Mesh网络中基于效用转发的路由恢复算法
2021-08-23康巧琴
康巧琴,袁 丁,严 清,杨 霞
(四川师范大学 计算机科学学院,四川 成都 610101)
0 引 言
无线Mesh网络(wireless mesh networks,WMNs)[1,2]是一种特殊的Ad Hoc网络[3],由于节点频繁移动,内存和能量等资源的有限,以及基于节点自身的原因,导致网络拓扑结构不断变化。因此,提供高质量高效率通信的路由协议是确保网络正确运行的关键。
WMNs路由协议的研究集中于:一方面考虑网络节点的移动性,选择最优的备选队列和下一跳转发节点;另一方面当网络中的节点进行数据交互之后,利用网络编码和机会路由以及两者的结合使节点获得更多数据转发的可能性,减少不必要的开销。在此过程中,WMNs中的节点在进行数据转发时,形成了WMNs特有的store-carry-and-forward通信模式。如Epidemic路由协议[4,5],即传染路由,该路由协议的传递率相对来说较高,并且传输时延也较小;缺点是其适应性较差,并且传递较多的副本会消耗更多的网络资源。Prophet路由协议[6,7],利用节点之间的历史相遇情况,计算每个节点传输数据的概率大小,选择概率相对较大的节点作为下一跳转发节点,减少了数据包的重传次数,因此减少了资源的浪费,但并不适用于大部分网络环境。而Spray-And-Wait路由算法[8,9]可以降低消息在网络中的复制份数;但是若节点数限制在较小的移动范围内,或者节点之间有较强的关联性,那么该路由协议的性能会有所下降。王博等[10]提出基于效用转发的自适应机会路由方案(简称URD),利用节点之间历史交互信息,计算节点的效用值并选择效用值较大的节点作为下一跳转发节点。优点是提高了数据包的转发效率,减少了资源的消耗,不足之处是较适用于理想状态,而在实际的网络环境中,由于节点不断移动,以及节点自身资源的有限,很难保证节点之间链路一直连通,尤其是在数据传输率较高的链路中,当网络的拓扑结构发生变化时,该算法的性能有所下降。本文提出了一种基于效用转发的路由快速恢复算法(简称URM),在计算效用值[11-14]时,考虑影响效用值的各因素所占的权重不同这一特点,动态获取权重值,从而使算法能更好适应真实的网络环境。同时综合网络时延,节点的效用值和节点对之间的跳数,选择最优的下一跳转发节点,减少了时延值的增加和资源的浪费。
1 效用转发模型
1.1 模型假设
