基于Train2Vec的消防培训数据分类
2021-08-23杨立红贾可佳
董 慧,程 岗,杨立红,孟 笛,贾可佳,陈 超+
(1.华北科技学院 安全工程学院,河北 三河 065201; 2.中国航天科工集团第二研究院七〇六所,北京 100854)
0 引 言
随着科技的进步与发展,虚拟现实(virtual reality,VR)、增强现实(augmented reality,AR)以及混合现实(mixed reality,MR)技术得到飞快发展,应用的领域也逐步扩大。如Meihui等通过搭建虚拟人物和虚拟破损机械设备实现模拟真实世界维修员维修机械设备的过程,不仅提高维修效率,还有效预防维修员受到伤害[1];Baiqiang等、Kurilovas等让用户在VR学习环境和AR学习环境下学习,分析用户在不同环境下的学习效率[2,3],以上都是通过搭建虚拟模型、分析模拟产生的过程数据得到预期结果,在众多的数据处理模型中,Word2vec模型是一种用于处理文本类数据的优秀模型,它是将自然语言中词语用向量表示出来的模型[4]。该模型已有多方面研究,例如周萌利用Word2Vec对商品评论数据进行分类处理,分析出该商品的优缺点以及客服的服务态度等问题[5];牛雪莹等基于Word2Vec对微博文本进行分类处理的研究[6];金贵涛等利用Word2Vec识别“隐私,泄露,安全”等敏感词汇,并划分安全等级,为防护数据安全提供有力的支撑[7];段琦利用Word2Vec训练出餐厅向量以及用户向量,实现向用户推荐感兴趣餐厅的研究[8]。
目前Word2Vec模型很少用于处理非文本类数据,因此本文将MR与Word2Vec模型结合,衍生出一种模型——Train2Vec,它是将混合现实消防培训的过程数据构建成培训向量的模型,通过计算现场培训向量与典型样本培训向量之间的相似度实现受训人员身份的预测,并为其生成个性化的应对火灾建议和消防培训任务。
1 系统介绍
Train2Vec模型所分析处理的消防培训数据来源于混合现实消防培训系统,该系统实现了虚拟火灾场景构建、火情演化、虚实灭火器的状态同步、培训过程数据与受训人员生理数据采集等功能,其架构如图1所示。

图1 混合现实消防培训系统架构
该系统由硬件层、仿真层和软件层3部分组成。硬件层通过在真实灭火器上安装霍尔传感器、光栅传感器以及位置跟踪芯片实现数据采集和空间定位,通过WIFI/蓝牙模块实现与计算主机的数据传输。改装后的灭火器如图2所示。

图2 改装的灭火器
仿真层使用Unity3 d平台搭建虚拟火灾场景和与实体灭火器等比例的虚拟灭火器[9],图3为客厅虚拟火灾场景。为模拟不同的火灾现场,系统实现了火情演化的控制,即着火点的位置、火焰的蔓延方向和速度等都可以在系统中定制。

图3 客厅虚拟火灾场景
在仿真层中还使用Lighthouse的空间定位信息实现虚拟灭火器与实体灭火器的位置精确匹配,培训时虚拟灭火器与真实灭火器的状态、位姿等完全同步变化,例如,受训人员按压真实灭火器把手后虚拟灭火器做出同步变化并喷出虚拟灭火剂,所喷出虚拟灭火剂的剂量完全由受训人员按压把手的程度控制,图4为虚拟灭火器喷出灭火剂。

