基于元嵌入的跨语言词嵌入方法研究
2021-08-23韩越艾山吾买尔
韩越,艾山·吾买尔
(1.新疆大学信息科学与工程学院,乌鲁木齐830046;2.新疆大学新疆多语种信息技术实验室,乌鲁木齐830046)
0 引言
跨语言词嵌入旨在学习一个共享的语义空间,在机器翻译[1]、文本分类[2]、信息检索[3]中都有重要意义。当前流行的跨语言词嵌入方法是基于单语词嵌入的线性映射[4]。该方法基于大规模单语语料训练单语词嵌入。认为不同语言上训练的单语词嵌入具有相似性,从而可以学习源语言嵌入到目标语言嵌入的映射关系,将两种或多种语言的嵌入映射到同一语义空间。这一思想被后续的很多研究继承和发展。但语言的固有属性致使不同语言家族的语言具有同构性这一假设面临着巨大挑战[5]。同时,低资源场景下训练的单语词嵌入因语料少难以训练充分或语料差异较大[6],难以得到符合同构性假设的单语词嵌入。
在以往基于映射方法的跨语言词嵌入研究中,对于单语词嵌入的训练没有一个统一的约束。但是对于基于映射的方法来说,单语词嵌入是跨语言词嵌入成功的基础。因此,训练高质量的单语词嵌入进行跨语言词嵌入的学习至关重要。
基于以上问题提出:将不同单语词嵌入训练方法得到的词嵌入进行融合得到元嵌入从而提高跨语言词嵌入的质量。该方法背后的假设为:不同的单语词嵌入方法捕获了语言中单词的不同特征,将不同单语词嵌入训练方法训练的嵌入进行融合,可以从更多维度对单词进行描述,从而得到更高质量的词嵌入。该方法操作简单,有效性强并且具有可扩展性,可以随着单语词嵌入模型和跨语言词嵌入模型质量的提高而提高。
1 相关工作
双语词嵌入近些年来被广泛研究。研究方法之间最大的不同在于监督信号的强度。最开始研究者在平行语料[7-9]以及可比语料[10-11]上训练跨语言词嵌入。进一步的,专家们使用了词典资源,利用WordNet[12]、ConceptNet[13]等词典资源。然而在很多语言上平行语料、可比语料难以获得,甚至高质量的词典也无法直接获得,因此研究者们致力于尽可能地减少监督信号。
2013年Mikolov提出基于线性映射的跨语言词嵌入[4]。该方法首先基于单语语料库训练单语词嵌入得到不同语言的词表示,再通过5000个词典对作为监督信号,将不同语言的词嵌入映射到同一语义空间。从而,给定一种语言的单语语料库中的某个单词,可以在映射到的语义空间中得到与该单词意义相同的另一语言的单词。后来的方法大多基于此研究和发展。Xing通过归一化词嵌入以及正交约束来优化这一方法[14]。前面的方法是将一种语言的嵌入空间映射到另一种语言。Faruqui和Dyer通过典型相关分析将两种语言的单语词嵌入空间映射到一个新的空间,从而提高跨语言词嵌入的性能[15]。Artetxe在Mikolov的基础上添加了白化技术,使得性能进一步提升,除此之外,还对先前方法底层的关联做了重新解释[16]。这一系列方法相比使用平行语料、可比语料等资源进行跨语言词嵌入的训练,不仅简单,而且使用较少的监督信号,这在低资源场景下大有裨益。
尽管先前的方法已经有了不错的表现,但是学者们致力于进一步减少监督信号,希望在少量种子词典甚至在没有任何监督信号的情况下训练跨语言词嵌入。Artetxe仅使用25个种子词典对学习映射,使用学习的映射以自学习的方式从单语词嵌入中归纳新的词典,使用新的词典学习新的映射[17]。Conneau仅使用单语词嵌入而无需任何监督信号来学习跨语言词嵌入。通过对抗训练来学习原语言空间到目标语言空间的线性映射,达到了与监督方法相匹敌的效果[18]。