通常意义上的WMNs模型很难用以往的G=(V,>E)的形式来表示,其中V是网络中节点的集合,E为边集。节点的高速移动性,导致网络拓扑结构不断变化,节点与节点之间边的连接不够稳定。随着节点之间不断进行数据交互,节点之间存在着某种特定且相对稳定的社会关系和极强的规律性,而找到这样的关系,对于路由协议的研究很有帮助。为了便于形象的描述本文的研究过程和分析,将做出如下的假设:
(1)G=(V,>E)为网络的拓扑图,由N个节点构成,其中V为网络中的节点集合,E为定义在节点之间边的集合。
(2)节点u,v∈V,当节点u,v之间进行数据传输时,链路eu,v∈E是双向的。在复杂的网络拓扑图中,由于网络环境的不同,在不同的时刻,链路eu,v处于不稳定状态,随时可能不连通。
(3)网络拓扑由多个节点组成,分为不同的簇块,每个簇块有各自的割点和割边,删除了割点或者割边,网络拓扑则分为若干个不同的小的簇块。
(4)每个节点的缓存空间大小是一样的,每个簇块内节点分配的个数也一样。
1.2 模型的定义
图1至图3是某时刻的部分网络拓扑图,由4个簇块组成,其中节点3,5,9,B分别作为各簇块的割点,边3-B,3-5,5-9和B-9作为簇块之间的割边。此时节点S要与节点D取得通信,则需要经过多个簇块,经过多个节点的转发。那么在节点不断移动的情况下,下一跳转发节点的选择至关重要。
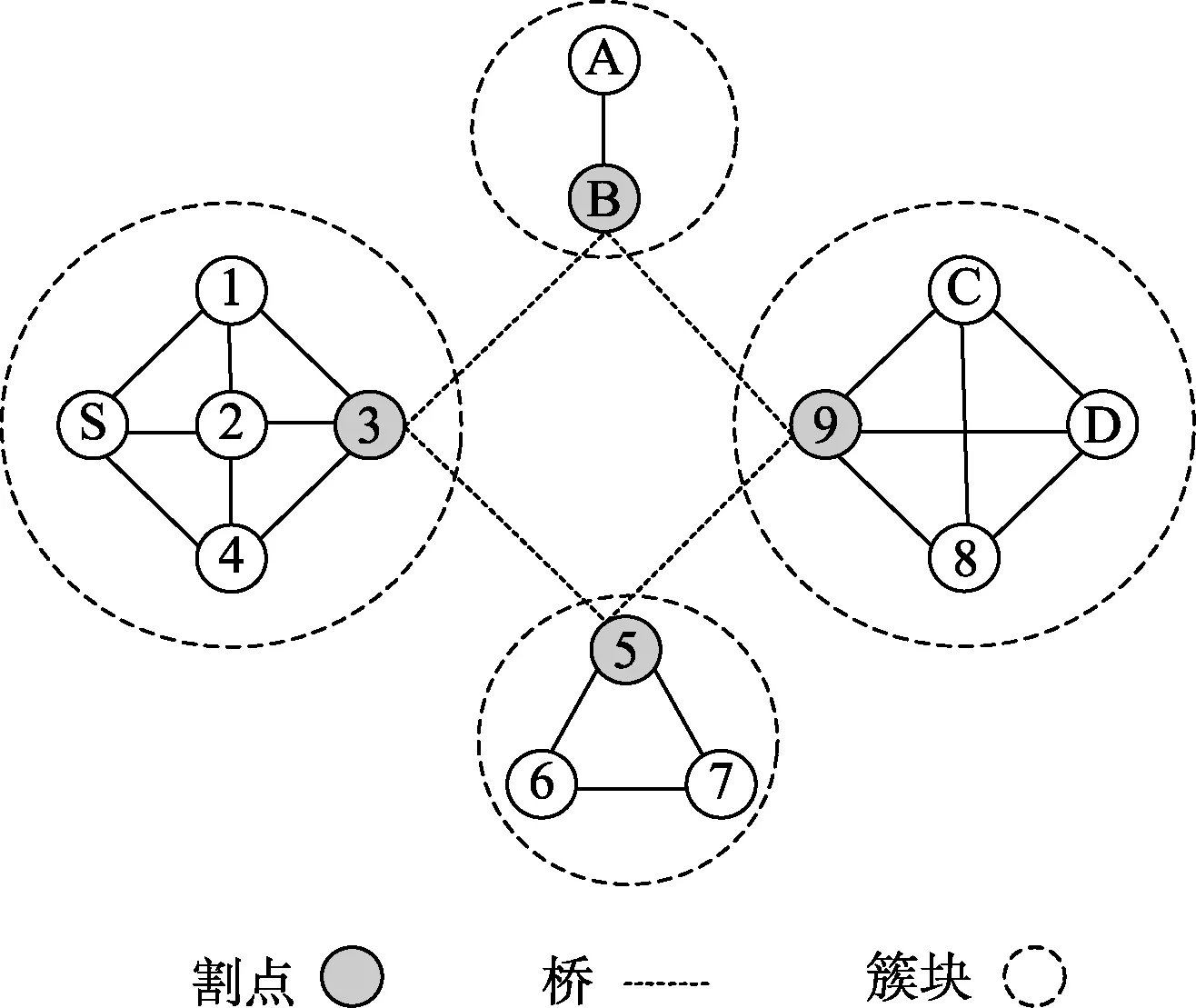
图1 t1时刻
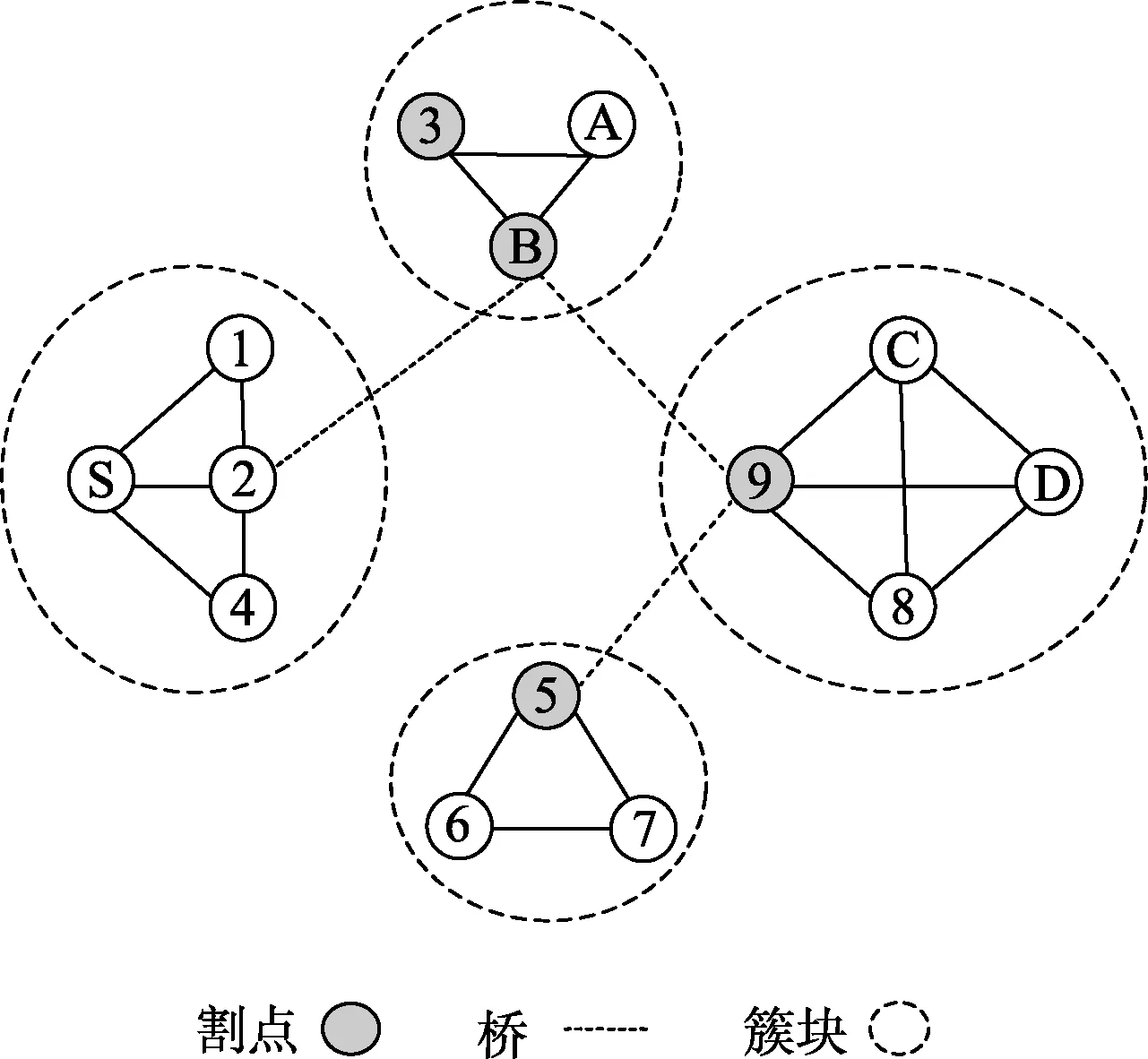
图2 t2时刻
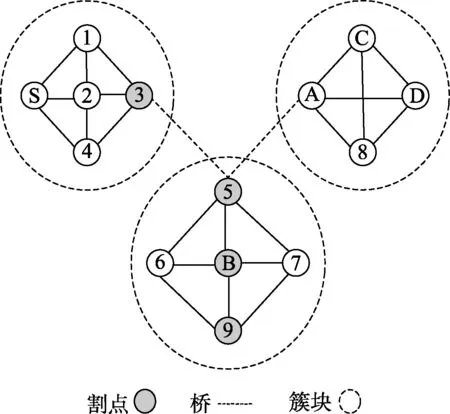
图3 t3时刻
显然,节点S和D之间没有直接的连通通道。为了选择合适的转发节点,首先节点S在其所在的簇块中,会将数据分组转发给节点3,再将数据发送给节点B或节点5,最后将数据转发给节点9,选择节点3,5,9和B的原因是这些节点作为簇块的割点。但是当前存在两个问题:
第一,由于网络中的节点在不断地移动,各个簇块中节点的位置不一定一直保持在原本的簇块中,很有可能移动到其它的簇块。比如以下的情况:
第一种情况。如图2所示,节点3在第一个簇块中时,若其将数据发送给位于第二个簇块中的节点B,此时节点3移动到第二个簇块中。这种情况下,对于下一步数据的转发没有很大影响,节点B将数据转发给节点9即可,再将数据直接转发给同一个簇块的节点D,本次数据的第一次传输完成,此过程体现了机会网络中的“存储—携带—转发”机制[15],如图4所示。

图4 节点间数据包的收发流程
