融合化学反应优化与K均值的文本数据聚类
2021-08-23董永权
王 琛,董永权
(1.江苏建筑职业技术学院 信电工程学院,江苏 徐州 221116; 2.江苏师范大学 计算机科学与技术学院,江苏 徐州 221116)
0 引 言
作为一种非监督学习技术,文本聚类[1]的目的是根据距离或相似性将文本文档集合划分为若干聚类,使得相同聚类内的文档具有最相近的文本特征,而不同聚类内的文档体现不同特征,它可以简化文本处理过程,将具有固有特征的文档聚类成集[2]。在没有文档分类标签的先验知识前提下,文本聚类需要管理非标签的文本文档集合。
K均值算法是一种最为简单快速的文本聚类算法[3],算法试图为每个文档寻找距离最短或相似性最高的质心,并通过质心的不断更新得到稳定聚类。但是,该算法过多依赖于初始质心选取,是一种局部最优搜索算法。为了进一步得到准确度更高的文本聚类结果,提出了一种融合化学反应算法与K均值算法的文本聚类算法,结合K均值算法的局部快速开发寻优能力和化学反应算法的全局勘探能力,以K均值得到的聚类解集合作为化学反应算法的初始分子结构群,通过4种化学反应操作,增加种群分子结构的多样性,在扩展搜索空间的基础上得到最优文本聚类。
1 相关研究
相关研究中,文献[4]针对传统K均值聚类在初始质心选取上的随机性,为样本点引入局部密度指标,并根据局部密度分布,选择密度峰值点作为初始质心,得到了更高聚类准确度。文献[5]针对特征词稀疏性,提出结合语义的K均值聚类算法。算法以词集表示短文本,解决了短文本特征词的稀疏问题,还克服了对初始质心的敏感性。文献[6]提出增强蜂群优化与K均值的文本聚类算法。首先引入克隆操作提高全局搜索能力,提高样本多样性并增强蜂群搜索能力;再通过克隆操作增强世代间的信息交流,提高聚类质量。元启发式算法也常用于数据聚类分析。文献[7]利用遗传算法和差分进化对K均值聚类做了改进。文献[8]利用智能蜂群算法选择聚类中心并创建文档聚类,建立了梯度搜索和混沌搜索两种局部搜索增强蜂群开发能力,在收敛速度和聚类质量上具备优势。文献[9]结合粒子群和布谷鸟算法进行聚类分析,将粒子群生成的聚类解作为布谷鸟算法的输入,融合两者优势,在F度量指标上有着优异表现。文献[10]提出基于粒子群算法的文本聚类算法,文献[11]提出基于遗传算法的文本聚类算法。元启发式算法在解决聚类问题时可能面临早熟或收敛过快问题,这会降低种群全局搜索能力。早熟收敛问题一般与初始解的质量相关,若初始解质量较优,元启发式算法的全局寻优也较易实现。因此,纯粹的元启发式求解方式并不一定能够在有限时间内得到全局最优解。若可以改进初始解集的随机选择特征,在此基础上利用更高效的全局搜索能力,定会在聚类解的求解速度、准确性、精确性等指标上取得均衡的优化效果。基于此考虑,结合K均值算法的局部快速开发寻优能力和化学反应算法的全局勘探能力,以K均值得到的聚类解集合作为化学反应算法的初始分子结构群,通过4种简单的化学反应操作,增加种群分子结构的多样性,更快速得到不同特征的文本文档聚类结果。
2 模 型
2.1 文本聚类模型
文本聚类即是将一个文本文档集合D划分为K个聚类,D表示文本文档集合D=d1,d2,…,di,…,dn,di表示集合D中的文档i,n表示集合D中所有文本文档数量。每个文档i可表示为矢量di=wi,1,wi,2,…,wi,j,…,wi,t,di即为集合D中的第i个文档,文档长度为t(词条数量),wi,j表示文档i中词条j的权重值,利用词频逆文本频率指数TF-IDF计算为
(1)
