基于重要性的信任感知推荐方法
2021-08-23谭晏松宋铁成
谭晏松,宋铁成
(1.重庆电子工程职业学院 人工智能与大数据学院,重庆 401331; 2.重庆邮电大学 通信与信息工程学院,重庆 400065)
0 引 言
由于近几十年来互联网上的信息爆炸,推荐系统(recomme-ndation systems,RS)已经成为大多数电子商务和社交网络系统中的重要模块[1,2],成为解决日益增长的信息过载问题的有效方法。在各种推荐方法中,协同过滤(collaborative filtering,CF)是一种最成功的方法,它利用许多用户的反馈来寻找相似的用户和项目,作为推荐的基础。但该技术也存在一些固有缺陷,如数据稀疏、冷启动和推荐结果失真[3]。推荐系统的关键作用导致了该领域的大量研究,而如何克服传统推荐系统的不足也成为研究的关键。
为了解决传统推荐系统存在的冷启动和准确率低等问题,基于机器学习的推荐模型得到了广泛关注[4]。Zou等[5]提出一种社会推荐方法,使用自适应邻居选择来提高预测的准确性。Wu等[6]提出了一种融合潜在社交信任模型的协同过滤推荐算法,以提高推荐质量。Hai等[7]提出了一种基于时空感知的推荐方法。考虑到用户的社会关系,通过构建用户、地点、时间、活动和朋友的信息网络,获得推荐活动。Wei等[8]提出了一种将离散内容与兴趣贴近度相结合的算法,用以提高推荐质量与性能。Li等[9]提出了一种结合社会标签和信任关系的社会网络推荐方法。Wu等[10]提出一种将社会网络结构与用户项目交互行为的内在联系有机结合起来的社会推荐神经网络结构。
已有的信任感知推荐系统大多认为不同项目对用户具有相同的重要性,但是现实生活中并非如此。本文基于不同人口统计学背景下项目重要性不一致的概念,提出了一种基于重要性的信任感知推荐方法,该方法通过用户的人口统计上下文来衡量项目对用户的重要性,然后以项目重要性来评估委托人和受托人之间的信任级别,从而有效地适应用户偏好的动态变化。
1 混合蛙跳算法
混合蛙跳算法[11](shuffled frog leaping algorithm,SFLA)在2003年由Eusuff等提出,是一种新型仿生学的群体进化算法,属于启发式智能优化算法。在这种算法中,一组青蛙(或初始解决方案)协同感知最大的食物来源。通过同时使用局部和全局搜索,SFLA对各种优化问题都是有效的[12]。
