基于社交媒体文本信息的金融时序预测
2021-08-23李大舟
李大舟,于 沛,高 巍,马 辉
(沈阳化工大学 计算机科学与技术学院,辽宁 沈阳 110142)
0 引 言
金融时序预测对于制定有效的市场交易策略和保持经济健康持续发展具有重要意义。近年来,深度学习技术在自然语言处理[1-3]、语音识别[4]等一系列的复杂时序任务中得到广泛应用。与传统的浅层机器学习相比,深度学习通过构造更深层的网络结构来加强模型捕捉高级复杂特征的能力,从而能够挑战更加复杂的问题。Peng等[5]将文本挖掘和词嵌入相结合,从金融新闻中提取特征,并使用深度神经网络模型(deep neural networks,DNN)预测股票走势。实验验证了金融新闻特征在股票预测任务中的有效性。Huy等[6]使用来自路透社、彭博社的财经新闻和股票价格数据集,通过双向门控循环单元(bidirectional gated recurrent unit,BiGRU)来预测未来的股票走势。Ishan等[7]利用格兰杰因果关系分析了大量过去可用的数据,将新闻数据与股票数据相结合,对股价的变动进行分类,并结合一定的因素进行评估,提出了一种基于分段向量的信息分类机制和长短时记忆网络(long short term memories,LSTM)的预测模型。Leonardo等[8]提出了一种基于字符级的神经语言模型,并利用金融新闻数据集和LSTM网络进行趋势预测的方法。Jordan等[9]使用各种文本情绪分析工具来处理金融新闻,如情绪分析和事件提取等,使用LSTM和特定的卷积架构来进行股市趋势预测。Liu等[10]使用TransE模型和卷积神经网络来从金融新闻中提取特征。这种方法有效地提高了文本特征提取的准确性,同时减少新闻标题的稀疏性。另一方面,该文章提出了一种从每日交易数据和技术指标中提取特征向量的联合特征提取方法与LSTM模型相结合来进行股票价格预测。Zhang等[11]使用RNN、LSTM、GRU分别对标准普尔(S&P)500股票指数进行金融时序预测。基于以上针对金融时序预测任务所取得的成果,本文提出了一种基于社交媒体文本信息的股票趋势预测(BiTCN-LSTM)模型,该模型主要包括:①构建基于双向时间卷积网络的情感分类方法,对爬取的金融新闻文章进行情感特征提取。②使用LSTM网络和差分运算完成金融时间序列预测任务。
1 构建基于社交媒体文本信息的股票趋势预测(BiTCN-LSTM)模型
本文提出了BiTCN-LSTM算法,用于股票预测任务。算法分为BiTCN情感分析和LSTM金融时序预测两部分。情感分析部分使用双向时间卷积网络对整个社交媒体文本信息进行情感分析,获得情感特征;金融时序预测部分将差分运算后的金融时间数据和从文本中得到的情感特征加权融合作为输入,运用LSTM神经网络完成股票预测任务。总体框架如图1所示。
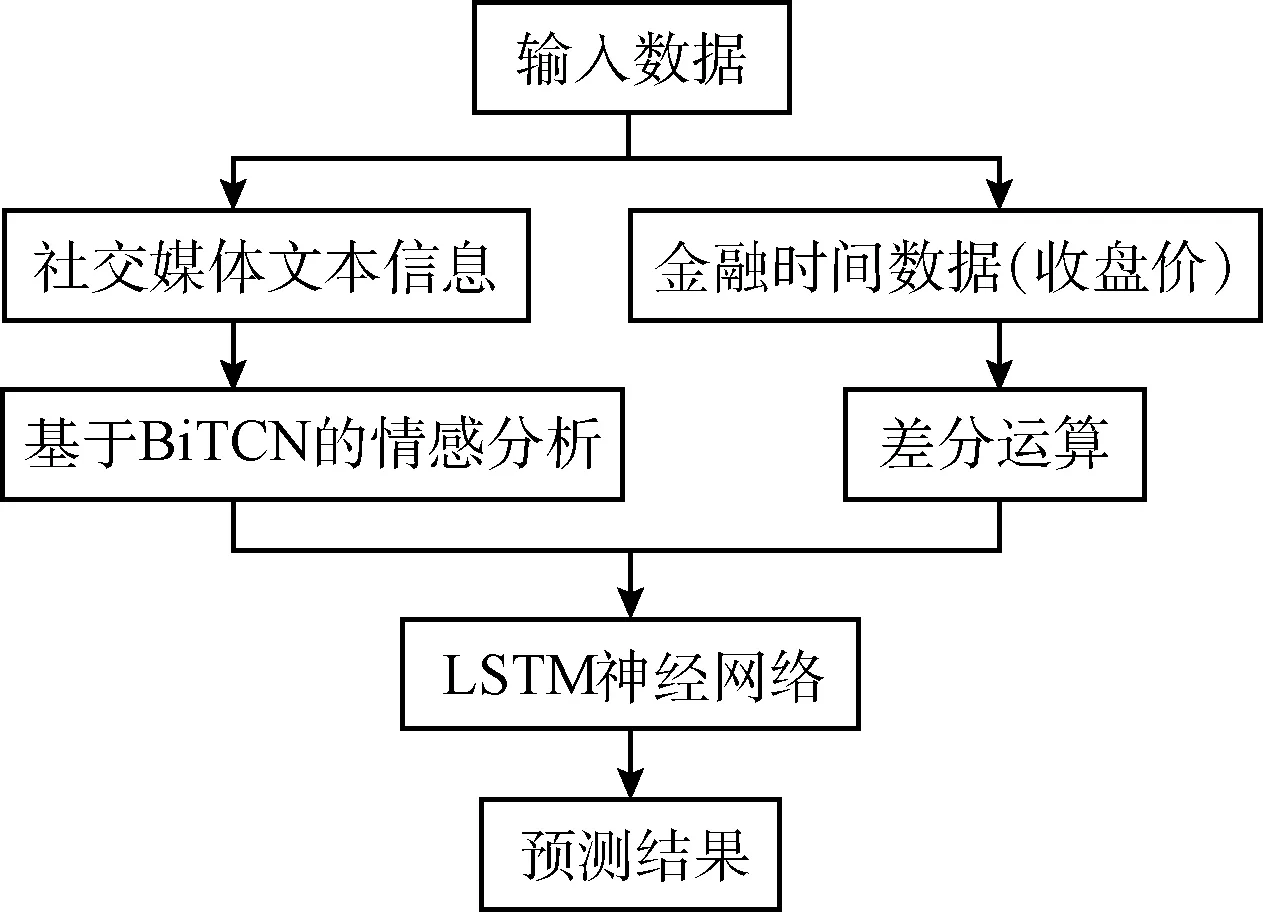
图1 总体框架
1.1 构建基于双向时间卷积网络的情感分类方法
为了能够更好地解决时序性问题,本文提出的模型应用了时间卷积网络[12]。普通的时间卷积网络对源文本数据进行单向卷积计算,完成序列建模,每个词汇(特指在文章分词后的一个词语,后文统称为词汇)的编码信息仅仅来自于上文的文本语义特征。但是在文本处理任务中,词汇的语义信息来源与词汇的下文语义信息也有很大的关联。因此,单向的时间卷积网络会忽略下文的语义信息,不能够更好地获取全文的文本语义特征。针对以上情况,本文提出一种基于双向时间卷积网络的情感分类算法,对文本进行双向特征提取,再将前向和后向的最后一个时刻的特征向量进行融合,从而得到文本整体语义向量,并在此基础上对文本进行情感分析。BiTCN情感分析部分框架如图2所示。

