基于线性回归的空气质量监测仪数据校准方法研究*
2021-08-23吴玲玲杜赵杭韩凯波陈一飞
吴玲玲,杜赵杭,韩凯波,陈一飞,赵 怡
(南京铁道职业技术学院,江苏 南京210031)
本文选取的空气质量监测国控点数据时间跨度为2018年11月14日10:00~2019年6月11日15:00,共4200个样本;自建点数据时间跨度为2018年11月14日10:02~2019年6月11日16:32,共234717个样本。我们首先对自建点数据进行预处理,将自建点数据处理为以一小时为间隔的样本,再对自建点数据中降水数据进行处理,最后将国控点数据与自建点数据进行匹配,得到4065个样本进行研究[1]。
1 数据分析
1.1 数据预处理
由于国控点数据是以一小时为间隔的样本,因此将自建点的数据同样处理为一小时间隔。采取的方案是,选取相应于国控点时间前15分钟和后15分钟区间的数据取平均值(除降水数据)。自建点数据中有降水量数据在某时段递增,然后清零。选取自建点降水数据中相应于国控点时间前5分钟和后5分钟区间内最后一个时刻的记录作为该整点的累积降水量。通过Excel统计,见图1(a),发现清零出现两次。另降水数据存在一些奇异点,将奇异点的数值通过前后时刻数据的对比进行订正。订正方法如下[1-2]:第一步,找出奇异点对应的时刻,对该时刻前后5分钟的数据进行分析,找出错误数据,将前后数据对比并订正,数据质量明显提高,见图1(b);第二步,若某整点数据缺测,根据前后数据进行订正。若前后数据相同,将缺测数据记为相同值;若前后数据不相同,仍记为缺测。然后用后一整点的累积降水量减去前一整点的累积降水量得到该整点的降水数据,遇缺测情况记为缺测。

