面向本地和外地用户情感分析推荐模型
2021-08-19魏宁袁方刘宇
魏宁,袁方,2,刘宇
(1.河北大学 数学与信息科学学院,河北 保定 071002;2.河北大学 计算机教学部,河北 保定 071002)
随着移动终端在社会中的广泛使用,使得用户信息的获取更加容易.通过机器学习的一些算法分析用户的个人信息,可以精确地得到用户的个人偏好.当前一些主流的兴趣点推荐主要以饭馆、人文景点推荐以及其他的各类地点推荐为主.在兴趣点推荐中可以把社会因素、地理因素、文本内容信息和时间因素融入到模型中.龚卫华等[1]提出了一种融合用户与位置实体及其多维关系的社区发现方法(multi-relational nonnegative matrixfactorization,MRNMF).任星怡等[2]提出一种GTSCP(geography,time,society,content and popularity,地理、时间、社会、内容和流行度)联合概率模型来实现了对于本地和外地用户的兴趣点推荐.在饭馆的推荐领域中,胡川等[3]把推荐融合与模型融合结合到一起,给出一个组推荐的方法.Wang等[4]给出了ST-SAGE推荐模型,通过分析同区域中每个用户的偏好,进而找出相同偏好的用户,从而给用户进行推荐生成最终的推荐结果.Li等[5]主要解决推荐系统中的冷启动问题,通过用户的历史记录、地理位置和社交网络信息定义了3类好友,进而定义3种签到方式,通过矩阵分解的方式融合了3类签到方式以解决冷启动问题.Wang等[6]主要考虑兴趣点的所有评论信息的整体情感倾向,提出了LSARS推荐模型,实现了本地和外地用户的推荐,没有把时间因素对于情感的影响考虑进去.Gao等[7]把用户的每条评论的情感作为主要的因素来研究,但是缺少了对于整体情感的考虑.
本文提出了基于地理标签和用户评论情感分析的兴趣点推荐模型(point-of-interest recommendation model based on geographical position and sentiment analysis of user reviews,GTSA),包括了一种基于地理位置信息的隐含概率模型框架STRM(simple topic region model).该模型将兴趣点划分到所属的区域中并且确定用户是不是属于本地用户,从而能够实现本地和外地推荐.考虑到兴趣点描述信息的单一,通过对该信息的扩充来实现兴趣点之间相似性的衡量.通过分析评论数据,挖掘兴趣点的累计评论的情感走向,提出一种对于无标签评论数据情感挖掘的方法,进而实现情感分析.在推荐列表阶段,提出了本地用户的排序方式和外地用户的排序方式.实验是在Yelp和Foursquare 2个数据集上进行,通过实验数据验证 GTSA 模型在其推荐的准确率上有较明显的提高.
1 GTSA推荐模型
用户签到某一个兴趣点时往往会受到以往用户态度的影响,以往用户的评论信息的情感决定着当前用户的抉择,即使该兴趣点符合用户的兴趣,但由于消极评论过多会使得用户更加慎重的选择.每一个兴趣点的群体情绪可以通过历史的评论信息的情感来获得.GTSA模型框架如图1所示.

图1 GTSA模型框架Fig.1 GTSA model framework
1.1 简易主题地区模型
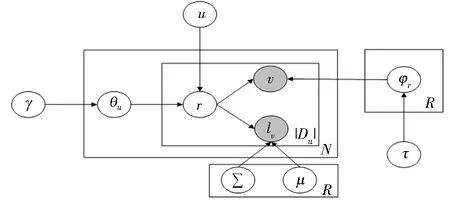
图2 STRM模型Fig.2 STRM model
GTSA模型中的地区划分采用了简易主题地区模型(simple topic-region-model,STRM)[6].该模型将用户的历史签到信息、兴趣点的位置信息相融合,如图2所示.用户在现实世界中的访问方式与网络中的访问方式不同.网络中的访问方式不受地理区域的限制.现实中由于受到距离的限制,用户一般只访问距离相对比较近的兴趣点,不会考虑远的兴趣点.通过用户的轨迹信息看出用户的活动范围比较固定且集中.用户在不同的区域中会访问不同类型的兴趣点,这就表现出每个区域也带有自己的特点.进而体现出用户在访问本地和外地兴趣点时其兴趣的变化.所以,利用该模型实现区域的划分并将每个兴趣点划分到所属的区域中.将地理空间划分成R个区域,并通过模型将每个兴趣点划分到所属的区域中.该模型的采样方式是Gibbs采样,通过多次的迭代计算最终完成区域的划分.
