面向文化产品水军的多视角特征发现与识别
2021-08-23张晏成
张晏成,李 涛
(武汉科技大学 计算机科学与技术学院 湖北省智能信息处理与工业实时系统 重点实验室,湖北 武汉 430065)
0 引 言
在水军识别技术中,采用具有代表性的特征因子能有效提高模型的分类效率。以往电商网络水军识别研究中,更多的是基于物质商品进行分析,而直接使用物质商品水军特征模型来解决文化产品水军识别问题具有不足,其本质在于文化产品存在如下的特殊性及用户活动特点。
(1)丰富的语义性。文化产品评论是对产品主题、情节表达形成了不同观念的碰撞交流,具有丰富的语义特征,评论主题与目标产品主题相关,若相关性过低或者不相关,则其评论存在较大的虚假性,并导致评论的有用数较低。
(2)严格的时效性。随着文化产品发布的时间越来越长,其热度逐渐降低,此时再通过水军进行炒作已没有过多价值。因此在文化产品中,平均评价积极度是区分正常用户与水军用户的重要指标。
(3)网络交互性。文化产品用户间具有较强的网络交互性,具有相同兴趣的正常用户之间更容易存在社交行为,通过找出用户与好友之间行为和兴趣的关联性,甄别出正常用户与水军用户,将行为关联性与兴趣关联性作为文化产品水军识别的新特征。
此外,个人信息的完善程度是人们对一个用户直观判断的入口。本文在传统属性特征基础上,提出了综合质量评价特征因子。
针对上述特点,本文从3个视角提出了6个新特征因子,结合传统特征提出了特征向量集合,使用特征选择方法,建立了针对文化产品水军识别的特征模型。另外,在以往研究方法中,只是选用单一的分类器,没有考虑使用弱分类器转化为强分类器的集成方法对模型进行识别,因此,基于文化产品的特征模型,运用集成学习算法进行水军识别具有较高的精准率。
1 相关研究
目前,电商水军识别已有较深入的研究,文化产品属于电商产品的分支,具有其特殊性,也有着其它电商评论的一般性,本文在特征分析与相应研究方法上,借鉴了其它电商平台的方法,将电商水军识别方法主要分为以下3 类:
(1)基于行为视角的研究,其包括评论偏差、评论频率等特征因子。文献[1]从用户行为目的角度,基于水军行为构建检测模型并对产品评分偏差以及产品目标差异性特征进一步细分从而挖掘水军团体。文献[2]综合考虑了评论者评价行为、交流行为以及对商品的关注行为并构建了D-S证据理论模型。文献[3]认为发文间隔、活动时间是水军识别的重要因素。评论偏差[4]对于水军识别也具有重要作用。
