基于RandomForest的取消酒店预订应用研究
2021-08-12顾凤云曹睿
顾凤云 曹睿


摘 要:酒店行业迅速发展的同时,存在专业人才短缺、缺乏成熟的管理模式和临时取消率高等问题。本文以Kaggle酒店取消预订数据集为研究对象,对原始數据进行预处理,再利用Lasso方法进行特征重要性排序,将特征提取后的数据作为RandomForest训练模型的输入进行预测,并且通过与XGBoost、LightGBM、DecisionTree等7种主流算法进行对比实验,结果表明本文方案在accuracy、recall、f1_score、AUC四种性能指标上优于对比模型。采用SHAP模型对已建立的价格模型进行解释,同时通过XGBoost, RandomForest的特征重要性排序,识别影响取消预订的关键因素是押金类型、预订时长以及预定渠道。
关键词:机器学习;取消预订模型;酒店行业;Randomforest模型;SHAP值
中图分类号:TP391 文献标识码:A 文章编号:1673-260X(2021)06-0015-08
随着经济的快速发展和各种交流活动的日益频繁,我国旅游行业与酒店行业得到了迅速发展。《2019年中国旅游业统计公报》显示,到2019年末,全国星级饭店10130家,平均房价378.55元/间夜,同比增长6.3%;平均出租率56.7%,同比下降1.3%;每间可供出租客房收入214.65元/间夜,同比增长4.9%;每间客房平摊营业收入40424.51元/间,同比增长5.4%[1]。众所周知,预订是现代酒店管理中一个重要的环节。顾客提前预订,是希望抵达酒店时就有满足其要求的客房,其目的是便于顾客的行程安排[2]。随着互联网的普及,使得提前预订更加便捷。但预订好客房的顾客可能会到了规定的日期而没有到店,或者临时取消预订,致使酒店预留的客房无法销售而造成损失[3]。目前学术界对于酒店行业的关注主要集中在用户行为[3-5]、竞争环境[6-8]、管理系统[9-11]、预订价格[12,13]等方面,针对建立取消酒店预订模型方面的相关研究相对较少。目前针对取消率及影响因素方面的研究,主要集中在交通[14,15]领域,缺乏针对酒店行业的相关研究。因此,在酒店行业专业人才短缺、缺乏成熟的管理模式、临时取消率高等问题的背景下,亟须建立科学规范的预测模型,这对于规范并提高酒店的智能化管理水平、提高酒店入住率并增加酒店收益等方面,都具有重要的促进意义。
1 研究概述
本文的核心是利用RandomForest模型解决酒店行业中预订取消的问题。熊伟以深圳大梅沙京基喜来登度假酒店为例对取消预订的酒店顾客预订行为进行了研究,结果显示,整体上取消预订的顾客以男性商务顾客居多。顾客大多为临时的行程取消或更改而取消预订,且性价比和顾客对酒店的信任度对此有一定影响[3]。龙凡认为我国经济型酒店还处于成长阶段,市场竞争虽然还未达到激烈状态,但消费者人群已经形成,并认可经济型酒店的存在,行业还有较大增长的潜力[6]。李昕提出了基于WLAN的酒店餐饮管理系统的设计方案,并通过对关键技术实现过程的具体描述,得出了嵌入式可视化软件的理想设计模式[9]。李东娟借用配对样本检验方法对我国酒店在线预订价格竞争进行实证研究。结果表明,酒店官网销售价格比相应的在线中介代理价格偏低,经济型酒店对中介代理的依赖程度比国内其他类型酒店要低,其官网价格具有一定的市场竞争力[12]。针对取消预订预测方面,研究者基于不同视角构建了不同的预测模型进行了相关研究。刘玉洁基于贝叶斯网络建立了延误波及模型,探讨了相关航班中,进港延误和航班取消对离港延误的影响。研究发现,进港延误对离港延误的波及现象在不同情况下的程度有差异[13]。李纯柱利用XGBoost算法对航班取消事件进行了预测。实验结果表明XGBoost分类器的性能优于基准模型,f1_score值为0.9695[14]。Agustin J提出一种仅使用13个独立变量就可以预测酒店预订取消的方法,除了采用遗传算法优化的人工神经网络外,还应用了机器学习技术,实验结果表明准确率高达98%[15]。Nuno Antonio将8家酒店的物业管理系统的数据与多个来源(天气、假日、事件、社会声誉和在线价格)的数据结合,并使用机器学习可解释的算法开发预订取消酒店的预测模型。研究结果显示,在实际的生产环境中,由于使用这些模型而提高了预测准确性,可以使旅馆经营者减少取消的次数,从而增加对需求管理决策的信心[16]。
