基于卷积神经网络模型的木材宏、微观辨识方法*
2021-08-10赵子宇杨霄霞葛浙东周玉成
赵子宇 杨霄霞 郭 慧 葛浙东 周玉成,
(1.山东建筑大学信息与电气工程学院 济南 250101;2.中国林业科学研究院木材工业研究所 北京 100091)
木材辨识在木结构古建筑、海关、进出口检疫检验等领域均有着广泛应用,对现代木材工业和木材贸易起到至关重要、保驾护航的作用。传统的木材辨识主要基于木材的微观解剖特征(显微结构参数)和宏观特征(颜色、气味、纹理等)判断材种的科、属或种,基于宏观特征辨识木材在生产实践上应用价值较大,但准确性较差;基于微观解剖特征辨识木材准确性较高,但在生产现场不太适用。近年来,机器视觉技术逐步应用到木材辨识中,如朱佳等(2014)提出一种基于Graph Cuts的图像分割方法对木材SEM进行特征提取,通过木材轮廓、细胞等特征辨识木材种类;Barmpoutis等(2018)将木材横切面图像的颜色、纹理等特征转化为多维联合直方图形式,通过支持向量机分类器辨识木材。但以上方法均存在木材辨识训练参数多、训练耗时长、分类正确率低等问题,需探寻更快、更准确的方法实现最佳辨识效果(项宇杰等,2019;刘子豪等,2013)。
卷积神经网络研究始于20世纪80年代(Lecunetal.,1989),是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一(Krizhevskyetal.,2012)。卷积神经网络具有表征学习能力,能够自动提取图像特征,模型可直接采用原始图像作为输入(Chenetal.,2017;Kiranyazetal.,2016)。Yang等(2019)以5种针叶材表面纹理图像作为卷积神经网络模型的输入,通过K倍交叉验证法对模型性能进行衡量,此方法运算耗时较长。陈龙现等(2018)采用自行开发的计算机断层扫描系统扫描木材内部缺陷,并使用LeNet-5模型对木材内部缺陷图像进行辨识,但木材种类相对单一,辨识效果不佳。刘英等(2019)将卷积神经网络应用到木材缺陷检测中,采用非下采样剪切波变换预处理和线性迭代聚类方法对木材缺陷进行分类,但辨识准确率较低。He等(2019)采用一种混合的全卷积神经网络(Mix-FCN)定位木材缺陷位置,并从木材表面图像中自动分类缺陷类型。但现有的卷积神经网络模型需要大量训练样本,耗时长,木材辨识仅对较少材种进行研究,并未能运用到实际应用中(李楠,2018)。
传统的微观解剖特征辨识方法需对木材样本横、径、弦三切面进行解剖,染色后用高倍显微镜获得图像,耗时7~15天,这对海关、进出口检疫检验等法定部门在尽可能短的时间内鉴别木材材种的要求不相符。鉴于此,本研究提出一种基于卷积神经网络模型——PWoodIDNet模型的木材宏、微观辨识方法,该模型以木材样本横切面图像作为输入,通过分解卷积核方式减少运算参数,并通过GPU并行算法对模型进行分类更新,从采集样本到鉴定出结果仅需1 h左右,可为海关、进出口检疫检验、家具企业等法定部门和企业提供先进的辨识方法和仪器,从而推动我国木材进出口检疫检验行业和木材加工制造企业的科技进步。
1 PWoodIDNet模型构建
PWoodIDNet模型采用双GPU模式,模型卷积层通过分解卷积核方式将多个小的卷积核堆叠,即改进后的Inception模块,减少运算参数,步长设置为1,使输出特征图尺寸不变;模型池化层是在卷积层之后分别设置4个最大池化层和1个平均池化层,从而达到特征选择和降维的目的;模型全连接层后设置Dropout方法,抑制过拟合现象。