混合蛙跳算法描述如下:首先随机初始化P只青蛙的种群,在D维搜索空间中,Xi=(Xi1,Xi2,…,XiD)表示第i个青蛙的位置。适应度函数用于评估每个个体的适应度。然后,按照青蛙的健康程度降序排列。种群中最好青蛙的位置用Xg表示。然后,将整个种群划分为m个模因丛,每个模因丛包含n只青蛙(即P=m×n)。为此,第((i-1)×m+j)个青蛙被分配给第j个模因丛(i,j=1,2,…,m)。然后,对于每一个模因,最差青蛙的位置通过进化过程得到改善。让Xw,j和Xb,j分别列出第j个模因丛中最差和最好青蛙的位置。在第j个模因进化过程中,最差的青蛙跳向位置Xb,j。第j个模因进化中最差的青蛙的跳跃步长计算如下
ΔXw,j=rand×(Xb,j-Xw,j)- ΔXmax≤ΔXw,j≤ΔXmax
(1)
式中:rand是(0.1)中的随机数,而ΔXmax是最大允许步长。因此,SFLA确定最差青蛙的新位置如下
Xw,j(new)=Xw,j+ΔXw,j
(2)
如果Xw,j(new)比Xw,j具有更好的适应值,那么当前位置将被新位置替换。另外,Xw,j是根据全局最佳青蛙的位置进行了改进。为此,用Xg代替Xb,j来重复式(1)和式(2)。如果仍然没有改进,SFLA用一个新的随机生成的解决方案替换最差的青蛙。进化过程在预定的迭代次数内继续。然后,执行洗牌过程以形成下一代的新种群。重复这些过程,直到满足终止条件。
2 基于重要性的信任感知推荐方法
传统的CF方法面临两个主要问题:稀疏性和冷启动。信任感知的RS通过使用用户之间信任网络中的其它信息来克服这些问题。基于信任的方法可以分为显式和隐式方法。在显式方法中,用户显式表达对其他用户的信任。显式方法的主要缺点是用户可能对提供显式信任语句不感兴趣,从而导致稀疏的信任网络。与显式方法相反,隐式方法从用户评级行为推断信任关系。因此,隐式方法比显式方法更实用。但是,已有的信任感知推荐方法均假定不同项目对用户具有相同的重要性,但是在现实生活中,项目的重要性对于个人用户来说并不尽然相同且是动态变化的,取决于性别、年龄、受教育程度等很多人口统计特征因素。