(2)基于内容视角的研究,其包括情感倾向[5]、文本相似度、文本长度等特征因子。文献[6]在情感极性中使用情感极性均值以及标准差来刻画虚假评论,采用SMOTE算法优化随机森林分类模型,从而提高识别效果。文献[7]针对电商领域,对评论文体提取引人关注的文本比率、专业词比率、词法有效性和文本相似度等新特征,采用支持向量机、逻辑回归、随机森林、朴素贝叶斯、J48等分类算法进行检测,并验证了SVM和逻辑回归对水军识别具有较好效果。
(3)基于行为、属性、内容的多视角研究。其包括以上两种视角的交叉融合。文献[8]通过评论数量、评论质量、评论相似度以及时间集中程度4个方面进行展开对网络水军进行研究,并结合水军评论3个感知方面建立了消费者购买行为影响模型。文献[9]提取了虚假评论人的属性以及行为特征,借助于“大众点评”权重机制,构建了逻辑回归预测模型。文献[10]对词频统计等评论内容以及评分情况等用户行为特征进行主成分分析,并验证了分别对评论内容和评论行为使用SVM、决策树进行分类识别整体性能优于朴素贝叶斯和逻辑回归。文献[11]通过评论数量、频率等行为特征以及专业程度、情感密度等内容特征采用K均值聚类算法对科技产品的虚假评论进行识别。文献[12]以大众点评网为例进行水军分析,通过内容以及行为等不同特征进行组合,采用朴素贝叶斯算法构建分类模型对水军进行识别。
以上研究方法,对电商水军检测奠定了一定的基础,但是应用在文化产品领域,仍存在着不足。单一视角的水军检测方法会有识别率低的问题,由于文化产品的特殊性,而现有的多视角检测方法设计的特征向量并没有针对文化产品,且使用的是单一分类器,导致在检测文化产品水军时,准确率也不高。为了解决以上问题,本文在已有多视角的研究方法上,提出了新的特征模型,并结合集成学习算法进行水军识别。经过实验验证,本文提出的特征模型及方法有效提高了文化产品水军识别效果。
2 特征设计与选择
2.1 特征设计
借鉴电商水军识别采用的特征,从用户属性、行为、内容3个视角进行计算以及记录。电商水军识别特征及描述见表1。

表1 电商水军识别特征及其描述
文化产品与电商水军识别在评论内容,用户行为,用户属性等特征上存在很大重合,同时也具有一定差异。基于文化产品特殊性以及用户活动特点,本文在电商水军识别特征基础上进行了新的特征设计。
(1)基于评论者的属性视角
