VAE过采样与迁移学习在网络入侵检测中的应用
2021-08-06黄仲英杨印根雷震春
黄仲英 杨印根 雷震春


摘 要: 在网络入侵检测中,异常样本通常要比正常样本少得多,数据的不平衡问题会导致检测模型的分类结果倾向于多数类,影响模型准确率。文章提出应用变分自编码器(VAE)模型对网络入侵检测中的不平衡数据进行过采样,通过学习原数据的特征后生成新样本重新平衡数据分布,以提高检测模型的性能。在训练检测模型时采用迁移学习方法,先在过采样后混合的数据集上预训练,再迁移到原数据集上进行训练,得到最终的检测模型。在NSL-KDD数据集上进行实验,网络入侵检测模型使用前馈神经网络。结果表明,基于深度学习的VAE过采样方法比传统的SMOTE过采样方法要更加有效,提高了网络入侵检测模型准确率3.23%。
关键词: 网络入侵检测; VAE; 迁移学习; SMOTE; 不平衡数据
中图分类号:TP393.08 文献标识码:A 文章编号:1006-8228(2021)07-50-05
Application of VAE oversampling and transfer learning in network intrusion detection
Huang Zhongying, Yang Yingen, Lei Zhenchun
(School of Computer and Information Engineering, Jiangxi Normal University, Nanchang, Jiangxi 330022, China)
Abstract: In network intrusion detection, the number of malicious samples is extremely less than that of normal samples. The data imbalance will lead to the classification results of detection models inclined to most categories, which leads to the low accuracy of the detection models. This paper proposes to use the variational auto-encoder (VAE) model to oversample the imbalanced data in network intrusion detection, and rebalance the data distribution with the new samples generated by learning the features of the original data, so as to improve the performance of detection model. When training the detection model, the transfer learning method is adopted, the final model is pre-training on the oversampled and mixed data set, and then training on the original data set. The experiment is carried out on NSL-KDD data set, and the network intrusion detection model uses feedforward neural network. The results show that the VAE oversampling method based on deep learning is more effective than the traditional SMOTE oversampling method, and the accuracy of network intrusion detection model is improved by 3.23%.