图1中红色区域表示采用改进后的Inception模块对图像进行卷积。现行Inception模块通过1×1、3×3、5×5的卷积核与3×3的最大池化层连接在一起,并在每个卷积层和池化层前添加1×1的卷积核进行降维。本研究对现行Inception模块进行改进,将5×5的卷积核、3×3的最大池化层替换为2组3×3的卷积核、3组3×3的卷积核,增加网络层数,减少运算参数,加深网络宽度,以提高网络对尺度的适应性。最后将4个分支进行特征融合,得到输出特征图,使下一层可从不同尺度上提取到更多的特征。构建方式如图2所示。

图2 改进的Inception模块Fig.2 Improved Inception module
图2中上一层的输出特征图(Input)输入到改进后的Inception模块,并行进入4个分支进行特征提取。第一分支由1×1的卷积核组成,第二分支由1×1的卷积核与1组3×3的卷积核组成,第三分支由1×1的卷积核与2组3×3的卷积核组成,第四分支由1×1的卷积核与3组3×3的卷积核组成,最后4个分支输出到Depth Concat层进行特征融合。
模型构建过程如下:
第一步,构建输入图像卷积层。设输入图像尺寸为Z(i,j,k)_In,0≤i≤224、0≤j≤224、k=3。构建32个5×5的卷积核,其中GPU1为16个5×5,GPU2为16个5×5。则GPU1的f=5,令步长为s0=2,扩充值为p′,则有:
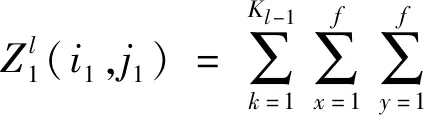
(1)
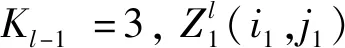
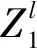
Ll1=(Ll-1+2p′-f)/s0+1。
(1.1)
由式(1.1)得,填充值p′=3。
GPU2的f=5,令步长为s0=2,扩充值为p′,则有:
(2)
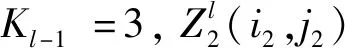
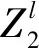
Ll2=(Ll-1+2p′-f)/s0+1。
(2.1)
由式(2.1)得,填充值p′=3。
第二步,构建最大池化层(32)。设上层GPU1和GPU2输出图像尺寸为A1(i1,j1)和A2(i2,j2),其中i1、j1、i2、j2均为113,即上层GPU1和GPU2输出图像均为113×113×16。构建32个3×3矩阵,GPU1为16个3×3矩阵,GPU2为16个3×3矩阵。则GPU1的f=3,令步长为s0=2,扩充值为p′,预指定参数p→∞,则最大池化模型为:
(i1,j1)∈{0,1,…,Ll+1}。
(3)
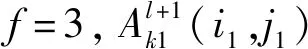

Ll+1=(Ll+2p′-f)/s0+1。
(3.1)
由式(3.1)得,填充值p′=0。
GPU2的f=3,令步长为s0=2,扩充值为p′,预指定参数p→∞,则最大池化模型为:
(4)
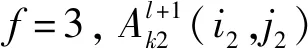

(4.1)
由式(4.1)得,填充值p′=0。
第三步,构建卷积层(64)。设上层GPU1和GPU2输出图像尺寸为Z1(i1,j1)和Z2(i2,j2),其中i1、j1、i2、j2均为56,即上层GPU1和GPU2输出图像均为56×56×16。
构建改进的Inception模块。
①第一分支:构建16个1×1的卷积核,GPU1为8个1×1,GPU2为8个1×1。
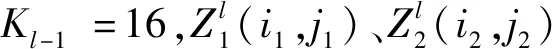
②第二分支:
a.构建6个1×1的卷积核,GPU1为3个1×1,GPU2为3个1×1。
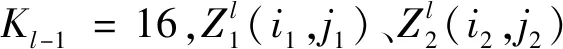
b.构建8个3×3的卷积核,GPU1为4个3×3,GPU2为4个3×3。
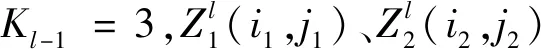
③第三分支:
a.构建6个1×1的卷积核,GPU1为3个1×1,GPU2为3个1×1。