本文提出的方法将目标转移到提高单语词嵌入的质量,通过在不同维度上对不同单语词嵌入模型训练的单语词嵌入进行融合,对单词进行更好的语义表示,从而更好的训练跨语言词嵌入。该方法能够和任何现有的单语词嵌入训练模型和跨语言词嵌入训练模型相结合,并随着它们质量的提高而提高。
2 模型选择与集成
2.1 单语词嵌入模型
当前最流行的两种训练单语词嵌入的模型为Word2Vec[19]和FastText[20]。因此实验中主要采取这两类模型训练单语词嵌入。
Word2Vec是2013年Mikolov年最开始提出来的将单词用分布式向量表示的方法。Word2Vec中包含两种训练模式分别为:CBOW以及Skip-Gram。它们的不同之处在于,CBOW通过上下文单词的词嵌入预测当前词的词嵌入,而Skip-Gram使用当前词的词嵌入预测上下文的词嵌入。使用Word2Vec训练的词嵌入是词级别的。在词典内的单词会被分配一个词嵌入,而词典外的单词的词向量由所有词典内单词向量的平均值表示。
FastText是基于Mikolov提出的词嵌入方法的扩展,通过学习子词信息的向量,将子词的向量表示之和作为单词的词向量。同样的FastText也有CBOW和Skip-Gram两种训练模式。由于FastText训练的词嵌入是通过单词的子词信息而来,因此,即使一个单词未在训练集中出现,但其词向量可以通过训练集中的子词信息而来。相比Word2Vec,它对未见词能有更好的表示。
由于以往的实验中对单语词嵌入的训练模型并没有同一的规定,不同方法间无法直接比较。因此实验中采用了两种词嵌入模型的两种训练模式,除了探讨不同的单语词嵌入方法对跨语言词嵌入的影响,还探讨将同一模型不同模式下训练的词嵌入加以集成以及将不同模型的相同模式加以集成对跨语言词嵌入的影响。
2.2 跨语言词嵌入模型
令X和Z表示给定双语词典的两种语言的词嵌入矩阵,该词嵌入矩阵的第i行Xi*和Zi*是字典中第i个条目的词嵌入。要找到一个线性映射矩阵W,使得XW接近Z,需要将欧几里得距离的平方最小化。即:

这等效于最小化残差矩阵的Frobenius范数:

因此,W将是线性矩阵方程XW=Z的所谓最小二乘解。这在线性代数中是一个著名的问题,可以通过取摩尔彭罗斯伪逆X+=(XTX)-1XT为W=X+Z,而这可以使用SVD进行计算。
实验中所采用的跨语言词嵌入模型为公开软件VecMap[16]。VecMap实现了以上算法,并添加了一些额外的技术,例如正交约束、词嵌入归一化、均值居中、白化等技术,形成一个统一的框架,能够训练鲁棒的跨语言词嵌入。
2.3 多策略元嵌入集成方法
元嵌入是集成了给定语言的多个预训练词嵌入的向量空间表示,这些预训练词嵌入可能使用不同的语料,或者对相同的语料使用不同的模型进行训练[19]。实验中主要对Word2Vec和FastText训练的词嵌入进行集成,集成办法如下:
(1)将Word2Vec的CBOW模式训练的词嵌入以及Word2Vec的Skip-Gram训练的词嵌入加以集成。
(2)将FastText的CBOW模式训练的词嵌入以及FastText的Skip-Gram训练的词嵌入加以集成。
(3)将Word2Vec的CBOW模式训练的词嵌入以及FastText的CBOW模式训练的词嵌入加以集成。
