基于主动缓存的云边端协同卸载策略
2021-08-23张苏豫江凌云
张苏豫,江凌云
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引 言
随着移动设备(MDs)和移动通信技术的发展,出现了越来越多的计算密集和延迟敏感的应用程序。如果MDs在本地执行这些计算任务,由于移动设备有限的计算能力,将消耗大量的能量同时产生很大的延迟。为了解决这个问题,移动云计算(MCC)应运而生。它通过将计算任务转移到云端,可以缓解移动终端的能耗问题。但由于用户与云端之间的距离较远,可能会引起网络抖动[1]和较长的延迟,不能满足延迟敏感的应用程序的需求。因此,移动边缘计算(MEC)被提出,以解决MCC在计算卸载方面的不足。由于边缘服务器被部署在无线网络的边缘,相对于云端距离用户更近,因此数据传输延迟大大降低。近年来,边缘服务器的缓存能力也受到了学术界和工业界的广泛关注。由于边缘服务器可以同时提供计算和存储功能[2],一些研究考虑将缓存和计算卸载结合起来以进一步提高系统性能。
最近的一些研究通过部署云端和边缘服务器形成一个三层的边缘计算架构。每个任务都可以在边缘服务器、云端或本地处理。将任务卸载到边缘服务器或云端将不可避免地产生额外的通信延迟,而在本地执行任务可能导致更大的计算延迟。所以,移动用户在三层计算架构中针对不同的计算需求做出正确的卸载决策是至关重要的。以前的许多研究表明,来自邻近社区的任务请求中有相当一部分是相同的。如果所有重复的任务请求都被计算一次,将会导致计算资源和网络资源的巨大浪费和严重的网络拥塞。为了避免这种情况,有必要找到一种有效的缓存算法来解决任务的重复请求问题。在网络边缘(如网关、基站和终端用户设备)缓存流行内容可以避免重复计算,因此会大大减少延迟[3],从而提高用户体验质量。目前主流的缓存方案为内容缓存和任务结果的主动缓存。与内容缓存不同,任务结果的主动缓存是根据当前用户的计算请求进行实时调整的,而不是预先放置在服务器中。因此,它可以大大提高缓存命中率,减轻计算负担并提高卸载效率。
1 相关工作
在移动边缘计算中,已经提出了一些任务计算结果缓存策略。文献[4]提出整数规划,以确定将哪些计算任务集中缓存到MEC服务器,哪些不缓存到MEC服务器。文献[5]采用智能优化算法,设计了MEC服务器和云端联合下的计算分流和数据缓存模型。将资源约束延迟最小化问题转化为优化问题,提出了一种基于遗传算法和模拟退火算法的启发式算法。文献[6]提出了多用户场景下移动边缘计算的缓存增强方案(OOCS)和最优卸载,分别最小化整体执行延迟。此外,还出现了许多策略和架构,如基于博弈论的文献[7]和基于MVR的文献[8,9],他们都以减少MDs的响应延迟和能耗为目标。在多用户卸载场景中,缓存问题、资源分配和云协作通常是相关的。文献[10]联合考虑了分流、内容缓存和资源分配,以最大限度地提高整体网络收益。文献[11]研究了支持全双工(FD)的小蜂窝网络中的内容缓存和计算卸载。文献[12]通过结合计算分流和数据缓存来优化调度计算请求,以最小化总延迟。文献[13]考虑了异构云场景中任务卸载的灵活调度策略,其中MEC服务器和云端可以协作处理具有不同延迟需求的应用程序。
但是以上提出的缓存算法和计算卸载算法只适用于单一MEC服务器或单目标函数场景,而且没有考虑到任务流行度的动态变化。因此本文首先提出多MEC服务器和云端联合缓存算法,在此基础上用线性回归模型进行任务预测,找出最优的云边端协同卸载方案,最小化总时延。
2 云边端协同卸载策略