b.构建16个3×3的卷积核,GPU1为8个3×3,GPU2为8个3×3。
④第四分支:
a.构建6个1×1的卷积核,GPU1为3个1×1,GPU2为3个1×1。
b.构建24个3×3的卷积核,GPU1为12个3×3,GPU2为12个3×3。
⑤将GPU1和GPU2在第一分支中输出的8个56×56的矩阵、第二分支中输出的4个56×56的矩阵、第三分支中输出的8个56×56的矩阵与第四分支中输出的12个56×56的矩阵相加,得到32个56×56的矩阵(32=8+4+8+12),即GPU1和GPU2中改进的Inception模块输出特征图尺寸均为56×56。
第四步,构建最大池化层(64)。设上层GPU1和GPU2输出图像尺寸为A1(i1,j1)和A2(i2,j2),其中i1、j1、i2、j2均为56,即上层GPU1和GPU2输出图像均为56×56×32。构建64个3×3矩阵,GPU1为32个3×3矩阵,GPU2为32个3×3矩阵。

第五步,构建卷积层(128)。设上层GPU1和GPU2输出图像尺寸为Z1(i1,j1)和Z2(i2,j2),其中i1、j1、i2、j2均为28,即上层GPU1和GPU2输出图像均为28×28×32。
构建Inception模块,同第三步计算步骤,将GPU1和GPU2在第一分支中输出的16个28×28的矩阵、第二分支中输出的8个28×28的矩阵、第三分支中输出的16个28×28的矩阵与第四分支中输出的24个28×28的矩阵相加,得到64个28×28的矩阵(64=16+8+16+24),即GPU1和GPU2中Inception模块输出特征图尺寸均为28×28。
第六步,构建最大池化层(128)。设上层GPU1和GPU2输出图像尺寸为A1(i1,j1)与A2(i2,j2),其中i1、j1、i2、j2均为28,即上层GPU1和GPU2输出图像均为28×28×64。构建128个3×3矩阵,GPU1为64个3×3矩阵,GPU2为64个3×3矩阵。
第七步,构建卷积层(256)。设上层GPU1和GPU2输出图像尺寸为Z1(i1,j1)与Z2(i2,j2),其中i1、j1、i2、j2均为14,即上层GPU1和GPU2输出图像均为14×14×64。
构建Inception模块,同第三步计算步骤,将GPU1和GPU2在第一分支中输出的32个14×14的矩阵、第二分支中输出的16个14×14的矩阵、第三分支中输出的32个14×14的矩阵与第四分支中输出的48个14×14的矩阵相加,得到128个14×14的矩阵(128=32+16+32+48),即GPU1和GPU2中Inception模块输出特征图尺寸均为14×14。
第八步,构建最大池化层(256)。设上层GPU1和GPU2输出图像尺寸为A1(i1,j1)和A2(i2,j2),其中i1、j1、i2、j2均为14,即上层GPU1和GPU2输出图像均为14×14×128。构建256个3×3矩阵,GPU1为128个3×3矩阵,GPU2为128个3×3矩阵。
第九步,构建卷积层(512)。设上层GPU1和GPU2输出图像尺寸为Z1(i1,j1)和Z2(i2,j2),其中i1、j1、i2、j2均为7,即上层GPU1和GPU2输出图像均为7×7×128。
构建Inception模块,同第三步计算步骤,将GPU1和GPU2在第一分支中输出的64个7×7的矩阵、第二分支中输出的32个7×7的矩阵、第三分支中输出的64个7×7的矩阵与第四分支中输出的96个7×7的矩阵相加,得到256个7×7的矩阵(256=64+32+64+96),即GPU1和GPU2中Inception模块输出特征图尺寸均为7×7。
第十步,构建平均池化层。设上层GPU1和GPU2输出图像尺寸为A1(i1,j1)和A2(i2,j2),其中i1、j1、i2、j2均为7,即上层GPU1和GPU2输出图像均为7×7×256。构建512个7×7矩阵,GPU1为256个7×7矩阵,GPU2为256个7×7矩阵。