其中,TF(i,j) 为文档i中词条j的频率,n为集合D内的文档数量,DF(j) 为包括词条j的文档数量,IDF(i,j) 则为文档频率倒数。
利用矢量空间模型VSM[12],文档集合D可表示为
(2)
文本聚类算法的目标是将文本文档划分为K个聚类,每个聚类拥有一个质心,表示为C=C1,C2,…,CK, 质心Ck可表示为词条权重矢量,即Ck=c1,c2,…,ct,c1为质心Ck的位置1上的取值,t为聚类质心长度。文本聚类算法应当先计算各个文档与各个聚类质心的距离,并将文档划分至距离最小的聚类质心。
2.2 聚类质量度量方式
文本文档聚类的目的是将相似文档划分至同一聚类中,不相似文档则划分在不同聚类中。余弦相似度是度量一个文档与聚类质心相似度的一种标准度量方式,可计算为
(3)
上式表示文档di与聚类质心Ck的余弦相似度。wi,j表示文档i中词条j的权重值,wk,j表示聚类质心Ck所代表的文档k中词条j的权重值。可以看出,若文档di与聚类质心Ck具有相似性,则余弦值接近于1;若文档di与聚类质心Ck不具有相似性,则余弦值接近于0。
欧氏距离是计算欧氏空间内文档与聚类质心的距离(相似性)的另一种计算方法。文档di与聚类质心Ck的欧氏距离计算为
(4)
可以看到,欧氏距离取值空间在0至1之间。若文档与聚类质心间的欧氏距离接近于0,则表明该文档与该聚类质心具有较大相似性,可划分至相应聚类中;若文档与聚类质心间的欧氏距离接近于1,则表明该文档与该聚类质心相距较远。
聚类质心Ck的计算方式为
(5)
其中,di表示文档i,nk表示聚类k中文档的数量,Ck为聚类k的质心,di∈Ck表明属于聚类k的所有文档。该式表明聚类内所有文档的矢量权重之和除以聚类内的文档数量即为该聚类的质心。
2.3 聚类目标函数
由于余弦相似度可以度量文档与质心间的相似性,欧氏距离可以度量文档与质心间的距离,本文将相似性和距离均考虑在聚类标准的目标函数中。在为文档选择相应聚类质心时,应该尽可能选择相似度高且距离最近的聚类质心,因此,聚类目标函数可设置为同步优化的双目标形式
obj(di,Ck)=Cos(di,Ck)+(1-Dis(di,Ck))
(6)
其中,Cos(di,Ck) 表示式(3)计算的余弦相似度,Dis(di,Ck) 表示式(4)计算的欧氏距离。由公式可知,聚类时目标函数应该最大化,即余弦相似度越大,欧氏距离越小,目标函数值越大。
2.4 K均值文本聚类
K均值聚类是数据聚类领域最简单有效的聚类算法,该算法可以通过聚类数K、初始聚类质心以及余弦相似度将文档划分至相似质心内,并通过若干次的质心迭代更新,直到满足终止条件,得到最终的聚类解。算法仅利用式(3)计算文档与质心间的相似度,并以一个矩阵A[K][n] 代表最终的文档聚类解,其中,K表示聚类数量,n表示文档集合中的文档数量,矩阵元素A[k][i] 定义为
(7)
上式表明,若文档di划分至质心Ck,则元素A[k][i]=1; 否则,A[k][i]=0。K均值文本聚类的目标即是寻找最优的矩阵A[K][n]。 算法执行过程如下:
算法1:K均值文本聚类过程
(1)输入: 文本文档集合D和聚类数量K
(2)输出: 以矩阵A[K][n]定义的聚类解
(3)randomly selectKdocuments as clusters centroidC=(C1,C2,…,CK)//随机选择K个文档作为初始聚类质心
(4)initialize all elements as zeros in matrixA[K][n]//初始化聚类解矩阵
(5)foreach documentdiinDdo