图1 降水量国控点和自建点数据概率分布图
1.2 PM2.5、PM10数据统计分析
利用Matlab软件对国控点和自建点数据中的PM2.5、PM10数据进行统计特征分析,包括平均值、标准差、最大值、最小值,并进行两组数据的对比[2-3(]见表1)。
从表1可以发现,PM2.5国控点数据与自建点数据的标准差相差不大,最值也相当,但自建点数据的平均值较国控点数据的平均值偏大很多。PM10自建点数据的标准差比国控点大很多,说明自建点数据分布更离散,并且自建点数据的平均值也较国控点数据的平均值大很多,而国控点数据的最大值接近自控点数据最大值的两倍。
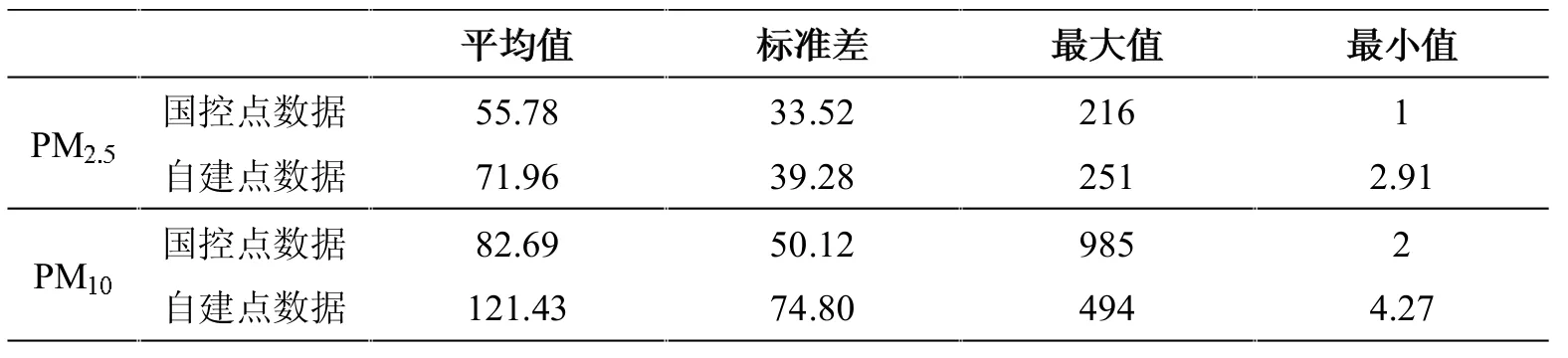
表1 两种污染物国控点与自建点数据的统计特征
分别绘制国控点和自建点数据的概率分布图(见图2)。PM2.5两组数据分布状况较一致,都呈单峰型分布。PM10国控点数据绝大部分分布在200以内,而自建点数据主要分布在350以内,存在量程漂移。
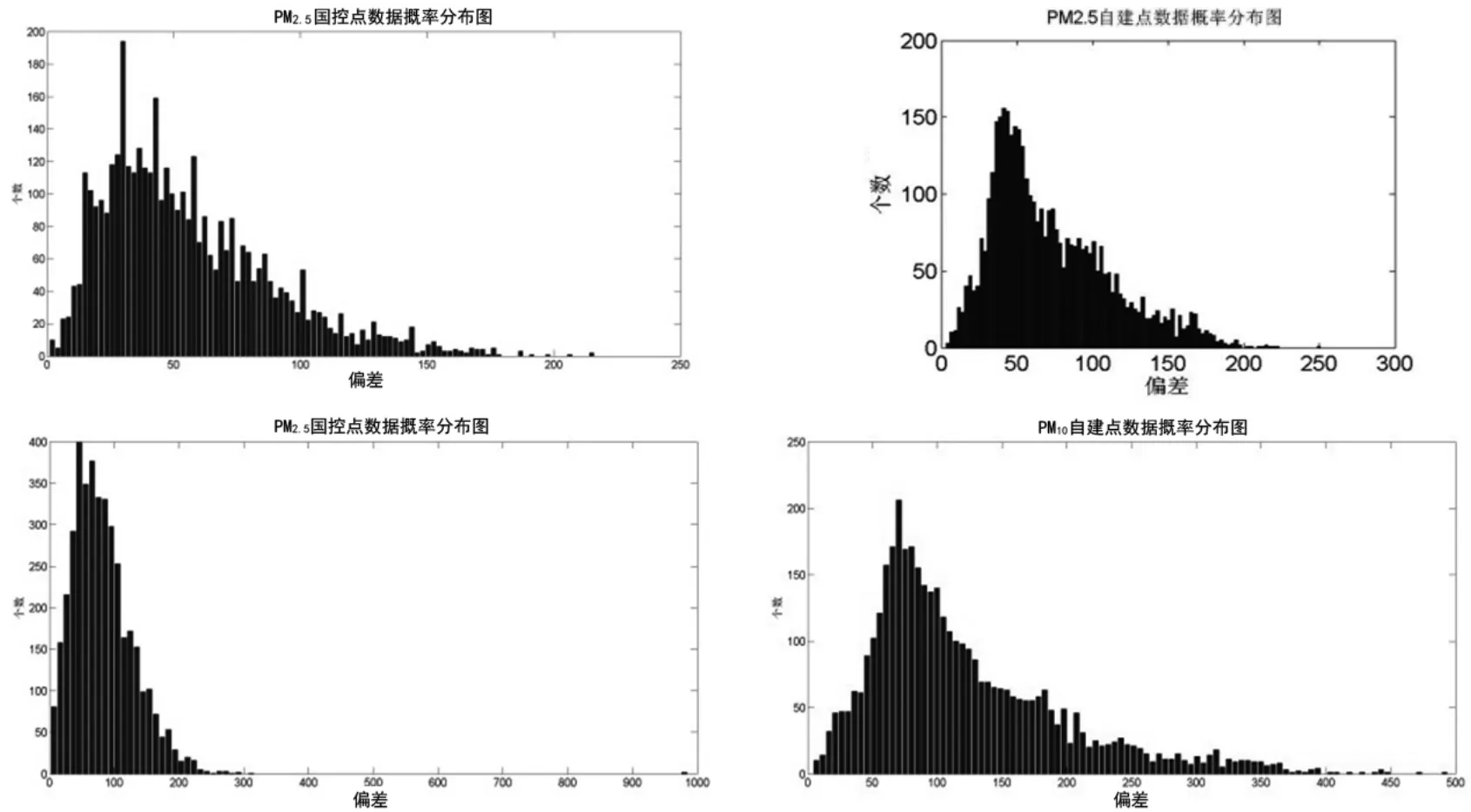
图2 PM2.5和PM10国控点和自建点数据概率分布图
接着,对PM2.5、PM10国控点数据和自建点数据绘制散点图(见图3(a)、图4(a))。利用国控点数据与自建点数据做差,对差值绘制PM2.5偏差概率分布图(见图3(b)、图4(b))。在图3(a)中,对比线A表征自建点数据与国控点数据完全相同。大部分散点集中在对比线附近,因此两组数据的偏差不是太大。