第二种情况。如图3所示,假如节点B和节点9移动至第三个簇块中,节点A移动至第四个簇块中,此时第四个簇块没有割点,而节点B在第三个簇块中。节点B若要将数据转发给目的节点,则需要重新寻找转发节点,那么找到合适的转发节点成为重点。
第二,利用簇块之间的割点作为转发节点,除了可以在某种程度上提高数据的转发效率之外。一方面因为割点频繁转发数据,容易导致网络拥塞,数据分组的丢失以及传输次数的增加;另一方面由于割点自身资源有限,导致其失效也极有可能。
综上,利用节点之间数据转发的历史信息,从多角度定义节点与节点之间的效用值,并且结合时延开销以及节点之间跳数的计算,选择备选队列以及最佳下一跳转发节点。给出以下定义请参见文献[10]。
定义1节点中心度,表示为CE(m)。
定义2节点频繁度,表示为FP(m,n)。
定义3节点亲密度,表示为CP(m,n)。
定义4节点新近度,表示为RP(m,n)。
定义5节点关联度,表示为AP(m,n)。
定义6节点相似度,表示为Sim(m,n)。
定义7节点移动连通度,表示为MC(m)。
1.3 效用值各权重的确定
基于节点之间数据交互的历史数据,令当前时刻节点m到达目的节点d的总体效用值U(m,>d)[10]的具体计算公式如下
U(m,d)=αAP(m,d)+βSim(m,d)+γ(CE(m)+MC(m))
(1)
上述公式中的α、β和γ是权重因子,并且α+β+γ=1。由于网络不断变化,恶意交互行为的存在,以及网络自身因素带来较大的误差率,所以在不同时刻效用值的各参数所占的权重不同。显然,0≤U(m,>d)≤1。当节点与节点之间第一次通信时,由于各节点之间没有数据交互的历史信息,节点结合自身簇块内的中心度计算各自的效用值,即α=β=0,γ=1;随着节点之间不断通信,增加关联度的计算;一段时间过后,节点之间的通信有了一定的规律,节点的利用率也更大,形成更有效的通信数据,增加节点的相似度和移动连通度的计算。此外,考虑受到节点自身网络资源以及网络拓扑动态变化等因素的影响,设置无法正常工作的节点效用值为0。
为了体现效用值计算的主观性,在确定3个权重系数时,由于中心度用于描述一个簇块内节点之间的联通程度,不能说明簇块之间节点的联通性;关联度描述需要进行数据交互的节点之间的联通程度,而并未说明没有进行数据交互的节点之间的联通程度,因此无法完整地体现网络的稳定性能;移动连通度描述网络动态变化的程度,增加或者减少的节点越多,说明节点转发数据的可能性越大,但网络的稳定性越不好;而相似度描述两个节点之间通信的公有邻居节点集,相似度越高,则说明节点进行下一次数据传输经过公有节点的概率越大。