在现实世界中,用户的访问是随机的且多样的.划分出R个区域,多项分布θu来表示用户u在R个区域中的分布,即表示用户访问每个区域的概率.使用高斯分布表示每个区域r.
根据公式(1)对地区r进行采样
(1)
其中,nu,r表示用户u在区域r中签到的次数r,nr,v表示区域r生成兴趣点v的次数,p(lv|μr,∑r)是高斯分布函数.经过迭代训练最终确定每个兴趣点属于每个地区r的概率,将兴趣点划分到概率最大的区域.
对于以上模型,用lq表示用户的当前位置,lu表示用户家乡所在的位置,当|lq-lu|大于100 km表示用户当前处于外地地区,小于100 km时表示用户在家乡即本地.根据公式(2)得到用户签到区域r的概率.
(2)
隐藏变量区域r的先验概率通过公式(3)
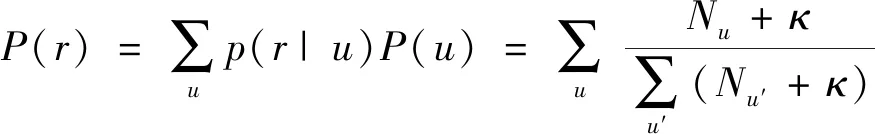
(3)
在公式(3)中,Nu为用户u访问兴趣点的个数.参数k为伪计数,其目的是防止模型过拟合.
1.2 用户评论的情感分析
用户的评论数据对于挖掘用户的潜在兴趣有着非常重要的作用.当用户有访问兴趣点的想法时,通常会浏览该兴趣点评论信息.对于那些自己感兴趣的兴趣点,其中评论数量多且好评占比大的兴趣点用户通常会有很高的概率去选择.由于实验中使用的是真实数据集,数据集中的评论是没有情感标签的,所以如何挖掘每条评论的情感是必须要解决的问题.因而提出基于Doc2vec和RNN的情感分析方法:
1)使用python的集成库TextBlob对除去训练数据和测试数据的其他数据添加情感标签.
2)训练Doc2vec词袋模型,将所有评论数据中的每一个词表示成向量.
3)对于每一条评论进行关键字的提取,使得提取出的词最能表征该条评论.
4)上述过程处理过后,将非实验用的数据用于RNN的训练,再将其结果输入神经网络中.将训练好的模型用于实验数据的情感识别,得到每条评论的情感值.
本文中兴趣点的相似度使用余弦公式来衡量.
1.3 兴趣点的排序方式
1.3.1 本地排序方法
对于本地用户,往往会更加倾向于与自己历史记录相似的兴趣点.因此用户会更多的以兴趣点的评论信息作为参考依据.那些评论数量多且好评占比大的兴趣点是用户选择的重点.一些发表时间长的评论信息其参考意义会随着时间的推移变小,越新的评论其参考价值会更大.因此可以看出时间因素对于每一条评论的情感的影响,进而影响到整体的情感偏向.不难看出,其中还会存在同一个兴趣点会相似于用户的多个签到记录,这说明该兴趣点与用户的偏好十分相近.综上所述,提出兴趣点的选择度的计算公式(4).
(4)
Si表示兴趣点i的得分,即用户对兴趣点i的选择度.C表示兴趣点i的所有评论,c表示C中的第c条评论,Rc(i)表示兴趣点i的第c个评论的情感值(该值介于[-1,1]之间).Timecur表示当前时间,TimeRc(i)表示该评论的发表时间.Sim(i)表示兴趣点之间的相似度.listu表示排序前的推荐列表.
1.3.2 外地排序方法
用户出于各种原因来到外地,对于多数人,脑中的第一想法就是当地的特色是什么.特色包含来了美食、特产以及当地的人文景观等.本文把特色定义为热度,即在当地很火热,火热在数据中表现为评论多即访问量大且评论正向.
通过上面的描述定义了热度的计算公式(5).
(5)
Sigmoid(C)表示对评论个数的归一化,剩余部分和公式(4)相似.
