浅谈OCR识别技术在科技档案管理中的运用
2021-08-06王瑜
王 瑜
(中国电建集团北京勘测设计研究院有限公司,北京 100024)
OCR文字识别技术的英文全称是Optical Character Recognition,译为光学字符识别。OCR文字识别是视觉感知中一个重要的技术,目的是从图片中提取文字信息。它是利用光学技术和计算机技术把印在或写在纸上的文字读取出来,并转换成一种计算机能够接受、人也可以理解的格式。文字识别是计算机视觉研究领域的分支之一,这个课题已经在很多行业得到应用。OCR识别技术主要可应用的场景有:教育场景文字识别、卡证文字识别、财务票据文字识别、医疗票据文字识别和汽车场景文字识别。
1 OCR技术的流程
OCR文字识别从本质上可以归类为序列化标注问题,主要目标是寻找文本串图形到文本串内容的映射。在工作流程上,《DA/T77-2019纸质档案数字复制件光学字符识别(OCR)工作规范》已有所规定,主要流程是:
1.1 图像输入
首先对图像的分辨率、倾斜度、清晰度、失真度等方面进行评估,并进行适当的调整。然后把不同的格式和压缩方式的图像进行解码。
1.2 图像预处理
主要包括二值化、去噪、倾斜矫正等。
1)二值化:图像录入设备采集到图像,一般都是彩色图像。二值化就是将具有灰度级的彩色图像转换为黑白图像,设定任意的阈值,并与各像素值进行比较,当大于阈值时转换为黑,小于阈值转换为白。
2)去噪:主要方法是均值滤波器、自适应维纳滤波器、中值滤波器、形态学噪声滤除器、小波去噪。
3)倾斜矫正:对图像识别前先对相关的内容进行校正。
1.3 对比识别
1)版式分析:对图片中文字进行分段落、分行的过程,称之为版面分析。
2)档案特征分析:通过分析归档章、公文要素分析、表格分析、印章分析等方面对档案进行分析。
1.4 识别和匹配
以特征提取数据库对比为主。文字的位移、笔画的粗细、断笔、粘连、旋转等因素极大地增加了特征提取的难度。
1.5 成果整理输出
1)成果整理:按照纸质档案数字复制件的版式对OCR成果的版式、公文要素、文字符号等内容进行理解与重建。
2)成果输出:将档案OCR成果同时保存为纯文本形式和双层版式文件形式。
2 OCR技术在科技档案管理中运用的几种场景
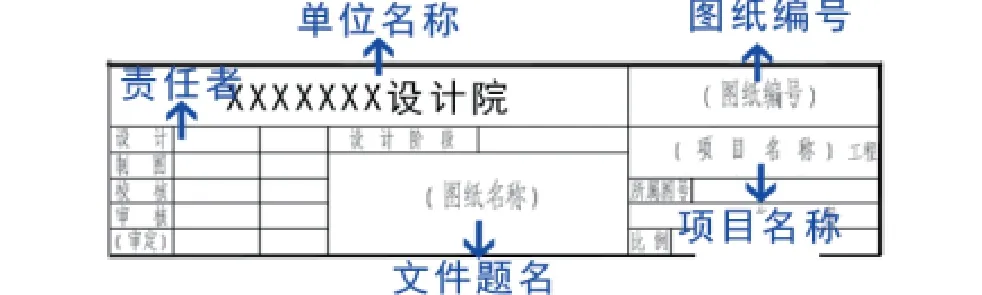
OCR识别在档案场景的应用,主要针对两方面:著录项数据抓取方面和全文OCR识别。在档案文件元数据抓取的方面的OCR识别技术的应用可以参考卡证文字识别,即把OCR技术和档案系统集成,让OCR识别出的文字直接被收录到相应的部位。这一点科技档案出版格式的高度标准化给OCR识别带来了方便。因为文字识别的主要目标是对定位好的文字区域进行识别,主要解决的是将一串文字图片转录为对应的字符的问题。以图纸图签中用于填写著录项目数据抓取为例,如图1所示。在图纸的图签中,我们可以把图签按照原有框格把每一个框格都切割成多个框格,对应框格内获得图纸名称、图号、设计人、制图人、校核人、审核人等信息。那么在档案著录时就可以靠定位和对信息的分析,寻找图签上我们需要的信息,然后导入档案系统中相应的著录项里。
OCR技术在科技档案管理中另一个非常重要的运用场景就是全文识别了。全文识别给档案的利用提供了便利。就我们自己单位来说,曾经在有人需要利用档案的时候,只能对著录项中著录的内容进行检索,这就需要提供相对准确的图号或关键词等信息,如果相应关键词关联的档案太多,就需要人工筛选。而且没有全文检索,也很难再借阅前知道文件内是否有自己需要的内容,不解决这些问题,档案部门没办法提供良好的档案利用服务。
3 OCR识别技术在科技档案管理的过程中遇到的问题
3.1 早期档案不清楚
最近形成的科技档案纸张干净、印刷清楚,给OCR识别技术提供了良好的环境。但是早期的档案就存在纸张泛黄、印刷模糊等问题。甚至很多档案在最初形成的时候所处环境就极度恶略,比如一些档案,是在工地上直接形成的,工地上条件不好,档案也有明显被水浸泡过的情况,或者沾上了其他的污渍,甚至皱皱巴巴的情况。这就给OCR识别带来了困难。