综上,相似度不仅描述了节点的社会属性[16,17],而且能逐渐区分出节点之间相互合作性能的高低,以及节点之间通信链路稳定性能的高低,从而在效用值的计算中,相似度对效用值的贡献相对较大。在不同的情况下,节点之间的接触频率和连接时间各不相同,节点会偏重不同的社会属性度量和效用值。为了使计算的结果更加符合实际的网络环境,考虑假设β=1/3,然后利用不同节点对中心度,移动连通度和关联度的偏重程度来动态确定α和γ。具体计算过程如下
α=AP(m,d)*(1-β)/AP(m,d)+(CE(m)+MC(m))
(2)
γ=(CE(m)+MC(m))*(1-β)/AP(m,d)+ (CE(m)+MC(m))
(3)
2 URM路由算法
在WMNs网络中,根据节点之间的历史交互信息,实时收集节点的移动情况并且更新节点本地的数据信息,结合节点自身缓存中的数据,从而计算各节点的效用值和时延值。URM路由算法包括3个部分:节点本地缓存的更新,节点的效用值、时延值的计算以及数据分组的转发。
第一个部分,节点本地缓存的更新。节点第一次通信,需要向所有邻居节点广播Hello数据包,在有效的TTL时间内,如果收到邻居节点的Response包,那么说明该邻居节点是有效的;同时在Response包中,包括邻居节点的私有信息,当前节点就将邻居节点的信息添加到自己的本地缓存中;若不是第一次通信,则当邻居节点位置发生改变时,当前节点需要更新邻居节点的位置信息。在下次转发数据时,直接查找当前节点的本地缓存,减少不必要的时延开销。因此在当前节点收到的数据包中,邻居节点私有信息的获取,将成为当前节点进行第一次的通信最主要的依据。
第二个部分,节点的效用值、时延值的计算。在数据包的转发过程中,主要包括两个部分,一是备选队列的选择,一是下一跳转发节点的选择。本文主要考虑3个方面:节点转发数据的时延值,效用值以及跳数的计算。其中,时延值的计算包括节点在等待通信链路处于空闲状态的时间,链路处于拥挤状态的时间以及节点在进行通信时的预热时间。在本地缓存中,节点会记录当前节点与其它节点之间的跳数,如果两个消息的跳数都小于或者大于阈值,则选择跳数较小的节点作为转发节点;若其中一个的跳数小于阈值,另一个的跳数大于阈值,则选择跳数小于阈值的节点。
如算法1所示,在计算节点之间的效用值时,由于在不同时刻下节点的位置和通信情况不同,所以节点参数的取值是一个动态变量。利用本地缓存中的数据,动态计算参数的值,使之更符合实际情况。