图4 虚拟场景中灭火器喷出灭火剂
软件层是将受训人员在培训时所佩戴智能手环采集到的心率等生理数据以及与虚拟场景交互产生的培训过程数据进行Train2Vec建模,从而得到该人员的培训向量,通过计算现场培训向量与典型样本培训向量之间的相似度实现受训人员身份的预测,并为其生成个性化的应对火灾建议和消防培训任务。
2 Train2Vec模型介绍
Train2Vec是将处理后的培训数据转换为多维培训向量的模型,一条培训数据对应一个培训向量。本模型的设计原理是受训员在培训过程中产生的多条培训数据之间具有一定的关联性,因此可利用Train2Vec求得培训向量,依据求解相似度推测出受训人员身份。
Train2Vec有两种训练模型,即Train2Vec-CBOW模型和Train2Vec-Skip-gram模型[4]。Train2Vec-CBOW是依据前后出现的培训数据t(h-c)、…、t(h-1)、t(h+1)、…、t(h+c)预测当前培训数据t(h)出现的概率,其中c为窗口大小;Train2Vec-Skip-gram模型是依据当前培训数据t(h)预测前后出现的培训数据t(h-c)、…、t(h-1)、t(h+1)、…、t(h+c)。两种模型的简单结构如图5、图6所示。
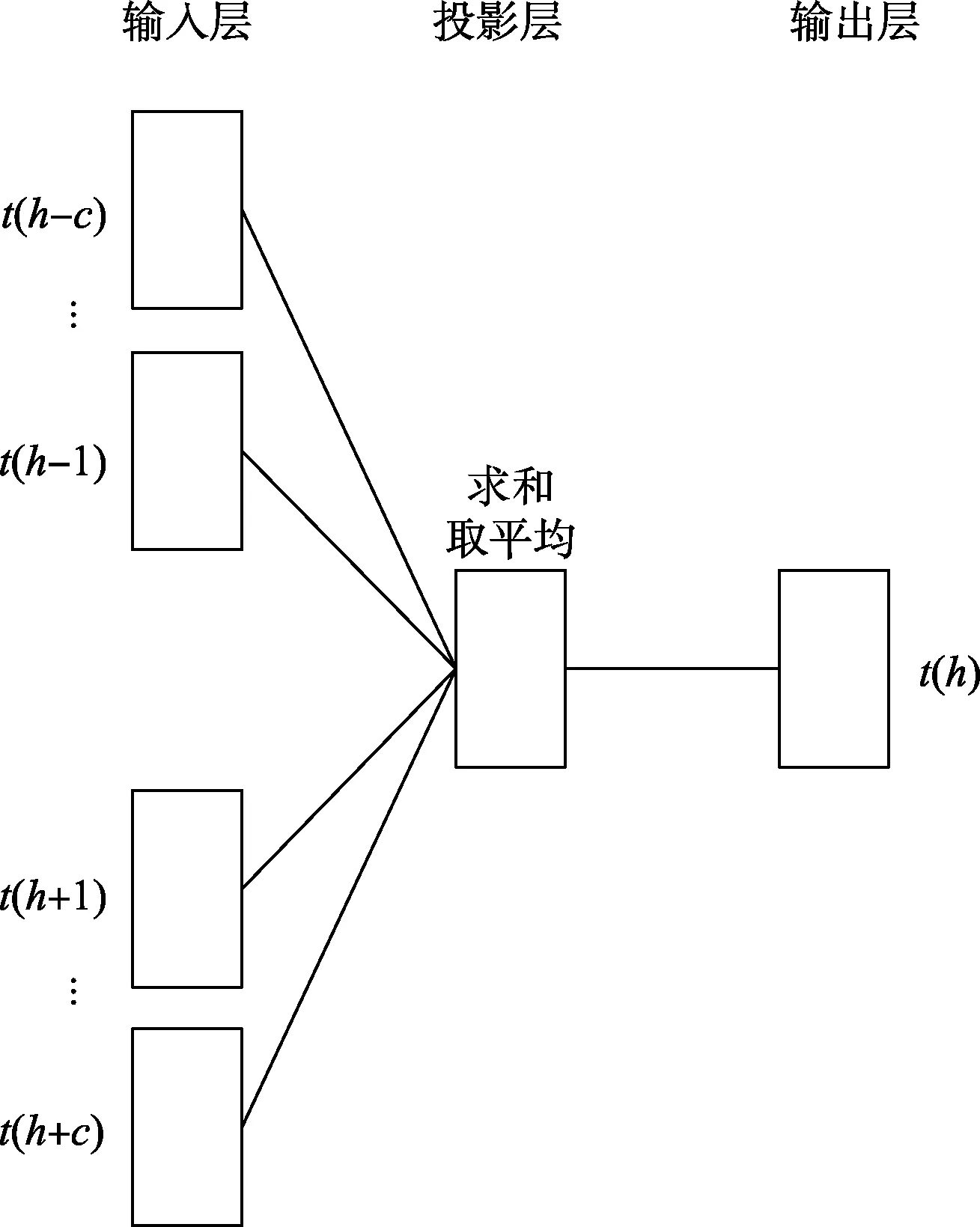
图5 Train2Vec-CBOW模型
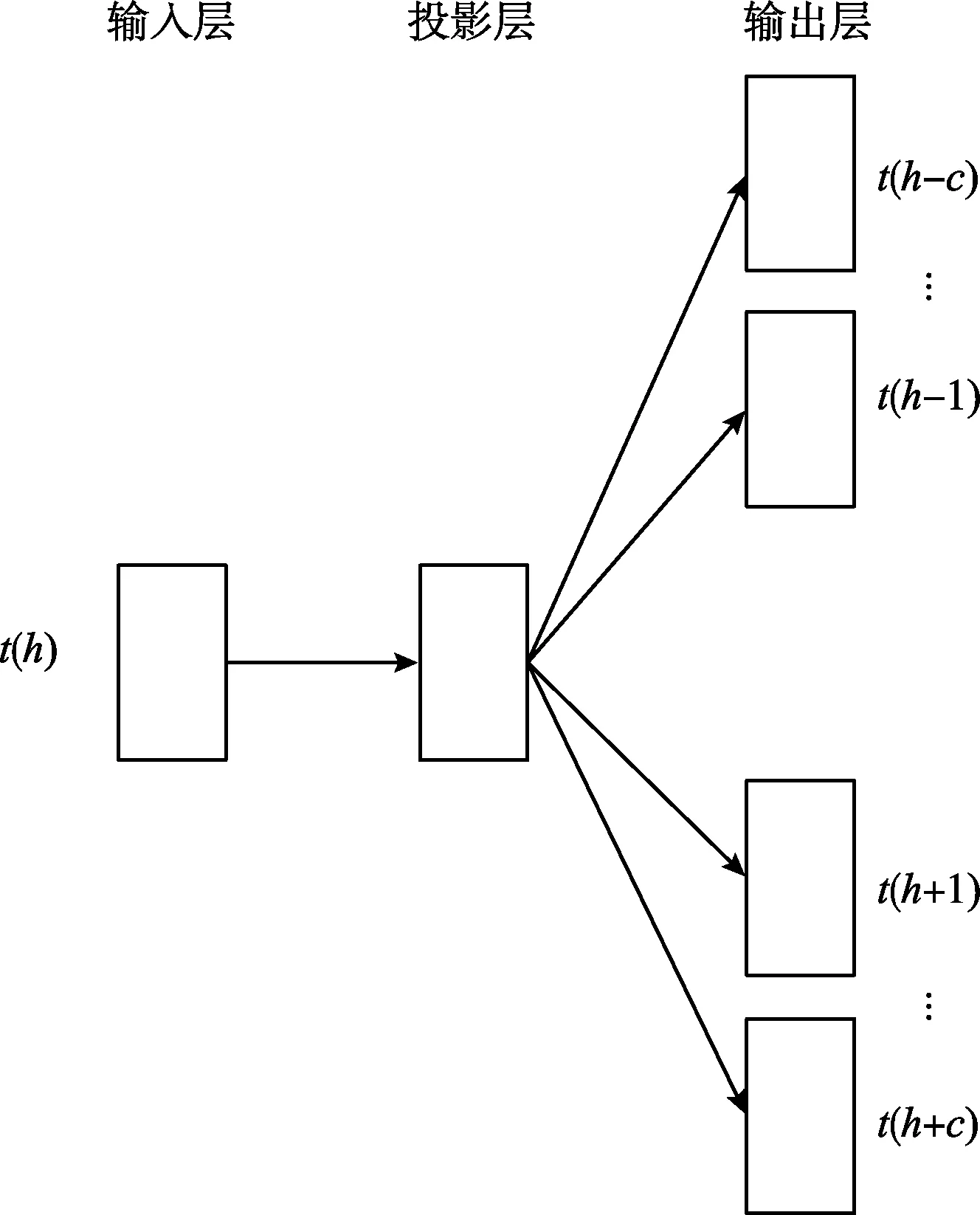
图6 Train2Vec-Skip-gram模型
其中,Train2Vec-CBOW模型的运算过程为:


输入矩阵与自定义的5×N维(N可任意取)的输入权重矩阵T相乘得到4个1×N维的向量
将得到的4个向量求和取平均,作为投影层的隐藏向量p
在给输出层传递数据前,先将隐藏向量p乘N×5维的初始化输出权重矩阵T′
最后将结果传输到输出层进行softmax计算,就可推测出第三条培训数据出现的概率分布
y=softmax([c1,c2,c3,c4,c5])=[d1,d2,d3,d4,d5]
O=logP(th|th-c,…,th-1,th+1,…,th+c)
Train2Vec-Skip-gram模型的运算过程为:
输入当前培训数据的one-hot编码,以上面的5条培训数据为例输入,将输入向量t1与自定义的输入权重矩阵T相乘得到隐藏层向量p
在给输出层传递数据前,将隐藏层向量p乘初始化输出权重矩阵T′
最后将结果传输到输出层做softmax计算得到该培训数据前后数据的概率分布
该模型的最大优化目标是
在模型建立过程中,为了使真正的培训数据出现的概率达到最大化,每次运算都会更新输入输出权重矩阵,如果培训数据量很大,模型的输入和输出权值矩阵的维度会随之变大,在输出层进行softmax计算的计算量也会变得非常大,加重了计算机的负担,为解决这个问题,提出了两种优化方式:
Train2Vec负采样[10]:对采集到的两条培训数据进行分析,如果二者不是一组前后培训数据关系,那么采集到的这一组数据就是负采样。该优化方式是通过在每次更新输出权重矩阵时减少更新负采样的方式达到优化目的。
Train2Vec层次softmax[10]:通过利用霍夫曼树降低输出层softmax计算复杂度达到优化目的。利用霍夫曼树还可将高频数据放在与根节点接近的位置,从而提高查找培训数据的效率。
3 基于Train2Vec模型的数据分类
为了验证Train2Vec模型的可行性,即是否能很好地计算两条,甚至多条培训数据之间的相似度,本文预采集了16名消防人员,23名应对火灾经验丰富人员和111名未经历过火灾人员的6173条带有身份标签的典型培训数据来搭建模型。
3.1 培训数据采集
消防培训过程中当实体灭火器的把手保持在按压状态时,系统认定受训人员正处于灭火状态,系统所采集的培训数据包括受训人员处于灭火状态时的心跳变化率、距最近火焰的距离、生命值等,采集频率为每5 s一次,这些数据的汇总见表1。