旅行到外地,尽管主要的目的是体会当地的风土人情,但不排除一些用户会选择一些与家乡相似的兴趣点.因此以用户签到记录为依据的推荐方式也很重要.若当地特色的兴趣点与用户的潜在兴趣相似,则表明该兴趣点更加符合用户的选择.所以该兴趣点会有选择度和热度2个值,因此将二者相加(即公式(4)和(5)求和).在外地的推荐列表中其兴趣点的种类会更加多样化,因为它包含了特色兴趣点以及与用户潜在兴趣相似的兴趣点.
对 GTSA 模型总结描述如下:
1)STRM 依据用户的历史记录将每一个兴趣点划分到所属的地区中.
2)依据用户的当前位置信息确定用户属于本地用户或者是外地用户.
3)若为本地用户,基于用户的历史信息推荐与历史记录相似的兴趣点.利用公式(4)对推荐列表中的兴趣点进行排序,最终得到本地推荐结果.
4)若为外地用户,除依靠3)中的本地推荐方式外,利用公式(5)对外地地区兴趣点热度进行排序并与本地推荐相结合,最终得到外地推荐结果.
2 实验分析
2.1 模型数据集介绍
本文的实验是在2个真实的数据集Yelp和Foursquare上进行的,如表1所示.

表1 Yelp和Foursquare的基本统计信息Tab.1 Basic statistics of Yelp and Foursquare
在Yelp数据集中,包含了9 704个用户,每个用户的签到信息包括用户标识、兴趣点标识、兴趣点位置信息、兴趣点描述信息、兴趣点评论信息以及签到的时间.选取了4个城市的16 853个兴趣点.
在Foursquare数据集中,包含了16 426个用户,每个用户的签到信息包括用户标识、兴趣点标识、兴趣点位置、兴趣点描述信息、兴趣点评论信息以及签到的时间.
2.2 比较算法与分析方式
GTSA模型与CKNN 算法[8]、UPS-CF 算法[9]、CAPRF 算法[7]、LCA-LDA算法[10]、JIM 算法[11]和LSARS算法[6]相比较.
通过文献[11-13]中给出的计算方法来对模型进行评估.当某个兴趣点v,出现在Top-k中,则表示其中一个样本命中,记为1,否则就记为0.
对于所有的测试样本用公式(6)来定义.
(6)
其中#hit@k表示测试样本中满足hit@k的数目,|Dtest|表示测试样本的数目.
2.3 实验结果
该部分主要展示GTSA模型与其他模型比较的结果.图3和图4分别展示了各个模型在Yelp和Foursquare数据集上本地和外地推荐的性能.各个模型在Top-k上推荐性能有明显的区别.本文将k的值设置为1、5、10、15、20.对于经典的Top-k推案方法,过大的k值意义不大,因此会被忽略掉.