算法1:UtilityComputing Algorithm
//计算节点m与邻居节点d之间的效用值
(1)if 节点之间首次通信,节点m没有与节点d的历史交互信息
(2)//计算节点的中心度
(3)节点m利用其所在的簇块中与其它节点的联通程度计算节点的中心度CE(m)
(4)在周期时间T内,节点获取当前簇块内的历史信息
(5)if 没有与节点d相关的数据交互信息 then
(6){
(7) AP(m,>d)←0
(8) Sim(m,>d)←0
(9) MC(m,>d)←0
(10)}
(11)else 节点m有与节点d的历史数据交互信息
(12){
(13) //(1)计算节点m和d之间的关联度[10]
(14) 获取节点m与节点d最近一次建立连接的时间,计算节点m和节点d的关联度AP(m,>d)
(15) AP(m,>d)←FP(m,>d)+CP(m,>d)+RP(m,>d)
(16) //(2)计算节点m与d的移动连通度
(17) 获取本地缓存中该周期时间T内,邻居节点表的数据,计算节点m与节点d的移动连通度MC(m)
(18) //(3)计算节点m与d的相似度
(19) 获取本地缓存中节点m与节点d的公有邻居节点集,得出公有邻居节点数,计算节点m与节点d的相似度Sim(m,>d)
(20) //(4)计算节点的效用值U(m,>d)
(21) if 节点m与节点d之间是第一次通信
(22) {
(23) U(m,>d)←CE(m)
(24) }
(25) else
(26) {
(27) 令β=1/3
(28) 利用上述计算的节点的关联度,中心度和移动连通度,计算α和γ
(29)α←AP(m,d)*(1-β)/AP(m,d)+(CE(m)+MC(m))
(30)γ←(CE(m)+MC(m))*(1-β)/AP(m,d)+(CE(m)+MC(m))
(31) U(m,d)←αAP(m,d)+βSim(m,d)+γ(CE(m,d)+MC(m,d))
(32) end if
(33) }
(34) end if
(35) }
第三个部分,数据分组的转发。首先利用节点之间的跳数和效用值来选择备选队列,再利用节点数据转发的时延值、效用值和跳数选择下一跳转发节点。具体如算法2所示:
算法2:DataForwarding Algorithm
(1)获取节点本地缓存的数据,包括节点在等待通信链路的时间,链路处于拥挤状态的时间和节点间通信之前的预热时间。
(2)计算节点总的时延值