定义1 综合质量评价(CE)
用户信息的完整性,在一定程度上反映了用户的真实性;综合质量评价涉及用户昵称、个性签名、地理位置多个属性,定义如下
CE=0.3用户昵称+0.4个性签名+0.3地理位置
(1)
(2)基于评论者的行为视角
定义2平均有用度(AU)
有用数是用户对评论内容的认可,通过平均有用度从普通用户群体的角度直观反映评论内容的价值,平均有用度即所有评论内容的有用数之和(TotalUseful)与评论总数(TotalNumber)的比值,定义如下
(2)
定义3平均评价积极度(AP)
为了达到宣传炒作的目的,发行方将雇佣水军短时间内刷高评分,因此通过平均评价积极度能对水军进行较好的区分,平均评价积极度即评论时间与上映时间差值的平均值,Xi指评论时间,Mi指产品上映时间,定义如下
(3)
定义4行为关联性(MCT)
基于社交行为属性,相互关注的用户,若对多个相同的文化产品具有较高的共识,则用户之间关系越密切,关系密切的粉丝数越多用户越真实,行为关联性(MCT)即用户拥有密切关系的粉丝数量(TotalMCT)与相互关注数(MUTUAL)之比,定义如下
(4)
定义5兴趣关联性(MCM)
物以类聚,人以群分,正常用户与好友之间存在着相同的兴趣标签,水军用户与所关注的对象并无太多联系。兴趣关联性(MCM)即与用户评论同一类型文化产品的粉丝数量(TotalMCM)与相互关注数之比,定义如下
(5)
(3)基于评论内容的视角
定义6评论主题相似度(TR)
采用语义分析技术,通过评论内容所反映的主题思想与文化产品主题进行比较,得出评论与主题的相似度,评论主题相似度即主题相似度高的评论数量(TotalTR)与评论总数之比,定义如下
(6)
2.2 卡方检验
在卡方检验中,假设分类变量为正常用户与水军用户,正常用户包含特征的频数为MF,正常用户不包含特征的频数为MN,正常用户频数为M,水军用户包含特征的频数为TF,水军用户不包含特征的频数为TN,水军用户频数为T,包含检验特征的频数为F,不包含检验特征的频数为N,总频数为S。卡方检验计算参数见表2。
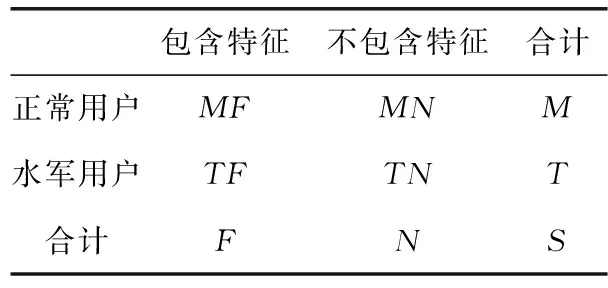
表2 卡方检验计算参数说明
卡方计算公式为
(7)
依次对每个特征计算获得卡方值,卡方值越大,说明特征与类别相关性越大,将计算所得值与按照显著性水平查找卡方临界值表进行对比,从而剔除冗余特征。