(6)k=argmaxk∈{1 to K}based onCos(di,Ck)//寻找余弦相似度最大的目标聚类质心
(7) allocatedito the clusterCkandA[k][i]=1//分配文档至聚类并更新矩阵元素
(8)endfor
(9)update the clusters centroid using Eq.(5)//更新聚类质心
(10)iftermination condition is not satisfied, return step 4; otherwise, return clustering solution and end
由于K均值算法在聚类过程中受初始质心选取的影响较大,所以较易于收敛在局部最优解上,尤其在文档特征相差较大时,无法找到接近最优的聚类解。因此,为了避免早熟,在已有K均值聚类较强的局部开发能力基础上,还需要进一步加强全局勘探过程。
3 融合化学反应优化和K均值的文本聚类
在若干次迭代的K均值文本聚类的结果上,本文进一步引入化学反应优化算法对文本聚类结果进行优化,寻找文本聚类结果的全局最优解。化学反应优化算法CRO模拟实现了封闭容器中分子所发生的一系列化学反应及相互作用的过程,通过不断迭代寻找分子结构的稳定状态[13]。每一次化学反应均会使环境中生成新的分子结构,且每一个分子拥有唯一的结构。
3.1 化学分子结构的聚类解编码及解码
将一个分子结构编码为一种可能的文本聚类解,每个分子由两个原子集构成,一个原子集代表分子的元素位置,表示文档序列,另一个原子集代表元素取值,表示对应文档所属的聚类质心。两个原子集均可表示为长度为n的矢量,n为文档总数。若文档划分为K个聚类,则元素取值代表的聚类质心原子的变量范围为 [1,2,…,K]。 图1所示为一种可能的分子结构,该分子结构表明总共有8个文档划分为3个文本聚类,即n=8,K=3。具体的分子结构解码信息为:聚类C2拥有3个文档,文档d1、d3和d6划分至聚类C2中;聚类C1拥有3个文档,文档d2、d5和d8划分至聚类C1中;聚类C3拥有两个文档,文档d3和d7划分至聚类C3中。
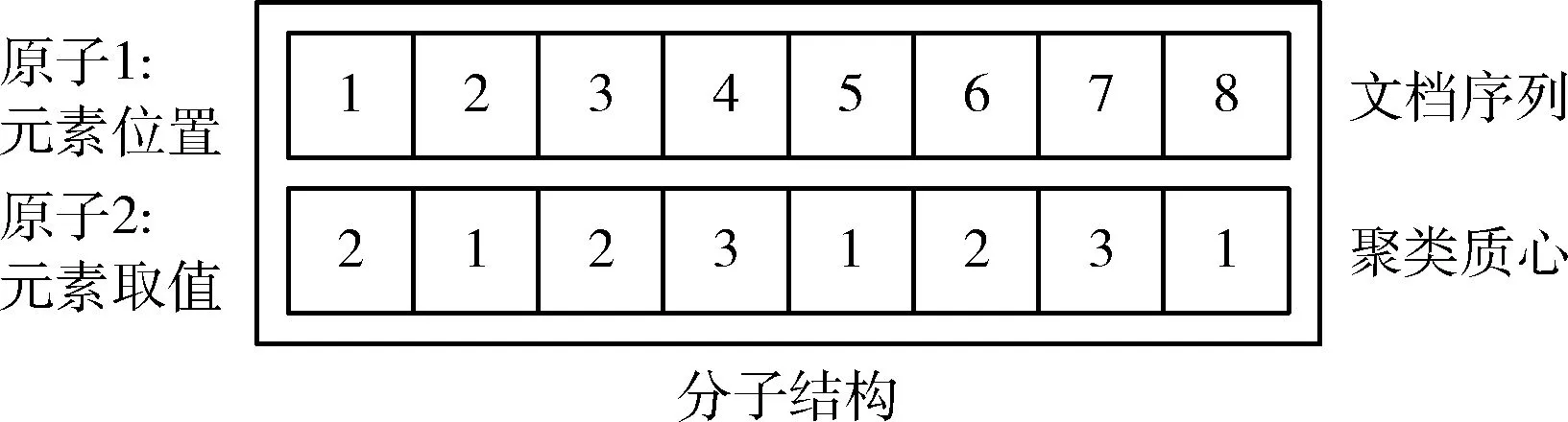
图1 化学分子结构编码
3.2 新聚类解的生成
化学反应优化算法CRO中,分子一共会经历4种化学反应操作:单分子碰撞、单分子分解、分子间碰撞和分子间合成。单分子碰撞与分子间碰撞对原分子结构的影响较小,主要用于在邻域空间内搜索局部更优解,属于局部开发过程;单分子分解和分子间合成对原分子结构的影响较大,可以较大改变原分子结构,主要用于开辟更大的搜索空间,属于全局勘探过程。
(1)单分子碰撞
单分子碰撞是单个分子的化学反应行为,即:一个原分子Φ与封闭容器内壁会发生碰撞,生成一个新的分子结构Φ’,两个分子在原子结构上拥有不同的特征。具体碰撞实施过程如下:首先,从表示元素位置的原子中随机选择一个位置,即随机选择一个文档;然后,将其对应的元素取值在[1,K]间做随机改变,生成一个新的分子结构,即:单分子碰撞会随机改变一个文档所属聚类。如图2所示的单分子碰撞示例中,随机选择的文档为x=d3,原本属于文本聚类C2,经过碰撞后,d3划分至聚类C1中,其它分子结构保持不变,即其它文档所属聚类不变。得到新分子结构后,算法解码出分子结构对应的文本聚类解,并计算聚类解的适应度。若适应度优于原分子,则保留新分子在候选聚类解中;否则,丢弃新分子。
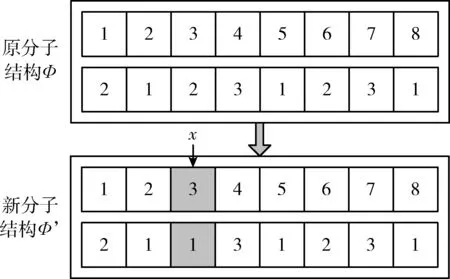
图2 单分子碰撞