表1 实验数据说明
表1中灭火器上下移动幅度是受训人员按压灭火器把手的同时上下移动灭火器的幅度;生命值表征受训人员在灭火过程中当前时刻的健康程度,培训开始时初始生命值为100,在培训过程中如果受训人员处于距火焰2 m-3 m内,则每5 s生命值减少1,如果受训人员距火焰距离小于2 m,则每5 s生命值减少3,如果受训人员距火焰距离大于3 m,则每15 s生命值减少1。
数据进行分析前,需要先对数据进行分析处理,本文先采用Python对原始数据归纳处理,观察不同身份受训员产生的培训数据存在的特点。由于受训员在消防培训过程中产生的过程数据和生理数据都具有不稳定性,且都会随时间随意改变,因此为达到预期效果,本文选择每隔5 s采集一次数据信息。在对原始数据进行归纳处理后发现数据具有一定的规律性,例如在数据处理时发现未经历过火灾人员的培训数据出现双极化现象,经过进一步调查发现这种双极分化的现象与受训人员的心理素质有关,因此将未经历过火灾人员类型再次划分为两类,即未经历过火灾心理素质良好人员和未经历过火灾心理素质较差人员,图7为从受训人员从开始灭火到灭火结束期间所产生的培训数据取平均值的统计。