总的时延值=等待通信链路的时间+链路处于拥挤状态的时间+节点通信之前的预热时间
(3)按照节点的跳数和效用值对邻居节点进行排序
(4)比较节点的时延值、效用值和跳数的大小。
(5)在当前的邻居节点的队列中,综合3个因素,选择最优的节点作为下一跳转发节点。
3 仿真实验与分析
3.1 仿真环境的建立
本文使用ONE仿真(opportunistic network environment simulator)[18]模拟系统作为本次模拟的实验平台。ONE是芬兰赫尔辛基大学用Java编写的开源软件,是一个机会网络环境模拟器,现在最多的将其应用于时延容忍网络模拟网络的真实工作情况。
基于以上的实验环境,做出平台中的某些参数的假设,见表1。

表1 实验平台的参数设置
3.2 实验参数
对于实验中所用到的对比参数:节点的平均占用率、节点之间转发数据的平均跳数、端到端的平均时延、节点预测数据包传递的可能性以及数据分组收发的成功率,进行如下的说明:
(1)平均缓存占用率(average node cache utilization):节点所利用的缓存大小与总的缓存空间之间的平均比值;
(2)数据转发的平均跳数(average hot count):节点之间保持数据交互的平均跳数,跳数越少,说明当前节点所对应的邻居节点作为下一跳的几率更大,并且所花的时间越少;
(3)端到端的平均时延[10](average end-to-end delay):节点之间通信的平均时间;
(4)数据包转发的平均可能性(average probability of packet forwarding):预测节点作为下一跳转发节点传输数据的可能性;
(5)数据包收发的平均成功率(the transceiver success rate of data packets):发送的数据包的数量和接收到的数据包数量的比例。
3.3 仿真实验结果分析
3.3.1 不同路由协议的对比
本文选择随机路径移动模型(random waypoint movement modal,RWP)作为节点的移动方式,并进行对比分析:
(1)平均缓存占用率