3.2 文字难以识别
在科技档案中存在很多数学公式。另外有的科技档案是手写的,虽然文字清晰,但是并不是常规的印刷体。另外档案中文字的排版也有各种各样的种类,还有表格和图片也给OCR识别技术带来了挑战。
4 解决办法
4.1 早期档案不清楚的问题的解决
1)图片预处理:对于模糊不清的档案,在数字化扫描过程中,首先应该严格按照《DA/T31-2017纸质档案数字化规范》执行,如为了最大限度保留档案原件信息,便于多种方式的利用,需要采用彩色模式进行扫描,如果页面为黑白两色,也可以采用黑白二值或灰度模式扫描,扫描分辨率应不小于200dpi。褶皱不平影响扫描质量的纸质档案应先进行压平等相应技术处理。对于扫描后仍然模糊的档案就需要应用计算机图片处理的技术来处理了。比如图片太黄可以调节亮度,模糊可以调高对比度,或者曲线来找到能使图片变得最清晰的方法。如果需要局部调节则是 用选框工具对想要修改的局部进行框选,再进行上述调节。如果局部边缘是不规则形状的话,则需要用钢笔工具建立选区进行修复。对于局部污渍的处理我认为可以高低频的方式进行修复。但是这些方法处理图片太过耗费精力,在操作时可以只对非常模糊的档案进行此类操作。
2)选择适应的二值化方法:常见的图像二值化方法很多目前二值化的方法主要分为全局阈值方法、局部阈值方法和基于深度学习的方法。全局阈值方法常见的有固定阈值方法和Otsu方法,其原理都是通过人工设定的公式直接找出一个合适的统一阈值对图像进行二值化。局部阈值方法主要有自适应阈值算法、Niblack算法等。是根据像素的临域块的像素分布来确定该像素位置上的二值化阈值。这样做的好处在于每个像素位置处的二值化阈值不是固定不变的,而是由其周围领域的分布来决定的。基于深度学习的二值化方法主要有全卷积的二值化方法,在图像分类和图像检测等方面取得了巨大的成就和广泛的应用,传统的基于CNN的分割方法的做法通常是:为了对一个像素分类,使用该像素周围的一个图像块作为CNN的输入用于训练和预测。
3)选择适应的降噪方法:图像噪声是指存在于图像数据中不必要的或多余的干扰信息,产生于图像的采集、量化或传输过程,对图像的后处理、分析均会产生极大的影响,因此一种好的去噪方法在去除噪声的同时,还需要保持图像的边界和细节。早期的去噪方法多为空间滤波,随着度学习的不断发展,基于神经网络的方法不断涌现。去噪方法很多可以通过实际需要进行选择。
4.2 文字难以识别的问题的解决
文字识别时首先要做到把图像增强,常用的图像增强方法有PCA抖动、颜色增强。随机尺度变换、随机剪裁、平移变换等。另外还可以利用深度学习的方法对图像中的文字进行处理。深度学习方法是合成自然场景文本的方法,非常适合于文字识别。在自然场景中,除了手写字,大部分文本都市由计算机生成的,只有物理渲染和成像过程不受计算机算法控制。合成的图像样本可以由图像前景层、图像背景层、边缘、阴影组合而成。主要可分为如下六步:
1)字体渲染:随机选取字体,将文本沿着水平文本线或随机曲线呈现到图像前景层中。
2)描边、加阴影、着色:选择字体,将文本沿水平文本线或随机曲线呈现到图像前景层。
3)基础着色:三个图像层中的每一层都填充从自然图像簇中采集的不同均匀色。
4)仿射投影扭曲:对前景和便捷图像层进行随机的全息投影变换,模拟3D环境。
5)自然数据混合:每个图层均从ICDAR203和SVT训练数据集随机采样的图像进行混合。混合方式与混合程度随机决定。该操作会产生折中的纹理和组合范围。三个图像通道也以随机方式混合在一起,提供单个输出图像通道。
6)加噪声:应用高斯噪声、模糊和JPEG压缩等方法为图像加噪声。
5 结语
2020年4 月,工信部印发《关于工业大数据发展的指导意见》,同年5月中宣部改办下发了《关于做好国家文化大数据体系建设工作的通知》足可见国家大力发展信息化产业的决心。近年来数字档案馆的建设、各项规章制度的发布,都像是在督促我们不断学习不断进步,只有这样才能跟上我们所热爱的档案事业进步的脚步,一起成长。
