基于LSTM的谣言检测
2021-08-23刘钟山
刘钟山
(天津工业大学计算机科学与技术学院,天津300387)
0 引言
中国互联网络中心(CNNIC)于2020年9月发布的《中国互联网络发展状况统计报告》显示,截至2020年6月,我国网民规模为9.40亿,较2020年3月新增网民3625万,互联网普及率达67.0%,较2020年3月提升2.5个百分点。其中,50岁及以上万民群体占比由2020年3月的16.9%提升至22.8%,互联网向中高年龄人群渗透的趋势愈发明显。
移动互联网使人们获取信息更加方便快捷,但网络中存在的谣言对公众产生了较大的影响。雷霞将谣言定义为:没有相应事实基础却被捏造出来并通过一定手段推动传播的言论。文献[1]特别对于识别信息能力较差的老年用户,谣言使他们不能获得正确的信息,阻挡了他们了解社会动态,谣言的传播也对社会稳定造成了不利影响。2020年12月,诸如“成都确诊女孩照片”、“武昌职业学院士官生集体发烧”等谣言混淆公众视听,对社会影响十分恶劣。
1 相关文献综述
传统方法的谣言检测通常基于文本的转发量、评论量、发布用户的注册时间、粉丝数等统计特征并结合SVM、机器学习等方法进行识别。
2013年,贺刚等人[2]将谣言识别视为可信性分类问题,引入识别谣言的符号特征、链接特征、关键词分布特征和时间差等新特征并基于SVM机器学习方法来预测是否为谣言;
2013年,程亮等人[3]通过微博谣言的传播特点和产生原因,利用BP神经网络模型及改进其激发函数并引入冲量项,对微博话题在传播过程中演变为谣言进行检测;
2016年,毛二松等人[4]提出了一种基于深层特征和集成分类器的微博谣言检测方法,首先对微博情感倾向性、微博传播过程和微博用户历史信息进行特征提取并利用训练的集成分类器进行分类;
2017年,武庆圆等人[5]提出一个针对微信等短文本的在文本与标签之间引入语义层的多标签双词主题模型;
2017年,魏阳等人[6]将网络谣言的识别因素归纳为信息来源、信息量、互文性等7种指标因素,采用灰色关联分析方法构建网络谣言识别模型,并通过聚类分析网络谣言案例进行数据处理分析网络谣言案例严重程度,对网络谣言进行分类处理,如图1所示。

图1 模型结构
传统方法的谣言检测通常基于统计特征进行识别,如符号特征、转发量、阅读量、发布者的相关信息等。本文基于长短期记忆网络(Long Short Term Memory,LSTM),首先在Embedding层中使用Skip-Gram模型将文本中的内容向量化并输入LSTM层,形成句子级向量,最后使用Softmax进行分类。基于文本内容特征进行谣言检测。
2 谣言识别
本文首先通过Embedding层将中文文本向量化,输出词向量,并将词向量输入到LSTM层融合成句子向量,最后通过分类器进行谣言于非谣言的判别。
2.1 Embedding层
传统的文本向量表示通常使用One-Hot向量表示词汇,但此方法通常存在以下两个问题[7]:
●One-Hot向量的维度等于词汇量的大小,若词汇量较大,那么得到的表示矩阵将非常稀疏。
●One-Hot向量无法得到词汇之间的关联信息。
2013年,Mikolov等人[8]提出了Word2Vec模型,其核心思想是同一上下文中的单词语义相近,单词可以由其上下文表示。
Embedding模型中,通常使用Continuous Bag of Words(CBOW)和Skip-Gram(SG)两种模型,CBOW模型通过上下文预测目标单词,而SG模型通过输入的目标单词预测上下文,CBOW模型和SG模型的结构如图2所示。

