基于改进LDA主题模型的个性化新闻推荐算法
2021-08-12丁正祁彭余辉孙刚
丁正祁 彭余辉 孙刚


摘 要:结合用户兴趣与新闻时效性的特点,对传统推荐算法和标准LDA主题模型进行思考,提出一种基于LDA(Latent Dirichlet Allocation)的文档-主题-词的三层贝叶斯概率模型结合时间函数的推荐算法,采用Gibbs Sampling进行超参数推导,提升推荐效果。实验结果表明,该算法在适当参数设定下的推荐结果比协同过滤及标准的基于改进LDA模型的算法有更小的预测误差,向用户推荐偏好新闻更有效率。
关键词:LDA主题模型;贝叶斯模型;推荐算法;时间函数
中图分类号:TP391;O212.8 文献标识码:A 文章編号:1673-260X(2021)06-0028-05
在网络迅速发展的今天,随着各种新闻网站的出现,报纸等纸质新闻已经逐渐离开人们的视线,给人们带来了极大的方便,人们能够通过网络来了解自己所偏好的新闻信息,但随着新闻信息井喷式的增加与高速的更新效率,海量的信息带来了大量的无用新闻以及重复新闻,甚至无法使今日新闻及时准确地推荐给用户,导致用户的需求无法及时满足,失去用户对新闻网站的友好度[1]。但随着推荐系统的使用与普及,各大新闻网站通过适当的推荐算法对用户的偏好、浏览记录、点击率等信息进行分析整合,通过预测用户的兴趣计算出相应的推荐列表,将靠前的新闻信息推荐给用户。
当前在新闻推荐中主流的推荐算法包括基于内容的推荐和协同过滤推荐算法。基于内容的推荐算法是通过对用户浏览新闻历史进行提取关键词,进行统计整合,判断用户对新闻类别的偏好,再将与用户偏好新闻信息内容相似的新闻推荐给该用户,并且无冷启动问题。基于用户的协同过滤推荐是通过获取不同用户的浏览记录来找到和目标用户相似的用户集合,并通过相似计算将用户集合中的偏好新闻相似的但目标用户未浏览过的新闻推荐给目标新闻。
1 相关文献概述
随着国内外学者对推荐算法的深入研究,越来越多的因素被考虑进推荐算法中,使推荐算法越来越复杂,准确率也越来越高。在关于新闻信息方面的推荐,随着对推荐算法的不断研究和探讨,其推荐效率也在逐渐提高。通过对用户的喜好和需求来进行推荐新闻内容,将有可能是用户偏好的新闻列表推荐给用户,解决了用户盲目寻找的问题[2],但推荐效率和准确率仍有待提高。一种对推荐列表进行增量更新并融合潜在语义分析的方法来将新闻文章的相关性保持正相关,解决了用户偏好的不确定性问题,但存在语义分歧的状况[3]。根据社交和时间因素提出了一种融合社交网络和时间函数的主题模型[4],更多地考虑用户特征来增加推荐效率,但却忽略了内容本身。使用LDA聚类的方法对数据进行主题簇的划分,快速给出合理的推荐列表[5]。在LDA模型基础上加入了对用户行为的分析来提高推荐的有效性和实时性[6]。为解决数据稀疏性,通过评分信息和每个时间段的访问量来构建LDA模型,从召回率、F1值等方面进行了充分地优化[7]。Basilico J等[8-10]也充分说明了时间在推荐算法中的重要性。同样为了防止出现词义的混淆、模糊提出了将文本交互信息作为数据基础源来提高推荐准确率的TIN-LDA模型[11]。通过设置用户排序主题模型来反映文档主题的重要性,进而提高用户对推荐算法的满意度[12]。通过构建LDA模型来发现用户对与部分主题的偏好及兴趣分布,极大地满足了用户对推荐算法的需求[13]。通过LDA结合多标记源分类器得到性能更高的主题模型,并利用主动学习思想来提高推荐的准确度[14]。