例如,越流行的产品对年轻人群的重要性要大于年老人群。在本文中,提出了一种基于重要性的信任感知推荐方法,该方法在计算用户之间的信任时考虑了项目的重要性。针对用户的人口统计上下文定义了此方法中使用的重要性度量。因此,所提出的方法可以适应用户兴趣的动态变化。
图1给出了提出的基于重要性的信任感知推荐方法的框架。从图中可以看出,提出的方法包含在线和离线两个阶段,离线阶段主要用于用户的集群,在线主要用于推荐列表的生产。在离线阶段,混合蛙跳算法用于根据用户的人口统计特征对用户进行聚类。在线阶段包括5个步骤:首先识别与活动用户最相似的群集,以获得候选邻域集,即邻居预选步骤;其次,计算活动用户与每个候选邻居之间的基于重要性的信任值,即基于重要性的信任计算步骤;再次,选择最合适的候选者作为最终邻居,即邻居选择步骤;然后,根据所选邻居的偏好来预测活动用户的未知评分,即评分预测步骤;最后,将前n个项目推荐给活动用户,即推荐列表生成步骤。下面给出每个阶段的详细描述。

图1 提出方法的框架
2.1 离线阶段

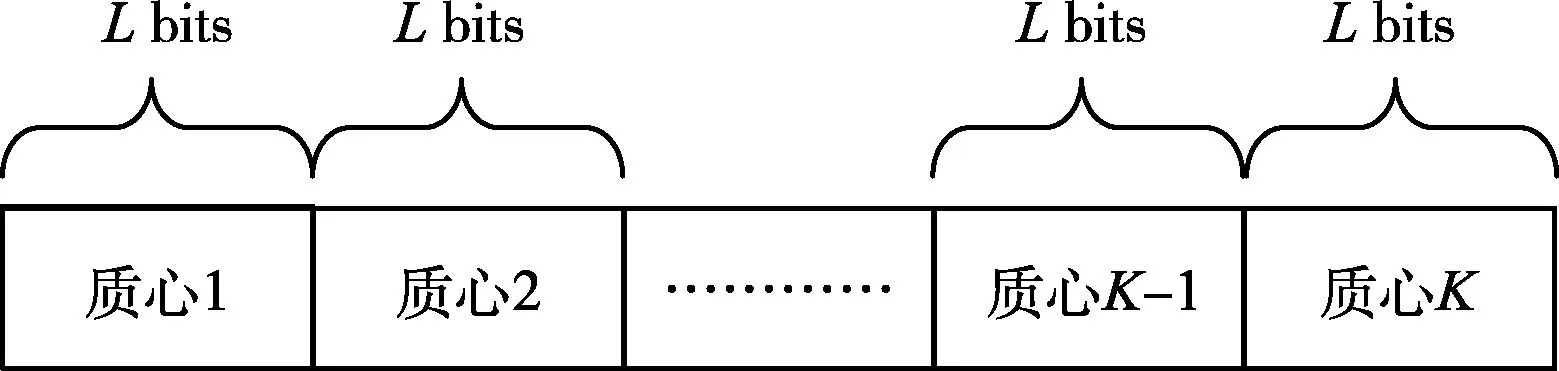
图2 青蛙的结构
对于每个解决方案,计算用户和每个集群中心之间的人口统计相似性,以将用户分配到最近的集群。用户u与质心Zk之间的相似度计算为其对应特征向量的余弦相似度
(3)
式中:DSimi(u,Zk)∈[0,1]是解Xi中u与第k个集群中心的人口统计学相似性。
下一步的目标是使用适应度函数评估每个解决方案,利用SFLA算法从中选择适应度最高的值作为最优解。集群解的适应度基于集群内距离之和确定,如式(4)所示
(4)
式中:Fitness(Xi)是青蛙Xi的适应度。显然,当集群内距离之和较小时,解的质量较高。
在模因进化过程中,每个模因丛中最坏的青蛙的位置是基于局部最优或全局最优青蛙的位置或基于随机位置进行改进的。Xw,j是第j个模因丛中最差青蛙的位置。根据跳跃的步长(i.e.,ΔXw,j),确定最差青蛙(i.e.,ΔXw,j(new))的新位置。由于位置向量的二元表示,将Xw,j(new)离散为二元向量,为此,使用改进的离散SFLA。在这个改进的算法中,用下列公式代替式(2)计算Xw,j(new)的第dbit