(4)将Word2Vec的Skip-Gram模式训练的词嵌入以及FastText的Skip-Gram模式训练的词嵌入加以集成。
(5)将不同窗口上两个模型上两种模式的词嵌入加以集成。
后续实验中我们将Word2Vec的CBOW训练的单语词嵌入用WC表示,Word2Vec的Skip-Gram训练的单语词嵌入用WS表示。将FastText的CBOW训练的单语词嵌入FC表示,FastText的Skip-Gram训练的单语词嵌入FS表示。
最常见的元嵌入方法是平均Meta-average和拼接Meta-con方法。文中首先探讨了这两种简单的集成方法,其次采用两种额外的对齐策略:先对不同模型训练的同一语言的单语词嵌入利用跨语言的词嵌入方法进行对齐,再将对齐后的词嵌入进行平均和拼接。具体如下:
(1)平均(Meta-average)方法。将不同模型训练的相同单词的词向量对应维度进行相加操作再除以2。
(2)拼接(Meta-con)方法。将不同模型训练的相同单词的词向量进行拼接,此时词嵌入的维度是之前的2倍。
(3)对齐平均(Aligned_average)。将不同模型训练的同一语料库的词嵌入先利用跨语言词嵌入的方法进行对齐,将对齐后的词嵌入进行平均。
(4)对齐拼接(Aligned_con)。将不同模型训练的同一语料库的词嵌入先利用跨语言词嵌入的方法进行对齐,将对齐后的词嵌入进行拼接。
由于不同模型对相同语料训练的词嵌入具有不同的嵌入空间。每个嵌入空间既有区别又有联系,因此利用训练出的词向量单词构建词典,来将使用同一语料训练的不同嵌入空间映射到同一个空间,期望映射后的词嵌入集成可以得到更好的单词表示。
3 实验设计与分析
3.1 实验设置
本实验的实验环境为Python 3.7、PyTorch 1.4。使用的CPU为Intel Xeon CPU E5-2640 v4@2.40GHz。
实验中采用的数据是由新疆大学多语种实验室小组建立的数据集,包括100万句英语数据以及100万句汉语句子。为验证提出的方法在不同数据集大小上的有效性,实验中在20万和100万数据集上分别做了实验。其中,小数据集是大数据的子集。对英语句子使用Moses中的tokenize进行分词,对汉语句子使用结巴分词。利用分好词的文本进行单于词嵌入的训练,采用的模型分别是Word2Vec[19]和FastText[20]。分别使用两种模型的Skip-Gram模式和CBOW模式。词嵌入的大小为300维,窗口的大小为10,训练的迭代次数为15。除非特别指定,后面的实验均采用此默认设置。
3.2 评价指标
实验中使用公开的MUSE[18]词典训练并评估跨语言词嵌入,通过提供的词典对进行跨语言词嵌入的训练。训练好跨语言词嵌入之后,给定MUSE词典的测试集,进行准确性评估。具体实现方式为:给定测试集中的源语言单词,通过训练好的跨语言词嵌入,使用最近邻算法找出距离最近的目标语言单词。查看该单词是否与测试集中的单词一致。
作为跨语言词嵌入的内部评估标准,它的准确率的提升一般主要来源于提高的跨语言词嵌入算法,以及相关检索方法的优化。
3.3 多策略元嵌入集成实验
3.3.1 同一单语词嵌入模型的不同训练模式相集成
为了验证不同语料规模下,相同模型不同训练模式训练的单语词嵌入集成是否会对跨语言词嵌入产生影响。将WS与WC相集成。FS与FC相集成。实验结果如表1所示。