大部分散点在对比线上方,说明自建点数据与国控点数据之间存在负偏差。在图3(b)中,自建点数据与国控点数据之间存在整体负偏差,且为单峰型分布,峰值左右较对称,类似正态分布的特征。在图4(a)中,大部分散点集中在对比线A上方,自建点数据与国控点数据之间存在明显的负偏差,且散点在对比线上下分布得不均匀,上面明显多于下面。此外,国控点的数据主要在0~200的范围内,而自建点数据在0~350的范围内。在图4(b)中,自建点数据与国控点数据之间存在整体负偏差,且为单峰型分布,峰值左侧的概率高于右侧,呈偏态分布。
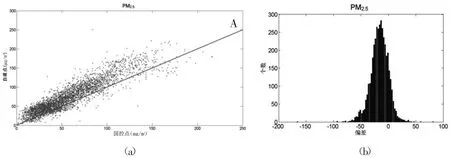
图3 PM2.5散点图和偏差概率分布图
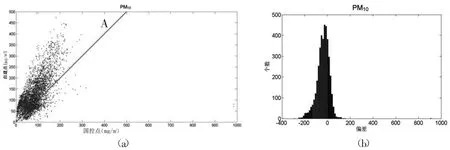
图4 PM10散点图和偏差概率分布图
1.3 PM2.5、PM10数据统计量计算
通过偏差、相关系数、均方根误差三个统计量对两组数据的整体特征进行统计分析。三种统计量的计算方法如下。
两组数据的偏差(bias)计算公式:

其中,Xi为自建点每个小时的数据,Yi为国控点每个小时的数据,n为数据个数。我们定义当bias大于0为正偏差,小于0为负偏差。
两组数据的相关系数(rXY)计算公式:
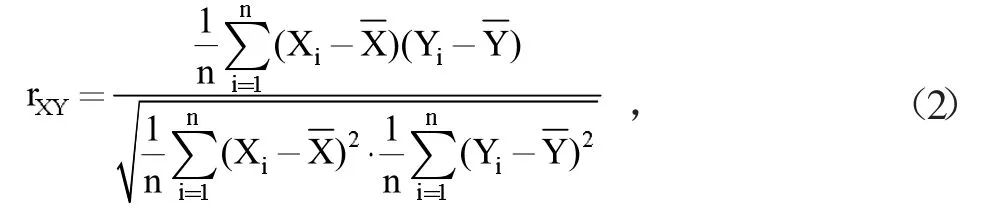
其中,Xi,Yi,n同上,X为自建点数据的平均值,Y为国控点数据的平均值。
两组数据的均方根误差(RMSE)计算公式:
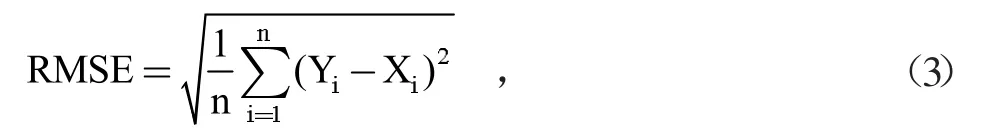