t=1/(1+exp(-ΔXwd,j))
(5)
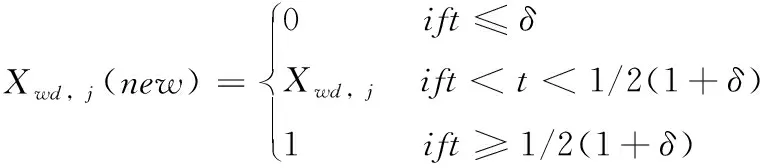
式中:下标d∈{1,2,…,K×L}表示对应向量的第d位,δ称为静态概率。当达到预定义的迭代次数时,满足停止条件。
2.2 在线阶段
提出算法的在线阶段主要目标是生成推荐意见,此阶段可以分为邻居预选、信任计算、邻居选择、评级预测和推荐列表生成5步。
2.2.1 邻居预选
在第一步中,识别与活动用户最相似的集群。这些集群的所有成员都被选为活动用户的候选邻居。设CNau为活动用户au的候选邻居。对CNau的定义如下
CNau={u∈ck|ck∈C∧DSim(au,Zk)≥α}
(6)
式中:α是相似度阈值。如果α小,则人口统计学相似性相对较低的那些用户也被视为候选邻居;当α大时,候选邻居的数量不足以识别可信赖的邻居。
2.2.2 基于重要性的信任计算
根据活动用户对候选邻居的共同评价项以及这些项对活动用户的重要性来计算活动用户对候选邻居的隐式信任。为了实现这一目标,定义了一个新的显著性度量,它基于人口统计学背景下的项目评级。然后,提出了一种新的信任度量方法,该方法考虑了项目的重要性。
首先是显著性计算,通过计算项目i的平均评级和评级的用户的百分比两个测量指标来计算项目i的重要性。假定si表示项目i的显著性,其最小值为0(非显著)和最大值为1(非常显著)。为了确保si介于0和1之间,额定值标准化为[0,>1]。使用最小-最大标准化方法,将原始评级r转换为标准化评级r′∈[0,1],如下所示
(7)
式中:最小值是最小额定值,最大值是系统中的最大额定值。
设ru,i为从用户u到项目i的标准化评级,设Ui={u∈U|ru,i≠·}为项目i评级的用户集,符号ru,i=·表示u没有对项目i进行评级,项目的重要性评价计算如下
(8)
式中:#表示集合的基数。
对于具有不同人口学特征的不同用户,项目的重要性是不同的。此外,用户的个人偏好可能在整个生命周期(从童年到老年)中发生变化。因此,当前对用户重要的项在将来可能变得不那么重要。为了处理这一事实,在测量项目对u的重要性时考虑了用户u的人口统计学背景。为此,将式(8)修改如下