本节首先给出了边缘计算系统结构,然后提出了多MEC服务器与云端联合的主动缓存算法,在此基础上介绍了用于任务预测的线性回归模型,最后给出了基于上述主动缓存算法的云边端协同卸载策略。
2.1 系统结构
图1给出了边缘计算系统结构,它由云端、MEC服务器和多个移动设备组成。MEC服务器和云端通过有线回程链路连接,而MEC服务器和移动设备通过无线链路连接。首先,将一个复杂的计算任务按优先级或QoS级别进行粒度划分,划分成多个子任务,每个子任务可以被卸载到适当的节点。移动用户可以选择在本地计算任务,也可以选择从MEC服务器和云端直接获取已经缓存的任务结果,或者将任务转移至MEC服务器和云端进行计算。
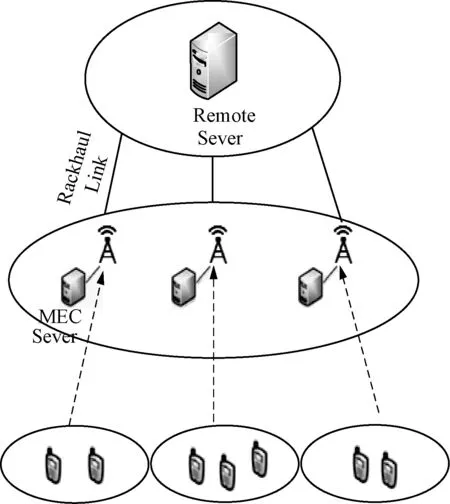
图1 系统结构
2.2 主动缓存算法
本节提出的主动缓存算法,是云边端协同卸载策略(CEECO)的核心。由于MEC服务器的缓存能力有限,但传输延迟小;而云有足够的缓存能力,但传输延迟大。所以我们利用云端和MEC服务器的联合缓存来确定任务结果的最佳缓存状态。我们假设在每个时隙中,所请求的计算任务服从Zipfs分布,我们定义第i个计算请求任务结果为Reqi,i∈N,该计算任务历史总请求次数为nReqi,近一周内的请求次数为nWeeki。每个MEC服务器都会通过一个计数器记录所有计算任务的历史总请求次数和近一周内的请求次数。假设MEC服务器缓存的任务结果集合为Ωe,云缓存的任务结果集合为Ωc。一开始Ωe和Ωc都为Φ。提出的缓存算法分为3个阶段。
第一阶段:MEC服务器的存储空间没有被填满。一些MDs将计算任务卸载到MEC服务器进行计算,MEC服务器计算完成后将任务结果缓存下来,同时记录每个任务历史总请求次数和近一周内请求次数,它们决定了该任务的流行度。随着计算任务的逐渐增加,进入下一阶段。
第二阶段:此时MEC服务器存储空间已满。如果新请求的任务具有更高优先级排名,那么已经缓存的任务结果将被新请求的任务结果替换掉。简单来说,流行度越高,任务结果占用存储空间越小,则优先级越高。比较后删除优先级最低的任务结果,并将该任务结果告知云端,然后进入下一阶段。
第三阶段:云端处理被MEC服务器删除的任务结果。如果云端缓存中没有被MEC服务器删除的任务结果,则将它缓存下来,否则丢弃。该算法的具体流程如图2所示。

图2 主动缓存算法流程
具体的算法如下所示:
算法1:主动缓存算法
(1)Initialize Ωe= Φ,Ωc= Φ,
(2)for i = 1: |N| do
(3)MEC gets Reqiby Zipf popularity;
nReqi=nReqi+1;
(4) if there is Reqiin Ωethen
(5) delete Reqi;
(6) else
(7) if Ωeis not full,then
(8) Reqi→Ωe;
(9) else
(10)Rank nReqiand nWeekiin descending order respectively,
(11) TotalRank=Rank(nReqi)+Rank(nWeeki);
(12) if exists a task na∈Ωe, with lower TotalRank than Reqior with same TotalRank as Reqibut larger than nReqithen
(13) Reqi→ Ωe;
(14) if no nain Ωcthen
(15) na→Ωc;
else
(16) delete na;