图2 BiTCN情感分析框架
(1)词嵌入
本文使用fastText[13]工具来构建词向量。在金融文本数据集上进行词向量预训练,得到所有词汇的稠密词向量表示。该方式训练的词向量能够很好地表达词汇的信息特征,能够体现出词汇之间的相似性和关联性。此外,fastText工具还可以快速搭建简单的分类器,对每一个词汇所属于的情感类别进行初步预判,从而帮助模型对文本进行情感分析。
本文对一篇文章分词后的序列E={e1,e2,…,en}进行词嵌入时,将每一个词汇et在词汇表中的one-hot编码拼接成输入矩阵nword∈Rn×Nword>,再通过嵌入矩阵Ww转化为词向量矩阵ew。词嵌入矩阵如图3所示
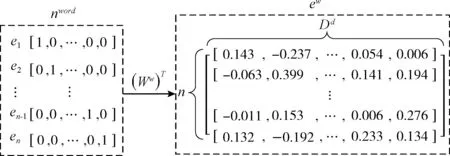
图3 词嵌入矩阵
ew=nword(Ww)T
(1)
其中,Ww∈RDd×Nword>,Nword表示词汇表中的词汇数,Dd表示词向量维度。
(2)双向空洞因果卷积层
时间卷积网络中卷积的因果性质主要通过因果卷积[14]实现。因果卷积的输出仅与当前(t时间点)与过去(0~t-1时间点)的输入有关,不涉及到未来(t+1时间点)的信息。一维因果卷积层可视化如图4所示。