(9)
式中:si,k∈[0,1]是集群ck用户i项的重要性,Uk是集群ck用户的集合,Ui,k={u∈ck|ru,i≠·}是集群ck用户中对i项评级的集合。
其次是对信任进行计算。本文采用的信任度量包含了项目的重要性。从用户u到用户v,STrustu→v∈[0,1]的基于显著性的信任定义如下
(10)

(11)


(12)
根据式(12),直接信任值由相应用户之间的共同评级项目数加权。这种传播方法的基本原理是,直接信任关系的可靠性随着共同评级项目的数量而增加。因此,如果两个用户有更多的共同评价项,那么在传播过程中,他们之间的关系权重会更大。信任网络中任意两个用户之间的间接信任可以通过等式(12)的重复应用来计算。如果网络中两个用户之间存在多个路径,则计算从可选路径推断的所有信任值的算术平均值。
2.2.3 邻居选择
从候选集中选择活动用户最可信的邻居。为此,选择信任值大于或等于指定阈值的候选对象作为邻居。让FNau表示活动用户au的最后邻居集。FNau定义如下
FNau={u∈CNau|STrustau→u≥θ}
(13)
式中:θ是信任阈值。
2.2.4 评分预测
选择的邻居用于预测活动用户的偏好。目标项的活动用户的未知分级估计如下
(14)
式中:pau,i是活动用户au对目标项目i∈I1Iu的预测评级。
2.2.5 生成推荐列表
最后,使用预测的评级为活动用户生成top-n推荐列表。目标项目根据其预测评级进行排名。然后,系统会推荐级别最高的项目。
3 实验结果与分析
3.1 数据集
实验数据集采用MovieLens 1M1(ML)和Book-Crossing(BX2)两个不同领域的公开来源真实数据集,ML和BX均包含用户的人口统计信息。
ML数据集由6040个用户为3952部电影提供的1 000 209个评级组成。评级从1分(差)到5分(优)。其稀疏度为95.809%。除了评级数据外,ML还提供了一些用户的人口统计信息,包括年龄、性别和职业。性别是“M”(男性)或“F”(女性)。在这个数据集中,有21种不同的职业,如工程师、艺术家、医生等。