表1 不同训练模式相集成
其中,CORPUS_SIZE表示语料规模,Method表示训练单语词嵌入的方法。Baseline表示不使用任何集成方法时的结果。例如:表中的23.34表示当训练单语词嵌入的方法为基于Word2Vec的Skip-Gram模型时,训练的跨语言词嵌入在词典上的准确率为23.34。Meta-average表示将单语词嵌入进行平均。例如表中的22.42表示将WS和WC训练的单语词嵌入相集成后训练跨语言词嵌入进行评估得到的准确率大小。同样的,Meta-con表示将单语词嵌入进行拼接。前文已加以描述,在此不加以赘述。Aligned-average则表示将训练的单语词嵌入先进行对齐,再进行平均。Aligned-con同理。
对实验结果从不同维度分析可以得到多个结论。首先从baseline上可以看到无论是在20万语料还是100万语料上,总是FS训练的单语词嵌入性能更好,在20万语料上,FS相对于最差的结果高达6.8%。在100万语料上,也能高达6%。这说明,单语词嵌入的质量对跨语言模型的训练至关重要。
其次,采用此种集成方法,简单的进行单语言词嵌入平均会降低跨语言词嵌入的性能。简单的拼接单语词嵌入在FastText模型上能够观察到明显的提升,准确率提高了2.47-5.7。随着语料规模增大,集成方法带来的收益减少。而在Word2Vec上提升不明显,甚至在20万语料上,准确率降低。同时,提出的先对齐再平均、拼接的方法带来了明显的准确率的提升。它的结果始终高于基线,这表明了我们提出的方法的有效性。
3.3.2 不同单语词嵌入模型的相同训练模式相集成
为了研究不同语料规模下,不同模型下相同训练模式训练的单语词嵌入集成会对跨语言词嵌入产生怎样的影响。将WS与FS相集成。WC与FC相集成。实验结果如表2所示。
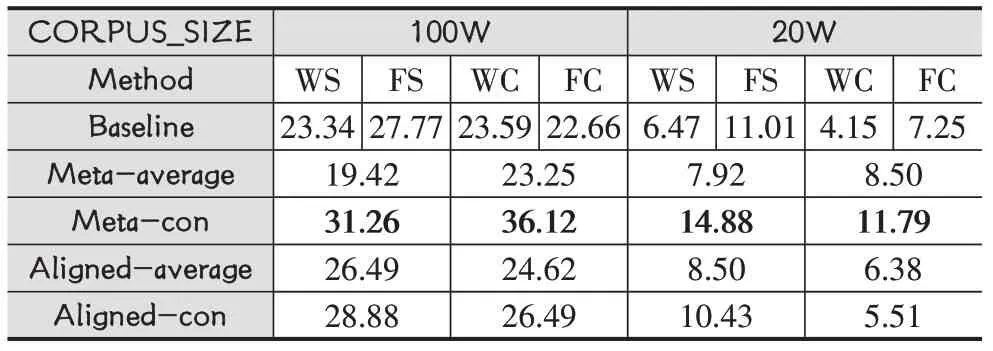
表2 不同模型相集成
通过表2实验结果可以发现:将不同模型下的相同训练模式训练的单语词嵌入进行集成时,简单的平均只在语料大小为20万时,将两个模型的CBOW进行集成时,准确率提高了1.1。其他情况下并没有理想的结果。同时先对齐再进行平均的方法虽然相比简单的平均准确率有所提高,但是相比于没有集成的最好结果并没有很大的竞争性。而先对齐再拼接的集成方法在语料规模较大的100万上观察到了提升,在20万上有所下降。这说明语料规模对这种集成方法较为敏感。令人惊讶的是,直接将不同模型的单语词嵌入进行拼接,反而会有明显的准确率的提高,准确率在20万语料上提高3.87%~4.54%,在100w语料上提高3.49%~12.53%。这一点与先对齐再拼接的集成策略表现一致。因此,可以得出结论,当语料规模增大时,将不同模型上相同训练模式训练的词嵌入进行拼接会有很大收益。
3.3.3 不同窗口上两个模型两种模式相集成
单语词嵌入的空间结构很大程度上依赖单词的共现统计,这是由上下文窗口大小所决定的。不同的上下文窗口大小决定了当前单词捕获的不同特征。当上下文窗口较大时,生成的单词嵌入捕获主题相似性,当上下文窗口较小时,生成的单词捕获共能相似性。因此是否将不同窗口上训练的词嵌入进行集成可以得到更好的单词表示,从而更好地为跨语言词嵌入训练提供帮助是这一集成策略背后的动机。实验结果如表3所示。

表3 不同窗口下的词嵌入集成