图4 一维因果卷积层
本文在输入序列的左侧进行k-1个零向量填充(k为卷积核大小)。目的是将输入向量的维度与卷积计算后的结果维度相同,即
(2)

如图3所示,若想要增加卷积的感受野,构建长期记忆,那么因果卷积需要非常多的层级数或较大的卷积核。而卷积层数的增加可能会带来梯度消失、训练复杂、拟合效果不好等问题。为了杜绝这个问题,本文提出的模型在因果卷积的基础上引入了空洞卷积。
空洞卷积的定义请参见文献[15],在保证参数个数不变和输出的特征映射大小不变的情况下,增大了卷积核的感受野。对于一维的输入序列ew∈R和卷积核filter:{1,2,…,k-1}∈R,对序列中的ω元素的空洞卷积运算公式如下
(3)
其中,d为空洞系数,控制两个卷积核之间插入多少个零向量,ω表示当前元素所在的单元位置,ω-d·i表示上一层使用的输入单元位置。
为了确保能够产生足够长的有效历史信息以及使卷积核能够在有效的历史信息中覆盖所有的输入单元,d将随着网络深度的增加而指数级地增大。空洞因果卷积层可视化如图5所示。

图5 空洞因果卷积层
如图5所示,卷积核大小k为2,第一层使用的空洞系数d为1,后面层级的空洞大小依次加大。如图4所示,常规因果卷积只能观察到最后5个输入数据,而空洞因果卷积可以观察到所有16个输入数据,并且空洞因果卷积执行的速度更快,效率更高。
由于时间卷积网络的感受野随网络深度的加深而扩大,会出现训练困难、收敛缓慢等问题,因此,本文模型引入残差模块[16]和批标准化手段以解决上述问题。模型在应用了批标准化后的残差模块结构如图6所示。

图6 加入批标准化的残差模块结构
批标准化是通过一定的规范手段,把在训练过程中越来越偏的分布强制拉回到均值为0方差为1的标准正态分布,让梯度变大,从而避免梯度消失问题产生。
假设每个batch输入为L={l1,l2,…,lu},共有u个,则某个样本li的线性激活值sli为
sli=Wlli+b
(4)
其中,Wl为权重矩阵,b为偏置系数。
如图5所示,对隐藏层内每个神经元的激活值sli进行均值为0,方差为1的正态分布变换。详细计算过程如下
(5)
(6)
(7)
(8)

通过式(4)-式(8),使模型的梯度增大并加快了训练收敛速度。但该正态分布变换会使网络的表达能力下降,故本文设置了两个调节参数γ,β。对变换后的值再进行反变换操作,从而抵消正态分布变换的副作用。

(9)
(10)
其中,Wp×q是线性变换参数矩阵,p为原始向量维度,q为线性变换后的语义向量维度。
所谓“无理”,是指语言表达打破了习惯的思维逻辑,违反常情,不合常理;而所谓“妙”,是指读者在品读诗句,鉴赏诗情时,所产生的独特深刻的审美快感。这些诗句有的描写事物时用一种反常规的词语搭配,或者反常规的句法结构;有的表达情意时有悖常识,或者不合情理,但表达出来的却是极为引人入胜的审美效果。诗歌若是写,新颖且别有滋味。而个中韵味,则有待我们细咂慢品。

(11)
(3)softmax输出
利用融合后的语义特征信息h,经过softmax层得到每个交易日的文本情感特征向量
p=softmax(hW2q×c+b)
(12)
其中,W2q×c为参数矩阵,c是情感分类的类别,b为偏差,其维度也是c。
1.2 构建基于LSTM神经网络的金融时序预测方法
在本小节中,将分别介绍差分运算和LSTM神经网络。首先,对实验数据集进行差分运算预处理,处理后的金融时序数据和文本情感特征向量作为输入,通过LSTM神经网络完成金融时序预测任务。金融时序预测部分框架如图7所示。