其中,Xi,Yi,n同上。
计算PM2.5自建点数据相对于国控点数据的偏差、相关系数和均方根误差,见表2。两组数据的偏差为-16.18,明显存在整体负偏差;两组数据的相关系数为0.91,说明两组数据的变化趋势一致;两组数据的均方根误差为22.85,表示两组数据存在较大差异。而PM10两组数据的偏差为-38.74,明显存在整体负偏差;两组数据的相关系数为0.65,说明两组数据的变化趋势较一致;两组数据的均方根误差为65.67,达到平均值的一半,表示两组数据存在较大差异。

表2 PM2.5、PM10国控点与自建点数据校准前后统计量
2 数据差异因素分析
由图3(b)发现PM2.5自建点数据明显存在负偏差,并且自建点开始的数据要明显高于国控点的数据,两种数据的最大值相当,两组数据的差异可能由零点漂移产生。而PM10的自建点数据明显存在整体负偏差,并且国控点的数据主要在0~200的范围内,而自建点数据在0~350的范围内,两组数据的量程不一致。图4(b)中的偏态分布,也有可能是量程不一致造成的。我们利用自建点数据进行一元线性回归,将数据进行校准。
3 数据校准
3.1 建立一元线性回归校准方案
根据两种数据中的PM2.5数据建立一元线性回归校准方程:
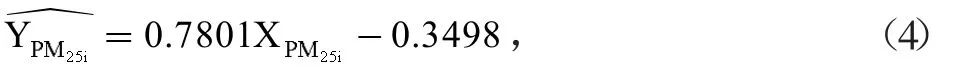
其中,XPM25i为自建点每个小时的数据,为自建点每个小时的校准数据。
对PM10数据建立一元线性回归校准方程:
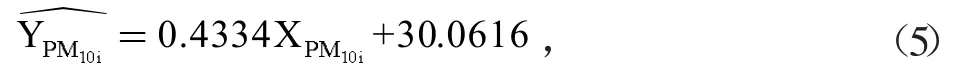