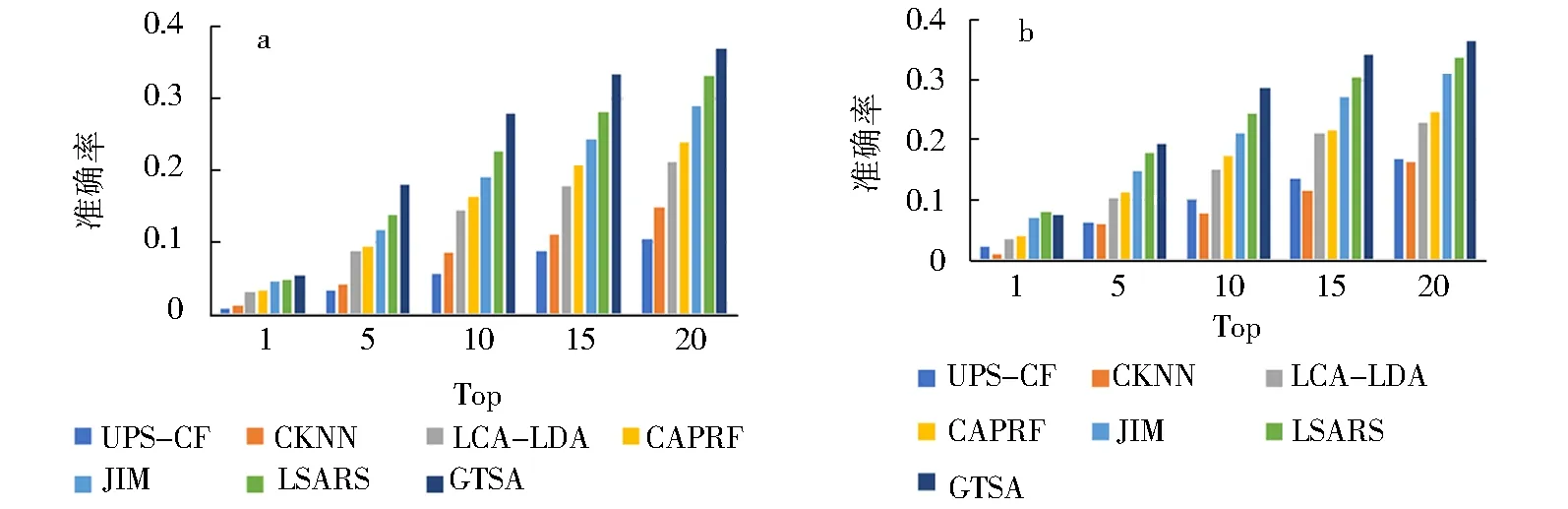
a.home-town;b.out-of-town.图3 在Yelp上的推荐结果Fig.3 Recommendations on Yelp
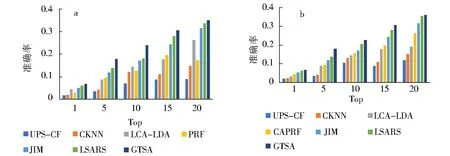
a.home-town;b.out-of-town.图4 在Foursquare上的推荐结果Fig.4 Recommendations on Foursquare
基于图3、图4的数据,可以直观的看出,GTSA模型均优于JIM、CAPRF、LCA-LDA、CKNN、UPS-CF 和 LSARS.进一步分析可以得出:1)由于UPS-CF 和CKNN是基于协同过滤的方法,受数据稀疏的影响较大,因此与JIM、LSARS、LCA-LDA和 GTSA这些基于内容的方法相比其效果较差,这说明兴趣点内容描述文本信息有效地缓解了数据稀疏所带来的问题;2)由于JIM、LSARS和GTSA模型中加入地理位置的原因,其表现效果优于LCA-LDA;3)GTSA 和 LSARS将兴趣点评论的整体情感加入到模型中,其本地和外地推荐精度优于CAPRF,这表明单个情感对于推荐效果的影响弱于整体情感;4)GTSA模型将时间因素对于情感变化的影响加入到模型中,其在本地和外地推荐中优与LSARS.
2.4 参数的影响
GTSA模型同样受到参数的影响,参数的适当调整以获得最佳性能是至关重要的.在GTSA模型中,区域划分的多少直接影响到最终的推荐精度.而区域的划分是由STRM模型来实现,因此通过调整 STRM 模型中的参数R,来分析不同的参数R对于 GTSA 模型推荐结果的影响.
在STRM模块中,对于超参数γ、τ而言,它们与其他的参数是相互独立,没有关系的,因此将超参数设置为固定的值γ=50/R,τ=0.01.在STRM中划分区域的个数会影响到其推荐的精度,即模型对R的个数很敏感.通过图5和图6来展示不同的R对模型推荐精度的影响.
通过图5和图6可以看出,区域数目的增加使得推荐精度先上升再降低.不仅在Yelp数据集上有这样的结果,在Foursquare数据集上也有类似的结果.因而将R设置为数值15最适合.这表明R代表了模型的复杂程度,R越大其复杂程度越高,其模型的拟合度会越好.但当R超过一定的阈值后就出现了过拟合的情况,对于模型产生了不好的影响.同样R的值越大其训练的时间成本也会越高,所以最终选择R的值为15.