BX数据集包含1 149 780个评级,来自271 379本书的278 858个用户。有433 681个明确的评级,等级为1到10,716 109个隐含评级(值为0)。在这个数据集中,人口信息包括年龄和地点(国家)。删除没有评级的用户和项目,数据集包含407 332个明确的评级,来自178 647本书的74 085个用户(99.996%稀疏度)。
对于这两个数据集,将用户的人口统计特征表示为二进制特征向量,其中1和0分别表示特征的存在和不存在。用户人口统计学向量的结构见表1。
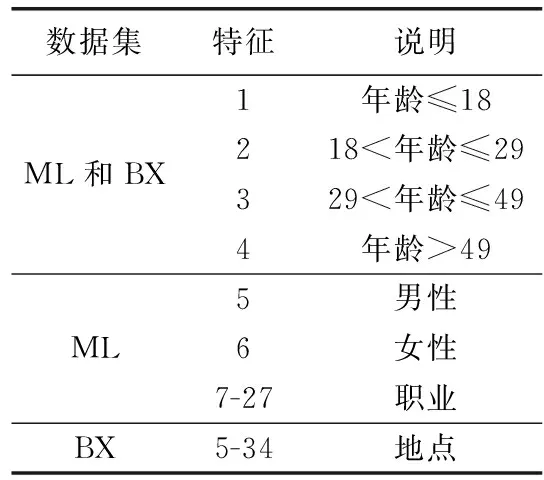
表1 数据集基本参数
根据表1,年龄、性别、职业和地点被定义为分类属性。有4个年龄类别,2个性别类别,21个职业类别和30个地点类别。如果用户属于某个类别,则相应的比特设置为1;否则为0。因此,对于每个分类属性,只有一个位是1,其余的是0。对于ML数据集,人口统计学向量的长度为27,而对于另一个数据集,长度为34。在这两种情况下,向量的前四位表示年龄类别。对于ML,第5和第6位表示用户的性别,其余的位对应于职业类别。对于BX,用户的位置由位5-34指定(表1)。
3.2 实验设置
在这项研究中,所有的实验都使用5倍交叉验证。评级数据被随机分成5个大小相等的子集。在每次评估运行中,一个子集用作测试数据,而另一个子集用作训练数据。以5次平均成绩作为总成绩。从两个不同的角度进行实验:①所有用户,其中对所有用户及其评级进行评估;以及②冷用户,主要关注评级低于10的用户。
选用配置为Intel Corei5 @2.53 GHz和4 GB RAM的机器测试,调整每种方法的参数以获得尽可能好的结果。对于所提出的方法,对SFLA进行微调以获得最佳结果。SFLA的参数值见表2。

表2 SFLA参数设置
3.3 评价指标
为了评估推荐算法的性能,在实验中预测精度是由均值绝对误差(mean absolute error,MAE)来评估的,均值绝对误差衡量的是预测值和实际值之间的误差,其值越小说明算法性能越好。让T表示要估计的额定值集(即测试集)。MAE定义如下
(15)
预测的质量根据覆盖率进行评估。评级覆盖率(rating coverage,RC)是指系统可以预测的测试评级百分比,其值越大说明算法预测质量越好