图7 各类培训数据平均值统计
从图7可见,不同身份人员在灭火时表现出的特征各有不同,见表2-表6。

表2 各类身份人员灭火时的平均心率范围

表3 各类身份人员在使用灭火器进行灭火时上下

表4 各类身份人员灭火后生命值范围

表5 各类身份人员灭火时距最近火焰距离范围

表6 各类身份人员灭火时长范围
出现上述现象是因为,专业消防人员经历过专门培训,具备较高的专业水平,因此在消防培训过程中,很少会出现心率偏高的情况,同时消防人员清楚怎样操控灭火器能高效率控制火势、短时间完成灭火任务,而且这类人操控灭火器时上下移动主要通过改变灭火器喷口的角度来扑灭不同位置的火焰,因此幅度较小,距最近火焰距离也保持在灭火最有效的安全距离;未经历过火灾心理素质良好和心理素质较差人员在培训过程中心率普遍较高,同时在操控灭火器时上下移动的幅度较大,过多地浪费了体力,这与该类人员未经历过火灾事故、未参与过消防培训任务有关,第一次身临其境遭遇火灾场景时会出现过分紧张、不清楚火焰作用的危险范围、不会合理操纵灭火器等状况;而应对火灾经验丰富人员由于培训前经历过火灾事故,参加过消防任务,对消防作业流程有一定的经验,在培训过程中产生的心跳、动作幅度等数据基本维持在消防员和未经历过火灾人员之间。
另外,专业消防人员灭火后生命值不是最高、灭火时长不是最短的原因为,专业消防员为了完成消防救援任务、完全控制火势,可以在可控的程度内忍受高温与烟雾的侵袭,灭火时也会合理控制与火焰间的距离,循序渐进地扑灭火焰;而未经历过火灾的两类人员在培训时,一般会出现“不怕火”和“太怕火”两种趋势,“不怕火”的受训人员(心理素质良好人员)为了达到快速完成灭火任务的目的会冒风险接近火焰,虽然灭火时长更短,但会因距火焰距离太近导致生命值较低,甚至出现生命值为0的情况,“太怕火”的受训人员(心理素质较差人员)害怕火焰对自己造成伤害,因此距火焰距离很远,灭火时长最长,但生命值会保持在较高水平。
通过对培训数据的分析可知,未经历过火灾的两类人员在面对火灾时会产生完全不同的反应,因此准确地做出分类并有针对性地生成应对火灾建议和消防培训任务是非常必要的。
3.2 Train2Vec模型构建
本文采用装有Windows系统、Anaconda和PyCharm的PC机作为搭建Train2Vec模型的环境,语言环境选择Python,用Python的gensim包构建Train2Vec模型,训练模型采用skip-gram模型,优化方式选用负采样。
建模时,设置Train2Vec模型的窗口大小为10,向量维数为100。让150名预先知道身份的受训人员进行虚拟消防演练(其中消防员16名,应对火灾经验丰富人员23名,未经历过火灾心理素质良好人员55名,未经历过火灾心理素质较差人员56名,心理素质的评判根据心理测评量表提前完成),每隔5 s采集一次培训数据,共采集到6173条培训数据,对应生成6173个典型培训向量,用来构成Train2Vec模型词典。为更清楚地观察每条数据以及它们之间的分布情况,采用UMAP降维算法将每条培训数据对应的培训向量的维度由100维降到2维,实现数据可视化的目标,如图8所示。