Key words: network intrusion detection; VAE; transfer learning; SMOTE; imbalanced data
0 引言
入侵檢测模型的作用是监视和分析网络通信,通过主动响应来识别网络中的异常行为[1]。在实际应用中,由于网络入侵行为并不是时刻都在发生,因此获取大量标签样本比较困难,需要耗费大量的人力物力,这就造成检测模型的训练集中恶意入侵类别的标签数据量较少,使得集中出现数据不平衡的问题。有限的标签数据只能反馈有限的信息,在少量的标签样本环境下训练出来的检测模型往往影响其检测性能。
从不平衡的数据中训练模型对于研究界来说是一个挑战。常规的网络入侵检测模型在不平衡数据集中通常表现不佳,因为它们会导致分类结果偏向于样本数量多的类[2]。目前,在处理网络入侵检测数据集中的数据不平衡问题时,研究者通常使用欠采样或者过采样方法进行处理。如陈高升等人[3]提出的基于簇内样本平均分类错误率的欠采样方法,在减少多数类样本数量的同时保留尽量多的对构建分类器有用的信息,最终得到一个平衡的数据集再进行实验。Abhishek Divekar等人[4]使用SMOTE过采样技术与随机欠采样技术结合对数据集中的恶意攻击标签样本数据进行调整构建一个均衡版本的NSL-KDD数据集进行网络入侵检测实验。
通过欠采样的方法对数据集进行处理容易丢失多数类样本信息导致模型对多数类的分类精度下降。SMOTE过采样方法则是基于简单的插值运算进行样本的过采样,容易制造出冗余的数据样本增加模型的训练难度。随着信息技术的发展,越来越多的入侵攻击方式也在不断的走向智能化、多样化,传统的过采样方法原理简单,已经不再适用于当下的网络环境。
近年来,在深度生成模型领域变分自编码器(Variational Auto-Encoders,VAE)被视为深度学习领域最具研究价值的方法之一,得到越来越多的应用。如图像处理领域中,田栋文等人[5]提出一种基于VAE的跨域图像生成算法,利用编码器对跨域图像进行编码得到其内容属性和风格属性后再进行拼接实现跨域图像过采样。人脸识别领域中,李顼晟等人[6]设计了一种基于自编码器结构的生成对抗网络,使模型既能生成人脸图像,又可以对人脸图像进行编码和重构。张鹏升等人[7]设计基于变分自编码器的产生式模型,采用[β-VAE]模型学习隐空间与真实图片空间关系,提高图片生成质量,并使用模拟加无监督学习方法,提高模型在训练过程的稳定性。语音处理领域中,Aggarwal等人[8]利用VAE和归一化流对表达性言语进行一次文本-语音合成,使用一个表达风格的例子作为编码器的参考输入,以生成所需风格的任何文本。范純龙等人[9]提出了一种基于变分自编码器(VAE)的无监督交互式旋律生成方法,通过给VAE引入显式的旋律轮廓条件推理学习,实现了对生成旋律局部与全局特征的灵活控制。基于深度生成模型的数据过采样方式已经在许多领域得到应用,其在过采样时利用深度学习方法强大的学习能力,通过深度生成模型学习到待采样数据的分布后,再进行数据的过采样。
在当下复杂的网络环境中,传统的过采样方法已经不适用于网络入侵检测数据集中不平衡数据的过采样。深度生成模型在图片处理、语音识别、自然语言处理等领域得到广泛应用,说明其在数据过采样方面具有很大的优势。本文应用深度生成模型中的变分自编码器模型对网络入侵检测数据集中的不平衡数据进行过采样,通过深度生成模型过采样,重新平衡数据集的样本数量分布后再训练检测模型,以提高检测模型的准确率。本文实验在网络入侵检测数据集NSL-KDD上进行,并且将传统的SMOTE过采样方法与深度生成模型中的VAE过采样方法对检测模型准确率的优化情况进行对比。
1 基于过采样的入侵检测模型
1.1 SMOTE过采样方法
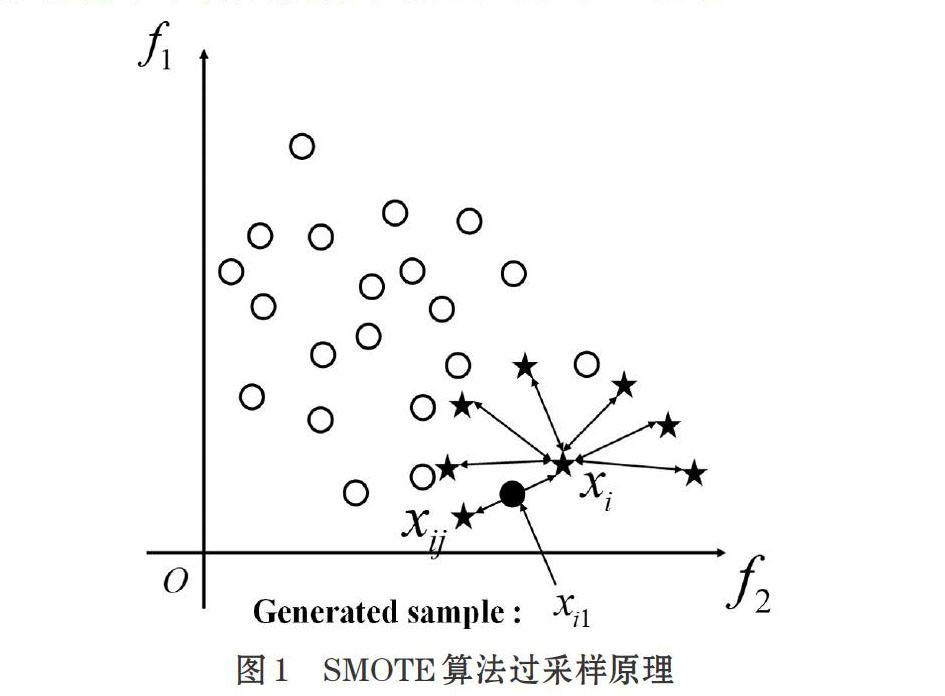
SMOTE过采样方法是基于插值的方法从现有的数据样本中合成新样本,其原理如图1所示。
SMOTE过采样方法通过在两个最近邻的样本连线中随机取一点作为新合成的样本,具体步骤如下。
Step1 对于数据集中的少数类样本[xi],找出样本[xi]的K个近邻;
Step2 在样本[xi]的K个近邻中随机选择一个样本记为[xij],同时生成一个0到1之间的随机数[α1],然后根据式(1)生成一个新的样本[xi1]:
[xi1=xi+α1?(xij-xi)] ⑴
Step3 根据需要过采样的数量,重复Step1和Step2即可以完成数据的过采样。
1.2 VAE过采样方法
变分自编码器是深度生成模型的一种形式,是由Kingma等人[10]提出的基于变分贝叶斯(Variational Bayes,VB)推断的生成式网络结构。如图2所示,VAE由编码器和解码器两个部分组成[11],编码器将原始数据X转化为隐向量Z,解码器将隐向量Z还原成尽可能接近原始数据的生成数据X'。
在进行样本生成时,编码器通过内部神经网络将真实样本X编码到隐空间的一个概率分布[q(Z|X)]中,由均值μ和方差σ2确定,然后从[q(Z|X)]中随机采样得到隐向量Z作为解码器的输入,最后得到生成样本X'。由于解码器的概率分布受到隐向量Z的约束[12],因此确定一个基于Z的条件概率分布[p(X'|Z)]。VAE的损失函数如下:
[cost=KLN(μ(X),σ2(X))N(0,1)-logPp(X'|Z)(X)] ⑵
在训练时将数据解码映射到标准正态分布N(0,1)中,使用KL散度表示[q(Z|X)]与标准正态分布N(0,1)的距离,用概率分布[p(X'|Z)]下P(X)的对数似然表示生成样本X'与输入样本X的距离。通过将损失函数最小化得到最优模型后,利用解码器进行样本的过采样。
1.3 基于过采样与迁移学习的入侵检测模型
网络入侵检测是指对异常的网络流量和活动进行监控,并将其与正常的网络预期行为进行区分[13]。本文使用深度前馈神经网络[14]构建网络入侵检测模型,并且应用变分自编码器模型对网络入侵检测数据集中的不平衡数据进行过采样,然后在过采样后混合的数据集上训练检测模型。
在传统的检测模型构建时,首先在训练集上对检测模型训练至最优状态以后再到测试集上进行检测实验,而本实验中的训练集包括过采样后混合的数据集以及没有过采样处理的原数据集,为了检测模型尽可能的学习到训练集中的样本特征,本文提出使用迁移学习的方法来构建检测模型。在检测模型训练时,首先在过采样后混合的训练集上训练检测模型,然后再迁移到没有过采样处理的训练集上进行微调训练确定最终的模型。系统流程如图3所示。
整个系统流程如下。
⑴ 网络入侵数据预处理。主要包括字符型特征属性数值化、数据标准化、标签数值化等。
⑵ 训练VAE过采样模型。将NSL-KDD数据集中的数据样本编码映射到高斯分布N(0,1)中,其中,编码器和解码器都是5隐层每层400个神经元的前馈神经网络。过采样模型在训练时使用Relu函数作为每个隐层的激活函数,并使用Adam optimizer优化器进行最小损失求解,得到最优状态下的过采样模型。
⑶ 数据过采样。对网络入侵检测数据集中的少数类进行过采样,使用VAE中的解码器以及SMOTE过采样方法对少数类的样本进行过采样,然后将过采样的样本与原样本混合,使得所有类别样本数量相等。
⑷ 入侵检测分类。本实验的检测模型使用5个隐含层,每个隐含层有100个神经元的FNN模型。在进行入侵检测实验时,首先将过采样数据与原数据混合,然后在混合后的数据集上迭代训练检测模型100次得到预训练的模型;再使用迁移学习的方法在原数据集上迭代训练20次,得到最终的检测模型;最后在测试集上进行测试,并对不同过采样方法中的检测模型准确率进行比较。
2 实验
2.1 数据集
本文实验使用网络入侵检测领域内公开的数据集NSL-KDD数据集,包括1个训练集KDDTrain+以及2个测试集KDDTest+和KDDTest21[15]。其中训练集包括22种攻击类型的标签样本,测试集包含39种攻击类型的标签样本。这些标签样本属于5种类型:Benign(正常)、DOS(拒绝服务攻击)、Probe(探测性暴力破解攻击)、R2L(远程对本地攻击)、U2R(特权升级尝试攻击)。表1为训练集和测试集的5种标签数据数量分布。
表1中Benign为正常样本的类别标签,其余四种均为恶意攻击样本的类别标签。从表1中可以看出R2L类、U2R类的数量远少于Benign类与DOS类的数量。因此,将R2L类与U2R类视为少数类,将Benign类与DOS类视为多数类。检测模型在训练时需要大量的标签数据进行学习,样本少则检测效果不好。为了解决这一问题,本文应用过采样的方法先对数据集中的不平衡数据过采样后再训练检测模型。