其中,XPM10i为自建点每个小时的数据,为自建点每个小时的校准数据。
3.2 校准前后数据对比
下面对数据校准前后进行比较[4]。从图5(a)、图5(b)可以发现,PM2.5订正后的自建点数据负偏差明显消失,且零点漂移的现象也明显减小。在偏差概率分布图中,0附近的概率最大。通过表2可知,校准后自建点数据的负偏差变为-0.01,显著减小,均方差根误差也明显减小。说明PM2.5的自建点数据得到了有效的校准,数据质量明显提高。从图6(a)、图6(b)可以发现,PM10订正后的自建点数据负偏差明显消失,且量程漂移的现象也明显减小。在偏差概率分布图中,峰值位于0附近,偏态分布也趋于正态分布特征。通过表2可知,校准后自建点数据的负偏差变为-0.46,显著减小,均方差根误差为32.26,也明显改善,同时两组数据的相关系数也进一步提高。说明PM10的自建点数据得到了有效的校准,数据质量明显提高。
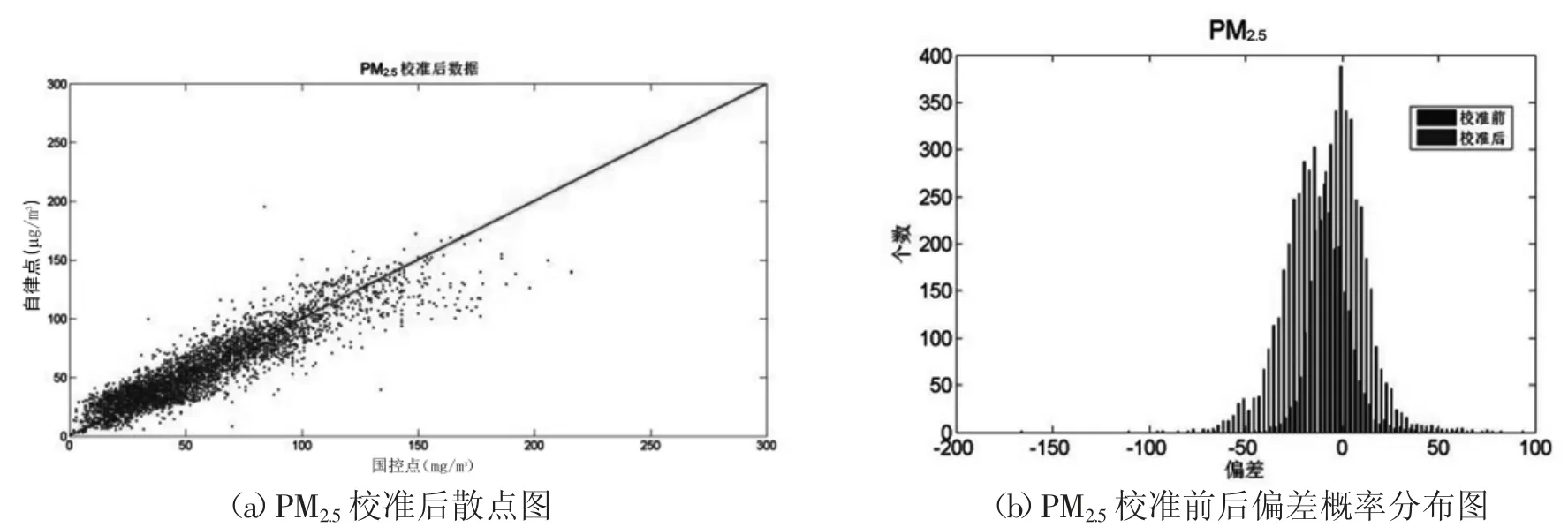
图5
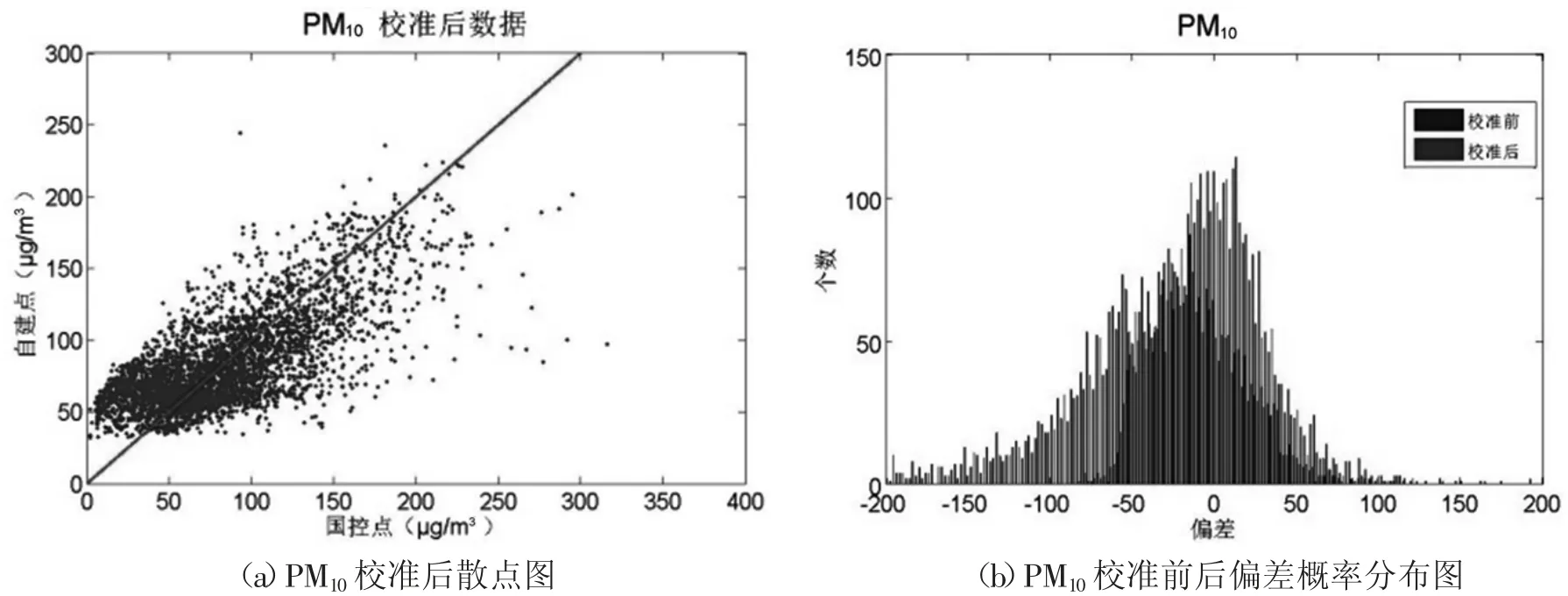
图6
4 结论
本文针对某公司研发的微型空气质量监测仪提供的实时空气污染物数据,分别对PM2.5和PM10两种污染物自建点数据进行了深入数据分析和详细的差异因素分析,并根据不同污染物数据误差特点给出了相应的一元线性回归校准方案,校准后的数据质量明显提高。该校准方案在业务上实践性强,对空气质量监测仪的数据有一定的订正效果。为微型空气质量监测仪后期能够提供更准确的实时空气质量监测数据以及传感器的改进提供了参考方案。