由图5可知,随着仿真时间的增加,5种协议的节点缓存占用率都在不断增加。比较而言,URD和URM协议的缓存占用率相对较低,并且URM的节点缓存占用率的增加相对趋于平稳。Epidemic和Spray-And-Wait协议相对较高,前者以洪泛的方式,只要有机会,就将数据转发给邻居节点,因此产生太多消息副本,占用了较大的存储空间;而后者则是折半将数据发送给邻居节点,缓存占用率相比Epidemic较低。Prophet、URD和URM协议都是利用了节点之间数据交互的历史信息,缓存占用率相对较低。Prophet协议是以计算节点投递数据的概率,选择概率较高的节点发送数据;URD协议是计算节点的效用值,选择效用值较大的节点发送数据;而URM协议综合节点的效用值、时延和跳数,选择最优的节点转发数据,从而URM的缓存占用率最小。此外,在RWP移动模式下,节点随机移动,每隔一定的时间,节点更新本地缓存中邻居节点的信息,包括节点的效用值、时延值和跳数等,因此URM的节点缓存占用率增加趋于平稳。
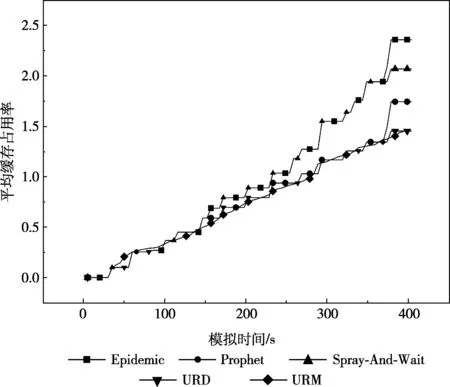
图5 5种协议的缓存占用率
(2)数据传输的平均跳数、转发的可能性、收发成功概率、端到端的平均时延
由图6表示数据传输的平均跳数、转发的可能性、收发成功概率、端到端的平均时延可知,对于平均跳数,URM和URD协议相比于其它协议较少,并且两者相近。Epidemic采用洪泛机制,将数据转发给所有节点,当一个节点获得数据,依次转发给下一个节点,因此跳数最高。而URM和URD协议的收敛性主要是基于邻居节点的效用值,通过移动连通度和相似度可知网络的联通性能和节点之间合作性能的高低,从而在不受到局部性影响的RWP移动模型下,节点之间的跳数相对较低。Prophet和Spray-And-Wait协议居于中间。

图6 平均跳数、转发的可能性、成功概率、平均时延
对于数据传输的可能性和成功概率,由于节点随机选择移动方向、速度和目的地,导致节点相遇概率低,消息的传输总数较少,并且使得大多数消息在TTL生存时间内未到达目的地而被丢弃,因此传输的可能性和成功概率较低。而URD和URM在转发数据包时,利用节点本地缓存的历史数据计算节点的效用值,有效地预测了节点间相遇的可能性,因此稍高于其它3种协议。而URM利用动态获取影响效用值的参数来计算效用值,更接近于真实的网络,所以稍高于URD协议。
对于数据传输的平均时延,由于场景中节点比较密集,并且在RWP移动模型下,节点相遇的概率较低,因此对于多拷贝方式的Prophet、Epidemic和Spray-And-Wait来说,每次传输数据时,都需要通过更多次数据的拷贝,增加了时延开销。而URD和URM协议基于历史信息来预测节点之间相遇的可能性,以及计算移动连通度和相似度时,更容易看出网络的联通性和节点之间的相互协作性能的高低,因此在一定程度上大大减少了时延开销。其中URM根据历史信息动态计算效用值,使结果更贴近于实际,所以较低于URD协议。