(2)单分子分解
与单分子碰撞相似,单分子分解也是分子自身的化学反应过程,但会生成两个新的分子结构Φ1’和Φ2’。具体分解过程如下:将原分子结构Φ划分为奇数号文档和偶数号文档,奇数号文档及其所属聚类结构保留至新分子Φ1’中,Φ1’中偶数号文档所属聚类则在[1,K]内随机生成;偶数号文档及其所属聚类结构保留至新分子Φ2’中,Φ2’中奇数号文档所属聚类则在[1,K]内随机生成。如图3所示的单分子分解示例中,新分子结构Φ1’中文档d1、d3、d5和d7所属聚类与原分子Φ保持一致,文档d2、d4、d6和d8所属聚类随机生成;新分子结构Φ2’中文档d2、d4、d6和d8所属聚类与原分子Φ保持一致,文档d1、d3、d5和d7所属聚类则随机生成。得到新分子结构后,算法解码出分子结构对应的文本聚类解,并计算聚类解的适应度。若适应度优于原分子,则保留新分子在候选聚类解中;否则,丢弃新分子。

图3 单分子分解
(3)分子间碰撞
分子间碰撞可以通过两个原分子结构Φ1和Φ2生成两个新的分子结构Φ1’和Φ2’,属于多分子间的化学反应行为。具体碰撞过程如下:在两个原分子结构Φ1和Φ2上随机选择两个位置x和y,将Φ1中位置x和y间的文档所属聚类保留至新分子结构Φ1’中,其余位置上文档的所属聚类与Φ2保持一致,得到新分子结构Φ1’;将Φ2中位置x和y间的文档所属聚类保留至新分子结构Φ2’中,其余位置上文档的所属聚类与Φ1保持一致,得到新分子结构Φ2’。如图4所示的分子间碰撞示例中,新分子结构Φ1’中文档d3、d4、d5和d6所属聚类原分子Φ1一致,文档d1、d2、d7和d8所属聚类原分子Φ2一致;新分子结构Φ2’中文档d3、d4、d5和d6所属聚类原分子Φ2一致,文档d1、d2、d7和d8所属聚类原分子Φ1一致。得到新的分子结构后,算法解码出分子结构对应的文本聚类解,并计算聚类解的适应度。若适应度优于原分子,则保留新分子在候选聚类解中;否则,丢弃新分子。

图4 分子间碰撞
(4)分子间合成
分子间合成可以通过两个原分子结构Φ1和Φ2生成一个新的分子结构Φ’,属于多分子间的化学反应行为。具体合成过程如下:在两个原分子结构Φ1和Φ2上随机选择一个位置x,保留Φ1中位置x左侧文档所属聚类信息至新分子结构Φ’的左侧位置,保留Φ2中位置x右侧文档所属聚类信息至新分子结构Φ’的右侧位置,得到一个新分子结构Φ’。如图5所示的分子间合成示例中,随机位置x=4,则新分子Φ’中文档d1、d2、d3和d4所属聚类原分子Φ1一致,新分子Φ’中文档d5、d6、d7和d8所属聚类原分子Φ2一致。得到新分子结构后,算法解码出分子结构对应的文本聚类解,并计算聚类解的适应度。若适应度优于原分子,则保留新分子在候选聚类解中;否则,丢弃新分子。

图5 分子间合成
3.3 分子质量评估适应度
适应度函数用于评估分子结构代表的聚类解质量。本文利用平均文档相似质心计算聚类解适应度,基于式(6)的目标函数,适应度函数综合利用了目标函数取值在K个聚类上的均值结果,具体为
(8)
其中,nk表示聚类k中的文档数量。
3.4 算法过程
