基于LED光电池阵列和神经网络的空间定位方法
2021-08-19谭昊炎邵瀚雍刘思胤王爱记白在桥
谭昊炎,邵瀚雍,刘思胤,王爱记,白在桥
(北京师范大学 物理学系, 北京 100875)
在许多实验场合中,经常需要对物体的运动轨迹进行非接触式的实时测量.例如在普通物理实验的单摆实验中,对待测小球的空间位置的测量.目前常用的方法是先拍摄运动视频,然后用软件(如Tracker)进行分析.这种方法虽然直观,但只能在实验结束后处理,难以得到实时的位置信息.另外,如果物体运动速度较快,且测量精度要求在毫米范围,现阶段还未有现成的低成本实验装置可以实现.
本文提出并验证了一种基于发光二极管-光电池阵列与神经网络学习的空间定位方法,以实现在5 ms延迟的响应时间下,高于0.2 mm的空间定位方法,在一定程度上可弥补上述不足.
1 测量原理
力学实验常用到光电门,其依据物体遮光情况探测物体的位置.如果光电门的光源有一定发散角,光探测器的接收面积也比较大,那么就可以根据遮挡光的强度在一定范围内测量物体的位置.
本文的方法推广了这个思路:在探测空间的上方放置m个光源,下方放置n个光探测器(见图1).当第i光源发光时,第j个探测器测量的光强为Ii,j.所有光强数据组成一个m×n维向量,记作
(1)
并称之为一个光强分布.

图1 测量原理示意图(虚线圆圈为待测物体)
显然光强分布是物体位置坐标的函数,以下记为f,即
q=f(p)=f(x,y,z)
(2)
本文希望通过合适的光源和探测器的摆放位置,使得映射f是单射,即不同位置的光强分布不同.从直观上理解,由于mn一般远大于3,同时在光探测器密度足够高而且位置随机分布的情况下,f的单射性是可以满足的.这样就可以根据光强分布反推出物体的位置,即
p=f-1(q)
(3)
换言之,式(2)表示光强分布编码了物体的位置信息,式(3)表示可以用f-1进行解码.
显而易见,这样的逆映射求解是相当复杂的,本文采取神经网络的方法学习并拟合出一个这样的逆映射.首先,采取定标的方式采集某些离散点所对应的信号,并借助这些有限点来刻画整个映射的函数模式.基于足够的信息,有可能揭露映射部分或整个形式,即通过机器学习找到这个映射或者这个映射的近似解.
人工神经网络(Artificial Neural Network)[1]是一类近年非常流行的机器学习模型.神经网络的基本单元是神经元.如同神经细胞一样,神经元接受来自前面的神经元输出的数值(也就是神经末梢的刺激),并将这些数值进行一次简单处理(权重和激活函数),随后将结果作为新的刺激,输出给下一个神经元. 原理如图2所示.

图2 神经网络工作示意图
对于本文的任务,最原始的多层感知器(Multilayer Perceptron,MLP)[2]就可以完成.MLP由多个全连接层构成.第k层的输入为一个dk维向量,表示为
(4)
其中第一层为输入层,即X(1)=q.第k层的输出即为第(k+1)层的输入,函数形式为
不同结晶时间下淀粉球晶热力学性质如表 2所示。由表2可以看出,淀粉球晶的起糊温度(To)、峰值温度(Tp)、终止温度(Tc)和焓值(△H)显著高于原淀粉,与Cai等[16]的研究结果一致;淀粉球晶的起糊温度随结晶时间的增加而升高,结晶24 h后淀粉球晶的起糊温度、峰值温度、终止温度和焓值分别达到75.09 ℃、90.96 ℃、107.03 ℃和17.44 ℃。表明形成的淀粉球晶相对于蜡质玉米淀粉结构较为紧密,在较高温度下才能破坏晶体结构;吸热焓值和淀粉结晶度有一定的对应关系[25],焓值越高,结晶度也相应增加,这和XRD测得结果相吻合,也和Liu等[26]报道的结果一致。
(5)

(6)
神经网络的多层感知器的每一层均有数量若干的神经元,层内的神经元互不影响,层与层之间的神经元相互联系、传递数值,其工作示意图如图3所示.
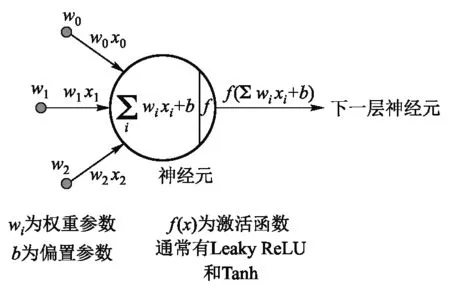
图3 神经元工作示意图
在网络结构确定之后,主要的工作是通过标定的训练数据学习到最佳的网络参数,即各层的权重与偏置系数,使得θi尽量接近pi.方法是先定义网络的损失函数,比如选用计算值与实际值的距离为
(7)
然后采用随机梯度下降法调整参数:
wα→wα-〈〉
(8)
这里wα代表任意的网络参数,〈A〉表示A在一批训练数据(以下简称batch)上的平均值,为学习率[3],是一个小的正数.经过多次的随机梯度下降(伴随学习率逐渐减小),直到在当前网络结构下的最佳效果.如果效果不理想,还可以调整网络结构(比如增加网络层数或者扩展某些层的维数).
2 装置与方法
2.1 装置
实验装置采用了6个强光LED做光源,用16个光电池,每2个一组构成8个光强探测单元.装置实物照片见图4,光电池分布见图5.