3.3.2 网络中节点的移动方式不同
本文利用4种不同的移动模型来进行模拟,分别是Random Walk(随机移动模型)、Shortest Path Map Based Movement(基于地图的最短路径移动模型)、Map Based Movement(基于地图的移动模型)、Car Movement(汽车移动模型)。为了更加说明算法的有效性,以下通过消息传输的平均时延和数据包收发的平均成功率来进行描述:
由图7表示不同移动模型下基于URM算法,数据包收发的平均成功率和平均时延值,图8表示不同移动模型下不同路由协议的平均时延值可知,基于不同的移动模型下,URM路由算法无论是在哪种移动模型下,与上述节点之间数据包收发的平均成功率的数据分析图相比,可以看出URM的数据包收发的平均成功率都是较大的。说明在不同的网络环境下,基于节点间通信的历史数据,动态计算效用值,在一定程度上减小了误差,URM协议对实际网络环境的适应性,相对于其它几种协议来说较好。基于不同的移动模型,对比于上述节点之间进行数据转发的平均时延值的数据分析图,可以看出URM路由算法的平均时延值较小。URM路由算法的时延主要是在节点之间进行数据转发的过程中消耗的,而由于选择同一节点作为下一跳转发节点的概率更大,因此消耗的时间减少。此外,由于不需要获取新的节点的数据信息,减少了获取信息的时延值。因此总体上相较于其它路由协议,URM路由算法的时延值最小。

图7 不同移动模型下基于URM算法,成功率和时延值
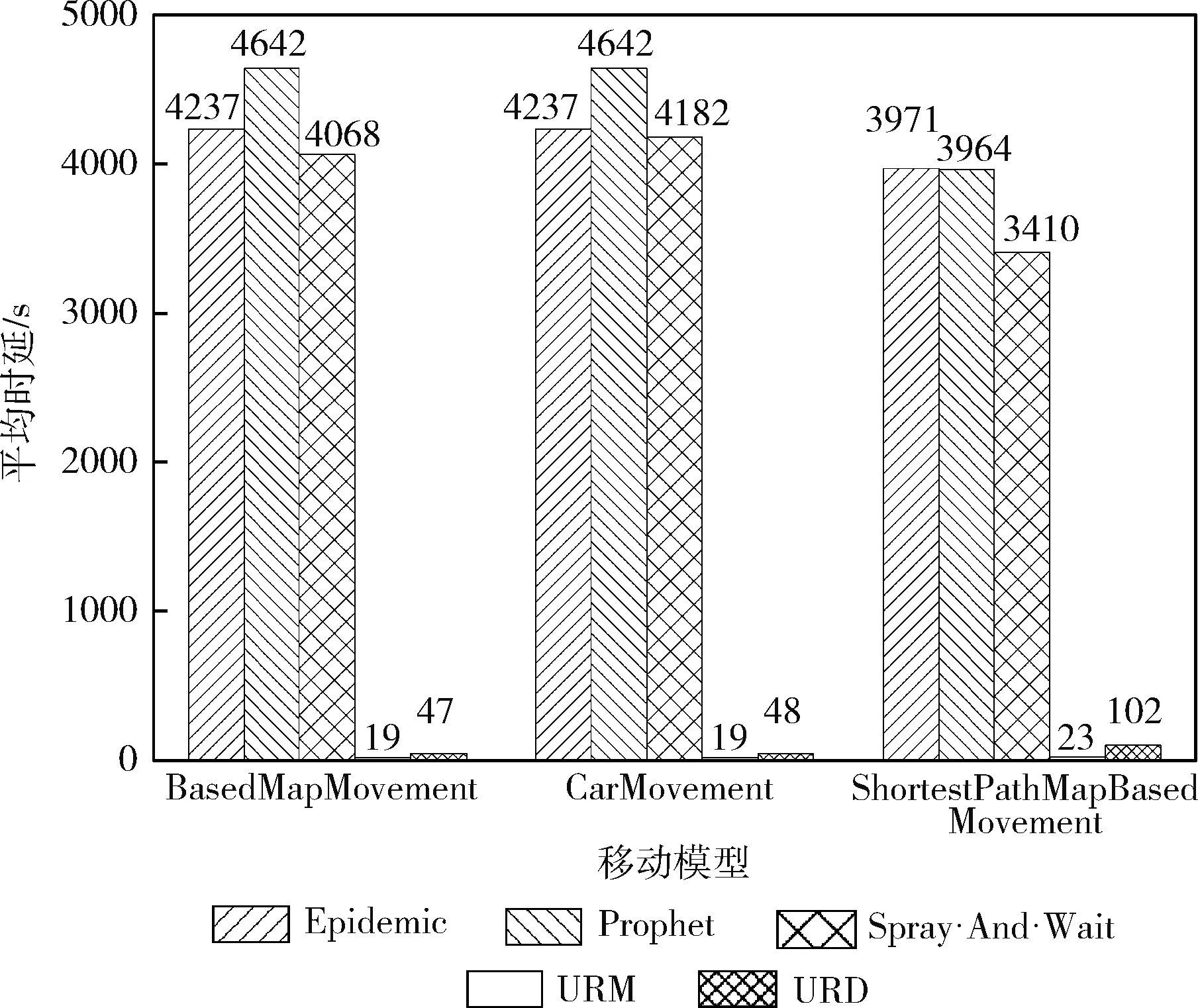
图8 不同移动模型下不同路由协议的平均时延值
4 结束语
为了解决无线Mesh网络由于节点的不断移动,存在网络拓扑结构动态变化、数据转发时延增加、网络资源浪费的问题,根据当前效用转发的路由算法较适用于理想状态的问题,提出基于效用转发的路由快速恢复算法,利用节点间的历史交互数据,动态获取在不同网络环境下,影响效用值的各因素所占权重值,从而使算法能更好适应真实的网络环境。同时综合网络时延,节点效用值和节点间跳数,选择最优的下一跳转发节点,减少网络中不必要的时延增加和资源浪费。ONE仿真结果表明,该算法能够判断网络稳定性能的高低,提高数据包的转发效率,减少网络恢复的时延开销,从而提升网络的性能。在未来的工作中,将考虑通过结合网络编码和机会路由选择更合适的转发节点,进一步优化该协议的性能。