第十一步,构建全连接层。设置1个全连接层,全连接层后加入Dropout方法,抑制过拟合。构建分类层(输出),采用Softmax分类器进行分类,分类数为16。
模型在每个卷积层和全连接层后均设置ReLU激活函数,实现模型更好地提取图像相关特征,拟合训练数据,且计算简单。
2 材料与方法
2.1 试验材料
试验用16种木材样本取自山东建筑大学木材标本馆,分别为东非黑黄檀(Dalbergiamelanoxylon)、尼泊尔紫檀(Glutasp.)、红栎(Quercussp.)、樟子松(Pinussylvestrisvar.mongolica)、辐射松(Pinusradiata)、西非苏木(Danielliasp.)、非洲檀香(Spirostachysafricana)、白梧桐(Triplochitonscleroxylon)、轻木(Ochromasp.)、南美红鸡翅(Andirasp.)、普拉藤黄(Platoniainsignis)、菲律宾乌木(Diospyrossp.)、军刀豆(Machaeriumsp.)、黄杨木(Buxussp.)、枫木(Acersp.)和纳托山榄(Palaquiumsp.)。采用SkyScan1272型显微CT和ZW-H3800工业相机,以木材横切面为研究对象,分别获取木材微观和宏观结构图像。表1所示为不同树种宏、微观部分图像效果。

表1 不同树种宏、微观部分图像效果Tab.1 Partial rendering of macro-and micro-images of different tree species
木材微观试验样本直径约2 mm,高约8 mm,分辨率0.95 μm,样本每旋转0.1°采集1次数据,每次扫描获得数据3 600行1 280列,直至完成对样本180°扫描。利用NRecon软件重构截面图像,消除环形伪影和射线硬化等不良影响,进行平滑和其他显示设置,截取图像大小为2 280×1 760。
木材宏观试验样本尺寸为50 mm×50 mm×20 mm。不同光照条件下获取木材样本纹理特征,并进行初步降噪与饱和度调整,图像大小为1 920×1 080。
2.2 样本数据处理
首先,选择16种木材样本,每种样本获取50张高分辨率显微CT图像和工业相机图像,共1 600幅;然后,截取具有木射线、薄壁组织、轴向管胞、纹孔等特征的目标区域,扩充至2 400幅,在样本表面纹理图像中随机选取波状纹、皱状纹、斑点状、多孔状等特征区域,扩充至2 400幅,共4 800幅,截取样本图像大小为224×224;通过水平翻转、垂直翻转、镜像、亮度变换等图像增强算法二次扩充数据集,最终宏、微观图像集扩充至19 200幅。截取后的图像通过手动筛选,避免样本选取的单一性和误选性,提升数据集的多样性。其中,70%图像用于木材辨识的训练集,30%图像用于验证集。
2.3 PWoodIDNet模型训练
2.3.1 模型训练参数 模型训练次数设为4 200次,学习率设为0.000 1,训练批次样本数设为16,权重参数和偏置参数初值用均值μ=0、标准偏差σ=0.01的截断正态分布随机生成,模型全连接层输出为16。
2.3.2 并行加速 为加快模型训练速度和搜索匹配速度,系统硬件采用AMD Ryzen Threadripper 2920X CPU @3.5GHz,内存为128 GB,GPU显卡采用NIVIDIA GeForce RTX 1080Ti,利用GPU运算库进行并行优化,提高训练模型精度和效率(Krizhevskyetal.,2012)。
3 结果与分析
3.1 模型优化