在以上相关研究中,本文与Agustín J和Nuno Antonio的研究内容较为接近,都是利用机器学习方法建立预测模型,但是本文与他们的研究不同之处在于Agustín J和Nuno Antonio采用的均为黑箱机器学习模型,这使得建立的预测模型缺乏可解释性,为了解决这一问题,本文通过引入SHAP模型,能够对影响取消预订的因素进行分析,为酒店行业改进服务质量提供了决策参考。
2 模型与方法
2.1 问题分析
设X为酒店预订特征集合(酒店类型、到达时间、入住人数、最终预订状态等信息),Y为是否取消,给定训练数据集为D={(x1,y1),(x2,y2),…,(xs,ys)},其中xi=(xi(1),xi(2),…,xi(p))为输入实例,p为特征个数,i=1,2,…,s,s为样本个数。将训练样本进行异常值处理、数据标准化等特征工程处理后,将样本输入到RandomForest模型中进行计算。随机森林是基于Bagging框架下的决策树模型,建立的是多个决策树,即通过结合多个弱学习器,从而达到强学习器的效果[17]。随机森林包含了很多树,每棵树给出分类结果,每棵树都有生成规则。
(1)如果训练集大小为N,对于每棵树而言,随机且有放回地从训练中抽取N个训练样本,作为该树的训练集,重复K次,生成K组训练样本集。
(2)如果每个特征的样本维度为M,指定一个常数m?垲M,随机从M个特征中选取m个特征。
(3)利用m个特征对每棵树尽最大可能的生长,并且没有剪枝过程。
随机森林的分类算法流程如图1所示:
2.2 SHAP的原理
在樣本量足够大的前提下,通过RandomForest算法可以训练出预测精度较高的分类模型,但是RandomFoest与传统的线性模型相比,在模型的可解释性上,几乎是一个黑箱模型。为了解决这个问题,本文采用SHAP值对模型中影响取消预订的因素进行解释分析。SHAP是由Lundberg和Lee[18]于2017年提出,用于增强XGBoost等模型的可解释性。
假设第I个样本为xi,第I个样本的第j个特征为xij,模型对该样本的预测值为yi,整个模型的基线为ybase,那么SHAP value服从以下等式:
yi=ybase+f(xi1)+f(xi2)+…+f(xip), (1)
其中f[(x)ij]为xij的SHAP值。RandomForest传统的feature importance只能反映出特征的重要程度,但并不清楚该特征是如何影响预测结果的。SHAP value最大的优势是SHAP能反映出每一个样本特征的影响力,而且还指出影响的正负性。
3 特征工程
3.1 数据概况
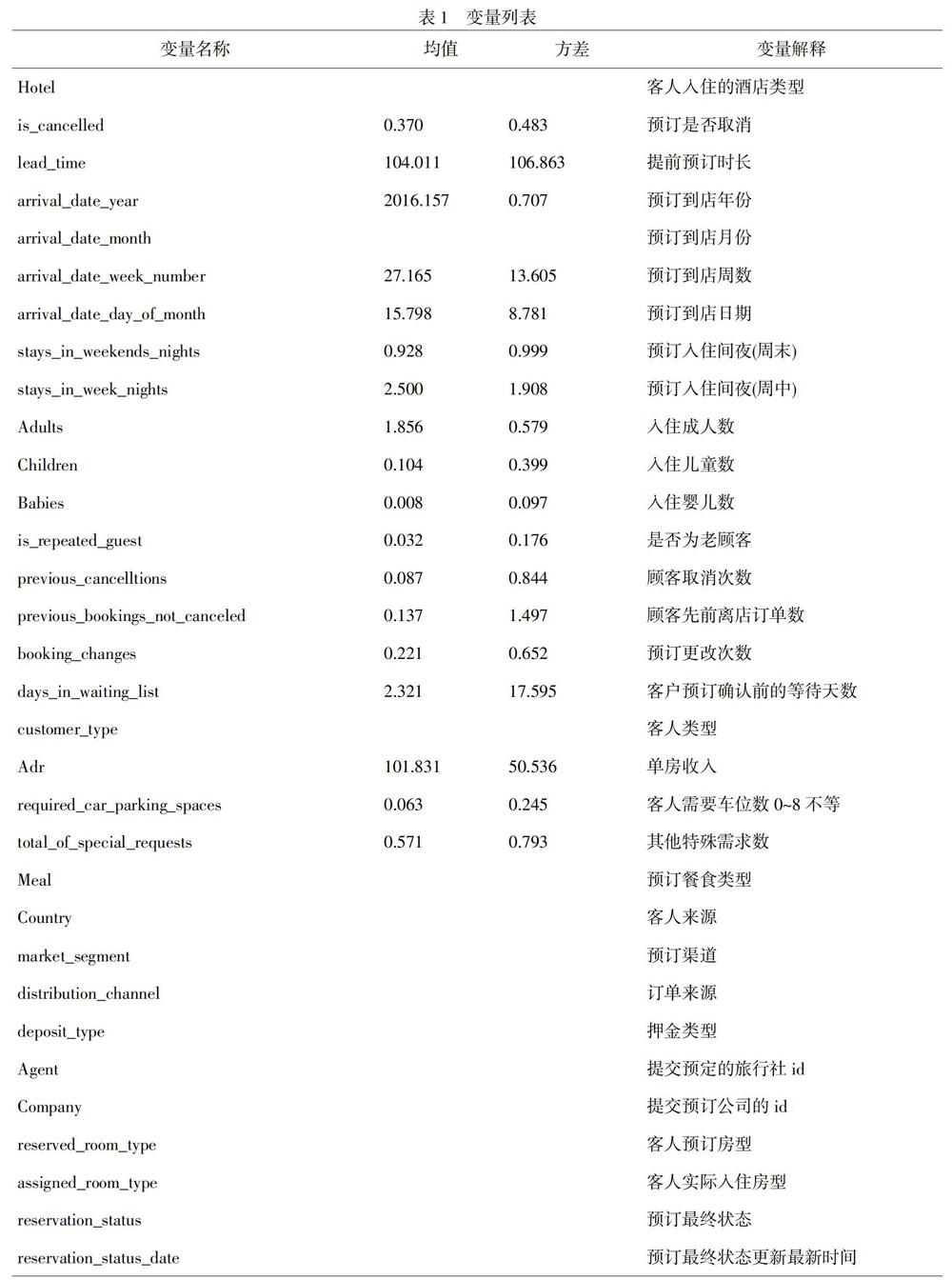
本文选取Kaggle竞赛Hotel booking demand(https://www.kaggle.com/jessemostipak/hotel-booking-demand)作为研究的数据源,该数据集包括酒店的基本信息,其中是否取消预订作为输出标签值。数据集总量为119390,特征总数为32。原数据集所含特征的均值和方差如表1所示。其部分特征如图2所示,不论是城市酒店还是度假村,5月至9月是入住旺季(68.7%);城市酒店的取消预订集中在4月至6月,而度假村在6月、8月及9月的取消次数较多。
3.2 特征工程