2.3 IG信息增益算法
卡方检验剔除冗余特征后,初步得到与类别相关性高的特征,但是仍然无法判断出特征对分类问题的影响力。信息增益算法可以描述特征区分样本的能力,选择信息增益算法进行下一阶段的特征处理。用X表示特征,Y表示用户是否为水军,于是信息增益的公式为
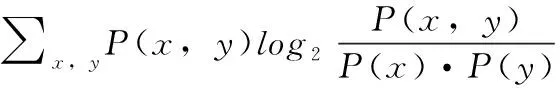
(8)
特征Xi的信息增益越大,表明该特征区分用户类别的影响力越大。
3 文化产品水军识别模型
3.1 识别模型概述
本文针对文化产品的用户特性分别从用户属性、行为以及评论内容3个视角进行特征设计,根据设计的特征收集数据并使用统计计算与自然语言处理技术提取出水军识别特征,使用卡方检验与信息增益对特征进行评价与选择,结合集成学习算法构建分类模型应用于水军识别,将按照8∶2划分的训练集与测试集用于模型训练,按照网格搜索算法进行参数调节选择结果最优模型。模型框架如图 1所示。
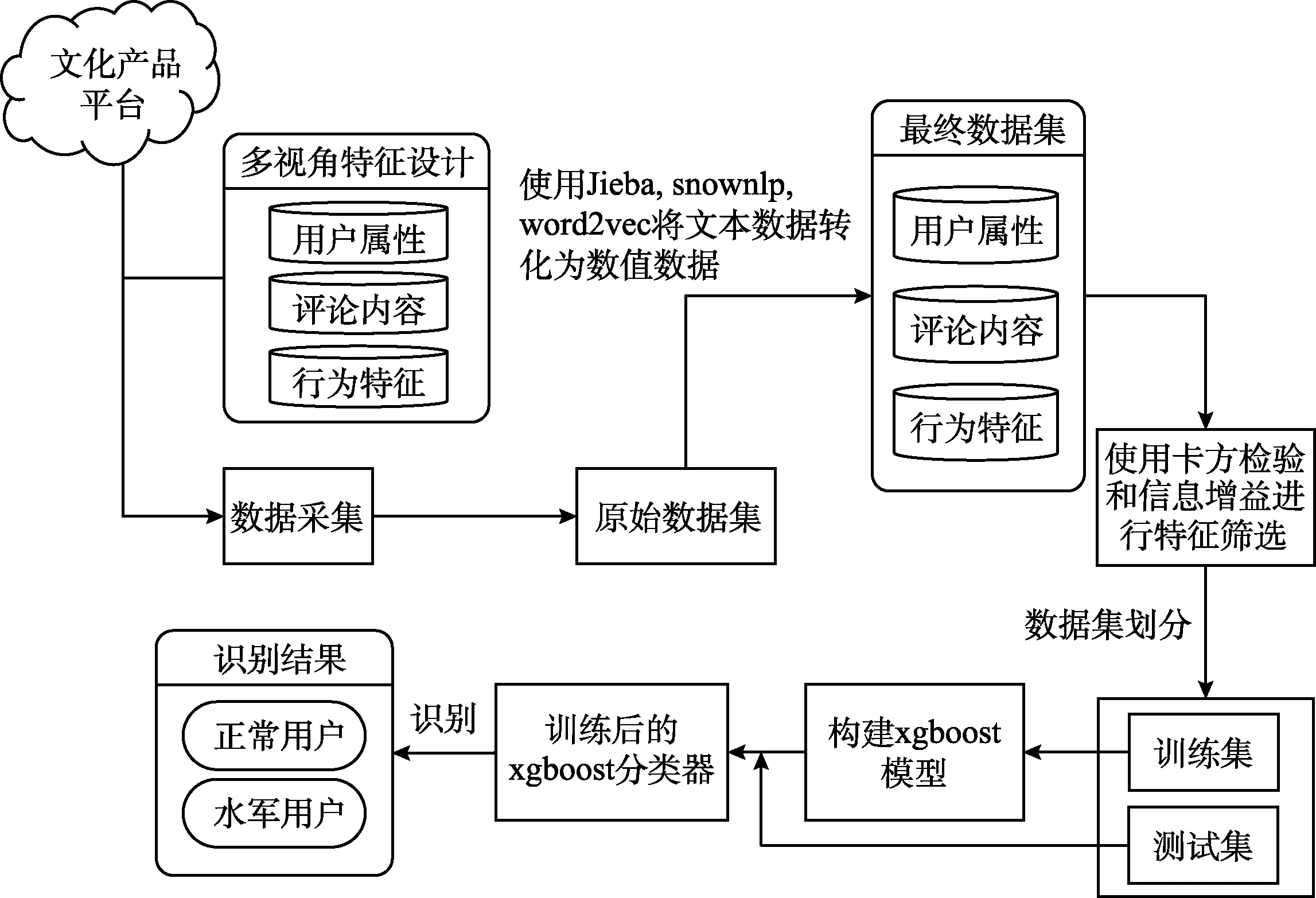
图1 文化产品水军识别模型
3.2 识别模型构建
水军识别问题,可以看作一个分类问题。在大量评论用户中识别出水军用户,则需要选择一个分类效率高且速度快的识别模型。xgboost是一种极端梯度提升集成算法,可以将弱分类器转化为强分类器,其核心思想是不断选择增益最大的特征进行分裂生成一颗树去拟合上一次预测的残差,使得整个模型的误差不断降低,直到满足停止条件,从而达到准确的分类效果。xgboost对代价函数进行二阶泰勒公式展开,有利于梯度下降的更快更准,并在代价函数里加入了正则项,用于控制模型的复杂度,降低了过拟合的可能性,从而使xgboost具有良好的效果。
模型的目标函数为
(9)
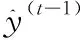
(10)
识别模型流程如下:
(1)将数据集按照8∶2的比例划分为训练集与测试集;
(2)对训练集,重复步骤1)-步骤3)。
1)从根节点开始,根据式(10)递归地找出分裂点,直到满足停止条件,至此所有特征都转化为了一棵回归树上的一个节点;
2)循环执行步骤1),使建立的多棵回归树能够在损失函数梯度上保持下降趋势;
3)多棵回归树组合后建立出基于xgboost算法的水军识别分类模型。使用GridSearchCV实现模型的自动调参,得到模型的最优参数集合。将最优参数带入xgboost模型,从而提高分类性能。将模型产生的预测值进行处理,大于0.5输出1;否则输出0。