NSL-KDD数据集中每个样本都具有41维特征,其中包含了3个字符型特征,对数据的预处理如下。
⑴ 字符型特征数值化。数据集中存在3个字符型特征(“protocol_type”、“service”、“flag”)。检测模型需要输入数值型特征进行计算,本文使用one-hot编码的方式将字符型特征转换为数值型。如特征“protocol_type”有3种取值:“tcp”,“udp”,“icmp”,经过one-hot编码以后对应变成二进制特征向量(1,0,0),(0,1,0),(0,0,1)。将数据集内的3个字符型特征使用one-hot编码转换为数值型特征后与剩下的38维数值型特征组合,得到118维的特征向量,以此作为检测模型的输入向量。
⑵ 数据标准化。训练集中不同的特征具有不同的量纲,为了消除不同的量綱对实验的影响,并且加快模型的计算速度。本实验使用数据标准化操作,对数据集中的数据特征规整后服从均值为0标准差为1的分布。
⑶ 标签数值化。将数据集内5种数据的标签Benign、Dos、Probe、R2L、U2R进行one-hot编码转换为二进制标签向量。
2.2 数据过采样
本文实验对NSL-KDD数据集中的不平衡数据使用SMOTE过采样与VAE过采样,具体采样数据如下:
⑴ SMOTE过采样。利用传统的SMOTE过采样方法,对NSL-KDD数据集中训练集KDDTrain+的恶意攻击类别DOS、Probe、R2L、U2R的样本进行过采样,生成DOS类别样本21416个,Probe类别样本55687个,R2L类别样本66348个,U2R类别样本67291个。然后,生成的样本与原样本混合,得到SMOTE过采样后的训练集,其中每个类别样本的数量都为67343个。
⑵ VAE过采样。在VAE模型训练至最优状态后,通过其内的解码器,从概率分布[q(Z|X)]中采样解码生成新的样本,对训练集中DOS、Probe、R2L、U2R类别的样本进行过采样,过采样的数量与SMOTE过采样中一致,然后将过采样中生成的样本与原样本混合。
2.3 入侵检测实验结果
图4所示为FNN模型作为检测模型在实验中的准确率变化情况。首先,检测模型分别在不同的训练集(SMOTE过采样后的训练集、VAE过采样后的训练集)上迭代训练100次,然后再到原数据集上迭代训练20次后确定最终的模型,最后在测试集上进行测试,得到准确率。
从图4中可以看出,在VAE过采样后混合的数据集上训练出的检测模型准确率最高,并且在使用迁移学习的方法后准确率还有进一步的提升,这说明模型充分的学习到了数据集中各类型样本的特征。为进一步的分析过采样方法对检测模型的作用,本文结合准确率(Accuracy)与各类别分类的精确率和召回率的调和平均值(F1-Score)对不同的过采样方法进行分析。结果如表2所示。
相比于原数据集上直接检测分类的方法,VAE过采样后检测模型的准确率提高了3.23%,比传统的SMOTE过采样方法高1.59%。F1-Score值越大表明模型对该类别的分类精度越高,从四个实验中的F1-Score可以看出在VAE过采样后的训练集上训练的检测模型对测试集中各个类别的样本分类精度都有所提高,基本上都高于传统的SMOTE过采样方法。
综合图4和表2中的准确率和F1-Score的值可以得出:使用过采样方法提高了检测模型对少数类的分类精度,从而提高了检测模型的准确率,并且基于深度学习的VAE过采样方法在提高检测模型性能方面要优于传统的SMOTE过采样方法。出现这种现象的原因可能是SMOTE过采样的原理过于简单,其基于插值来合成的过采样样本,使得样本缺乏创新性而成为冗余样本,增加模型的训练难度。基于深度学习的过采样方法,能够更加准确的学习到待采样样本的分布,最大程度的减少冗余样本的出现,并且生成出具有一定创新性的样本,使得检测模型在检测未知攻击上具有更大的潜力。
3 结束语
针对网络入侵检测领域中由于训练集的数据数量分布不平衡而导致检测模型性能降低的问题。本文以重新平衡数据集内的样本数量分布为研究目标,通过应用VAE模型对不平衡数据进行过采样,并加入迁移学习的方法在过采样数据集与原数据集上训练检测模型,提高检测模型的准确率。在NSL-KDD数据集上实验结果表明,与传统的SMOTE过采样方法相比,在提高检测模型的准确率上基于深度学习的VAE过采样方法更具有优势。深度生成模型在网络安全领域存还有非常多的应用场景,更多的应用方式还需要进一步的挖掘。