基于以上主题模型的研究,通过分析新闻信息的更新速度以及时效性,本文通过构造改进的LDA主题模型(NR_TLDA)来进行推荐,将用户浏览过的新闻文本信息转化成容易建模的数字信息,通过新闻主题分布及关键词分布来判断用户的兴趣偏好,并结合时间衰减函数缓解因时间跨度较大带来的兴趣迁移的影响,将更准确地推荐列表推荐给目标用户,减少预测误差。
2 NR_TLDA推荐算法
通过分析用户浏览的新闻文本信息及其时效性特点,本文在LDA模型提取新闻主题的同时考虑到新闻发表时间,在建模过程中,对距离当前时间更近的关键词给予更大的时间权重,通过对时间的限制来优化用户偏好主题模型,如图1所示。
2.1 LDA主题模型
LDA模型于2003年由Blei等人提出,是包含document-topic-word的无监督贝叶斯概率模型[15],训练集不需要手工标注。该模型也是典型的词袋模型[16],认为document由互不关联且无先后顺序的词汇组成,根据词在文中的概率分布来反映document中的主题分布信息,相对于提取关键词技术[17],LDA模型更注重语义信息,通过对文档进行建模,挖掘出文档集中潜在的主题信息。
LDA三层贝叶斯模型如图2所示。其中?琢→?酌m→Zm,n组成Dirichlet-multi共轭,表示从先验Dirichlet分布?琢中取样生成文档m的主题分布?酌m,再从?酌m中取样生成文档m中第n个词的doc-word分布Zm,n;
?茁→?啄k→Wm,n组成Dirichlet-multi共轭,表示从先验Dirichlet分布?茁中取样生成topic-word分布?啄k,再从?啄k中采样生成词Wm,n。
doc-topic分布和topic-word分布是相互独立的,这是因为主题产生词时不依赖任何文档。
根据LDA原理及贝叶斯公式可得:
其中p(w|m)表示文档m中单词n的分布概率, p(w|Zk)表示第k个主题Z中单词w的分布概率,p(Zk|m)表示文档m中第k个主题的分布概率。
Gibbs采样是当前LDA模型中主流的采样方法,适用于长文本信息例如新闻,通过多次迭代得出doc-topic分布矩阵?酌m和topic-word分布矩阵?啄k,其估算公式如下:
。
Gibbs Sampling是MCMC(马尔科夫链蒙特卡洛)算法的一种,其在LDA模型中的物理意义是在k条doc-topic-word路径中进行采样,路径图如图3所示。通过迭代收敛即可得到所有word的主题z,然后统计topic-word关系矩阵,即可得到LDA模型。为了得到质量更好的主题模型,本文取Gibbs采样后的所有结果取平均值来做参数估计。
2.2 构造结合时间因子的用户权重矩阵
统计每个用户中由LDA模型中得出的预测值大于0.4的主题个数,构造user-topic矩阵,用户在具体某一时间段的偏好被认为是相對固定的,当其对新闻信息进行浏览或评论时具有时间属性,用户对同一类型新闻的浏览时间越接近,说明其在此时间段的兴趣偏好越相似,由此可以加入时间因子来计算用户偏好矩阵。
时间衰减因子函数常用指数衰减函数,其时间因子权重公式:
tu,i=exp{-?子(tn-thu,i)} (4)
其中tu,i表示时间权重,tn表示当前时间点,thu,i表示用户u浏览新闻i的时间点,?子表示权重参数。
在计算相似度的过程中,用户对某类新闻主题的评分用该类新闻主题的个数来代替,在这里使用Pearson系数来计算相似度,可得结合时间因子的用户相似度为:
其中sim(u,v)指用户u和v间考虑时间因子后的相似度,tui指用户u浏览某类新闻i的时间权重,rui指用户浏览某类新闻的次数(以下均以评分对待)。
根据sim(u,v)值按照顺序排列选出用户的最近邻,然后使用平均偏差法对相应新闻进行预测评分,公式为:
其中qui表示用户u对新闻i的预测评分,N(u)k表示与用户u相似度最大的前k个用户,ru表示用户已有评分的平均值,rvi指用户v对新闻i的评分,由此可得user-topic的偏好矩阵。
2.3 通过对user-topic矩阵加权处理产生推荐
根据上式得到的预测值进行排序,取排在前N名的新闻推荐给用户,针对推荐过程中的新用户问题,对其推荐热门物品来解决冷启动问题。
2.4 NR_TLDA推荐算法描述
算法:基于改进LDA主题模型的个性化新闻推荐算法;输入:分词后的新闻信息文本集、主题数K、超参数?琢和?茁;输出:doc-topic概率分布?酌、topic-word分布?啄、目标用户对新闻信息的预测评分pre。
步骤1 对爬取的新闻信息文本集D进行数据预处理,通过LDA模型进行建模处理,生成doc-topic和topic-word分布。
步骤2 通过Gibbs采样得到最终收敛的?啄,?酌参数估计值(采样结果取平均值),得到标准LDA模型。
步骤3 将预处理后的用户新闻信息浏览记录集d导入LDA模型,生成user-topic概率模型,每当用户浏览一条新闻信息文本,该概率模型会更新一次。
步骤4 根据步骤3中得到的主题模型,统计pre>0.4的主题数目,得到user-topic列表。
步骤5 加入时间权重tu,i,通过Pearson系数进行相似度计算,得到user-topic矩阵。
步骤6 将步骤3和步骤5中的用户偏好矩阵进行加权处理,得到最终的偏好矩阵(即输出目标用户对新闻信息的预测评分pre),将生成的Top-N列表推荐给用户,并将用户所浏览的记录加入用户新闻信息浏览记录集d中。
3 实验结果与分析
3.1 实验设置
本实验数据集是通过Google浏览器及python爬虫爬取今日头条新闻网站50,000多条各类新闻信息及50名用户的新闻浏览记录信息9,000余条。为了确保推荐的有效性,将浏览记录数低于20条新闻信息的用户过滤。
本文实验环境为Windows10操作系统,Pycharm,Seleuimn,Python。
本文中LDA建模过程中,根据经验所得,设置超参数?琢=0.1,?茁=0.01,Gibbs采样迭代次数为2000,设置N为10。
3.2 数据预处理
在进行实验之前,为了保证数据的可塑性,需要对原始数据进行预处理,通过去噪、处理缺失值、文本合并、分词、去停用词。选取用户浏览记录集中80%作为训练集,另外20%作为测试集。
3.3 实验评估指标
通过阅读文献,Herlocker等人对推荐算法中的衡量标准进行了详细的讲解,为了使模型的效果能更好地展现出来,本文采用准确率(Precision)、召回率(Recall)、F-Measure(F1)作为衡量NR_TLDA推荐算法效果的标准[18]。
Precision是指命中的新闻信息数目占推荐新闻总数的比例,其公式为:
其中|hitsu|指在推荐的新闻列表中,用户u所浏览过的新闻数目,|recsetu|指推荐给用户u的新闻列表集合的总数目。
Recall是指命中新闻信息数目占理论上最大命中数量的比例,其公式为:
其中|testsetu|指用户u理论上应该推荐相关新闻数目的最大值。