结合K均值和化学反应优化算法CRO,本文设计了一种文本聚类算法,算法命名为KMCRO。KMCRO算法将K均值聚类生成的结果作为化学反应算法CRO的初始输入,将K均值聚类优秀的局部开发能力和化学反应算法强大的全局勘探能力有效结合,有效避免陷入局部最优,防止聚类早熟收敛。算法2是KMCRO算法的执行过程。该算法分为两个阶段,第一阶段执行K均值聚类算法,即步骤(3)~步骤(16)。该阶段在若干次迭代基础上寻找局部的最优聚类,由于仅是局部最优解,迭代次数可以设置较小,以较快的时间获得最优解。第二阶段执行化学反应算法,即步骤(17)~步骤(30),K均值聚类生成的解集合将作为化学反应算法的初始输入。该阶段在已有K均值聚类的局部最优解的基础上进一步做全局勘探,因此其迭代次数要长于K均值阶段,以便最终获得全局最优解。融合K均值和化学反应算法的文本聚类算法KMCRO可以在局部开发能力和全局勘探能力间做出有效均衡,并最终获得更准确的文本聚类解。
算法2: KMCRO算法
(1)输入: 文本文档集合D、 文档数量n、 聚类数量K、K均值聚类迭代次数KImax、 化学反应过程迭代次数CImax
(2)输出: 最优聚类解
(3)initialize randomly a solution setCRMwithSclustering solution
(4)fors=1 toSdo
(5) randomly selectKdocuments as clusters centroidC=(C1,C2,…,CK)
(6)forI=1 toKImaxdo
(7) initialize all elements as zeros in matrixA[K][n]
(8)foreach documentdiinDdo
(9)k=argmaxk∈{1 to K}based onCos(di,Ck)
(10) allocatedito the clusterCkand setA[k][i]=1
(11) update the clusters centroid using Eq.(5)
(12)endfor
(13)endfor
(14) transfer matrixA[K][n] into encoded solutions of CRO
(15) generate newCRMwith solutions produced byK-means clustering
(16)endfor
(17)forI=1 toCImaxdo
(18) select randomly solutionΦfromCRM
(19)call单分子碰撞
(20) compute fitness of new molecule and reserve the better molecule toCRM
(21) select randomly solutionΦfromCRM
(22)call单分子分解
(23) compute fitness of new molecule and reserve the better molecule toCRM
(24) select randomly solutionΦ1andΦ2fromCRM
(25)call分子间碰撞
(26) compute fitness of new molecule and reserve the better molecule toCRM
(27) select randomly solutionΦ1andΦ2fromCRM
(28)call分子间合成
(29) compute fitness of new molecule and reserve the better molecule toCRM
(30)endfor
(31)returnthe molecule with best fitness inCRMand encode clustering solution