图8 UMAP降维后的典型培训向量分布
从图8中可看出,点集分布密集的地方代表此处的相似典型培养向量多,两点距离越近代表其对应的典型培训向量相似度越高,产生这两条典型培训向量的用户身份类型应是一致的。
3.3 Train2Vec模型验证
Train2Vec模型构建完成后,首先通过手动输入的方式验证模型的准确性,图9为选用一条未经历过火灾心理素质良好人员的培训数据进行相似性解算,根据提示输入对应的心率、灭火器移动幅度等培训数据后,系统会自动找到最优结果。

图9 手动输入的方式验证模型的准确性
根据运算结果,发现与“未经历过火灾心理素质良好人员”的相似度高达0.99多,而与其它身份的相似度很低,与事实基本相符。为降低使用孤立的培训向量进行相似度求解所带来的偶然性偏差,系统在计算出受训人员全部培训向量的类型后,再分别算出4种类型培训向量占全部培训向量的百分比,最终将该受训人员归类为百分比最大的类型。如图10所示,某受训人员的培训时长为1 min 43 s,共产生培训向量21条,其中与“未经历过火灾心理素质良好人员”典型培训向量相似度最高的培训向量为19条,占全部培训向量的90.48%,与“消防员”典型培训向量相似度最高的培训向量为1条,占全部培训向量的4.76%,与“应对火灾经验丰富人员”典型培训向量相似度最高的培训向量为1条,占全部培训向量的4.76%,与“未经历过火灾心理素质较差人员”典型培训向量相似度最高的培训向量为0条,占全部培训向量的0.00%。根据匹配向量占全部培训向量的百分比的高低,系统给出该受训人员为“未经历过火灾心理素质良好人员”的结论,与事实相符。