为了观察Precision和Recall之间的权衡变化,需要增加推荐集合的规模,命中相关新闻信息的机会就会增加,Recall就会增加,而Precision则会降低。为了有效地平衡Precision和Recall,使用F1衡量标准,其公式为:
F1值随着Precision和Recall的变化而变化,并且当F1值较高时,模型效果更好。
3.4 实验对比分析
根据当前的研究成果和大量文献表明,在推荐算法领域应用LDA主题模型的准确性要比协同过滤算法高,同时时间因素也是增加准确性的因素之一。因此,本文所提出的算法NR_TLDA将与基于标准的LDA主题模型推荐算法、本文算法中未增加时间因素的NR_LDA算法及协同过滤(CF)推荐算法进行比较。
3.4.1 LDA主题模型潜在主题个数K的确定
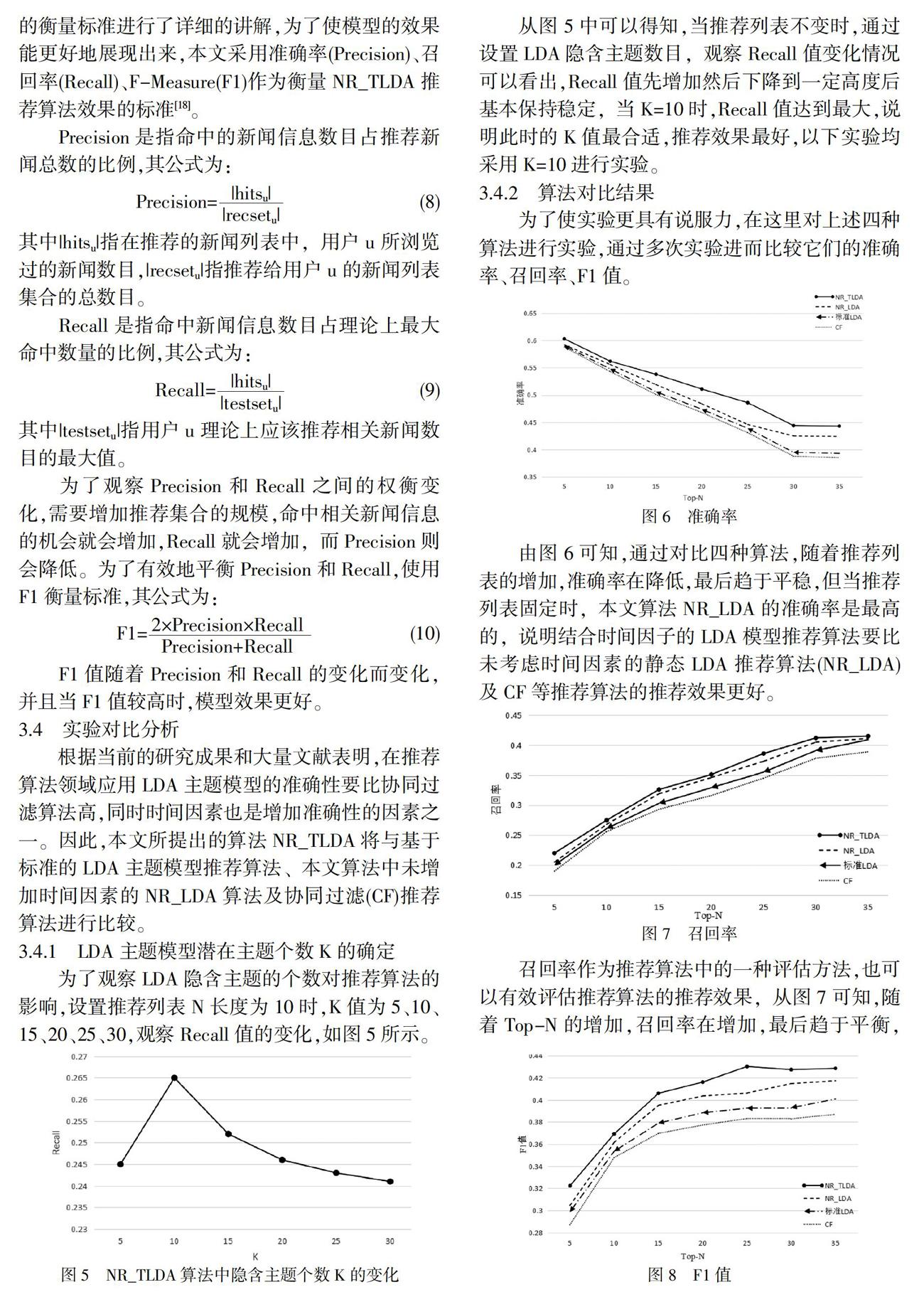
为了观察LDA隐含主题的个数对推荐算法的影响,设置推荐列表N长度为10时,K值为5、10、15、20、25、30,观察Recall值的变化,如图5所示。
从图5中可以得知,当推荐列表不变时,通过设置LDA隐含主题数目,观察Recall值变化情况可以看出,Recall值先增加然后下降到一定高度后基本保持稳定,当K=10时,Recall值达到最大,说明此时的K值最合适,推荐效果最好,以下实验均采用K=10进行实验。
3.4.2 算法对比结果
为了使实验更具有说服力,在这里对上述四种算法进行实验,通过多次实验进而比较它们的准确率、召回率、F1值。
由图6可知,通过对比四种算法,随着推荐列表的增加,准确率在降低,最后趋于平稳,但当推荐列表固定时,本文算法NR_LDA的准确率是最高的,说明结合时间因子的LDA模型推荐算法要比未考虑时间因素的静态LDA推荐算法(NR_LDA)及CF等推荐算法的推荐效果更好。
召回率作为推荐算法中的一种评估方法,也可以有效评估推荐算法的推荐效果,从图7可知,随着Top-N的增加,召回率在增加,最后趋于平衡,本文算法NR_TLDA算法在固定推荐列表下召回率高于其他三种推荐算法,说明NR_TLDA推荐算法的效果更好。
为了平衡准确率和召回率,使用F1值来作为评估指标,由图8可知,随着Top-N的增加,F1值在增加,最后趋于平稳,而在四种算法中,NR_TLDA算法的F1值要高于其他算法,即NR_TLDA算法的推薦效果由于其他算法。
由表1可知,本文算法在离线阶段进行矩阵处理的时长要比其他算法多,但在线阶段所需时间较少,说明该算法在本数据集中有较好的推荐体验。
4 实验总结
在NR_TLDA算法中,将新闻文本、新闻主题、词作为三层贝叶斯结构来进行建模,通过统计主题数目来解决用户对每一类新闻的评分问题,再结合时间因子来完善用户对新闻信息的偏好程度,再根据实验过程中用户每一次浏览的新闻记录对LDA模型进行完善,并将两user-topic矩阵进行加权融合,形成最终的偏好矩阵。在此次设计与实验过程中,用户的阅读兴趣会随着时间的变化而影响推荐质量,时间因子很好地缓解了这种问题。
下一步可以采用矩阵分解来对LDA模型进行分解,更加全面地考虑新闻和用户的属性,并结合用户的评论来提取特征词,更全面地建立用户的兴趣模型,来更好地提升推荐质量。
参考文献:
〔1〕徐毅,叶卫根,戴鑫,等.融合用户信任度与相似度的推荐算法研究[J].小型微型计算机系统,2018, 39(01):78-83.
〔2〕王博.新闻内容推荐算法研究[J].信息与电脑(理论版),2016,28(06):146-147.