(17) else
(18) if no Reqiin Ωcthen
(19) Reqi→Ωc;
(20) else
(21) delete Reqi;
(22)end for
(23)Output Ωe,Ωc
2.3 云边端协同卸载策略
2.3.1 任务预测
我们准备用训练好的线性回归模型对任务计算时间进行预测。线性回归是一种对因变量y和自变量x之间的关系进行建模的监督学习方法,它利用线性预测函数建立线性回归方程,是第一个被广泛研究和应用的回归技术。当自变量x1,x2,x3,x4的值与因变量y的值密切相关时,可以用线性回归模型具体地描述他们之间的关系。在我们的模型中,输入为T_CPU,T_Mem,M_CPU,M_Mem,输出为Time(s)。
T_CPU,T_Mem表示处理任务所需的CPU和内存资源。M_CPU,M_Mem表示一个处理器(MEC,云或本地)当前所拥有的CPU和内存资源。Time(s)为任务计算时间。具体的模型建立过程见第三节。
2.3.2 卸载策略
基于以上提出的主动缓存算法,我们得出了5种云边端卸载执行策略。每种策略的总延迟由计算延迟和传输延迟相加得到。其中计算延迟均由线性回归预测模型预测得到。计算卸载参数见表1。

表1 计算卸载参数
(1)MEC缓存模型:我们将MEC服务器的缓存向量定义为Y={y1,>y2,>…,>yN},其中yi∈{0,1}。如果yi=1,则表示MEC服务器已经缓存了第i个任务结果并直接传输给MD,否则yi=0。此外,由于MEC服务器的传输功率远大于MD,而任务结果大小远小于任务本身的大小,可以忽略无线下行链路上的传输延迟。因此,我们认为MEC缓存模型的总延迟为0。
(2)云缓存模型:云缓存向量为X={x1,>x2,>…xN},其中xi∈{0,1}。xi=1表示云端已经缓存了第i个任务结果并传输给MEC服务器,然后MEC服务器通过无线下行链路传输给MD;否则xi=0。考虑到云与基站之间的距离较长,回程延迟是不容忽视的。
云缓存模型总延迟由式(1)得到
(1)
(3)本地计算模型:本地计算向量定义为α={α1,α2,>…,>αN},αi∈{0,1}。如果αi=1,表示在本地执行第i个计算任务,否则αi=0。由于没有传输延迟,本地计算模型总延迟TLocal直接由线性回归模型预测得到。
(4)MEC计算模型:MEC计算向量定义为β={β1,β2,>…βN},βi∈{0,1}。如果βi=1,表示在MEC服务器计算第i个计算任务,否则βi=0。MEC计算模型总延迟(Tc_MEC)由线性回归模型预测得到。
MEC计算模型总延迟由式(2)得到
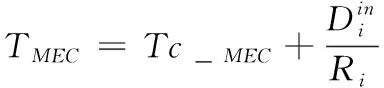
(2)
(5)云计算模型:云计算向量定义为θ={θ1,θ2,…,θN},θi∈{0,1}。如果θi=1,表示在云上计算第i个计算任务,否则θi=0。云计算延迟(Tc_CLOUD)由线性回归模型预测得到。
云计算模型总延迟由式(3)得到
(3)
第i个计算任务的执行延迟可以简化为

综上所述,卸载策略为:
(1)当MEC服务器缓存了当前任务的计算结果(yi=1),直接从MEC服务器获取任务结果,此时时延近似为0,这是优先级最高的方案。
(2)当MEC服务器没有缓存当前任务的计算结果(yi=0),但是云端缓存了任务结果(xi=1),此时比较本地计算任务、将任务卸载到MEC服务器进行计算、直接从云端缓存获取任务结果的时延,取最小时延方案。其中本地计算和卸载到MEC服务器进行计算的时延通过训练好的线性回归模型预测得到。