1:LED;2:光电池阵列;3:待测小球;4:数据采集卡图4 装置实照

图5 光电池的分布模式
2.2 信号获得

用数据采集卡采集8组光电池的信号(采样率为40 kHz,波形图参见图6),编程从中提取每个光电池组在不同LED照明下的平均光强以及背景平均光强.用存在LED照明下的光强减去背景光强,从而消除背景光的影响.为了消除LED发光强度漂移的影响,把同一LED照明对应的光强归一化,最终得到有7×6=42个独立分量的光强分布信号.

图6 LabVIEW采集界面,实际颜色是不同的
2.3 数据定标
选取了一个40 mm×40 mm×10 mm 的方形测量区域,水平方向的移动步长为1 mm,垂直方向移动步长为5 mm,得到41×41×3个位置上的光强分布.采样点把空间分为40×40×2个网格.如图7所示. 定标数据在后续的实验中有2个作用:一是以此为基础生成训练数据,二是作为测试集检验模型的训练效果.
图7 测量网络点示意
2.4 神经网络训练
用LabVIEW编写了一个简单MLP学习项目.相比通用的机器网络学习平台(如TensorFlow,PyTorch等),LabVIEW在功能与效率上均不占优.但由于本文的问题规模很小,LabVIEW程序更容易与数据采集结合,便于后期将网络整合进测量程序.此外,LabVIEW的图形界面也方便监视网络训练进展.
为获得训练数据,先在测量区域随机产生给定数目的位置.对于每个位置,找到包围它的网格,对该网格的8个顶点的光强分布进行线性插值,得到这个点的光强分布.此外,由于测量数据有噪声,为了避免过拟合,计算的光强也要加入一定强度的随机噪声.如此生成一个batch的训练数据.当一个batch训练一定次数之后,就重新生成一个batch的数据继续训练.
除了上述数据增强技术,本文还考虑了网络参数正则化(regularization):为了让模型尽量简单,在Loss中引入惩罚项:
(9)
其中λ为正数,其值越大,训练结果越倾向于简单(权重更稀疏)的模型,希望通过这些措施,使得网络学习的光强分布-空间位置函数对噪声不敏感,具有更好的稳定性.
3 实验结果
3.1 训练过程
经过多次测试,本文选择了一个4层网络,每层分别有42、100、50和3个神经元,并且使用ReLU作为非线性激活函数.
下面展示训练过程.为直观评估训练的效果,在不同阶段计算41×41×3个定标数据对应的坐标,画出它们在x-y平面的投影.机器每次会拟合4800个点,用黑点表示.其距离格点越近,分布越均匀,代表拟合效果越好,误差越小.
在图8中绘出了4个阶段的训练效果.图中格点表示真实值,黑点表示计算值.一开始,由于网络参数是随机赋值的,计算结果分布在很小的区域.随着训练次数的增加,计算值逐渐扩展开来,越来越接近实际的网格.
在图9中绘出了最终的结果,此时计算值构成基本均匀分布的网格,与实际值的平均误差小于0.2个网格宽度,意味着对应水平方向的定位误差小于0.2 mm.且误差超过0.5的点不多于40个,这意味着拟合较差的区域部分少于4%.

图8 不同训练阶段的训练效果

图9 最终训练效果,此时已经分布的相当均匀
3.2 使用效果
将最终训练所得的网络与数据采集系统整合为一个LabVIEW程序.该程序可以实现每秒测量200次小球的坐标,实现小球的运动轨迹的实时记录和反馈.
图10给出了一段小球做单摆运动的图像,z轴位置变化小,仅考虑xy水平运动.由于单点测量噪声比较大,测量结果做了一定的平滑化处理.图中可以看出小球的椭圆形轨迹.

图10 实际测量效果,横纵坐标为毫米
从图10中可以看到,测量得到的轨迹在右上和左下方存在一定的缺陷,推测是由于光电池摆放不够合理,在这附近未能收集到具有较大差异的数据,导致学习、测量的效果不够理想.
4 结论
本文利用一个6×8的光源-探测器阵列和人工神经网络,在40 mm×40 mm×10 mm的区域内,实现了采样率为200 Sample/s,水平位置平均测量误差小于0.2 mm的空间定位方法.本文还可以优化光源和探测器的分布,适当增加光源和探测器的数量,优化神经网络模型等以提高精度. 此方法原理简单,装置易于搭建,性能有较大的提升空间.
此方法具有较广的应用场景:学生实验、科研工作以及工业生产中涉及小范围、高精度、实时性等空间测量时均可以采用此方法.