图7 金融时序预测框架
(1)差分运算
平稳的时间序列是建立时间序列预测模型的前提,由于金融时间数据具有非线性、非平稳[17]的特性。因此,选用差分运算对实验数据集进行预处理。差分运算通过计算相邻交易日的调整后收盘价的差值,来获得较为平稳的时间序列。假设金融时间序列为D={d1,d2,…,dm},m是金融时序数据量,t时刻的差分运算如式(13)所示
d′>t=dt-dt-1
(13)
其中d′>t是差分后的序列(第t-1天和第t天调整后收盘价的涨跌点),dt和dt-1分别是原始序列中第t天和第t-1天的调整后收盘价。
(2)LSTM神经网络
循环神经网络(recurrent neural network,RNN)是一种特殊的深度神经网络结构,其与传统的神经网络相比,RNN模型具有时序性,前一个隐层的输出会作为下一个隐层的输入,由此引入了时间维度。但在预测过程中,仍然存在梯度爆炸和梯度消失的问题。因此,使用RNN模型进行长序列处理的效果不佳,导致时间序列的长期依赖关系难以学习[18]。
长短时记忆网络(long short term memories,LSTM)是一种特殊的循环体结构,它的一个重要设计是加入了记忆细胞状态c和三大“门”结构。LSTM模型与RNN模型相比,克服了梯度爆炸和梯度消失的困难,更能够记住长期的信息[19]。LSTM网络单元如图8所示。

图8 LSTM网络单元
如图8所示,差分后金融时间数据的输入序列为D={d′>1,d′>2,…,d′>m},文本情感特征的输入序列为P={p1,p2,…,pm},则LSTM的隐藏状态分别为S1,S2,…,Sm。LSTM模型具有三“门”一状态结构,包括输入门、遗忘门、输出门和细胞状态。其中,输入门控制那些信息传递到当前状态中,遗忘门控制从当前状态中移除哪些信息,输出门控制当前状态中的哪些信息用作输出。
在LSTM循环体中,输入门、遗忘门和输出门的输入均为t时刻的金融数据输入d′>t、t时刻的文本特征输入pt和t-1时刻的隐藏状态St-1,并使用sigmoid函数将门的输出控制在区间[0,1]。假设隐藏单元个数为s,t时刻的输入门、遗忘门和输出门分别计算如下
(14)
it=σ(d′>tWdi+ptWpi+St-1Whi+bi)
(15)
ft=σ(d′>tWdf+ptWpf+St-1Whf+bf)
(16)
ot=σ(d′>tWdo+ptWpo+St-1Who+bo)
(17)
其中,σ为sigmoid函数,Wdi,Wpi,Wdf,Wpf,Wdo,Wpo为输入权重,Whi,Whf,Who分别为输入门权重、遗忘门权重和输出门权重,bi,bf,bo为偏差参数。

(18)
其中,Wdc,Wpc,Whc为权重参数,bc为偏差参数。
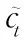
(19)
其中,⊗为按元素乘法。
最后,t时刻的记忆细胞ct经过tanh层得到一个值域为[-1,1]的向量,该向量与输出门得到的输出向量ot相乘,便可得到最终的隐藏状态St
St=ot⊗tanh(ct)
(20)
2 实验与分析
2.1 数据集
本文以上海证券综合指数(又称上证指数)作为研究对象,金融时序数据样本采用从2010年1月1日到2020年4月15日的上证指数数据,共计2499个交易日的股票历史数据。每个交易日都拥有5个标签(开盘价、最高价、最低价、调整后收盘价、振幅和成交额),本文选用调整后收盘价作为该模型的预测目标。上证指数的调整后收盘价如图9所示。

图9 上证指数的调整后收盘价
为了从数据源上保证文本语料和股市之间的领域相关性,本文自行爬取的金融社交媒体的文本信息主要来源是东方财富财经新闻。每个交易日对应数十条社交媒体信息,共371 020条社交媒体信息数据。
本文将金融时序数据按照80%和20%的比例分为两部分,分别为训练集和测试集。测试集有252个数据,用于评估模型的预测效果。实验数据集见表1。