其中,W表示上下文窗口的大小。例如:表中的3.86表示当训练单语词嵌入的模型是Word2Vec的Skip-Gram时,设置上下文窗口大小为1。此时训练的单语词嵌入用于训练跨语言词嵌入,在测试词典上得到的准确率是3.86。表中的6.09则表示将窗口大小为1和窗口大小为10时训练的单语词嵌入进行平均后训练跨语言词嵌入进行评估得到的结果。
同样的,该实验在不同语料大小上进行的实验表现出相同的实验结果。即无论是语料大小为20万还是100万,简单的拼接方法总是能带来最大的提升。在20万语料上准确率的提升在1.16-9.57之间,100万语料上准确率的提升在2.73-3.41之间。这与3.3.2中提到的集成策略表现一致。其他的集成方法在大多数情况下能带来竞争性的结果,但这一结果相比简单的拼接稍显逊色。同实验一的相似之处在于,FastText模型相比于Word2Vec模型在跨语言词嵌入任务的学习上显示出了绝对的优势。
3.4 跨语言词嵌入的反向训练
在之前的实验中,跨语言词嵌入的训练及其评估主要包含以下4步:①分别用多个模型训练两种语言的单语词嵌入。②将不同模型下训练的单语词嵌入进行集成。③利用现有跨语言词嵌入工具将集成后的单语词嵌入作为输入,学习源语言到目标语言的映射关系,最终得到同一语义空间中的不同语言的词嵌入表示。④给定源语言单词,根据相关的检索算法,如:最近邻算法、CSLS算法等找到与该单词相同意义的目标单词。然而在实验中发现,在训练时,学习目标语言到源语言的映射关系,但是在归纳双语词典时,给定原语言单词,检索与该单词对应的目标单词会极大程度地提高测试词典的准确率。实验结果如表4所示。

表4 反向训练实验结果
该实验可以直接与3.3.2的实验结果做对比,都是基于不同模型的相同模式进行集成的。首先从不加任何集成方法的baseline就可以看出,在20万语料上,测试词典上的准确率是之前的2倍多。在100万语料上准确率提升了7.67%~15.5%。除此之外,提出的集成策略在此基础上带来了更大的提升。和之前的实验表现基本一致,平均的集成策略似乎并不利于跨语言词嵌入的学习。而拼接方法能够带来更大的收益。这样一来,先将单语词嵌入进行集成,再反向训练跨语言词嵌入,可以在双语词典归纳中得到更好的表现。在该实验中的100万语料上,最高的准确率是基线的2倍,从一开始的27.77到集成、反向训练后的50.51。而在20万的低资源上最高准确率几乎是基线的4倍,从一开始的7.25到现在的27.73。
4 结语
在主流的跨语言词嵌入研究中,单语词嵌入是该类方法的基础,因此,训练高质量的单语词嵌入至关重要。在英汉上的实验首先探讨了不同单语词嵌入模型训练的词嵌入对跨语言词嵌入影响,发现融合了子词信息的FastText模型下的Skip-Gram训练的单语词嵌入更加有益于跨语言词嵌入训练。其次,在不同数据规模上,实验了多种对不同单语词嵌入进行集成得到元嵌入从而进行跨语言词嵌入研究的策略。实验结果表明,无论数据规模有多大,集成办法总是有效的,并且简单的词嵌入拼接方法似乎更加有利于跨语言词嵌入的训练。最后,经验表明,当反向训练的时候,准确率会有极大的提升,这为之后的研究提供了新的思路。该方法极具扩展性,包括:在实践中,可以将更大语料上的词嵌入进行集成,可以将更多样的单语词嵌入模型进行集成。同时,该方法与跨语言词嵌入模型的训练无关,因此,它可以与任何跨语言词嵌入模型相结合。并随着跨语言词嵌入模型算法的改进进一步提高双语词典归纳的准确率。