算法详细说明:步骤(1)和步骤(2)为算法的输入输出,步骤(3)随机初始化一个规模为S的聚类解集CRM,针对每一个CRM中的解,执行K均值聚类算法对其更新,具体地,步骤(5)随机选择K个质心,步骤(7)对K均值的聚类解矩阵初始为0,步骤(8)~步骤(10)为每个文档寻找至质心相似度最大的质心进行聚类,步骤(11)更新质心,步骤(14)将K均值矩阵聚类解转换为化学反应算法中使用的分子结构编码,并在步骤(15)中以所有生成的聚类解得到新的解集合CRM,化学反应算法在现有CRM基础上做进一步聚类搜索。步骤(18)~步骤(20)执行化学反应中的单分子碰撞,步骤(21)~步骤(23)执行化学反应中的单分子分解,步骤(24)~步骤(26)执行化学反应中的分子间碰撞,步骤(27)~步骤(29)执行化学反应中的分子间合成,最终,步骤(31)输出当前CRM中适应度最高的分子结构并解码出文本聚类解作为KMCRO算法的最终解。
图6所示是文本文档完整聚类分析流程图。流程分为3个阶段,第一阶段是对文本信息进行预处理,包括对词语进行分割、移除文档中的终止词、提取文档词干并计算词条权重值;利用词频逆文本频率指数TF-IDF计算得到全部词条权重后,即可将文档信息表征为矢量空间模型VSM,基于VSM对文档进行聚类分析。第二阶段是利用K均值算法实现文本聚类,经过KImax次迭代后,将K均值算法生成的聚类解集转换为化学反应优化算法的分子结构。第三阶段将K均值聚类结果作为化学反应优化的初始分子结构群,经历CImax次迭代过程的单分子碰撞、单分子分解、分子间碰撞和分子间合成4种化学反应操作后,最后输出适应度最优的分子结构并解码为最终的文本文档聚类解。

图6 文本文档完整聚类分析流程
4 实验分析
4.1 测试文本
利用Matlab实现融合化学反应算法与K均值的文本聚类算法KMCRO,观察在给定测试文本数据集合中融入化学反应机制后聚类效果的变化。利用表1所示的6种基准文本数据集测试算法性能,该数据集是美国加州大学计算智能实验室 LABIC提供的文本聚类标准数据集(http://sites.labic.icmc.usp.br/text_collections/),是经过词条提炼后得到的数值抽象形式。数据集DS1为技术报告文摘,包含理论、人工智能、机器人和系统4类话题;数据集DS2来自Web页面,包含山羊、生物医学、绵羊和乐队4类话题;数据集DS3、DS4、DS5和DS6均来自TREC,涉及的话题数分别为6、8、9、10。同时,测试数据集还给出了其包含的文档数量和词条数量。选择常规K均值文本聚类算法、基于粒子群算法的文本聚类算法PSOTC[10]和基于遗传算法的文本聚类算法GATC[11]进行对比分析。

表1 测试文档数据集
4.2 评估指标
引入4种常用文本聚类评估指标对算法的聚类效果进行评估,包括:准确率(Accuracy,A)、精确率(Precision,P)、召回率(Recall,R)和F度量(F-meansure,F)。除此之外,通过计算迭代过程中聚类解的适度度值描述算法的收敛情况,来评估文本聚类算法的计算速度。
(1)精确率P
精确率P表示所有相关文档与所有聚类中文档总量的比例,计算方式为
P(i,j)=ni,j/nj
(9)
其中,P(i,j) 表示聚类j中分类i的精确值,ni,j表示聚类j中分类i的实际成员数量,nj为聚类j中的所有成员数量。
(2)召回率R
召回率R表示相关文档的实际数量与所有聚类文档间的比例,该指标需要根据给定的分类标签对每个聚类进行计算,计算方式为
R(i,j)=ni,j/ni
(10)
其中,R(i,j) 表示聚类j中分类i的召回值,ni表示分类i中的实际成员数量。