(3)利用测试集对模型进行评估。
4 实验与分析
实验运行环境:Windows 10操作系统,16 G内存,3.5 GHz四核心处理器,实验软件为Python 3.7。
4.1 数据预处理
本文选择国内最早且用户基数最大、评论数量最多的影评聚集地豆瓣平台作为研究对象。根据刘正山等[14]对电影评论“恶评”的相关研究,“恶评”是指评论与正常评分相差过大的评论总称,豆瓣电影排行榜按照评分高低依次排序,Top2F50评分普遍较高,依据大数定理研究“恶评”分布定律,短评中差评用户具有更大的水军嫌疑,本文爬取豆瓣Top250电影站点用户信息,去除重复数据,最终得到4165个评论人信息,共约5万条评论数据。最后,邀请专业人员标注出数据集中的网络水军。对数据集中特征处理如下:
(1)根据第2章中的特征设计计算出数值型数据。
(2)使用中文词库和中文分词第三方库jieba对文化产品简介,短评文本进行分词,确定汉字之间的关联概率。汉字间概率大的组成词组,形成分词结果。
(3)使用word2vec将单词转换成向量形式。将进行分词、去除停用词等操作后的词组,利用word2vec转换成词向量,然后计算评论内容词向量间以及每条评论对应文化产品简介间的余弦距离,进而求出短评内容的自相似度SR以及评论与文化产品主题相关性TR。主题相似度计算伪代码如下:
算法1:主题相似度TR
输入:用户评论集合C={C1,>C2,>…,>Cn},集合长度N评论对应的电影简介集合M={M1,>M2,>…,>Mn}
(1)初始化字典类型变量dict,N*N的二维数组list
(2)fori=1,>2,>…,>Ndo
(3)t← 使用jieba的cut对C[i]划分得到词组
(4)w← 使用word2vec的word2vec计算t得到词向量
(5)dict[C[i]]=w
(6)endfor
(7)初始化计数器counter为0
(8)whileC不为空 do
(9)c=C.pop()
(10)list[counter].append()
(11)m=len(C)
(12)fori=1,>2,>…,>mdo
(13)q← 使用word2vec的similarity计算dict[c]与list[C[i]]之间的相似度
(14)ifq>0.7then