〔3〕刘辉,万程峰,吴晓浩.基于增量协同过滤和潜在语义分析的混合推荐算法[J].计算机工程与科学,2019,41(11):2033-2039.
〔4〕高茂庭,王吉.融合用户关系和时间因素的主题模型推荐算法[J/OL].计算机工程:1-7[2020-07-25].https://doi.org/10.19678/j.issn.1000-34 28.0054096.
〔5〕程磊,高茂庭.结合时间加权和LDA聚类的混合推荐算法[J].计算机工程与应用,2019,55(11):160-166.
〔6〕李散散.基于用户行为分析和LDA模型的数字媒体推荐系统的设计与实现[J].现代电子技术,2020,43(07):146-149+154.
〔7〕魏童童,冯钧,唐志贤,王纯.基于时序背景LDA与协同过滤的混合推荐模型[J].计算机与现代化,2015,31(10):1-5+9.
〔8〕Basilico J, Raimond Y. Déjà Vu: The Importance of Time and Causality in Recommender Systems[C].the Eleventh ACM Conference. 2017.
〔9〕Jin X, Zheng Q, Sun L. An Optimization of Collaborative Filtering Personalized Recommendation Algorithm Based on Time Context Information[M]. Information and Knowledge Management in Complex Systems. Springer International Publishing, 2015.
〔10〕Hu Y, Peng Q, Hu X, et al. Web Service Recommendation Based on Time Series Forecasting and Collaborative Filtering[C]. IEEE International Conference on Web Services. IEEE Computer Society, 2015.
〔11〕郑伟.基于TIN-LDA模型的微博推荐方法研究及应用[D].安徽理工大学,2019.
〔12〕车丰.基于排序主题模型的论文推荐系统[D].大连海事大学,2015.
〔13〕邸亮.基于主题模型的个性化信息推荐[D].北京工业大学,2014.
〔14〕侯涛文.基于LDA的多标记源文本分类研究[D].北京建筑大学,2019.
〔15〕Jordan M I,Blei D M. Latent Dirichlet Allocation[J]. Journal of Machine Learning Research,2003,3: 465-473.
〔16〕陈二静,姜恩波.文本相似度计算方法研究综述[J].数据分析与知识发现,2017,1(06):1-11.
〔17〕雷琨.电子商务个性化推荐系统研究[D].电子科技大学,2012.
〔18〕Herlocker J L, Konstan J A, Terveen L G, et al. Evaluating collaborative filtering recommender systems[J]. ACM Transactions on Information Systems (TOIS), 2004,22(01): 5-53.