4两个过滤器)时,情感子句预测效果最好。

表3 CNN对情感子句预测的影响
2.4.3 情感子句预测标签对原因子句提取的影响
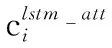

表4 消融实验对原因提取的影响
从表4可以看出忽略情感与原因之间的关系,情感子句预测与原因子句独立进行时,原因子句提取效果最差。在考虑情感与原因之间的关系后,通过Concat方式与Att方式将情感与原因联系起来提高了原因子句提取的效果。通过Concat与Att结合的方式(即EPCEM)进一步增强了情感与原因之间的联系,从而提高原因子句提取的效果。因此验证了在进行原因子句提取时,考虑情感与原因的关系,将情感特征融入句子特征去进行原因子句提取能进一步提高原因提取的效果这一结论。
2.4.4 相同任务定义下的模型对比
相同任务定义是指在未给定文档情感标签的情况下,找出文档情感子句,并提取相应的原因子句。目前在此任务定义下的模型仅为文献[19]的Inter-EC模型。本文模型与Inter-EC模型对比结果见表5。从表中可以看出,在情感子句预测上,本文模型的f1值比Inter-EC模型的f1值高出了1.1%,这是因为本文模型在进行情感子句预测时考虑了局部语义信息,使得句子特征更完整,从而提高了情感子句预测的效果。在原因子句提取效果上,本文模型得到的f1值比Inter-EC模型得到的高出了2.35%,原因在于本文模型使用了情感导向注意力,使得情感与原因更相关,从而提高了原因子句提取的效果。

表5 相同任务定义的模型对比
2.4.5 与传统的原因提取任务模型对比
传统的情感原因提取任务ECE(emotion cause extraction)是指在标注好情感信息后,提取引起情感信息的潜在原因,需要在测试集中对文本情感信息进行标注。而本文的情感原因提取任务是预测情感信息,并提取引起情感信息的原因。对比结果见表6,其中:
RB:手工定义语义规则方法[15]。
CB:基于常识定义的方法[17]。
RB+CB+ML:RB与CB结合并通过机器学习SVM分类训练。
SVM:使用1-grams、2-grams和3-grams作为特征通过SVM分类器进行分类[17]。
CNN:使用CNN提取候选子句和已确定的情感子句的特征进行情感原因提取[18]。
MANN:基于多注意力的上下文情感原因分析神经网络模型[18]。
从表6可以看出,即使在测试集中没有对文档进行情感信息标注,所取得结果仍然优于大部分传统模型,仅次于MANN模型,这是由于MANN模型是预先标注好情感标签的原因提取,而本文模型是预测情感标签后再去提取原因,预测情感标签的效果会影响到原因提取的效果。
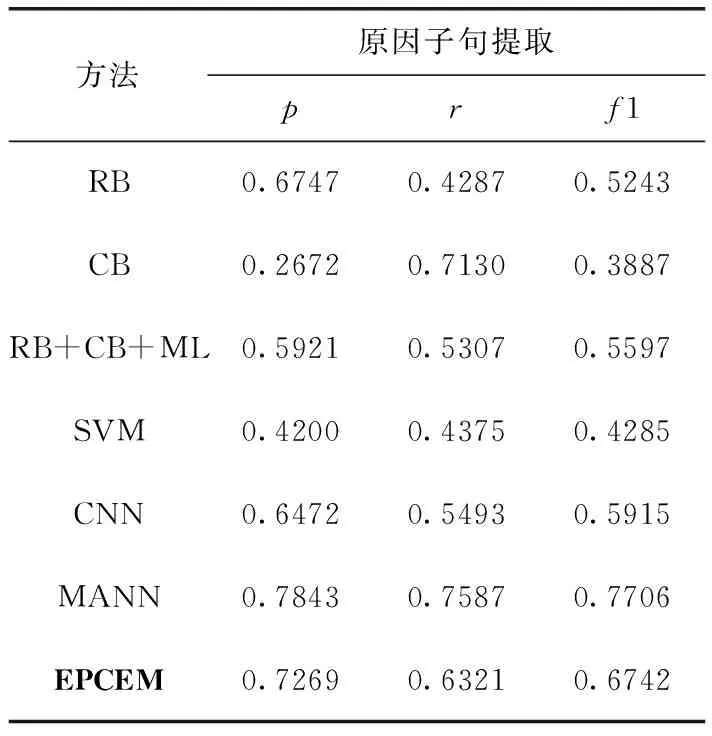
表6 与传统情感原因提取任务方法比较
3 结束语
本文提出了一种基于注意力的情感子句预测与原因子句提取方法,与传统的情感原因提取方法的不同之处在于该方法不需要预先对文本进行情感标注,在未给定情感标签的情况下,在预测文本情感的同时匹配其对应的原因。该方法节约了人工标注的成本,扩大了情感原因提取任务在现实中的应用范围。
实验结果表明,在预测情感子句时,一个完整的句子特征需要包括局部语义信息、上下文语义依赖信息以及情感表达的关键部分。在进行原因子句提取时,融入预测的情感信息能更好提高原因子句提取的准确率,且通过注意力的方式的融合使原因子句提取的准确率有更进一步的提高。