(15)list[counter].append()
(16)C.remove(C[i])
(17)endif
(18)endfor
(19)counter=counter+1
(20)endwhile
(21)TR=counter/N
输出:用户的主题相似度TR
4.2 评价标准
为平衡正负样本,提高实验准确性,本文采用了精准率(PR)来评估分类器的准确性。将检测值分类汇总,建立混淆矩阵。TP代表模型中分类检测的水军数,FP代表模型中误测为水军数,TN代表模型中分类检测的正常用户数,FN代表模型中误测为正常用户数。混淆矩阵见表3。

表3 混淆矩阵
(1)精准率(PR)定义如下
(11)
TP/(TP+FP)表示水军样本精准率,TN/(TN+FN)表示非水军样本精准率。水军样本与非水军样本精准率两者值的高低将影响平均精准率PR,防止因水军样本与非水军样本数偏差影响精准率。
(2)召回率(RR)定义请参见文献[15]。
(3)调和平均值(F1)定义如下
(12)
4.3 特征选择实验
通过卡方检验与信息增益算法对特征进行选择与评价,在特征选择实验中,对设计的特征进行去冗余操作,经过筛选后,按照信息增益值大小对特征进行排序。特征IG值排序见表4。
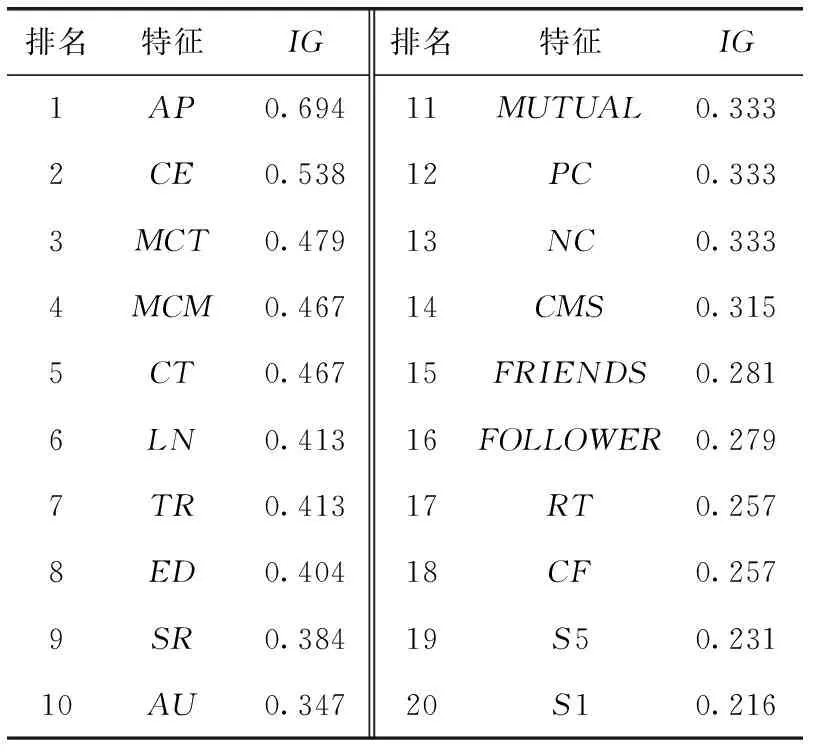
表4 特征处理后的IG值
经过信息增益进行特征排序后,为了使模型训练效率更高,设定阈值为0.333即选择IG值大于0.333的特征为影响文化产品水军识别的显著特征,并将传统水军识别特征、加入新提出的特征以及进行特征选择后的特征,分别在同一数据集下,使用本文水军识别模型进行测试,得到实验结果。实验结果见表5。
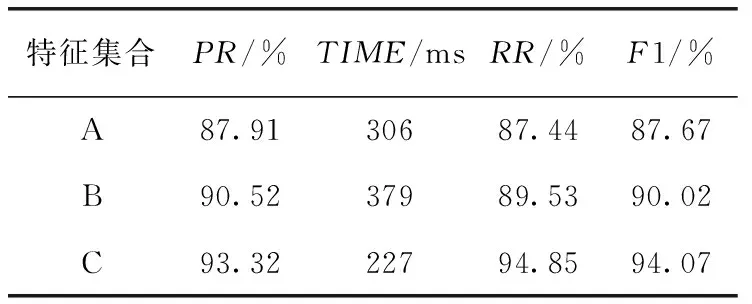
表5 不同特征下的效果对比
A代表已有电商水军特征,B代表在A的基础上加入本文提出的新特征,C代表B特征处理后的数据。实验结果验证了本文提出的新特征对文化水军识别具有一定效果提升,精准率提高了2.61%,由于特征维数增加,后续水军识别在时间性能上有所降低,时间增加了73 ms,使用特征选择后相对未作处理的新特征集合精准率提高了2.8%,时间减少了152 ms,相对于电商水军识别特征,经过卡方检验与信息增益筛选后的特征在精确度以及时间效率上都有所提升,精准率提高了5.41%同时时间减少了79 ms,验证了本文提出的新特征能有效提高识别率,卡方检验与信息增益能够剔除冗余特征提高了精准率的同时减少了时间消耗。