表1 实验数据集统计
2.2 参数设置
本文中出现的符号说明见表2,其它符号均在文中详细标注。
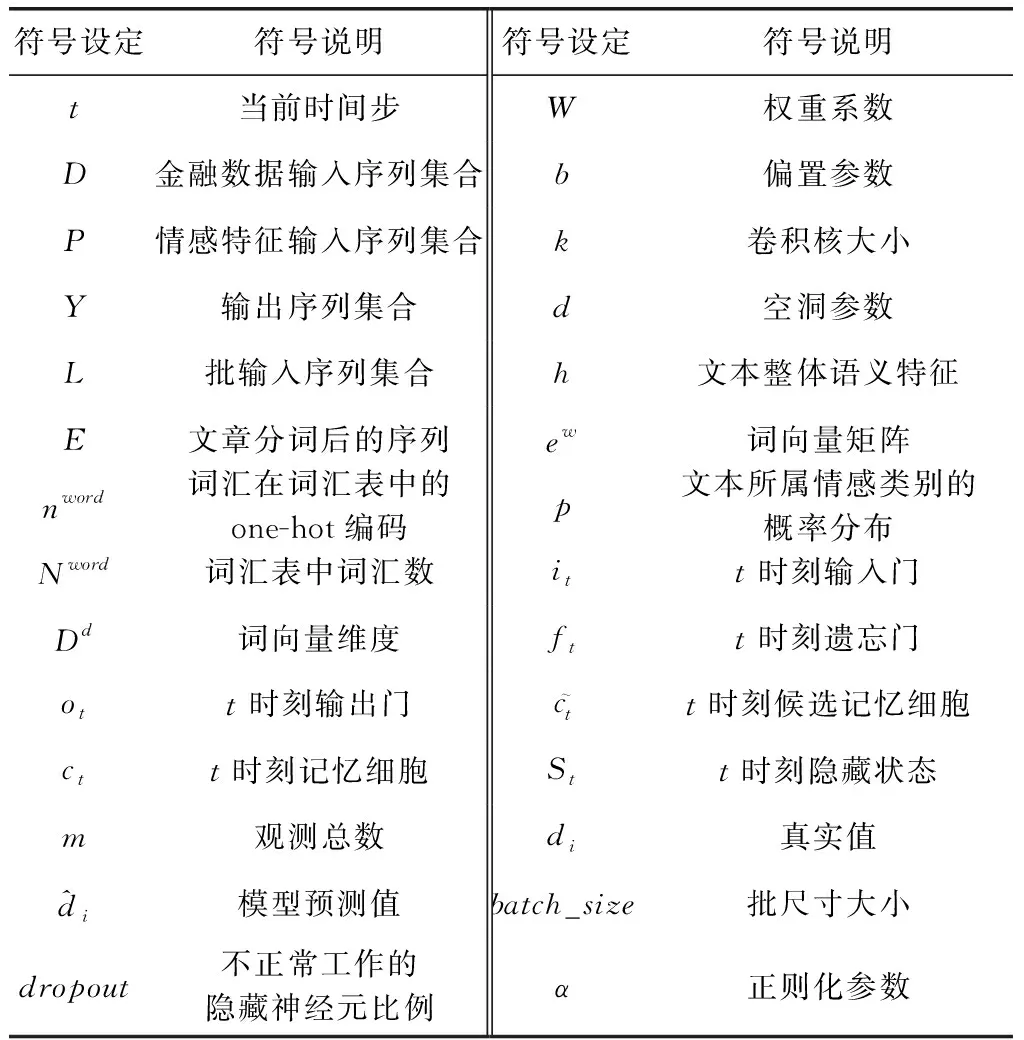
表2 本文中出现的符号说明
本文通过对数据集与模型的分析,调整超参数初始值,以达到误差最小化。模型的验证曲线与学习曲线如图10所示。
如图10(a)所示,网络深度在0-5层内,随着网络深度的增加,训练分数和交叉验证分数不断增大。网络深度到达5层之后,分数慢慢接近最大值。因此本文的网络深度选择为5层。如图10(b)所示,学习曲线显示了一个非常高的可变性,并且在第520个交易日之前交叉验证分数很低。