参考文献(References):
[1] S.Dubey and J.Dubey, "KBB: A Hybrid Method for Intru-sion Detection", in International Conference on Computer, Communication and Control,2015:1-6
[2] CHAWLA N V, BOWYER K W, HALL L O. SMOTE:Synthetic minority over-sampling technique[J].Artificial Intelligence Research,2002.16:321-357
[3] 陈高升.基于机器学习的网络入侵检测方法研究[D].重庆邮电大学,2020.
[4] A. DIVEKAR, M. PAREKH, V. SAVLA, R. "Bench-marking datasets for Anomaly-based Network Intrusion Detection: KDD CUP 99 alternatives,"[C]//2018 IEEE 3rd Interna-tional Conference on Computing, Communication and Se-curity (ICCCS), Kathmandu,2018:1-8
[5] 田栋文.基于自编码器的图像生成算法研究[D].北方民族大学,2020.
[6] 李顼晟.基于自编码器结构的生成对抗网络人脸图像生成技术研究[D].電子科技大学,2020.
[7] 张鹏升.基于变分自编码器的人脸正面化产生式模型[J].软件导刊,2018.17(12):48-51
[8] BEAULIEU-JONES B K, WU Z S, WILLIAMS C, et al. Privacy-Preserving Generative Deep Neural Networks Support Clinical Data Sharing[J]. Circulation Cardiovas-cu-lar Quality and Outcomes,2019.12(7).
[9] 范纯龙,张振鑫,丁三军,滕一平,王翼新.基于变分自编码器的交互式旋律生成方法[J].计算机应用研究,2021.38(2):479-483
[10] Kingma D P,Welling M.Auto-encoding variational bayes[C]//International Conference on Learning Represen-tations,2014.
[11] 翟正利,梁振明,周炜,孙霞.变分自编码器模型综述[J].计算机工程与应用,2019.55(3):1-9
[12] 罗智钰,黄立群.基于变分自编码器的入侵检测系统设计与实现[J].电脑知识与技术,2020.16(13):22-24
[13] NASEER S, SALEEM Y, KHALID S. Enhanced NetworkAnomaly Detection Based on Deep Neural Networks[J]. IEEE Access,2018.6:48231-48246
[14] INGRE B, YADAV A. Performance analysis of NSL-KDD dataset using ANN[C]//International Conference on Signal Processing & Communication Engineering Systems. IEEE,2015:92-96
[15] TAVALLAEE M, BAGHERI E, LU W, et al. A detailedanalysis of the KDD CUP 99 data set[C]//Computational Intelligence for Security and Defense Applications, 2009. CISDA 2009. IEEE Symposium on. IEEE,2009:1-6