(16)
式中:pu,i≠·表示用户u对项目i的评级是可预测的。
3.4 实验结果与分析
在第一个实验中,验证算法在离线、在线阶段对参数的敏感性。图3给出了离线阶段集群K数量对算法的影响。从图中可以看出,随着K的增加,所提算法的MAE先下降后上升,ML和BX数据集分别在K=14和17时取得最优。

图3 集群K对算法的影响
图4给出了在线阶段相似度阈值α对算法的影响。从图中可以看出,RC随着α的增大而减小,并且较低的α值会导致较高覆盖率和较低的准确性。对于两个数据集,α分别取0.6和0.5时,可以获得最佳的MAE。
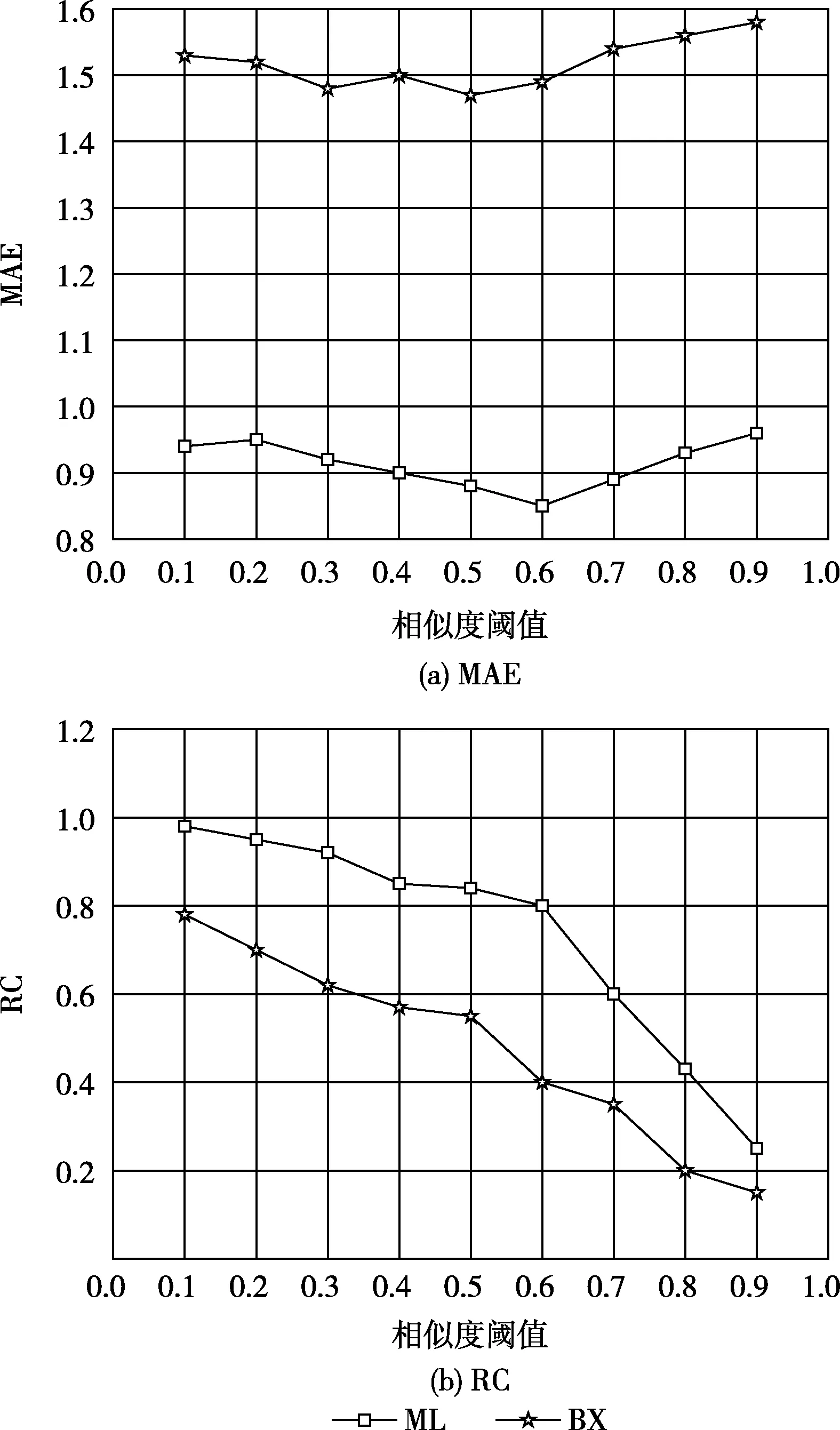
图4 相似度阈值α对算法的影响
在第二个实验中,将提出的方法的整体性能与SRANS[5]、
DTTN[13]、TCFACO[14]这3种流行算法进行了比较。所有用户(包括冷启动和非冷启动用户)都参与了这个实验。两个数据集的MAE和RC结果见表3。

表3 ML和BX数据集的所有用户视图的MAE和RC结果
如表3所示,提出的方法在两个数据集中的MAE最低。这验证了基于重要性的信任度量在提高信任感知推荐系统性能方面的能力。此外,基于重要性的信任感知推荐方法具有比其它方法更高的RC。由于人口统计信息的利用,即使没有评级数据,它也能为用户找到足够的邻居。
第三个实验,评估了提出的方法在缓解冷启动问题方面的有效性。评级低于10项的用户被视为冷启动用户,设N为测试用户观察到的评级数。通过改变评级的数量来评估预测和建议的质量。对于每个测试用户,保留N个培训等级,其余的则丢弃。实验进行了N等于2,4,6和8的实验。结果如图5-图10所示。
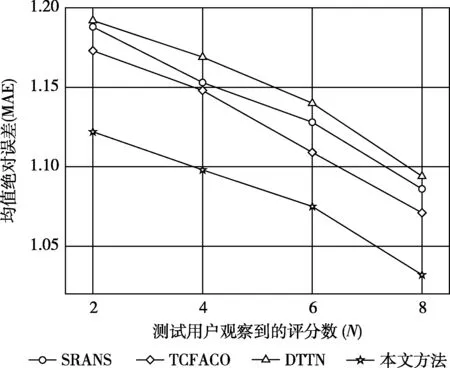
图5 不同算法在ML数据集冷用户视图的MAE结果
图5-图6分别给出了4种不同方法在ML数据集的预测精度和质量结果,从图5中可以看出,所提出的方法比其它3种方法的MAE值要低,当评级数N越高时MAE值越低;图6展示了它们在ML数据集冷用户视图的RC结果对比,同样从图中可以看出,所提出的方法的RC值均高于其它3种方法,当评级数N越高时RC值也越高。图7-图8则给出了4种方法在BX数据集的表现,结果与在ML数据集的表现相似。基于重要性的信任感知推荐方法,在预测精度和预测质量上均优于对比的方法。结果表明,将人口统计信息纳入基于重要性的信任感知推荐方法有助于解决冷启动问题。