在卷积神经网络中,优化算法选择是模型设计的关键。当前,优化算法种类繁多,其中以SGDM(Rumelhartetal.,1986;Traorebetal.,2018;Dimauroetal.,2019)、RMSprop(Hintonetal.,2012)、Adam(Kingmaetal.,2014)最为常见。本研究选用木材微观数据集,分别对3种常见优化算法进行比较,选出最适合PWoodIDNet模型的优化算法。
采用3种优化算法对模型进行训练,如图3所示。SGDM优化算法模型分类准确率曲线最平缓,当迭代次数为300次时,模型已接近收敛状态;同时,SGDM优化算法能够抑制模型震荡,并加速学习。RMSprop优化算法模型分类准确率曲线持续出现振荡现象,振荡频率范围最大位置准确率最低达30%(0.3)。Adam优化算法模型分类准确率曲线较RMSprop平缓,网络结构模型的训练分类精度波动较大,训练过程未达到收敛状态。
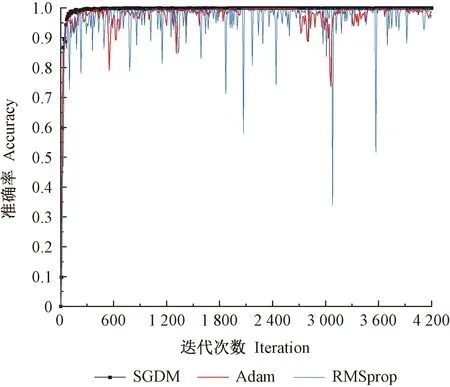
图3 不同优化算法分类准确率对比Fig.3 Comparison of classification accuracy of different optimization algorithms
不同优化算法损失值对比如图4所示。训练初期,SGDM、Adam优化算法模型的初损失值较大,但收敛速度较快;RMSprop优化算法模型持续出现振荡现象,并一直持续到训练结束。训练中期,SGDM优化算法模型持续处于收敛状态,损失值接近0,高于其他算法的收敛速度。当迭代次数达3 600次后,Adam优化算法模型振荡现象减轻,并逐渐趋于收敛状态。
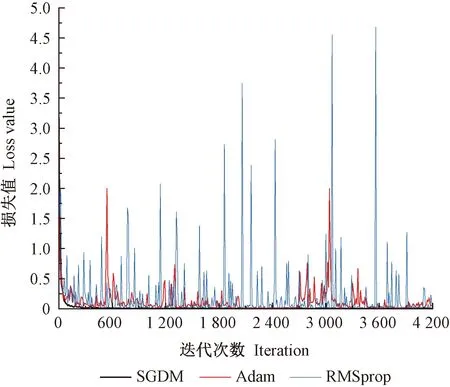
图4 不同优化算法损失值对比Fig.4 Comparison of loss value of different optimization algorithms
不同优化算法的分类结果如表2所示。在迭代次数相同的情况下,SGDM优化算法模型对木材显微CT图像的辨识效果最佳,测试集的平均分类准确率为99.17%,相比Adam优化算法提高1.72%,相比RMSprop优化算法提高2.86%。
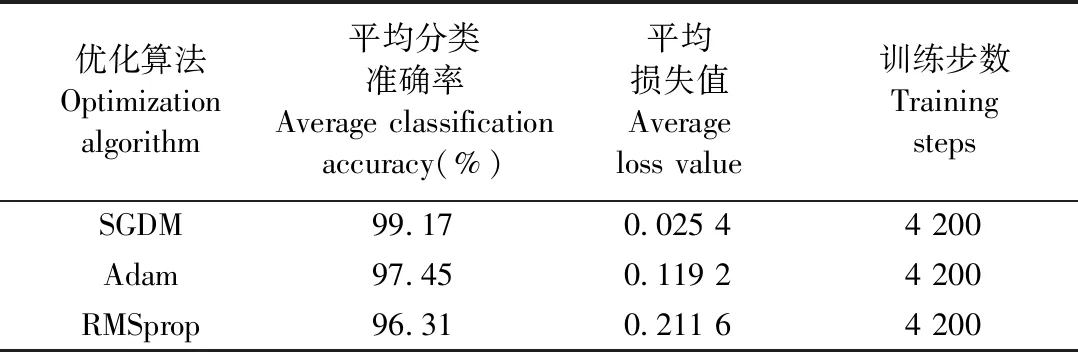
表2 不同优化算法的分类结果Tab.2 Classification results of different optimization algorithms
综上所述,采用SGDM优化算法可有效抑制模型振荡,收敛更稳定,能够提高PWoodIDNet模型对木材的辨识效果。
3.2 PWoodIDNet模型与现行模型准确率比较
对国内外现行经典的AlexNet模型、GoogLeNet模型(Szegedyetal.,2015)与PWoodIDNet模型进行分类准确率和损失值比较,数据集分别采用木材微观和宏观数据集。
3种模型的分类准确率如图5所示。训练初期,PWoodIDNet模型分类准确率随迭代次数增加逐渐趋于收敛状态,当迭代次数为300次时,分类准确率达99%,并一直持续到迭代完成,辨识效果优于其他模型,分类准确率最高可达99.98%;GoogLeNet模型分类准确率随迭代次数增加持续增大,但分类准确率曲线出现振荡现象,未达到收敛状态;AlexNet模型分类准确率曲线振荡现象比较严重,分类准确率较低。随迭代次数增加,GoogLeNet模型、AlexNet模型分类准确率曲线仅出现小范围振荡,未出现剧烈波动,逐渐趋于收敛状态。

图5 3种模型的分类准确率Fig.5 Classification accuracy of three models