图5 本地推荐准确率Fig.5 Home-town recommended accuracy
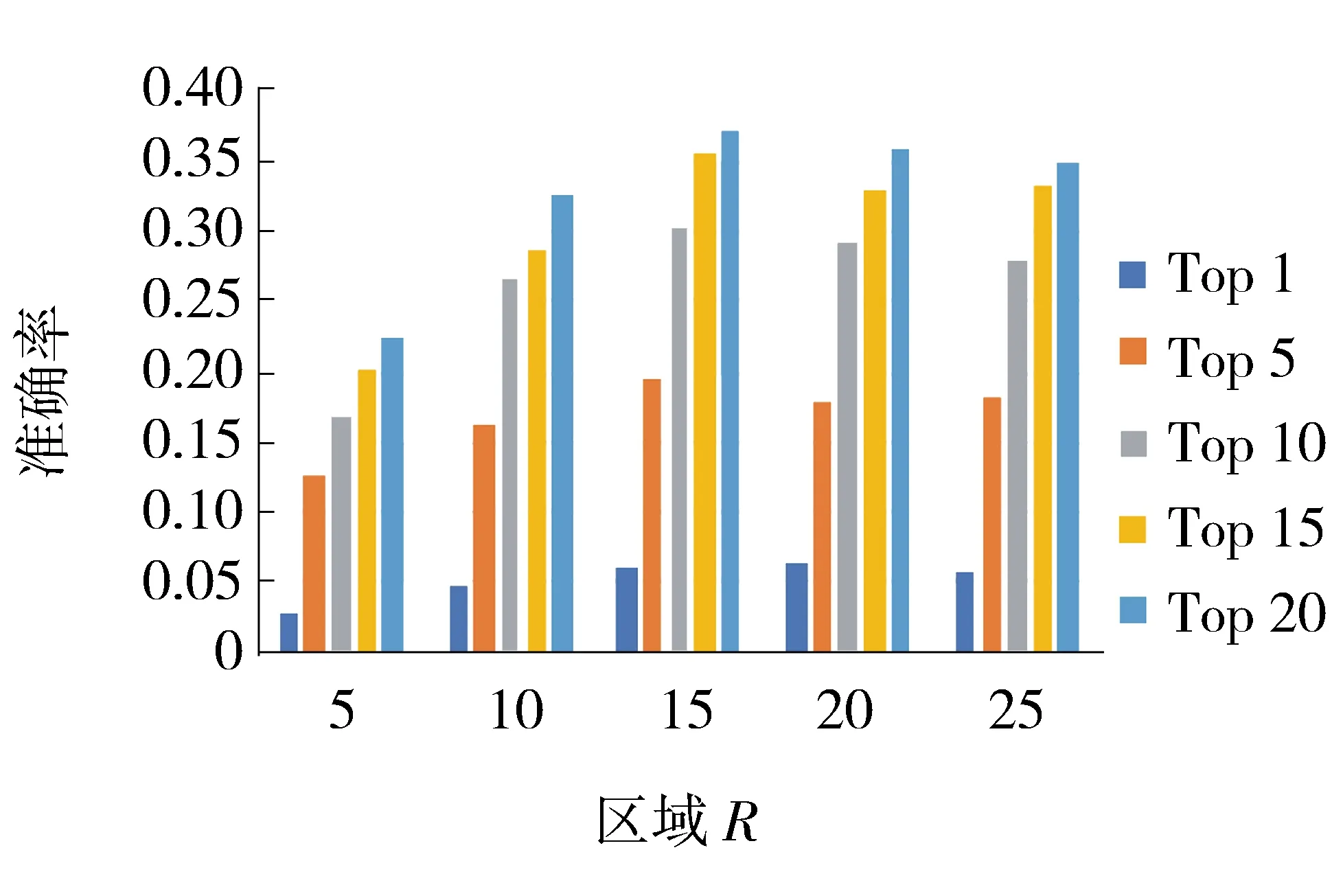
图6 外地推荐准确率Fig.6 Out-of-town recommended accuracy
3 结束语
本文提出了GTSA推荐模型,采用了一种基于地理位置信息的隐含概率模型框架STRM,兴趣点的内容相似度的计算,无标签的评论数据的情感分析的方法,基于本地推荐和外地推荐的兴趣点的排序方法.GTSA模型与其他经典模型相比在精度上有明显提高.当前,推荐系统不能够及时捕捉用户兴趣的实时变化情况.今后从此问题入手,及时捕捉用户兴趣的迁移,并将当前社会的主流因素融入到推荐方法中.同样,冷启动一直以来是推荐系统最大的问题,今后也可以将工作重心放到这方面来.