(1)异常值处理 预测建模需要对数据进行异常数据剔除和缺失数据处理,如图3所示。在119390个初始样本中,剔除lead_time大于500、stays_in_ weekend_nights大于6、stays_in_week_nights大于10、adults大于4、children大于8以及babies大于8的异常样本,剩余118489个样本。
(2)缺失值处理及数据编码 缺失数据的处理按照特征的属性区别对待,对children用众数填充;对country采用字符串unknown填充;因company缺失90%,故选择剔除该变量。对meal、market_segment、distribution_channel、reserved_room_ type、assigned_room_type、customer_type、reservation _status等特征进行独热编码;对country、hotel采用标签编码。
(3)相关性分析 目标变量(is_canceled)与lead_time、required_car_parking_spaces、total_of_ special_requests、deposit_given等变量的相关系数较高,说明以上变量的变动可能对目标变量产生较大影响,如图4所示。
(4)特征转换 添加新变量family、deposit、total_customers以及total_nights。family的取值为:当adults大于0且children大于0时,取1,其他取0;deposit的取值为:当deposit_type为No Deposit且为Refundable时,取0,其他取1。
(5)Lasso特征选择 在实际的工作中,Lasso的参数λ越大,参数的解越稀疏,选出的特征越少。本文采用交叉验证方法计算模型的RMSE,然后选择RMSE的极小值点,从而确定参数λ的值。特征的重要程度如图5所示,最终选取特征为61个。
4 实验结果及讨论
4.1 算法评价指标及超参数配置
本文以accuracy(正确率)、precision(精度)、recall(召回率)、f1_score作为预测模型的评价函数。其计算公式如(2)-(5)。
首先介绍几个常见的模型评价术语,假设分类目标只有两类,计为正例(positive)和负例(negative)分别是:
(1)True positives(TP):被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数。
(2)False positives(FP):被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数。
(3)False negatives(FN):被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数。
(4)True negatives(TN):被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。
正确率(accuracy) 正确率是最常见的评价指标,即被分对的样本数除以所有的样本数,通常来说,正确率越高,分类效果越好。
精度(precision) 精度是精确性的度量,表示被分为正例的示例中实际为正例的比例。
召回率(recall) 召回率是覆盖面的度量,度量有多个正例被分为正例。
f1-score是对精度和召回率的调和平均。
本文中所有对比算法的超参数配置如表2所示。
4.2 与其他主流机器学习模型的对比分析
8种算法的预测评价指标结果如表3所示。以RandomForest算法为例,将处理完毕后的数据以70%的训练数据,30%的测试数据作为数据切分方案,各算法超参数配置,最终利用70%的数据训练得到模型,并在30%的验证数据集上预测最终详细结果。