图2
左:CBOW结构图,右:Skip-Gram模型结构图。
在Embedding层中,本文使用Skip-Gram训练来创建词向量。通过无监督的SG模型进行文本特征化处理,将文本向量化,并作为LSTM层的输入。
2.2 LSTM层
1996年Hochreiter等人[9]提出了长短期记忆网络LSTM。
LSTM是循环神经网络(Recurrent Neural Network,RNN)的一种,但辅助RNN决策的主要是最后输入的信号,缺少长期依赖的关系,RNN对较远距离信息的处理能力不够好。LSTM有效地克服了RNN的梯度消失问题。
与RNN相比较,LSTM保留了RNN的基本结构并进行了改进,LSTM充分考虑到了“细胞”之间的自循环,其结构如图3所示。LSTM引入输入门、遗忘门、输出门,主要通过三个“门”的结构控制信息的添加与删除,其中输入们控制当前时间步计算的状态将以多少程度更新到记忆单元,遗忘门控制前一时间步传来的信息将以多大程度被遗忘掉,输出门控制当前时间步的记忆单元将以多大程度输出。
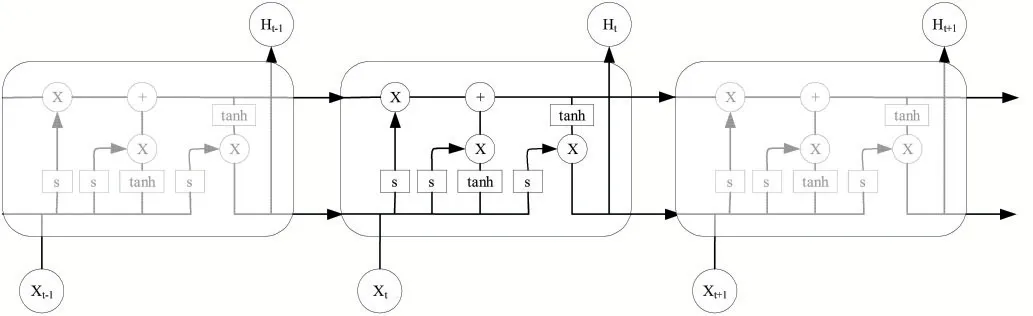
图3 LSTM基本结构
(1)遗忘门。遗忘门的作用是根据当前的输入、上一时刻的输出和门的偏置项决定需要丢弃多少信息,若以ft表示当前LSTM单元遗忘门的输出值:
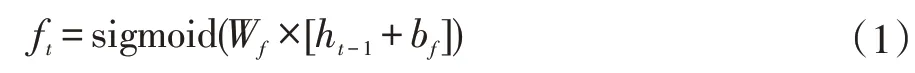
(2)输入门。输入门决定当前输入中有多少会写入单元状态:
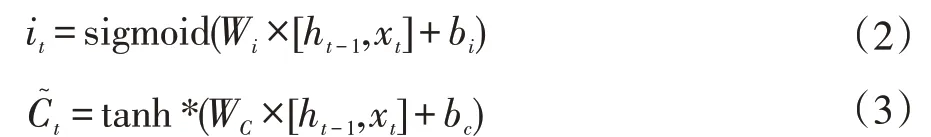
并将Ct-1时刻的信息更新到Ct:

(3)输出门。输出门决定最终输出的值:

LSTM层将Embedding层输出的词向量融合为句子向量,通过Dropout层后经分类器进行分类。
2.3 Dropout层
在模型训练的过程中,通常会遇见过拟合问题,过拟合问题通常表现为模型在训练数据上损失函数较小,预测准确率高,在测试集上损失大,预测准确率较低,过拟合的模型会影响模型的预测效果。
2012年Hinton等人[10]提出Dropout,用于防止过拟合,Dropout通过修改神经网络中的神经元节点以防止训练的模型出现过拟合的现象,如图4所示。
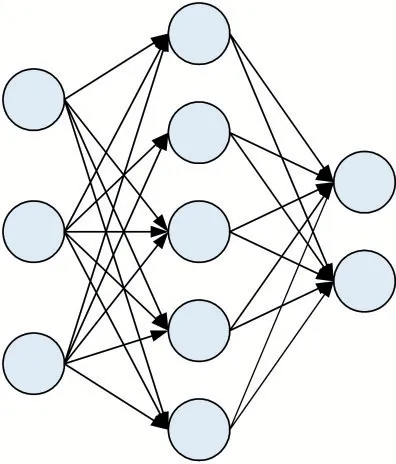
图4 Dropout使用前
Dropout使用后删掉了其中部分的隐藏层神经元单元,每一次迭代都随机删除部分的隐藏层神经元,随着迭代次数的增多,每一次都用部分神经元去训练整个网络,最终有效避免了过拟合,如图5所示。