4.4 水军识别对比实验
为验证识别方法的有效性,选择电商水军识别的4种方法与本文提出的面向文化产品水军的识别方法进行对比,将xgboost方法分别与文献[10]中的支持向量机、文献[9]中的逻辑回归、文献[12]使用的贝叶斯模型以及文献[6]中基于SMOTE过采样的随机森林方法进行实验对比;为了使结果更准确,采用十折交叉的方法,将数据集按照8∶2的比例进行10次随机划分,8份用作训练集,2份用作测试集,对10次实验结果求平均得到如图2所示。
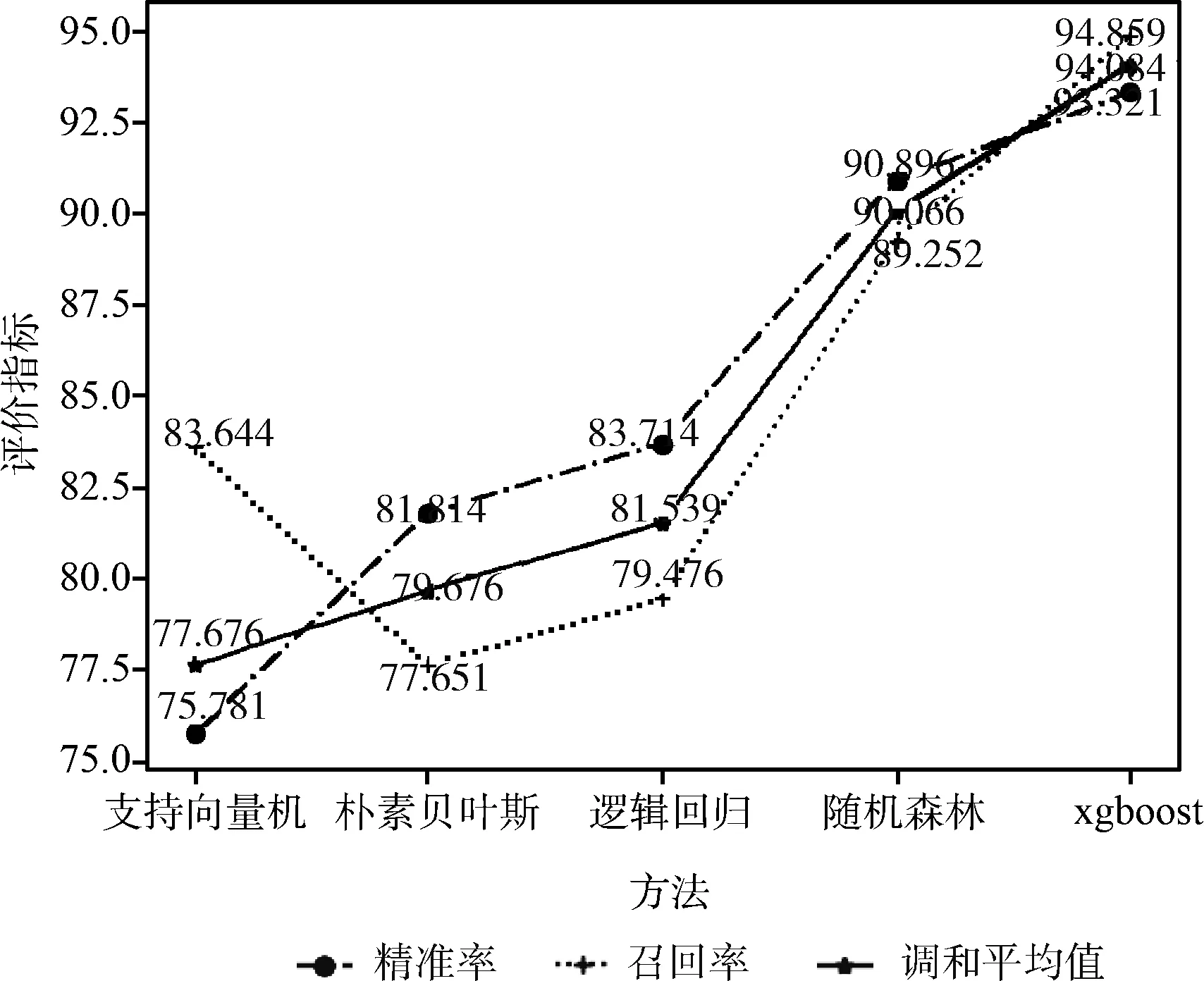
图2 不同识别方法的分类结果
由图可知,xgboost模型与随机森林、逻辑回归、朴素贝叶斯以及支持向量机识别方法相比,精准率、召回率和调和平均值有较大提高,整体性能优于对比方法。实验结果表明,xgboost模型与随机森林模型识别效果明显高于其它方法,其原因是特征取值范围广,树形结构更适用于处理此类数据分类,而本文使用的xgboost模型较随机森林模型精准率提高了2.425%,调和平均值提高了4.018%,这是因为xgboost是所有预测结果的累积并在原有梯度提升树基础上对损失函数进行了改进,而随机森林采用的则只是多投票原则决定最终结果,以上分析可知,xgboost模型结合本文提出的特征集合,可以有效识别文化产品水军。
5 结束语
随着在线文化产品的不断发展,在线评论对后续消费者有着较大的影响。文化产品带来的巨大利益使发行方希望通过雇佣水军获得竞争优势,扰乱文化产品市场正常秩序。因此,识别文化产品评论中的网络水军,还原真实的评论环境,有利于文化产业健康发展。本文鉴于文化产品网络水军的特性,通过从多视角分析,在电商水军特征基础上,运用语义分析以及统计计算等技术,提出了新的特征集合,并通过卡方检验以及信息增益算法进行特征筛选,建立新的特征模型,结合集成学习模型对文化产品水军进行识别。以豆瓣短评为数据来源,通过对比实验验证了本文提出的特征模型集合与集成学习分类模型对文化产品网络水军识别具有较好的提升效果,精准率达到了93.32%,能有效地进行文化产品水军识别。
在未来的研究中,需要获取文化产品领域中更多的数据集,并采用识别水军团体的方法提高文化产品水军识别效率。