从表3及图6中的详细数据可以看出,总体上8种算法的性能对比结果是:RandomForest效果最佳,precision值为0.884,recall值为0.798,f1得分为0.838,AUC值达到0.868。StochasticGradientDescent效果最差。其中,在precision指标上,随机森林能够达到0.884,其次是XGBoost,值为0.851。而逻辑回归在precision指标上只达到了0.786。其他算法的precision值均在区间[0.80,0.87]内。在recall指标上,RandomForest与其他8种算法之间的差距比较明显,SVC的recall值只有0.506,而决策树、RandomForest分别能够达到0.800、0.798,其他算法的recall值均在区间[0.60,0.70]内。在f1_score指标上,RandomForest的值可以达到0.838,而逻辑回归以及StochasticGradientDescent的值只有0.697。其他7种算法的f1_score值均在区间[0.70,0.80]内。在AUC指标上,RandomForest算法与其他算法之间的差距并不明显,AUC值均在区间[0.75,0.88]内。
综上所述,RandomForest在3个评价指标上误差都小于其他7个算法,预测效果最为理想。比较8个算法的预测效果可以看出:(1)在预测效果上,RandomForest比其他算法预测效果好,三个指标均为最优,这表明本文的指标体系是有效的,深入挖掘影响取消酒店预订的因素可以更加准确地预测顾客是否会取消预订。(2)基于非线性的XGBoost、LightGBM算法比线性回归、决策树的预测效果好,这表明数据集往往表现出复杂的非线性关系并含有一定程度的噪声数据,所以使用基于非线性关系的模型可以获得较好的预测效果,但与此同时也会增大模型的复杂度。(3)基于集成方法的RandomForest、XGBoost算法预测效果较好,其原因在于RandomForest作为一种集成方法,其通过了结合多个弱学习器达到一个强学习器的效果。研究结果表明:在Lasso特征选择的基础上,通过RandomForest分类可以合理地预测顾客是否会取消酒店预订,而且RandomForest方法在模型的推广泛化上具有一定优势。
4.3 模型超参数调优及模型收敛分析
Randomforest中的超参数总共有19个,主要分为Bagging的框架参数(如booster、oob_score等)、决策树的参数(如max_features、max_depth等)。本文在参数调优过程中采用网格参数搜索技术(GridSearchCV)并以accuracy为评价指标,以表现最优的Randomforest模型为训练集,选择以n_estimators、max_depth、min_samples_split、min_samples_leaf四个对模型性能影响最大的参数为主,参数的搜索空间及第一轮调优结果如表4所示。
(1)先确定n_estimators,把n_estimators设置成100,其他参数使用默认参数,使用GridSearchCV函数进行网格搜索确定合适的n_estimators。(2)找到合适的迭代次数后使用GridSearchCV函数对模型的其他三个主要参数进行网格搜索自动寻优。使用5折交叉验证的方法来选择参数,即每次将训练数据集分成5份,轮流将4份用于训练集训练剩下1份用于测试集测试,每次试验都会得到相应的accuracy值,最后将5次测试分数的均值作为最后的accuracy值。参数最终选择为n_estimators、max_depth、min_samples_split、min_samples_leaf的结果为:200、8、5、3。相比未调参的结果0.884(precision值),调参后为0.925(precision值),优化效果比较显著。