图10 受训人员培训向量与4种类型典型培训 向量的相似情况统计
为验证本模型对受训人员身份信息进行预测的准确率,本文分别找来13名专业消防人员、19名应对火灾经验丰富人员、32名未经历过火灾心理素质良好人员以及36名未经历过火灾心理素质较差人员参加本系统中的灭火训练(这些人员与之前采集典型培训向量时的人员没有重叠),最终系统给出的身份预测结果见表7。
从表7中可以看出,该模型预测的身份信息基本符合人员的真实身份,准确率为92.00%。出现个别与真实身份不一致情况的原因有偶然性因素,例如应对火灾经验丰富人员在培训过程中状态良好,产生的培训向量与消防员的典型培训向量相似度很高,模型会将其归类为消防员身份。在准确预测出受训人员的身份信息后,系统将基于其身份推荐不同的消防培训任务,给出不同的遭遇火灾应对策略,如对于“未经历过火灾心理素质较差人员”,系统将推荐火灾逃生类培训任务而不是灭火类培训任务,同时会给出遭遇火灾时及时寻找逃生出口并第一时间逃生的建议。
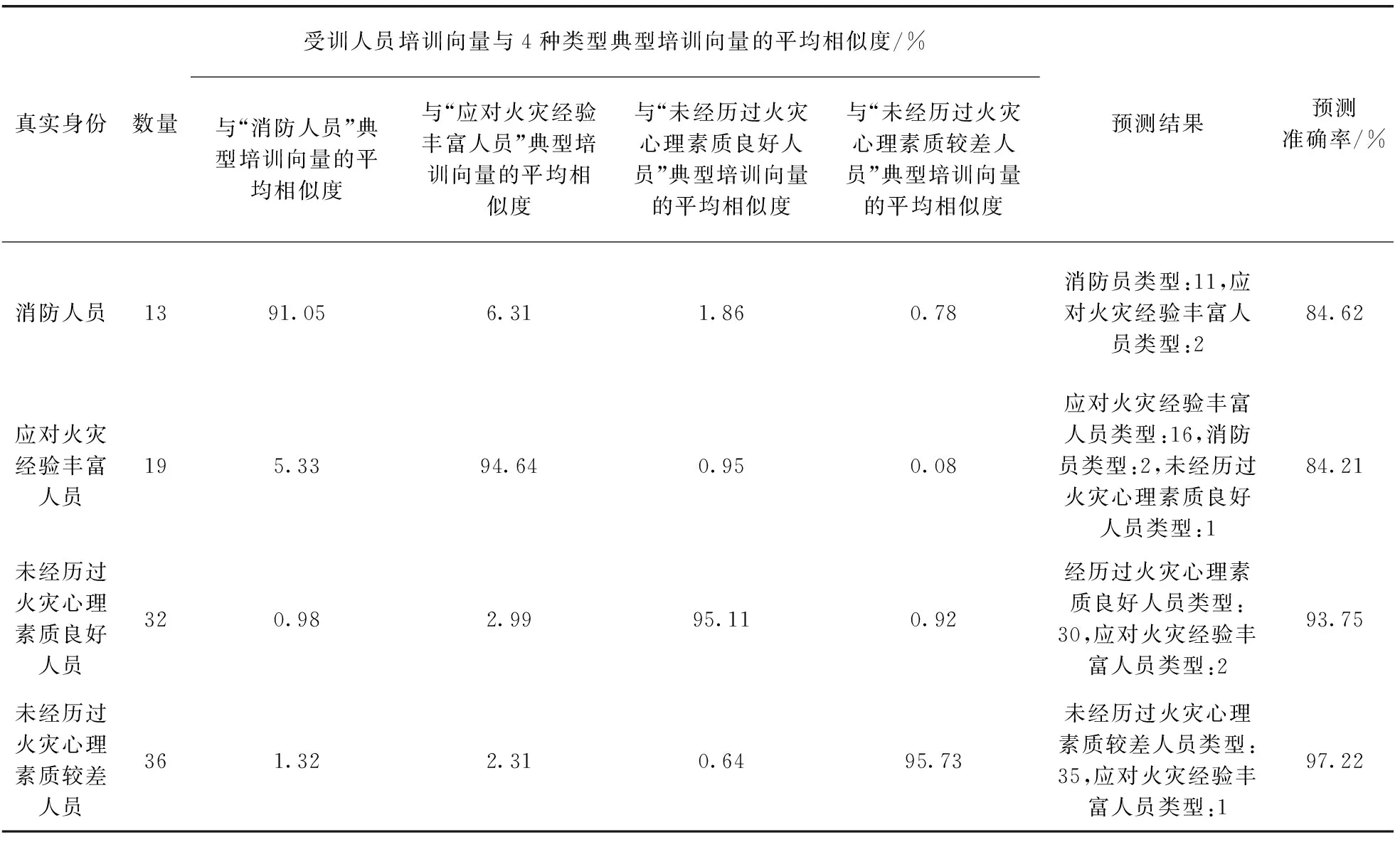
表7 Train2Vec模型身份预测准确率统计
4 结束语
实验结果表明,通过本文提出的Train2Vec模型对受训人员进行的身份预测准确率较高,基于身份预测结果可以有针对性地对受训人员开展消防培训。为让预测结果准确率更高,之后会将培训时的更多因素考虑进来,例如开始灭火时的火势大小、火焰的蔓延速度、培训场景内的烟雾浓度等因素,同时还需要在系统不断应用的过程中扩充典型培训向量数据集,构建更大量样本的Train2Vec模型。