图6 不同算法在ML数据集冷用户视图的RC结果比较
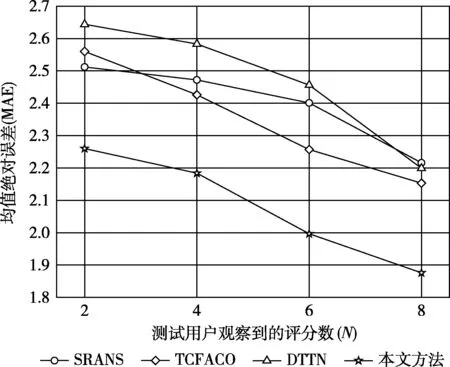
图7 不同算法在BX数据集冷用户视图的MAE结果

图8 不同算法在BX数据集冷用户视图的RC结果比较
图9给出了不同推荐方法在ML和BX数据集上的执行时间对比结果。从图中可以看出,在所有方法中,提出方法的执行时间最短。由于采用了两层邻居选择策略,DTTN的执行时间较长。SRANS比DTTN慢是因为SRANS需要复杂的过程来识别初始邻居集合并以自适应方式对其进行优化。TCFACO具有最长的执行时间,因为它同时使用信任和相似性信息来构造用户映射,然后在该映射上应用ACO搜索策略来查找用户的最佳邻居。
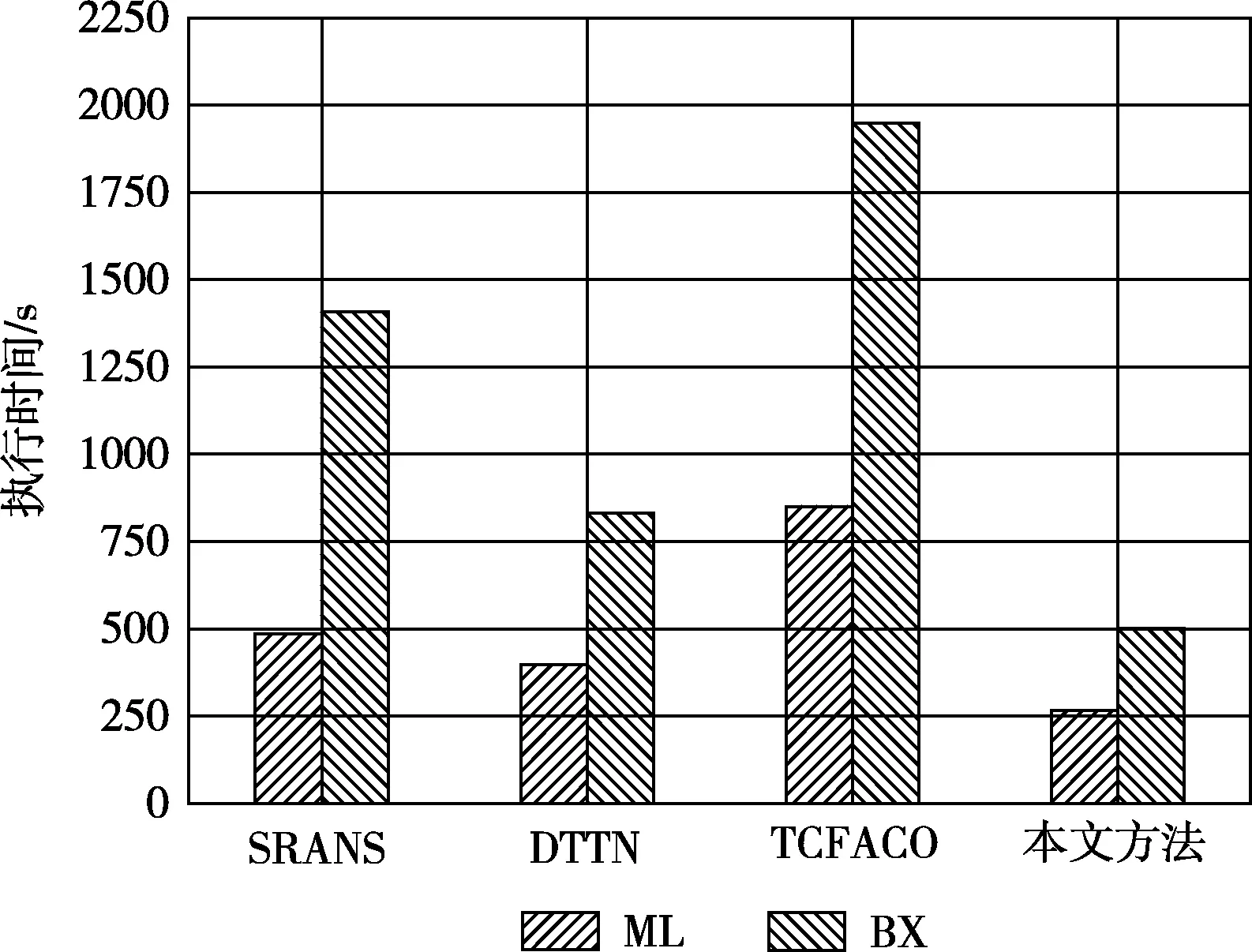
图9 不同算法的执行时间对比结果
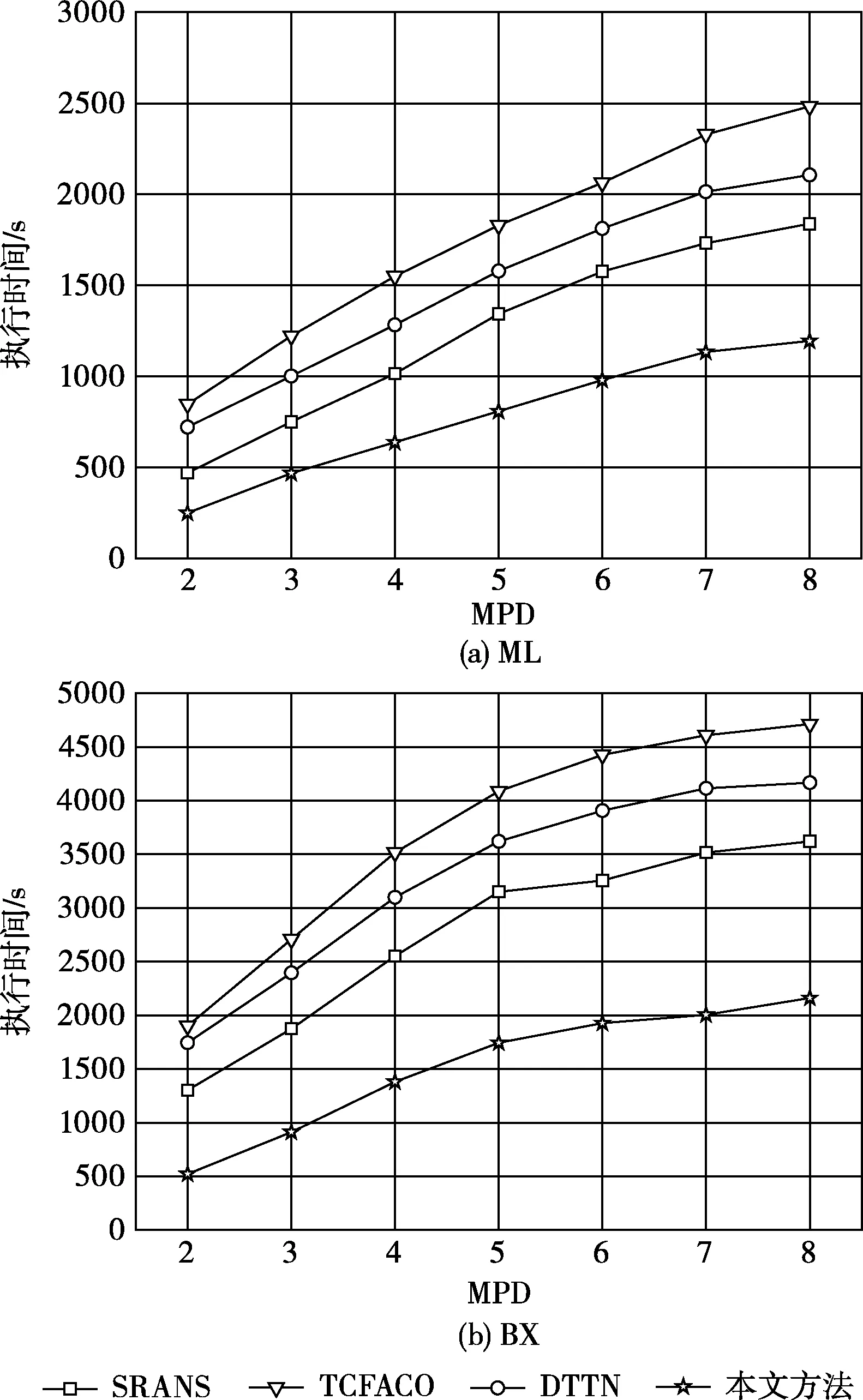
图10 不同传播距离下的执行时间
为了更好地理解所提推荐方法的效率,图10比较了不同方法对MPD的不同值的执行时间。MPD是决定信任者与被信任者之间最大距离的参数。基于该参数,重复使用信任传播式(12)来计算用户u与其他用户之间的信任。从图中可以看出,随着传播距离的增加,其它方法的效率急剧下降,所提方法的在不同传播距离下执行时间最短,该方法优势随着距离的增加而变得更加明显。
4 结束语
本文针对传统推荐系统存在的局限,提出了一种基于重要性的信任感知推荐方法,该方法的研究重点是一种基于项目重要性的信任度量。本文方法分为两个关键阶段,在离线阶段,项目采用混合蛙跳算法(SFLA),对用户的重要性是根据用户的人口统计特征来衡量的,以此可以实现用户偏好的动态变化。在线阶段根据活动用户的信任邻居的偏好为其生成top-n推荐列表。实验结果表明,通过与几种最新推荐方法的比较,在预测精度和预测质量上,提出的方法优于其它方法。