如图7所示,Randomforest与其他模型学习曲线对比,其中图7(a)-(d)分别表示Randomforest、DecisionTree、XGBoost以及LightGBM的學习曲线。从图7中可以发现各算法的拟合效果相差较大,可以看到除DecisionTree、RandomForest外,其他两种算法随着样本量的增加,模型都趋于逐步收敛,而DecisionTree、RandomForest的测试集与交叉验证集性能存在较大差距。Randomforest、XGBoost、LightGBM分别在样本量为30000时,模型就取得了较好拟合效果,并随着样本量的逐步增加,交叉验证的性能也逐渐趋于稳定。从拟合趋势上看,随着样本量的不断增大,XGBoost与LightGBM模型能够达到更优的拟合效果,但XGBoost在测试集上的稳健性相比LightGBM更为出色。
4.4 基于SHAP的模型解释分析
图8显示了整个模型的特征重要度,该图根据要素对影响取消预订的因素重要性对其进行排序。可以看到country(顾客来源)、total_of_special_requires(其他特殊需求数)、deposit_given(押金类型)、required_car_parking_spaces(需要停车位数)、market_segment_Online TA(网上预订)、lead_time(提前预订时长)、previous_cancellations(提前取消次数)等特征的差异对模型的影响较显著。整体来说,前20个特征对模型产生的正面影响的占多数。具体而言,country对模型产生的正面影响较大,即country值越大,SHAP value的值也越大,红色区域集中于SHAP value大于0的部分,蓝色区域集中在SHAP value小于0的部分;与之产生相同影响的时deposit_given,该值越大,SHAP value的值也越大。而total_of_special_requires(其他特殊需求数)对模型产生的负面影响较大,即红色区域聚集于SHAP value小于0的部分,蓝色区域聚集于SHAP value大于0的部分,说明该值越大,SHAP value越小。
经过XGBoost、RandomForest的训练后,可以得到每个特征的重要性指标。表5为两种算法特征重要性对比。
通过表5及图9观察发现,经过XGBoost、RandomForest训练后,排名10的特征重要度并不完全相同。结合数据集的特征重要度排序,可以得出影响取消预订的关键因素是deposit_type(押金类型)、country(客户来源)、lead_time(提前预订时长)、market_segment(预订渠道)、adr(入住总人数)以及reserved_room_type(预留房型)。具体而言,deposit_type若为No default(无保证金),取消预订的概率越高是肯定的;若lead_time(提前预订时长)越大,取消预订的概率越高。取消的原因可能是顾客无法控制的,例如计划变更、疾病、事故或天气。然而,由于顾客的行为,取消也可能发生,例如找到价格更优惠的酒店,找到位置更好或更理想的酒店,寻找一家服务设施更好的酒店。
5 结论
酒店行业发展迅速,研究者对其的关注主要集中在用户行为、竞争环境、管理系统、预订价格等方面,针对建立取消酒店预订模型方面的相关研究相对较少,并且已有工作中采用的均为黑箱机器学习模型,缺乏模型的可解释性。所以,本文以kaggle酒店取消预订数据集为研究对象,研究了基于RandomForest算法对酒店预订场景下预测是否取消的问题。首先,对原始数据进行预处理,再利用Lasso方法进行特征提取;其次,将特征提取后的数据作为RandomForest训练模型的输入进行预测;并且通过与XGBoost、LightGBM、DecisionTree、SVC、LogisticRegression、Adaboost以及SGD等7种主流算法对比实验,证明了RandomForest算法的有效性。最后,采用SHAP模型对已建立的价格模型进行解释,同时通过XGBoost, RandomForest的特征重要性排序,识别出影响取消预订的关键因素是押金类型、预订时长以及预定渠道。下一步工作可以考虑加入更多特征(如位置、天气状况、酒店星级、价格等),进一步提升模型的预测精度。