第520个交易日后两条曲线慢慢融合在一个很高的分数上,因此,数据量大的数据集可以使模型预测效果变好。
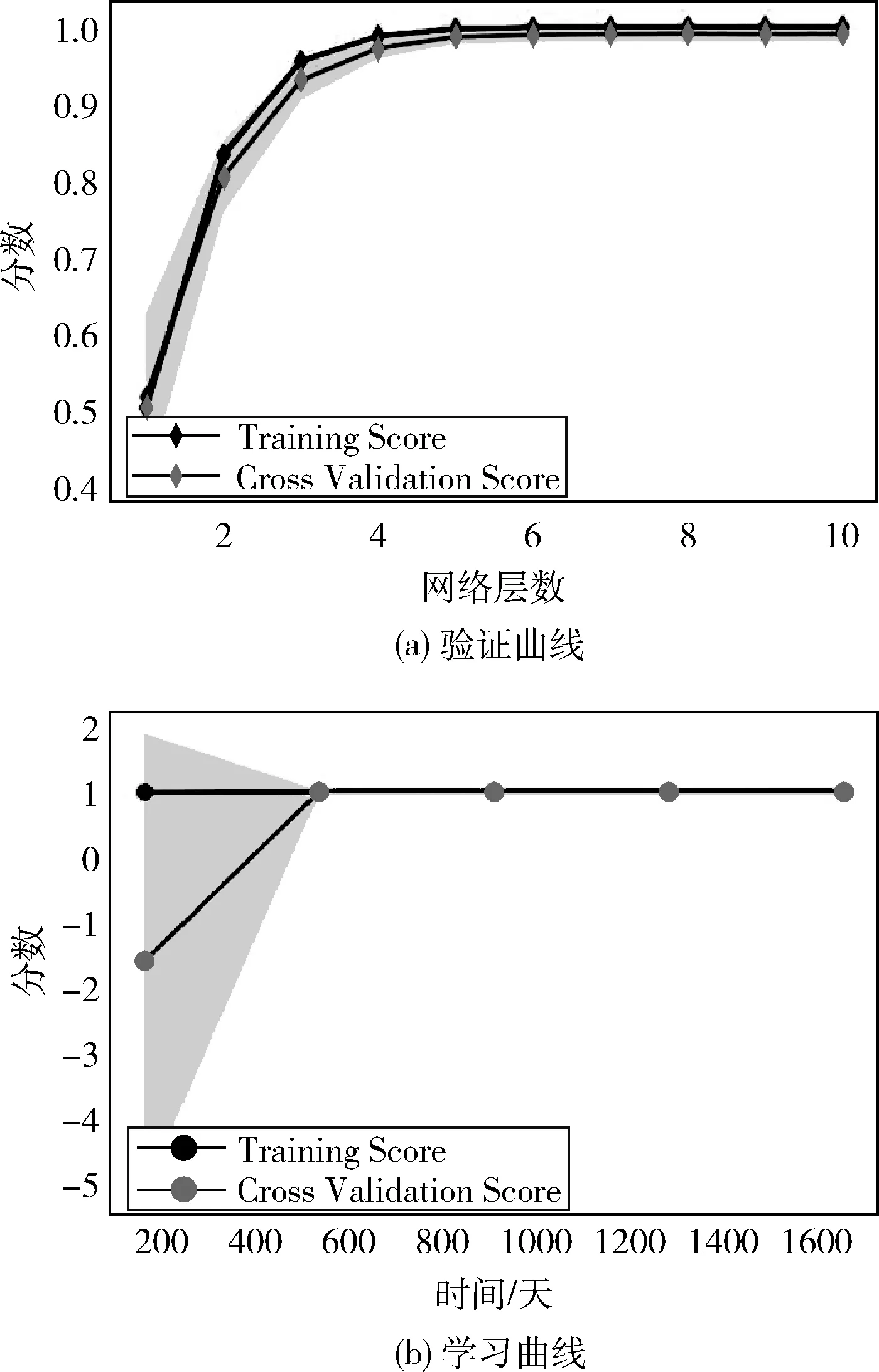
图10 BiTCN-LSTM模型的验证与学习曲线
正则化旨在引入一个α值参数来对其相互之间系数的权重进行标准化并且惩罚其模型复杂度。α值与模型复杂度呈负相关性,α值越低,模型越复杂,由于方差增加而增加的误差也会相应增加。另一方面,α值越高,模型越简单,由于偏差造成的误差就会越大。因此,选择最佳的α值,以便达到最小化误差的效果。不同α值选择对正则化的影响如图11所示。