(3)当MEC服务器和云端都没有缓存当前任务的计算结果(yi=0,>xi=1),此时比较本地计算任务、将任务卸载到MEC服务器进行计算、云端计算的时延,并取最小时延方案。三者的时延都可以通过训练好的线性回归预测模型预测得到。
3 评 估
本节对提出的算法进行了仿真。先利用数据集训练并验证了线性回归预测模型的有效性,再将主动缓存算法(ACA)与其它缓存算法进行对比,结果显示了ACA算法有着更小的任务响应时延。最后,将提出的基于主动缓存算法的云边端协同卸载策略(CEECO)与其它相关卸载策略进行对比,结果显示CEECO有着更好的时延优化。
3.1 线性回归预测模型的有效性
3.1.1 训练数据收集
为了准确预测每个子任务的处理时间,我们使用Google-cluster-2011-2数据集跟踪训练我们的线性回归模型,该数据集是在一个拥有大约12.5 k个云节点的集群上收集的,时间跨度为2011年5月以来的29天,是进行任务调度研究常用的数据集。虽然是以前的数据集,服务器性能在不断提高,但是只要衡量服务器性能的单位保持一致,就不影响训练模型的正确性。为了方便处理,首先我们对数据进行归一化。部分训练数据见表2。
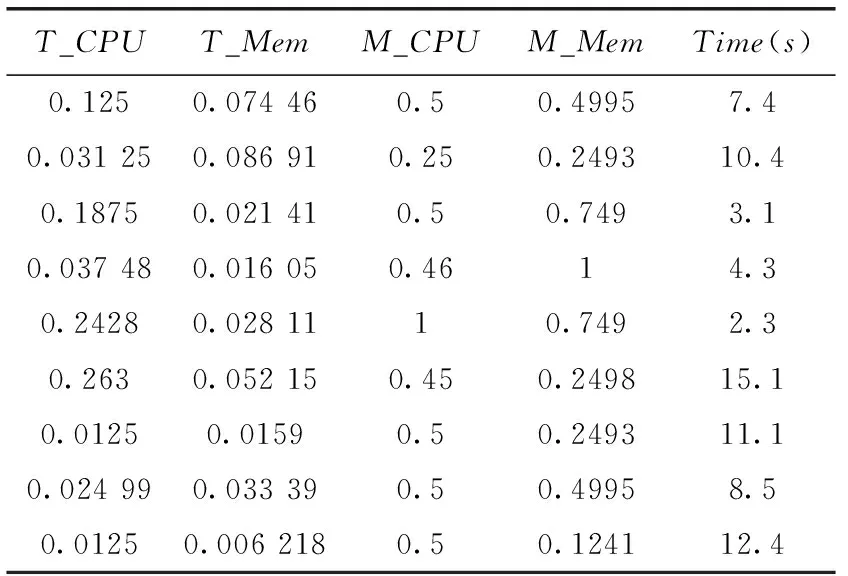
表2 训练数据
T_CPU,T_Mem通过查阅数据集中《任务事件表》的“所需CPU核心资源”和“所需内存资源”字段得到。他们都是通过程序分析得到。
M_CPU,M_Mem通过查阅数据集中《处理器事件表》的“资源:CPU”,“资源:内存”字段和云端资源监视器监控的处理器当前负载百分比联合得到。最后,Time(s)是某节点当前状态下执行某任务的时间,这个数据可以由《任务资源利用表》中“任务计算起始时间”和“任务计算终止时间”字段得到。利用这些数据,我们训练了一个线性回归模型。
3.1.2 模型训练
我们选取了2000组数据进行训练,并随机选出一个预测值与标签值进行对比。训练环境为python 3.5 Tensorflow and Keras。模型训练参数见表3。

表3 模型训练参数
模型训练结果如图3所示。

图3 预测模型结果
MSE(均方损失)为0.0183,说明拟合效果比较理想。图中W为权重矩阵。可知执行任务时延与T_CPU,T_Mem正相关,与M_CPU,M_Mem负相关,与实际情况相符合。
综上所述,我们提出的线性回归预测算法准确率高,与实际执行时延相差很小。
3.2 云边端协同卸载策略(CEECO)的性能评估
3.2.1 主动缓存算法的有效性
在本节中,我们将通过实验仿真首先来验证所提主动缓存算法的有效性。随机生成20个MDs和5个MEC服务器,同时包含一个远程云服务器。每个MD请求的计算任务来自固定子任务集k。该任务集中子任务文件的大小服从高斯分布,(平均值,方差)为(10,2)MB。子任务文件的流行度符合Zipf分布[14]。每个MEC服务器都有100 MB缓存空间。为了进行比较,我们引入了3个基准缓存算法:任务流行缓存算法(TPC)、最优任务缓存算法(OPTC)和远程云缓存算法(RCSR)。
最优任务缓存算法(OPTC): MDs请求的所有子任务结果都缓存到其访问最频繁的MEC服务器中,即MD可以直接从MEC服务器获取相应的子任务结果,即所有的子任务请求都可以获得最低的延迟响应,这是一种理想状态。
任务流行缓存算法(TPC):不考虑其它影响因素,所有的MEC服务器都缓存流行度最高的子任务结果。在这种情况下,任务流行度是唯一的影响条件,同时也忽略了流行度不高的子任务。