参考文献:
〔1〕国家旅游局.2019年中国旅游业统计公报[EB/OL].https://www.sohu.com/a/403183779_168 029?_trans_=000014_bdss_dkygcbz,2020-06-20/2020-11-20.
〔2〕江浩.饭店预订业务应更有作为[J].商业研究,2006,49(07):103-105.
〔3〕熊伟,蓝文婷.基于no-show和取消预订的酒店顾客预订行为研究——以深圳大梅沙京基喜来登度假酒店为例[J].旅游研究,2012,4(03):51-59.
〔4〕孙文龙.一种基于用户行为特征的个性化酒店推荐模型[J].电子世界,2014,36(24):469-469.
〔5〕Falk M, Vieru M J. Modelling the Cancellation Behaviour of Hotel Guests[J]. Social ence Electronic Publishing, 2018, 30(10):3100-3116.
〔6〕龙凡.我国经济型酒店行业竞争环境分析[J].商业经济研究,2008,27(012):101-103.
〔7〕冯小伟.激烈竞争环境下的经济型酒店创新经营[J].河北联合大学学报(社会科学版),2014,14(1):57-60.
〔8〕邹林辰.基于SSM的酒店管理系统开发[J].科学技术创新,2020,24(32):55-56.
〔9〕李昕,孟祥福,刘玥.基于WLAN的酒店餐饮管理系统的实现[J].微计算机信息,2007,23(06):17-18,31.
〔10〕丁蕾锭,兰海翔,卢涵宇,祁小军,薛安琪.餐饮酒店信息管理系统设计与实现[J].电脑知识与技术,2019,15(25):152-154.
〔11〕尚天成,吴雪,刘培红,等.酒店客房价格影响因素研究进展[J].天津大学学报:社会科學版,2017,19(01):1-6.
〔12〕李东娟,熊胜绪.我国酒店在线预订价格竞争的实证研究[J].旅游学刊,2011,26(12):37-41.
〔13〕刘玉洁,何丕廉,刘春波,等.基于贝叶斯网络的航班延误波及研究[J].计算机应用,2008,44(17):242-245.
〔14〕李纯柱,刘博,卢婷婷.基于XGBoost算法的航班取消问题研究与预测分析[J].民航学报,2020, 4(05):117-122.
〔15〕Agustín J. Sánchez-Medina, Eleazar C-Sánchez. Using machine learning and big data for efficient forecasting of hotel booking cancellations[J]. International Journal of Hospitality Management, 2020, 89:102546.
〔16〕Nuno Antonio.Big Data in Hotel Revenue Management: Exploring Cancellation Drivers to Gain Insights Into Booking Cancellation Behavior[J].Cornell Hospitality Quarterly. 2019, 60(04):298-319.
〔17〕BREIMAN L. Random forests[J]. Machine Learning, 2001,45(01):5-32.
〔18〕Lundberg S M, Lee S I. A unified approach to interpreting model predictions[C]// Advances in neural information processing systems. 2017:4765-4774.