图11 误差与不同α值选择的变化曲线
如图11所示,α值为2.006时,模型误差达到最小化。故本文正则化参数α值设置为2.006。
2.3 金融时序预测的评价方法

(21)
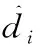
2.4 实验结果分析
本文采用上述数据集进行实验,在金融时序预测模型训练过程中使用均方误差损失,使用Adam算法来优化神经网络权重,batch_size为40,dropout[20]设置为0.8。迭代500轮的结果如图12所示。虚线和实线分别代表训练损失值(train loss)变化情况和测试损失值(test loss)变化情况。

图12 BiTCN-LSTM模型训练损失值与测试损失值 变化曲线
模型测试集中500天的预测值与真实值的对比曲线如图13(a)所示。实线和虚线分别代表数据标准化后的测试集预测值和真实值的变化情况。预测值与真实值之间的差异曲线如图13(b)所示。残差如图13(c)所示。

图13 BiTCN-LSTM模型预测值与真实值对比
如图13(b)、图13(c)所示,模型预测值曲线呈正态分布,符合自然规律。此外,本文提出的BiTCN-LSTM模型对由重大政治事件或重大自然灾害等因素影响而引起的突然的价格上涨或下跌也具有较好的预测效果。
此外,本文与3个传统金融时序预测模型进行了对比实验,实验结果详情见表3。其中:
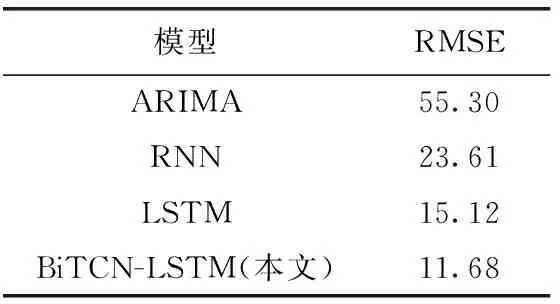
表3 不同模型之间的RMSE评价指标对比
ARIMA[21]:代表文献[21]中提出的股票趋势预测模型。
RNN[22]:代表基于循环神经网络的股票趋势预测模型。
LSTM[23]:代表基于长短时记忆神经网络的股票趋势预测模型。
BiTCN-LSTM(本文):代表本文提出的基于社交媒体文本信息和LSTM的股票趋势预测模型。
由表3可以看出,以上海证券综合指数作为研究对象,使用ARIMA模型、RNN模型和LSTM模型所得到的RMSE值分别为55.30、23.61和15.12。与此同时,本文设计的BiTCN-LSTM模型得到的RMSE值为11.68,本文模型与传统金融时序预测模型相比,RMSE值分别降低78.88%、50.53%和22.75%。
2020年初的新冠肺炎疫情肆虐,从2020年第一个交易日的A股暴跌到美股的4次熔断,疫情对股市的影响巨大。本文针对上述情况将LSTM模型与本文模型(BiTCN-LSTM)做对比实验。实验结果如图14所示。虚线代表使用LSTM模型的预测值,点线代表真实值,实线代表使用本文模型的预测值。
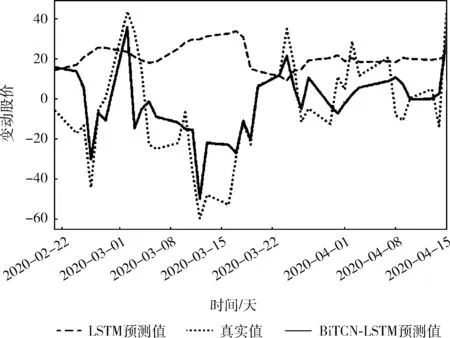
图14 LSTM模型与本文模型的对比实验结果
如图14所示,由于疫情影响,导致近期股市的波动剧烈。LSTM模型无法做到准确预测,而本文模型在加入社交媒体文本情感特征后,能够较为准确地预测股市趋势。因此,本文所提出的BiTCN-LSTM模型具有更好的预测性能。
3 结束语
股市在市场经济中占据重要地位,准确的金融时序预测结果对股市交易操作和规避股市风险都具有指导作用。本文通过对金融时序预测的研究与学习,针对传统预测模型中忽略社交媒体文本信息对股价变化影响等问题,提出了一种融合社交媒体文本信息和LSTM的股票趋势预测模型(BiTCN-LSTM)。针对传统预测模型中忽略社交媒体文本信息对股价变化的影响,该方法使用双向时间卷积网络对社交媒体文本信息进行特征提取和情感分类,在预测模型的输入层面加入社交媒体文本信息特征。同时结合差分运算和LSTM神经网络,有效解决了时间序列的平稳性问题,进一步提高了预测准确率。采用上证指数和股票社区评论作为基准数据集,实验对比分析了现有金融时序预测方法,本文的股票趋势预测效果有了很大的提升。