图5 Dropout使用后
2.4 Softmax分类层
Softmax分类层是模型的最后一层,用于进行有监督化分类训练。文本经LSTM层和Dropout层处理后,形成语句级特征向量,使用Softmax对其进行分类,对文本是否为谣言进行识别。

公式(7)为Softmax输出函数的公式,输出p表示y属于m的概率,根据概率决定分类的类别,o为特征融合后的向量[11]。
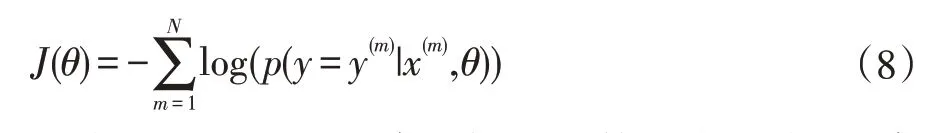
公式(8)为Softmax代价损失函数的表达式,N代表训练、测试集,x、y对应训练样本。
3 实验与分析
本文使用刘知远等人[12]公开的微博谣言数据集,并对其中数据进行整理,构建数据字典与数据列表,并得到可用于模型训练的数据集如表1所示。
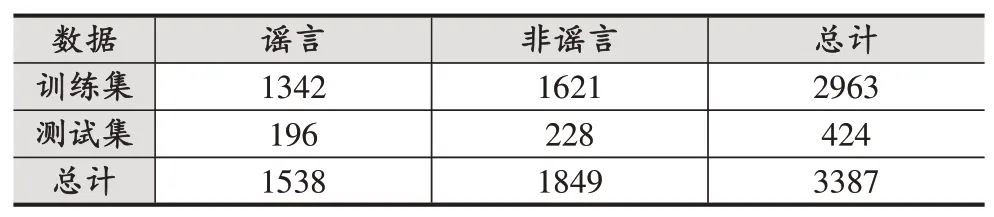
表1 训练数据
本文使用二分类问题的精确率(P)、准确率(A)、召回率(R)、F1值作为评价指标;定义非谣言为正类,谣言为负类,则:
True Positive(TP):将真实标签为正类的预测为正类,即正确识别非谣言;
False Positive(FP):将真实标签为负类的预测为正类,即将谣言识别为非谣言;
False Negative(FN):将真实标签为正类的预测为负类,即将非谣言识别为谣言;
True Negative(TN):将真实标签为负类的预测为负类,即正确识别谣言。
混淆矩阵如表2所示。

表2 混淆矩阵
本文采用二分类问题的常见评价指标对算法的识别结果做出评价,各指标计算方法如下:
准确率表示测试集中全部预测正确的概率:

精确率表示该类别中预测为该类别的消息数中实际为该类别的比例;

F1值用来衡量模型的整体效果,是召回率和精确度的调和平均。
本文采用Adagrad优化器,初始学习率为0.001,经过200次迭代后得到实验结果如表3所示。

表3 本文算法实验结果

表4 实验结果对比
本文算法与上述算法比较,在准确率、精确率、召回率、F1得分方面均取得了较好的效果,这也证明了本文基于文本内容特征进行谣言识别的谣言识别模型对谣言识别具有良好的效果。
4 结语
本文首先通过Embedding层将文本向量化并输入到LSTM层,基于文本的内容充分发掘其特征,并利用Softmax分类器进行分类,训练过程中,通过Dropout层避免模型过拟合,利用来自微博的文本数据进行训练。经实验得知,本文算法的准确率为95.3%,谣言和非谣言的精确率为93.3%、96.9%,召回率分别为96.3%、94.5%,F1得分分别为94.8%、95.7%,均取得了不错的效果。
考虑到本文在训练模型时使用的数据量有限,且均来自新浪微博,并且在训练模型时,没有综合考虑到用户相关信息、转发量等相关的统计特征,因此,下一步的工作重点是研究将来自文本内容特征提取与统计特征提取综合,并采用更高质量的数据集训练模型,以加强谣言检测的能力。