远程云缓存算法(RCSR):只有远程云缓存所有子任务结果,MEC服务器不缓存任何子任务结果。
图4显示了所利用的MEC服务器缓存空间与子任务平均响应时间之间的关系。总的来看,所利用的服务器缓存空间越大,子任务的响应时间越短。因为随着缓存越来越满,子任务请求就越容易命中。当缓存空间固定时,我们需要合理地将子任务结果部署到边缘服务器和云端,以提高子任务的命中率,减少子任务的响应时间。由于OPTC意味着所有子任务请求总是以最佳方式完成,所以性能也与MEC服务器的缓存空间无关。从图4可知,在这种情况下,子任务响应延迟始终保持在0.25 s以下。RCSR只在远程云中缓存最流行的子任务结果,传输延迟大,所以会造成最大的响应延迟。TPC的响应延迟约为1.5 s,提出的主动缓存算法(ACA)的性能总是优于TPC。而当缓存空间足够大时,ACA算法性能几乎和OPTC一样。
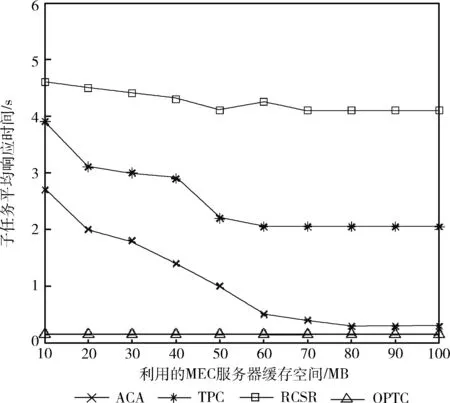
图4 子任务响应时间随缓存空间的变化
这是因为:①我们提出的主动缓存算法属于动态缓存算法,将最流行的子任务结果优先缓存到MEC服务器,传输延迟小。同时又考虑了子任务结果大小对缓存空间的影响。②由于MEC服务器的缓存空间有限,我们还结合了云端缓存,云端有充足的缓存空间,所以基本覆盖最近流行的所有子任务,特别是流行度不高但仍然有访问量的子任务。
3.2.2 云边端协同卸载策略的性能评估
在本节中,我们将通过实验仿真来评估基于上述主动缓存算法的云边端协同卸载策略(CEECO)的性能。同样随机生成20个MDs和5个MEC服务器,同时包含一个远程云服务器。仿真时将CEECO与随机卸载策略和本地计算做对比,对比结果如图5所示。可以看到本地计算的总延迟最大,总延迟随着需要处理的子任务数量呈线性增长。这是因为客户端设备计算能力小,基本一直处于满负载状态,所以只能一个一个串行完成。在子任务数量不多的情况下,随机卸载策略的总延迟和CEECO相差不大,但是随着等待处理的子任务数量增多,随机卸载策略的总延迟增长速度越快,这是因为随机卸载策略没有考虑到设备的实时负载情况,将子任务卸载给满负载状态的设备会造成更多的等待时延。而由于CEECO实时监测上下文信息(设备的负载状态、信道条件),所以总能做出最优的卸载选择,表现是最好的。另外,由于一开始预测过程耗费的时延不可忽视,以及缓存还没满未达到最佳缓存状态,所以与随机卸载策略相比优势并不明显。但是随着子任务数量的增多,每个子任务的处理几乎都能选择时延最小的方案,总时延表现相对其它策略优势越来越大。

图5 总延迟随子任务数量的变化
4 结束语
随着物联网的飞速发展,新兴的应用比如AR、VR对时延要求很高,而且当下很多任务卸载存在重复计算问题。解决这些问题,首先提出了一个云端和MEC服务器联合的主动缓存算法,以确定任务结果的最佳缓存状态。该算法是考虑到任务流行度的动态缓存算法。我们将该算法与现在流行的任务结果缓存算法作比较,结果表明我们提出的主动缓存算法时延响应更低。在此基础上,我们训练了线性回归模型进行任务预测,结果验证了该模型的有效性。最后,提出了基于上述主动缓存算法的云边端协同卸载策略(CEECO)来解决资源分配和任务执行模式的选择问题。仿真验证了所提出策略的最优性和有效性,与随机卸载策略和本地计算相比时延收益最好。并且随着执行的子任务数量增多,累积的时延收益越来越大。
未来,我们将继续探索优化任务缓存算法和卸载策略,比如通过增加训练数据样本来继续优化预测模型,进一步完善主动缓存算法,以实现更小的应用程序执行时延。