3种模型的损失值如图6所示。PWoodIDNet模型损失值随迭代次数增加逐渐降低,当迭代次数为200次时出现拐点,损失值逐渐趋于收敛状态,直至迭代结束。随PWoodIDNet模型网络层数增加,运算参数减少,加速损失值收敛速度。GoogLeNet模型迭代600次左右时曲线出现轻微振荡现象,损失值整体呈下降趋势,随迭代次数增加逐渐趋于收敛状态。AlexNet模型损失值整体呈下降趋势,当迭代次数为1 000次时,曲线仍不断出现振荡现象,收敛速度较慢,迭代次数达3 000次后,损失值变化缓慢,逐渐接近0。

图6 3种模型的损失值Fig.6 Loss value of three models
采用卷积神经网络模型实现木材宏、微观图像的辨识,结果如表3所示。同一模型,微观图像平均分类准确率均高于宏观图像。PWoodIDNet模型分类准确率、运算速度明显高于其他2种模型,相比现行GoogLeNet模型,准确率提高1.49%,速度提高59.69%;相比现行AlexNet模型,准确率提高3.76%,速度提高2.63%。PWoodIDNet通过优化模型和分解卷积核方式,提高了分类准确率,验证了模型的有效性。
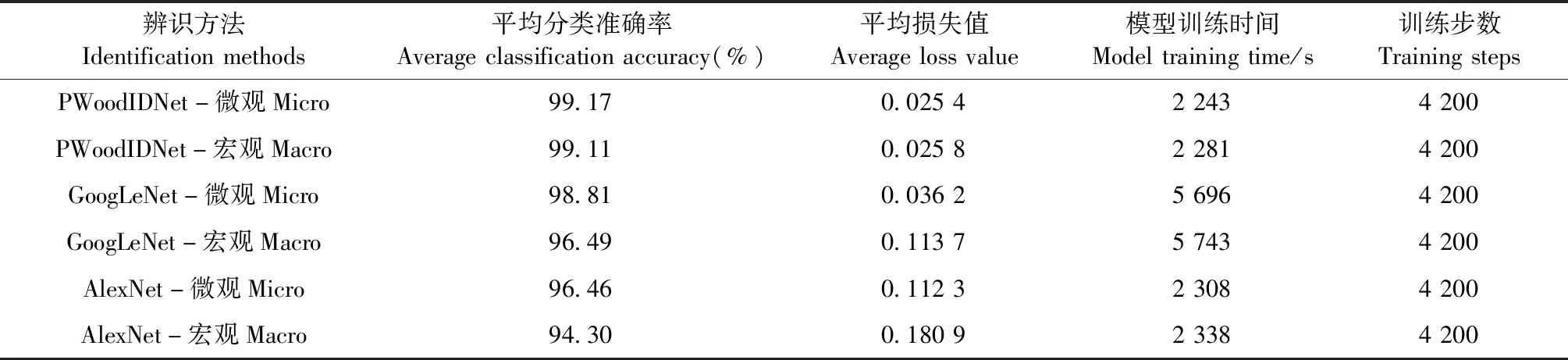
表3 木材辨识模型结果Tab.3 Results of wood identification model
3.3 PWoodIDNet模型复杂度与时间消耗分析
PWoodIDNet模型通过分解卷积核方式将1×1与3×3的卷积核堆叠,减少运算参数,即改进后的Inception模块。采用小尺寸的卷积核进行卷积,通过4组改进后的Inception模块,网络层数仅72层,模型整体复杂度降低,训练和预测时间减少。木材微观数据集下PWoodIDNet模型与现行GoogLeNet模型的损失值如图7所示,虽然PWoodIDNet模型的初损失值较高,但收敛速度最快,模型的泛化能力强。如表4所示,PWoodIDNet模型网络层数和训练耗时最少,体现出模型复杂度较低的特点,其他3种GoogLeNet模型的网络层数较多且复杂,收敛速度较慢。

图7 微观数据集下PWoodIDNet模型与GoogLeNet模型的损失值Fig.7 Loss value of PWoodIDNet and GoogLeNet models under micro data sets

表4 不同模型的复杂度与时间对比Tab.4 Complexity and time comparison of different models
4 讨论
4.1 高分辨率显微CT对木材辨识的影响
木材辨识技术包括宏观辨识和微观辨识2种方法,通常采用无损检测设备,既不破坏木材内部结构又省去切片制作过程,提高了辨识效率。高分辨率显微CT具有穿透力强、检测速度快、非破坏性等特点,常用于木材缺陷检测、密度测定等方面(彭冠云等,2009;费本华等,2007)。本研究将高分辨率显微CT应用于木材微观构造辨识,薄壁组织、管胞、树胶道、导管、木射线等特征清晰可见,很大程度上提高了木材辨识的质量。应进一步丰富木材图像数据集,建立属于自己的Web网站服务器,实现高分辨率显微CT检测的木材微观图像云共享。
4.2 PWoodIDNet模型对木材辨识的影响
本研究通过优化模型和卷积核尺寸,实现快速、准确辨识木材,克服了传统手动特征提取、分类效果不佳、训练方法复杂、训练参数过多、耗时过长等问题。采用高分辨率显微CT获取的木材微观图像,提高了样本质量,应用PWoodIDNet模型,提升了模型分类准确率,加快了辨识速度。但本研究只对16种木材样本进行研究,木材种类相对单一,应增加木材种类,并设计开发出更适合多树种识别的网络模型。
5 结论
PWoodIDNet模型突破现有辨识方法木材辨识种类范围窄、准确率低和辨识速度慢的难点,能够有效辨识木材,分类准确率可达99%,是一种高效、无损、准确的木材辨识分类方法,可为海关、进出口检疫检验、家具企业等法定部门和企业提供先进的辨识方法和仪器,推动我国木材进出口检疫检验行业和木材加工制造企业的科技进步。