(3)F度量F
F度量根据聚类精确率P和召回率R进行计算。最佳的文本聚类效果是F度量值尽量接近于1。聚类j中分类i的F度量计算为
(11)
所有聚类的F度量计算为
(12)
其中,n表示文档集合D中的文档总量。
(4)准确率A
准确率用于计算分配至每个聚类的真实文本文档所占的比例,计算为
(13)
其中,K表示总聚类数量,P(i,j) 表示聚类j中分类i的精确值。
(5)适应度
即式(7)定义的聚类解的适应度值,可用于描述算法的收敛速度。
4.3 实验分析
表2所示是4种算法在6种测试数据集合中得到的聚类精确率、准确率、召回率和F度量指标上的性能表现,加粗数值为该指标上的最优值。从整体上可以看到,本文算法在绝大多数测试文本数据中均可以得到最佳的性能指标值,在数据集DS1、DS5和DS6上算法的4个指标均是最优的。DS2和DS3中的精确率和DS4中的准确率稍有差异,但不足以影响算法的整体性能,这可能是源于第一阶段中初始质心选择的影响。在6个文本测试数据集中稳定的表现表明,本文算法结合K均值算法的局部快速开发寻优能力和化学反应算法的全局勘探能力进行文档聚类是有效可行的。

表2 聚类指标表现
图7是6种基准文本数据集测试得到的4种算法的适应度变迁情况。最终的稳定聚类适应度值是经过迭代进化得到的最优聚类解的适应度值。从不同类型的文本数据集的测试结果看,K均值聚类算法在多数情况下收敛较快,但其得到的适应度值最小,这是由于该算法基本是一种局部寻优算法,其最终的聚类解对于初始聚类质心的选择较为依赖,而随机式的初始质心选择也加大了算法的不稳定性。两种元启发式对比算法通过种群进化机制对聚类解空间做了进一步扩展,加大了得到全局最优解的概率,但其随机化的粒子初始位置以及遗传个体的随机性依然没有根本解决进化个体可能出现的早熟问题。本文算法结合K均值算法的局部快速开发寻优能力和化学反应算法的全局勘探能力,以K均值得到的聚类解集合作为化学反应算法的初始分子结构群,通过4种化学反应操作,增加种群分子的多样性,在扩展搜索空间的基础上得到最优文本聚类结果,因此,其得到的适度值是最高的。同时,综合6种测试数据集合的结果来看,本文算法具有很好的适应性,面对不同类型不同话题分布的文本集,基本上都可以得到最佳的聚类适应度,说明聚类效果上相似性和距离度量均做到了最优。

图7 适应度值
图8观察本文算法在利用不同的聚类质量标准时的性能,即单独利用余弦相似度度量、单独利用欧氏距离度量以及混合双目标度量时的表现,选择聚类准确率A和F度量值进行评估。左侧纵坐标为聚类准确率指标,右侧纵坐标表示聚类F度量指标,横坐标上的柱状图对应左侧纵坐标,横坐标上的折线图对应右侧纵坐标。可以看到,同步融合余弦相似度和欧氏距离在适应度函数中得到的聚类效果在所有测试文本数据集中均产生了比单目标度量更好的效果。此外,单独以余弦相似度或欧氏距离作为聚类标准时的效果相差并大,从准确率和F度量看,余弦相似度得到的聚类效果略好一些。
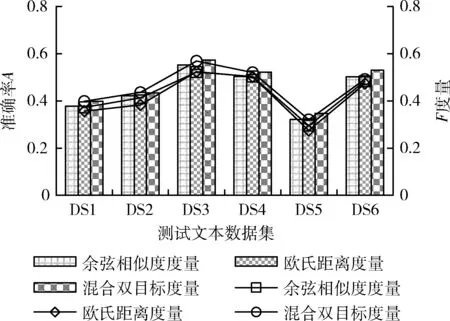
图8 聚类目标度量方式
5 结束语
提出一种融合化学反应算法和K均值算法的文本文档聚类算法。算法首先利用K均值算法快速获得文本聚类局部最优解集合,再以该解集合作为化学反应机制的初始输入,在此侯选聚类解集合上进行4种分子化学反应,结合K均值的局部快速开发寻优能力和化学反应算法的全局勘探能力,得到文本聚类最优解。经过6种数据集的聚类测试,结果表明,该算法可以比基准算法获得性能更好的聚类结果,且适应度更优,聚类准确度更高。
